2022 Gachon University Data Science Term Project -YOUNGMIN OH Prof-
We apply step of the end-to-end BigData process in this project
If you have any questions about this project, please contact us by email
박태환 [[email protected] ] Preprocessing
김현종 [[email protected]] Regression
유소연 [[email protected]] Knn
김민준 [[email protected]] K-Fold Validation
We use 2022 Fuel Consumption Rations about vehicles
Kaggle Data at 2022 Fuel Consumption Ratings
- Desciption : Dataset offers model-specific fuel consumption ratings and estimated carbon dioxide emissions for new light-duty vehicles for retail sale in Canada in 2022
- Objective : Analze how the vehicle type, engine specifiationsm,transmission, fuel, and fuel'efficiency rate to the cunt of carbon dioxide generated.
FuelConsumptionRatings
├─.vscode
├─resources
│ └─MY2022 Fuel Consumption Ratings.csv
│
└─src
└─tp_rating_knn.ipynb
└─tp_rating_regression.ipynb
└─.ipynb_checkpoints
- resources : The dataset we used 2022 Fuel Consumption Ratings
- src : Jupyter notebook file with model (KNN , Poly Regression) training and testing
-
Preprocessing
- We use data Scaling and encoding
- Use the OrdinalEncoder to encode the brand name, car class, fuel type, and transmission numerically
- Normalization is carried out using StandardScaler
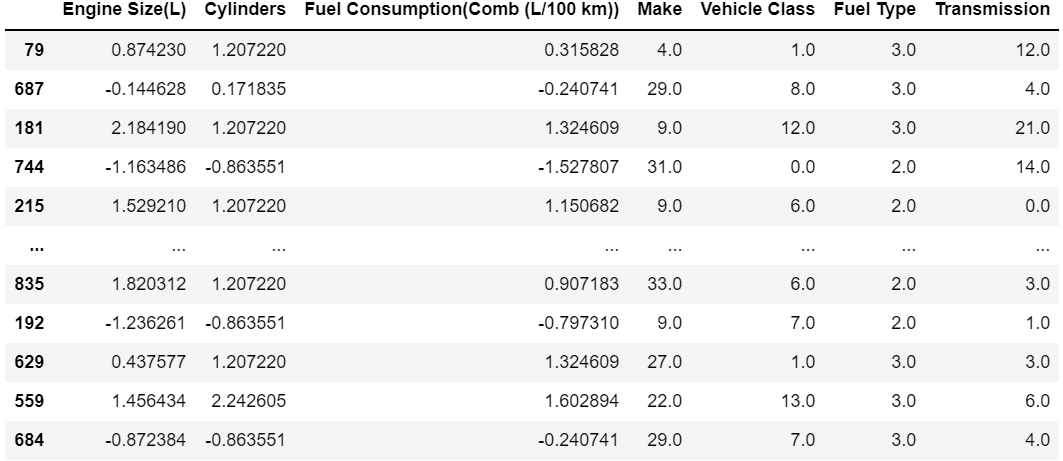
-
Poly regression
- predict with Polynomial Regression Model
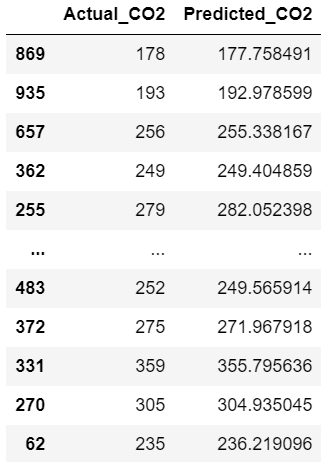
- predict with Polynomial Regression Model
-
KNN
- set k = n^(1/2).
