Training an Ocropus OCR model 中文
上一篇文章Extracting text from an image using Ocropus 使用Ocropus从图片中提取文本,我们了解了 Ocropus OCR 处理的过程.从如下的图片中提取到文字:

使用默认的模型得到的结果说得过去但不是很理想:
O1inton Street, aouth from LIYingston Street.
Auguat S, 1934.
P. L. Sperr.
NO REPODUCTIONS.
对于larger corpus 中的图片,识别错误率大约在10%左右。默认模型没有遇到过打印字体,也没用处理过ALLCAPS 文本,而在这个语料库里却占了相当的比重。因此识别的准确率低是理所应当的。
这篇文章我会介绍如何训练一个Ocropus 模型来识别我们的图片语料库中的印刷体文本。文章的最后,可以看到识别的效果特别好
Ocropus 使用supervised learning方法来训练模型:需要一行行的文本图片外加正确的文本。如果你试图识别一种已知的字体,你可以使用ocropus-linegen生成任意数量的标记数据。但在我们的案例中,必须手动标记图片。
标记工作是很冗长的,需要进行大量的输入。亚马逊的Mechanical Turk适合此类任务,但我们更倾向于使用localturk手动完成。
耗时并不像你所想像的那么夸张,我输入了800行花了大约1小时二十分钟。同时标记工作的好处在于你不得不浏览大量的数据样本,也能帮助你更好的理解数据。
(localturk in action)

我使用该模板来完成转录。 Ocropus 要求真实数据保存在后缀为 .gt.txt的文件,且和原始PNG图片同名,比如:
book/0001/010001.pngbook/0001/010001.gt.txt
你只转录单行文本,而非整个页面是很重要的。最开始我是转录的整个页面。想让 Ocropus 学习这些页面,但根本行不通。
Ocropus trains a model by learning from its mistakes. It transcribes the text in a line, then adjusts the weights in the Neural Net to compensate for the errors. Then it does this again for the next line, and the next, and so on. When it gets to the last line of labeled data, it starts over again. As it loops through the training data over and over again, the model gets better and better.
ocropus-rtrain -o modelname book*/????/*.bin.png
This produces lots of output like this:
2000 70.56 (1190, 48) 715641b-crop-010002.png
TRU: u'504-508 West 142nd Street, adjoining and west of Hamilton'
ALN: u'504-5088 West 422nd Street, adjoining and west of Hammilton'
OUT: u'3od-iS est 4nd Street, doning nd est of Sarilton'
2001 32.38 (341, 48) 726826b-crop-010003.png
TRU: u'NO REPRODUCTIONS'
ALN: u'NO REPRODUCTIONS'
OUT: u'sO EROCoOri'
...
TRU is the truth data. OUT is the output of the model. ALN is a variant of the model output which is aligned to the truth data. It's used to adjust the model weights more precisely. It typically looks better than the model output, especially in early iterations. It lets you know that you're making progress.
