MNIST data는 60,000개의 train data와 10,000개의 test data가 있다. KNN알고리즘 중에, weighted majority vote를 통해 10,000개 중에 100~1000개를 랜덤으로 추출한 test data를 classification한다. 그 다음, 계산한 값(label)과 실제 value값(label)이 같은지 비교해서 정확도를 측정한다.
하드웨어 및 OS : PyCharm 2021.1 x64 (Python 3.7)
먼저, test data와 가까이에 있는 train data K개를 뽑는다. test data와 train data들의 거리가 label를 판별하는 데 영향을 미치도록 가중치 값을 설정한다. K개 train data의 거리가 가까울수록 더 큰 영향을 미치는 가중치 값을 index(0~9)별로 합해준다. 가중치 합이 가장 많은 index가 그 test data의 label로 판별한다.
MNIST data의 image(28x28)를 가공해서 (7x7)로 차수를 줄이는 과정이다. data image인 28x28을 4x4의 크기로 분할해서 각 배열의 합을 구한 다음, 7x7인 배열을 생성해서 그 합을 넣는다. 글로는 설명하기 힘들어서 그림으로 예시를 들겠다.
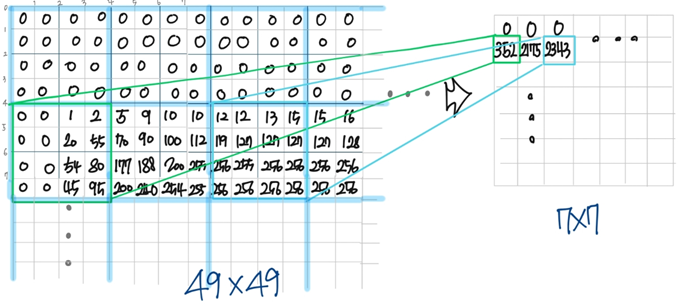
-
train data : x_train ( MNIST train data의 image(28x28) 60,000개가 들어있는 배열 ), t_train ( MNIST train data의 label 값(숫자 0~9) 60,000개가 들어있는 배열)
-
test data : x_test ( MNIST test data의 image(28x28) 10,000개가 들어있는 배열 ), t_test ( MNIST test data의 label 값(숫자 0~9) 10,000개가 들어있는 배열)
-
K의 값 : K, Knum (K의 값) ( 3, 5 ,10 중 하나)
-
추출할 test data의 개수 : N, Num (100~1000 중 하나)
-
추출할 test data의 index : rand_idx (10000개의 index중에 N개를 랜덤으로 추출한 배열)
- w_cnt : KNN 알고리즘의 weighted majority vote에서, test data와 가까운 K개의 train data의 가중치를 (0부터 9까지의 index_MNIST label)에 저장해두는 배열
“ 아래의 3개는 for문을 통해 출력 ”
- N개의 test data index : rand_idx[i]
- N개의 계산된 test data value : w_cnt.index(max(w_cnt))
- N개의 test data의 실제 값 : t_test[i]
-
0_acc : KNN 알고리즘을 통해 classification 된 test data의 정확도
-
H_acc : KNN 알고리즘을 통해 classification 된 hand-crafted 한 test data의 정확도
-
O_time : test data를 KNN알고리즘을 통해 classification 하는 시간
-
H_time : hand-crafted 한 test data를 KNN알고리즘을 통해 classification 하는 시간
test data는 N개 train data는 60000개의 image를 모두 handcraft할 때까지 밑에 있는 그림의 과정을 반복

소스코드를 실행하면 출력되는 결과들을 표로 도식화했다.
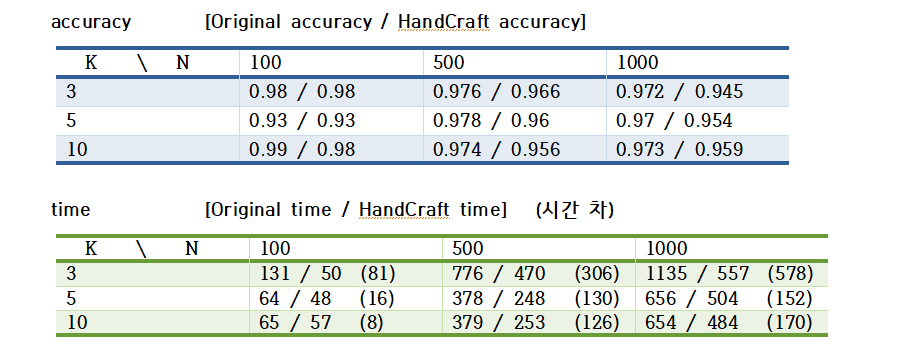
time 표를 보면 시간은 hand crafted한 test data가 원래 test data보다 시간이 더 적게 걸리고 N개를 더 크게 할수록 그 시간 차이가 더 커진다. 추가로, K가 커질수록 시간도 줄어드는 경향이 있다는 것을 확인할 수 있다. accuary 표를 참고하면, 정확도는 hand crafted한 test data가 원래 test data보다 더 1~3퍼센트 떨어지거나 같고, N개를 더 크게 해도 똑같이 1~3퍼센트 차이가 난다. 그리고, 모두 90%이상의 정확도를 갖고 있다.
따라서, test data가 클수록, 원래 test data를 처리하는데 걸리는 시간과 hand crafted test data를 처리하는 시간의 차이(hand crafted data가 더 작게)가 더 크게 나는 반면에, 정확도는 차이가 벌어지지는 않고, 일정한 퍼센트(간격)만큼 떨어진다고 볼 수 있다.
그러므로, classification 할 때에는 data 모두를 쓰는 것 보다는 data의 특징을 잘 파악해서 data를 hand craft하면, 처리하는 data의 개수도 줄일 수 있고 훨씬 더 효율적이고 빠르게 분류할 수 있다는 것을 알 수 있다.