We are interested in GPU-accelerating the SoftImpute algorithm from Hastie et al's paper. This is a SVD-based collaborative filtering algorithm.
We use randomized SVD as it seems to work better with GPUs. We use the accelerated proximal gradient method also mentioned in Quanming Yao et al's paper. See below for references.
We compare these GPU-accelerated versions against the CPU version. We see that there is at least a 10X speedup. We also compare against a simple SGD implementation with a bit of tuning. All CPU implmentations, SoftImpute or SGD, use Eigen or BLAS. They are pretty efficient, to be fair.
For the data, currently we only have the MovieLens 20M dataset. We split the data into 5 parts and use one part for measuring the error. (There is no validation set but we hardly do any tuning anyway.)
The results seem to be that SGD is still faster, even when on single core.
Our CPU is a I7-6700K. Our GPU is a Titan-X with 12G RAM.
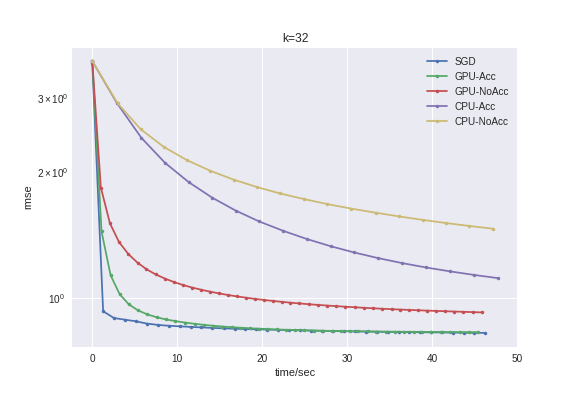
- The slowest is CPU-NoAcc which is the CPU version with un-accelerated proximal gradient.
- The next slowest is CPU-Acc which is the CPU version with accelerated proximal gradient.
- The GPU versions are all significantly faster, seemingly >10X. (We do have a fast GPU unfortunately.)
- However, SGD still seems to be the fastest.
The most tricky part of the GPU code is probably the evaluation of many short inner products. It seems to be the bottleneck, and we have to write a custom kernel to do that efficiently.
export OPENBLAS_NUM_THREADS=1
export OMP_NUM_THREADS=1
DIR=/home/jchiu/projects/gpuimpute/getdata/ml-20m
./impute_main.o \
--output_filename=/tmp/a.txt \
--train_filename=$DIR/train_1.csr \
--train_t_filename=$DIR/train_1.t.csr \
--test_filename=$DIR/validate_1.csr \
--train_perm_filename=$DIR/train_1.perm \
--use_gpu=true \
--max_time=60 \
--log_every_sec=5 \
--soft_threshold=true \
--accelerated=trueWe do not use the one from synaptic. If you have it, delete it. Otherwise it might cause some conflcits.
Run the two installers. Second one is the patch. Say we install to /usr/local/cuda.
We install CUDA to /usr/local/cuda.
- The libs are in
/usr/local/cuda/lib64. Add that toLD_LIBRARY_PATH. - The binaries are in
/usr/local/cuda/bin. Add that toPATH. - The headers are in
/usr/local/cuda/include. Add that tomakefile.
Check nvcc:
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2016 NVIDIA Corporation
Built on Tue_Jan_10_13:22:03_CST_2017
Cuda compilation tools, release 8.0, V8.0.61Try out the sample programs. Do a ldd to make sure it is using the right CUDA library.
We like to use locally compiled libs.
Download OpenBLAS. Install to /opt/OpenBLAS by default. Make sure we have all the interfaces included:
OpenBLAS build complete. (BLAS CBLAS LAPACK LAPACKE)
Instead of using cmake, we will use our own make.inc.
cp make.inc-examples/make.inc.openblas ./make.incAt the bottom of make.inc, add in
OPENBLASDIR = /opt/OpenBLAS
CUDADIR = /usr/local/cuda-8.0
Then make and make install. Check out some of the test programs. Here is an example.
$ ./testing_sgemm --lapack
% MAGMA 2.2.0 compiled for CUDA capability >= 2.0, 32-bit magma_int_t, 64-bit pointer.
% CUDA runtime 8000, driver 8000. OpenMP threads 8.
% device 0: GeForce GTX TITAN X, 1076.0 MHz clock, 12207.2 MiB memory, capability 5.2
% Sat Jul 29 20:29:44 2017
% Usage: ./testing_sgemm [options] [-h|--help]
% If running lapack (option --lapack), MAGMA and cuBLAS error are both computed
% relative to CPU BLAS result. Else, MAGMA error is computed relative to cuBLAS result.
% transA = No transpose, transB = No transpose
% M N K MAGMA Gflop/s (ms) cuBLAS Gflop/s (ms) CPU Gflop/s (ms) MAGMA error cuBLAS error
%========================================================================================================
1088 1088 1088 2205.31 ( 1.17) 3728.02 ( 0.69) 385.84 ( 6.68) 1.13e-08 1.13e-08 ok
2112 2112 2112 3107.60 ( 6.06) 4018.22 ( 4.69) 432.14 ( 43.60) 1.06e-08 1.06e-08 ok
3136 3136 3136 3288.46 ( 18.76) 4961.51 ( 12.43) 413.64 ( 149.12) 1.13e-08 1.14e-08 ok
4160 4160 4160 3419.69 ( 42.10) 5181.66 ( 27.79) 390.72 ( 368.50) 1.02e-08 1.02e-08 ok
5184 5184 5184 3338.83 ( 83.45) 5740.53 ( 48.54) 389.53 ( 715.30) 1.16e-08 1.16e-08 ok
6208 6208 6208 4185.88 ( 114.31) 5945.47 ( 80.48) 427.83 (1118.44) 1.14e-08 1.14e-08 ok
7232 7232 7232 4099.77 ( 184.52) 5809.57 ( 130.22) 430.40 (1757.66) 1.06e-08 1.06e-08 ok
8256 8256 8256 3997.71 ( 281.53) 5772.81 ( 194.96) 399.81 (2815.05) 1.23e-08 1.23e-08 ok
9280 9280 9280 3929.56 ( 406.75) 5886.12 ( 271.55) 419.18 (3813.07) 1.72e-08 1.72e-08 ok
10304 10304 10304 3589.88 ( 609.49) 5405.51 ( 404.77) 385.24 (5679.61) 2.05e-08 2.05e-08 ok
Download from https://github.com/google/googletest/releases. Use cmake and make install.
Just use synaptic.
On applying accelerated proximal gradient method to SoftImpute by Quanming Yao, James T. Kwok https://arxiv.org/abs/1703.05487 https://github.com/quanmingyao/AIS-impute
Spectral regularization algorithms for learning large incomplete matrices by Mazumder, Hastie, Tibshirani. https://web.stanford.edu/~hastie/Papers/mazumder10a.pdf