

In our research, we found many approaches to building a conversational agent. All are categorizable into two main types:
End-to-end models are one-component systems where the input (the user utterance in our case) is directly fed into the model, and its output (the agent response) is propagated to the user directly.
Our problem requires a sequence-to-sequence model, and a popular choice for seq2seq models is BERT.

Problems with this approach:
- Learning a mapping from a user utterance to a bot response is a tough task to learn that requires a huge amount of training data, and it’s especially challenging in our case because:
- The bot is required to speak in Arabic, which is notorious for its lack of training data.
- The bot should be able to interact with the users about health-related topics, which is even harder to learn mapping for.
- These types of models are convenient for QA bots, but we need our bot to be able to interact with the user in long conversations and to be able to preserve context.
Modules-based systems are composed of multiple components each responsible for a certain task and organized together as a whole.

There are many ways to build a modules-based conversational agent, and our solution of choice was a Task-oriented Dialogue System.
Agents that operate in a dialogue-driven environment (for example, chat applications) and their goal is to accomplish a user task, such as providing a diagnosis given user symptoms.

NOTE: The components of this system are only explained intuitively below without technical details. That’s because the technology which we used to implement this system, Rasa, doesn’t adapt fully to the system described in the diagram, and so some components might be irrelevant to us (like the user simulator). But we introduced the system here because it will lay out an intuitive foundation for understanding the different components of our bot, and their technical details are explained in the implementation section.
This component is responsible for transforming the user input into structured information that the computer can use and make assumptions on, called the Semantic Frame. It has two main jobs:
- Intent classification.
- Named-entity extraction.
Example:
-
Input: “I’ve stomachache”
-
Output:
{ "intent": "symptoms_report", "symptoms": ["stomachache"] }
After propagating the semantic frame produced by the NLU component to the DM, it uses this information for the next action prediction. It’s composed of two sub-components:
-
State tracker.
This component uses the information passed down to it through the semantic frame, along with information it gets from interacting with a knowledge base (if necessary), to generate the current agent state.
-