Here's a video that Thomas, the Ocropus developer, put together. It shows the network's output for a single image as it learns (see the YouTube page for explanations of the different charts):
For my first model, I used 400 of the labeled lines as training data and held out the other 400 as test data. Ocropus saves models to disk every 1000 iterations, so it's simple to evaluate the model's performance as it learns:
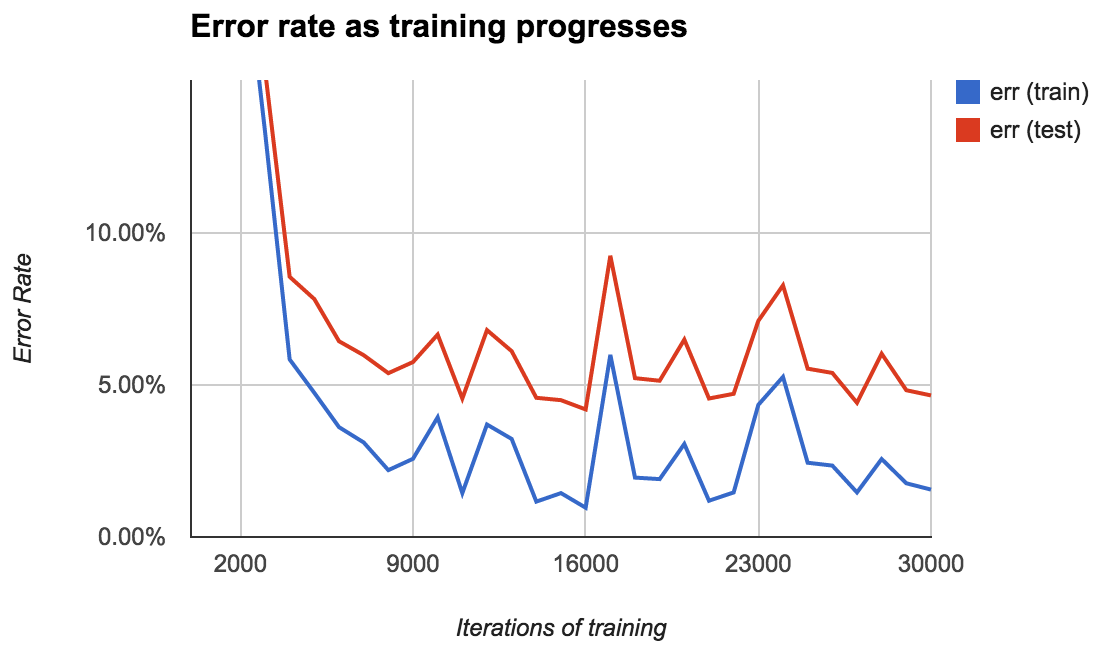
The error rate starts high (over 50%) but quickly comes down to about 2% after 10,000 iterations, eventually hitting a minimum of 0.96% at 16,000 iterations.
The error rate on the test set is consistently about 3% higher than that on the training set. The best error rate on the test set was 4.20%.
There's a lot of variation in the error rate. You might expect it to slowly decrease over time, but that's not at all the case. I'm not quite sure how to interpret this. Does the error rate spike at 17,000 iterations because the model tries to jolt itself out of a local minimum? Is it just randomness?
In any case, it's important to generate a chart like this. Choosing the wrong model could lead to needlessly bad performance.
You'd expect that training on more data would yield a better model. So for my next model, I trained on all 800 labeled images (rather than just 400). I didn't have a test set. Here's what the error rate looked like:
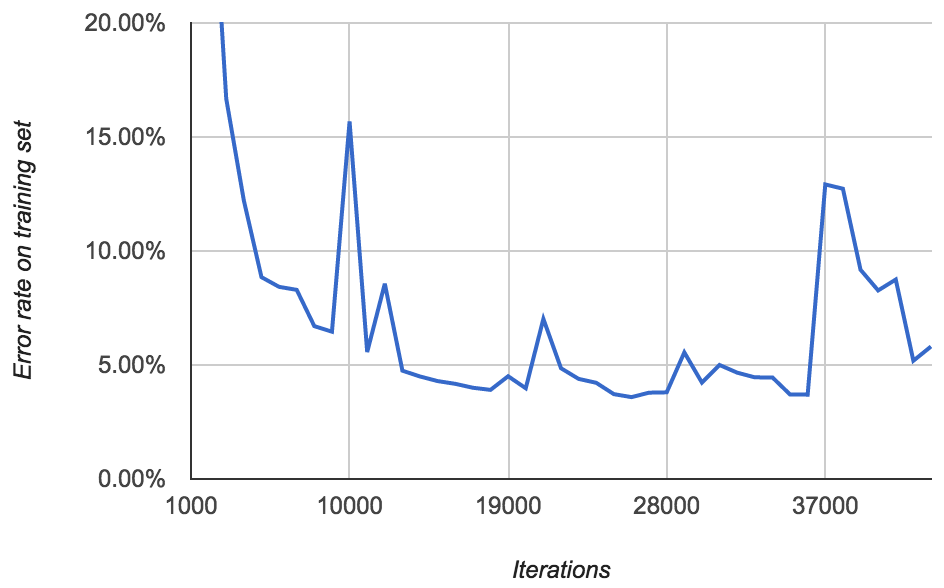
This doesn't make much sense to me. The lowest error rate on the 800 training images is 3.59%. But the model from the previous section achieved an error rate of 2.58% on the same data set (average of 0.96% and 4.20%). And it only saw half the data! How is that possible? Maybe this model just had bad luck.
