我发现在研究生学习中遇到的很多问题都是相似的,不管是科研任务、代码实现、服务器管理。但一届一届的师兄师弟都在找着同样的资料,浪费着同样的时间。我希望这种经验贴能够帮助新老同学,新同学能够更快入门,老同学没必要去纠结自己一年前解决过的问题。个人能力有限,希望同学们一起分享、订正、补充 (留下Issues或者直接联系我) 🤗。
News:
- (2024.04.01)准备更新升学相关内容,包括:找工作、实习、博士申请,提前感谢@yinguoweiOvO (yinguowei)、TankosTao (HeTao) 。
- (2024.04.01)如何用Latex撰写毕业论文开始持续更新,感谢@yinguoweiOvO (yinguowei)提供的重庆大学毕业论文Latex模板。
Notes: 很多内容没有具体详细的代码和指令,只会提供一个思路或者关键词,希望同学们能够善用ChatGPT、Bing AI、Google ,中文相关问题可以尝试国内大模型例如,ZhiPu😀。
Tips:
- 代码问题:优先查看相应的官方文档、Github官方仓库的Issues(很多软件或者包都是开源的,都有官方仓库,特别是当你复现人家论文的时候,找到作者的仓库,然后直接看Issues或者提出Issues)、Bing AI
- 论文问题:最好看原文,再结合官方代码。知乎或者CSDN解析都差很多意思,而且最新的文章一般没有(该建议来自于其它大佬)
- Latex问题:Bing AI、Google、Overleaf(Overleaf上其实有很多很多Latex相关的语法或者编译问题解答,文档较全,一般能解决问题)
- Adobe破解:https://baiyunju.cc/8602 (一般来说老的版本可以用amt-emulator,去破解
amtlib.ddl,只要包含amtlib.ddl的版本应该都能破解,不仅仅是2017及以前。但是vposy大神的版本感觉更好用更安全点,就是可能百度网盘下载速度有点问题,这里也有个妥协的办法) - 实验问题:推荐大家使用Docker、Wandb、Git管理自己的实验环境、数据、代码、模型。这可能是完成高质量实验的一个基础,有利于你实验结果的稳定性、可复现性、可扩展性 (据我了解,在大组、公司这几乎是必须的流程)
Resources:
- wandb: http://10.236.11.202:8080. 用户名和密码私下找我
- docker registry: http://10.236.11.202:5000. 用户名和密码私下找我
- New Bing (破解版): http://10.236.11.67:3001/
工欲善其事必先利其器
我尝试使用过Zotero这种自定义更高的工具,但ReadPaper相关功能更易用且更完善。个人推荐。 该软件目前已收费,而且功能较为繁杂,没有之前推荐,但仍然是一个较好的软件
可以在设置里面选择下载预览版(
dev版),一般来说可以先享受新的features
个人认为重要程度大于Photoshop,很多时候你不能P图,但你需要处理PDF
破解版 百度云,更多信息见文章开头,Adobe破解部分
推荐和OneDrive一起使用,一般来说OneDrive有送的5G空间。直接把数据库放在OneDrive上,实现多端同步,非常简单
有破解教程,直接买也不贵
国产替代
Notepad--,目前我也在试用中
可以和VSCode搭配使用,在本地搭建Texlive环境
- 多用户协同是优于本地
Texlive+Git,而且可以任意使用多版本Texlive,有时候需要切换版本- 注意Overleaf默认编译条件特别宽松,可以进行设定
- Overleaf还可以直接发布,这个功能我还在探索中
- 直接支持
Markdown书写,Word、- 多端云同步,免费空间也较大,作为手机端笔记记录软件也非常好用
好用,重装系统推荐,特别是Linux
- Google Scholar 关键词,建议先找综述
- 看最新顶会文章中的相关工作(很好用,一般来说大组顶会文章的相关工作做的非常详细)
这个插件可以显示出论文发表期刊会议的CCF等级、所属出版商、IF、SCI分区等
\usepackage[ruled,noline]{algorithm2e}
\usepackage{setspace} % change the margin
\definecolor{commentcolor}{RGB}{110,154,155} % define comment color
\newcommand{\PyComment}[1]{\ttfamily\textcolor{commentcolor}{\# #1}} % add a "#" before the input text "#1"
\newcommand{\PyCode}[1]{\ttfamily\textcolor{black}{#1}} % \ttfamily is the code font\setlength{\algomargin}{0em} % change the margin
