- DevOps Engineer Professional
- Exam Objectives
- Concepts
- Services
- Amazon EMR
- Amazon Inspector (Core Service)
- API Gateway (Core Service)
- Athena
- CloudFormation (Core Service)
- CloudFront
- CloudSearch
- CloudTrail (Core Service)
- CloudWatch (Core Service)
- CodeBuild (Core Service)
- CodeCommit (Core Service)
- CodeDeploy (Core Service)
- CodePipeline (Core Service)
- CodeStar
- Config (Core Service)
- DynamoDB
- ECS
- Elastic Beanstalk (Core Service)
- Elasticsearch Service
- GuardDuty (Core Service)
- Kinesis (Core Service)
- Lambda (Core Service)
- License Manager
- Macie
- Managed Services
- OpsWorks Stacks (Core Service)
- Organizations
- Personal Health Dashboard
- QuickSight
- Redshift
- Relational Database Service
- Route 53
- S3
- Secrets Manager
- Service Catalog (Core Service)
- Step Functions
- Systems Manager (Core Service)
- Trusted Advisor (Core Service)
- X-Ray (Core Service)
- Etc
10/2019 - 6/2020
- Implement and manage continuous delivery systems and methodologies on AWS
- Implement and automate security controls, governance processes, and compliance validation
- Define and deploy monitoring, metrics, and logging systems on AWS
- Implement systems that are highly available, scalable, and self-healing on the AWS platform
- Design, manage, and maintain tools to automate operational processes
- Domain 1: SDLC Automation
- Domain 2:Configuration Management and Infrastructure as Code
- Domain 3: Monitoring and Logging
- Domain 4: Policies and Standards Automation
- Domain 5: Incident and Event Response
- Domain 6: High Availability, Fault Tolerance, and Disaster Recovery
- Apply concepts required to automate a CI/CD pipeline
- Determine source control strategies and how to implement them
- Apply concepts required to automate and integrate testing
- Apply concepts required to build and manage artifacts securely
- Determine deployment/delivery strategies (e.g., A/B, Blue/green, Canary, Red/black) and how to implement them using AWS Services
- Determine deployment services based on deployment needs
- Determine application and infrastructure deployment models based on business needs
- Apply security concepts in the automation of resource provisioning
- Determine how to implement lifecycle hooks on a deployment
- Apply concepts required to manage systems using AWS configuration management tools and services
- Determine how to set up the aggregation, storage, and analysis of logs and metrics
- Apply concepts required to automate monitoring and event management of an environment
- Apply concepts required to audit, log, and monitoroperating systems, infrastructures, and applications
- Determine how to implement tagging and other metadata strategies
- Apply concepts required to enforce standards for logging, metrics, monitoring, testing, and security
- Determine how to optimize cost through automation
- Apply concepts required to implement governance strategies
- Troubleshoot issues and determine how to restore operations
- Determine how to automate event managementand alerting
- Apply concepts required to implement automated healing
- Apply concepts required to set up event-driven automated action
- Determine appropriate use of multi-AZ versus multi-region architectures
- Determine how to implement high availability, scalability, and fault tolerance
- Determine the right services based on business needs (e.g., RTO/RPO, cost)
- Determine how to design and automate disaster recovery strategies
- Evaluate a deployment for points of failure
- Overview
- Single target deployment
- All-at-once deployment
- Minimum in-service style deployment
- Rolling deployment
- Rolling deployment with extra batches
- Blue/green deployment
- Red/black deployment
- A/B testing
- Canary deployment
General Strategies
| Strategy | Deploy time |
Downtime | Testing | Deployment Costs |
Impact of failed deployment |
Rollback process |
|---|---|---|---|---|---|---|
| Single Target Deployment | 🕑 | complete deploy | limited | no extra costs | downtime | redeploy |
| All At Once | 🕑 | complete deploy | limited | no extra costs | downtime | redeploy |
| Minimum In Service | 🕑🕑 | none | can test new version while old is still active |
no extra costs | no downtime | redeploy |
| Rolling | 🕑🕑🕑 | usually none | can test new version while old is still active |
no extra costs | no downtime | redeploy |
| Rolling With Extra Batches | 🕑🕑🕑 | usually none | can test new version while old is still active |
little extra costs | no downtime | redeploy |
| Blue/Green | 🕑🕑🕑🕑 | none | can test prior to cutover |
extra costs for new stack | no downtime | revert cutover |
Strategies per AWS service
| Strategy | Auto Scaling Group |
CodeDeploy EC2/On-Premises |
CodeDeploy ECS | CodeDeploy Lambda | Elastic Beanstalk |
OpsWorks |
|---|---|---|---|---|---|---|
| Single Target Deployment | . | . | . | . | redeploy | . |
| All At Once | AutoScalingReplacingUpdate |
All-at-once | . | . | all at once | . |
| Minimum In Service | . | . | . | . | rolling | . |
| Rolling | AutoScalingRollingUpdate |
One-at-at-time | . | . | rolling | . |
| Rolling With Extra Batches | . | . | . | . | rolling with extra batches |
. |
| Blue/Green | . | Traffic is shifted to a replacement set of instances * All-at-once * Half-at-a-time * One-at-a-time |
Traffic is shifted to a replacement task set * Canary * Linear * All-at-once |
Traffic is shifted to a new Lambda version * Canary * Linear * All-at-once |
immutable comes close or: create new environment and use DNS |
create new environment and use DNS |
| Canary | . | . | See above * Canary |
See above * Canary |
Traffic Splitting | . |
| System | Deploy |
|---|---|
v1 |
Initial State |
v1-2 |
Deployment Stage |
v2 |
Final State |
- When initiated a new application version is installed on the (single) target server
- Practically not in use any more
| pros | cons |
|---|---|
| Simple & very few moving parts | Downtime |
| Deployment is faster than other methods | Limited testing |
| System | Deploy | . |
|---|---|---|
v1 v1 v1 v1 v1 |
Initial State | . |
v1-2 v1-2 v1-2 v1-2 v1-2 |
Deployment Stage | . |
v2 v2 v2 v2 v2 |
Final State | . |
- Single build stage triggers multiple target environments
| pros | cons |
|---|---|
| Deployment is relatively fast | Downtime (like STD) |
| . | Limited testing (like STD) |
| . | Everything in-flight - can't stop deployment/rollback if targets fail |
| . | More complicated than STD, often requires orchestration |
| System | Deploy | . |
|---|---|---|
v1 v1 v1 v1 v1 |
Initial State | . |
v1 v1 v1-2 v1-2 v1-2 |
Deployment Stage 1 | Minimum targets required for operational state: 2 |
v1-2 v1-2 v2 v2 v2 |
Deployment Stage 2 | . |
v2 v2 v2 v2 v2 |
Final State | . |
- Orchestration engines know how many targets are required for a minimum operational state
- System ensures that this number of instances is active while completing the rest of the deployment as quickly as possible
- Happens to as many targets as possible
- Suitable for large environments
| pros | cons |
|---|---|
| No downtime | Many moving parts, requires orchestration |
| Deployment happens in (two) stages | . |
| Generally quicker & with less stages than rolling deployments | . |
| System | Deploy | . |
|---|---|---|
v1 v1 v1 v1 v1 |
Initial State | . |
v1-2 v1-2 v1 v1 v1 |
Deployment Stage 1 | Deploy first set of targets |
v2 v2 v1-2 v1-2 v1 |
Deployment Stage 2 | Only if health checks succeed: Deploy next set of targets |
v2 v2 v2 v2 v1-2 |
Deployment Stage 3 | Only if health checks succeed: Deploy next set of targets |
v2 v2 v2 v2 v2 |
Final State | . |
- Do x deployments at once, than move on to the next x
- Flexible on failing health checks - roll back stage or whole deployment
- Was considered cheapest and least risk method until hourly and consumption-based billing entered the market
| pros | cons |
|---|---|
| No downtime (if number of stage deployments is small enough) | Does not necessarily maintain overall application health |
| Can be paused to allow for multi-version testing | Many moving parts, requires orchestration |
| . | Can be least efficient deployment method in terms of time taken |
| System | Deploy | . |
|---|---|---|
v1 v1 v1 v1 |
Initial State | . |
v1 v1 v1 v1 . . |
Deployment Stage 1 | Deploy new batch of servers |
v1 v1 v1 v1 v2 v2 |
Deployment Stage 2 | Deploy new version to new servers |
. . v1 v1 v2 v2 |
Deployment Stage 3 | Undeploy first batch |
v2 v2 v1 v1 v2 v2 |
Deployment Stage 4 | Deploy new version to first batch |
v2 v2 . . v2 v2 |
Deployment Stage 5 | Undeploy second batch |
v2 v2 v2 v2 |
Deployment Stage 6 | Decommission servers from second batch |
- Deploy new batch of servers first
- Very similar to rolling deployment
| pros | cons |
|---|---|
| No downtime (if number of stage deployments is small enough) | Does not necessarily maintain overall application health |
| Can be paused to allow for multi-version testing | Many moving parts, requires orchestration |
| . | Can be least efficient deployment method in terms of time taken |
| System | Deploy | . |
|---|---|---|
(v1 v1 v1)() |
Initial State | Blue environment, all traffic goes here |
(v1 v1 v1)(v v v) |
Deployment Stage 1 | Bring up green environment |
(v1 v1 v1)(v2 v2 v2) |
Deployment Stage 2 | Deploy application into green environment |
(v1 v1 v1)(v2 v2 v2) |
Deployment Stage 3 | Cutover - direct traffic from blue to green |
() (v2 v2 v2) |
Final State | Blue environment removed |
- Deploys to a separate environment to provide outage risks
- Different cutover techniques
- DNS routing
- Swap Auto Scaling Group behind load balancer
- Elastic Beanstalk immutable: Merge new ASG into old one
- Update auto scaling launch configuration
- Swap environment of an AWS Elastic Beanstalk application
- Clone stack in AWS OpsWorks and update DNS
| pros | cons |
|---|---|
| Rapid all-at-once deployment process, no need to wait for per target health checks | Requires advanced orchestration tooling |
| Can test health prior to cutover | Significant cost for a second environment (mitigated by advanced billing models) |
| Clean & controlled cutover (various options) | . |
| Easy rollback | . |
| Can be fully automated using advanced templating | . |
| By far the best method in terms of risk mitigation and minimal user impact | . |
... are just like blue/green, but they happen at a much faster rate.
