NYU ECE-GY 9143 · High Performance Machine Learning · Spring 2026
This project distills a large Swin-Large (~197 M params) vision transformer into a compact Swin-Tiny (~28 M params) student using multi-level knowledge distillation on ImageNet-1K. The distilled student is then repurposed as a frozen feature extractor for monocular depth estimation on NYU-Depth V2 via a DPT head, with further refinement through LoRA fine-tuning and post-training quantization.
Large vision transformers achieve state-of-the-art accuracy but are impractical for deployment due to their size and compute cost. Knowledge distillation transfers the learned representations of a large teacher into a smaller student, closing much of the accuracy gap while keeping the student compact. This project studies how well a distilled student backbone transfers to a downstream task (monocular depth estimation) without further backbone training, and explores three efficiency techniques: LoRA, post-training quantization, and multi-GPU scaling.
Phase 1 — ImageNet Distillation
─────────────────────────────────────────────────────────────────
Image ──► Teacher (Swin-Large, ~197 M, frozen)
│ │ Stage features [C = 192, 384, 768, 1536]
│ │
│ Feature Adapter (per stage, 1×1 conv bottleneck)
│ │ projects student → teacher channel space
│
└──► Student (Swin-Tiny, ~28 M) ──► Stage features [C = 96, 192, 384, 768]
│
┌───────────┴──────────────────────────────────┐
│ Distillation Losses │
│ • Feature-level cosine / MSE loss │
│ • Attention Transfer (AT) loss │
│ • Logit KL-Divergence (τ = 4) │
│ • Cross-entropy task loss (ground-truth) │
└───────────────────────────────────────────────┘
Phase 2 — Depth Estimation (NYU-Depth V2)
─────────────────────────────────────────────────────────────────
Image ──► Frozen distilled Swin-Tiny ──► 4 stage features
│
DPT Neck + Head
(Intel/dpt-swinv2-tiny-256)
│
Depth map (B, 1, H, W)
Phase 3 — LoRA Fine-Tuning
─────────────────────────────────────────────────────────────────
Frozen student + LoRA A/B adapters on every QKV layer
+ trainable DPT head → fine-tuned depth predictions
Phase 4 — Post-Training Quantization (PTQ)
─────────────────────────────────────────────────────────────────
FP32 baseline → FP16 (GPU) → Dynamic INT8 (CPU)
Comparison on RMSE, AbsRel, δ1, memory, and latency.
| Component | Choice | Rationale |
|---|---|---|
| Teacher | Swin-Large (22K→1K fine-tuned) | Strongest public Swin checkpoint |
| Student | Swin-Tiny (random init) | Shows learning from scratch under distillation |
| Feature adapter | 2-layer 1×1 Conv bottleneck + BN | Cheap projection; ~2 M params total |
| Feature loss | Cosine similarity | Scale-invariant; prevents one stage dominating |
| Depth head | DPT (Intel/dpt-swinv2-tiny-256) | Hierarchical features → dense predictions |
| LoRA target | qkv attention projections |
Highest parameter leverage per layer |
| Quantization | Dynamic INT8 (torch.ao) | No calibration data needed; 2× memory saving |
| Optimizer | AdamW + cosine LR + AMP | Standard for ViT-scale training |
| Multi-GPU | torchrun DDP on NYU H200/H100 |
Linear throughput scaling target |
Distilled Swin-Large (~197 M) into Swin-Tiny (~28 M) using multi-level feature distillation, attention transfer, and logit-level KD. Per-stage feature adapters (1×1 conv bottleneck) project the student's narrower features into teacher channel space. Training runs for 100 epochs on ImageNet-1K with cosine LR, AdamW, and mixed-precision (FP16 via AMP).
Key deliverables:
models/teacher.py,models/student.py,models/adapters.pydistillation/losses.py— Feature (MSE/cosine), AT, KD, task lossesdistillation/trainer.py— Full training loop with AMP, gradient clipping, checkpointing, W&Bconfigs/distill_config.yaml— All hyperparameters- W&B dashboard tracking train/val losses and Top-1/Top-5 accuracy
Attached a DPT neck + head (from Intel/dpt-swinv2-tiny-256) to the frozen distilled student and fine-tuned on NYU-Depth V2. Both frozen-backbone and full fine-tuning variants were explored. Evaluated with RMSE, AbsRel, and δ1/δ2/δ3 threshold accuracy.
