좋아, 이제 시작할 때다! 만약 네가 소개글을 읽지 않고 넘겨버리는 끔찍한 부류의 인간이라해도, 어쨌든 소개글의 마지막 섹션을 읽고 싶어하게 될 거야. 왜냐하면 이 튜토리얼을 따라오기 위해 필요한 것들에 대한 설명과, 함수를 어떻게 하면 불러올 수 있는 지에 대한 설명이 거기에 다 있거든. 우리가 여기서 처음으로 하게 될 것은 ghc의 상호작용 모드를 실행하는 것과, haskell에 대한 기본적인 감각을 느낄 수 있는 몇몇 함수들을 호출해보는 거야. 터미널 창을 열고 ghci라고 쳐봐. 아마 아래와 같은 환영 문구를 볼 수 있을 거야.
GHCi, version 6.8.2: http://www.haskell.org/ghc/ :? for help
Loading package base ... linking ... done.
Prelude> 축하해. 너는 GHCI 안에 들어왔어! 여기서 프롬프트는 Prelude> 지만 이 이름이 세션 내용에 집중하기 힘들게 만들 수 있기 때문에, 앞으로 우리는 ghci> 라는 이름을 이용할 거야. 만약 자료와 똑같은 프롬프트를 사용하고 싶다면 :set prompt "ghci> "라고 치면 돼.
여기 몇 가지 단순한 산술식 예제가 있어.
ghci> 2 + 15
17
ghci> 49 * 100
4900
ghci> 1892 - 1472
420
ghci> 5 / 2
2.5
ghci>이 건 너무 뻔하지. 물론 한 줄에 여러 개의 연산자를 이용할 수도 있고, 일반적인 연산의 우선순위들도 적용돼. 연산 우선순위를 바꾸기 위해서 괄호를 이용할 수 있어.
ghci> (50 * 100) - 4999
1
ghci> 50 * 100 - 4999
1
ghci> 50 * (100 - 4999)
-244950 깔끔하지? 흠, 사실 나는 이게 깔끔하지 않다는 걸 알아. 잘 들어봐. 여긴 주의해야할 작은 위험이 있는데, 그건 바로 음수야. 음수를 다룰 때에는 항상 음수를 괄호로 싸는게 좋아. 5* -3과 같은 수식은 GHCI가 경고를 할테지만, 5 * (-3)은 정상적으로 동작할거야.
부울 대수(Boolean Algebra)도 굉장히 직관적이야. 네가 이미 알고 있다시피, &&는 and를, ||는 or를 의미해. not은 True 또는 False의 부정을 의미하고.
ghci> True && False
False
ghci> True && True
True
ghci> False || True
True
ghci> not False
True
ghci> not (True && True)
False 두 값이 서로 같은지에 대한 비교도 이와 비슷해.
5+"llama" 나 5 ==True와 같은 연산은 어떻게 동작할까? 음, 첫 번째 식을 실행하면 우리는 굉장히 끔찍한 에러 메시지를 보게 될거야!
No instance for (Num [Char])
arising from a use of `+' at <interactive>:1:0-9
Possible fix: add an instance declaration for (Num [Char])
In the expression: 5 + "llama"
In the definition of `it': it = 5 + "llama" 으악! 여기서 GHCI가 말하고자 하는 건 "llama"는 숫자가 아니고, 그래서 이걸 어떻게 5랑 더해야될 지 모르겠다는 거야. 이게 "llama"가 아니라 "four"나 "4"라도 마찬가지야. Haskell은 그게 숫자가 될 수 있는 지 고려하지 않아. + 연산자는 좌변과 우변에 숫자가 올거라고 예측해. True == 5 라는 수식을 실행할 경우에는, GHCI는 우리에게 두 개의 타입이 일치하지 않는다고 말할거야. + 연산자가 숫자로 고려할 수 있는 것들에 대해서만 동작한다면, == 연산자는 서로 비교될 수 있는 두 개체에 대해서만 동작해. 그러나 문제가 되는 건 두 개가 서로 같은 타입의 개체여야만 한다는 거지. 너는 사과와 오렌지를 비교할 수 없어. 우리는 타입에 대해서 조금 더 있다가 살펴보게 될거야. 알아둘건, 5 + 4.0은 가능하다는 거야. 왜냐하면 5는 교활해서 정수처럼도, 부동소수점처럼도 행동할 수 있기 때문이지. 4.0은 정수처럼 행동할 수 없고, 따라서 이 경우 5는 부동소수점으로 다뤄지게 돼.
굳이 알 필요는 없지만, 우리가 지금까지 써온 것들은 전부 함수야. 예를 들어서, *는 두 개의 숫자를 받아서 그 둘을 곱한 결과를 돌려주는 함수지. 위에서 본 것처럼, 우리는 이걸 두 숫자 사이에 놓음으로써 호출할 수 있어. 우리는 이런걸 중위(infix) 함수라고 부르지. 숫자와 같이 사용하지 않는 대부분의 함수들은 전위(prefix) 함수야. 이제 이것들을 살펴보자고.
