KISTI 2020 연구데이터•AI 분석활용 경진대회 참가 (장려상) - ICES팀
문서 내에서 원하는 내용 혹은 질문에 대한 답을 찾고자 할 때 흔히 검색 기능을 이용한다. 하지만 문장 간에 이해 관계가 중요한 과학기술 논문의 경우, 단어의 빈도수나 유사도를 측정하는 단순한 검색만으로는 원하는 바를 찾아내기가 어렵다. 이 때문에 단어 수준의 정보 습득을 넘어 문법적, 의미적 맥락을 파악하는 기계독해를 이용한다. 학술 논문들의 양이 급속도로 증가함에 따라, 학술 논문에 대한 분석과 이해 역시 자연어 처리 분야에서 주목받고 있다.
본프로젝트는 한국어 논문의 초록에서 기계독해 과제를 통해 질의응답 모델을 만들고, 성능을 개선하는 것을 목표로 두고 있다.
-
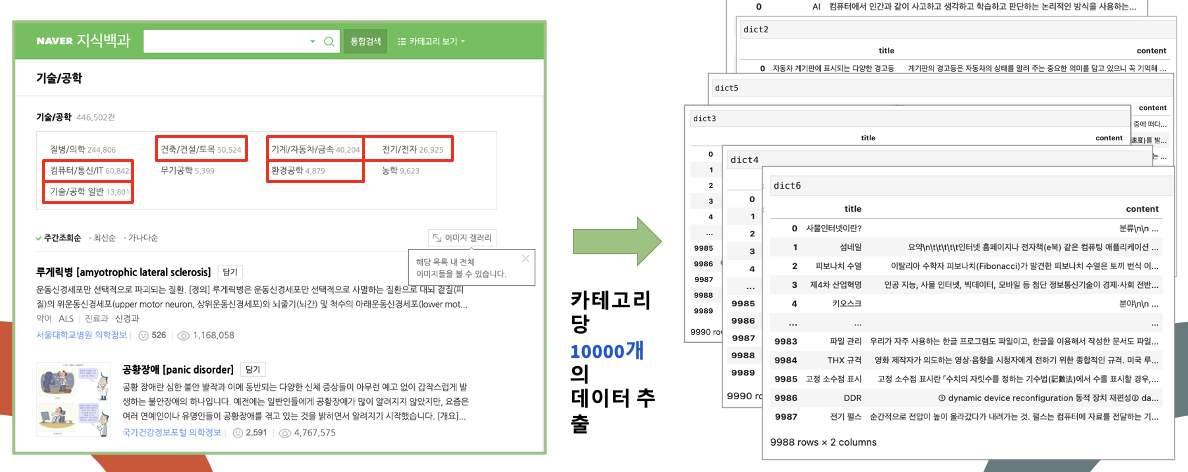
네이버 백과사전에서 기술/공학 카테고리에서 용어와 개념 정리 크롤링 (총 60000개)
-
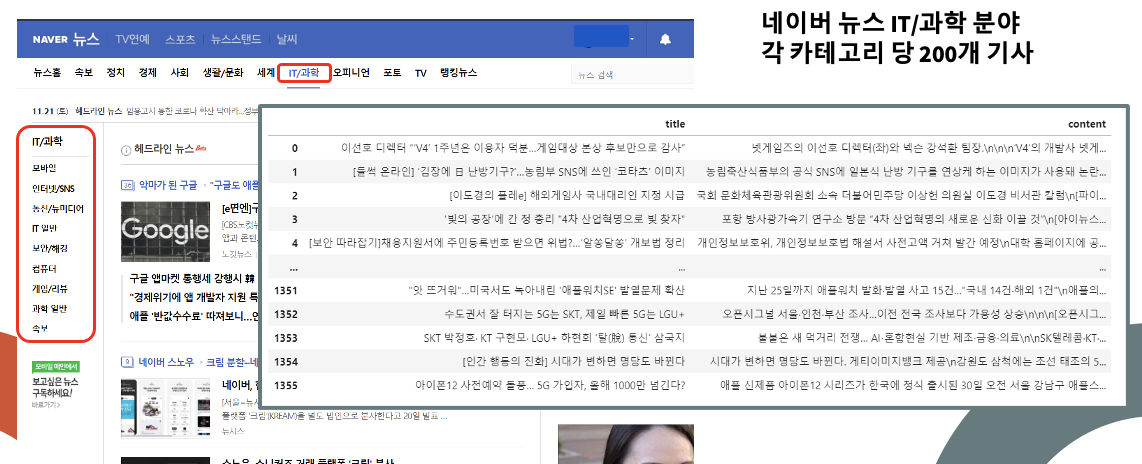
네이버 뉴스 IT/과학 카테고리에서 카테고리당 약 200개의 기사 크롤링 (총 1400개)
-
KISTI AI 인공지능 대회에서 제공한 질의 응답 data set
- Tag 제거
- &~~; pattern 제거
- 이중 공백 모두 제거
- 연산 기호, 단위 기호, 마침표를 제외한 특수 문자 제거
- 초록 논문 + Bert vocab + crawling을 이용해 만든 dataset
-
Word piece tokenizer 사용
-
Mecab + Word piecee tokenizer 사용
- Mecab 선정 이유
- word piece의 경우 자주 나오는 단어를 그 자체로 저장하기 떄문에 한글과 같이 변형이 다양한 언어에서는 잘 동작하지 못함
- 이를 해결하기위해 한국어에 맞게 만들어진 형태소 분석기를 이용
- 많은 한국어 형태소 분석기 중 mecab의 경우 다른 형태소 분석기들과 비교했을때 분석 시간이 굉장히 빠름
- 띄어쓰기가 안되어 있는 문장이 input으로 들어올지라도 훌륭한 분석 결과를 보여줌
-
Mecab 사용 (한글)
