This CLI tool visualizes foundation model (FM) usage in Amazon Bedrock. It calculates the tokens-per-minute/TPM and requests-per-minute/RPM. It also aggregates the FM usage across Bedrock application inference profiles and provides visibility on current usage gap towards the service quotas.
While Amazon CloudWatch already provides metrics for the FMs used in Bedrock, it might not be straightforward to calculate TPM & RPM, to aggregate token usage across application inference profiles, and see how each profile contributes to usage. Also, the quota lookup needs to be done separately via AWS service quotas. With this tool, you can specify the region and model to analyze and it will fetch the usage across last 1 hour, 1 day, 7 days, 14 days, and 30 days, each with aggregated data across the application inference profiles. It will generate HTML report containing the statistics table and time series data.
This CLI tool can help answers:
- What is the usage TPM and RPM of this FM?
- What is the total TPM across all of Bedrock application inference profiles for that model?
- What project/application tags contribute the most to my usage of that model? (provided that you tag the application inference profile appropriately)
- When did the throttling occur for this model and which project/application contributed the most for that?
- How far is my current TPM against the quota?
This tool works by calling AWS APIs from your local machine, including CloudWatch Get Metric Data and Bedrock List Inference Profiles. It then generates a JSON and HTML output file per model/system inference profile being analyzed inside results folder. The tool uses bundled metadata files to obtain the list of available regions and FMs and to map each FM into the AWS service quotas L code (L-xxx).
You can refresh the available regions, the available foundation models, and the service quotas mapping for the FMs using the bedrock-usage-analyzer refresh commands (or bua refresh for short). The FM to service quotas mapping is done intelligently with the help of foundation model called through Bedrock.
