Welcome to the Reinventing Multi-Modal Search with Anyscale and MongoDB repository! This project demonstrates a comprehensive solution for improving search capabilities in an e-commerce setting.
If you don't have an Anyscale account, you can register here.
If you already have an account, login here.
If you don't have a MongoDB account, follow the instructions here to sign up for a free MongoDB Atlas account.
If you don't have a MongoDB cluster created, follow the instructions here to create a free MongoDB Atlas cluster.
Use the 0.0.0.0/0 network access list to allow public access to your cluster. To do so follow the instructions here.
Get the connection string for your MongoDB cluster by following the instructions here.
If you don't have a Hugging Face account, you can register here.
If you already have an account, login here.
Visit the tokens page to generate a new API token.
Visit the following model pages and request access to these models:
Once you have access to these models, you can proceed with the next steps.
Once you are logged in, go to workspaces by clicking the "Workspaces" tab on the left side of the home screen:
Create a new workspace by clicking the "Create Workspace" button:
Specify Workspace details as displayed below and click "Create":
Wait for the workspace to be created:
(this can take up to one minute)
Note
Your workspace is ready!
Open the terminal in the workspace and clone the repository by running the following command:
git clone https://github.com/anyscale/mongodb-multi-modal-search-prototype.git
Go to the project directory:
cd mongodb-multi-modal-search-prototype/Set the MongoDB connection string DB_CONNECTION_STRING and huggingface access token HF_TOKEN as environment variables under the Dependencies section of the workspace
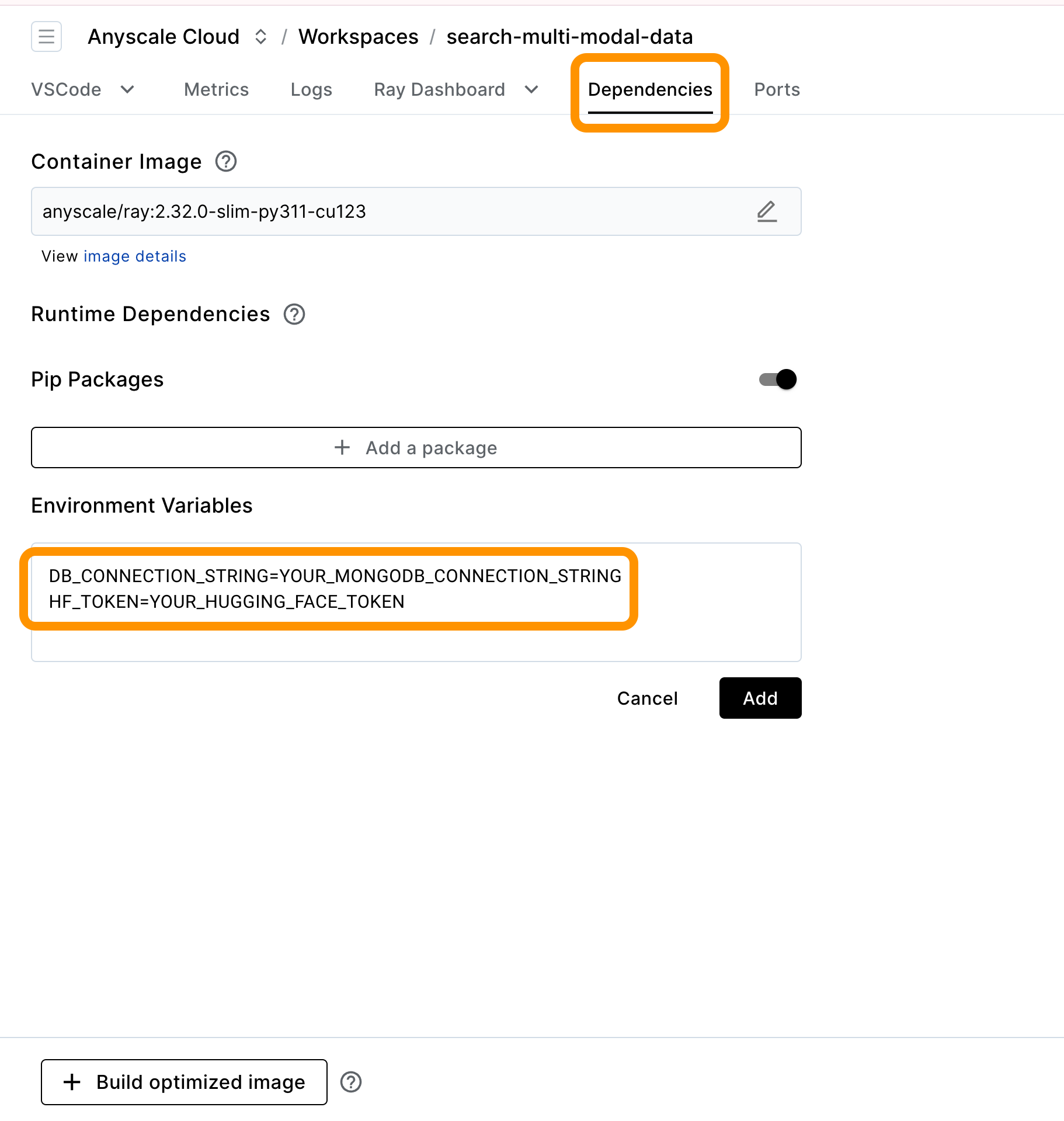
Set the proper environment variables in the data_pipelines/job.yaml file
name: enrich-data-and-upsert
entrypoint: python cli.py --data-path s3://anyscale-public-materials/mongodb-demo/raw/myntra_subset_deduped_10000.csv --nsamples 10000 --mode first_run --collection-name myntra-new
working_dir: .
