Questions regarding Panther's usage #2
Comments
|
Apologize for the delayed response.
Sample output: The above record was in the first line (id 0), and the D similar records are: 0, 505748, 1, 157140.... |
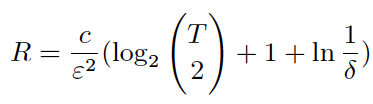
|
Would it be possible to provide pointers to Rolde Detection, Role Clustering, or Role Discovery? I would like to focus more on that front since that is what RoleSim is for. |
|
I am afraid this is not the problem that Panther was supposed to resolve. |
|
If that is the case then do you know of any RoleSim replacements or alternatives? Would Vertex Similarity be similar to Link Prediction? |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
The text was updated successfully, but these errors were encountered: