Further reduce runtime #3
Description
A full run of the P2A rule engine (for 10km downscaled climate data) for a region clocks in at about 19 minutes, waaaaay too long.
The profiling shows that (appropriately) most of the compute time is spent pulling data out of NetCDF files and calculating statistics.
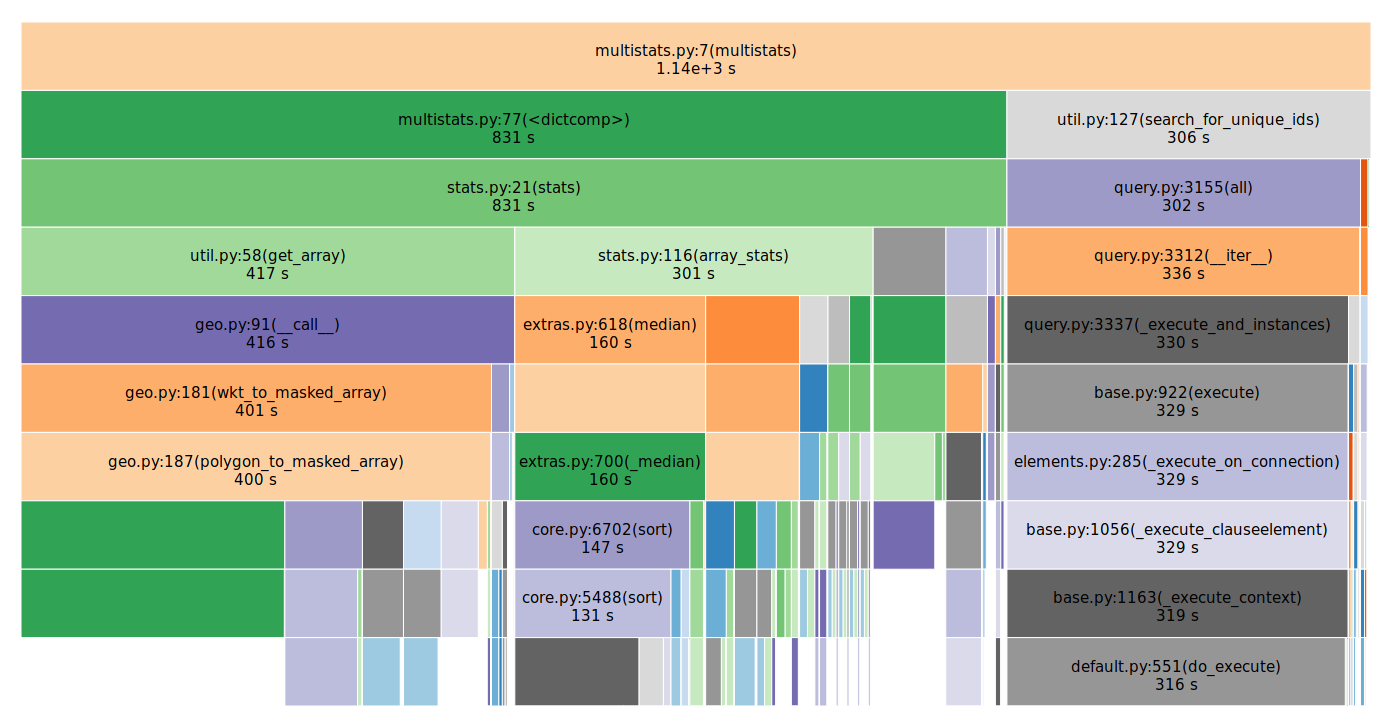
But there are several ways to potentially provide some further performance gains:
- Precompute percentiles of ensembles of models
- The engine uses lots of rules like 25th/75th percentiles, so rather than querying 10+ models and then computing it in real time, this step can be done in advance. Could reduce runtime by 90%.
- These ensemble statistics could be made available by the
climate-explorer-backend.
- Grouping queries to like files together
- 35% of the total runtime is pulling data out of files. If there are multiple reads to the same file, group these together to take advantage of OS filesystem caching
- Only compute stats that are needed
- This will require an API change (additional parameter to the stats/multistats calls), but the fact that 25% of the computation is computing stats, and each stats call returns 5 different stats, if we only use one of them, there's a potential for a 20% speedup here.
- Optimize
multistatsqueries forsearch_for_unique_ids.- This is fully 26% percent of the run time and I can't see a good reason why those queries would take so long. Again, this has to happen in the
climate-explorer-backend
- This is fully 26% percent of the run time and I can't see a good reason why those queries would take so long. Again, this has to happen in the