Example:
DNS->LB->ASG1DNS->LB->ASG2
- Like blue/green deployment, but only shift a percentage of the traffic over, not everything at once
- Gradually increase percentage of traffic sent to the new environment
- Allows for different end goal:
- Measuer user feedback and decide whether a feature should be rolled out or rolled back
- This can be decided well before the new environment gets 100% of the traffic
- Could only role out a feature to 10% of the users and switch back after metrics have been collected
- -> different to red/green deployment
- Achieved via AWS route 53 weighted routing
| pros | cons |
|---|---|
| . | Different versions across the environment |
| . | DNS switching affected by caches and other DNS related issues |
- Like A/B testing, but gradually increases percentage of traffic to green environment
- A container for an IAM role that you can use to pass role information to an EC2 instance when the instance starts.
- An EC2 Instance cannot be assigned a role directly, but it can be assigned an Instance Profile which contains a role.
- If you use the AWS Management Console to create a role for Amazon EC2, the console automatically creates an instance profile and gives it the same name as the role.
- If you manage your roles from the AWS CLI or the AWS API, you create roles and instance profiles as separate actions.
- Access Logging is an optional feature of Elastic Load Balancing that is disabled by default.
- After you enable access logging for your load balancer, Elastic Load Balancing captures the logs and stores them in the Amazon S3 bucket as compressed files.
- You can disable access logging at any time.
- Can log every 5 or 60 minutes
- There's no additional charge
- If you have associated your Auto Scaling Group with a Classic Load Balancer, you can use the load balancer health check to determine the health state of instances in your Auto Scaling Group. By default, an Auto Scaling Group periodically checks the health state of each instance.
- Your Application Load Balancer periodically sends requests to its registered targets to test their status. These tests are called health checks.
- The status of the instances that are healthy at the time of the health check is
InService. The status of any instances that are unhealthy at the time of the health check isOutOfService.
- Need end-to-end security
- Encrypt all communication
- Use HTTPS (layer 7) or SSL (layer 4)
- Need to deploy an X.509 certificate on ELB
- Can configure back-end authentication
- Once configured, ELB only communicates with an instance if it has a matching public key
Amazon EC2 Auto Scaling helps you ensure that you have the correct number of Amazon EC2 instances available to handle the load for your application. You create collections of EC2 instances, called Auto Scaling Groups. You can specify the minimum number of instances in each Auto Scaling Group, and Amazon EC2 Auto Scaling ensures that your group never goes below this size. You can specify the maximum number of instances in each Auto Scaling Group, and Amazon EC2 Auto Scaling ensures that your group never goes above this size. If you specify the desired capacity, either when you create the group or at any time thereafter, Amazon EC2 Auto Scaling ensures that your group has this many instances. If you specify scaling policies, then Amazon EC2 Auto Scaling can launch or terminate instances as demand on your application increases or decreases.
- Auto scaling can play a major role in deployments
- Need to avoid downtime during deployments
- How long does it take to deploy code and configure an instance?
- How do you test a new launch configuration?
- How do you phase out older launch configurations?
- Use lifecycle hooks for custom actions
- CloudFormation init scripts
- Cloud init scripts
- Scale out/scale in
- Can launch spot instances as well as on-demand instances (also configure ratio between these instance options)
- On AWS: Service - FAQs - User Guide
- Contains a collection of Amazon EC2 instances that are treated as a logical grouping for the purposes of automatic scaling and management
- To use Amazon EC2 Auto Scaling features such as health check replacements and scaling policies
- Instance configuration template that an Auto Scaling Group uses to launch EC2 instances
- One Launch Configuration per ASG, can be used in many ASGs though
- Can't be modified, needs to be recreated
- To change instance type, copy the old Launch Configuration, change instance type, double max and desired, wait till new values have propagated, revert max and desired
- Similar to Launch Configuration
- Launch Templates can be used to launch regular instances as well as Spot Fleets.
- Allows to have multiple versions of the same template
- Can source another template to build a hierachy
- With versioning, you can create a subset of the full set of parameters and then reuse it to create other templates or template versions
- AWS recommends to use Launch Templates instead of Launch Configurations to ensure that you can use the latest features of Amazon EC2
- To specify which instances to terminate first during scale in, configure a Termination Policy for the Auto Scaling Group.
- Policies will be applied to the AZ with the most instances
- Can be combined with instance protection to prevent termination of specific instances, this starts as soon as the instance is in service.
- Instances can still be terminated manually (unless termination protection has been enabled)
- Unhealthy instance will still be replaced
- Spot instance interuptions can still occur
- Instance protection can also be applied to an Auto Scaling Group - protecting the whole group: protect from scale in
- Can specify multiple policies, will be executed in order until an instance has been found
- Default policy being last in a list of multiple policies is like
catchAll, will always find an instance- Determine which AZ has most instances and at least one instance that's not protected from scale in
- [For ASG with multiple instance types and purchase options]: Try to align remaining instances to allocation strategy
- [For ASG that uses Launch Templates]: Terminate one of the instances with the oldest Launch Template
- [For ASG that uses Launch Configuration]: Terminate one of the instances with the oldest Launch Configuration
- If there are multiple instances to choose from, pick the one nearest to the next billing hour
- Choose one at random
| . | . | . |
|---|---|---|
| 0 | Default | Designed to help ensure that your instances span Availability Zones evenly for high availability3->4->random |
| 1 | OldestInstance | Useful when upgrading to a new EC2 instance type |
| 2 | NewestInstance | Useful when testing a new launch configuration |
| 3 | OldestLaunchConfiguration | Useful when updating a group and phasing out instances |
| 5 | OldestLaunchTemplate | Useful when you're updating a group and phasing out the instances from a previous configuration |
| 4 | ClosestToNextInstanceHour | Next billing hour - useful to maximize instance us |
| 6 | AllocationStrategy | Useful when preferred instance types have changed |
The EC2 instances in an Auto Scaling Group have a path, or lifecycle, that differs from that of other EC2 instances. The lifecycle starts when the Auto Scaling Group launches an instance and puts it into service. The lifecycle ends when you terminate the instance, or the Auto Scaling group takes the instance out of service and terminates it.
Allows to cater for applications that take longer to deploy/tear-down.
After Lifecycle Hooks are added to the instance:
- ASG responds to scale-out/scale-in events
- Lifecycle Hook puts instance into
pending:wait/terminating:waitstate, instance is paused until we continue or timeout- This can be extended by configuring a heartbeat
- Custom actions are performed through one or more of these options:
- CloudWatch Events target to invoke Lambda function
- Notification target for Lifecycle Hook is defined
- Script on instance runs as instance starts, script can control lifecycle actions
- Can also notify SQS or SNS, but Lambda is the preferred option
- Going into
pending:proceed/terminating:proceedafter that. - By default, the instance remains in a wait state for one hour, and then the Auto Scaling Group continues the launch or terminate process
| . | . |
|---|---|
| Scale out | scale out -> Pending -> Pending:Wait -> Pending:Proceed -> InService |
| Scale in | scale in -> Terminating -> Terminating:Wait -> Terminating:Proceed -> Terminated |
| Troubleshoot | InService -> StandBy |
Scaling is the ability to increase or decrease the compute capacity of your application. Scaling starts with an event, or scaling action, which instructs an Auto Scaling Group to either launch or terminate Amazon EC2 instances.
- Manual scaling
- Specify min/max/desired
- Scheduled scaling
- Specify time and date
- Scaling Policies
- Target Tracking Scaling Policy
- With target tracking scaling policies, you select a scaling metric and set a target value. Amazon EC2 Auto Scaling creates and manages the CloudWatch alarms that trigger the scaling policy and calculates the scaling adjustment based on the metric and the target value.
- Simple Scaling Policy
- With simple and step scaling policies, you choose scaling metrics and threshold values for the CloudWatch alarms that trigger the scaling process.
- Both require you to create CloudWatch alarms for the scaling policies.
- Both require you to specify the high and low thresholds for the alarms.
- Both require you to define whether to add or remove instances, and how many, or set the group to an exact size.
- Step Scaling Policy
- The main difference between the policy types is the step adjustments that you get with step scaling policies. When step adjustments are applied, and they increase or decrease the current capacity of your Auto Scaling Group, the adjustments vary based on the size of the alarm breach.
- We recommend that you use step scaling policies instead of simple scaling policies, even if you have a single scaling adjustment
- After a scaling activity is started, the policy continues to respond to additional alarms, even while a scaling activity or health check replacement is in progress.
- Therefore, all alarms that are breached are evaluated by Amazon EC2 Auto Scaling as it receives the alarm messages.
- However, scaling actions from previous alarms are taken into account (thereby not changing the absolute outcome of the scaling action)
- Target Tracking Scaling Policy
- Predictive scaling
- AWS using data collection from actual EC2 usage
Protect instances from scaling in by setting termination protection, e.g. per API call
- Long running workers
- 'Special' instances, e.g. master of a cluster
- Can send SNS notifications
- Success/failure on instance launch/termination
- Better to integrate with CloudWatch Events
- No direct integration with CloudWatch Logs
- However if the CloudWatch agent is installed on the instances they will send logs
Amazon EC2 Auto Scaling can determine the health status of an instance using one or more of the following:
- Status checks provided by Amazon EC2 to identify hardware and software issues that may impair an instance. The default health checks for an Auto Scaling group are EC2 status checks only.