There's the same pattern as before of occasional spikes in error rate. More disturbing, after around 40,000 iterations, I started seeing lots of FloatingPointErrors. It's unclear to me exactly what this means. Perhaps the model is diverging?
Here's another model that I trained for even longer:
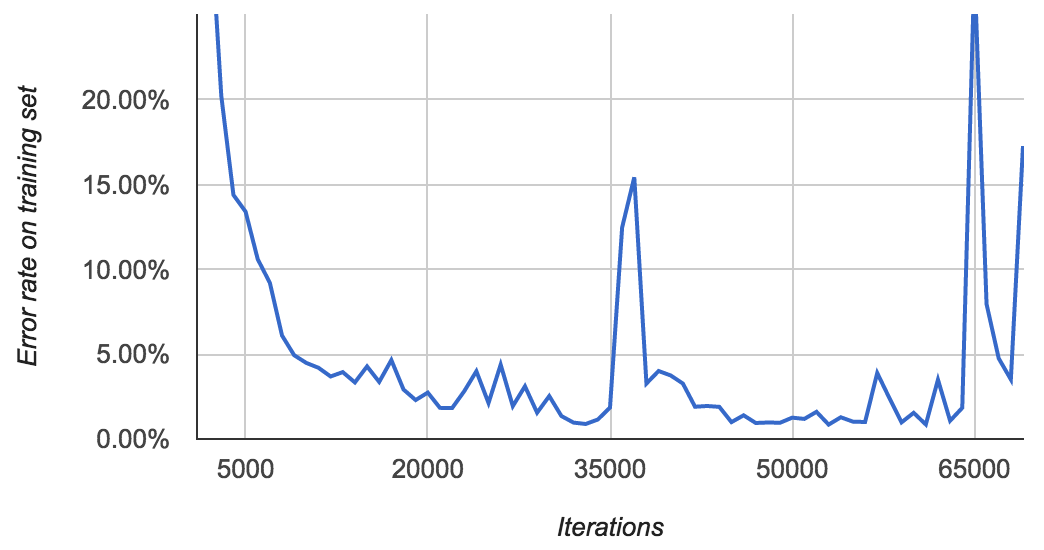
It achieves an error rate of 0.89% at iteration 33,000, then spikes to over 15% at 37,000. It eventually gets back down to 0.85% after 53,000 iterations, then starts spiking again. By the time I stopped it, I was again seeing lots of FloatingPointErrors.
The point of all this is that the error rates are quite erratic, so you need to look at them before choosing which model you use!
So far we've built our models from scratch. But you can also build on top of an existing model.
Even though it's never seen typewriter text or ALLCAPS, the default Ocropus model presumably knows a lot about Latin characters and the relationship between them in English words. And I trust the Ocropus developers to build a good Ocropus model far more than I trust myself.