Dialogue policy.
This component predicts the best next action given the current agent state produced by the state tracker, dialogue history, and previous agent actions. This policy is usually learned in a Reinforcement Learning setting.
This component is necessary only during training time to learn the dialogue policy mentioned above.
It encapsulates a certain user goal, for example, knowing the diagnosis of a certain disease given user symptoms, and it interacts with the dialogue system component to teach the policy optimal action prediction.
Our technology of choice for implementing the described Task-oriented system is Rasa.
Rasa is an open-source machine learning framework for building conversational agents. It provides rich APIs which can be used to build various task-oriented dialogue systems.
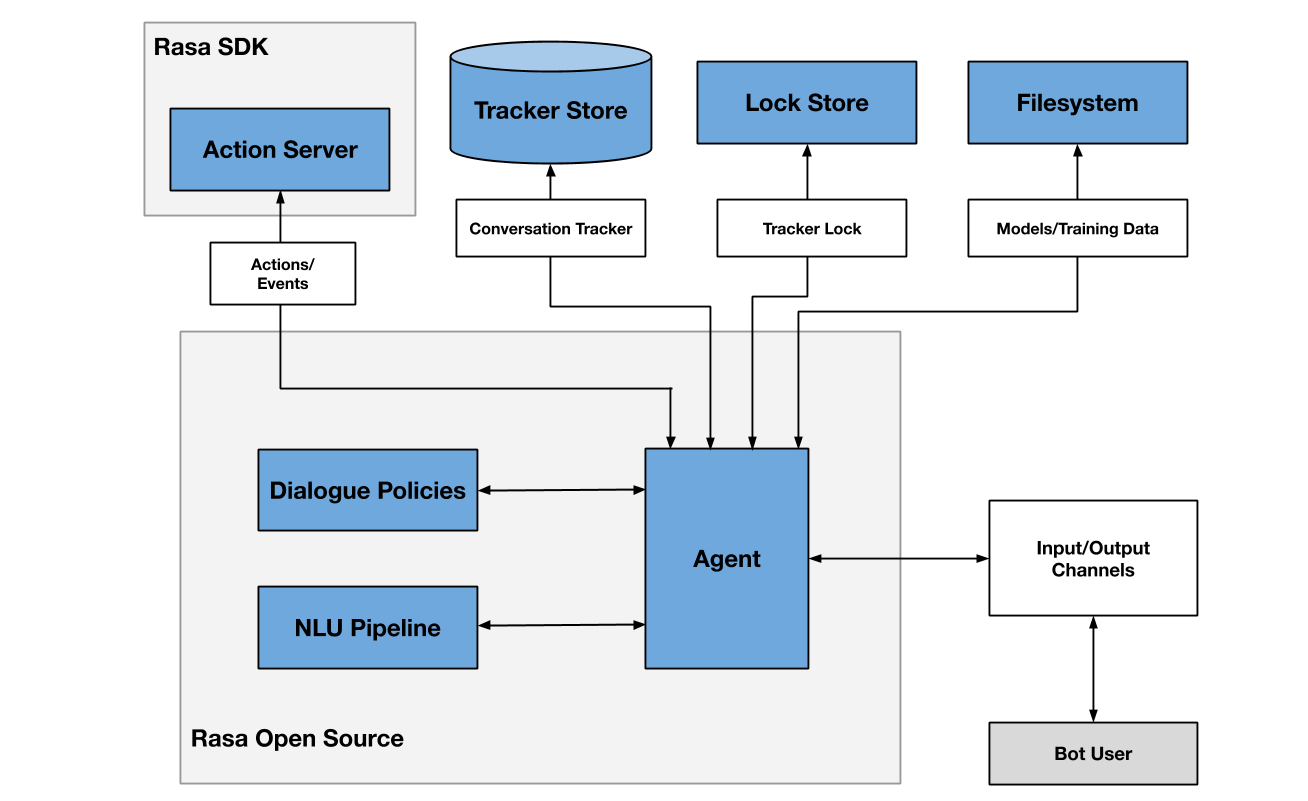
Rasa bot architecture
The interface of the bot. It has APIs to train a model, load it, and receive and send messages through its RESTful API endpoints. It wraps around the NLU and DM components and uses them for the actual user message processing.
A series of steps that are responsible for intent classification and entity extraction training and prediction. Those steps are defined in the config.yml file.
The intents and entities are defined in a domain.yml file, the file which represents everything the agent knows (intents, entities, slots, actions, and responses). The related code from the file:
intents:
- affirm # e.g: Yes, indeed.
- age_report # e.g: I'm 21 years old.
- deny # e.g: No, not really.
- dont_know # e.g: I'm not sure.
- goodbye # e.g: Bye. see you.
- greet # e.g: Hi.
- nlu_fallback # Any message that doesn't fall into one of the other intents.
- observations_report # e.g: I have a very bad stomachache.
- restart # e.g: I would like to restart this conversation.
- sex_report # e.g: I'm a male.
- symptoms_inquiry # e.g: What are the symptoms of COVID-19.
entities:
- sex # Synonyms like (رجل, ذكر, انثى, ابي) are mapped to either male or female.
- ageThe intents and entities’ training examples are defined in a nlu.yml file. A sample from the file:
nlu:
- intent: deny
examples: |
- لا
- intent: affirm
examples: |
- صحيح
- intent: dont_know
examples: |
- لا اعرف
- intent: age_report
examples: |
- عمري [15](age) عام
- intent: sex_report
examples: |
- انا [انثى]{"entity": "sex", "value": "female"}
- intent: observations_report
examples: |
- أشعر بألم في اعصاب يدي
- intent: symptoms_inquiry
examples: |
- ما هي اعراض مرض السكري؟
- intent: greet
examples: |
- مرحبا
- intent: goodbye
examples: |
- وداعا
- intent: restart
examples: |
- اعادة البدء
- intent: nlu_fallback
examples: |
- كم عمرك؟Entity tagging is done by Rasa using the BILOU tagging scheme:

