Lipsync
VTube Studio 可以使用你的麦克风来分析你的语音并据此计算 Live2D 模型嘴型。根据你的模型设置,这也可以与基于相机/手机的跟踪相结合。
你可以在两种口型同步类型之间进行选择:
-
单一口型:
- 旧版选项,仅限 Windows,基于 Occulus VR Lipsync
- 不推荐, 建议使用 更多口型 。
- 本页不会进行讨论,因为 更多口型支持相同(甚至更多)参数并且更加准确。
- 更多口型:
注意: 这里不讨论“单一口型”。如果你仍在使用它,请考虑继续使用“更多口型”。它支持相同 以及更多 参数,性能更高,并且适用于所有平台。
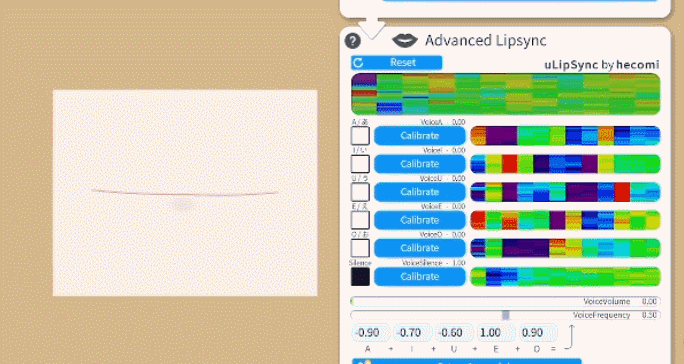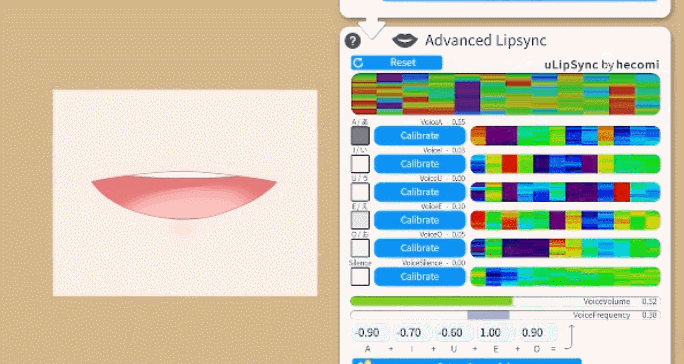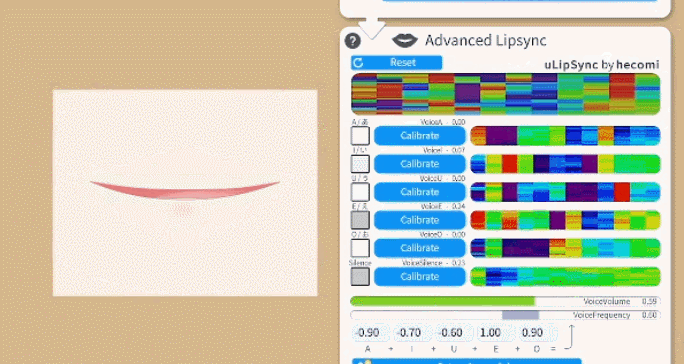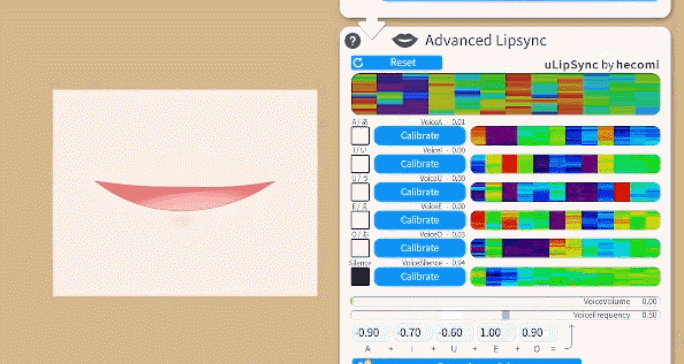
要使用 更多口型,请使用“对口型模式”按钮进行选择。然后选择你的麦克风并确保“使用麦克风”已打开。
主配置卡片上有三个滑块:
-
音频增益: 提高麦克风的音量,将对
VoiceVolume和VoiceVolumePlusMouthOpen参数以及所有VoiceA/I/U/E/O参数产生影响。 - 音量限幅: 降噪,消除低音量噪音。最好将其保持在较低水平或为0,并在音频输入 VTube Studio 之前设置降噪程序。
-
频率增益: 对
VoiceFrequency、VoiceFrequencyPlusMouthSmile以及所有VoiceA/I/U/E/O参数值进行提升。
如果你的麦克风滞后,你可以单击“刷新”按钮重新启动麦克风。你还可以为此设置一个快捷键。
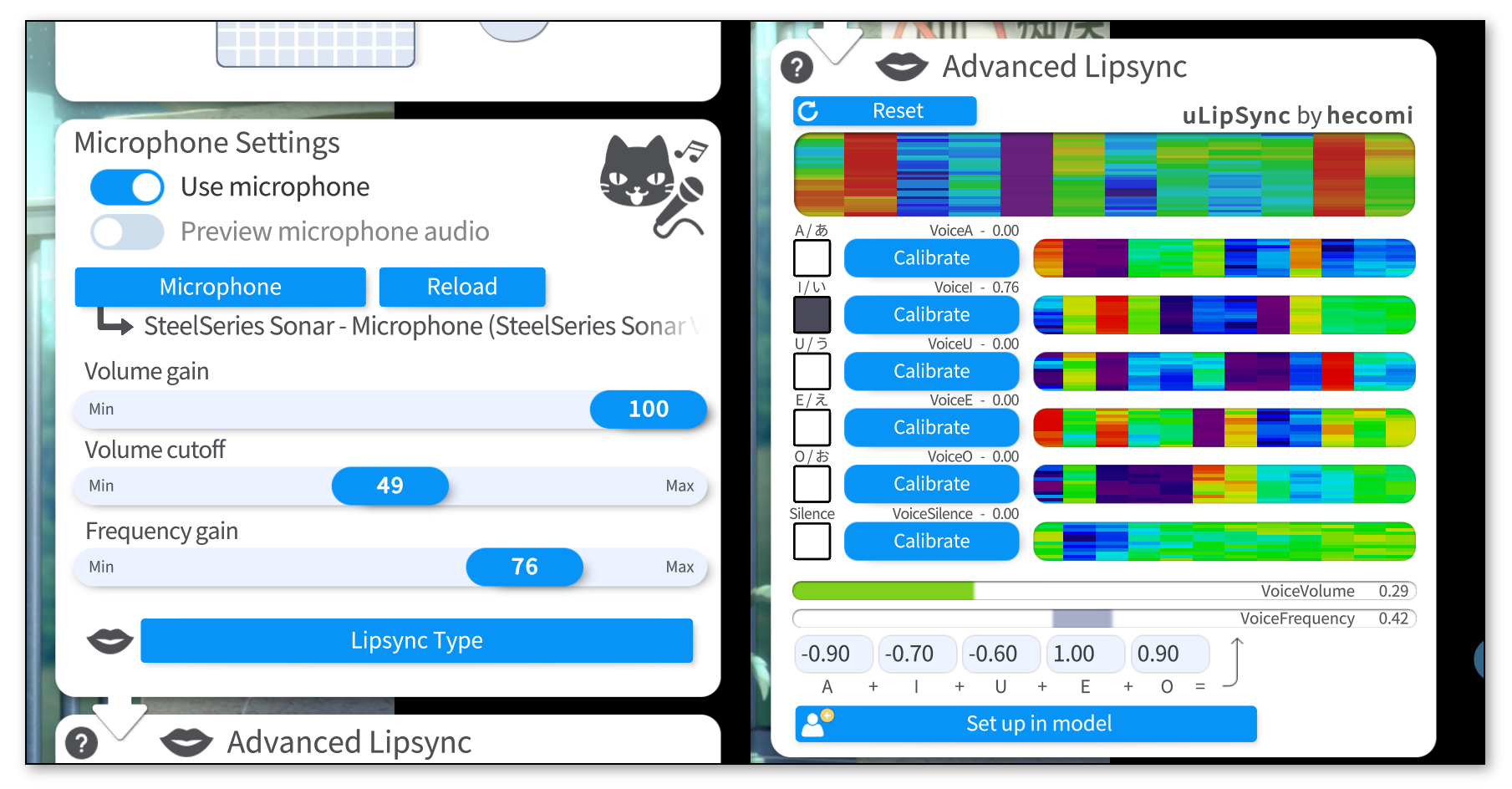
