PostgreSQL의 공식 문서에 따르면 PosgreSQL은 현재 Query Planning에 관여하는 비용 상수들의 값을 가장 이상적으로 정의할 수 있는 방법이 존재하지 않는다. 이러한 문제점에 기여해 보고자 BERT를 활용하여 입력이 된 SQL Query문을 파악한 뒤 가장 이상적인 비용 상수값을 알려주는 인공지능을 구현한다.
- OS : Windows 11
- IDE : Visual Studio Code
- Used tools : PyTorch, PostgreSQL, TPC-H, Django
- Used languages : Python, PostgreSQL, HTML, CSS
-
TPC-H Benchmark를 이용하여 Database에 대한 Metadata 확보
- 확보된 Metadata
8개의 TablesTable 들에 속해있는 Dataset (사용된 Dataset 용량 : 0.01GB ~ 10GB)22개의 Queries
- 확보된 Metadata
-
22개의 Query 이외에 학습을 위한 추가적인 Query 제작
-
train_labels.txt 구현
-
PostgreSQL 에서 random_page_cost의 값을
1.0 2.0 4.0 8.0 16.0 32.0 이와 같이 6개의 값을 측정하여 빠른 실행시간을 내는 cost value 를 탐색
-
빠른 실행시간을 내는 경우에는
1, 아닌 경우에는0을 부여한다. -
만약 1.0, 8.0의 값을 가질때 빠른 실행시간을 내는 경우 label을
100100으로 선정
-
-
Query data preprocessing, vocab.txt 구현
-
train_query_data_refining.py -
학습을 시키기 위해서 Query data의 정제가 필요
-
Ex)
[정제 전] SELECT name, avg(age) FROM users AS u WHERE name LIKE 'Choi%' AND salary < 500 ORDER BY name ASC[정제 후] SELECT c1 avg c2 FROM t1 WHERE c1 LIKE AND c3 ORDER BY c1 ASCtrain_data.txt구현- 정제시 사용할 단어들을 미리 list로 구현
- vocab.txt를 생성하는 source 구현
-
-
modeling.py-
train_label.txt 파일을 참고하여 labels list를 제작한다.
-
label은 6차원 vector로 재정의 한다.
100100→ [1, 0, 0, 1, 0, 0] -
** Modeling 환경 **
|
Epochs|200| |Batch|16| |Validation rate20%| |Optimizer|AdamW|Learning rate2e -5
-
- 2 종류의 Accuracy
-
Accuracy는 두 종류의 Accuracy로 나뉜다.
-
Accuracy
- 6차원 Target Label 값들 중 예측된 Label의 값과 하나라도 일치가 되면 100% 이다.
- Ex)
예측 Label Target Label Accuracy [1, 1, 0, 1, 0, 0][0, 1, 0, 0, 0, 1]100% -
Exact Accuracy
- 6차원 Target Label 값들과 예측된 Label의 값들을 하나하나 비교한다.
- Ex)
예측 Label Target Label Exact Accuracy [1, 1, 0, 1, 0, 0][0, 1, 0, 0, 1, 1]33.3% - 위 예시의 경우 cost value가 2.0, 4.0 인 경우만 Label이 제대로 예측 되었으므로 33.3% 의 Exact Accuracy를 가진다.
-
-
Accuracy / Exact Accuracy graph
Accuracy Exact Accuracy 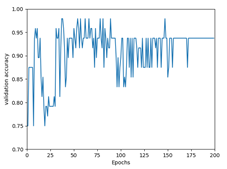
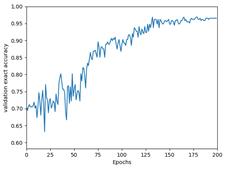
-
Loss graph
Loss 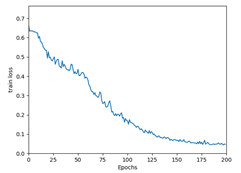
-