Key deliverables:
models/depth_model.py—StudentWithDPT(frozen student + DPT head)models/dpt_head.py— DPT neck and depth headdata/nyu_depth_dataset.py— NYU-Depth V2 dataloaderdistillation/depth_trainer.py— SiLog-based depth training loopconfigs/depth_config.yaml
Applied LoRA (rank-4) to the QKV attention projections of the frozen distilled student, keeping the DPT head trainable. This adds only ~0.5 M new trainable parameters while adapting the backbone's attention patterns to the depth task.
Key deliverables:
models/lora.py—LoRALinear,apply_lora,count_lora_paramsdistillation/lora_depth_trainer.py— LoRA training loopconfigs/lora_depth_config.yamlscripts/validate_lora.py— LoRA checkpoint validation
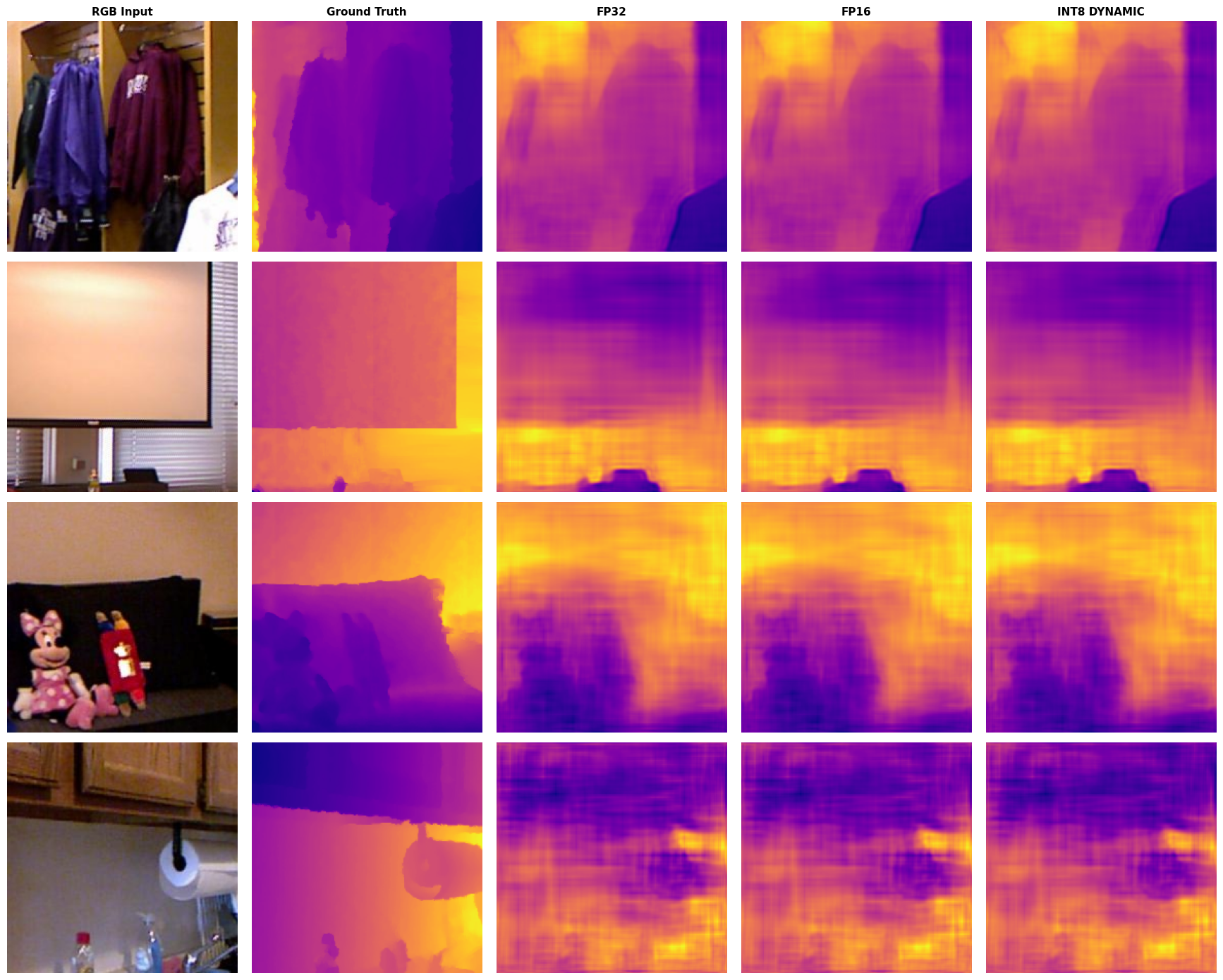
Evaluated depth models at FP32, FP16 (GPU), and Dynamic INT8 (CPU). Reported RMSE, AbsRel, δ1, memory footprint, disk size, and per-image inference latency for each precision level. Visualized depth predictions across precision regimes.
