![]()



Install & usage docs: https://docs.privategpt.dev/
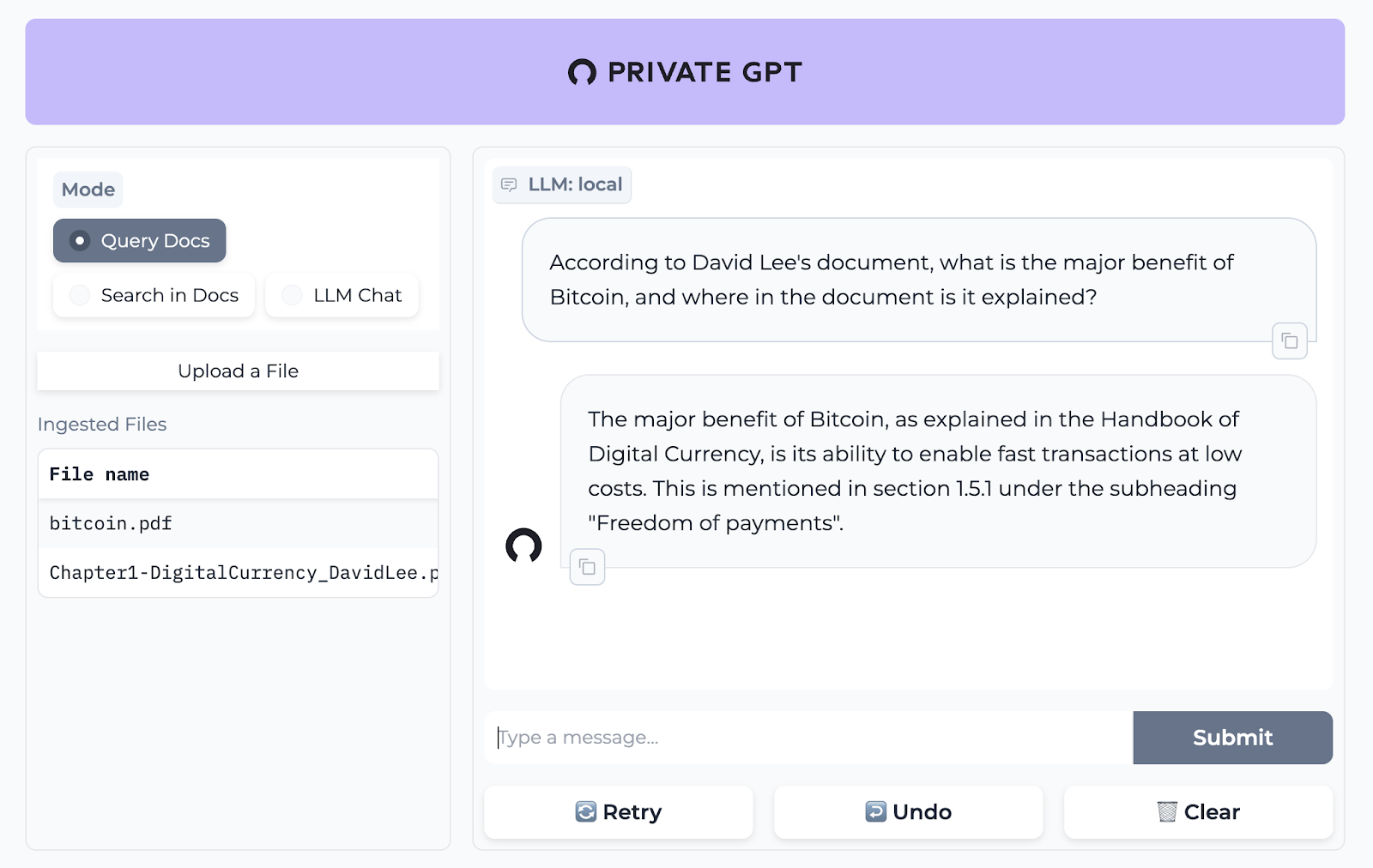
PrivateGPT is a production-ready AI project that allows you to ask questions about your documents using the power of Large Language Models (LLMs), even in scenarios without an Internet connection. 100% private, no data leaves your execution environment at any point.
The project provides an API offering all the primitives required to build private, context-aware AI applications. It follows and extends the OpenAI API standard, and supports both normal and streaming responses.
The API is divided into two logical blocks:
High-level API, which abstracts all the complexity of a RAG (Retrieval Augmented Generation) pipeline implementation:
- Ingestion of documents: internally managing document parsing, splitting, metadata extraction, embedding generation and storage.