requirements: requirements.txt
env_vars:
DB_CONNECTION_STRING: <your mongodb connection string> # replace with your MongoDB connection string
HF_TOKEN: <your huggingface token> # replace with your Hugging Face token
...Submit the job by running the following command in your workspace terminal:
cd data_pipelines/
anyscale job submit -f job.yamlCheck the status of the job by visiting the Anyscale Job interface
Note, if you are using a small cluster size of "m0", "m2" or "m5" you will need to manually create the search indices in MongoDB.
If instead you chose a larger cluster size, you can skip this step. The search index would have been automatically and programmatically created for you.
To do so, follow these steps
- Select your database
- Click on the "Search Indexes" tab or the "Atlas Search" tab
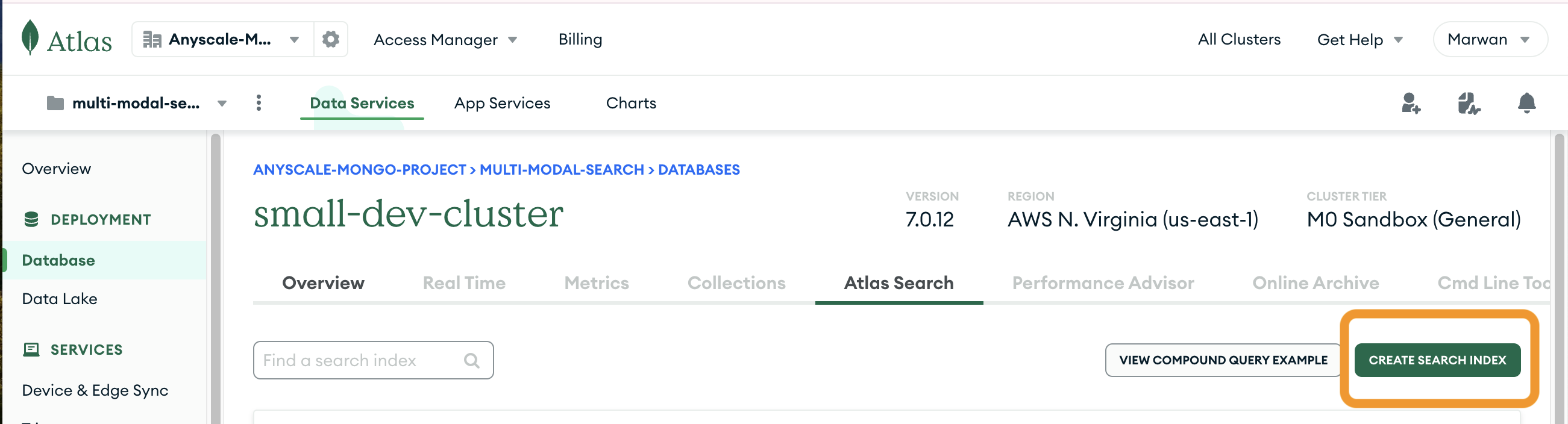
From here on, follow these steps to build the Atlas Vector Search Index
- Click on the "JSON Editor" Option
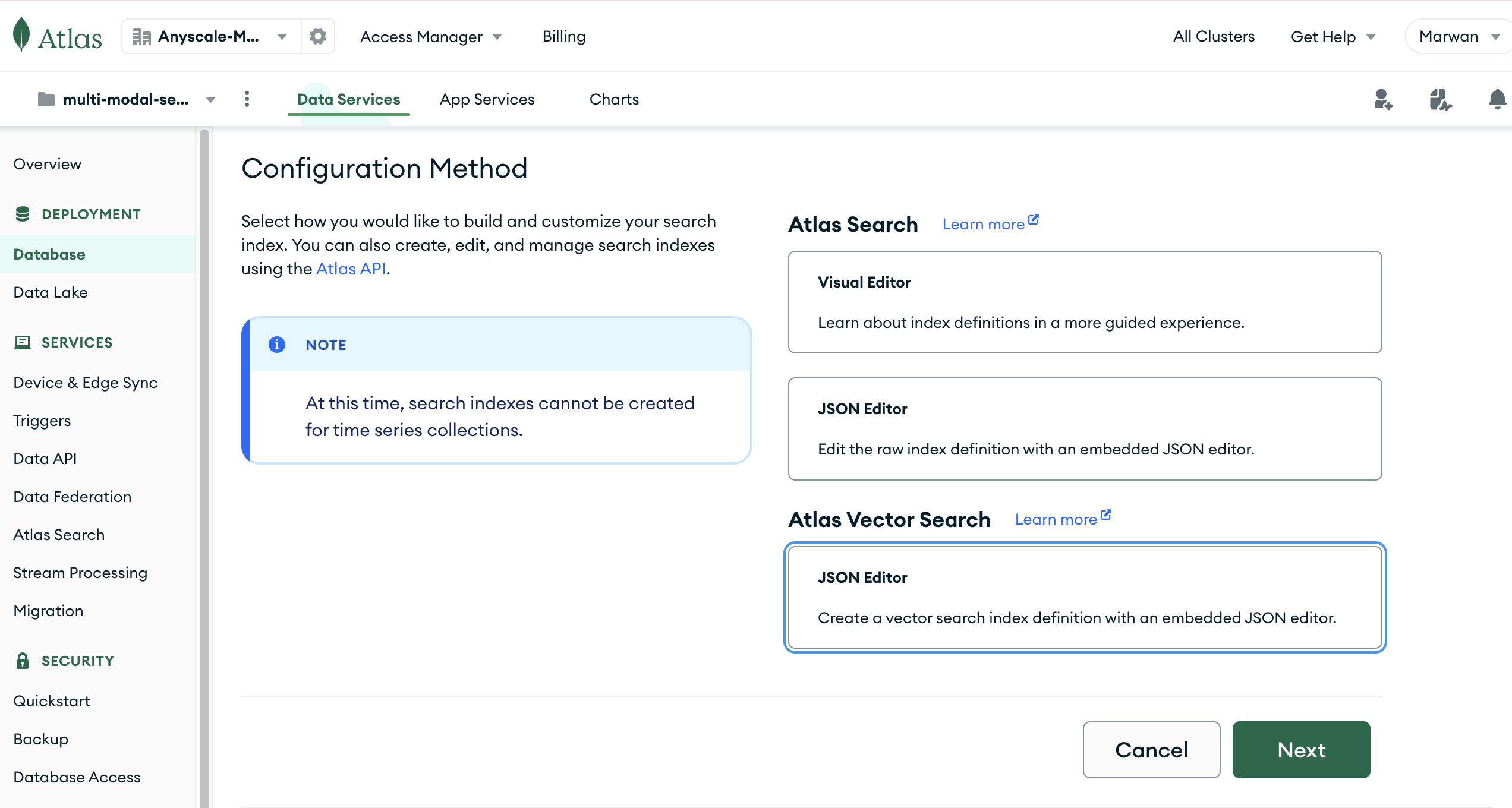
- Click Next
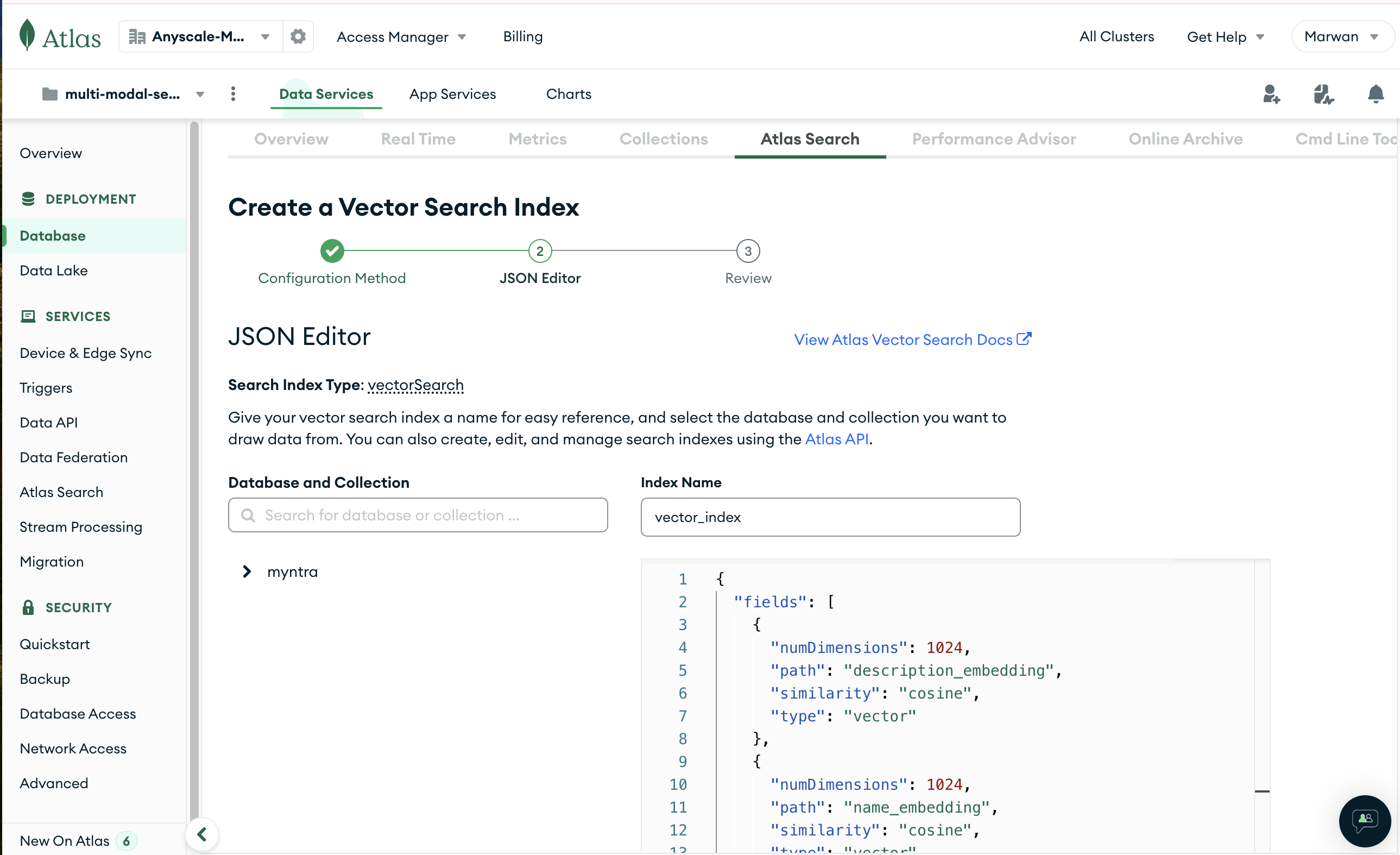