함수는 종종 전위(prefix)적으로 사용되고 따라서 이제부터 따로 명시하지 않는 한 함수는 전위 함수를 말하는 거라고 가정하자. 대부분의 명령형 언어에서 함수는 함수 이름을 쓰고, 콤마로 구분되는 함수의 인자를 이어지는 괄호 안에 쓰는 걸 통해 호출되지. Haskell에서, 함수는 함수 이름을 쓰고, 그 뒤에 공백과 공백으로 구분되는 인자들을 순서대로 씀으로써 호출돼. 처음이니까, 우리는 Haskell에서 가장 지루한 함수 중 하나를 호출해볼거야.
ghci> succ 8
9succ 함수는 successor가 정의된 어떤 것을 받아 그 successor를 돌려줘. 위에서 봤듯이, 단지 공백만으로 함수의 이름과 인자를 구분해. 여러 개의 인자를 가진 함수의 호출도 마찬가지로 단순해. min 함수와 max 함수는 정렬될 수 있는 두 개의 인자를 받지(숫자 같은 것들 말이야!). min은 더 작은 것, max는 더 큰 것을 돌려줘. 직접 확인해봐.
ghci> min 9 10
9
ghci> min 3.4 3.2
3.2
ghci> max 100 101
101 함수 적용(함수 이름을 적고 공백과 함께 함수의 인자들을 입력하여 함수를 호출한 것)은 모든 것들 중에서 가장 높은 우선순위를 가져. 그 말은, 아래의 두 문장이 동일한 뜻이라는 거야.
ghci> succ 9 + max 5 4 + 1
16
ghci> (succ 9) + (max 5 4) + 1
16 하지만, 우리가 9와 10의 곱의 successor를 얻고 싶다면, succ 9*10 이라고 쓰면 안 돼. 왜냐하면 이건 9의 successor를 가져온 다음, 10과 곱해서 100을 돌려주기 때문이지. 91이라는 결과를 얻기 위해서는 succ (9*10)이라고 써야돼.
만약 함수가 두 개의 인자를 취한다면, 우리는 이걸 backtick(`)으로 감싸는 것을 통해 중위(infix) 함수로 호출할 수 있어. 예를 들어, div 함수는 두 개의 정수를 취하고 그 둘을 나눈 몫을 돌려줘. div 92 10은 결과로 9를 돌려주지. 하지만 이렇게 호출하면, 어떤게 나누는 수이고 어떤게 나눠지는 수인지 약간 혼란이 있을 수가 있어. 그래서 우리는 이걸 92 `div` 10 과 같은 식으로 중위(infix) 함수로 호출할 수 있고, 이게 훨씬 명확하지.
명령형 언어를 배우다 온 사람들은 함수 호출에서 괄호를 사용하는 표기법에 집착하는 경향이 있어. 예를 들자면, C언어에서는 함수를 호출하기 위해 foo(), bar(1), 또는 baz(3, "haha")와 같이 쓰지. Haskell에선 함수를 쓸 때 단순히 공백만 사용해. 따라서 위와 같은 함수들은 foo, bar 1, 그리고 baz 3 "haha"와 같이 써서 호출되지. 따라서 bar (bar 3)이라고 쓰인 코드는, bar이 bar과 3이라는 두 개의 인수를 이용해 호출되는게 아니라, 먼저 bar과 3을 이용해 함수를 호출해 그 결과로 다시 bar을 호출한다는 거야. C로 따지자면 bar(bar(3))과 같지.
이전 섹션에서 우리는 함수를 호출하는 방법에 대해 기본적인 감을 익혔지. 이제는 우리만의 함수를 만들어 볼 차례야! 네가 좋아하는 텍스트 편집기를 켜고 숫자 하나를 받아 두 배로 늘려서 돌려주는 아래 함수를 타이핑해봐.
doubleMe x = x + x 함수는 호출하는 방식과 비슷한 방식으로 정의해. 함수의 이름, 그리고 그 뒤에 함수가 받는 인자들이 공백을 기준으로 분리되어 뒤따라 나오지. 하지만 정의를 할 때는, 우리가 정의하고자 하는 함수 뒤에 = 기호가 붙어. 방금 작성한 걸 baby.hs, 혹은 아무거나 마음에 드는 이름으로 저장해봐. 그리고 해당 파일이 저장된 곳에서 ghci를 실행시켜봐. ghci에서 :l baby 라고 타이핑하면 네가 작성한 스크립트가 불러와지고,우린 이제 우리가 정의한 함수를 갖고 놀 수 있지.
ghci> :l baby
[1 of 1] Compiling Main ( baby.hs, interpreted )
Ok, modules loaded: Main.
ghci> doubleMe 9
18
ghci> doubleMe 8.3
16.6 + 연산자는 정수 뿐만 아니라 부동소수점, 그리고 숫자와 유사하게 다뤄질 수 있는 어떤 개체에 대해서도 잘 동작하기 때문에, 우리의 함수는 어떤 숫자에 대해서도 잘 동작해. 이제 두 개의 숫자를 받아서 두 숫자 각각을 2배로 늘린 뒤 둘을 더하는 함수를 만들어 보자.
doubleUs x y = x*2 + y*2 간단하지. 우리는 이걸 doubleUs x y = x + x + y + y 라고 정의할 수도 있어. 함수의 동작 결과는 굉장히 뻔하겠지. 테스트해보기 위해선 위 함수를 baby.hs 파일의 맨 뒤에 덧붙이고, 저장한 다음 GHCI에서 다시 :l baby 명령을 타이핑하면 돼.
ghci> doubleUs 4 9
26
ghci> doubleUs 2.3 34.2
73.0
ghci> doubleUs 28 88 + doubleMe 123
478 눈치챘겠지만, 만들고자 하는 함수의 정의 부분 내에서도 함수를 호출할 수 있어. 그걸 염두에 두면, 우리는 doubleUs를 아래와 같이 정의할 수 있지.
doubleUs x y = doubleMe x + doubleMe y 이게 Haskell에서 일반적으로 접할 수 있는 패턴의 가장 간단한 예제야. 명백히 올바른(correct) 기본적인 함수들을 만든 다음, 그것들을 결합해서 더 복잡한 함수들을 만드는 거지. 이 방법을 통해 반복도 피할 수 있어. 만약에, 어떤 수학자가 2랑 3이 알고보니 똑같은 숫자였다는 증명을 해냈다고 치자. 그럼 우리는 우리 프로그램을 어떻게 수정해야할까? 그냥 doubleMe 함수만 x + x + x라는 결과를 돌려주도록 수정하면 돼. 왜냐하면 doubleUs 함수는 doubleMe 함수를 호출해서 동작하고, 따라서 이 2랑 3이 똑같은 이상한 세계에서도 잘 동작하도록 자동으로 수정되거든.