- Chat & Completions using context from ingested documents: abstracting the retrieval of context, the prompt engineering and the response generation.
Low-level API, which allows advanced users to implement their own complex pipelines:
- Embeddings generation: based on a piece of text.
- Contextual chunks retrieval: given a query, returns the most relevant chunks of text from the ingested documents.
In addition to this, a working Gradio UI client is provided to test the API, together with a set of useful tools such as bulk model download script, ingestion script, documents folder watch, etc.
👂 Need help applying PrivateGPT to your specific use case? Let us know more about it and we'll try to help! We are refining PrivateGPT through your feedback.
DISCLAIMER: This README is not updated as frequently as the documentation. Please check it out for the latest updates!
Generative AI is a game changer for our society, but adoption in companies of all sizes and data-sensitive domains like healthcare or legal is limited by a clear concern: privacy. Not being able to ensure that your data is fully under your control when using third-party AI tools is a risk those industries cannot take.
The first version of PrivateGPT was launched in May 2023 as a novel approach to address the privacy concerns by using LLMs in a complete offline way.
That version, which rapidly became a go-to project for privacy-sensitive setups and served as the seed for thousands of local-focused generative AI projects, was the foundation of what PrivateGPT is becoming nowadays; thus a simpler and more educational implementation to understand the basic concepts required to build a fully local -and therefore, private- chatGPT-like tool.
If you want to keep experimenting with it, we have saved it in the primordial branch of the project.
It is strongly recommended to do a clean clone and install of this new version of PrivateGPT if you come from the previous, primordial version.
PrivateGPT is now evolving towards becoming a gateway to generative AI models and primitives, including completions, document ingestion, RAG pipelines and other low-level building blocks. We want to make it easier for any developer to build AI applications and experiences, as well as provide a suitable extensive architecture for the community to keep contributing.
Stay tuned to our releases to check out all the new features and changes included.
Full documentation on installation, dependencies, configuration, running the server, deployment options, ingesting local documents, API details and UI features can be found here: https://docs.privategpt.dev/
Conceptually, PrivateGPT is an API that wraps a RAG pipeline and exposes its primitives.
- The API is built using FastAPI and follows OpenAI's API scheme.
- The RAG pipeline is based on LlamaIndex.
The design of PrivateGPT allows to easily extend and adapt both the API and the RAG implementation. Some key architectural decisions are:
- Dependency Injection, decoupling the different components and layers.
- Usage of LlamaIndex abstractions such as
LLM,BaseEmbeddingorVectorStore, making it immediate to change the actual implementations of those abstractions. - Simplicity, adding as few layers and new abstractions as possible.
- Ready to use, providing a full implementation of the API and RAG pipeline.
Main building blocks:
- APIs are defined in
private_gpt:server:<api>. Each package contains an<api>_router.py(FastAPI layer) and an<api>_service.py(the service implementation). Each Service uses LlamaIndex base abstractions instead of specific implementations, decoupling the actual implementation from its usage. - Components are placed in
private_gpt:components:<component>. Each Component is in charge of providing actual implementations to the base abstractions used in the Services - for exampleLLMComponentis in charge of providing an actual implementation of anLLM(for exampleLlamaCPPorOpenAI).
Contributions are welcomed! To ensure code quality we have enabled several format and
typing checks, just run make check before committing to make sure your code is ok.
Remember to test your code! You'll find a tests folder with helpers, and you can run
tests using make test command.
Don't know what to contribute? Here is the public Project Board with several ideas.
Head over to Discord #contributors channel and ask for write permissions on that Github project.
Join the conversation around PrivateGPT on our:
If you use PrivateGPT in a paper, check out the Citation file for the correct citation.
You can also use the "Cite this repository" button in this repo to get the citation in different formats.
Here are a couple of examples:
@software{Martinez_Toro_PrivateGPT_2023,
author = {Martínez Toro, Iván and Gallego Vico, Daniel and Orgaz, Pablo},
license = {Apache-2.0},
month = may,
title = {{PrivateGPT}},
url = {https://github.com/imartinez/privateGPT},
year = {2023}
}Martínez Toro, I., Gallego Vico, D., & Orgaz, P. (2023). PrivateGPT [Computer software]. https://github.com/imartinez/privateGPT
PrivateGPT is actively supported by the teams behind:
- Qdrant, providing the default vector database
- Fern, providing Documentation and SDKs
- LlamaIndex, providing the base RAG framework and abstractions
This project has been strongly influenced and supported by other amazing projects like LangChain, GPT4All, LlamaCpp, Chroma and SentenceTransformers.