- Copy the JSON from here, select your collection in the left-hand menu and click Next
From here on, follow these steps to build the Atlas Search Index
- Click on the "JSON Editor" Option
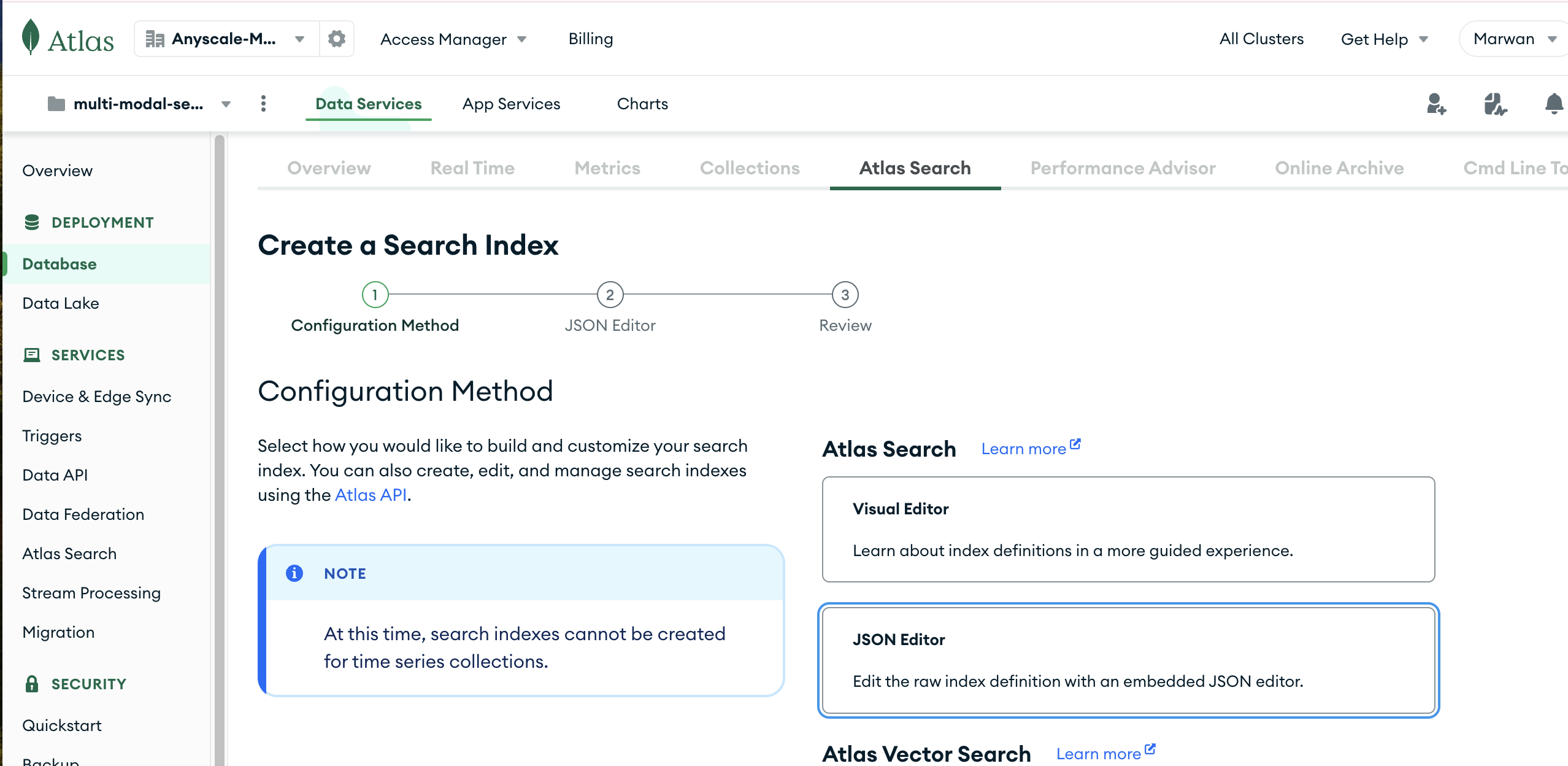
- Click Next
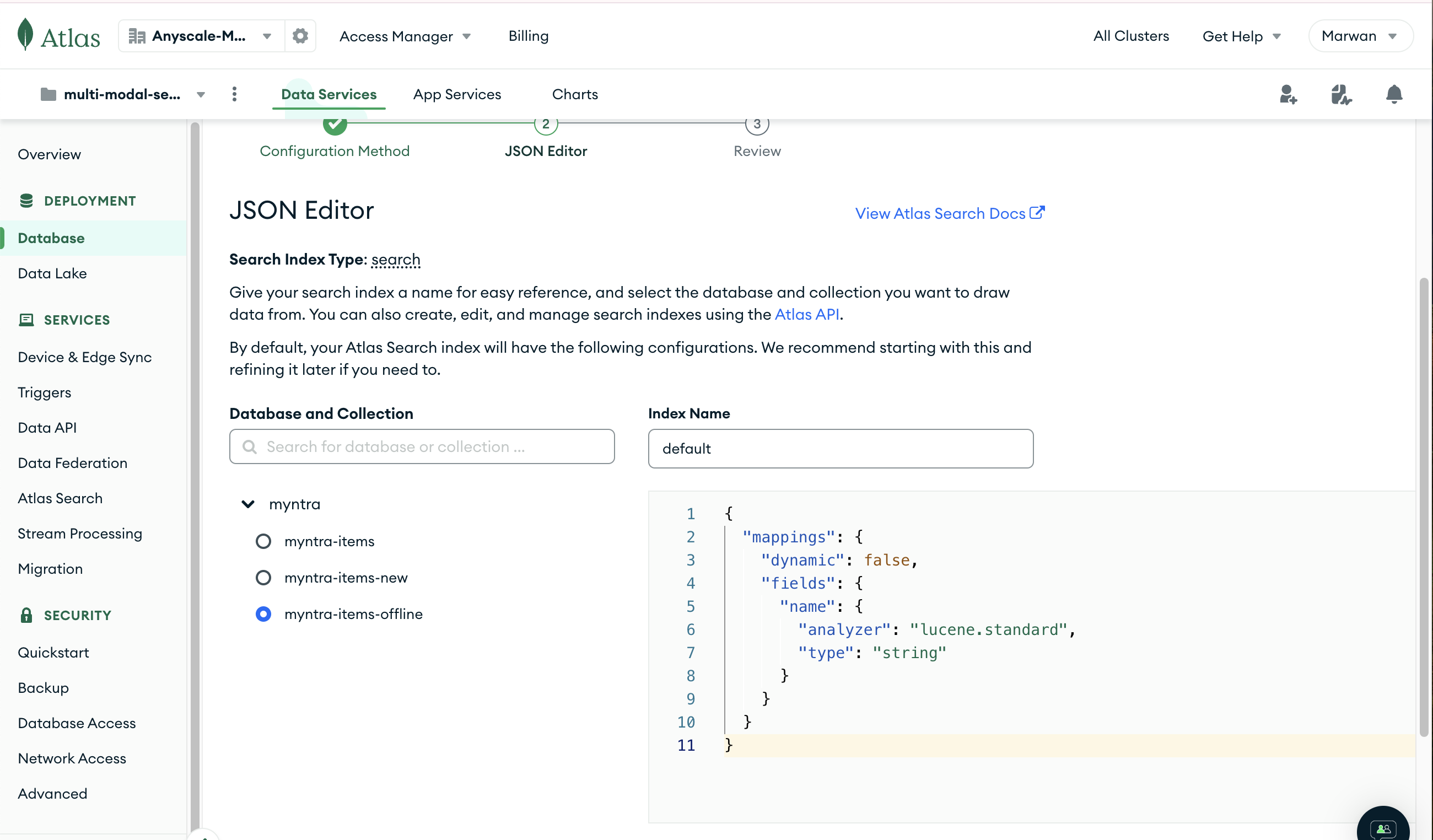
- Copy the JSON from here, select your collection in the left-hand menu, and click Next