\SetAlFnt{\small} % set the font size
\begin{algorithm}[thb]
\setstretch{0.8} % chagne the line spacing
\PyComment{this is a comment} \\
\PyComment{this is a comment} \\
\PyComment{} \\
\PyComment{going to have indentation} \\
\PyCode{for i in range(N):} \\
\Indp % start indent
\PyComment{your comment} \\
\PyCode{your code} \PyComment{inline comment} \\
\Indm % end indent, must end with this, else all the below text will be indented
\PyComment{this is a comment} \\
\PyCode{your code}
\caption{PyTorch-style pseudocode for PicT testing scheme}
\label{algo:your-algo}
\end{algorithm}Creating multiple bibliographies in the same document - Overleaf, Online LaTeX Editor
\usepackage[resetlabels,labeled]{multibib}
\newcites{Math}{Math Readings}
\newcites{Phys}{Physics Readings}\cite{paper1} and \cite{paper2} were published later than
\citeMath{paper3}. See also \citePhys{paper4}.
\bibliographystyle{unsrt}
\bibliography{references}
\bibliographystyleMath{unsrt}
\bibliographyMath{refs-etc}
\bibliographystylePhys{unsrt}
\bibliographyPhys{refs-etc}
- 值得注意的是,使用该包会生成多个 .aux文件,必须对每个文件都进行bibtex编译后,再使用pdftex编译
- 每个部分的bib文件最好单独存放,并单独命令各自的引用文章简写
- 先看论文本身,一般在首页、摘要有官方链接,或者实验部分、补充文档
- Github,直接在搜索框搜论文名字,几乎所有放在github上的复现代码,都会在readme中写上论文标题。这种方法特别重要,因为一些实验室的代码可能并不够好或者用的Tensorflow,这种方法能找到一些大佬复现的Pytorch或者质量更高的代码
- paperwithcode,这个网站初衷很好,但近几年几乎没有维护,个人感觉不好用
LaTeX (Latex)是一个研究生必备的工具,通常用于撰写学术论文,因为通常会议、期刊都会提供相应的Latex模板。虽然各大高校早已习以为常,但在重庆大学,使用Latex撰写毕业论文算一个新鲜事。以下内容致力于推进此事
- 重庆大学有一个非官方古老模板,该模板文档较为完善,后续其它模板也基本根据它来进行改动。但它本身比较古老,近两年没有更新,没有匹配2023版毕业论文格式要求
- 2023年,重大有个博士师兄分享了他自己撰写毕业论文的模板,本次我们使用的模板在此基础上进行改动。2023这个版本有部分格式和word版本有较大出入,且无法在
overleaf上进行编译- 2024版为531实验室修改版本,基本和word版本完全相同,细节请查看项目仓库,感谢@yinguoweiOvO (yinguowei)的贡献
如果你是在用Latex撰写学术论文,我推荐你使用
Overleaf而非本地编译器,其在多人协作、版本管理、编译上有太多优势。但Overleaf本身是Linux系统进行编译,有部分字体问题,毕业论文最后可以在本地进行编译
TexLive 是本地编译环境的核心包,推荐搭配VScode,SumatraPDF一起使用
在安装中,推荐使用可视化界面,能够进行预装包的选择,推荐多个Tex版本都进行安装,因为毕业论文的编译是靠XeLaTex和bibTex,常规的PdfTex对中文支持较差
后续会在2024版仓库进行详细更新,这里只会提供部分Tips
PPT中绘制的图,有多种方式导出,经本人经验,不同方式导出的质量有所不同,而根据不同的需求应该选择不同的方式
- 如果你的图完全由
矢量元素构成,那么推荐使用导出\创建PDF文档。这种方式会更好地处理适量元素的阴影等特效。 - 如果你的图包含