Haskell에서 함수는 어떤 특정한 순서를 갖고 있지 않아. 그래서 doubleMe 함수를 먼저 선언하고 doubleUs 함수를 선언하나 그 반대로 선언하나 별 상관은 없어.
이제 숫자에 2를 곱하되, 그 숫자가 100이하일 때만 2를 곱해주는 함수를 만들어볼 차례야. 왜냐하면 100을 넘는 숫자는 이미 춧분히 큰 숫자거든!
doubleSmallNumber x = if x > 100
then x
else x*2 이제 Haskell의 if 문(if statement)를 소개할 차례야. 아마 다른 언어에서의 if 문과 이미 상당히 친숙하리라고 생각해. Haskell에서의 if문과 명령형 언어에서의 if문의 차이는, Haskell에서는 if문의 else 부분을 생략할 수 없다는 거야. 명령형 언어에서는 조건이 만족되지 않으면 많은 명령을 생략하고 넘어갈 수 있지만, Haskell에서는 모든 표현식과 함수가 반드시 뭔가를 돌려줘야만 해. 또 if문을 한 줄에 모두 다 쓸 수 있고 난 이게 더 가독성이 좋다고 생각해. Haskell의 if문에 대한 또다른 특징은, 이게 표현식(expression)이라는 거야. 표현식은 기본적으로 값을 돌려주지. 5는 5라는 값을 돌려주기 때문에 표현식이고, 4+8은 x+y가 x와 y의 합을 돌려주는 표현식이기 때문에 마찬가지로 표현식이야. Haskell의 if문에서 else 부분은 필수적이고, 따라서 if문은 항상 뭔가를 돌려주기 때문에 역시 마찬가지로 표현식이야. 우리가 아까 만든 함수에서 나온 결과에서 항상 1을 더해 돌려주는 함수를 만든다고 해보자. 그럼 아래와 같은 방식으로 정의할 수 있을거야.
doubleSmallNumber' x = (if x > 100 then x else x*2) + 1 만약 괄호를 빼먹는 다면 x가 100보다 크지 않을 때만 1을 더하게 될거야. 함수 이름의 끝에 '이 붙어있는 걸 봐봐. 아포스트로피(apostrophe, ') 기호는 Haskell의 구문에서 특별한 의미를 갖고 있지 않아. 함수 이름에서 사용가능한 문자지. 보통의 경우 함수의 좀 더 엄격한 버젼(게으르지(lazy) 않은 것)이나 살짝 수정된 버젼의 함수, 변수를 나타내기 위해 ' 기호를 사용해. ' 기호가 함수에서 사용가능한 문자기 때문에 함수를 아래와 같은 방식으로도 만들 수 있어.
conanO'Brien = "It's a-me, Conan O'Brien!" 이 함수에서 두가지 명심해둘만한 것이 있어. 첫 번째는 함수의 이름에서 우리는 Conan의 이름을 대문자로 시작할 수 없다는 거야. 왜냐하면 함수의 이름은 대문자로 시작할 수 없거든. 이 점에 대해선 나중에 다시 살펴볼거야. 두 번째는 이 함수는 어떤 인자도 취하지 않는다는 거야. 우리는 이걸 보통 정의(definition) 또는 *이름(name)*이라고 불러. 이름(과 함수)이 뭘 의미하는 지를 한 번 정의하고 나면 바꿀 수 없기 때문에, conanO'Brien과 "It's a-me, Conan O'Brien!" 문자열은 서로 교환되어 사용될 수 있지.
실세계에서의 쇼핑 리스트와 유사하게, Haskell에서 리스트(list)는 매우 유용해. 리스트는 가장 많이 사용되는 자료구조이고, 수없이 많은 문제들을 풀고 모델링하는데 있어 굉장히 다양한 방식으로 사용될 수 있지. 리스트는 정말 멋져. 이 섹션에서 우리는 리스트의 기본과 문자열(문자열도 리스트야), 그리고 조건제시형 리스트(list comprehension)에 대해 살펴 볼 거야.
Haskell에서, 리스트는 동일한 타입의 원소들을 담는(homogenous) 자료구조야. 무슨 뜻이냐면 정수들의 리스트나 문자들의 리스트를 만들 순 있지만 몇 개의 정수와 몇 개의 문자를 가지는 리스트는 만들 수 없다는 거야.
우리는 GHCI에서 이름(name)을 정의하기 위해 let 키워드를 사용할 수 있어. GHCI에서 let a = 1 이라고 타이핑 하는 건 스크립트에서 a=1이라고 쓰고 그걸 불러오는 것과 똑같아.
ghci> let lostNumbers = [4,8,15,16,23,42]
ghci> lostNumbers
[4,8,15,16,23,42] 위 코드에서 볼 수 있듯이, 리스트는 대괄호와 콤마(,)로 분리되는 리스트의 값들로 표현돼.만약 [1,2,'a',3,'b','c',4]같은 리스트를 만들려고 한다면, Haskell은 문자(Haskell에서 문자는 곁따옴표 사이의 문자로 표현됨)는 숫자가 아니라고 항의할 거야. 문자에 대해 좀 얘기해보자면, 문자열은 문자의 리스트일 뿐이야. "hello"는 ['h','e','l','l','o']를 편하게 축약해서 쓴 거지. 문자열도 리스트기 때문에 문자열에 대해서도 리스트에 관련된 함수들을 쓸 수 있고, 이게 굉장히 편리해.