The tool generates HTML report showing token usage over time with quota limits. Please find the example screenshots in the following.
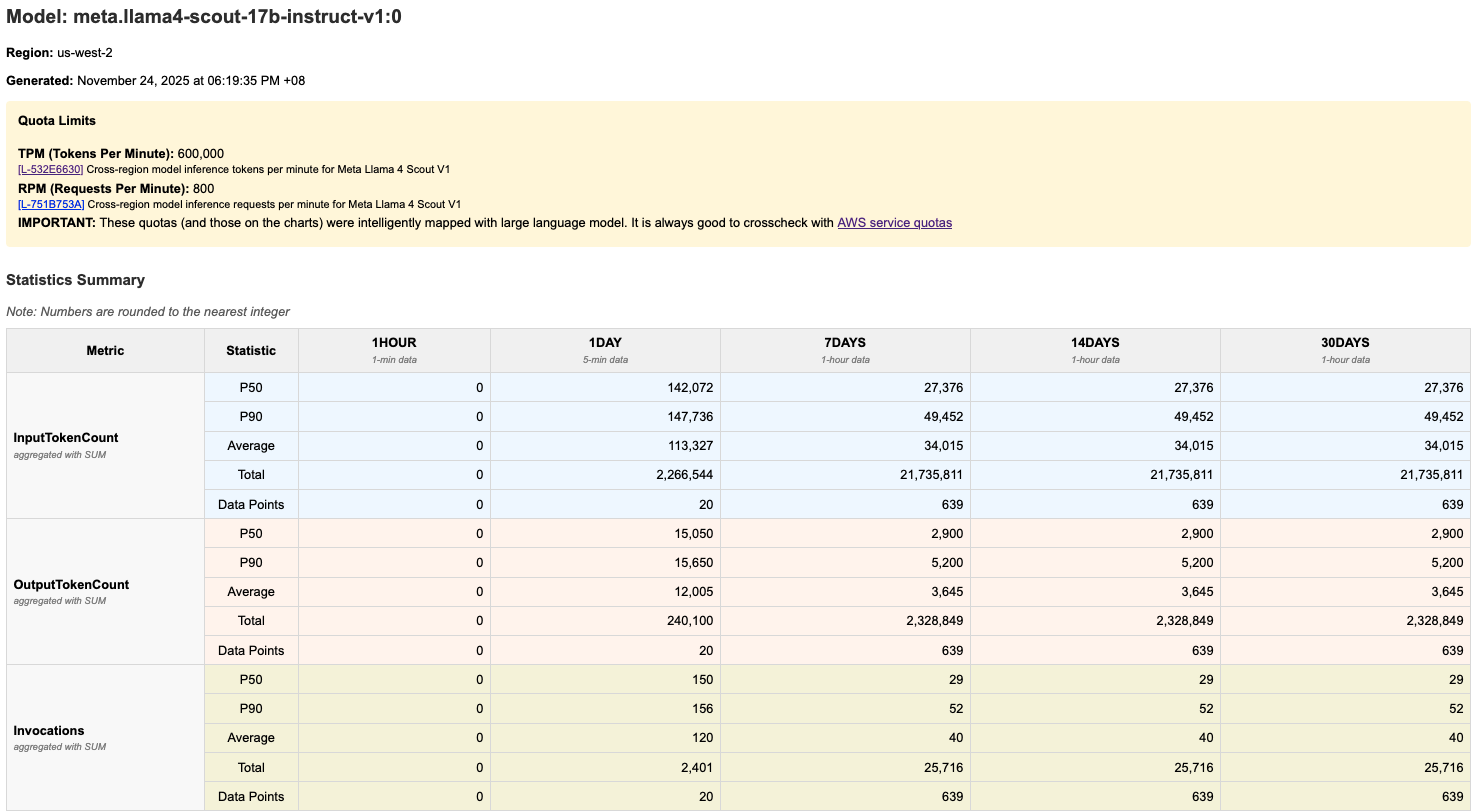
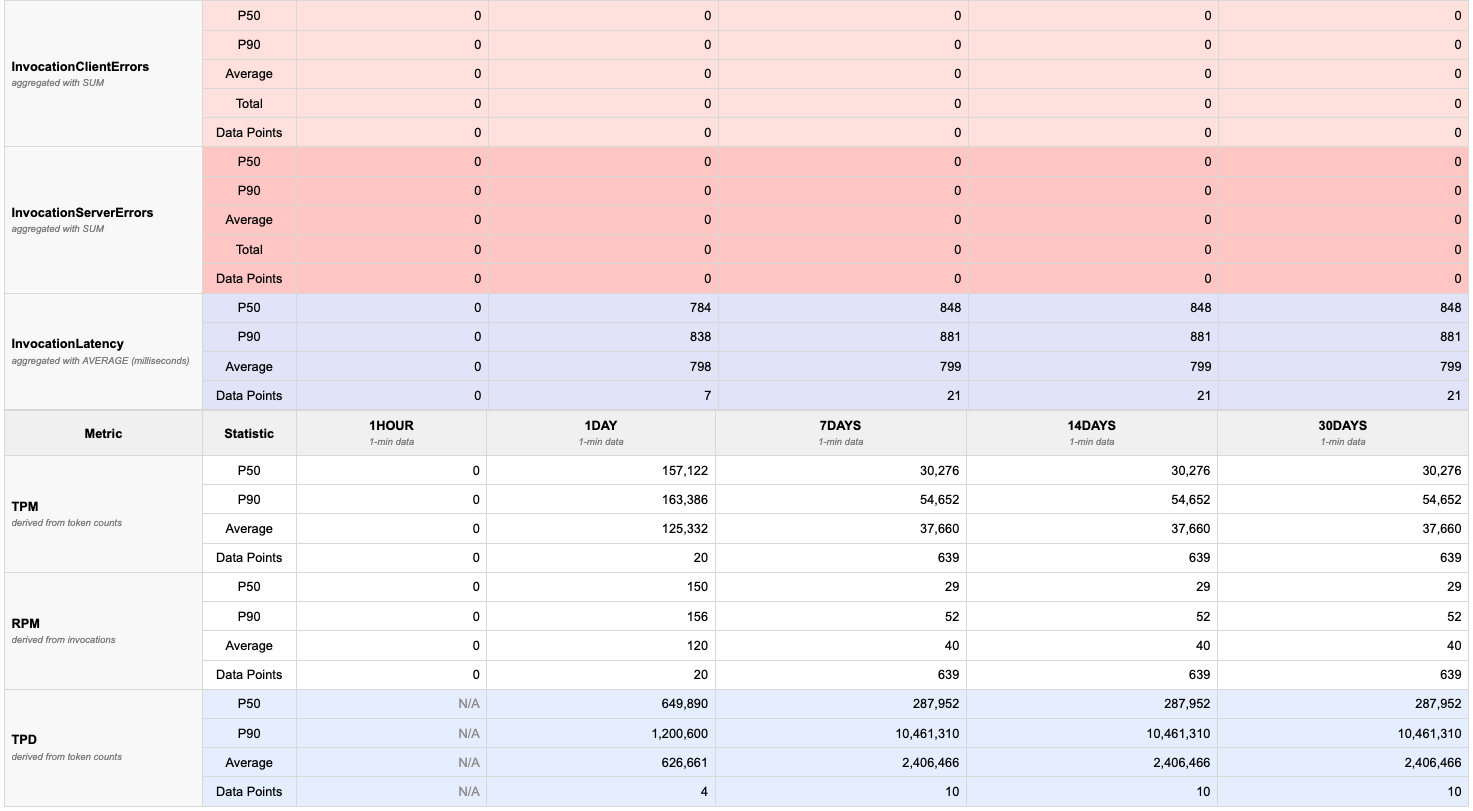
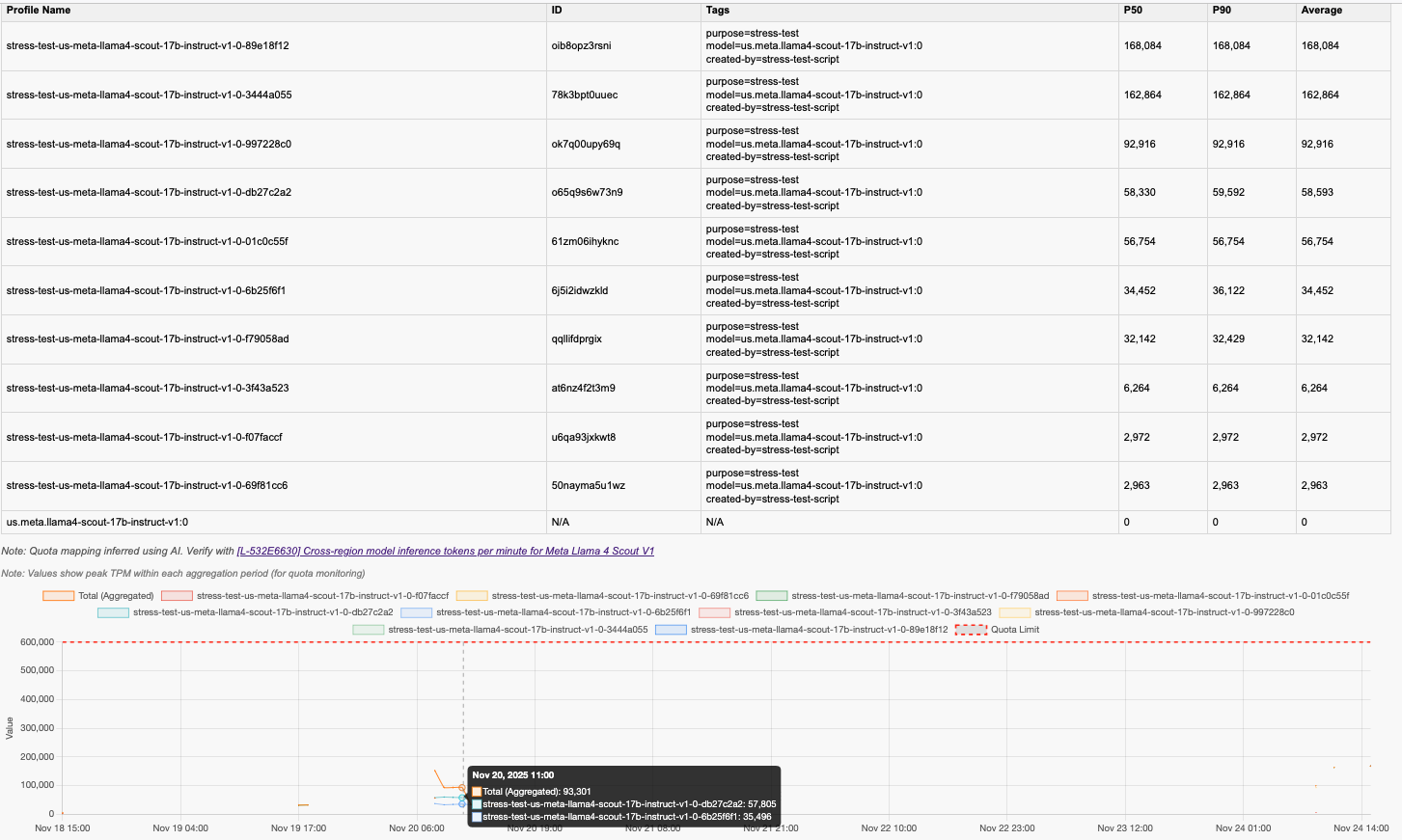
The report includes:
- Quota visualization: Red dashed lines showing TPM/RPM/TPD quotas
- Time series charts: Graphs for each time period that displays usage across application inference profiles for that model
- Percentile statistics: p50, p90, and average values in tables
- Multiple metrics: TPM, RPM, TPD (tokens-per-day), invocations, invocation throttles, input token count, output token count, and invocation latency.
- Python >= 3.9 with venv
- AWS CLI configured with appropriate credentials
- GIT to clone this repository (only needed for development install)
- Bedrock Access: Enabled foundation models in your AWS account
- IAM Permissions: See detailed permission requirements below
- Endpoint Access: For accessing APIs from Amazon CloudWatch and Amazon Bedrock, either via the internet or via-VPC access.
This tool requires different IAM permissions depending on which features you use:
Use this if: You only run bedrock-usage-analyzer analyze (or ./bin/analyze-bedrock-usage) to analyze token usage.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "BedrockUsageAnalysis",
"Effect": "Allow",
"Action": [
"sts:GetCallerIdentity",
"bedrock:ListInferenceProfiles",
"bedrock:ListTagsForResource",
"cloudwatch:GetMetricData",
"servicequotas:GetServiceQuota"
],
"Resource": "*"
}
]
}What this allows:
sts:GetCallerIdentity- Get your AWS account IDbedrock:ListInferenceProfiles- Discover inference profiles for selected modelsbedrock:ListTagsForResource- Retrieve tags for inference profiles (for metadata display)cloudwatch:GetMetricData- Fetch CloudWatch metrics for token usage (TPM, RPM, TPD, throttles)servicequotas:GetServiceQuota- Retrieve service quota limits for visualization
Note: This option uses the bundled metadata files that come with the package.