高清非矢量图,而你又需要导出的PDF中的非矢量图画质较高,那么推荐使用另存为\Adobe PDF打印机。Adobe PDF打印机可以自主调节图片压缩选项,最极端的,可以完全不压缩图片生成PDF - 如果你的导出
PDF过大,可以直接使用Adobe Acrobat DC进行图片压缩
现在外界流传的
dogcom和dogcom.conf非常老,配置文件在个别服务器上出错,并且不能登出。我根据drcom-generic/Drcom_CQU_HuxiCampus.py at master · drcoms/drcom-generic (github.com)重新写了一个python3的联网脚本,支持登出Tips:
校园网使用哆点进行认证,github上有相关的仓库:drcoms/drcom-generic: Dr.COM/DrCOM 现已覆盖 d p x三版。 (github.com)、mchome/dogcom at 309db8f545d7454b464a5d5d1d7dc4bde313f07a (github.com),如果有问题或者后续修改,可以查询相关仓库
latest_w.py和dr.sh在 /tools/dogcom/下请修改
latest_w.py文件中的34和35行 (username和password变量),以使用自己的校园网账户进行登陆
# case1: 直接使用python文件登陆,这种情况会在终端显示log,并且随着终端的kill而kill,没有进程持久化
python3 latest_w.py
# case1: 按Ctrl+C,直接关闭该进程同时登出
# case2: 使用nohup维持进程持久化,我这里写了一个shell dr.sh
bash dr.sh
# case2: 这种情况下,请先使用ps找到你的python3进程
ps -aux | grep python3
# case2: 找到对应的 python3 latest_w.py 的进程号pid,kill该进程
kill -9 pid
# kill该进程的同时登出,相关的log会在./log下VSCode有ssh插件,可以直接通过ssh连接服务器,并支持直接编辑服务器上的文件。扩展可以直接装在服务器上
Tips:
- 可以使用公钥,避免每次打开文件都需要输入密码。(如果你已经在服务器
A上配置了公钥登录,那只需要配置VSCode的ssh配置文件即可)简单流程如下:
- 本地主机创建公钥、私钥。公钥文件一般为
id_rsa.pub,在c:\Users\$username\.ssh\下- 复制你的公钥内容至服务器
A的密钥认证文件/home/$username/.ssh/authorized_keys中- 修改VSCode的ssh配置文件
- 如果遇到ssh问题,请查看VSCode的
output,一般来说将服务器上的VSCode Server (/home/$username/.vscode-server/bin/$bin_code)进行删除可以解决大部分问题。可以在output中查看到$bin_code
不要直接在ssh窗口开始跑实验,请使用
tmux,其会创建一个持久化的窗口。以避免你当前窗口因特殊情况崩溃导致的实验中断
tmux new -s xxx
tmux a -t xxx
tmux kill-session -t xxx请最好使用AMP(半精度)训练,实验室GPU资源较为紧张,使用AMP训练可以有效降低显存,也不会损害你的性能。大厂都在用,一般来说训练速度还会有所提升
Automatic Mixed Precision package - torch.amp — PyTorch 2.0 documentation
Backbone模型不推荐自己复现,也不推荐看CSDN复现,仅推荐查看相关领域论文或timm。NLP-Transformer类请参见huggingface
训练代码不推荐完全自己写,也不推荐看CSDN,仅推荐查看相关领域论文(大组),或者大佬的,以下是我觉得很好的几个例子:
- 推荐使用
yaml文件存储config,而非全部config写在parser中- 两个例子中有特别多的
trick,例如batchsize scale, amp, ddp, gradient accumulate, gradient clip, mixup, checkpoint, ...很多trick能有效提点,有些没有这么神奇
管理实验数据、代码特别特别特别重要。一般来说实验代码会随着你的研究进程不断迭代,但一般人的水平都很难做到一直迭代还能保证能复现之前结果。因此最好对实验代码做版本管理
Wandb:
- 存储你的Git的
checkout,本身也可以存储代码文件,详情查看文档- 记录所有
metrics和log,并自动提供可视化,方便后续论文撰写- 注意,如果不设定存储路径(本地,在Pytorch代码中设定),会默认在你项目路径下备份一个实验数据(另一份传至服务器)。一般来说项目路径在
/home/$username/下面,因此请设定存储路径到/data/$username- wandb也可以存储模型梯度,