- Accurancy of KNN classifier
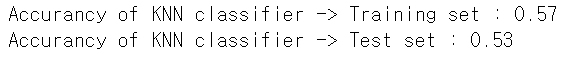
-
Evaluation
- K-Fold Validation
- default K = 10
Poly regression - 10 K Fold Validation
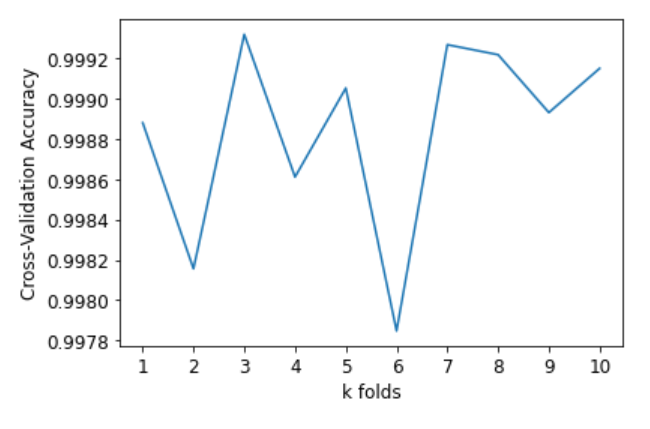
KNN - 10 K Fold Validation
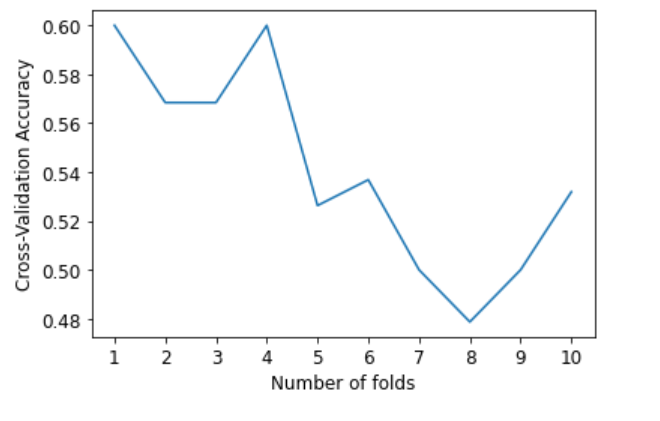
- K-Fold Validation
See the Jupyter Notebook files for more information.
- After creating a Polynomial Regression model and learning with the values of training x and y, the model and predictions are returned by making predictions with test X.
def predict_poly_regression(train_X, train_y, test_X, deg):
regression_model = Pipeline([('poly', PolynomialFeatures(degree=deg)),
('linear', LinearRegression(fit_intercept=False))])
regression_model = regression_model.fit(train_X, train_y)
predicted_co2 = regression_model.predict(test_X)
return regression_model, predicted_co2- From the 2 to the 10 degree, the regression model is predicted, and the R square adj value is calculated to return the degree with the largest R square adj value.
def get_degree(train_X, train_y, test_X, test_Y):
max_r2_adj = 0
max_degree_r2_adj = 0
for deg in range(2, 11):
regression_model, predicted_co2 = predict_poly_regression(train_X, train_y, test_X, deg)
r_score = r2_score(test_Y, predicted_co2)
n = len(test_Y)
r2_adj = 1 - (1 - r_score) * (n - 1) / (n - len(columns) - 1)
if max_r2_adj < r2_adj:
max_r2_adj = r2_adj
max_degree_r2_adj = deg
return max_degree_r2_adj- Evaluate a score by cross-validation.
Model : estimator object implementing ‘fit’
X : features
y: The target variable to try to predict in the case of supervised learning
k : the number of folds
return : Array of scores of the estimator for each run of the cross validation.
def kfoldValidation(model,X,y,k):
kfold = KFold(n_splits=k, shuffle=True ,random_state=0)
scores = cross_val_score(model, X, y, cv=kfold)
return scores- The decision tree algorithm is added to the existing knn algorithm to predict the result with the voting algorithm and return the accuracy.
def get_score_of_voting(depth):
tree = DecisionTreeClassifier(max_depth=depth)
voting = VotingClassifier(estimators=[('KNN', knn), ('tree', tree)], voting='soft')
voting.fit(X_train, Y_train)
pred = voting.predict(X_test)
return accuracy_score(Y_test, pred)- Polynomial Regression : scikit-learn regression-extending-linear
- Degree : sklearn.metrics.r2_score
how-do-i-calculate-the-adjusted-r-squared-score-using-scikit-learn - KNN algorithm: sklearn.neighbors.KNeighborsClassifier
- K fold Cross Validation 1 : https://todayisbetterthanyesterday.tistory.com/21
- K fold Cross Validation 2 : https://techblog-history-younghunjo1.tistory.com/102)
- Voting algorithm : https://techblog-history-younghunjo1.tistory.com/102