두 개의 리스트를 하나로 합치는 건 흔히 있는 일이지. 이럴 땐 ++연산자를 사용하면 돼.
ghci> [1,2,3,4] ++ [9,10,11,12]
[1,2,3,4,9,10,11,12]
ghci> "hello" ++ " " ++ "world"
"hello world"
ghci> ['w','o'] ++ ['o','t']
"woot" 길이가 긴 문자열에 대해 ++ 연산자를 반복적으로 사용할 땐 주의해야 돼. 두 개의 문자열을 하나로 합칠 때([1,2,3] ++ [4]처럼 리스트 맨 뒤에 원소가 하나인 리스트를 덧붙일 때에도), 내부적으로 Haskell은 ++ 연산자의 왼쪽 편(left side)를 모조리 훑어 봐. 크기가 작은 리스트들을 다룰 땐 별 문제가 아닌데, 500만 개의 원소를 가진 리스트의 맨 뒤에 원소를 하나 덧 붙인다고 하면 아마 시간이 꽤 걸릴거야. 반면에, 리스트의 맨 앞에 어떤 원소를 집어넣을 땐 : 연산자(cons 연산자라고 불러)를 사용하는 편이 속도가 빨라.
++ 연산자가 두 개의 리스트를 취하는 반면 : 연산자는 어떻게 숫자와 숫자들의 리스트, 혹은 문자와 문자들의 리스트를 취하는 지 주의해서 봐봐. ++ 연산자를 이용할 경우에는 리스트 맨 뒤에 원소를 하나만 추가하려는 경우에도, 대괄호를 이용해 해당 원소를 감싸서 리스트로 만들어줘야만 하지.
[1,2,3]은 실제로는 1:2:3:[]의 간단한 표현(syntactic sugar)이야. []은 텅 빈 리스트지. 우리가 이 앞에 3을 덧붙이면, 이건 [3]이 돼. 그 앞에 2를 붙이면 [2,3]이 되고, 그렇게 계속 붙여나가는 거지.
[], [[]], 그리고 [[],[],[]]는 전부 다른 거야. 첫 번째 건 텅 빈 리스트고, 두 번 째건 텅 빈 리스트를 하나 갖고 있는 리스트고, 세 번째건 세 개의 텅빈 리스트를 갖고 있는 리스트지.
인덱스를 이용해서 리스트의 원소를 갖고 오고 싶다면 !! 연산자를 써. 인덱스는 0부터 시작해.
ghci> "Steve Buscemi" !! 6
'B'
ghci> [9.4,33.2,96.2,11.2,23.25] !! 1
33.2 하지만, 만약 원소가 4개 밖에 없는 리스트에서 6번째 원소를 가져오려고 시도한다면 에러가 날 테니 조심해야할 거야!
리스트는 리스트를 포함할 수 있어. 얼마든지 중첩해서 리스트를 포함하는 리스트를 포함하는 리스트를 포함하는... 같은 것도 만들 수 있어.
ghci> let b = [[1,2,3,4],[5,3,3,3],[1,2,2,3,4],[1,2,3]]
ghci> b
[[1,2,3,4],[5,3,3,3],[1,2,2,3,4],[1,2,3]]
ghci> b ++ [[1,1,1,1]]
[[1,2,3,4],[5,3,3,3],[1,2,2,3,4],[1,2,3],[1,1,1,1]]
ghci> [6,6,6]:b
[[6,6,6],[1,2,3,4],[5,3,3,3],[1,2,2,3,4],[1,2,3]]
ghci> b !! 2
[1,2,2,3,4] 리스트 안의 리스트는 길이는 서로 다를 수 있지만 타입은 달라선 안 돼. 몇 개의 문자와 몇 개의 숫자를 가진 리스트를 만들 수 없는 것과 마찬가지로, 넌 몇 개의 숫자 리스트와 몇 개의 문자 리스트를 가진 리스트를 만들 수 없어.
리스트는 자신이 포함하고 있는 원소들이 비교될 수 있다면 서로 비교할 수 있어. 리스트끼리 비교하기 위해 <, <=, >, >= 연산자를 사용할 때는, 사전 순에 따라 비교를 진행해. 첫 번째 원소끼리 비교하고, 둘이 서로 같으면 두 번째 원소를 비교하고, 그것도 같으면 세 번째 원소를 비교하고... 하는 식으로.
ghci> [3,2,1] > [2,1,0]
True
ghci> [3,2,1] > [2,10,100]
True
ghci> [3,4,2] > [3,4]
True
ghci> [3,4,2] > [2,4]
True
ghci> [3,4,2] == [3,4,2]
True 이것 말고 리스트로 할 수 있는게 뭐가 더 있을까? 리스트와 관련된 기본적인 함수들을 살펴보자.
head는 리스트를 인자로 받아서 그 머리(head)를 돌려줘. 리스트의 머리는 기본적으로 그 첫 번째 원소를 말해.
ghci> head [5,4,3,2,1]
5 tail은 리스트를 인자로 받아서 그 꼬리(tail)를 돌려줘. 다른 말로, 이건 리스트의 머리를 잘라 내.
ghci> tail [5,4,3,2,1]
[4,3,2,1] last는 리스트를 인자로 받아서 그 마지막 원소를 돌려줘.
ghci> last [5,4,3,2,1]
1 init은 리스트를 인자로 받아서 마지막 원소를 제외한 나머지 모두를 돌려줘.
ghci> init [5,4,3,2,1]
[5,4,3,2] 리스트를 한 마리의 괴물처럼 본다면, 어떤게 어떤 걸 말하는 지는 아래와 같이 표현할 수 있어.

