This repository contains Jupyter notebook examples showcasing scenarios where Datalayer proves highly beneficial.
Datalayer allows you to scale runtimes from your local JupyterLab or CLI to the cloud, providing the capability to run your code on powerful GPU(s) and CPU(s). 🚀
The first examples delves into system checks and performance benchmarks to ensure optimal GPU and CPU utilization, the next ones explore typical AI scenarios where scaling proves essential.
💡 Note that you can use any notebook within Datalayer without requiring any code changes.
pip install datalayer
git clone https://github.com/datalayer/examples.git datalayer-examples
cd datalayer-examples
jupyter labRead the documentation website to know more about how setup Datalayer.
Don't worry, it is easy 👍 You just need to install the package, open JupyterLab, click on the Jupyter Runtimes tile in the JupyterLab launcher, create an account, wait a bit for your Kernels to be ready, and then just assign a Remote Runtime from any Notebook kernel picker.

- GPU sanity checks
- Performance comparison of CPU and GPU serial and parallel execution
- Parallel execution performance comparison
- Face detection on YouTube video with OpenCV
- Image classification model training with fast.ai
- 'Personalized' text-to-image model creation with Dreambooth
- Text generation using the Transformers library
- Instruction tuning for Mistral 7B on Alpaca dataset
- LLM Inference with llama.cpp
This notebook contains scripts and tests to perform GPU sanity checks using PyTorch and CUDA. The primary goal of these checks is to ensure that the GPU resources meet the expected requirements.
In this notebook, we compare the inference performance of the DeepSeek-R1-Distill-Llama-8B model using GPU acceleration and CPU only.
It demonstrates the significant speedup achieved with GPU offloading and highlights the benefits of quantization (using the GGUF model format) for memory and performance optimization.
Compare the performance with parallel execution.
This example utilizes OpenCV for detecting faces in YouTube videos. It uses a traditional Haar Cascade model, which may have limitations in accuracy compared to modern deep learning-based models. It also utilizes parallel computing across multiple CPUs to accelerate face detection and video processing tasks, optimizing performance and efficiency. Datalayer further enhances this capability by enabling seamless scaling across multiple CPUs.


This example demonstrates how to build a model that distinguishes cats from dogs in pictures using the fast.ai library. Due to the computational demands of training a model, a GPU is required.

This example uses the Dreambooth method which takes as input a few images (typically 3-5 images suffice) of a subject (e.g., a specific dog) and the corresponding class name (e.g. "dog"), and returns a fine-tuned/'personalized' text-to-image model (source: Dreambooth). To do this fune-tuning process, GPU is required.