Deploy the application by running the following command
cd applications/
anyscale service deploy -f app.yamlCheck the status of the service by visiting the service url.
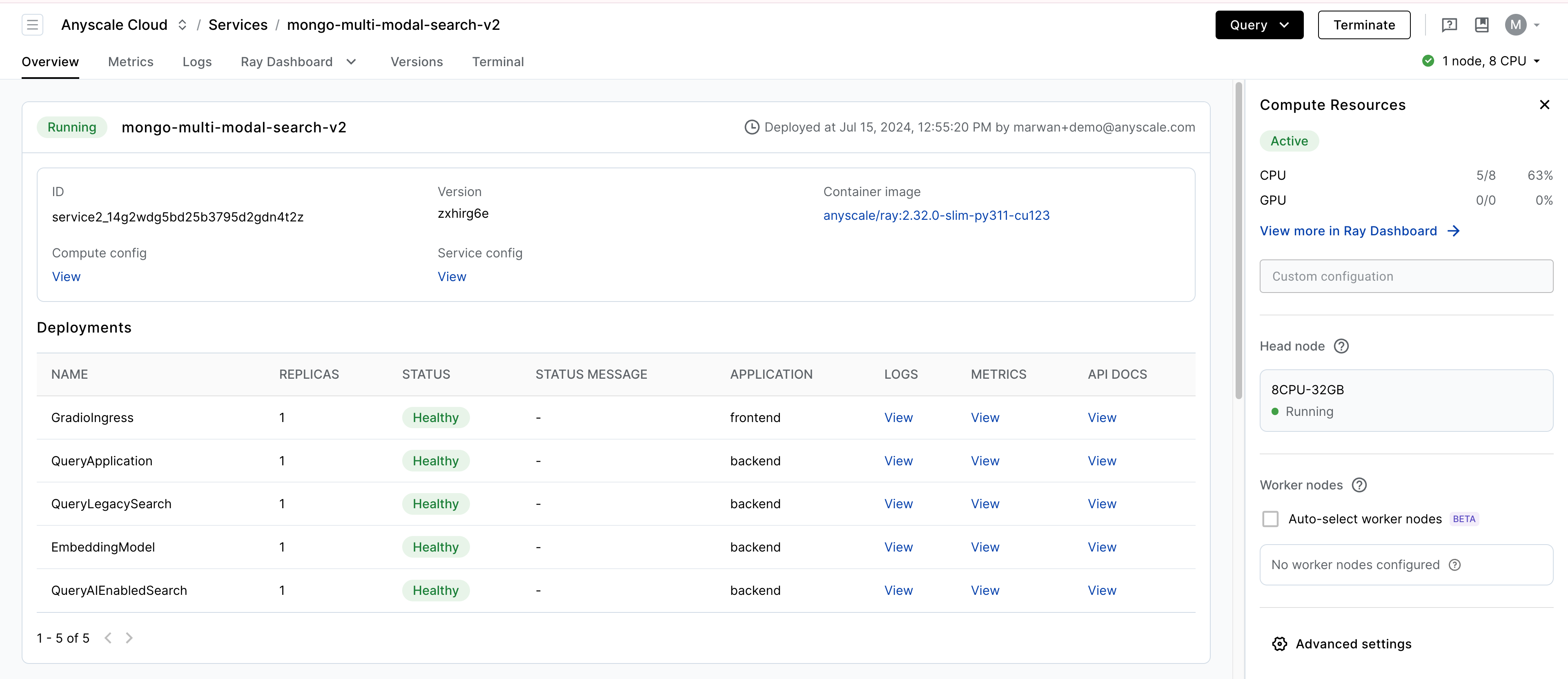
Visit the Application URL to see the application. You can find the URL under the service "Query" dropdown.