만약 텅 빈 리스트의 head를 얻으려고 한다면 무슨 일이 일어날까?
ghci> head []
*** Exception: Prelude.head: empty list 이런! 뭔가 잘못됐어! 어떤 몬스터도 없다면, 당연히 그 머리도 없겠지. head, tail, last, init를 사용할 때 텅 빈 리스트에 사용하지 않게 주의해야돼. 이건 컴파일 타임에는 잡아낼 수가 없고, 따라서 뜻하지 않게 Haskell에게 텅빈 리스트에서 원소를 꺼내달라고 요구하는 걸 미리 방지하는게 항상 좋은 습관이야.
length는 리스트를 취해서 그 길이를 돌려줘.
ghci> length [5,4,3,2,1]
5 null은 리스트가 텅 비었는지 확인해줘. 텅 비었다면 True를, 아니라면 False를 돌려주지. 어떤 리스트 xs에 대해 xs == [] 라고 쓰는 대신에 이 함수를 써.
ghci> null [1,2,3]
False
ghci> null []
True reverse는 리스트를 거꾸로 뒤집어줘.
ghci> reverse [5,4,3,2,1]
[1,2,3,4,5] take는 숫자와 리스트를 인자로 받아. take는 리스트의 시작점으로부터 여러 개의 원소를 추출하지. 봐봐.
ghci> take 3 [5,4,3,2,1]
[5,4,3]
ghci> take 1 [3,9,3]
[3]
ghci> take 5 [1,2]
[1,2]
ghci> take 0 [6,6,6]
[] 리스트의 크기보다 더 많은 원소를 추출할 경우에는 그냥 원래의 리스트를 돌려줘. 0 개의 원소를 추출할 경우에는 빈 리스트를 돌려주고.
drop은 비슷하게, 리스트의 시작점으로부터 해당 개수의 원소를 없애버려.
maximum은 어떤 순서를 가진 개체들의 리스트를 받아서 그 중 가장 큰 원소를 돌려줘.
minimum은 가장 작은 걸 돌려주고.
ghci> minimum [8,4,2,1,5,6]
1
ghci> maximum [1,9,2,3,4]
9 sum은 숫자들의 리스트를 받아서 그 합을 돌려줘.
product는 숫자들의 리스트를 받아서 그 곱을 돌려줘.
ghci> sum [5,2,1,6,3,2,5,7]
31
ghci> product [6,2,1,2]
24
ghci> product [1,2,5,6,7,9,2,0]
0 elem은 개체와 그 개체들의 리스트를 받아서 해당 개체가 리스트 안에 속하는 원소인지를 알려줘. 가독성때문에 보통 이건 중위(infix) 함수로 쓰여.
ghci> 4 `elem` [3,4,5,6]
True
ghci> 10 `elem` [3,4,5,6]
False 이것들이 리스트에 대해 쓸 수 있는 몇몇 기본적인 함수들이야. 우리는 이후에 대 많은 리스트 관련 함수들을 살펴볼거야.
만약 1부터 20까지의 모든 숫자들로 이루어진 리스트를 만들고 싶다면 어떻게 해야 할까? 물론, 그냥 걔네들을 다 적어버리면 되겠지만 자신의 프로그래밍 언어에 탁월함(excellence)을 요구하는 신사들에겐 그런건 해결책이 될 수 없지. 대신에, 우리는 범위(range)를 쓸 거야. 범위(range)는 열거될 수 있는 요소들의 등차수열(arithmetic sequence)을 만드는 방법이야. 숫자들은 열거될 수 있지(enumerated). 1,2,3,4, ... 문자들도 열거될 수 있어. 알파벳은 a부터 z까지 문자들의 열거지. 이름은 열거될 수 없어. "John" 다음에 뭐가 올까? 알 수 없지.
1부터 20까지의 모든 자연수를 포함하는 리스트를 만들기 위해선 [1..20]이라고 쓰기만 하면 돼. 이건 [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]이라고 쓰는 거랑 똑같고, 원소들의 긴 열거를 손으로 일일히 다 쓰는게 멍청한 짓이라는 것 빼곤 둘 사이에 차이는 없어.
ghci> [1..20]
[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]
ghci> ['a'..'z']
"abcdefghijklmnopqrstuvwxyz"
ghci> ['K'..'Z']
"KLMNOPQRSTUVWXYZ" 범위는 스텝(step)을 명시할 수 있기 때문에 멋져. 1부터 20까지의 모든 짝수를 포함한 리스트를 만들려면 어떻게 해야할까? 1부터 20 사이의 3의 배수를 모두 포함하는 리스트를 만들려면?
ghci> [2,4..20]
[2,4,6,8,10,12,14,16,18,20]
ghci> [3,6..20]
[3,6,9,12,15,18] 그냥 첫 두 원소를 콤마(,)로 구분해서 적고 그 상한선이 어딘지만 표기하면 되는 문제야. 굉장히 영리하긴 하지만, 스텝을 이용한 범위는 사람들이 생각하는 것 만큼 똑똑하진 않아. 2의 모든 제곱수를 얻기 위해 [1,2,4,8,16 .. 100]이라고 쓰면 안 돼. 왜냐하면 넌 제일 첫 스텝 하나만 명시할 수 있고, 등차가 아닌 몇몇 수열들은 처음 몇 개만 가지고 얻어 내기엔 모호하거든.
20부터 1까지의 모든 원소들을 가진 리스트를 만들고 싶다고 [20..1]이라고 쓰는 건 안 돼. 이럴 땐 [20,19 .. 1]이라고 써야하지.
범위에서 부동 소수점을 이용할 땐 조심해야돼! 왜냐하면 얘네들은 완전히 정밀하지 못하거든(정의부터 그렇잖아). 범위에서 부동소수점을 이용하는 건 꽤나 파격적인 결과를 갖고 오지.
ghci> [0.1, 0.3 .. 1]
[0.1,0.3,0.5,0.7,0.8999999999999999,1.0999999999999999] 난 그냥 리스트 범위에서는 부동소수점을 쓰지 말라고 충고해주고 싶어.
범위는 상한선을 지정하지 않음으로써 무한대 크기의 리스트를 만드는 것에도 이용할 수 있어. 나중에 무한 리스트에 대해 좀 더 자세히 살펴볼거야. 지금은, 13의 배수중 제일 처음 24개를 가져오는 방법을 한 번 알아보자. 물론 [13,26 .. 13*24]라고 하면 돼. 하지만 더 좋은 방법이 있어. take 24 [13,26..] 라고 쓰는 거지. Haskell은 게으르고, 무한대 크기의 리스트는 절대 끝나지 않을 것이기 때문에, 무한대 크기의 리스트를 바로 평가하려고 하지 않아. Haskell은 네가 무한대 리스트로부터 뭘 얻어내길 원하는 지 알아내기 위해 기다려. 여기선 네가 그 중 첫 24개를 원한다는 걸 알아낼 수 있고, 기꺼이 시킨 일을 수행하지.