wandb.watch(),详情查看文档- 请不要建立太多
project,因为实验室服务器只能有一个账号,所有人的project都在里面- 具体ip和账号名询问管理员
Basic Setup - Documentation (wandb.ai)
将wandb.your-shared-local-host.com替换成本地的IP:Port
wandb login --host=http://wandb.your-shared-local-host.com在 http://wandb.your-shared-local-host.com/settings 界面可以找到API keys
下面部分是管理wandb私人服务器,如果只是使用请忽略。至于如何在代码中使用wandb,请查询官方document
不要对 Volumes 进行操作,这是保存数据的文件。可以删除 Containers ,然后在WSL中执行以下命令重新打开一个 APP。 --restart=always 可以让容器每次随着docker服务启动。-e HOST=http://$server_ip:8080可以让wandb的前端界面正常和后端服务器交互信息,不然会默认为127.0.0.1:8080。
docker run -d --mount type=volume,src=wandb,dst=/vol -p 8080:8080 -e HOST=http://$server_ip:8080 --name wandb-local --restart=always wandb/localdocker pull wandb/local目标volume:wandb ,保存位置:/home/tangwenhao/twh ,backup文件名:backup.tar
sudo docker run \
--rm \
-v wandb:/files_to_copy \
-v /home/tangwenhao/twh:/place_to_paste \
busybox \
sh -c 'cd /files_to_copy && tar cf /place_to_paste/backup.tar .'目标volume:wandb ,保存位置:/home/tangwenhao/twh ,backup文件名:backup.tar
$ docker run \
--rm \
-v wandb:/place_to_paste \
-v /home/tangwenhao/twh:/files_to_copy \
busybox \
sh -c 'cd /place_to_paste && tar xf /files_to_copy/backup.tar .'造成原因可能是 $VOLUME_DIR/env/users.htpasswd 下的记录消失,user表和entities表中仍有记录。无法登录,无法重置密码
利用之前备份的记录,重写入/env/users.htpasswd
1070820773@qq.com:$2a$10$lupwoWa8YKrDmFqKdu4huOqAVHFdCGjHE/ZZG8QpPXRTa.jdPSuWq
#对应密码:123456789恢复正常
- 比向日葵好用100倍,但只适用于内网,且需要Windows专业版(在你需要被远程的那个主机上安装,淘宝10元)
- 可以搭配ipv6使用,实现内网穿透,但有一定的网络风险。Ipv6的地址最好用
[]括上。
十分方便,不需要任何配置,只需要联网即可
选择其中一个服务器
A作为远程仓库,保证其它所有服务器都能与A进行ssh连接。这里推荐ssh公钥的形式
-
这里需要在其余服务器
B,C,D,...上初始化公钥、私钥(如果已经有请跳过,一般来说存放在/home/$username/.ssh/下名字为id_rsa.pub) -
将服务器
B,C,D,...上的公钥中的内容复制下来,粘贴到服务器A的认证密钥文件(/home/$username/.ssh/authorized_keys)中。 -
在服务器
A上初始化git服务器其等效于远程仓库,获得目录/home/$username/.../xx.gitgit init --bare xx.git
-
在服务器
B,C,D,...上添加远程仓库,通过ssh的形式ssh://$username@Server_A_IP:/home/$username/.../xx.git
这里的
Server_A_IP是服务器A的IP。 -
Tips:就算在服务器
A上,也要在另外一个目录放置代码,然后使用git进行代码管理,不能直接修改服务器A上的git服务器的代码。
GitHub repo: https://github.com/canton7/SyncTrayzor
最好不要用,但紧急情况下,可以私下联系我。后续更新
主要难点在于之前的系统引导(UEFI或者Legacy)要与当前对应。不然在新系统分区那里,没办法在原硬盘上设定安装引导程序
重点在于一定要备份!!!