Those notebook examples demonstrate how to leverage Datalayer's GPU kernels to accelerate text generation using Gemma model and the HuggingFace Transformers library.
This notebook uses Gemma-7b and Gemma-7b-it which is the instruct fine-tuned version of Gemma-7b.
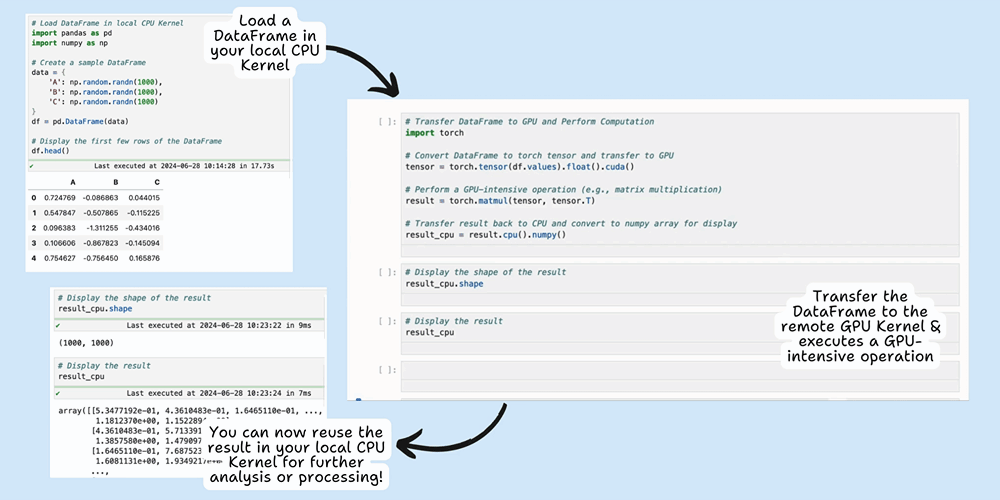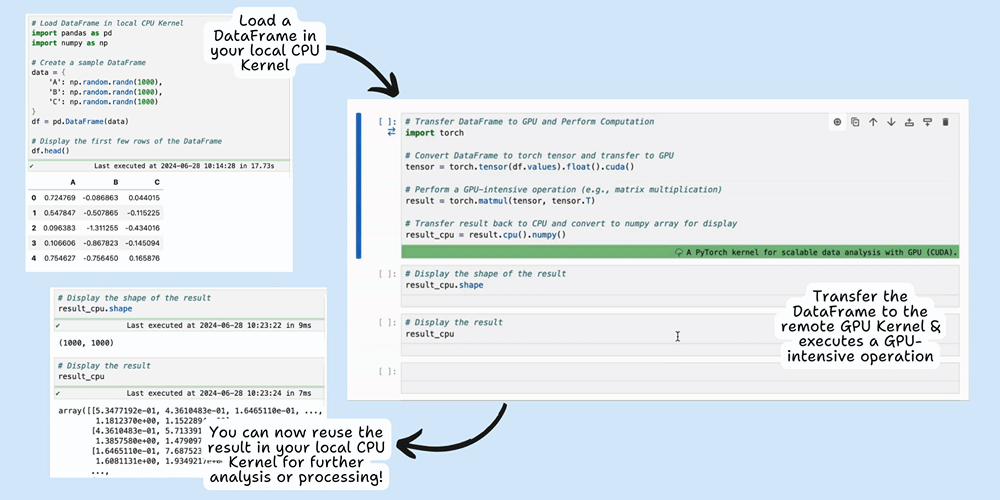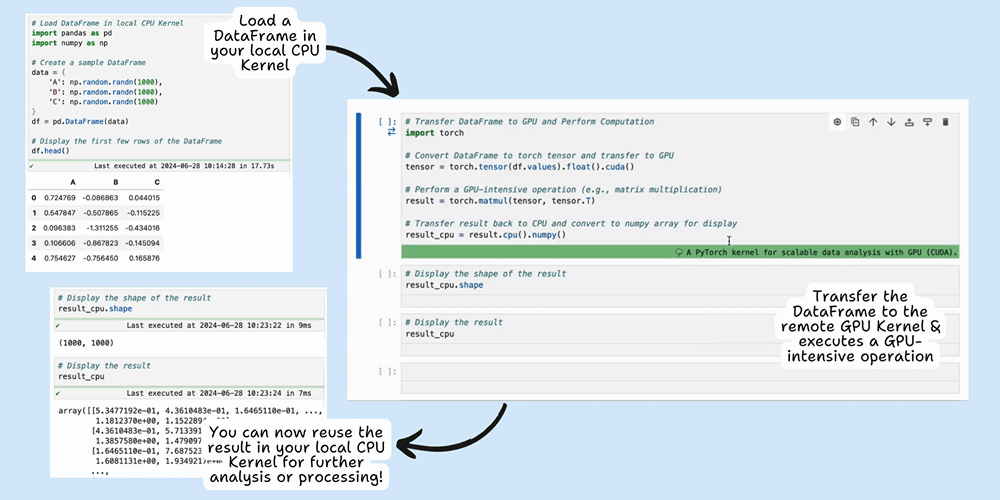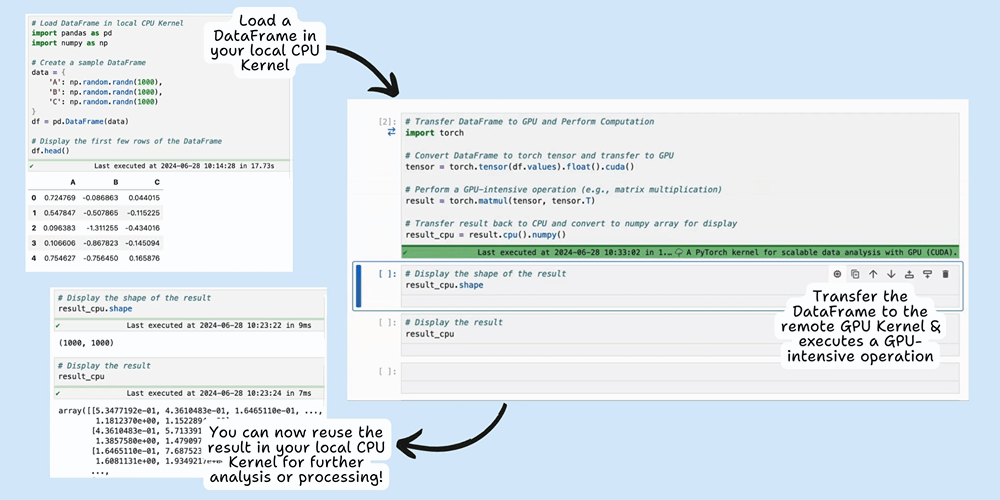
This example demonstrates how you can leverage Datalayer's Cell Runtimes feature on JupyterLab to offload specific tasks, such as sentiment analysis, to a remote GPU while keeping the rest of your code running locally. By selectively using remote resources, you can optimize both performance and cost.
This hybrid approach is perfect for tasks like sentiment analysis via llm where some parts of the code require more computational resources than others. For a detailed explanation and step-by-step guide on using Cell Kernels, check out our blog post on this specific example.
Mistral 7B is a large language model (LLM) that contains 7.3 billion parameters and is one of the most powerful models for its size. However, this base model is not instruction-tuned, meaning it may struggle to follow instructions and perform specific tasks.
By fine-tuning Mistral 7B on the Alpaca dataset using torchtune, the model will significantly improve its capabilities to perform tasks such as conversation and answering questions accurately. Due to the computational demands of fine-tuning a model, a GPU is required.

llama.cpp library is used for efficient inference with support for GPU.
LangChain is used.
Datalayer supports the remote execution of code using the CLI. Refer to this page for more information.
CLI Remote Execution

Sharing State between Notebook and CLI

When using the same Kernel, variables defined in a notebook can be used in the CLI and vice versa. This holds also true when using multiple notebooks connected to the same kernel, for example.
Datalayer offers the possibility to use cell-specific Runtime, allowing you to execute specific cells with different kernels.
This feature optimizes costs by enabling you to, for example, leverage the local CPU for data preparation and reserving the powerful (and often more expensive) GPU resources for intensive computations.