Use this if: You run metadata refresh commands (bedrock-usage-analyzer refresh *) or test data generators. This includes all permissions from Option 1 plus additional permissions:
Note: You need to replace some part with your own account ID and the region used.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "BedrockUsageAnalysis",
"Effect": "Allow",
"Action": [
"sts:GetCallerIdentity",
"bedrock:ListInferenceProfiles",
"bedrock:ListTagsForResource",
"cloudwatch:GetMetricData",
"servicequotas:GetServiceQuota"
],
"Resource": "*"
},
{
"Sid": "MetadataManagement",
"Effect": "Allow",
"Action": [
"account:ListRegions",
"bedrock:ListFoundationModels",
"servicequotas:ListServiceQuotas"
],
"Resource": "*"
},
{
"Sid": "QuotaMappingWithLLM",
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel"
],
"Resource": [
"arn:aws:bedrock:::foundation-model/anthropic.claude-*",
"arn:aws:bedrock:YOUR_REGION_FOR_LLM_CALL::foundation-model/anthropic.claude-*",
"arn:aws:bedrock:YOUR_REGION_FOR_LLM_CALL:YOUR_CURRENT_ACCOUNT_ID:inference-profile/*",
"arn:aws:bedrock:YOUR_REGION_FOR_LLM_CALL:YOUR_CURRENT_ACCOUNT_ID:application-inference-profile/*"
]
}
]
}Additional permissions explained:
account:ListRegions- List enabled AWS regions (forbedrock-usage-analyzer refresh regions)bedrock:ListFoundationModels- List all foundation models (forbedrock-usage-analyzer refresh fm-list)servicequotas:ListServiceQuotas- List all Bedrock quotas (forbedrock-usage-analyzer refresh fm-quotasandbedrock-usage-analyzer refresh quota-index)bedrock:InvokeModel- Invoke Claude models for intelligent quota mapping (forbedrock-usage-analyzer refresh fm-quotasonly, restricted to Claude models)
- Principle of Least Privilege: Use Option 1 if you don't need to refresh metadata
- Resource Restrictions: The
bedrock:InvokeModelpermission is limited to Claude models only that is used in quota mapping - No Write Permissions: All permissions are read-only except for model invocation
- Region Scoping: Consider adding
Conditionblocks to restrict to specific regions if needed
You can install it in three ways:
pip install bedrock-usage-analyzer
# Run the analyzer
bedrock-usage-analyzer analyze
# Or use the short alias
bua analyze# Clone the repository
git clone https://github.com/awslabs/bedrock-usage-analyzer.git
cd bedrock-usage-analyzer
# Install in editable mode
pip install -e .
# Run using the CLI
bedrock-usage-analyzer analyze# Clone the repository
git clone https://github.com/awslabs/bedrock-usage-analyzer.git
cd bedrock-usage-analyzer
# The bin scripts will automatically create venv and install
./bin/analyze-bedrock-usage
# Windows (without bash): Run Python module directly
python -m bedrock_usage_analyzer analyzeEnsure your AWS CLI is configured with credentials that have the required permissions to the right AWS account. Please refer to this documentation. Then performt he following command to verify.
# Verify your AWS identity
aws sts get-caller-identityBefore analyzing usage, you may want to refresh the foundation model lists:
# Refresh regions list
bedrock-usage-analyzer refresh regions
# Or: ./bin/refresh-regions
# Refresh foundation models for all regions
bedrock-usage-analyzer refresh fm-list
# Or: ./bin/refresh-fm-list
# Or refresh for a specific region
bedrock-usage-analyzer refresh fm-list us-west-2
# Or: ./bin/refresh-fm-list us-west-2This step is optional because this repository comes with preloaded metadata that contains these information. However, you might want to refresh those metadata since new regions, new foundation models, or new quotas for the FMs might have come since this repository was refreshed.
# Launch the interactive usage analyzer
bedrock-usage-analyzer analyze
# Or: ./bin/analyze-bedrock-usageThe script will prompt you to:
- Select AWS region - Choose the region where you have Bedrock usage
- Select granularity - Choose the time granularity to aggregate usage across (e.g. 1 min, 5 mins, 1 hour)
- Select model provider - Filter by provider (Amazon, Anthropic, etc.)