要校准口型系统,请在说出相关元音的同时单击每个“校准”按钮,直到校准结束。这样,口型同步系统就会根据你的声音进行校准。如果你更改麦克风或音频设置,你可能需要重新进行校准。
单击“重置”会将校准数据重置为默认值。
再次说出所有元音并检查相应的元音是否在 UI 上亮起,以确保校准良好。
校准按钮旁边显示的有趣的彩色可视化与校准期间记录在声音中的频谱相关。如果你想了解更多详细信息,请查看 uLipSync 。
口型同步系统输出以下语音跟踪参数。你可以将它们用作 任何 Live2D 参数的输入,而不仅仅是嘴参数。
例如,你可以使用它们通过将元音检测参数连接到模型中的自定义参数来创建“均衡器”效果或其他很酷的音频可视化工具和颜色效果。
以下参数可用:
-
VoiceA- 0 到 1 之间
- 检测元音
A的程度。
-
VoiceI- 0 到 1 之间
- 检测元音
I的程度。
-
VoiceU- 0 到 1 之间
- 检测元音
U的程度。
-
VoiceE- 0 到 1 之间
- 检测元音
E的程度。
-
VoiceO- 0 到 1 之间
- 检测元音
O的程度。
-
VoiceSilence- 0 到 1 之间
- 当检测到“静音”时(基于你的校准)或当音量非常低(接近 0)时为 1。
-
VoiceVolume/VoiceVolumePlusMouthOpen- 0 到 1 之间
- 检测到的麦克风音量有多大。
-
VoiceFrequency/VoiceFrequencyPlusMouthSmile- 0 到 1 之间
- 如果你已经使用
VoiceA,VoiceI, ... 参数,则 不会使用这些参数。如果你的模型只有一个嘴形参数,这只是你的一种选择,因此你可以使用它将检测到的元音组合成一个参数。 - 根据检测到的元音计算。你可以设置如何乘以元音检测值来生成此参数。


可以在此处下载示例模型: "aaa_BlendshapeMouthExample.zip"