Key deliverables:
scripts/validate_ptq.py— Full PTQ validation pipeline with W&B uploadutils/quantization.py— PTQ utilities (dynamic, static, bitsandbytes)- Per-checkpoint precision tables saved to
logs/ptq_validation/
Four variants of frozen/unfrozen backbone × pretrained/random head, plus the Intel DPT baseline, were benchmarked side-by-side on NYU-Depth V2:
| Experiment | Backbone | DPT Head Init |
|---|---|---|
Intel_dpt_swin_tiny_256 |
Public pretrained Swin-Tiny | Public pretrained DPT |
frozenBase_pretrainedUnfrozenHead |
Frozen distilled | Intel pretrained |
unfrozenBase_pretrainedUnfrozenHead |
Trainable distilled | Intel pretrained |
frozenBase_unfrozenHead |
Frozen distilled | Random init |
unfrozenBase_unfrozenHead |
Trainable distilled | Random init |
Key deliverables:
customization/— One script per experiment + shared utilitiescustomization/validation.py— Side-by-side metric table + depth prediction gridcustomization/run_all_experiments.sh— One-command experiment runner
Strong and weak scaling experiments on NYU H200/H100 clusters via SLURM + torchrun (DDP). Strong scaling holds the total batch size constant while adding GPUs (wall-clock speedup test). Weak scaling holds per-GPU batch constant (throughput test).
| Experiment | GPUs | Per-GPU Batch | Total Batch | LR |
|---|---|---|---|---|
| Baseline | 1 × H200 | 256 | 256 | 8e-4 |
| Strong 2-GPU | 2 × H100 | 128 | 256 | 8e-4 |
| Strong 4-GPU | 4 × H100 | 64 | 256 | 8e-4 |
| Weak 2-GPU | 2 × H100 | 256 | 512 | 1.6e-3 |
| Weak 4-GPU | 4 × H100 | 256 | 1024 | 3.2e-3 |
Key deliverables:
scripts/train_multigpu.s— 4-GPU SLURM job (torchrun, Singularity, H200)scripts/scale_2gpu_strong.s,scale_2gpu_weak.s— 2-GPU scaling scriptsscripts/scale_4gpu_strong.s,scale_4gpu_weak.s— 4-GPU scaling scriptsscripts/submit_scaling.sh— One-command batch submission for all scaling runs
A FastAPI web server that accepts an uploaded image and returns a colorized depth map in real time. Supports FP32, FP16, and INT8-quantized model loading.