- 没网的时候注意不要先设定网络连接,会导致后面安装失败
- 禁用Sleep:
systemcyl status sleep.target可以查看是否开启该服务。禁用:sudo systemctl mask sleep.target suspend.target hibernate.target hybrid-sleep.target
- 一般Ubuntu使用
/etc/netplan或者/etc/nework配置IP,这俩只能取其一。配置文件就在其中。- 要弄明白
dhcp和static,机房默认是static,找管理员要网关、DNS- 记得备份默认的配置文件
mv default.yaml default.yaml.backup- 虽然这两个工具都可以热重启,但还是推荐重启服务器,可以省很多麻烦
- 注意网线插的网口是否和配置文件一致,如果一直不起效,请将网线插入其它网口试试
编辑 /etc/modprobe.d/blacklist-nouveau.conf 文件,添加以下内容:
blacklist nouveau
blacklist lbm-nouveau
options nouveau modeset=0
alias nouveau off
alias lbm-nouveau off关闭nouveau:
echo options nouveau modeset=0 | sudo tee -a /etc/modprobe.d/nouveau-kms.conf重新生成内核并重启:
sudo update-initramfs -u
sudo reboot重启后,执行:lsmod | grep nouveau。如果没有屏幕输出,说明禁用nouveau成功。
- 注意,安装的driver版本最好和CUDA版本相对应。各个CUDA版本的Doc:CUDA Toolkit Archive | NVIDIA Developer。在此处查看:Release Notes :: CUDA Toolkit Documentation (nvidia.com)
nvidia-smi有时候很慢,注意更改持久模式:sudo nvidia-persistenced --persistence-mode或者sudo nvidia-smi -pm 1- Ubuntu重启有可能找不到Driver,一般情况是内核进行了更新。使用
ls /usr/src查看驱动版本号,然后生成导向模块sudo dkms install -m nvidia(nvidia-srv) -v 530.30.02。Ubuntu20.04重启后找不到Nvidia显卡驱动 - keep-minding - 博客园 (cnblogs.com)
采用apt方法
使用命令ubuntu-drivers devices获取可用驱动信息,如果命令不存在自己安装一下。
sudo apt install nvidia-driver-***-server
CUDA Toolkit Archive | NVIDIA Developer
选择对应的版本,最好采用runfile的安装形式,有一个交互过程,deb的安装会默认替换掉你先有的driver,非常麻烦
sudo sh cuda_11.4.0_470.42.01_linux.run
切记:安装driver之后,不要在安装CUDA时再次安装!!!
注意,当提醒你已经安装了driver的时候,直接continue。当选择安装内容的时候,务必把driver前面的x取消掉,因为我们已经安装了驱动!!!
添加环境变量:
vim /etc/profile :(将 *** 替换为对应的CUDA版本)
export PATH=/usr/local/cuda-***/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-***/lib64\
${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}nvcc -V 显示相关信息,表示安装成功
CUDA Deep Neural Network (cuDNN) | NVIDIA Developer
Installation Guide :: NVIDIA Deep Learning cuDNN Documentation
最好下载TAR,然后复制
解压:
tar -xvf cudnn-linux-x86_64-8.x.x.x_cudaX.Y-archive.tar.xz复制:
$ sudo cp cudnn-*-archive/include/cudnn*.h /usr/local/cuda/include
$ sudo cp -P cudnn-*-archive/lib/libcudnn* /usr/local/cuda/lib64
$ sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*- 首先查看当前驱动版本
ls /usr/src | grep nvidia- 重新安装现有的驱动版本
sudo dkms install -m nvidia -v 450.57 # 版本即使上一个命令的输出
# 如果没有安装dkms包
sudo apt-get install dkms- 重启
sudo rebootdocker命令 报Got permission denied while trying to connect to 错误 - ranh - 博客园 (cnblogs.com)
sudo usermod -aG docker $usernameRootless mode allows running the Docker daemon and containers as a non-root user to mitigate potential vulnerabilities in the daemon and the container runtime.
Rootless mode does not require root privileges even during the installation of the Docker daemon, as long as the prerequisites are met.
Rootless mode was introduced in Docker Engine v19.03 as an experimental feature. Rootless mode graduated from experimental in Docker Engine v20.10.
