Retrieve basic information from links using sealed unions to better handle possible cases.
install linkfo:
linkfo: <latest_version>
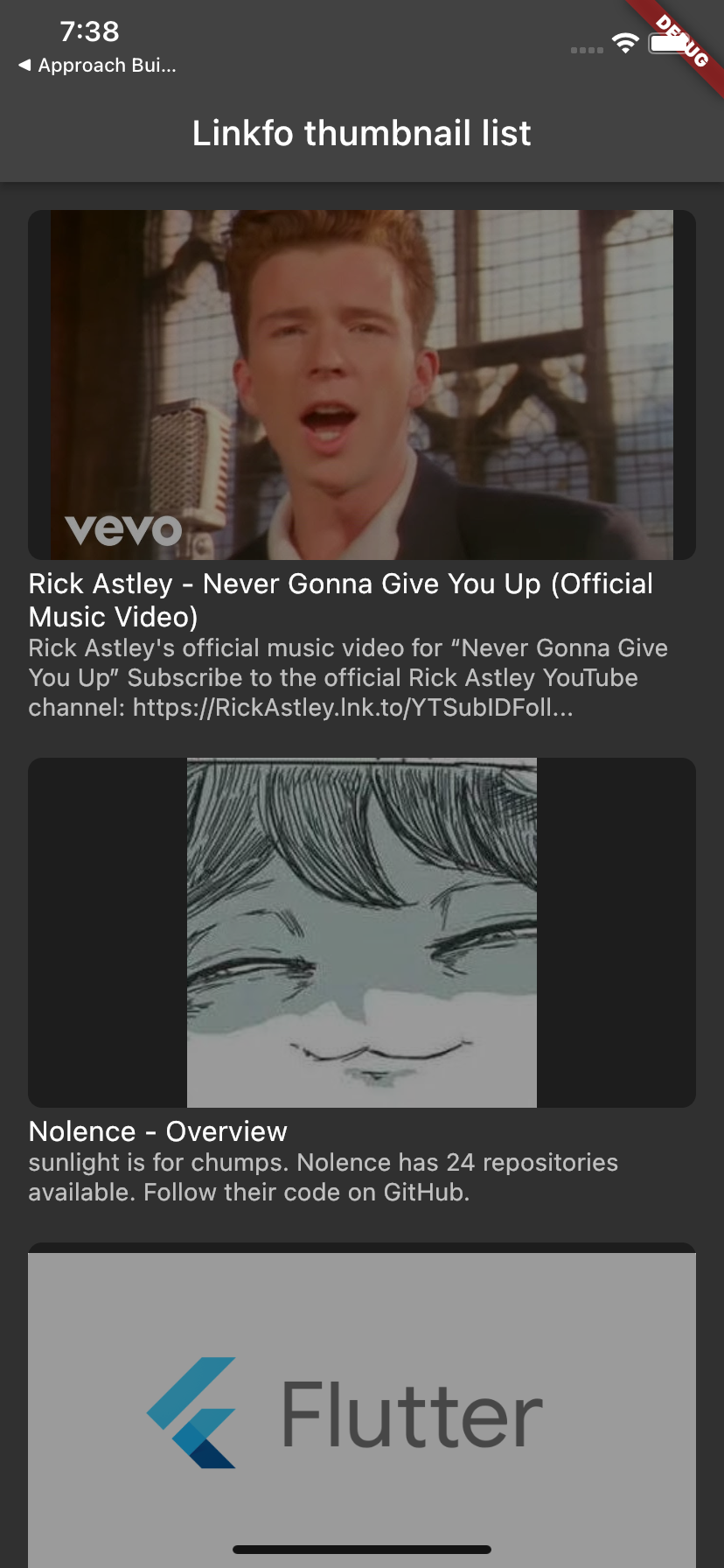
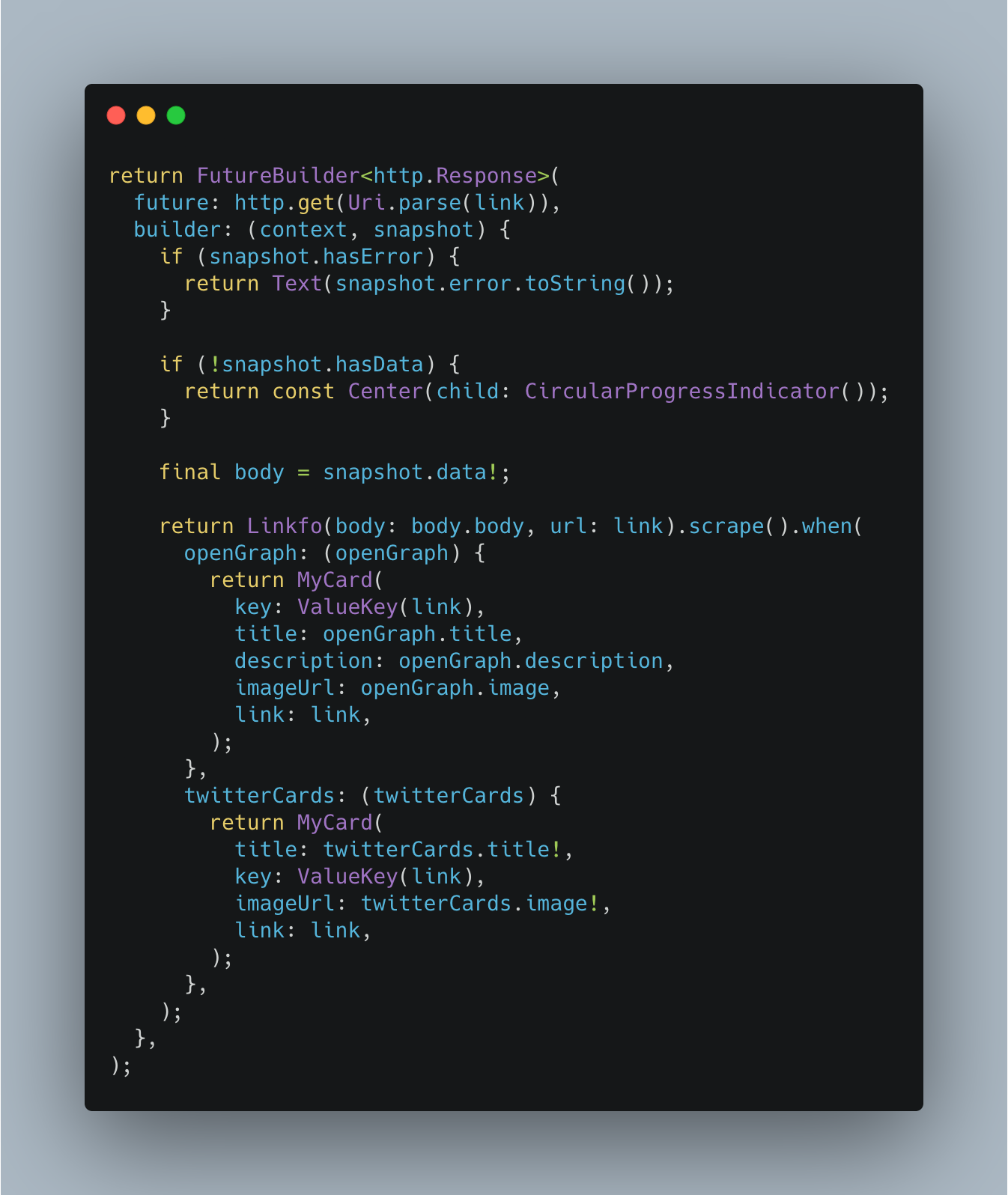
This library is composed of child scrapers and one parent Linkfo scraper. You can scrape as broad or as narrow you'd like. Using Linkfo gives you the option to handle all possible cases.
const url = 'https://www.youtube.com/watch?v=45MIykWJ-C4';
final response = await client.get(Uri.parse(url));
final scraper = Linkfo(body: response.body, url: url);
final info = scraper.scrape();
info.maybeWhen(
openGraph: (info) {
print(info.description);
print(info.image);
print(info.title);
},
twitterCards: (_) {
// ...
},
orElse: () {
// ...
},
);If you're certain you'll only run into one schema, you can use that specific scraper.
const url = 'https://www.youtube.com/watch?v=45MIykWJ-C4';
final response = await client.get(Uri.parse(url));
final scraper = TwitterCardsScraper(body: response.body, url: url);
final info = scraper.scrape();
info.map(
app: (_) {
// ...
},
summaryLargeImage: (_) {
// ...
},
player: (playerInfo) {
print(playerInfo.title);
print(playerInfo.player);
},
summary: (_) {
// ...
},
);const url = 'https://www.imdb.com/title/tt0117500/';
final response = await client.get(Uri.parse(url));
final scraper = OpenGraphScraper(body: response.body, url: url);
final info = scraper.scrape();
expect(info.description, isNotNull);
expect(info.image, isNotNull);
expect(info.title, isNotNull);This api is in early development and might change drastically as I look for the best way to return parsed information.
PRs and Issues welcome. Note, one of my goals was to assume the least amount of nullability and go from there. Some websites are super weird too. Please provide all necessary information when creating issues for broken urls.