该示例模型经过简化(并且有点残缺),但它显示了一种可能的设置,可用于将 基于相机/手机 的口型同步与 麦克风口型同步相结合。
在这个视频中,Brian Tsui 和我仔细研究了这个模型设置,试图找出它的工作原理。如果你有兴趣,请看这里: https://www.youtube.com/watch?v=X2-nHPeF5Q0

总的思路是这样的:
- 当从麦克风检测到 重要声音时,根据声音的响度,口型会逐渐淡化为麦克风口型同步生成的形状。
- 当检测到 很少或没有声音时,只需使用基于相机跟踪的口型即可。
为了实现这一点,我们可以进行以下参数设置: (此处为常规 MouthOpen/MouthForm 参数设置, 但是也可以包括 VBridger 口型)
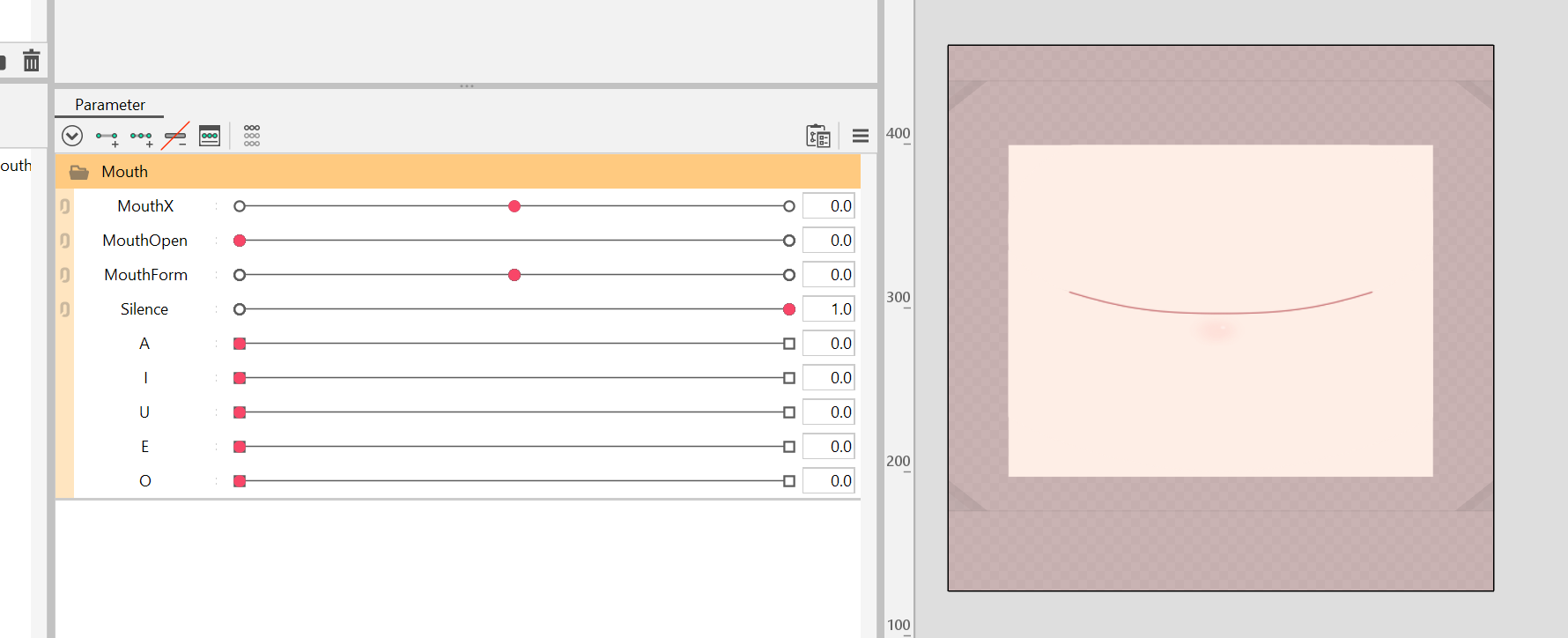
ParamMouthOpen 和 ParamMouthForm 的设置与平常一样。 此外,设置一个 ParamSilence参数。 这个参数之后会连接到 VoiceSilence, 因此当麦克风检测到没有或几乎没有声音时,它的值是 1。
接下来,为 ParamSilence 添加关键帧,以确保 ParamMouthOpen 和 ParamMouthForm 仅在 ParamSilence 位于 1 时,移动 ParamMouthOpen 和 ParamMouthForm 不会使嘴部变形。
以默认闭嘴为基准,设置 融合变形 参数 ParamA, ParamI, ParamU, ParamE 和 ParamO。
对于这 5 个融合变形参数,只需想象一下模型在发出相应元音时的嘴巴会是什么样子。使用典型的日语发音作为参考通常效果很好,即使对于其他语言也是如此。
根据模型绘制的风格,嘴型可能看起来截然不同,但这是我为可爱/少女嘴型制作的参考。一般来说,让他们看起来不那么快乐、更平淡可能会更好。