- Health checks provided by Elastic Load Balancing (ELB). These health checks are disabled by default but can be enabled.
- Your custom health checks.
ALB -> Target Group <- ASG
- Configure ASG
- Target Group from ALB
- Health Check Type ELB
- Can configure Slow Start Mode on Target Group level (up to 15min), so that new instances don't get the full load immediately
- Should redirect from http (80) to https (443)
- Can put instances into Standby so that they don't receive traffic.
- Can put instances into Scale In Protection so that they don't get terminated on Scale In.
- Install CodeDeploy agent on instances as per UserData
- Create CodeDeploy Application and Deployment and tie it to the Auto Scaling Group
- CodeDeploy will create Deployments for existing and new instances
- Can choose between in-place and blue-green deployments
- Blue-green will provision new Auto Scaling Group
- Must have a load balancer configured so that traffic can be switched over
- Blue-green will provision new Auto Scaling Group
- When deploying a new application version this will not be considered 'latest' until it has succeeded
- So for Auto Scaling events, the old version is still getting deployed
- CreationPolicy
- Wait for notification from instances that they created successfully
- Instances use
cfn-signalin UserData section
- UpdatePolicy
- If Launch Configuration or Launch Template are changing, deployed instances will not update unless defined in UpdatePolicy
- Can configure policy for rolling, replacing and scheduled updated
- It's common pattern to have instances from within an ASG consuming messages from SQS
- Can implement custom metric in CloudWatch to control Auto Scaling behaviour
- E.g. size of individual backlog on instances
| Name | Before | Intermediate | After |
|---|---|---|---|
| In Place | [ASG [Instance 1]] |
- | [ASG [Instance 2] |
| Rolling | [ASG [Instance 1]] |
[ASG [Instance 1,2]] |
[ASG [Instance 2] |
| Replace | [ALB [ASG1 [...]]] |
[ALB [ASG1 [...]][ASG2 [...]] |
[ALB [ASG2 [...]]] |
| Blue/Green | [R53 [ALB1 [ASG1 [...]]]] |
[R53 [ALB1 [ASG1 [...]]]][ALB2 [...]] |
[R53 [ALB2 [ASG2 [...]]]] |
- Attempting to use wrong subnet
- AZ no longer available or supported (outage)
- Security group does not exist
- Associated keypair does not exist
- Auto scaling configuration is not working correctly
- Instance type specification does not exist in that AZ
- Invalid EBS device mapping
- Attempt to attach EBS block device to instance-store AMI
- AMI issues
- Attempt to use placement groups with instance types that don't support that
- AWS running out of capacity in that AZ
- If an instance is stopped, e.g. for updating it, auto scaling will consider it unhealthy and terminate - restart it. Need to suspend auto scaling first.
You can suspend and then resume one or more of the scaling processes for your Auto Scaling Group. This can be useful for investigating a configuration problem or other issues with your web application and making changes to your application without invoking the scaling processes.
| . | . |
|---|---|
Launch |
Disrupts other processes as no more scale out |
Terminate |
Disrupts other processes as no more scale in |
HealthCheck |
. |
ReplaceUnhealthy |
. |
AZRebalance |
. |
AlarmNotification |
Suspends actions normally triggered by alarms |
ScheduledAction |
. |
AddToLoadBalancer |
Will not automatically add instances later |
- Can download Amazon Linux 2 AMI in VM format to run on-premises
- Can import existing VMs into EC2
- Gather information about On-premises instances to plan a migration
- Server utilization and dependency mappings
- Track with AWS Migration Hub
- Replicate
- On-prem -> AWS
- AWS -> On-prem
- AWS -> AWS
- Incremental replication of on-prem instances into AWS
A tag is a label that you or AWS assigns to an AWS resource. Each tag consists of a key and a value. For each resource, each tag key must be unique, and each tag key can have only one value. You can use tags to organize your resources, and cost allocation tags to track your AWS costs on a detailed level. After you activate cost allocation tags, AWS uses the cost allocation tags to organize your resource costs on your cost allocation report, to make it easier for you to categorize and track your AWS costs. AWS provides two types of cost allocation tags, an AWS generated tags and user-defined tags. AWS defines, creates, and applies the AWS generated tags for you, and you define, create, and apply user-defined tags. You must activate both types of tags separately before they can appear in Cost Explorer or on a cost allocation report.
- TLS for transit encryption
- ACM to manage SSL/TLS certificates
- Load Balancers
- ELB/ALB/NLB provide SSL termination
- Can have multiple SSL certificates per ALB
- Optional SSL/TLS encryption between ALB and EC2
- CloudFront with SSL
- All AWS services expose https endpoint
- S3 also has http (shouldn't use it)
- S3
- SSE-S3: Server-side encryption using AWS' key
- SSE-KMS: Server-side encryption using own KMS key
- SSE-C: Server-side encryption using own key
- Clinet-side encryption: Already encrypted data is send through to AWs
- Can enable default encryption on S3 buckets
- Can enforce encryption via bucket policy
- Glacier is encrypted by default
- Other services:
- Easy to configure for EBS, EFS, RDS, ElastiCache, DynamoDB, ...
- Usually either service encryption key or own KMS key
- Easy to configure for EBS, EFS, RDS, ElastiCache, DynamoDB, ...
- Data categories:
- PHI - protected health information
- PII - personally-identifying information
- Direct Connect
- Private direct connection between on-site and AWS
- Public Internet: Use VPN
- Site-to-site VPN that supports Internet Protocol Security (IPsec)
- Network ACLs for instance protection
- WAF - Web Application Firewall
- Security Groups
- System Firewalls running on EC2 instances
- Assign AZ
- ELB, EFS, ASG, Elastic Beanstalk
- Synchronous database for failover in different AZ
- RDS, ElastiCache, Aurora (for DB itself, data is already multi AZ)
- Elasticsearch
- S3 (with the exception of One Zone Infrequent Access)
- DynamoDB
- All of AWS' propriertrary services
| . | . |
|---|---|
| DynamoDB Global Tables | multi-way replication, implemented by Streams |
| AWS Config Aggregators | multi region as well as multi account |
| RDS | Cross-region read replicas |
| Aurora Global Database | One region is master, other for read & DR |
| EBS/AMI/RDS | Snapshots |
| VPC Peering | Private traffic between VPCs between regions |
| Route 53 | Uses global network of DNS servers |
| S3 | Cross-region replication |
| CloudFront | Global CDN at Edge Locations |
| Lambda@Edge | For global Lambda functions at Edge Locations |
| CloudFormation | StackSets |
| CodePipeline | action can be region specific -> multi-region deploys |
- Deploy stacks behind ALB in different regions
- Use Route 53 routing
- Latency
- Geo-proximity
- Configure health checks
- Trigger automated DNS failover
- E.g. base health checks on CloudWatch Alarms
| . | . |
|---|---|
| IAM | Define IAM Trust to enable cross account actions Use STS to assume into roles in different accounts |
| CodePipeline | Trigger CodeDeploy across accounts |
| AWS Config | Agregate across accounts |
| CloudWatch Events | Use EventBus to share events across accounts |
| CloudWatch Logs | Use Logs Destination to send events into logging account |
| CloudFormation | StackSets can be deployed across accounts |
| CloudTrail | Can deliver trails into cross-account bucket |
- DR is about preparing for and recovering from a disaster
- Recovery Point Objective - RPO
- How often do you run backups? How much data will be lost (since last backup)
- Recovery Time Objective - RTO
- How much downtime is acceptable?
| From | To | . |
|---|---|---|
| On-prem | On-prem | Traditional DR, very expensive |
| On-prem | Cloud | Hybrid recovery |
| Cloud Region A | Cloud Region B | . |
| . | RPO | RTO | Costs | Comment | What to do for DR |
|---|---|---|---|---|---|
| Backup & Restore | High | High | $ | Regular backups | Restore |
| Pilot Light | Medium | Medium | $$ | Core system is always running | Add non-critical systems |
| Warm Standby | Low | Low | $$$ | Full system at minimum size always running | Add resources |
| Multi Site/Hot Site | Lowest | Lowest | $$$$ | Full system at production size always running | Only switch traffic |
| Service | What it does | Will warn about (example) |
|---|---|---|
| Amazon Inspector | * Application and service security, scans EC2 instances for CVEs * Network scans |
Root login via ssh not disabled |
| Config | * Ensure instance has proper AWS configuration, e.g. no open SSH port * Track audit and compliance over time |
Checks whether Amazon SNS topic is encrypted with KMS |
| GuardDuty | * Scans accounts and workloads | Instance has bitcoin activiy, unusual console logins (e.g. new location) |
| Macie | * Protects data | SSH private key uploaded to S3 |
| Security Hub | * Aggregates view from GuardDuty, Amazon Inspector, Macie, IAM Access Analyzer, AWS Firewall Manager. Also integrates 3rd party services |
Whatever was integrated with SecurityHub |
| Service Catalog | * Restrict how instances are launched by minimizing configuration | . |
| Systems Manager | * Run automations, patches, commands, inventory at scale | . |
| TrustedAdvisor | * Scans accounts, recommends cost optimisations, fault tolerance, performance, service limits, security | Open security groups, EBS snapshot permissions |
| Service | SNS (native) | CloudWatch/EventBridge Events | CloudWatch Metrics/Alarms | Comment |
|---|---|---|---|---|
| Amazon Inspector | + | - | + (every 5 min) |
Notify SNS on assessment run and findings |
| API Gateway | - | - | + (API monitoring) |
. |
| Auto Scaling Lifecycle Hooks | + SNS or SQS |
+ | + | . |
| CloudFormation | + | - | - | . |
| CloudTrail | + | - | - | . |
| CodeBuild | - | + | + | . |
| CodeCommit | + Trigger to SNS or Lambda Notification to SNS or Chatbot(Slack) |
+ | - | |
| CodeDeploy | + Trigger to SNS Notification to SNS or Chatbot(Slack) |
+ | - | . |
| CodePipeline | + Notification to SNS or Chatbot(Slack) |
+ | - | . |
| Config | + All events only |
+ | - | . |
| ECS | - | + | + | . |
| Elastic Beanstalk | + | - | + minimal, environment health only |
. |
| GuardDuty | - | + | - | . |
| Kinesis | - | - | - | . |
| Lambda | - | - | + | . |
| Macie | - | + | - | . |
| OpsWorks | - | + | + | . |
| S3 | + Event notifications: SNS SQS Lambda |
- | + | documentation |
| Server Migration Service | - | + | - | . |
| Service Catalog | + | - | + | . |
| Systems Manager | + | + | + Run Command metrics |
Various CloudWatch Events |
| Trusted Advisor | - | + | + | documentation |
- All services have API calls delivered to EventBridge via CloudTrail.
