本次的程式碼與目錄結構可以參考 FastAPI Tutorial : Day15 branch
我們在 Day01 就有提到 FastAPI 支援非同步 handler
而 Day10 到 Day14 我們成功連接 DB 、 設定 SQLAlchemy 以 ORM 來 CRUD
但是到目前為止我們的 DB 存取都是同步的
也就是說,當我們的 API endpoint 有 DB 存取的時候,會等待 DB 存取完成後才會回傳 response
這樣的話,當 DB 存取時間過長時,會造成 API endpoint 的 response time 過長 ( 因為被 Block 住 )
所以我們可以將 DB 存取改為非同步的方式,讓 API endpoint 在等待 DB 存取的時候,可以先處理其他的 request
如果之前沒跟著實作的朋友可以直接跳到 非同步存取 DB
為了今天的 benchmark 我們會將專案架構做一些調整
最後會比較sync和async存取 DB 的 performance
我們新增一個 sync 木怒在 backend 底下
並複製 api crud database 到 sync 底下
調整完的目錄結構如下:
.
├── api
│ ├── depends.py
│ ├── infor.py
│ ├── items.py
│ └── users.py
├── crud
│ ├── items.py
│ └── users.py
├── database
│ ├── fake_db.py
│ └── generic.py
├── main.py
├── models
│ ├── base.py
│ ├── item.py
│ └── user.py
├── run.py
├── schemas
│ ├── items.py
│ └── users.py
├── setting
│ ├── .env.dev
│ ├── .env.prod
│ ├── .env.test
│ └── config.py
└── sync
├── api
│ ├── depends.py
│ ├── infor.py
│ ├── items.py
│ └── users.py
├── crud
│ ├── items.py
│ └── users.py
└── database
├── fake_db.py
└── generic.py與 Day10 相似,用一樣的方法來加上 run_mode 的選項
讓我們能夠以 --run_mode 來決定要使用 sync 還是 async 的方式來存取 DB
run.py
# ...
# 新增 run_mode
run_mode = parser.add_argument_group(title="Run Mode", description="Run the server in Async or Sync mode. Default is Async.")
run_mode.add_argument("--sync",action="store_true", help="Run the server in Sync mode.")
# ...
if args.sync:
os.environ["RUN_MODE"] = "SYNC"
else:
os.environ["RUN_MODE"] = "ASYNC"
# ...所以在 setting/config.py 中,我們可以透過載入 RUN_MODE 來動態的載入對應的 Database url
同時也需要調整 .env 中的原本 Database url
.env.dev
SYNC_POSTGRESQL_DATABASE_URL='postgresql+psycopg2://fastapi_tutorial:fastapi_tutorial_password@localhost:5432/fastapi_tutorial'
ASYNC_POSTGRESQL_DATABASE_URL='postgresql+asyncpg://fastapi_tutorial:fastapi_tutorial_password@localhost:5432/fastapi_tutorial'
SYNC_MYSQL_DATABASE_URL='mysql+pymysql://root:fastapi_tutorial_password@localhost:3306/fastapi_tutorial'
ASYNC_MYSQL_DATABASE_URL='mysql+aiomysql://root:fastapi_tutorial_password@localhost:3306/fastapi_tutorial'可以看到 SYNC_POSTGRESQL_DATABASE_URL 和 ASYNC_POSTGRESQL_DATABASE_URL 的差別在於
ASYNC 的 Driver 是我們剛剛多加的非同步 Driver asyncpg
SYNC 的 Driver 是原本的 psycopg2
setting/config.py
class Settings():
# ...
# 多新增 run_mode
run_mode:str = os.getenv("RUN_MODE").upper() # <--- 新增
database_url: str = os.getenv(f"{run_mode}_{db_type}_DATABASE_URL") # <--- 修改
# ...這樣 settings 就可以依據 argument --sync 來決定要使用 ASYNC 還是 SYNC 的方式來存取 DB !
因為我們現在將 同步處理 與 非同步處理 分開
所以在 main.py 中也要依據現在的 RUN_MODE 來決定來載入 async 或 sync 的 Router 或 CRUD
多新增 settings 來判斷要載入 async 或 sync 的 Router 或 CRUD
main.py
from fastapi import FastAPI
from setting.config import get_settings # <--- 新增
settings = get_settings()
app = FastAPI()如果是 ASYNC 的話,就載入 async 的 Router 或 CRUD
main.py
# ...
if settings.run_mode == "ASYNC":
from api.infor import router as infor_router
from api.users import router as user_router
from api.items import router as item_router
from database.generic import init_db , close_db
app.include_router(infor_router)
app.include_router(user_router)
app.include_router(item_router)
@app.on_event("startup")
async def startup():
await init_db()
@app.on_event("shutdown")
async def shutdown():