Where:
- U (unit): Marks single-token entities.
- B (beginning): Marks the beginning of multi-token entities.
- I (inside): Marks the inside of multi-token entities.
- L (last): Marks the last token of a multi-token entity.
- O (outside): Marks non-entity tokens.
The training examples were either scrapped from medical forums like WebTeb, or written manually by us.
Rasa has multiple rule-based and machine-learning policies that can be used to decide what action to take next given a user utterance. The desired policies are configured inside the config.yml file.
At every conversation turn (initiated by a user utterance), each of the defined policies predicts the next action to take by the agent along with a confidence level, and the agent predicts the action with the highest confidence. If two or more policies predicted actions with the same confidence level, the agent predicts the action of the policy with the highest predefined priority. And if two or more policies of the same priority predicted actions with the same confidence level, the agent predicts one of the actions at random.
Actions predictions can either be:
- predefined responses which are defined in the
domain.ymlfile as follows:
responses:
utter_confirm_restart:
- text: هل انت متأكد انك تريد الاعادة من البداية؟
utter_greet_back:
- text: مرحبا, انا حكيم, طبيبك الالي 👨⚕️. يمكنك ان تبدأ بان تخبرني بأية اعراض تشعر بها, وسوف احاول مساعدتك من هناك
utter_goodbye:
- text: وداعا واتمنى ان اكون قد افدتك بمعرفتي
utter_observations_too_long:
- text: الرجاء التأكد من ان طول الرسالة لا يتجاوز 2048 حرف
utter_specify_sex:
- text: ما هو جنسك؟
utter_specify_age:
- text: ما هو عمرك؟
utter_no_observations:
- text: لم يتم تحديد اي اعراض في الرسالة, الرجاء التأكد من محتوى الرسالة
utter_pediatrics_not_supported:
- text: للأسف انا لا ادعم طب الاطفال تحت سن 13 عاما
utter_age_too_high:
- text: عمرك اكبر من العمر المحدد وهو 130 الرجاء التأكد من العمر المدخل
utter_symptoms_inquiry_out_of_scope:
- text: حاليا انا لا ادعم الاسئله عن اعراض الامراض
utter_fallback_message:
- text: اعتذر لكنني لا افهم ما تحاول السؤال عنه
utter_default:
- text: هذا السؤال خارج نطاق معرفتي, هل انت متأكد من صياغة السؤالResponses use cases:
-
utter_confirm_restart: Used for when the user asks to restart the state of the conversation. -
utter_greet_back: Used for welcoming users. -
utter_goodbye: Used for farewell messages. -
utter_observations_too_long: Used for when the message reporting the user observations is longer than 2048 characters. -
utter_specify_sex: Used for when the user sex is not specified. -
utter_specify_age: Used for when the user age is not specified. -
utter_no_observations: Used for when the previous user message that was identified as reporting observations doesn’t have any actual observations. e.g: “تؤلمني كثيرا”. -
utter_pediatrics_not_supported: Used for when the specified age is less than 13 years old. -
utter_age_too_high: Used for when the specified age is more than 130 years old. -
utter_symptoms_inquiry_out_of_scope: Used when the user asks about the symptoms of a disease. We indicate that we understood the request but it's currently out of scope (its skill is not implemented yet). -
utter_fallback_message: Used for when the previous message doesn't fall into any of the predefined intents. -
utter_default: Used for when the dialogue policies fail to predict the best next action. -
or custom actions, which are carried out to the actions server to be executed.
Custom actions can execute any code, most notably, they are used for integrations with third-party services and knowledge bases. And this is the case for us as we integrate with Infermedica as our medical knowledge base through custom actions.
Our custom actions defined in the
domain.ymlfile are as follows:actions: - action_setup_interview - action_diagnose
-
action_setup_interviewThis is the action responsible for setting up the diagnosis interview. More specifically, given an
observations_reportmessage, it:-
Translates the message into English using Google Translation API.
-
The English message is parsed using Infermedica’s parse endpoint to get all the observations (symptoms and risk factors) mentioned in the message.
-
The observations are stored inside the
collected_observationsslot.Slots are the bot's memory, stored as a dictionary of key-value pairs, and defined inside of the
domain.ymlfile.The observations stored at this stage are marked as
initial. That’s because when using the diagnosis endpoint of the Infermedica API, observations that were reported initially affect the quality and speed of the diagnosis significantly. -
We use Infermedica’s suggest endpoint to get observations reported by users with similar initial observations, sex, and age. Those observations are then stored inside of the
observations_questionsslot, and the user is asked about them later in theaction_diagnoseaction.Observations returned by Infermedica’s suggest endpoint are marked as
suggest. That’s because they help the diagnosis process just as much as the observations marked withinitialdo.