- EventBridge supports many services.
- All services that publish CloudWatch Metrics.
- Can replace CodeBuild, CodePipeline, CodeDeploy
- Tight integration with those services
- Master/Slave setup
- Master/slaves can run on the same instance, but usually run on separate instances
- Can have multiple master with respective set of slaves assigned to them
- Must manage Multi-AZ, deploy on EC2, ...
Jenkinsfileto configure CI/CD- Many AWS plugins
- CodePipeline can send build jobs to Jenkins instead of CodeBuild
- Jenkins can pull from CodeCommit and eg. upload build result to ECR, invoke Lambda, ...
- Direct Jenkins support in CodePipeline, requires CodePipeline-plugin on the Jenkins end
- EC2-Plugin
- Allows Jenkins to start agents on EC2 on demand, and kill them as they get unused.
- Also support spot instances
- CodeBuild-Plugin
- Send builds to CodeBuild
- Official AWS plugin
- ECS-Plugin
- Launch slaves into ECS
Amazon EMR is a managed cluster platform that simplifies running big data frameworks, such as Apache Hadoop and Apache Spark, on AWS to process and analyze vast amounts of data. By using these frameworks and related open-source projects, such as Apache Hive and Apache Pig, you can process data for analytics purposes and business intelligence workloads. Additionally, you can use Amazon EMR to transform and move large amounts of data into and out of other AWS data stores and database, such as Amazon Simple Storage Service (Amazon S3) and Amazon DynamoDB.
Use cases:
- Machine learning
- Extract transform load (ETL)
- Clickstream analysis (from S3, using Apache Spark and Apache Hive)
- Real-time streaming
- Interactive analytics
- Genomics
Amazon Inspector is an automated security assessment service that helps improve the security and compliance of applications deployed on AWS. Amazon Inspector automatically assesses applications for exposure, vulnerabilities, and deviations from best practices. After performing an assessment, Amazon Inspector produces a detailed list of security findings prioritized by level of severity. These findings can be reviewed directly or as part of detailed assessment reports which are available via the Amazon Inspector console or API.
Amazon Inspector security assessments help you check for unintended network accessibility of your Amazon EC2 instances and for vulnerabilities on those EC2 instances. Amazon Inspector assessments are offered to you as pre-defined rules packages mapped to common security best practices and vulnerability definitions. Examples of built-in rules include checking for access to your EC2 instances from the internet, remote root login being enabled, or vulnerable software versions installed. These rules are regularly updated by AWS security researchers.
- Network Assessments
- Does not require agent
- Host Assessments
- Requires agent
- Can automate assessments via scheduled CloudWatch Events
- Can use tag to find instances to asses
- Cannot launch AMI, requires instance
- Assessment templates can notify SNS
- Could trigger Lambda to remediate EC2 findings via SSM documents
- On AWS: Service - FAQs - User Guide
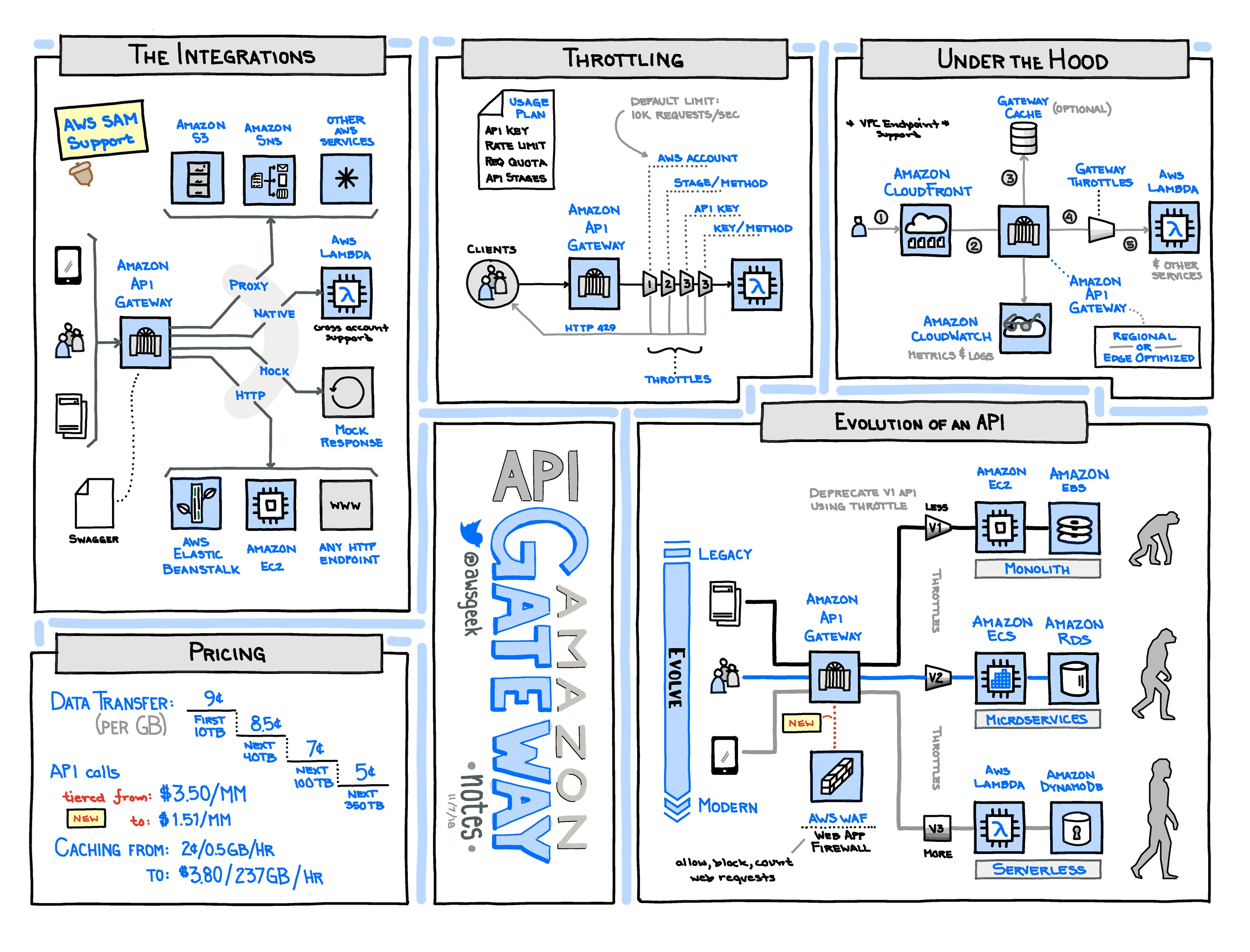
Amazon API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. With a few clicks in the AWS Management Console, you can create REST and WebSocket APIs that act as a “front door” for applications to access data, business logic, or functionality from your backend services, such as workloads running on Amazon Elastic Compute Cloud (Amazon EC2), code running on AWS Lambda, any web application, or real-time communication applications.
- On AWS: Service - FAQs - User Guide
- See also: AWS Geek 2020
- See also: AWS Geek 2018
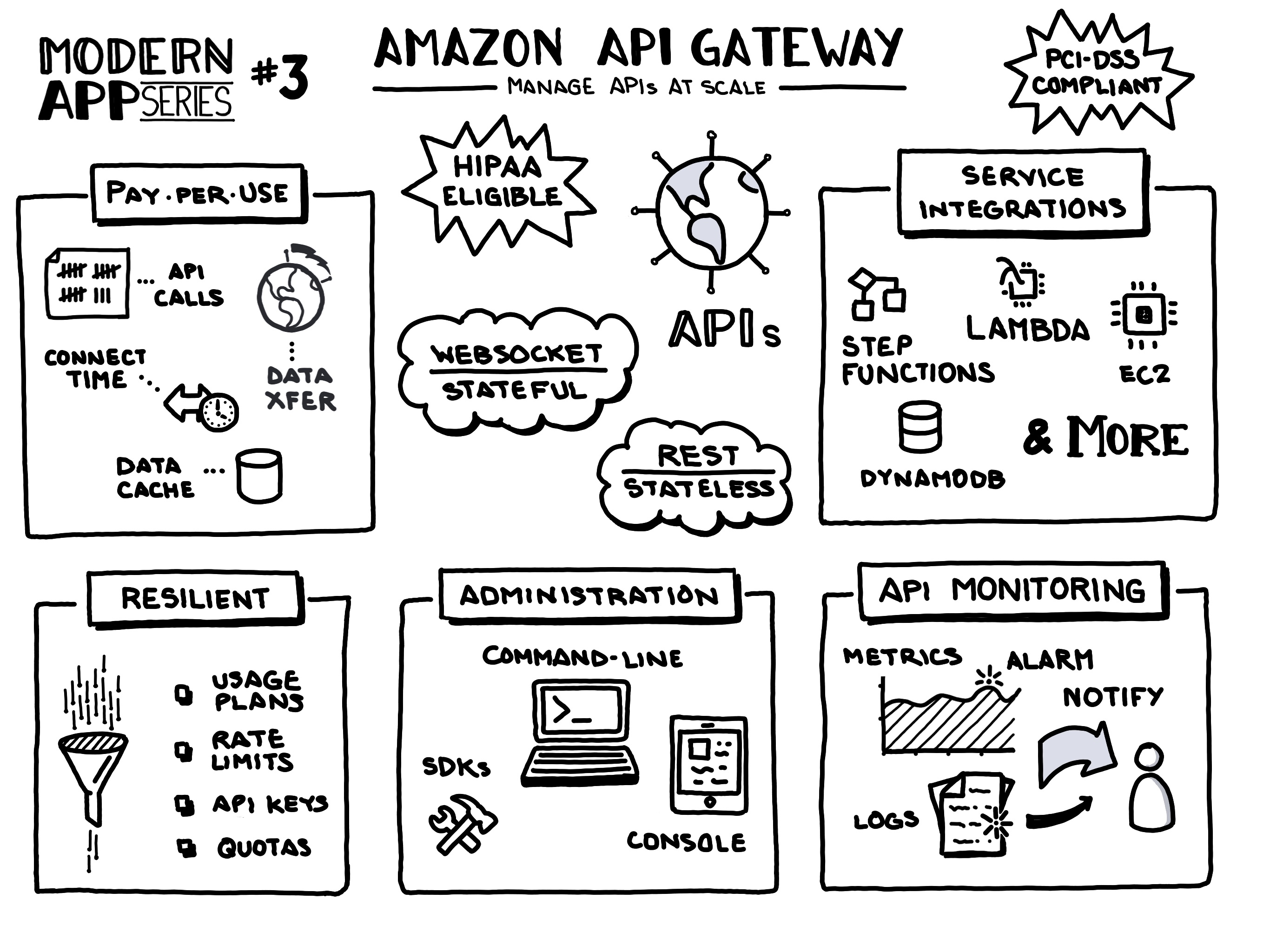{kind=link}
{kind=link}
- RESTful (stateless) or Websocket (stateful) APIs
- Powerful, flexible authentication mechanisms, such as AWS IAM policies, Lambda authorizer functions, and Amazon Cognito user pools.
