Architecture
This page describes the workflow supported by the ids.r2dfoo component and how the core design of the component supports that workflow.
DLS use of the IDS is primarily via the TopCAT web interface which is currently in the process of being replaced by DataGateway, although DataGateway retains the original server side TopCAT component (now datagateway-download-api) and most of the communication with the IDS is via that component.
The workflow is based around the following 3 calls to the IDS:
- prepareData(invIds, datasetIds, datafileIds)
- isPrepared(preparedId)
- getData(preparedId)
First the prepareData call is made, passing the IDs of any combination of Investigations, Datasets and Datafiles that the user has selected. This call returns a preparedId which is stored by TopCAT/DataGateway and used to make subsequent calls.
Periodically, the TopCAT/DataGateway server side component polls the isPrepared method of the IDS, each time passing the preparedId returned by prepareData. The IDS will not return true until all of the files requested have been retrieved from archive storage (tape) and are present on the IDS main storage area (disk).
After true has been returned by isPrepared, the Download button is enabled in the TopCAT/DataGateway front end and, if requested, the user receives an email to say that the data is ready for download. The email contains a link which when clicked on will initiate the download process in a web browser. This download takes place via a getData call to the IDS, again passing the preparedId.
The first thing that happens when the IDS receives a prepareData request is to break the combination of Investigation, Dataset and Datafile IDs down, retrieve all of the Dataset and Datafile information that will be required, and write this information to a "prepared" file in a sub-dir of the IDS cache directory. (Note that Dataset information is not required by ids.r2dfoo, but has been retained for initial deployment such that the "prepared" files that get written remain compatible with the IcatProject ids.server component.)
At this point, the total number of files requested is added to a Map in the RestoreFileCountManager keyed on the preparedId, so that this value remains readily available to calculate the progress of a restore request. The list of Datafiles required is then passed to the RestorerThreadManager where the request enters the core of the restore process shown in the diagram below:
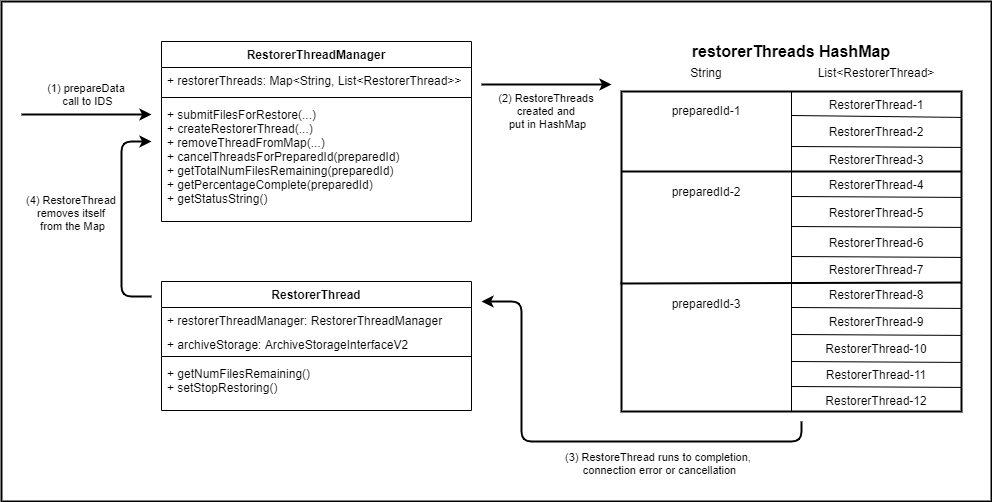
When the RestorerThreadManager submitFilesForRestore method runs, it first checks the main (disk) storage area for files that are already available.
If all files are already available, a "completed" file is created to indicate that the prepareData call completed and an empty "failed" file is created to indicate that no files failed to restore.
If not all files are already available on main storage (this will be the case most of the time) then the RestorerThreadManager looks at the maxRestoresPerThread value and splits the list of files into equal sized smaller lists, all of which are below the maxRestoresPerThread value. If the maxRestoresPerThread is set very high then all the files are likely to be sent to StorageD in a single request, and when set lower, multiple restore requests will be sent to StorageD which will happen in parallel and are likely to be quicker (to a point). The best balance between the number of files per request and the number of simultaneous request will need to be found during testing. The RestorerThreadManager then creates a RestorerThread for each of the sub-lists of Datafiles and places these in a List of RestorerThreads in the restorerThreads HashMap, keyed on the preparedId. Each RestorerThread has a reference back to the RestorerThreadManager, allowing it to re-create another RestorerThread if connection problems to StorageD are encountered, and to remove itself from the restorerThreads HashMap when it completes.
During the prepareData process, the getTotalNumFilesRemaining and getPercentageComplete methods can be called on the RestorerThreadManager to get an indication of how many/what percentage of files are now available on the main (disk) storage area. To carry out these calls the RestorerThreadManager goes to the restorerThreads HashMap and asks each thread for the given preparedId how many files it is still waiting for.
If the cancelThreadsForPreparedId method is called, the RestorerThreadManager again goes to the restorerThreads HashMap and sets the stop flag on each of the RestorerThreads. This allows each RestorerThread to complete writing the file it is currently working on before exiting, thus ensuring that no half written files are left on the main storage area.
When isPrepared is called, this goes directly to the RestorerThreadManager to check whether the number of files remaining for the given preparedId is zero (ie. the restore has completed). This is a very lightweight call, which is good because it will repeatedly be called after a restore has been requested. If no restore thread are running, the "prepared" file is read to get the list of Datafiles requested. The failed file is also read to get a list of any files that failed to restore. The main storage area is then checked to ensure all the files are still present, apart from those that failed to restore. If they are all available, true is returned, otherwise a restore request is submitted to restore the missing files (they may have been on the main storage a long time and some of them may have been removed by the Tidier).
When getData is called, almost identical checks are performed as for isPrepared to check that all the Datafiles are still on main storage. If they are, then an IdsStreamingOutput is created which uses the zip and compress flags to decide whether to put all the files into a zip file and whether that zip file should be compressed or not. No zip file is created on disk - the requested files are written directly to the OutputStream, which is read by the browser, wget, curl or whatever tool is being used to make the getData call.
With the ICAT Project ids.server, a "storage plugin" needs to be deployed in Payara before the IDS is installed, and the IDS run.properties file specifies which classes in that plugin are used for MainStorage, ArchiveStorage and the ZipMapper.
To simplify both development and deployment in ids.r2dfoo, the StorageD plugin is now defined in the pom.xml file so that it does not need to be deployed separately but is instead included in the deployed version of ids.r2dfoo. Also a modification was required to the ArchiveStorageInterface so that in addition to the 'restore' method already being used, an additional method 'getNumFilesRemaining' is defined. This allows for the implementation of the new functionality to report on the progress of a restore request. The new interface, ArchiveStorageInterfaceV2 is defined within the ids.r2dfoo codebase, along with the implementation of it, ArchiveSDStorageV2. This is almost identical to the ArchiveSDStorage class defined in the StorageD plugin but has minor modifications to enable the additional method 'getNumFilesRemaining' to be implemented. In addition to the StorageD implementation of ArchiveStorageInterfaceV2, an ArchiveStorageDummy implementation was created for development and testing purposes. More information on what it does and how it works can be found in the Javadoc comments of the class itself.