Run the Docker daemon as a non-root user (Rootless mode) | Docker Documentation
这种情况下,系统中有两个单独的Docker,相互独立
rootless Docker存在一定限制:
Run the Docker daemon as a non-root user (Rootless mode) | Docker Documentation
刷新配置,重启服务:
systemctl --user daemon-reload
systemctl --user restart docker更多Rootless的 TIPS
- 需要手动安装[
slirp4netns包](Releases · rootless-containers/slirp4netns (github.com)),这个包无法通过apt-get安装
daemon.json 文件应该在 ~./config/docker/ 下
绝大多数mirror都无法正常使用,阿里云的已经不再更新,dockerproxy.com好像还行,不知道是个啥组织
学校的网好像可以直接访问官方hub
关键在于Keras一些层权重包的存储方式和Torch不同,要进行一个维度转化
def keras_to_pyt(km, pm):
weight_dict = dict()
for layer in km.layers:
if type(layer) is keras.layers.convolutional.Conv2D:
if (len(layer.get_weights()) >= 1):
weight_dict[layer.get_config()['name'] + '.weight'] = np.transpose(layer.get_weights()[0], (3, 2, 0, 1))
if (len(layer.get_weights()) >= 2):
weight_dict[layer.get_config()['name'] + '.bias'] = layer.get_weights()[1]
elif type(layer) is keras.layers.Dense:
if (len(layer.get_weights()) >= 1):
weight_dict[layer.get_config()['name'] + '.weight'] = np.transpose(layer.get_weights()[0], (1, 0))
if (len(layer.get_weights()) >= 2):
weight_dict[layer.get_config()['name'] + '.bias'] = layer.get_weights()[1]
elif type(layer) is keras.layers.DepthwiseConv2D:
if (len(layer.get_weights()) >= 1):
weight_dict[layer.get_config()['name'] + '.weight'] = np.transpose(layer.get_weights()[0], (2, 3, 0, 1))
if (len(layer.get_weights()) >= 2):
weight_dict[layer.get_config()['name'] + '.bias'] = layer.get_weights()[1]
elif type(layer) is keras.layers.BatchNormalization:
if (len(layer.get_weights()) >= 1):
weight_dict[layer.get_config()['name'] + '.weight'] = layer.get_weights()[0]
if (len(layer.get_weights()) >= 2):
weight_dict[layer.get_config()['name'] + '.bias'] = layer.get_weights()[1]
if (len(layer.get_weights()) >= 3):
weight_dict[layer.get_config()['name'] + '.running_mean'] = layer.get_weights()[2]
if (len(layer.get_weights()) >= 4):
weight_dict[layer.get_config()['name'] + '.running_var'] = layer.get_weights()[3]
elif type(layer) is keras.layers.ReLU:
pass
elif type(layer) is keras.layers.Dropout:
passAutomatically Add Static Routes After Connecting to VPN | Windows OS Hub (woshub.com)
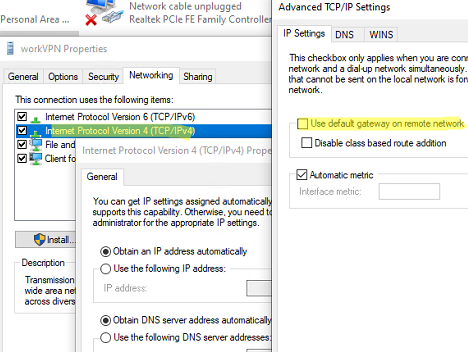
OR
Set-VpnConnection –Name workVPN -SplitTunneling $True添加路由:
Add-VpnConnectionRoute -ConnectionName workVPN -DestinationPrefix 192.168.11.2/32 -PassThru该指令是在你激活VPN的时候添加路由信息,在退出VPN服务器后,删除该路由
删除路由:
Remove-VpnConnectionRoute -ConnectionName workVPN -DestinationPrefix 192.168.111.0/24 -PassThru直接使用xftp进行拖拽
- 登录: sftp -P port user@ip (-P 是大写)
- 使用 ls 命令列出目录,使用 "cd CloudData" 命令进入数据根目录
- 使用 "get <文件名>", 从云盘下载文件到本地当前目录
- 使用 "get -r <文件夹名>", 从云盘下载目录到本地当前目录
- 使用 "put <文件名>", 把当前目录的本地文件上传到云盘
- 使用 "put -r <文件夹名>", 把本地当前目录上传
如果你是Root-less,有坑!!