- Developer portal for publishing your APIs.
- Canary release deployments for safely rolling out changes.
- CloudTrail logging and monitoring of API usage and API changes.
- CloudWatch access logging and execution logging, including the ability to set alarms.
- Ability to use AWS CloudFormation templates to enable API creation
- Support for custom domain names.
- Integration with AWS WAF for protecting your APIs against common web exploits.
- Integration with AWS X-Ray for understanding and triaging performance latencies.
A hostname for an API in API Gateway that is deployed to a specific region. The hostname is of the
form {api-id}.execute-api.{region}.amazonaws.com.
The following types of API endpoints are supported:
- Regional - deployed to the specified region and intended to serve clients in the same AWS region.
- Edge Optimized - deployed to the specified region while using a CloudFront distribution to facilitate client access typically from across AWS regions
- Private - exposed through interface VPC endpoints
A logical reference to a lifecycle state of your REST or WebSocket API (for example, dev, prod,
beta, v2).
- API stages are identified by API ID and stage name.
- Each stage has its own configuration parameters.
- Can be rolled back in history.
- Have stage variables, that are like environment variables for API Gateway.
- Can be used to configure enpoints that the stage talks to.
- Accessible from Lambda context as well.
- Can enable canary deployments for a stage (usually
PROD)- Canaray releases attaches a new version to an existing stage deployment and randomly shift traffic over
- Logs and metrics are generated separately for all canary requests
- This is blue/green for API Gateway/Lambda
After creating your API, you must deploy it to make it callable by your users. To deploy an API, you create an API deployment and associate it with a stage. Each stage is a snapshot of the API and is made available for client apps to call.
- Use stage variables for canary deployments
- Integrate Lambda via alias:
GetStartedLambdaProxyIntegration:${stageVariables.lambdaAlias} - Overwrite stage variable in canary deployment
- Integrate Lambda via alias:
- Could also use Lambda's canary functionality with weighted aliases
- Lambda Proxy - request is passed through straight to a Lambda
- Proxy Lambda deals with complete
httprequest
- Proxy Lambda deals with complete
- Lambda Non-Proxy/Custom
- Allows integration of mapping template
- Can transform request as well as response
- Allows to evolve the API while keeping Lambda function static
- Any service
- All AWS services support dedicated APIs to expose their features. However, the application protocols or programming interfaces are likely to differ from service to service. An API Gateway API with the AWS integration has the advantage of providing a consistent application protocol for your client to access different AWS services.
- A scripts in Velocity Template Language (VTL) that transforms a request body from the frontend data format to the backend data format.
- Cannot add default values to fields, only add new static fields
A data schema specifying the data structure of a request or response payload.
- Account-wide limit of 10,000 requests per second.
- Applies at service/account level
- Can create usage plan:
- Rate, burst, quota
- Can assoicate with stage/method/API key (to limit certain clients)
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run.
Athena is easy to use. Simply point to your data in Amazon S3, define the schema, and start querying using standard SQL. Most results are delivered within seconds. With Athena, there’s no need for complex ETL jobs to prepare your data for analysis. This makes it easy for anyone with SQL skills to quickly analyze large-scale datasets.
Athena is out-of-the-box integrated with AWS Glue Data Catalog, allowing you to create a unified metadata repository across various services, crawl data sources to discover schemas and populate your Catalog with new and modified table and partition definitions, and maintain schema versioning.
- On AWS: Service - FAQs - User Guide
AWS CloudFormation provides a common language for you to describe and provision all the infrastructure resources in your cloud environment. CloudFormation allows you to use a simple text file to model and provision, in an automated and secure manner, all the resources needed for your applications across all regions and accounts. This file serves as the single source of truth for your cloud environment.
AWS CloudFormation is available at no additional charge, and you pay only for the AWS resources needed to run your applications.
- Allows to create and provision resources in a reusable template fashion
- Declarative - no need for ordering and orchestration
- Separation of concerns - different stacks for different purposes
- On AWS: Service - FAQs - User Guide
A CloudFormation template is a JSON or YAML formatted text file
| Element | Comment |
|---|---|
AWSTemplateFormatVersion |
2010-09-09 |
Description |
. |
Metadata |
Details about the template |
Parameters |
Values to pass in right before template creation |
Mappings |
Maps keys to values (eg different values for different regions) |
Conditions |
Check values before deciding what to do |
Resources |
Creates resources - only mandatory section in a template |
Outputs |
Values to be exposed from the console or from API calls |
- Type:
String,Number,List,CommaDelimitedList, AWS-specific types likeAWS::EC2::KeyPair::KeyName, SSM-Parameter key (AWS::SSM::Parameter)- SSM SecureString is not supported
- Description, Default Value, Allowed Values, Allowed Pattern
- Validation: regular expression/MinLength/MaxLength/MinValue/MaxValue
- Can set
NoEchofor secrets, will be masked with**** - Can set
UsePreviousValuefor stack updates - Pseudo parameters are parameters that are predefined by AWS CloudFormation. You do not declare them in your template. Use them the same way as you would a parameter, as the argument for the Ref function.
AWS::AccountId,AWS::NotificationARNs,AWS::NoValue,AWS::Partition,AWS::Region,AWS::StackId,AWS::StackName,AWS::URLSuffix
- Reference a parameter within the template
!Ref myParam - Usage of parameters might make it hard to instantiate stacks
- Fixed (hardcoded) variables within CloudFormation template
RegionMap:
us-east-1:
HVM64: ami-0ff8a91507f77f867
HVMG2: ami-0a584ac55a7631c0c
us-west-1:
HVM64: ami-0bdb828fd58c52235
HVMG2: ami-066ee5fd4a9ef77f1
...
myEC2Instance:
Type: "AWS::EC2::Instance"
Properties:
ImageId: !FindInMap [RegionMap, !Ref "AWS::Region", HVM64]
Conditions:
CreateProdResources: !Equals [ !Ref EnvType, prod ]
- Can use (and combine)
Fn::And,Fn::Equals,Fn::If,Fn::Not,Fn::Or
- Over 220 types of resources,
AWS::aws-product-name::data-type-name - AWS figures out creation, update and delete of resources for us
- Update can impact a resource in 4 possible ways
- No interruption
- E.g. change
ProvisionedThroughputof a DynamoDB table
- E.g. change
- Some interruption
- E.g. change
InstanceTypeof an EC2 instance
- E.g. change
- Replacement
- E.g. change
AvailabilityZoneof an EC2 instance - E.g. change
ImageIdof an EC2 instance - E.g. change
Tablenameof a DynamoDB table
- E.g. change
- No interruption
- Update can impact a resource in 4 possible ways
- Can toggle creation with
Condition:Resources: MountPoint: Type: "AWS::EC2:VolumeAttachment" Condition: CreateProdResources
- Can be
- constructed value/parameter reference/pseudo parameter/output from a function like
fn::getAttorRef
- constructed value/parameter reference/pseudo parameter/output from a function like
- Can be used in a different stack (cross stack references)
!ImportValue NameOfTheExport- Cannot delete stack if its outputs are used in another stack
- Used to pass in values that are not available until runtime
- Usable in
resources,outputs,metadataattributes andupdate policyattributes (auto scaling). You can also use intrinsic functions to conditionally create stack resources. - Most intrinsic functions have a short and a long form (not
Ref):Fn::GetAtt: [ logicalNameOfResource, attributeName ]!GetAtt logicalNameOfResource.attributeName
| Name | Attributes | Description |
|---|---|---|
Ref |
logicalName | * Returns the default value of the specified parameter. For resource typically physical id |
Fn::Base64 |
valueToEncode | * Provides encoding, converts from plain text into base64 |
Fn::Cidr |
ipBlock, count, cidrBits | * Returns an array of CIDR address blocks. The number of CIDR blocks returned is dependent on the count parameter |
Fn::FindInMap |
MapName, TopLevelKey, SecondLevelKey | * Returns the value corresponding to keys in a two-level map that is declared in the Mappings section |
Fn::GetAtt |
logicalNameOfResource, attributeName | * Returns the value of an attribute from an object, either the default or the specified attribute * Object is either from the same or a nested template |
Fn::GetAZs |
region | * Returns an array that lists Availability Zones for a specified region * If region is omitted return AZs from the region the template is applied in |
Fn::If |
boolean, string1, string2 | * Returns string1 if boolean is true, string2 otherwise |
Fn::And, Fn::Equals, Fn::Or, Fn::Not |
. | * Good for condition element |
Fn::ImportValue |
sharedValueToImport | * Returns the value of an Output exported by another stacki * You can't delete a stack if another stack references one of its outputs. * You can't modify or remove an output value that is referenced by another stack. |
Fn::Join |
delimiter, [ comma-delimited list of values ] | * Joins a set of values into a single value separated by the specified delimiter |
Fn::Select |
index, listOfObjects | * Returns a single object from a list of objects by index |
Fn::Split |
delimiter, source string | * Split a string into a list of string values so that you can select an element from the resulting |
Fn::Sub |
- String - { key: Value, ... } |
* Substitutes variables in an input string with values that you specify string list Also: !Sub 'arn:aws:ec2:${AWS::Region}:${AWS::AccountId}:vpc/${vpc}' |
Fn::Transform |
Name: String Parameters: { key: Value, ... } |
* Specifies a macro to perform custom processing on part of a stack template |
- Related resources are managed in a single unit called a stack
- All the resources in a stack are defined by the stack's CloudFormation template
- Controls lifecycle of managed resources
- Stack has
name&id - Can be updated directly or via change set
- Will rollback stack if it fails to create (can be disabled via API/console)
- Possible to detect stack drift, if supported by created rersources
- Can enable termination protection
- Can send stack events to SNS topic
- A stack policy is an IAM-style policy statements that governs who can do what
-
Defines which actions can be performed on specified resources.
