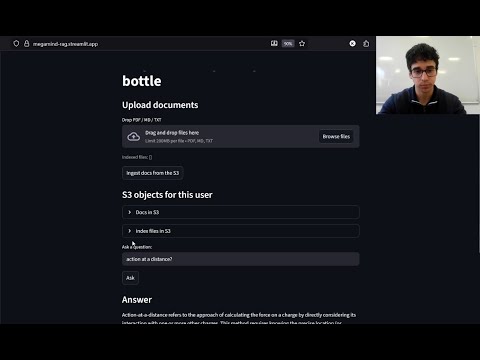
A fully online Retrieval-Augmented Generation (RAG) system with Streamlit frontend and FastAPI backend.
Upload PDFs, Markdown, or text files → automatically chunk, embed, index, and query them semantically: all in the cloud.
- Frontend: https://megamind-rag.streamlit.app
- Backend: https://megamind-rag.onrender.com/docs
Streamlit UI → FastAPI Backend → AWS S3 → FAISS Index → OpenAI Embeddings → LLM Response
Flow
- Upload documents via Streamlit.
- Files are stored in your S3 bucket (
/users/{user_id}/docs/). - Click Ingest to trigger the backend:
- Downloads from S3
- Chunks text into overlapping segments
- Generates embeddings (OpenAI or MiniLM)
- Builds a FAISS index → uploads back to S3
- Ask a question → retrieves top chunks → sends to LLM → returns contextual answer + citations.
| Component | Purpose |
|---|---|
| FastAPI | REST backend for /ask and /ingest |
| Streamlit | Frontend UI for uploads, ingestion, and Q&A |
| OpenAI / MiniLM | Text embeddings |
| FAISS | Vector similarity search |
| AWS S3 (boto3) | Cloud document + index storage |
| Render | Backend hosting (Dockerized) |
| Streamlit Cloud | Frontend hosting |
| Path | Description |
|---|---|
{APP_ENV}/users/{user_id}/docs/ |
Uploaded PDFs, Markdown, and TXT files |
{APP_ENV}/users/{user_id}/indexes/ |
Generated FAISS index and metadata |
- Chunking: Breaks long docs into overlapping sections to preserve context.
- Embedding: Maps text to semantic vector space using pretrained models.
- FAISS: Finds the most semantically similar chunks fast.
- RAG: Retrieval + Generation = grounded, explainable AI responses.
- Semantic (topic-aware) chunking
- Re-ranking retrieved chunks before LLM query
- Domain-tuned embeddings for specialized corpora
Alvaro Balbin: for programming everything.
Gen AI: for writing this README (but not the ideas in it, just polishing)