- 下面命令会报错,因为Rootless的配置文件位置不同
sudo nvidia-ctk runtime configure --runtime=docker这个时候建议你在普通Docker配置文件应在位置/etc/docker建一个文件,然后复制改写后的内容到Rootless的配置文件.config/docker下。
- 还要记得改
/etc/nvidia-container-runtime/config.toml,将里 面的no-cgroups设为true
Tips:
- 宿主主机的Driver版本跟你在Container中能用的CUDA版本挂钩,你Driver版本太低用不了高版本的CUDA。其中
495(cuda 11.5)和520 (cuda 11.8)版本的driver几乎没有兼容性,宿主主机千万别是这俩。CUDA兼容性问题(显卡驱动、docker内CUDA) - 知乎 (zhihu.com) - CUDA的Forward compatibility好像仅对Tesla架构的显卡有用,所以最好升级你的driver。PyTorch的CUDA错误:Error 804: forward compatibility was attempted on non supported HW - 知乎 (zhihu.com)
DockerHub 中 Torch和Nvidia官方的image都有devel这个版本,大小会比普通的runtime大很多。如果你需要在image中使用cuda编译某个包,就需要devel,如果你只是想用下pytorch-gpu那就完全没必要。nvidia的官方base-image还要选择是否使用cudnn
sudo timeshift --help
服务端升级Ubuntu 20.04 LTS 记录 - 知乎 (zhihu.com)
-
不要无脑continue,一定要看清楚,保证网络畅通,记得提前更换apt源,不然肯定失败
-
除了sshd的配置之外,其它配置都推荐不要维持原版本,sshd不知道也不会不会冲突,最后都用新的自己重新配置
Releases · Dreamacro/clash (github.com)
需要手动下载Country.mmdb,将其改名为Country.mmdb
下载proxychains4,配置目录/etc/proxychains.conf
- 改为
dynamic_chain - 添加代理ip,好像不能添加
https
测试是否成功
proxychains4 curl www.httpbin.org/ip非root可能报错,见proxychains4配置使用 - 0xcreed - 博客园 (cnblogs.com)
proxychains4 对docker无效,docker代理需要单独配置
-
一次性,指定
uid可以正常使用用户读写文件夹,不然权限错误sudo mount -o uid=$UID /dev/sdc1 /mnt/book -
每次开机自动挂载
ubuntu自动挂载硬盘实现所有用户可读写 - 知乎 (zhihu.com)
# 查看 TYPE 和 UUID sudo blkid # 编辑 /etc/fstab文件 UUID=$UUID /mnt/book $TYPE defaults,uid=$UID,gid=$GID 0 0
该问题核心在于内网穿透,但ipv6解决了该问题,因此下面都是基于通信两边都具有公网ipv6且已经解决了路由器问题和防火墙问题
sftp: 要注意加上
-6,不然默认会解析成ipv4的地址,还要把地址加上[]ssh: 直接使用ipv6地址即可
使用docker-compose搭建私有docker registry - 落叶&不随风 - 博客园 (cnblogs.com)
Docker Compose 部署配置和使用 Registry 私有镜像仓库 - 思有云 - IOIOX
TODO:
- 令牌认证,对不同用户的权限进行规范
-
启动一个一次性容器用于创建账号密码.密码文件路径以
/root/registry/htpasswd为例,账号密码以admin和12345678为例.docker run --rm --entrypoint \ htpasswd httpd:2 -Bbn \ admin 12345678 > /root/registry/htpasswd -
daemon.json写入:{ "insecure-registries": [ "[私有仓库 ip:port]" ] } -
docker-compose.yaml,该文件可以在任意位置,后续-f指定即可version: '3' services: registry: image: registry:2 restart: "always" ports: - 5000:5000 environment: - REGISTRY_AUTH=htpasswd - REGISTRY_AUTH_HTPASSWD_PATH=/auth/htpasswd - REGISTRY_AUTH_HTPASSWD_REALM=Registry Realm - REGISTRY_STORAGE_DELETE_ENABLED=true volumes: - $DATA_ROOT:/var/lib/registry - $PASSWD_ROOT:/auth/htpasswd
-
使用