-
With CloudFormation stack policies you can protect all or certain resources in your stacks from being unintentionally updated or deleted during the update process.
-
Check stack policy if updates are allowed
- No policy present: All updates are allowed -> This differs from IAM default!
- Once a policy is applied
- It cannot be updated or removed from the stack (deleted)
- All resources that are not explicitely allowed are denied
- Default deny can be explicitely overwritten
- Policy format JSON
- Contains policy documents
-
Don't confuse with
DeletionPolicy,UpdatePolicy,UpdateRollbackPolicyattributes
-
| Element | . |
|---|---|
Effect |
. |
Principal |
Must be wildcard for stack policies |
Action |
Update:Modify,Update:Replace,Update:Delete,Update:(wildcard) |
Resource,NotResource |
. |
Condition |
Typically evaluates based on resource type |
- Template upload into S3 bucket
- Template syntax check
- CloudFormation will check for any IAM resources being created, and require
CAPABILITY_IAM|CAPABILITY_NAMED_IAMif so - Will raise
InsufficientCapabilitiesotherwise
- CloudFormation will check for any IAM resources being created, and require
- Stack name & parameter verification & ingestion (apply default values)
- Template processing & stack creation
- Resource ordering
- Natural ordering
- CloudFormation knows about 'natural' dependencies between resources.
- DependsOn
- Also
DependsOnattribute - Allows to direct CloudFormation on how to handle more complex dependencies
- Applies to creation as well as deletion & rollback
DependsOncan be a single resource or a list of resources- Will error on circular dependencies
DependsOnis problematic if the target resource needs more complex setup than just stack creation
- Also
- -> Wait conditions allow further control about what happens when
- Natural ordering
- Resource creation
- Will try to create as many resources as possible in parallel
- Includes pausing and waiting for other resources to be created first
- Associate the
CreationPolicyattribute with a resource to prevent its status from reaching create complete until AWS CloudFormation receives a specified number of success signals or the timeout period is exceeded.
- Output creation
- Resource ordering
- Stack completion or rollback
- Rollback settings can be provided while creating the stack
onFailure-ROLLBACK|DELETE|DO_NOTHING
- Can try to manually resolve problems if in state
UPDATE_ROLLBACK_FAILED
- Rollback settings can be provided while creating the stack
- Direct updates
- You submit changes and AWS CloudFormation immediately deploys them
- Change sets
- You can preview the changes AWS CloudFormation will make to your stack, and then decide whether to apply those changes by executing the change set
- Change sets are JSON-formatted documents that summarize the changes AWS CloudFormation will make to a stack
- Use the
UpdatePolicyattribute to specify how AWS CloudFormation handles updates to theAWS: AutoScaling::AutoScalingGroup,AWS::ElastiCache::ReplicationGroup,AWS::Elasticsearch::DomainorAWS::Lambda::Aliasresources.- Values depend on resource type, e.g. ASG replacing vs rolling update
- Use the
UpdateReplacePolicyattribute to retain or (in some cases) backup the existing physical instance of a resource when it is replaced during a stack update operation. - On Failure, the stack will rollback automatically to the last known working state
- Interuption while updating
- Update can impact a resource in 3 possible ways
- No interruption
- E.g. change
ProvisionedThroughputof a DynamoDB table
- E.g. change
- Some interruption
- E.g. change
EbsOptimizedof an EC2 instance (EBS-backed) - E.g. change
InstanceTypeof an EC2 instance (EBS-backed)
- E.g. change
- Replacement
- E.g. change
AvailabilityZoneof an EC2 instance - E.g. change
ImageIdof an EC2 instance - E.g. change
Tablenameof a DynamoDB table
- E.g. change
- No interruption
- Update can impact a resource in 3 possible ways
- Specify the stack to delete, and AWS CloudFormation deletes the stack and all the resources in that stack.
- With the
DeletionPolicyattribute you can preserve or (in some cases) backup a resource when its stack is deleted. - If AWS CloudFormation cannot delete a resource, the stack will not be deleted.
- A stack can have termination protection enabled, which will prevent it from being deleted accidentally
- Resource Deletion policy
- Policy/statement that is associated with every resource of a stack
- Controls what happens if stack is deleted
DeletionPolicyDelete- (default)
- Creates transitive environment - immutable architecture
Retain- Obviously needs further cleanup - non-immutable architecture
Snapshot- Takes snapshot prior to deletion
- Some resourcetypes only
AWS::EC2::VolumeAWS::ElastiCache::CacheClusterAWS::ElastiCache::ReplicationGroupAWS::Neptune::DBClusterAWS::RDS::DBClusterAWS::RDS::DBInstanceAWS::Redshift::Cluster
- Allow data recovery at a later stage
StackSets lets you create stacks in multiple AWS accounts across multiple regions by using a single CloudFormation template. All the resources included in each stack are defined by the stack set's AWS CloudFormation template. As you create the stack set, you specify the template to use, as well as any parameters and capabilities that template requires.
- Can roll out from Organizations master account
- To all accounts
- to all accounts of an OU
- Stack sets are created in a region of an administrator account
- A stack instance is a reference to a stack in a target account within a region
- Can exist without a stack, e.g. if stack failed to create, then the stack instance shows the reason for that
- Operations: Create, Update, Delete
- For updates, can choose to overwrite parameters only for some accounts/regions
| Operation options | . |
|---|---|
| Maximum concurrent accounts | Maximum number or percentage of target accounts in which an operation is performed at one time |
| Failure tolerance | Maximum number or percentage of stack operation failures that can occur, per region, beyond which AWS CloudFormation stops an operation automatically |
| Retain stack (delete operations only) | Keep stacks and their resources running even after they have been removed from a stack set |
| Script Name | Purpose |
|---|---|
cfn-init |
Use to retrieve and interpret resource metadata, install packages, create files, and start services. |
cfn-signal |
Use to signal with a CreationPolicy or WaitCondition, so you can synchronize other resources in the stack when the prerequisite resource or application is ready. |
cfn-get-metadata |
Use to retrieve metadata for a resource or path to a specific key. |
cfn-hup |
Use to check for updates to metadata and execute custom hooks when changes are detected. |
- CloudFormation User Data
- Scripts and commands to be passed to a launching EC2 instance.
- Failing user data scripts don't fail the CFN stack
- Logged to
/var/log/cloud-init-output.log - Needs to be base64-encoded
UserData:
Fn::Base64: |
#!/bin/bash -x
...
- cfn-init
- Use the AWS::CloudFormation::Init type to include metadata on an Amazon EC2 instance for the cfn
init helper script. If your template calls the
cfn-initscript, the script looks for resource metadata rooted in theAWS::CloudFormation::Initmetadata key. - Different sections:
packages,groups,users,sources,files,commands,services - Need to make sure
aws-cfn-bootstrapis in place und up to date - Logged to
/var/log/cfn-init.log - Can use WaitCondition/
cfn-signalto make CloudFormation wait for successful finish of code
- Use the AWS::CloudFormation::Init type to include metadata on an Amazon EC2 instance for the cfn
init helper script. If your template calls the
- By default, user data scripts and cloud-init directives run only during the boot cycle when you first launch an instance.
- Can use
cfn-hupto detect changes in resource metadata and run user-specified actions when a change is detected - Use
cfn-get-metadatato fetch a metadata block from AWS CloudFormation and print it to standard out
Creation Policy
- Can (only) be used for EC2 Instances and Auto Scaling Groups
- Creation policy definion
- Defines desired signal count & waiting period
- Signal configuration
- Call to
cfn-signalfrom EC2 user-data
- Call to
AutoScalingGroup:
Type: AWS::AutoScaling::AutoScalingGroup
Properties:
...
CreationPolicy:
ResourceSignal:
Count: '3'
Timeout: PT15M
LaunchConfig:
Type: AWS::AutoScaling::LaunchConfiguration
Properties:
...