-
-
action_diagnoseIf the previous action was executed flawlessly, action
action_diagnoseis executed as follows:- Ask the user about the state of the first observation stored inside the
observations_questionsreport. - When the user replies with
affirm,deny, ordont_know, store that observation and its state inside thecollected_observationsslot, and remove it from inside of theobservations_questionsslot. - Repeat from step 1 until there are no more observations inside the
observations_questionsslot, and then invoke Infermedica’s diagnose endpoint. - If the result of the previous endpoint suggest stopping the interview, we stop it and output the diagnosis returned by Infermedica. Otherwise, we add the next observation question returned by the previous endpoint to the
observations_questionsslot. - Ask the user about the state of the current (and only) observation stored inside the
observations_questionsreport. - Repeat from step 2.

- Ask the user about the state of the first observation stored inside the
-
Training data format for the dialogue policies:
-
Stories, defined in
stories.ymlfile.A representation of a conversation between the user and the bot. In this format, user inputs are expressed as intents (and entities when necessary), while the bot's responses are expressed as action names. Example story:
stories: - story: diagnosis - happy path # The name of the story steps: - intent: greet # The intent of the user message - action: utter_greet_back # The bot's action - intent: observations_report # A user message that's reporting observations. e.g: I have stomachache entities: - sex: male - age: 15 - sex: male - slot_was_set: # Setting the age slot from the detected entities - age: 15 - action: action_setup_interview # Calling the action_setup_interview custom action - slot_was_set: # In this action, we store the initial observations detected from the observations_report message - collected_observations: - id: s_100 state: present source: initial - slot_was_set: # Also in this action, we store the observations to suggest that we got back from Infermedica's suggest endpoint given the user initial observations, sex, and age - observations_questions: - id: s_81 source: suggest - action: action_diagnose # Calling the action_diagnose custom action to start the diagnosis interview
-
Rules, define in
rules.ymlfile.They have the same format as stories and are used to describe short pieces of conversations that should always follow the same path. Example:
rules: - rule: greet back whenever the user sends a message with the intent `greet` steps: - intent: greet - action: utter_greet_back
When the agent predicts the next action to be a custom action, this custom action is invoked by calling a RESTful API endpoint that follows a Rasa predefined standard for communicating the input and the output of that custom action back to the agent.

Illustration showing the nature of the relationship between the bot server and the custom actions server
The endpoint of the actions server which the agent has to communicate with is defined inside the endpoints.yml file.
action_endpoint:
url: "http://localhost:5055/webhook" # When the actions server is hosted locallyA channel connector is the means through which the agent receives user messages.
We can integrate it with our own website, Facebook Messenger, Slack, Telegram, and many other channel connectors. We choose Facebook Messenger as our channel connector of choice.
This is the place where the bot’s conversations are stored. Rasa provides out-of-box integrations with different store types like SQL, Redis, and MongoDB. But for this phase, we used the default in-memory store, which stores the conversations in the server’s memory.
The configuration of our NLU Pipeline inside the config.yml file:
pipeline:
- name: WhitespaceTokenizer
- name: LanguageModelFeaturizer
model_name: bert
model_weights: asafaya/bert-base-arabic
- name: DIETClassifier
epochs: 100
- name: EntitySynonymMapper
- name: ResponseSelector
epochs: 100
- name: FallbackClassifier
threshold: 0.3
ambiguity_threshold: 0.1-
WhitespaceTokenizerThis component is responsible for splitting up the input text into tokens based on the whitespaces between words in the sentence.
-
LanguageModelFeaturizerUses BERT with its weights downloaded from HuggingFace to map each token from the previous component into pre-trained word2vec embeddings.
-
DIETClassifierA multi-task architecture for intent classification and entity extraction.
Takes as input a features vector for each token, and thus it requires the pre-trained embeddings from the previous component.
-
EntitySynonymMapperNormalizes the entities extracted by
DIETClassifierinto male or female. -
FallbackClassifierThis component classifies a user message with the intent
nlu_fallbackif none of the classified intents have a confidence level higher than the definedthreshold, or if the difference between the highest confidence levels is greater than the definedambiguity_threshold.

The configuration of our dialogue policies inside the config.yml file:
policies:
- name: MemoizationPolicy
- name: RulePolicy
- name: TEDPolicy
max_history: 5
epochs: 100-
MemoizationPolicyThis policy memorizes the conversations from the training data. It checks if the current conversation matches the stories defined in the
stories.ymlfile, and predicts the next action from the matching stories with a confidence level of 1, otherwise, it predicts actionNonewith confidence 0. -
RulePolicyThis policy uses the rules defined in the
rules.ymlfile to make fixed predictions upon encountering an utterance that is defined in the mentioned file. -
TEDPolicyThis is the policy responsible for generalizing to unseen conversation paths.
The input to the TED architecture is a features vector composed of:
-
The featurization of the previous message intent.
-
The featurization of the previous message entities.
-
The featurization of the bot’s slots.
The featurization of a slot differs based on its type. For example, a slot of type
list, like thecolleted_observationsslot, affects the final features vector depending on whether the list is empty or. -
The featurization of the bot’s previous actions.
The model has to learn a mapping from this input features vector to the correct action as defined in the
stories.ymlfile.The featurization could be one-hot encoding or categorical encoding.
-

We learned a lot about building a chatbot from this project. We can confidently say that we have gone from zero to hero in the task of building a conversational agent. We learned about many NLP concepts and all the phases important to building an AI project, starting from the idea until deployment. It’s true that we didn’t get the most optimal results for this task, but it was definitely a successful experience, and if we ever decided to pursue Hakim in the future, now we know where to start from, and what are the most important problems that need addressing.