Key deliverables:
webapp/app.py— FastAPI serverwebapp/index.html— Browser UI
Efficient-Distillation/
│
├── configs/ # YAML config files for each task
│ ├── distill_config.yaml # ImageNet distillation hyperparameters
│ ├── depth_config.yaml # NYU-Depth V2 + DPT head training
│ ├── lora_depth_config.yaml # LoRA fine-tuning on depth task
│ └── sweeps/
│ └── sweep_base.yaml # W&B hyperparameter sweep config
│
├── data/ # Dataset loaders
│ ├── coco_dataset.py # COCO 2017 dataloader
│ └── nyu_depth_dataset.py # NYU-Depth V2 dataloader + transforms
│
├── distillation/ # Training loops
│ ├── losses.py # Feature (MSE/cosine), AT, KD, task losses
│ ├── trainer.py # ImageNet distillation training loop
│ ├── depth_trainer.py # Depth estimation training loop (SiLog loss)
│ └── lora_depth_trainer.py # LoRA depth training loop
│
├── models/ # Model definitions
│ ├── teacher.py # SwinTeacher (Swin-Large or Swin-Base, frozen)
│ ├── student.py # SwinStudentTiny (~28 M params)
│ ├── adapters.py # FeatureAdapter + SingleStageAdapter (1×1 conv)
│ ├── depth_model.py # StudentWithDPT (frozen backbone + DPT head)
│ ├── dpt_head.py # DPT neck + depth head (from HuggingFace)
│ ├── dpt_head_original.py # Reference original DPT head implementation
│ └── lora.py # LoRALinear, apply_lora, count_lora_params
│
├── finetuning/ # Standalone fine-tuning scripts
│ ├── base_validation.py # Baseline validation before fine-tuning
│ ├── frozenBase_customHead.py # Frozen student + trainable DPT head
│ └── unfrozenBase_customHead.py # Full fine-tuning (student + DPT head)
│
├── customization/ # Milestone 5 experiment suite
│ ├── shared.py # Shared train/val loop, metrics, checkpoint helpers
│ ├── Intel_dpt_swin_tiny_256.py # Intel DPT baseline (inference only)
│ ├── frozenBase_pretrainedUnfrozenHead.py # Exp 1
│ ├── unfrozenBase_pretrainedUnfrozenHead.py # Exp 2
│ ├── frozenBase_unfrozenHead.py # Exp 3
│ ├── unfrozenBase_unfrozenHead.py # Exp 4
│ ├── validation.py # Side-by-side comparison + depth grid
│ ├── batchsize_sweep.py # Batch size sweep utility
│ ├── metrics_guide.py # Depth metric definitions and notes
│ ├── test_rotation.py # Data augmentation sanity check
│ └── run_all_experiments.sh # One-command runner for all 5 experiments
│
├── scripts/ # SLURM scripts + utilities
│ ├── train_multigpu.s # 4-GPU H200 ImageNet distillation (torchrun)
│ ├── scale_2gpu_strong.s # 2-GPU strong scaling (H100)
│ ├── scale_2gpu_weak.s # 2-GPU weak scaling (H100)
│ ├── scale_4gpu_strong.s # 4-GPU strong scaling (H100)
│ ├── scale_4gpu_weak.s # 4-GPU weak scaling (H100)
│ ├── submit_scaling.sh # Submit all scaling jobs at once
│ ├── lora_sequential.sh # Sequential LoRA rank sweep
│ ├── download_nyu_depth.py # NYU-Depth V2 download helper
│ ├── download_imagenet.s # ImageNet SLURM download script
│ ├── sanity_check.py # Forward-pass smoke test (no dataset needed)
│ ├── inspect_checkpoint.py # Print checkpoint contents + param counts
│ ├── validate_lora.py # Validate LoRA checkpoints on NYU-Depth
│ ├── validate_ptq.py # PTQ comparison: FP32 / FP16 / INT8
│ ├── upload_lora_results.py # Upload LoRA metrics to W&B
│ ├── upload_ptq_results.py # Upload PTQ metrics to W&B
│ └── visualize_depth.py # Depth map visualization utility
│
├── utils/ # Shared utilities
│ ├── checkpoint.py # save_checkpoint / load_checkpoint helpers
│ ├── device.py # Device selection, autocast, GradScaler helpers
│ ├── logger.py # Stdout logger setup
│ ├── metrics.py # Top-1/5 accuracy, depth metrics (RMSE, AbsRel, δ)
│ ├── quantization.py # PTQ helpers (dynamic, static, bitsandbytes)
│ └── wandb_logger.py # W&B run initialization
│
├── webapp/ # Interactive depth estimation demo
│ ├── app.py # FastAPI server (upload image → depth map)
│ └── index.html # Browser UI
│
├── train.py # Main entry point — dispatches on cfg["task"]
├── validation.py # Standalone validation script
├── visualize_depth.py # Depth visualization helper (root-level)
├── forwardpass.py # Single forward-pass test