아래는 무한대 리스트를 생성하는 함수들 중 일부야.
cycle은 리스트를 인자로 받아서 그걸 무한히 순회하지. 그 결과를 화면에 띄우면, 이건 네가 멈추기 전까지 무한히 반복될거야.
ghci> take 10 (cycle [1,2,3])
[1,2,3,1,2,3,1,2,3,1]
ghci> take 12 (cycle "LOL ")
"LOL LOL LOL " repeat는 원소를 하나 받아서 그 원소들로만 이루어진 무한대 리스트를 만들어. 원소 하나짜리 리스트로 cycle을 쓰는 거랑 비슷하지.
ghci> take 10 (repeat 5)
[5,5,5,5,5,5,5,5,5,5] 한 원소로만 이루어진 리스트를 만들고 싶다면 replicate 함수를 쓰는 게 더 간단하긴 해. replicate 3 10 은 [10,10,10]을 돌려줘.
수학 수업을 한 번이라도 들은 적이 있다면, 아마 집합의 조건 제시법(set comprehension)을 배워본 적이 있을거야. 보통 일반적인 집합에서 더 명시적인 집합을 만들어낼 때 사용되는 방법이지. 처음 10개의 짝수를 포함하는 집합을 만드는 일반적인 조건제시법은 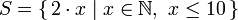
|) 이전의 부분은 출력 함수(output function)라고 부르고, x는 변수, N은 입력 집합, 그리고 x <= 10은 술어(predicate)야. 이건 자연수를 2배한 모든 숫자 중에서 술어를 만족하는 애들만 포함하는 집합을 의미하지.
이걸 Haskell에서 사용하고 싶다면, take 10 [2,4 ..]라고 쓰는 걸로 비슷한 걸 얻을 수 있어. 하지만 우리가 첫 10개의 짝수가 아니라 좀 더 복잡한 함수가 적용된 뭔가를 얻고 싶다면 어떻게 해야 할까? 이럴 때 조건 제시형 리스트를 이용할 수 있어. 조건 제시형 리스트는 조건 제시법하고 굉장히 비슷해. 다시 첫 10개의 짝수를 얻는 방법에 대해 알아보자. 조건 제시형 리스트에서 우리는 [x*2 | x <- [1..10]]을 사용할 수 있어. x는 [1..10]에서 얻을 수 있고, [1..10]의 모든 원소(우리가 x와 묶은 - bound)에 대해 두 배를 곱하겠다는 거야. 여기 실제 실행 결과가 있어.
ghci> [x*2 | x <- [1..10]]
[2,4,6,8,10,12,14,16,18,20] 봤듯이, 우리는 원하는 결과를 얻었어. 이제 여기에 조건(혹은 술어)을 더해보자. 술어는 묶음부(binding parts) 뒤에 오고 서로 콤마(,)로 구분해. 첫 10개의 짝수 중에서 값이 12이상인 애들만 구한다고 해보자.
ghci> [x*2 | x <- [1..10], x*2 >= 12]
[12,14,16,18,20] 좋아, 잘 동작해. 만약 50부터 100까지 숫자 중에서 7로 나눈 나머지가 3인 숫자들은 어떤 식으로 구할 수 있을까?
ghci> [ x | x <- [50..100], x `mod` 7 == 3]
[52,59,66,73,80,87,94] 성공이야! 술어(predicate)를 이용해서 리스트에서 필요없는 원소들을 제거하는 건 필터링(filtering)이라고도 부른다는 걸 기억해둬. 이제 다른 예제를 살펴보자. 10보다 큰 홀수는 "BANG!"으로 바꾸고, 그렇지 않은 홀수는 "BOOM!"으로, 홀수가 아니라면 제거해버리는 조건제시형 리스트(list comprehension)를 원한다고 하자. 아주 편리하게, 우리는 이 조건 제시형 리스트를 함수 안에 집어넣어서 쉽게 재활용할 수 있어.
boomBangs xs = [ if x < 10 then "BOOM!" else "BANG!" | x <- xs, odd x] 조건 제시형 리스트의 마지막 부분은 술어야. odd 함수는 숫자가 홀수면 True를, 아니면 False를 리턴해. 원소들은 술어가 True로 평가됐을 때만 리스트에 포함돼.
ghci> boomBangs [7..13]
["BOOM!","BOOM!","BANG!","BANG!"] 여러 개의 술어를 포함할 수도 있어. 만약 10부터 20까지의 숫자 중에서 13,15,19를 제외한 나머지를 얻고 싶다면 이렇게 하면 돼.
ghci> [ x | x <- [10..20], x /= 13, x /= 15, x /= 19]
[10,11,12,14,16,17,18,20] 리스트 안에 여러 개의 술어를 포함할 수 있을 뿐만 아니라(결과 리스트의 원소는 모든 술어를 만족해야돼), 여러 개의 리스트로부터 원소를 가져올 수 있어. 여러 개 리스트로부터 원소를 가져올 때, 조건 제시형 리스트(comprehension)는 주어진 리스트들의 모든 조합을 만들어내고 우리가 제공하는 출력 함수로 걔네들을 합쳐. 길이가 4인 리스트 두개를 이용한 조건 제시형 리스트에서 아무런 필터링을 하지 않는다면 결과 리스트는 길이가 16이 될거야. 만약 [2,5,10], [8,10,11] 두 개의 리스트에서 가능한 모든 조합에 대해 둘의 곱을 얻고 싶다면 아래와 같이 하면 돼.