You train on top of an existing model using the --load option:
ocropus-rtrain --load en-default.pyrnn.gz -o my-model *.png
Here's what the error rate looks like:
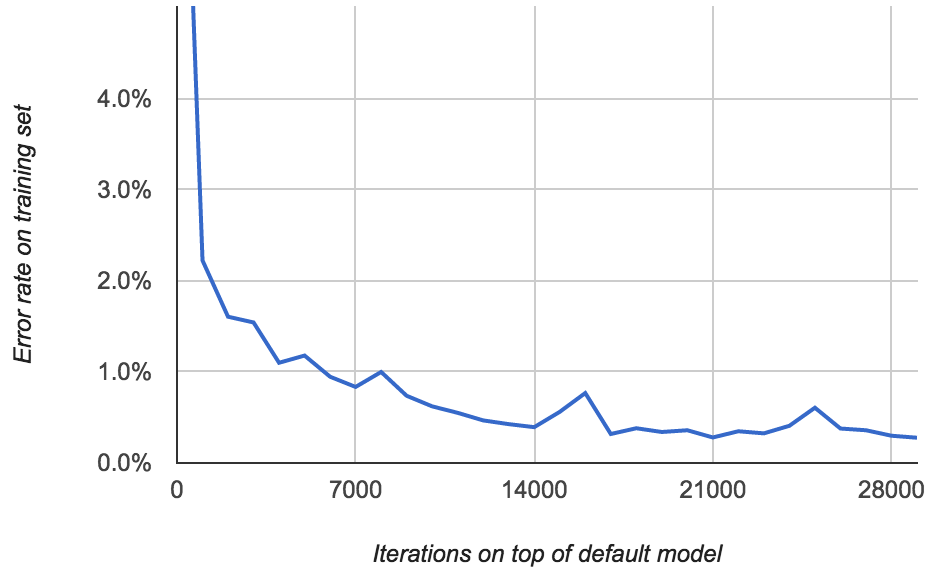
Now we're getting somewhere: the error rate gets all the way down to 0.277%!
Something interesting happens when you get the error rate significantly below 1%. The "mistakes" that the model makes are quite likely to be errors that you made while transcribing truth data! I noticed that I misspelled some words and even hallucinated new words like "the" into some of the lines.
Even crazier, there were typos in the original images that I subconsciously corrected:
(Look at the second to last word.)
A model with a 0.2% error rate is good enough to produce readable text. For example, here's what it produces for the image from the last post:
→ Clinton Street, south from Livingston Street.
→ P. L. Sperr.
→ NO REPRODUCTIONS.
→ August 5, 1934.


i.e. it's perfect. Here's the output of the Neural Net for the last line:
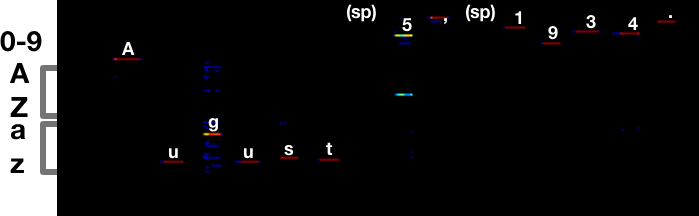
Compare that to what it was before:
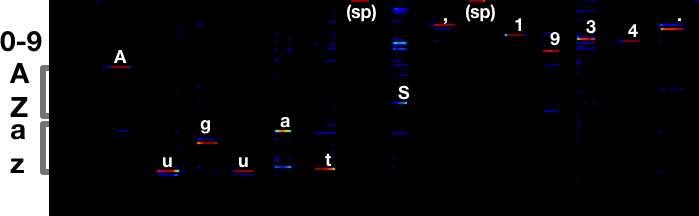
There's still some ambiguity around 5/S, but it makes the right call. The a vs s error is completely gone.
At this point the model is good enough. If I were to improve it further, I'd either improve my image cropper or incorporate some kind of spell checking as a post-processing step.
The behavior of the models as they're trained is sometimes inscrutable. Finding a good one involves a lot of trial and error. To avoid flailing, measure your performance constantly and keep a list of ideas to explore. "Train a model starting with the pre-built one" was item #6 on my list of ideas and it took me a while to get around to trying it. But it was the solution!
If you're feeling lost or frustrated, go generate some more training data. At least you'll be doing something useful.
At the end of the day, I'm very happy with the OCR model I built. Ocropus has some rough edges, but it's simple enough that you can usually figure out what's going on and how to fix problems as they come up. And the results speak for themselves!