├── test_teacher.py # Teacher model sanity check
├── simple_student_model_check.py # Student architecture check
├── gpu_run.sh # Sync code to remote GPU + run in tmux
├── gpu_setup.sh # One-time remote GPU environment setup
└── requirements.txt # Python dependencies
# Create and activate a Python environment
conda create -n distill python=3.11 -y
conda activate distill
# Install PyTorch (adjust CUDA version as needed)
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
# Install all other dependencies
pip install -r requirements.txtImageNet-1K:
# Download via SLURM (NYU HPC)
sbatch scripts/download_imagenet.s
# Expected layout:
# /path/to/imagenet/
# train/ (1000 class folders)
# val/ (1000 class folders)NYU-Depth V2:
python scripts/download_nyu_depth.py --out_dir data/nyu_depth_v2
# Expected layout:
# data/nyu_depth_v2/
# train/ (RGB + depth HDF5)
# val/# Quick smoke test (no dataset required, 2 batches, W&B disabled)
python scripts/sanity_check.py
# Single-GPU training
python train.py --config configs/distill_config.yaml
# Resume from a checkpoint
python train.py --config configs/distill_config.yaml \
--resume checkpoints/epoch_065.pth
# Override hyperparameters inline
python train.py --config configs/distill_config.yaml \
--override epochs=50 lr=5e-4 feat_loss_type=mse
# Warm-start adapters only (keeps student fresh, avoids NaN on cosine loss)
python train.py --config configs/distill_config.yaml \
--adapter_warm_start checkpoints/epoch_065.pth
# Multi-GPU distillation on NYU HPC (4× H200, via torchrun)
sbatch scripts/train_multigpu.s# Train DPT head on top of the frozen distilled student
python train.py --config configs/depth_config.yaml
# Resume depth training
python train.py --config configs/depth_config.yaml \
--resume checkpoints/depth/epoch_020.pth
# Frozen backbone (edit configs/depth_config.yaml: freeze_student: true)
# Full fine-tuning (edit configs/depth_config.yaml: freeze_student: false)# Train LoRA adapters (rank=4) on frozen student + trainable DPT head
python train.py --config configs/lora_depth_config.yaml
# Resume LoRA training
python train.py --config configs/lora_depth_config.yaml \
--resume checkpoints/lora_depth/epoch_050.pth
# LoRA-only mode: freeze DPT head, only A/B matrices train
# Edit configs/lora_depth_config.yaml: freeze_dpt_head: true
# Sequential rank sweep (r = 2, 4, 8, 16)
bash scripts/lora_sequential.sh
# Validate a LoRA checkpoint
python scripts/validate_lora.py \
--checkpoint checkpoints/lora_depth/best.pth \
--student_checkpoint checkpoints/best.pth \
--nyu_depth_root data/nyu_depth_v2# Full PTQ validation (FP32 + FP16 + Dynamic INT8) on all depth checkpoints
python scripts/validate_ptq.py \
--checkpoints_dir checkpoints/customization \
--nyu_depth_root data/nyu_depth_v2 \
--student_checkpoint checkpoints/best.pth \
--output_dir logs/ptq_validation \
--wandb --wandb_project depth-ptq
# Quick test (2 batches per precision, skip INT8)
python scripts/validate_ptq.py \
--checkpoints_dir checkpoints/customization \
--nyu_depth_root data/nyu_depth_v2 \
--student_checkpoint checkpoints/best.pth \
--max_val_batches 2 --skip_int8
# Save FP16 and INT8 model files for deployment
python scripts/validate_ptq.py \
--checkpoints_dir checkpoints/customization \
--nyu_depth_root data/nyu_depth_v2 \
--student_checkpoint checkpoints/best.pth \
--save_quantized --output_dir logs/ptq_validation# Run all 5 experiments in sequence (Intel baseline + 4 frozen/unfrozen variants)
bash customization/run_all_experiments.sh # 30-epoch quick run
bash customization/run_all_experiments.sh --epochs 300 # Full run
# Run individual experiments
python customization/Intel_dpt_swin_tiny_256.py \
--nyu_root data/nyu_depth_v2
python customization/frozenBase_pretrainedUnfrozenHead.py \
--student_checkpoint checkpoints/best.pth \
--nyu_root data/nyu_depth_v2 --epochs 30
python customization/unfrozenBase_pretrainedUnfrozenHead.py \
--student_checkpoint checkpoints/best.pth \
--nyu_root data/nyu_depth_v2 --epochs 30