- 한글 단어만 추출
- mecab morph를 이용하여 tokenize
- mecab 품사 태깅을 이용하여 word piece구조로 vocab 저장
-
Word piece 사용 (영어)
- 영어 단어만 추출
- word piece tokenize
- Mecab 선정 이유
-
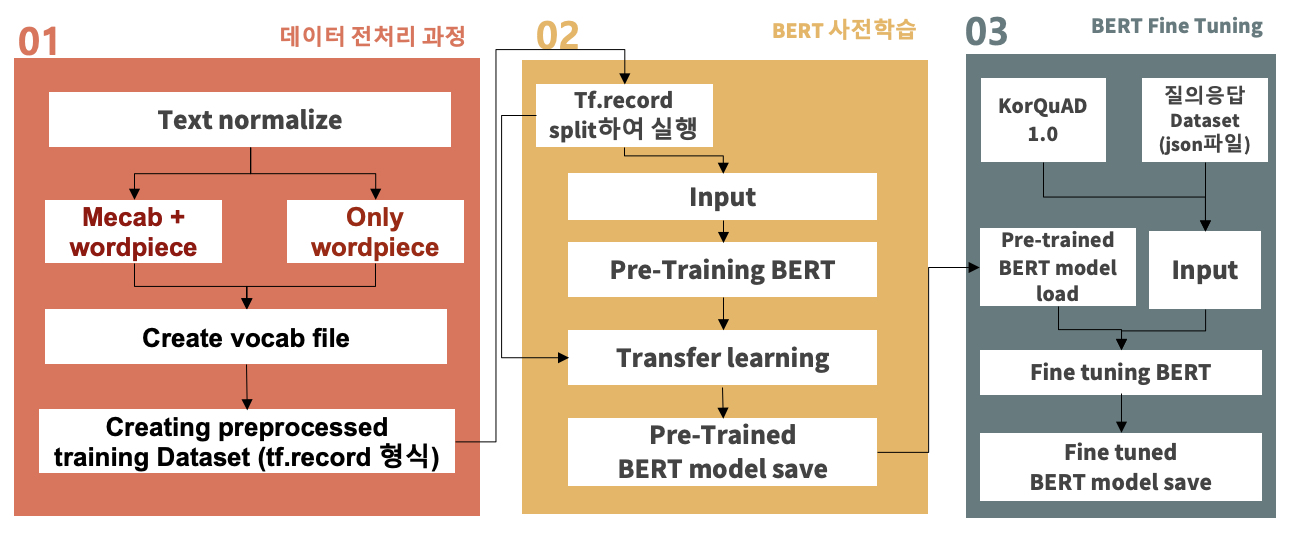
TF.record 생성
- tf.record 만드는 순서
- 1번 과정에서 crawling한 데이터 셋과 논문 데이터 셋이 합쳐진 txt file을 읽는다
- ‘\n’을 기준으로 문서들이 나눠져 있다. 이 문서들을 랜덤하게 섞는다
- Input으로 넣어준 vocab.txt파일을 딕셔너리 형태로 만든다
- Vocab dictionary를 기반으로 문서를 token화 한다
- tf.record 만드는 순서
-
전처리 과정에서 생성한 preprocessed training Dataset (tf.record 형식)를 이용해 BERT 사전학습 진행


-
Input: QA_data.json (KISTI 제공) + KorQuAD QA dataset
-
QA_data.json -> Bert 입력 형식에 맞게 csv 변환시 문제점
- 질문에 대한 답이 한 단락(context)을 넘어가는 경우 답을 찾아내지 못함
- 전처리 시 태그를 삭제하기 위해 <...>를 삭제했지만 답에 존재
- 전처리 시 &...; 를 삭제 해 주어 특수기호 표기 시 문제 발생 (+ 표기가 대체 가능한 것들은 예외처리 해 주었지만, 모든 특수기호를 찾아 예외처리 할 수 없었음)
-
-
과정 및 결과 : Question에 정답이 되는 Paragraph의 substring을 뽑아내는 것이므로,[SEP] token 이후의 token들에서 Start/End Span을 찾아내는 task를 수행
-
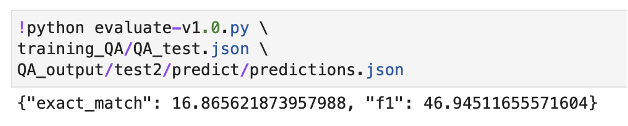
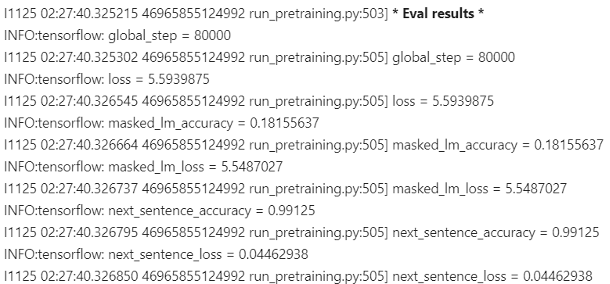
BERT 성능 결과
-
Fine Tuned BERT 성능 결과 (최종)