我不建议使用它作为“模板”。它只是传达想法的参考。

请记住,如果多个参数同时位于 1 ,融合变形会看起来很怪。 VTube Studio 将确保控制这些 Live2D 融合变形的口型同步参数( VoiceA, VoiceI, VoiceU, VoiceE, VoiceO)永远不会同时为 1 ,并且控制它们仅在较小的参数值下混合。
这就是你需要的全部设置。现在,将模型导入 VTube Studio 并运行 更多口型同步的自动设置(口型同步配置底部的按钮)。这将设置以下映射(当然你也可以手动设置):
-
MouthOpen→ParamMouthOpen -
MouthSmile→ParamMouthForm -
VoiceSilence→ParamSilence -
VoiceA→ParamA -
VoiceI→ParamI -
VoiceU→ParamU -
VoiceE→ParamE -
VoiceO→ParamO
同样,当音频口型同步系统检测到音量时, ParamSilence 参数将强制将 MouthOpen 和 MouthSmile 设置为默认值,此时融合变形将进行接管,它们由 VoiceA, VoiceI, ... 跟踪值驱动。
如果你想降低融合变形对口型的影响,可以尝试减小 音频增益和 频率增益滑块。
另请注意,你可以随时关闭麦克风。这将使 ParamSilence 变为 1 ,这意味着你的嘴现在 100% 由基于网络摄像头/手机的跟踪控制,直到你重新打开麦克风。
当检测到声音时,融合变形就会进行接管,这意味着基于网络摄像头/iPhone 的跟踪在很大程度上(或完全)被忽略。不幸的是,这也意味着元音融合变形无法与嘴唇笑容捕捉共存。
还有其他参数设置可以通过不使用融合变形来解决这个问题,但这些设置可能会变得非常复杂,而对改善模型质量几乎没有什么作用。