UserData:
"Fn::Base64":
!Sub |
#!/bin/bash -xe
yum update -y aws-cfn-bootstrap
/opt/aws/bin/cfn-signal -e $? --stack ${AWS::StackName} --resource AutoScalingGroup --region ${AWS::Region}
Wait Conditions and Handlers
- For other resources (external to the stack)
- Wait condition handler
- CloudFormation resource with no properties
- Generates signed URL to communicate success or failure
- URL can be used by
cfn-signalto send data to- Takes custom data as well
- Wait condition
- Links handler and resource
- Know which resource they depend on
- Hold reference to handler
- Have response timeout
- Have a desired count (defaults to 1)
- Allows to define complex wait order
- Links handler and resource
WebServerGroup:
Type: AWS::AutoScaling::AutoScalingGroup
Properties:
...
WaitHandle:
Type: AWS::CloudFormation::WaitConditionHandle
WaitCondition:
Type: AWS::CloudFormation::WaitCondition
DependsOn: "WebServerGroup"
Properties:
Handle:
Ref: "WaitHandle"
Timeout: "300"
Count:
Ref: "WebServerCapacity"
- Problems with existing CloudFormation resources:
- Sometimes lacks behind AWS services
- Cannot deal with non-AWS resources
- Cannot do much logic beyond the scope of intrinsic functions
- Cannot interact with external services
- Solvable with custom resources:
- Custom resource type that is backed by SNS or Lambda
Type: Custom::NameOfResourceTypeServiceToken: arnOfSnsOrLambda
- If stack is created, updated or deleted a payload is sent to
ServiceToken- Payload contains any custom data that's defined with the resource together with the action type
- This invokes a Lambda that performs any sort of custom action
- Or an SNS topic, e.g. to communicate with on-prem resources
- Returns outcome of operation back to CloudFormation, typically includes custom data as well
- Custom resource type that is backed by SNS or Lambda
- Can detect drift on an entire stack or on a particular resource
- Not supported by all resources types
- CloudFormation
- Compares the current stack configuration to the one specified in the template that was used to create or update the stack
- Reports on any differences, providing you with detailed information on each one.
- Resources in a stack can be references by other stacks
- How to nest
- Declare resources as
AWS::CloudFormation::Stack - Point
TemplateURLto S3 URL of nested stack - Use
Parametersto provide the nested stack with input values (defaults will be used otherwise) - Output values of nested stack are returned to parent (root) stack
!GetAtt nestedStack.Outputs.db_name
- Declare resources as
- Benefits
- Allows infrastructure to be split over many templates
- Allows infrastructure reuse
- Allows to workaround limitations like max resources or max template size
- Considered best practice by AWS
| . | . |
|---|---|
| Max stacks per region | 200 |
| Max templates per region | unlimited |
| Max template size (stored in S3) | 460kB |
| Parameters per stack | 60 |
| Mappings per stack | 100 |
| Resources per stack | 200 |
| Outputs per stack | 60 |
Amazon CloudFront is a web service that speeds up distribution of your static and dynamic web content, such as .html, .css, .js, and image files, to your users. CloudFront delivers your content through a worldwide network of data centers called edge locations. When a user requests content that you're serving with CloudFront, the user is routed to the edge location that provides the lowest latency (time delay), so that content is delivered with the best possible performance.
- CloudFront is usually the cheapest and simplest way to add caching to web application
Lambda@Edge is a feature of Amazon CloudFront that lets you run code closer to users of your application, which improves performance and reduces latency. With Lambda@Edge, you don't have to provision or manage infrastructure in multiple locations around the world. You pay only for the compute time you consume - there is no charge when your code is not running.
With Lambda@Edge, you can enrich your web applications by making them globally distributed and improving their performance — all with zero server administration. Lambda@Edge runs your code in response to events generated by the Amazon CloudFront content delivery network (CDN). Just upload your code to AWS Lambda, which takes care of everything required to run and scale your code with high availability at an AWS location closest to your end user.
Master Lambda, associated withCloudFront distribution trigger->Edge replica- Can use Lambda@Edge for A/B testing
Amazon CloudSearch is a fully managed service in the cloud that makes it easy to set up, manage, and scale a search solution for your website or application.
With Amazon CloudSearch you can search large collections of data such as web pages, document file, forum posts, or product information. You can quickly add search capabilities without having to become a search expert or worry about hardware provisioning, setup, and maintenance. As your volume of data and traffic fluctuates, Amazon CloudSearch scales to meet your needs
AWS CloudTrail is a service that enables governance, compliance, operational auditing, and risk auditing of your AWS account. With CloudTrail, you can log, continuously monitor, and retain account activity related to actions across your AWS infrastructure. CloudTrail provides event history of your AWS account activity, including actions taken through the AWS Management Console, AWS SDKs, command line tools, and other AWS services. This event history simplifies security analysis, resource change tracking, and troubleshooting. In addition, you can use CloudTrail to detect unusual activity in your AWS accounts. These capabilities help simplify operational analysis and troubleshooting.
CloudTrail is enabled by default in every account. All activities in an AWS account are being recorded as CloudTrail events.
- On AWS: Service - FAQs - User Guide
- JSON format, who did what (API calls).
- ~15min delay
- Stored for 90 days
- Can configure what type of events to log
- Management events
- CloudWatch Insights events
- Data events
- One region/all regions/organization-wide
- Store data in nominated S3 bucket, this can be encrypted as well
- Can be in a different region
- Can also deliver and analyse events in a trail with CloudWatch Logs and CloudWatch Events
- Can validate integrity of log files using digest files
- Can deliver trails from multiple accounts into the same bucket
- Change bucket policy to allow that
Amazon CloudWatch is a monitoring and management service built for developers, system operators, site reliability engineers (SRE), and IT managers. CloudWatch provides you with data and actionable insights to monitor your applications, understand and respond to system-wide performance changes, optimize resource utilization, and get a unified view of operational health. CloudWatch collects monitoring and operational data in the form of logs, metrics, and events, providing you with a unified view of AWS resources, applications and services that run on AWS, and on-premises servers. You can use CloudWatch to set high resolution alarms, visualize logs and metrics side by side, take automated actions, troubleshoot issues, and discover insights to optimize your applications, and ensure they are running smoothly.
- Access all your data from a single platform
- Easiest way to collect custom and granular metrics for AWS resources
- Visibility across your applications, infrastructure, and services
- Improve total cost of ownership
- Optimize applications and operational resources
- Derive actionable insights from logs
- On AWS: Service - FAQs - User Guide
- See also: AWS Geek 2019
{kind=link}
- Log events are records of some activity recorded by the application or resource being monitored
- Log streams are sequences of log events from the same source
- Log groups are groups of log streams that share the same retention, monitoring, and access control settings
- Metric filters allow to extract metric observations from ingested events and transform them to data points in a CloudWatch metric
- Search for and match terms, phrases, or values in log events
- Can increment the value of a CloudWatch metric
- Retention settings can be used to specify how long log events are kept in CloudWatch Logs Default: Indefinetely
- Logs can be exported to S3 for durable storage.
- This can be automated with
EventsFilter->Lambda
- This can be automated with
- Allow real-time delivery of log events
- Can create subscription filter for Lambda, Elasticsearch, Kinesis Data/Firehose (not supported from console)
- Only Kinesis Stream supports cross-account
- Need to establish log data sender and log data recipient.
- The log group and the destination must be in the same AWS region. However, the AWS resource that the destination points to can be located in a different region.
- Only Kinesis Stream supports cross-account
| Service | Target(s) |
|---|---|
| Load Balancer Access Logs (ELB, ALB, NLB) |
S3 |
| CloudTrail Logs | S3, CloudWatch |
| VPC Flow Logs | S3, CloudWatch |
| Route 53 Access Logs | CloudWatch |
| S3 Access Logs | S3 |
| CloudFront Access Logs | S3 |
Namespaces
- Container for CloudWatch metrics
- Metrics in different namespaces are isolated from each other
- The AWS namespaces typically use the following naming convention:
AWS/service
Metrics
- Metrics are the fundamental concept in CloudWatch Metrics
- A metric represents a time-ordered set of data points that are published to CloudWatch.
- Available metrics are based on currently used service
- Not everything is available out of the box, e.g. no data on memory usage of EC2 instances
- Can also create Custom Metrics
- Publish individual data points via AWS CLI or API
- Exist only in the region where they were created
- Expire after 15 months if no data is published
aws cloudwatch put-metric-data --metric-name PageViewCount --namespace MyService --value 2 --timestamp 2016-10-20T12:00:00.000Z
- Can also export metrics
get-metric-statistics --namespace <value> --metric-name <value> --start-time <value> --end-time <value>...
- Metrics produced by AWS services are standard resolution by default.
- When you publish a custom metric, you can define it as either standard resolution or high resolution.
- When you publish a high-resolution metric, CloudWatch stores it with a resolution of 1 second, and you can read and retrieve it with a period of 1 second, 5 seconds, 10 seconds, 30 seconds, or any multiple of 60 seconds.
- Higher resolution data automatically aggregates into lower resolution data
| Resolution | Data retention |
|---|---|
| <60s | 3h |
| 60s | 15d |
| 300s (5min) | 63d |
| 3600s (1h) | 15m |
Time Stamps
- Each metric data point must be associated with a time stamp.
- Can be up to two weeks in the past and up to two hours into the future.
Dimension
- A dimension is a name/value pair that is part of the identity of a metric.
- You can assign up to 10 dimensions to a metric.
- Every metric has specific characteristics that describe it, and you can think of dimensions as categories for those characteristics.
- For example 'ec2 instance id'
Statistics
- Statistics are metric data aggregations over specified periods of time
- Average, Sum, Minimum, Maximum, Sample Count, pNN.NN (value of specified percentile)
- Can be computed for any time periods between 60-seconds and 1-day
Period
- The length of time associated with a specific Amazon CloudWatch statistic
Aggregation
- CloudWatch aggregates statistics according to the period length that you specify when retrieving statistics
- Based on thresholds defined on metrics, including custom metrics
- Can only be based on a single metric
- Can trigger Lambda, SNS, email, ...