ghci> [ x*y | x <- [2,5,10], y <- [8,10,11]]
[16,20,22,40,50,55,80,100,110] 처음에 예상한대로, 만들어진 리스트의 길이는 9야. 이 중 50보다 큰 숫자만 필요하다면?
ghci> [ x*y | x <- [2,5,10], y <- [8,10,11], x*y > 50]
[55,80,100,110]형용사 리스트와 명사 리스트를 합치는 조건 제시형 리스트는 어떨까? 그 정돈 아주 쉽지!
ghci> let nouns = ["hobo","frog","pope"]
ghci> let adjectives = ["lazy","grouchy","scheming"]
ghci> [adjective ++ " " ++ noun | adjective <- adjectives, noun <- nouns]
["lazy hobo","lazy frog","lazy pope","grouchy hobo","grouchy frog",
"grouchy pope","scheming hobo","scheming frog","scheming pope"] 알겠어! 이제 우리만의 length 함수를 만들어 보자! length' 정도로 부를 수 있겠지.
length' xs = sum [1 | _ <- xs] _ 기호는 list로부터 얻은 원소가 뭔지 신경쓰지 않겠다는 거야. 그래서 사용하지도 않을 변수 이름을 쓰는 대신, 그냥 _라고 쓸 수 있어. 이 함수는 리스트의 모든 원소를 1로 바꾼 다음 그 합을 돌려줘. 결과값은 리스트의 길이임을 의미하겠지.
이전에 이야기했듯이 문자열도 리스트기 때문에, 우린 스트링을 다루고 만드는 데에 조건 제시형 리스트를 사용할 수 있어. 여기 문자열을 받아서 대문자를 제외한 모든 문자를 제거하는 함수가 있어.
removeNonUppercase st = [ c | c <- st, c `elem` ['A'..'Z']] 테스트 결과는 다음과 같아.
ghci> removeNonUppercase "Hahaha! Ahahaha!"
"HA"
ghci> removeNonUppercase "IdontLIKEFROGS"
"ILIKEFROGS" 이 술어는 전부 잘 동작해. 이 술어는 새 리스트에 포함될 수 있는 문자는 ['A'..'Z'] 리스트에 속한 문자여야한다는 뜻이야. 리스트를 포함한 리스트에 대한 연산을 하는 경우에 조건 제시형 리스트의 중첩(Nested list comprehension)도 가능해. 숫자의 리스트를 원소로 가지는 리스트에서 홀수인 원소들을 모두 제거해보자.
ghci> let xxs = [[1,3,5,2,3,1,2,4,5],[1,2,3,4,5,6,7,8,9],[1,2,4,2,1,6,3,1,3,2,3,6]]
ghci> [ [ x | x <- xs, even x ] | xs <- xxs]
[[2,2,4],[2,4,6,8],[2,4,2,6,2,6]] 조건 제시형 리스트를 여러 줄에 걸쳐서 쓰는 것도 가능해. GHCI 안에서가 아니라면, 길이가 긴 조건 제시형 리스트는 여러 줄에 걸쳐 쓰는게 좋고 특시 중첩해서 쓰는 경우에는 더 그래.
어떤 면에서, 튜플은 리스트와 비슷해. 튜플도 여러 개의 값들을 하나의 값 안에 저장하지. 하지만, 여기엔 몇가지 근본적인 차이가 있어. 숫자의 리스트는 숫자의 리스트야. 그게 타입이고 얘들은 원소가 한 개 있는 지 무한 개 있는 지는 신경 안 써. 하지만 튜플은 네가 합치고 싶은 원소의 개수가 정확히 몇 개인지 알고 있을 때 쓰고, 그 타입은 구성 요소의 개수와 각각의 타입에 영향을 받아. 튜플은 소괄호와 콤마(,)로 구분되는 구성 요소(component)들로 표현돼.
또다른 중요한 차이점은 얘네들은 똑같은 타입으로만 구성될 필요가 없다는 거야. 튜플은 리스트랑은 다르게 구성 요소들의 타입이 여러 종류여도 상관없어.
2차원 벡터를 Haskell에서 어떻게 표현해야할 지 생각해보자. 한 가지는 리스트를 쓰는 방법이야. 이것도 제대로 동작할거야.2차원 평면에서의 도형을 표현하기 위해 여러 개의 2차원 벡터를 리스트에 집어넣고 싶다면 어떻게 해야할까? 아마 [[1,2],[8,11],[4,5]] 처럼 표현할 수 있을거야. 이 방식의 문제점은 [[1,2],[8,11,5],[4,5]]처럼 표현할 수도 있고 이 것도 역시 숫자의 리스트의 리스트기 때문에 Haskell은 어떤 문제도 없다고 인식할테지만, 우리가 표현하려고 했던 건 이게 아니었지. 하지만 크기가 2인 튜플(페어pair라고도 부름)은 그 자체로 하나의 타입이고, 그 말인즉슨 여러 개의 페어를 포함하고 있는 리스트가 트리플(triple - 크기가 3인 튜플)을 포함할 수 없다는 거야. 리스트 대신에 튜플을 한 번 써보자. 벡터를 둘러싸는 괄호를 대괄호가 아니라 소괄호로 바꿔봐. [(1,2),(8,11),(4,5)]. [(1,2),(8,11,5),(4,5)]같은 도형을 만들려고 시도하면 어떻게 될까? 음, 이런 에러가 발생해.
Couldn't match expected type `(t, t1)'
against inferred type `(t2, t3, t4)'
In the expression: (8, 11, 5)
In the expression: [(1, 2), (8, 11, 5), (4, 5)]
In the definition of `it': it = [(1, 2), (8, 11, 5), (4, 5)] 이건 우리가 페어와 트리플을 같은 리스트에 집어넣으려고 시도했다고 말해주는 거야. 이외에도 [(1,2),("One",2)] 같은 리스트도 만들 수 없어. 왜냐하면 리스트의 첫번째 원소가 숫자의 페어이고, 두번째 원소가 문자열과 숫자로 이루어진 페어기 때문이야. 튜플은 다양한 종류의 데이터를 표현하는데 사용될 수 있어. 예를 들어, Haskell에서 누군가의 이름과 나이를 표현하고 싶다면, 트리플을 사용하면 돼. ("Cristopher", "Walken", 55). 이 예제에서 볼 수 있듯이 튜플은 리스트(문자열=리스트)도 포함할 수 있어.