docker-compose部署仓库docker-compose -f $DOCKER_COMPOSE_CONFIG up -d
HTTP API V2 | Docker Documentation
Docker私有仓库Registry删除镜像的方法【20220321】 - 鬼谷子叔叔 - 个人主页 (tongfu.net)
docker私有镜像仓库搭建和镜像删除 - 简书 (jianshu.com)
这个比较麻烦,总的来说,可以通过API的方法来删,但也需要修改container里面的config,位置在/etc/docker/registry/config.yml,然后查询digest,然后根据digest调用DELETE API进行删除,最后垃圾回收
第二个攻略说是没有删干净,但我发现其实主体文件通过以上步骤可以完全删除,只是会留下一个registry,占用空间很小
先看本地有什么现存的image
docker image ls跑实验需要的特制化image都放在本地仓库中,通用的请查看 Docker_Hub。先查看本地仓库有哪些image,本地仓库ip默认为10.236.11.202:5000
# 登陆本地仓库,输入账户名和密码
docker login $LOCAL_REGISTRY_IP
# 先查看有哪些image
curl -u $USER:$PASSWD http://$LOCAL_REGISTRY_IP/v2/_catalog
# 再查看具体的image下有哪些tag
curl -u $USER:$PASSWD http://$LOCAL_REGISTRY_IP/$IMAGE_NAME/tags/listpull, push,非特殊情况,不要随意push image到本地仓库中,就算要push,也要在commit的时候做好comment,然后 tag写清楚。目前本地仓库没有做权限限制,登陆后就可以对上面的所有image做任何操作
# PULL跟常规一样,只是要注意要在image前面加上本地仓库的Ip,否则会默认从docker_hub获取
docker pull $LOCAL_REGISTRY_IP/$IMAGE_NAME:$TAG
# push
# push之前需要先commit一个本地的image
docker commit -a $AUTHOR_NAME -m $COMMENT $CONTAINER $LOCAL_REGISTRY_IP/$IMAGE_NAME:$TAG
docker push $LOCAL_REGISTRY_IP/$IMAGE_NAME:$TAG先看是否创建了container:
docker ps -adocker 管理工具推荐:portainer, 可以方便的删除,重启,暂停,重新配置docker容器。设定好docker容器的配置文件夹,可以很方便的迁移。
docker pull portainer/portainer
docker run -d -p 9000:9000 -v /var/run/docker.sock:/var/run/docker.sock --restart=always --name prtainer portainer/portaine如果已经有创建好的container就不要再run
# 针对已经stopped的container
docker start -a $CONTAINER_NAME
# 针对还在运行中的container
docker attach $CONTAINER_NAME如果没有现存container,就直接从run image。要注意的是,timm库和torch的模型默认的权重文件存放在./cache/huggingface和./cache/torch中,最好也把这两个文件夹做映射避免在不同image中重复下载。尽量只映射huggingface和torch这两个子文件夹,$LIB就是huggingface或者torch。
docker run --gpus all -it --shm-size 32g -p $CONTAINER_SSH_PORT:22 -v $CODE_DIR:/workspace/code -v $DATASET_DIR:/workspace/dataset -v $OUTPUT_DIR:/workspace/output -v $CACHE_DIR:/root/.cache/$LIB --name $CONTAINER_NAME $IMAGE_NAME想要使用ssh连接container
-
首先要在创建时进行端口映射
-p $CONTAINER_SSH_PORT:22 -
将客户端公钥放入
/root/.ssh/authorized_keys,可能需要创建该文件 -
记得查看
container中是否已经打开ssh_server服务:service ssh start -
建议使用
tmux进行实验,确保在terminal崩溃的情况下,实验能够继续
- 最好直接使用
host网络(--network host),跑实验用的container个人感觉不需要复杂的通讯,其带来的好处和便利非常诱人,例如:完整的ipv6支持
-
一般来说不会想在
container里面去支持ssh,然后去配置git仓库相关。因此,如果你是在宿主主机配置的git目录,然后映射到container中,那你最好运行以下命令:git config --global --add safe.directory /workspace/code