await close_db()反之,如果是 SYNC 的話,就載入 sync 的 Router 或 CRUD
main.py
# ...
else:
from sync.api.infor import router as infor_router
from sync.api.users import router as user_router
from sync.api.items import router as item_router
from sync.database.generic import init_db , close_db
app.include_router(infor_router)
app.include_router(user_router)
app.include_router(item_router)
@app.on_event("startup")
def startup():
init_db()
@app.on_event("shutdown")
def shutdown():
close_db()SQLAlchemy 也有支援非同步的方式來存取 DB
不過我們需要使用其他的 DB driver
不同的 DB 有不同的 driver
- PostgreSQL :
asyncpg - MySQL :
aiomysql
而
greenlet是asyncpg的 dependency
poetry add asyncpg
poetry add greenlet
poetry add aiomysql與之前的 database/generic.py 相比,我們只需要將 Session 改為 AsyncSession
而原本的 create_engine 要改為 create_async_engine
create_engine是在from sqlalchemy import create_engine底下create_async_engine是在from sqlalchemy.ext.asyncio中sessionmaker也要改為async_sessionmaker
database/generic.py
# async version
from sqlalchemy.ext.asyncio import create_async_engine , async_sessionmaker
from sqlalchemy.orm import DeclarativeBase
from setting.config import get_settings
settings = get_settings()
# 這邊要改為 create_async_engine
engine = create_async_engine(
settings.database_url,
echo=True,
pool_pre_ping=True
)
# 改為 async_sessionmaker
SessionLocal = async_sessionmaker(engine, expire_on_commit=False, autocommit=False)
class Base(DeclarativeBase):
pass
# 等等會特別說明這個 `get_db`
async def get_db() -> AsyncGenerator:
async with SessionLocal() as db:
async with db.begin():
yield db
async def init_db():
async with engine.begin() as conn:
await conn.run_sync(Base.metadata.create_all)
async def close_db():
async with engine.begin() as conn:
await conn.close()
要注意的是,我們的 get_db 有一點不一樣
因為改為非同步的方式,所以我們需要使用 async with connection.begin() 來取得 connection
並透過 yield 來回傳一個 AsyncGenerator
讓我們在 api 或 crud 中可以透過 Depends 來取得 AsyncSession
常見的寫法如下:
接下來都先以 get users 為例
在 SQLAlchemy 2.0 中,使用 AsyncEngine 在跑 create_all 時並不會成功 create tables
所以我們可以透過在 AsyncSession 中使用 CreateTable 來解決這個問題
database/generic.py
async def init_db():
async with SessionLocal() as db:
async with db.begin():
await db.execute(CreateTable(User.__table__,if_not_exists=True))
await db.execute(CreateTable(Item.__table__,if_not_exists=True))雖然在官方 Doc 中有提到
AsyncEngine可以使用create_all來 create table
但不知道為什麼我在使用create_all時,並不會真的 create table
這邊要注意的是,我們需要在 async with db.begin() 中使用 await db.execute(CreateTable(...))
並且要使用 if_not_exists=True 來避免重複 create table error
這樣就可以成功的 create table 了
crud/users.py
from sqlalchemy.ext.asyncio import AsyncSession # <--- 新增
# ...
async def get_users(db_session:AsyncSession, keyword:str=None,last:int=0,limit:int=50):
stmt = select(UserModel.name,UserModel.id,UserModel.email,UserModel.avatar)
if keyword:
stmt = stmt.where(UserModel.name.like(f"%{keyword}%"))
stmt = stmt.offset(last).limit(limit)
result = await db_session.execute(stmt)
users = result.all()
return users
# ...這邊要注意的是,我們透過 Depends(get_db) 來取得 AsyncSession 再傳入 CRUD 的 get_users
api/users.py
@router.get("/users",
response_model=List[UserSchema.UserRead],
response_description="Get list of user",
)
async def get_users(page_parms:dict= Depends(pagination_parms), db_session:AsyncSession=Depends(get_db)):