데이터의 일부 조각이 가져야만 하는 구성 요소가 얼마나 많은 지 미리 알 수 있을 때에 튜플을 써. 튜플은 크기가 다르면 서로 다른 타입으로 취급하기 때문에 좀 더 엄격하고, 따라서 튜플의 맨 앞에 원소를 추가하는 일반적인 함수같은 건 만들 수 없어. 대신에 페어의 맨 앞에 원소를 붙이거나, 트리플의 맨 앞에 원소를 붙이거나, 크기가 4인 튜플의 맨 앞에 원소를 붙이거나 하는 식으로 함수를 만들어야해.
원소가 하나인 리스트는 존재할 수 있지만, 원소가 하나인 튜플 같은 건 없어. 왜 그런지는 조금만 생각해보면 알거야. 원소가 하나인 튜플은 그게 포함하는 원소와 똑같아. 그래서 그런걸 따로 만들 이유가 없지.
리스트와 비슷하게, 튜플도 그 구성 원소들이 비교가 가능하다면 서로 비교할 수 있어. 다만 리스트는 크기가 서로 달라도 비교가 가능한 반면 튜플은 크기가 다르면 비교가 불가능해. 페어에 대해 사용가능한 유용한 함수 두 가지가 있어.
fst는 페어를 인자로 받아서 그 첫번째 구성요소를 돌려줘.
ghci> fst (8,11)
8
ghci> fst ("Wow", False)
"Wow" snd는 페어를 인자로 받아서 그 두번째 구성요소를 돌려줘.
이 함수들은 페어에 대해서만 동작해. 트리플, 4-튜플,5-튜플, 기타등등에 대해선 동작하지 않아. 다른 방식으로 튜플에서 데이터를 추출하는 방법은 좀 더 나중에 살펴볼거야.
페어들의 리스트를 만들어내는 아주 멋진 zip이라는 함수가 있어. 이건 두 개의 리스트를 받아서 그 둘의 원소들을 각각 매칭시켜 하나의 리스트로 압축해버려. 이건 정말로 간단한 함수지만 쓸모가 많아. 이건 두 개의 리스트를 합치거나 두 개의 리스트를 동시에 순회할 때 특히 유용해. 여기 그에 대한 증명이 있어.
ghci> zip [1,2,3,4,5] [5,5,5,5,5]
[(1,5),(2,5),(3,5),(4,5),(5,5)]
ghci> zip [1 .. 5] ["one", "two", "three", "four", "five"]
[(1,"one"),(2,"two"),(3,"three"),(4,"four"),(5,"five")] 이건 원소들을 짝지어서 하나의 리스트로 만들어주지. 첫번째 원소끼리 짝짓고, 두번째 원소끼리 짝짓고, ... 페어는 서로 다른 타입을 담을 수 있기 때문에 zip 함수 역시 서로 다른 종류의 리스트를 인자로 받아서 하나로 합칠 수 있어. 만약 두 리스트의 길이가 다르다면 어떻게 될까?
ghci> zip [5,3,2,6,2,7,2,5,4,6,6] ["im","a","turtle"]
[(5,"im"),(3,"a"),(2,"turtle")] 간단하게 더 작은 쪽에 맞춰서 길이가 긴쪽의 리스트가 잘려나가. Haskell은 게으르기 때문에, 유한 크기의 리스트와 무한 크기의 리스트를 서로 zip할 수도 있어.
ghci> zip [1..] ["apple", "orange", "cherry", "mango"]
[(1,"apple"),(2,"orange"),(3,"cherry"),(4,"mango")] 튜플과 조건 제시형 리스트를 같이 다루는 문제가 있어. 각 변의 길이가 모두 10이하의 정수이고 그 둘레는 24인 직삼각형엔 어떤게 있을까? 먼저, 모든 변의 길이가 10 이하인 삼각형을 만들어보자.
ghci> let triangles = [ (a,b,c) | c <- [1..10], b <- [1..10], a <- [1..10] ] 단순히 세 개의 리스트로부터 원소를 받아서 그걸 하나로 합치기만 하면 돼. 이제 GHCI에서 triangles라고 타이핑하면 모든 변의 길이가 10이하인 삼각형의 가능한 목록을 모두 얻을 수 있어. 이제, 여기에 이 삼각형이 직삼각형이라는 조건을 더해보자. 직삼각형의 각 변은 빗변보다 길 수 없고, 두 변의 제곱의 합은 빗변의 제곱과 같다는 조건을 만족하면 되니까 단순히 이 조건을 더해주기만 하면 돼.
ghci> let rightTriangles = [ (a,b,c) | c <- [1..10], b <- [1..c], a <- [1..b], a^2 + b^2 == c^2] 이제 거의 다 됐어.이제, 그 둘레가 24라는 조건만 추가해주면 돼.
ghci> let rightTriangles' = [ (a,b,c) | c <- [1..10], b <- [1..c], a <- [1..b], a^2 + b^2 == c^2, a+b+c == 24]
ghci> rightTriangles'
[(6,8,10)]이게 정답이야! 그리고 이게 함수형 프로그래밍을 하는 일반적인 방법이야. 해의 집합을 구하는 것으로부터 시작해서, 거기에 변형을 적용하는 과정을 거듭해서, 올바른 결과를 얻을 때까지 걸러내면 돼.
- 이전 챕터 : 01 - 소개
- 다음 챕터 : 03 - 타입과 타입클래스