- Select model - Choose the specific model to analyze
- Select inference profile (if applicable) - Choose base model or cross-region profile
For automation, CI/CD pipelines, or scheduled runs, you can pass arguments directly to skip interactive prompts:
# Fully non-interactive (all arguments specified)
bedrock-usage-analyzer analyze \
--region us-west-2 \
--model-id amazon.nova-premier-v1:0 \
--granularity 1min \
--output-dir ./results
# With cross-region inference profile (note the 'us.' prefix)
bedrock-usage-analyzer analyze \
--region us-west-2 \
--model-id us.amazon.nova-premier-v1:0 \
--granularity 5min
# Partial arguments (prompts only for missing values)
bedrock-usage-analyzer analyze --region us-west-2 --granularity 1hour
# → prompts for model selection onlyCLI Arguments:
| Argument | Short | Description |
|---|---|---|
--region |
-r |
AWS region (e.g., us-west-2, eu-west-1) |
--model-id |
-m |
Model ID with optional prefix (e.g., amazon.nova-premier-v1:0 for base, us.amazon.nova-premier-v1:0 for cross-region) |
--granularity |
-g |
Aggregation granularity (see below) |
--output-dir |
-o |
Directory to save results |
--yes |
-y |
Skip account confirmation prompt |
Granularity Options:
You can specify granularity in two ways:
-
Single value - applies to all time periods:
# Use 1-minute granularity for all periods bedrock-usage-analyzer analyze -r us-west-2 -m amazon.nova-premier-v1:0 -g 1min # Use 5-minute granularity for all periods bedrock-usage-analyzer analyze -r us-west-2 -m amazon.nova-premier-v1:0 -g 5min # Use 1-hour granularity for all periods bedrock-usage-analyzer analyze -r us-west-2 -m amazon.nova-premier-v1:0 -g 1hour
-
JSON format - different granularity per time period:
# Fine granularity for recent data, coarser for older data bedrock-usage-analyzer analyze \ -r us-west-2 \ -m amazon.nova-premier-v1:0 \ -g '{"1hour":"1min","1day":"5min","7days":"1hour","14days":"1hour","30days":"1hour"}'
When using JSON format, you must specify all five time periods:
1hour,1day,7days,14days,30days. Valid values for each are:1min,5min,1hour.
Multi-Account Usage with AWS_PROFILE:
To analyze usage in different AWS accounts, use the AWS_PROFILE environment variable:
# Fully programmatic example (no prompts, no confirmations)
AWS_PROFILE=my-profile-name bua analyze -r us-west-2 -m us.meta.llama4-scout-17b-instruct-v1:0 -g 1min -y -o .
# Use a specific AWS profile
AWS_PROFILE=production bedrock-usage-analyzer analyze \
-r us-west-2 \
-m amazon.nova-premier-v1:0 \
-g 1min \
-y
# Or export for multiple commands
export AWS_PROFILE=production
bedrock-usage-analyzer analyze -r us-west-2 -m amazon.nova-premier-v1:0 -g 1min
bedrock-usage-analyzer analyze -r us-east-1 -m amazon.nova-premier-v1:0 -g 1min
# Switch to another account
AWS_PROFILE=development bedrock-usage-analyzer analyze \
-r us-west-2 \
-m amazon.nova-premier-v1:0 \
-g 1minEnsure your ~/.aws/credentials file has the profiles configured:
[production]
aws_access_key_id = AKIA...
aws_secret_access_key = ...
[development]
aws_access_key_id = AKIA...
aws_secret_access_key = ...Or use SSO profiles in ~/.aws/config:
[profile production]
sso_start_url = https://my-sso.awsapps.com/start
sso_region = us-east-1
sso_account_id = 123456789012
sso_role_name = PowerUserAccess
region = us-west-2After analysis completes, find your results in the results/ directory:
# List generated reports
ls -lh results/
# Open HTML report in browser (macOS)
open results/<model-name>-<timestamp>.html
# Open HTML report in browser (Linux)
xdg-open results/<model-name>-<timestamp>.html
# View JSON data
cat results/<model-name>-<timestamp>.json | jqThe HTML report contains several sections:
1. Quota Limits Section (if available)
- Shows TPM, RPM, and TPD quota limits for your model (if applicable)
- Displayed at the top for quick reference
2. Statistics Table
- One colum per time period (1hour, 1day, 7days, 14days, 30days)
- Columns: Metric Type, p50, p90, Average, Total, Data Points
- Metrics: TPM, RPM, TPD, InvocationThrottles, Invocations, InvocationServerErrors, InvocationClientErrors, InvocationLatency, InputTokenCount, and OutputTokenCount
3. Charts
- Time series graphs for each metric and time period
- Red dashed lines: Quota limits (when available)
- Colored lines: Model usage over time
- Hover over points to see exact values
- The chart can have multiple lines showing the aggregated (total) usage for that metric and the individual application inference profile usage
Token Usage Patterns:
- p50 (median): Typical usage - 50% of time periods are below this
- p90: High usage - only 10% of time periods exceed this
- Average: Mean value across all data points
- Total: Sum of all values in the period
Quota Comparison:
- If lines approach or cross red dashed quota lines, you may hit limits
- Consistent p90 near quota suggests you need a quota increase
- Large gap between p50 and quota indicates headroom
- IMPORTANT: Please cross-check the quota with ones from AWS service quotas manually, since the large language model-mapped quotas might not be always accurate.
