Este projeto utiliza a base de dados Census Income para realizar análises exploratórias de dados (EDA). A base de dados foi extraída do Censo dos Estados Unidos de 1994 e contém informações demográficas e socioeconômicas.
A estrutura do projeto é composta pelos seguintes arquivos:
Census_Income.ipynb: Notebook Jupyter com a análise exploratória de dados, pré-processamento, construção e avaliação de modelos.adult.data: Arquivo com os dados de treinamento.adult.test: Arquivo com os dados de teste.old.adult.names: Descrição das colunas presentes no dataset.
O dataset Census Income contém informações demográficas e econômicas de indivíduos, incluindo atributos como:
- Idade (
age): Idade do indivíduo. - Tipo de emprego (
workclass): Setor de emprego, como setor privado, governo local, etc. - Peso final da amostra (
fnlwgt): Uma medida de peso amostral. - Educação (
educationeeducation-num): Grau de instrução e número de anos de educação. - Estado civil (
marital-status): Estado civil como casado, solteiro, divorciado. - Ocupação (
occupation): Tipo de ocupação como técnico, executivo, vendas, entre outros. - Horas trabalhadas (
hours-per-week): Número médio de horas trabalhadas por semana. - Rótulo de renda (
income): Binário, indicando se a renda é>50Kou<=50K.
- Correções e Limpeza: A base de teste apresentava um erro na coluna
class(target), onde as categorias eram exibidas como>50.em vez de>50e<=50.em vez de<=50. Além disso, algumas variáveis continham "?" no lugar de valores categóricos, indicando dados ausentes. - Pontos de Atenção:
- Identificação e remoção de linhas duplicadas.
- Identificação de outliers para cada variável.
- Verificação do percentual de valores nulos em cada variável.
- Contagem de valores distintos por variável para uma primeira análise exploratória.
- Estatísticas descritivas das variáveis numéricas para identificar possíveis inconsistências.
Nesta etapa, técnicas de estatística como métricas descritivas (média, moda, mediana, Q1, Q3), gráficos (boxplot e histograma) e testes de hipóteses foram massivamente exploradas para trazer sustentação às afirmações acerca dos dados.
- Idade e Renda: A maioria das pessoas com renda
<=50Kestá concentrada nas faixas etárias mais jovens (20-40 anos). Indivíduos com renda>50Ktêm idade média significativamente maior.

- Disparidade de Gênero: A proporção de homens que ganham
>50K(30.39%) é significativamente maior do que a de mulheres (10.94%), indicando uma disparidade de gênero em relação a rendas elevadas.

- Relação entre Raça e Renda: Um teste Chi-Quadrado revelou uma associação significativa entre raça e renda (p-valor: 0.0000), com asiáticos e pessoas das ilhas do Pacífico apresentando o maior percentual de renda
>50K, seguidos por brancos. Negros e indígenas americanos têm as menores proporções.

- Estado Civil e Renda: Pessoas casadas compõem a maior proporção de indivíduos na faixa de renda
>50K.

Análises de boxplot podem passar uma falsa impressão de que as distribuições de capital são praticamente idênticas entre si para os diferentes estados civis:
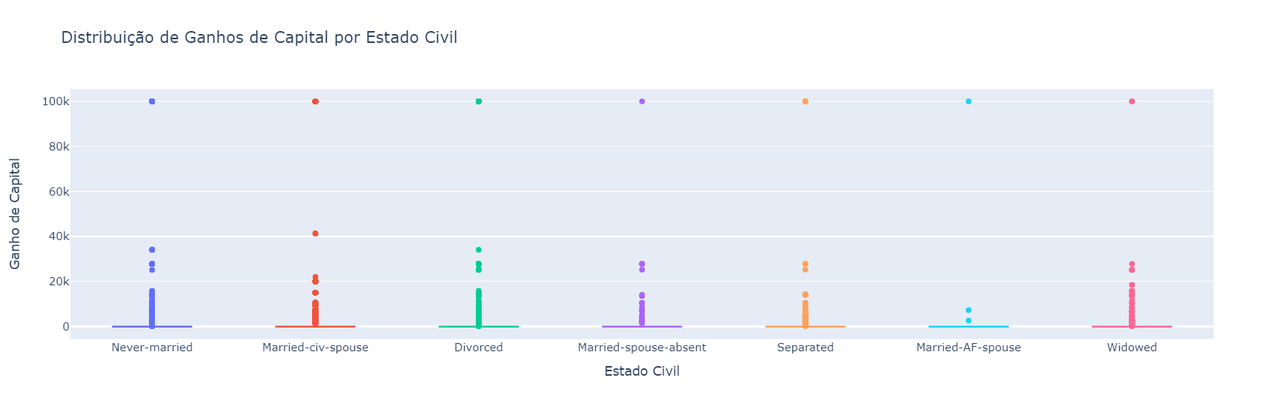
Mas para identificar se há uma diferença estatísticamente significante entre os ganhos de capital de cada um dos estados civil, podemos aplicar um teste de hipótese através do teste de Kruskal-Wallis:
Hipótese Nula (H0): As distribuições de ganhos de capital são iguais para todos os estados civis
Hipótese Alternativa (H1): Pelo menos uma das distribuições de ganhos de capital é diferente entre os estados civis
H-statistic: 845.48, p-value: 0.00000
Rejeitamos a hipótese nula. Há uma diferença significativa nas distribuições de ganhos de capital entre os estados civis
- Distribuição Desbalanceada: Cerca de 76.06% dos indivíduos possuem renda
<=50Ke 23.94% possuem renda>50K.

- Técnicas de Balanceamento:
- SMOTE (Synthetic Minority Over-sampling Technique): Utilizado para balancear a classe minoritária por interpolação, reduzindo o risco de overfitting em comparação com o oversampling tradicional.
- Class Weight: Alternativa ao SMOTE, onde o peso das classes é ajustado de forma inversamente proporcional à frequência, influenciando a função de perda e penalizando erros na classe minoritária.