users = await UserCrud.get_users(db_session,**page_parms)
return users如果在每個有使用到 CRUD 的 Routers 都需要這樣寫的話,會有點冗長
我們可以透過將 Depends(get_db) 抽出來寫在開頭
api/users.py
db_depends = Depends(get_db) # <--- 新增
@router.get("/users",
response_model=List[UserSchema.UserRead],
response_description="Get list of user",
)
async def get_users(page_parms:dict= Depends(pagination_parms), db_session=db_depends):
users = await UserCrud.get_users(db_session,**page_parms)
return users這樣我們只要使用 db_session=db_depends 就可以取得 AsyncSession 來注入 CRUD
我們可以透過 Apache benchmark tool (ab) 來測試 API endpoint 的 performance
如果是使用 Mac , 內建就有安裝
ab了 但是 hostname 必須使用127.0.0.1不能使用localhost
如果是以 50000 個 request 並且將 concurrency 設為 32 來打 API 的話:
sync:ab -n 50000 -c 32 http://127.0.0.1:8001/sync/api/users
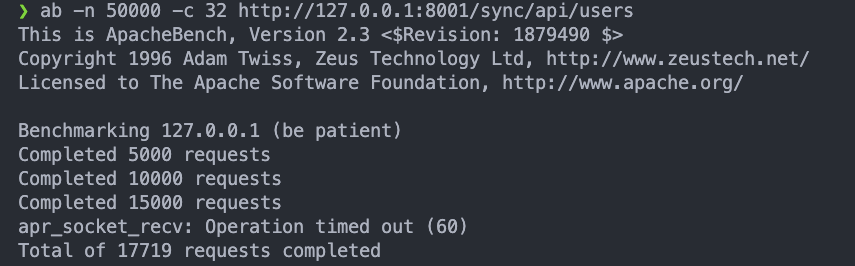 會發先跑到一半就跳出
會發先跑到一半就跳出 apr_socket_recv: timeout的 errorasync:ab -n 50000 -c 32 http://127.0.0.1:8001/api/users
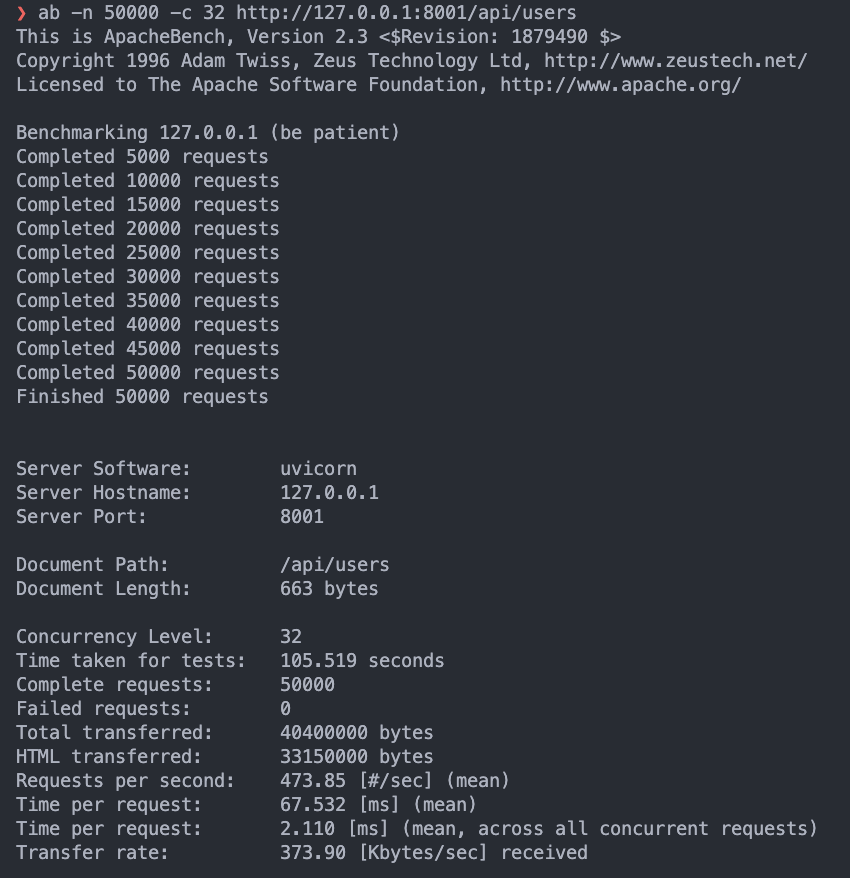 可以完整的跑完
可以完整的跑完 50000個 request
Time per request是約67ms
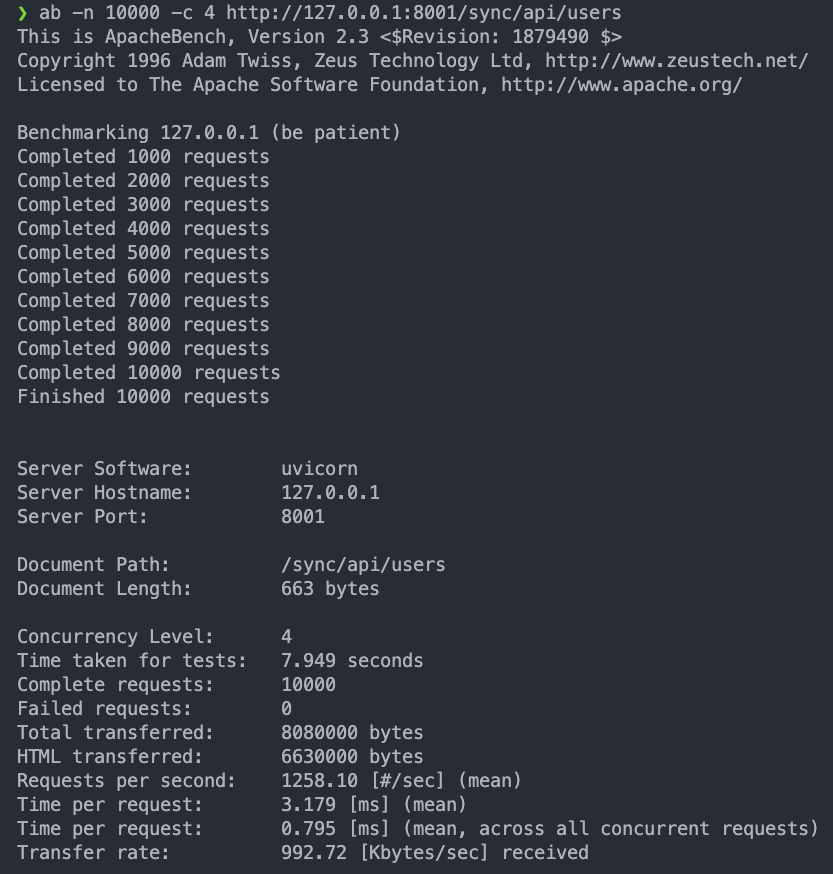
如果是以 10000 個 request 並且將 concurrency 設為 4 來打 API 的話:
sync:ab -n 10000 -c 4 http://127.0.0.1:8001/sync/api/users
async:ab -n 10000 -c 4 http:///127.0.0.1:8001/api/users
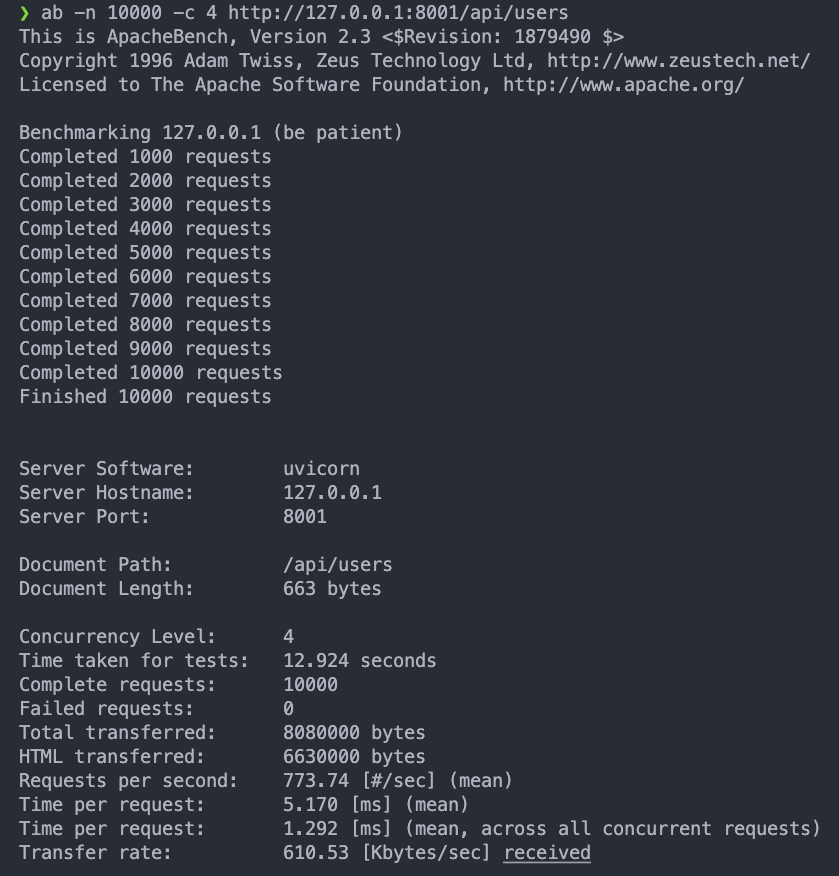
會發現反而 sync 的 performance 比 async 好
- 將原本
sync的 code 切到/sync/api/xxx
原本的/api/xxx改為async - 設定 SQLAlchemy 以
async的方式來存取 DB - 透過
Depends將AsyncSession注入到 CRUD function - 透過
abbenchmark 後
發現async的 performance 會隨著 concurrency 的增加而變好
但是在低 concurrency 的時候,反而sync的 performance 比async好