Throttles:
- Any non-zero throttle count indicates you've hit rate limits
- Check which time periods show throttles to identify peak usage times
The tool can automatically map AWS Service Quotas to foundation models:
# Run the quota mapping tool
bedrock-usage-analyzer refresh fm-quotas
# Or: ./bin/refresh-fm-quotas-mappingHow it works:
- Uses Bedrock foundation model to extract base model family names (e.g., "nova-lite" → "nova")
- Matches quota names containing model family + endpoint type
- Recognizes "on-demand", "cross-region", and "global" quota patterns
- Only makes 2-3 inference calls per model profile (on-demand, cross-region, global)
- Caches results to avoid redundant API calls
You can then validate the mapped quota. To make the validation easier, you can run the following command to create a .csv file where each row constitutes the model, endpoint, and metric combination.
# Generate quota index CSV
bedrock-usage-analyzer refresh quota-index
# Or: ./bin/refresh-quota-indexThe CSV file will be saved in your user data directory (see Metadata Storage). You can then validate the mapping for each row, either manually or with your AI assistant.
The analyzer supports various customization options through the interactive prompts:
Model Selection:
- Filter by provider to narrow down choices
- Select specific model variants
- Choose inference profiles (base, us, eu, jp, au, apac, global)
Time Periods:
- 1hour: Recent short-term patterns
- 1day: Daily patterns
- 7days: Weekly trends
- 14days: Bi-weekly patterns
- 30days: Monthly trends
# Main analysis
bedrock-usage-analyzer analyze
# Refresh metadata
bedrock-usage-analyzer refresh regions # Refresh AWS regions list
bedrock-usage-analyzer refresh fm-list # Refresh FM lists for all regions
bedrock-usage-analyzer refresh fm-list us-west-2 # Refresh FM list for specific region
bedrock-usage-analyzer refresh fm-quotas # Refresh quota mappings (interactive)
bedrock-usage-analyzer refresh quota-index # Generate quota index CSV
# For maintainers: also update bundled metadata
bedrock-usage-analyzer refresh regions --update-bundle
bedrock-usage-analyzer refresh fm-list --update-bundleShort alias: You can use bua instead of bedrock-usage-analyzer for all commands above.
