{kind=link}
A simple Large Language Model trained on Homer's Iliad! Based on Andrej Karpathy's Let's build GPT tutorial!
Named after Orpheus - the legendary Greek musician! I felt this was appropriate as I trained the model on Homer's Iliad.
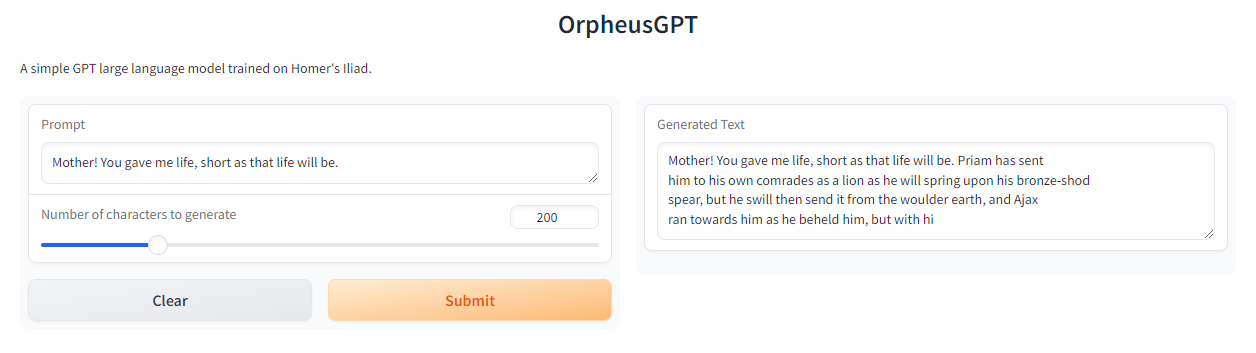
The LLM is hosted on 🤗 Hugging Face Spaces here! You'll find all the usage instructions there.
Note: You should first try generating 10-20 characters (tokens) only. I believe this helps cache whatever can be cached, saving some time when generating more.
Orpheus is a Large Language Model, specifically a Generative Pre-Trained Transformer.
A Large Language Model is a very specific type of Artificial Intelligence that understands and generates human language (like English, for Orpheus). Since computers yet cannot directly be taught all the nuances of Grammar, they are instead fed a large amount of text, and are allowed to 'train' and learn patterns themselves. This has worked for games like Chess (see AlphaZero). Based on this training, they are benchmarked on a certain set of training data kept aside for validation, and finally released when their performance is good enough.
Essentially, LLMs are prediction machines - they learn to predict the next word given enough context.
A GPT (Generative Pretrained Transformer) is a type of LLM developed by OpenAI. It's designed to answer questions, translate text, have conversations, etcetera. GPTs are based on the transformer-architecture (see below).
Transformers were introduced in the Attention Is All You Need paper by Vaswani et al.
Transformers are built on the idea of self-attention which helps the model understand the context it's provided better by focusing on different parts of the text given, the position of letters and words, etc.
No computer in the world can understand language and letters. Computers understand mathematics. This is why before the GPT can be trained, there must be some tokenization involved - which means transforming text into a series of tokens (the fundamental unit of text). For example, for Orpheus, I have used single-character tokenization. This means each character (space, 'a', ':', '!', etc.) is one token. Some other methods involve using a mix of several characters (for example, 'the' could be one token, and 'ee' could be another). OpenAI developed tiktoken an open-source tokenization library.
Self-attention allows the model to understand the relationships between tokens relative to others. This allows models to understand and build connections between tokens even when they are far away.
Mathematically, self-attention works by computing three vectors for each word: Query (Q), Key (K) and Value (V). These are matrices of tokens, and are used to calculate attention scores.
Note: softmax is used to ensure that the attention scores are normalized to 1.
Note 2:
Each layer in a GPT is a feed-forward network that processes the output of the self-attention mechanism. This consists of two linear transformations* with a non-linear activation function** between them.
Here, x is the input,
Transformers don't understand the position of words, so GPT models introduce positional encoding to add more information to build stronger connections. This helps the model understand and predict sequences better.
Note: pos is the position of the word in the sequence (each sequence is composed of 256 tokens in Orpheus).
Note 2: i is the dimension.
Note 3: d is the total dimension of the model.
Overfitting happens when a model becomes too familiar with the training data, and thus becomes unreliable in other scenarios. To prevent this, models use dropout - a technique which involves dropping out (setting to 0) some neurons while training. This helps the model generalize better.
- Nodes (also called neurons) are the basic units that receive inputs, process them (using mathematical functions), and pass them to the next layer.
- Bigram Language Model is another type of Large Language Models. Orpheus uses a GPT built on top of this type of model. The reason we cannot use Bigram Language models directly anymore is that these only consider the previous word when predicting the next one (they belong to a family called n-gram models, and the bi suggest two - which means a sequence of two words). So, we could have 'The car is on the' and the model will give 'tree' because it only considers the word 'the.' GPT analyses more information, and thus is more reliable than these simple models.
- *Linear transformations involve simple changes to data. For example if you have the numbers (2,7), a linear transformation could involve multiplying this by another value (3) and adding a constant (2), so we get (8, 23). It's called linear because it preserves the 'straight' line relationship between the original and transformed numbers. Non-linear transformations involve more complex patterns, for example, squaring or logarithms. This results in non-linearity as the relationship between the numbers is no longer that of a straight line.
- **A non-linear transformation function could involve taking the sigmoid (squashes the output between 0 and 1), or in the case of GPT, using ReLU (Rectified Linear Unit). ReLU takes the input and converts all the negative values to 0 and keeps positive values as they are.
- A massive thank you to the Internet Classics Archive for the translated copy of the Iliad! I have uploaded the original text as well (the original translation, as seen on the website).
- Another thank you to Andrej Karpathy for not just founding OpenAI but also taking the time out to upload high-quality instructional tutorials online!
- I am fairly new to Large Language Models and Artificial Intelligence in general. I will appreciate any feedback on the code.
- Please feel free to add on to this README. I have tried to cover everything to the best of my understanding, but there might be problems still!