python customization/frozenBase_unfrozenHead.py \
--student_checkpoint checkpoints/best.pth \
--nyu_root data/nyu_depth_v2 --epochs 30
python customization/unfrozenBase_unfrozenHead.py \
--student_checkpoint checkpoints/best.pth \
--nyu_root data/nyu_depth_v2 --epochs 30
# Side-by-side comparison across all experiment checkpoints
python customization/validation.py \
--student_checkpoint checkpoints/best.pth \
--nyu_root data/nyu_depth_v2 \
--out_dir checkpoints/customization# Submit all scaling experiments at once
bash scripts/submit_scaling.sh
# Submit individual scaling jobs
sbatch scripts/scale_2gpu_strong.s # 2-GPU strong scaling (total batch = 256)
sbatch scripts/scale_2gpu_weak.s # 2-GPU weak scaling (per-GPU batch = 256)
sbatch scripts/scale_4gpu_strong.s # 4-GPU strong scaling
sbatch scripts/scale_4gpu_weak.s # 4-GPU weak scaling
# Monitor running jobs
squeue -u $USER# Start the depth estimation server (FP32)
python webapp/app.py \
--checkpoint checkpoints/customization/frozenBase_pretrainedUnfrozenHead/best.pth \
--student_checkpoint checkpoints/best.pth \
--device cuda --port 8000
# Serve a quantized FP16 model
python webapp/app.py \
--checkpoint logs/ptq_validation/<timestamp>/best_fp16.pth \
--quantized --device cuda --port 8000
# Serve a dynamic INT8 model (CPU only)
python webapp/app.py \
--checkpoint logs/ptq_validation/<timestamp>/best_int8_dynamic.pth \
--quantized --device cpu --port 8000
# Access via SSH tunnel from your laptop:
ssh -J ag11023@torch-login-a-2 -L 8000:localhost:8000 ag11023@gh117
# Then open http://localhost:8000# Inspect a checkpoint (parameter counts, keys, epoch, best metric)
python scripts/inspect_checkpoint.py checkpoints/best.pth
# Visualize depth predictions
python scripts/visualize_depth.py \
--checkpoint checkpoints/customization/frozenBase_pretrainedUnfrozenHead/best.pth \
--student_checkpoint checkpoints/best.pth \
--nyu_depth_root data/nyu_depth_v2
# Upload LoRA results to W&B
python scripts/upload_lora_results.py \
--results_dir logs/lora_validation \
--wandb_project efficient-distillation
# Upload PTQ results to W&B
python scripts/upload_ptq_results.py \
--results_dir logs/ptq_validation \
--wandb_project depth-ptq-validation| Parameter | Default | Description |
|---|---|---|
teacher_variant |
swin_large |
swin_large (~197 M) or swin_base (~88 M) |
student_pretrained |
false |
Random init — demonstrates learning from scratch |
adapter_stages |
[0,1,2,3] |
Stages with feature adapters |
feat_loss_type |
cosine |
cosine (scale-invariant) or mse |
w_feat |
2.0 |
Feature-level loss weight |
w_at |
1.0 |
Attention Transfer loss weight |
w_kd |
1.0 |
Logit KD loss weight |
temperature |
4.0 |
KD softmax temperature (τ) |
lr |
8e-4 |
Peak LR (AdamW, scaled for batch size 256) |
epochs |
100 |
Training epochs |
amp |
true |
Mixed-precision (FP16) |
compile |
true |
torch.compile student + adapter (~20% speedup) |
| Parameter | Default | Description |
|---|---|---|
lora_r |
4 |
LoRA rank |
lora_alpha |
1.0 |
Scaling factor (effective scale = α/r = 0.25) |
lora_target_modules |
["qkv"] |
Attention layers to adapt |
freeze_dpt_head |
false |
If true, only LoRA A/B matrices train |
| Component | Parameters | Trainable During Training |
|---|---|---|
| Swin-Large (teacher) | ~197 M | 0 (fully frozen) |
| Swin-Tiny (student) | ~28 M | ~28 M |
| Feature Adapters (4 stages) | ~2 M | ~2 M |
| DPT Depth Head | ~30 M | ~30 M (or 0 if frozen) |
| LoRA adapters (r=4, all QKV) | ~0.5 M | ~0.5 M |
Training was performed on NYU Torch HPC using SLURM with Singularity containers (CUDA 12.2). The virtual environment is managed with uv and pinned to Python 3.11.
torch >= 2.1.0
torchvision >= 0.16.0
timm >= 0.9.12
transformers >= 4.40.0
wandb >= 0.17.0
All experiments are logged to Weights & Biases under the project efficient-distillation (entity: ag11023-new-york-university).
Here are some of the results we obtained by running the Depth head over the best performing model (Dataset - NYU-Depth V2)