当你只是发出声音而不张开嘴时(例如发出“姆——————————”的声音),基于声音的跟踪将接管并张开你的嘴,因为它可能会检测到 A 元音。你可以通过使用“姆——————”声音校准 Silence 检测来稍微改善这种特殊情况。
如果麦克风音频滞后于 UI 上显示的值,请使用“重新加载”按钮重新加载所选麦克风。或者,你可以使用快捷键重新加载麦克风。
确切的参数和元音映射设置很大程度上取决于你的模型设置。尝试一下,看看什么对你有用。这可能需要一些尝试和错误,但如果设置正确,这看起来真的很棒,尤其是在唱歌的时候 ♪ ♫ ♬

![]() 如果你遇到了任何该手册中没有回答的问题,请到 VTube Studio Discord
如果你遇到了任何该手册中没有回答的问题,请到 VTube Studio Discord![]() !!
!!
![]()
- 使用单个网络摄像头或iPhone Android设备控制多个模型
- 在模型间复制配置
- 载入自定义背景
- 重新着色模型和挂件
- 录制动画
- 使用OBS录制/串流
- 将数据传输至VSeeFace
- 以管理员身份启动
- 不通过Steam启动应用
- 向Mac/PC推流
- 多人联机
- Steam创意工坊
- 截图与分享
- Live2D Cubism Editor 通信
- VTube Studio设置
- VTS模型设置
- VTS模型文件
- 视觉特效
- Twitch互动
- Twitch热键触发器
- Spout2背景
- 按键表情
- 动画
- 动画、表情、面部追踪、物理等之间的交互
- Google Mediapipe面部捕捉
- NVIDIA Broadcast面部捕捉
- Tobii 眼球捕捉
- 手部捕捉
- 音频口型同步
- 挂件系统
- Live2D挂件
- 层间挂件固定
- 挂件场景和挂件热键
- 添加特殊的ArtMesh功能
- 屏幕光源着色
- VNet网络安全
- 插件 (YouTube, Twitch等平台)
- Web挂件
- Web挂件插件