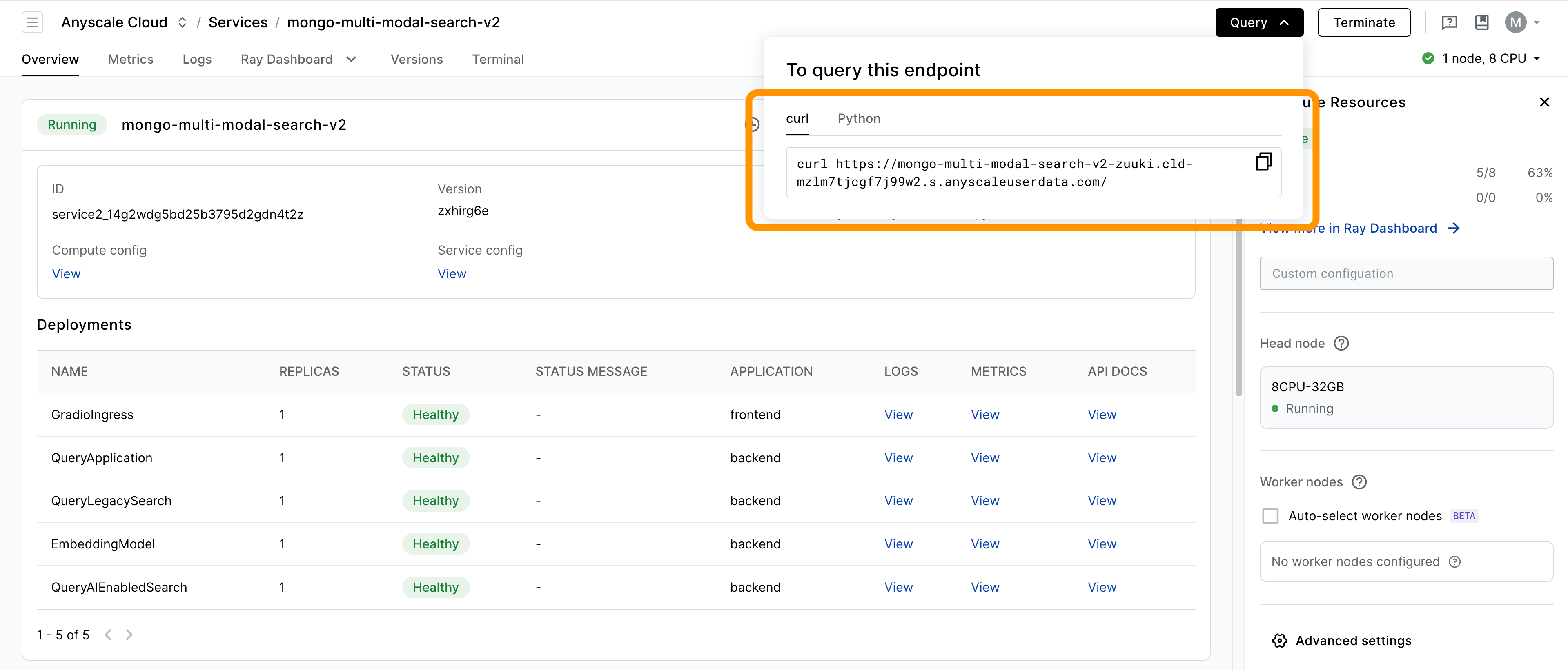
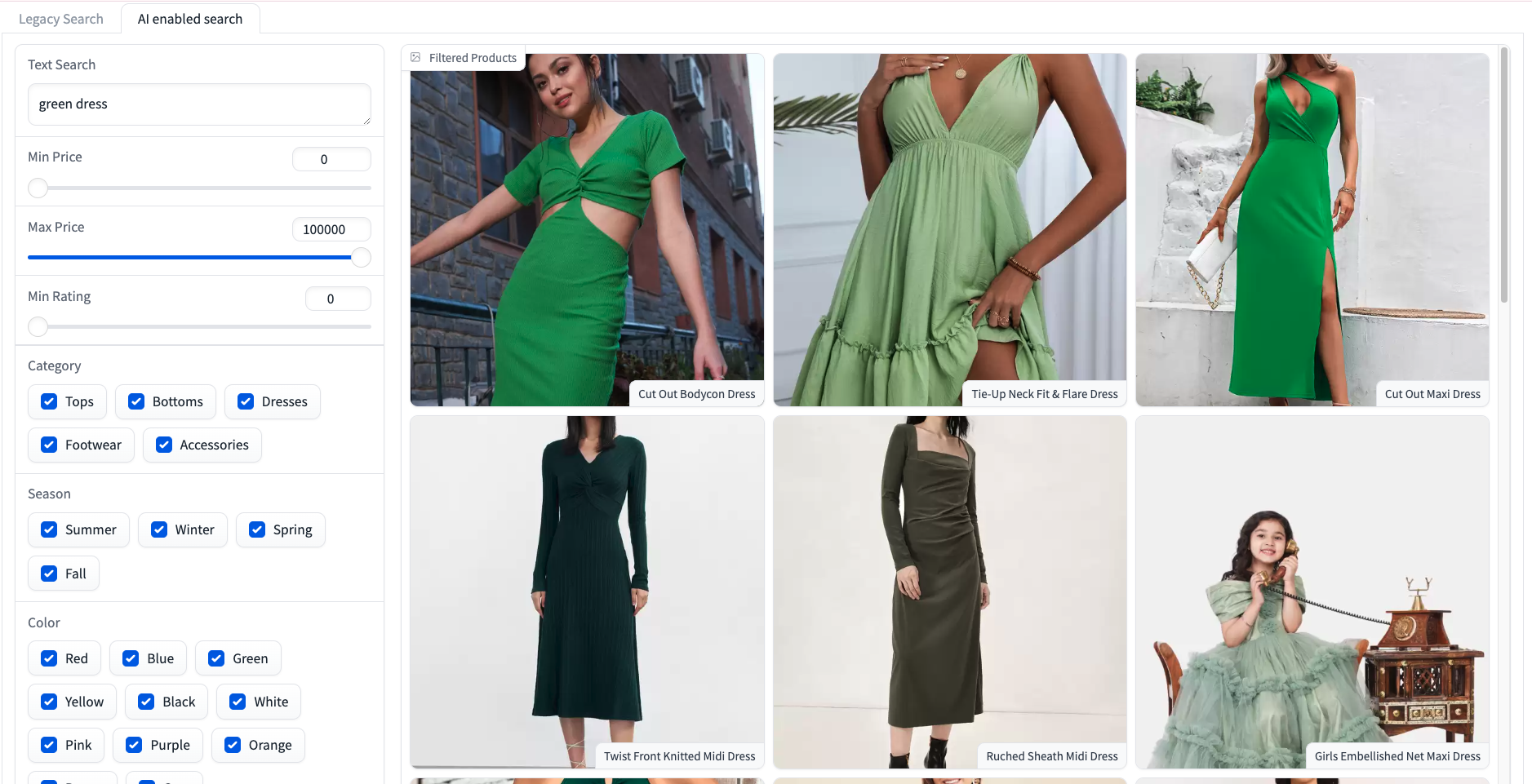
Query the application by entering a query in the search bar and clicking the search button
In case new data is available, or changes have been made to the existing data, you can run the job to update the data in MongoDB. This time however you need to make sure to set the mode parameter to update in the data_pipelines/job.yaml file.
name: enrich-data-and-upsert
entrypoint: python cli.py --data-path {path-to-updated-data} --nsamples {number-of-samples} --mode update --collection-name myntra-new # note the mode parameter
...Submit the job by running the following command in your workspace terminal:
cd data_pipelines/
anyscale job submit -f job.yamlWe split our system into an offline data indexing stage and an online search stage.
The offline data indexing stage performs the processing, embedding, and upserting text and images into a MongoDB database that supports vector search across multiple fields and dimensions. This stage is built by running multi-modal data pipelines at scale using Anyscale for AI compute platform.
The online search stage performs the necessary search operations by combining legacy text matching with advanced semantic search capabilities offered by MongoDB. This stage is built by running a multi-modal search backend on Anyscale.
The data pipelines show how to perform offline batch inference and embeddings generation at scale. The pipelines are designed to handle both text and image data by running multi-modal large language model instances.
data_pipelines/data.py: Handles data I/O operations, transferring data from the Data Lake to MongoDB.offline_compute.py: Manages offline batch inference and embeddings computation/online_compute.py: A naive implementation via a REST API for online inference and embeddings computation.
ray[data]vLLMpymongosentence-transformers
The search backend combines legacy lexical text matching with advanced semantic search capabilities, offering a robust hybrid search solution.
applications/backend.py: Implements the hybrid search backend.frontend.py: Provides a Gradio-based UI for interacting with the search backend.
ray[serve]gradiomotorsentence-transformers
Created with