./bin/analyze-bedrock-usage
- Main script for analyzing token usage
- Interactive prompts for region, provider, model selection
- Generates JSON and HTML reports in
results/directory
./bin/refresh-regions
- Fetches enabled AWS regions for your account
- Run when you enable new regions
./bin/refresh-fm-list [region]
- Fetches foundation models and inference profiles
- Run without argument to refresh all regions
- Run with region argument to refresh specific region
- Preserves existing quota mappings
./bin/refresh-fm-quotas-mapping
- Intelligently maps service quotas to foundation models
- Arguments:
[target_region] [bedrock_region] [model_id]- all optional - Examples:
# Interactive mode - prompts for all parameters ./bin/refresh-fm-quotas-mapping # Skip region selection - only process us-east-1 ./bin/refresh-fm-quotas-mapping us-east-1 # Skip all prompts - process us-east-1 using us-west-2 for API calls ./bin/refresh-fm-quotas-mapping us-east-1 us-west-2 us.anthropic.claude-haiku-4-5-20251001-v1:0
./bin/refresh-quota-index
- Generates CSV index of all quota mappings for validation
The tool uses metadata files (regions, FM lists, quota mappings) from these locations:
| OS | Path |
|---|---|
| Linux | ~/.local/share/bedrock-usage-analyzer/ |
| macOS | ~/Library/Application Support/bedrock-usage-analyzer/ |
| Windows | %LOCALAPPDATA%\bedrock-usage-analyzer\ |
Set the BEDROCK_ANALYZER_DATA_DIR environment variable:
export BEDROCK_ANALYZER_DATA_DIR=/path/to/custom/locationDelete the user data directory to revert to bundled defaults:
# Linux
rm -rf ~/.local/share/bedrock-usage-analyzer/
# macOS
rm -rf ~/Library/Application\ Support/bedrock-usage-analyzer/Q: "No metrics found" error A: This means CloudWatch has no data for the selected model. Verify:
- The model has been used in the selected region
- You're checking the correct time period
- CloudWatch metrics are enabled for Bedrock
Q: Quota limits not showing in report A: Quotas are only shown if they've been mapped. You can:
- Manually edit quota mappings in the user data directory, or
- Re-run
bedrock-usage-analyzer refresh fm-quotas.
If the quota limits are still not shown, it could be that the FM is not yet listed. You can run bedrock-usage-analyzer refresh fm-list before bedrock-usage-analyzer refresh fm-quotas.
Q: "Model not found" error A: Refresh your foundation model lists:
bedrock-usage-analyzer refresh fm-listQ: Quota mapping fails with "ValidationException" A: Ensure:
- The selected Bedrock region supports the chosen model
- You have access to the Claude model you selected
- The model ID is correct (check for typos)
Q: Some models show no quota mappings A: This can happen if:
- The model is new and quotas haven't been created yet
- The model name doesn't match quota naming patterns
- The foundation model couldn't identify matching quotas
Q: "AccessDenied" errors A: Verify your IAM permissions. See the IAM Permissions section for detailed permission requirements. Use:
- Option 1 if you only run
bedrock-usage-analyzer analyze - Option 2 if you also run
bedrock-usage-analyzer refreshcommands
Q: Analysis is very slow A: CloudWatch queries can take time for large time ranges. To speed up:
- Analyze shorter time periods
- Use specific models instead of analyzing all models
- Check your network connection to AWS
Q: How do I switch to different AWS accounts when using this tool? A: You can use different AWS profile as shown in the following code snippet:
AWS_PROFILE=<YOUR AWS PROFILE NAME> bedrock-usage-analyzer analyze
# Or: AWS_PROFILE=<YOUR AWS PROFILE NAME> ./bin/analyze-bedrock-usage- Credentials: Never commit AWS credentials to the repository
- Quota Data: Quota information is fetched from AWS and not hardcoded
- API Calls: All Bedrock API calls use your AWS credentials
- Data Storage: Analysis results are stored locally in
results/. Refreshed metadata is stored in your user data directory (see Metadata Storage)
When using bedrock-usage-analyzer analyze (or ./bin/analyze-bedrock-usage), the following cost is expected:
- CloudWatch GetMetricData that is measured on the number of metrics requested
- Refer to CloudWatch pricing page to view the unit price per region.
- The total cost of this component depends on the number of metrics being requested, that also depends on how many FMs are included in the query and how many times this tool is run
When running bedrock-usage-analyzer refresh fm-quotas (or ./bin/refresh-fm-quotas-mapping) to refresh the mapping between FM metric and the quotas, the following additional cost will apply:
- Bedrock model invocation cost that is based on the total tokens used.
- This is because this functionality invokes FM in Bedrock to intelligently perform the mapping.
- Refer to Bedrock pricing page
- The cost will depend on the FM chosen to perform the intelligent mapping, as well as the number of available FMs and quotas to map. One can run this functionality against only 1 region to save cost, instead of refreshing FM mapping for all regions.