{kind=link}
##Run Hadoop Cluster within Docker Containers
将Hadoop打包到Docker镜像中,就可以快速地在单个机器上搭建Hadoop集群,这样可以方便新手测试和学习。
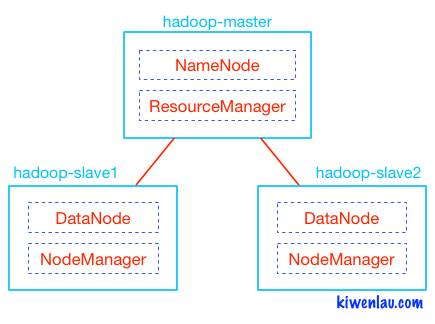
如下图所示,Hadoop的master和slave分别运行在不同的Docker容器中, 其中hadoop-master容器中运行NameNode和ResourceManager, hadoop-slave容器中运行DataNode和NodeManager。 NameNode和DataNode是Hadoop分布式文件系统HDFS的组件,负责储存输入以及输出数据, 而ResourceManager和NodeManager是Hadoop集群资源管理系统YARN的组件,负责CPU和内存资源的调度。
###3 Nodes Hadoop Cluster
#####1. pull docker image
sudo docker pull kiwenlau/hadoop:1.0
#####2. clone github repository
git clone https://github.com/kiwenlau/hadoop-cluster-docker
#####3. create hadoop network
sudo docker network create --driver=bridge hadoop
#####4. start container
cd hadoop-cluster-docker
sudo ./start-container.sh
output:
start hadoop-master container...
start hadoop-slave1 container...
start hadoop-slave2 container...
root@hadoop-master:~#
- start 3 containers with 1 master and 2 slaves
- you will get into the /root directory of hadoop-master container
#####5. start hadoop
./start-hadoop.sh
#####6. run wordcount
./run-wordcount.sh
output
input file1.txt:
Hello Hadoop
input file2.txt:
Hello Docker
wordcount output:
Docker 1
Hadoop 1
Hello 2
###Arbitrary size Hadoop cluster
#####1. pull docker images and clone github repository
do 1~3 like section A
#####2. rebuild docker image
sudo ./resize-cluster.sh 5
- specify parameter > 1: 2, 3..
- this script just rebuild hadoop image with different slaves file, which pecifies the name of all slave nodes
#####3. start container
sudo ./start-container.sh 5
- use the same parameter as the step 2
#####4. run hadoop cluster
do 5~6 like section A