- Also Auto Scaling or EC2 action
- Alarms do not raise CloudWatch Events themselves
- High resolution alarms down to 10 seconds
- Takes place once, at a specific point in time
- Disable with
mon-disable-alarm-actionsvia CLI
- Disable with
- Can be added to dashboard
- Using alarm actions, you can create alarms that automatically stop, terminate, reboot, or recover your EC2 instances.
- Notfications on billing metrics
- Only available in us-east-1
- Define actions on things that happened
- Or schedule
cron-based events - Events are recorded constantly over time
- Targets process events
- Lambda functions
- Amazon EC2 instances
- Streams in Amazon Kinesis Data Streams
- Delivery streams in Amazon Kinesis Data Firehose
- Log groups in Amazon CloudWatch Logs
- Amazon ECS tasks
- Systems Manager Run Command
- Systems Manager Automation
- AWS Batch jobs
- AWS Step Functions state machines
- Pipelines in AWS CodePipeline
- AWS CodeBuild projects
- Amazon Inspector assessment templates
- Amazon SNS topics
- Amazon SQS queues
- Built-in targets: EC2 CreateSnapshot API call, EC2 RebootInstances API call, EC2 StopInstances API call, and EC2 TerminateInstances API call
- The default event bus of another AWS account
- Rules match incoming events and route them to targets
- CloudTrail integration allows to trigger events on API calls
- ReadOnly calls (
List*,Get*,Describe*) are not supported
- ReadOnly calls (
- CloudTrail integration allows to trigger events on API calls
- E.g. CodeCommit automatically triggers CodePipeline on new commits
- Targets process events
- Can deliver cross-account
- Must be in the same region
- CloudWatch Events in its core
- Adding other (3rd party service partners) event sources into the mix
- On bucket events send to SNS, SQS or Lambda
- Not everything is covered by S3 notifications
- Only object-level operations, not bucket-level
- Can also integrate with CloudTrail, but need a trail configured for that bucket
- Customizable home pages in the CloudWatch console that you can use to monitor your resources in a single correlated view
- Even those resources that are spread across different Regions.
- You can use CloudWatch dashboards to create customized views of the metrics and alarms for your AWS resources.
- Collects metrics and logs from
- EC2 instances (Linux/Windows)
- On-Prem instances (Linux/Windows)
- Stores configuration in SSM parameters
- Easy to share
- Can configure CloudWatch Agent to boot directly from SSM parameter store
- Offers a variety of metrics on top of the EC2 standard metrics
- EC2 metrics are based on what is exposed to the hypervisor.
- Basic Monitoring (default) submits values every 5 minutes, Detailed Monitoring every minute
| Metric | Effect |
|---|---|
CPUUtilization |
The total CPU resources utilized within an instance at a given time. |
DiskReadOps,DiskWriteOps |
The number of read (write) operations performed on all instance store volumes. This metric is applicable for instance store-backed AMI instances. |
DiskReadBytes,DiskWriteBytes |
The number of bytes read (written) on all instance store volumes. This metric is applicable for instance store-backed AMI instances. |
NetworkIn,NetworkOut |
The number of bytes received (sent) on all network interfaces by the instance |
NetworkPacketsIn,NetworkPacketsOut |
The number of packets received (sent) on all network interfaces by the instance |
StatusCheckFailed,StatusCheckFailed_Instance,StatusCheckFailed_System |
Reports whether the instance has passed both/instance/system status check in the last minute. |
- Can not monitor memory usage, available disk space, swap usage
- This can be achieved with the Unified CloudWatch Agent
| Metric | Effect |
|---|---|
GroupMinSizeGroupMinSize |
The minimum/maximum size of the Auto Scaling Group. |
GroupDesiredCapacity |
The number of instances that the Auto Scaling Group attempts to maintain. |
GroupInServiceInstancesGroupPendingInstancesGroupStandbyInstancesGroupTerminatingInstances |
The number of instances that are running/pending (not yet in service)/standby (still running)/ terminating as part of the Auto Scaling Group. |
GroupTotalInstances |
The total number of instances in the Auto Scaling Group. This metric identifies the number of instances that are in service, pending, and terminating. |
| Metric | Effect |
|---|---|
Latency |
Time it takes to receive an response. Measure max and average |
BackendConnectionErrorr |
Number of not successfully established connections to registered instances, measure sum and look at difference between min and max |
SurgeQueueLength |
Total number of request waiting to get routed, look at max and average |
SpilloverCount |
Dropped requests because of exceeded surge queue. Look at sum |
HTTPCode_ELB_4XXHTTPCode_ELB_5XX |
The number of HTTP XXX server error codes that originate from the load balancer. This count does not include any response codes generated by the targets. Look at sum |
HTTPCode_Backend_2XX...... HTTPCode_Backend_5XX |
The number of HTTP XXX server error codes that originate from the backend. Look at sum |
RequestCount |
Number of completed requests |
HealthyHostCount,UnhealthyHostCount |
Self explainatory |
- Elastic Load Balancing reports metrics only when requests are flowing through the load balancer. If there are requests flowing through the load balancer, Elastic Load Balancing measures and sends its metrics in 60-second intervals.
spillover and surge queue give an indication of the ELB being overloaded
- Typically this means that the backend system cannot process requests as fast as they are coming in
- Ideally load balance into an Auto Scaling Group.
| Metric | Effect |
|---|---|
RequestCount |
Number of completed requests |
HealthyHostCount,UnhealthyHostCount |
Self explainatory |
TargetResponseTime |
The time elapsed after the request leaves the load balancer until a response from the target is received. |
HTTPCode_ELB_3XX_CountHTTPCode_ELB_4XX_CountHTTPCode_ELB_5XX_Count |
The number of HTTP XXX server error codes that originate from the load balancer. This count does not include any response codes generated by the targets. |
| Metric | Effect |
|---|---|
processedbyte |
The total number of bytes processed by the load balancer, including TCP/IP headers. |
tcp_client_reset_count |
the total number of reset (rst) packets sent from a client to a target. |
tcp_elb_reset_count |
the total number of reset (rst) packets generated by the load balancer. |
tcp_target_reset_coun |
the total number of reset (rst) packets sent from a target to a client. |
| . | . | . |
|---|---|---|
| CloudWatch Events/Eventbridge | Relay Events to AWS Systems Manager Run Command | Configure event ASG, Instance Launch and Terminate, EC2-Instance-Launch lifecycle action Target: SSM Run Command, add command(s) |
| CloudWatch Events/Eventbridge | Log the State of an Amazon EC2 Instance Usings | Configure event EC2, Instance State Change, Specific states: Running Invoke lambda the logs state from incoming event |
| CloudWatch Events/Eventbridge | Log the State of an Auto Scaling Group | Configure event ASG, Instance Launch and Terminate, EC2-Instance-Launch lifecycle action Invoke lambda the logs state from incoming event |
| CloudWatch Events/Eventbridge | Log Amazon S3 Object-Level Operations | Configure CloudTrail trail to monitor S3 bucket(s)(no events otherwise) Implement Lambda that logs state Configure event to trigger on PutObjectInvoke Lamdba |
| CloudWatch Events/Eventbridge | Use Input Transformer to Customize What Is Passed to the Event Target | . |
| CloudWatch Events/Eventbridge | Log AWS API Calls | . |
| CloudWatch Events/Eventbridge | Schedule Automated Amazon EBS Snapshots | . |
| CloudWatch Events/Eventbridge | Set AWS Systems Manager Automation as an EventBridge Target | . |
| CloudWatch Events/Eventbridge | Relay Events to a Kinesis Stream | . |
| CloudWatch Events/Eventbridge | Run an Amazon ECS Task When a File Is Uploaded to an Amazon S3 Bucket | . |
| CloudWatch Events/Eventbridge | Schedule Automated Builds Using AWS CodeBuild | . |
| CloudWatch Events/Eventbridge | Log State Changes of Amazon EC2 Instances | . |
| CloudWatch Events/Eventbridge | Download Code Bindings for Events using the EventBridge Schema Registry | . |
AWS CodeBuild is a fully managed continuous integration service that compiles source code, Runs tests, and produces software packages that are ready to deploy. With CodeBuild, you don’t need to provision, manage, and scale your own build servers. CodeBuild scales continuously and processes multiple builds concurrently, so your builds are not left waiting in a queue. You can get started quickly by using prepackaged build environments, or you can create custom build environments that use your own build tools. With CodeBuild, you are charged by the minute for the compute resources you use.
- Provides preconfigured environments for supported versions of Java, Ruby, Python, Go, Node.js, Android, .NET Core, PHP, and Docker
- Build images are Amazon Linux 2, Ubuntu 18.04, Windows Server Core 2016
- Can use build image from ECR, even cross-account
- On AWS: Service - FAQs - User Guide
- Fully managed build service
- Serverless
- Leverages Docker under the hood
- Can use own docker images
- Integrates with KMS, IAM, VPC and CloudTrail
- Continuous scaling
- Extensible
- Can use own build tools and runtimes
- Can attach to VPC
- Source code from CodeCommit, S3, GitHub, Bitbucket
- Build defined in
buildspec.yml- Build timeouts up to 8h
- Uses queue to process build jobs
- Triggers can schedule a build, can also use cron expressions
- CloudWatch integration
- Logs (can also go to S3)
- Metrics to monitor CodeBuild statistics
- Can set up Alarms on top of those
- Can schedule CloudWatch Events
- CodeBuild is provided with a build project.
- Defines how Codebuild runs
- Source code location, build environment to use, build commands
- Defines how Codebuild runs
- CodeBuild uses information from build project to create build environment
- Build runs in container, in phases
submitted,queued,provisioning,download_source,install,pre_build,build,post_build,upload_artifacts,finalizing,completed
- Download source code into build environment, use buildspec to build
| . | . | . |
|---|---|---|
version |
0.3 |
. |
run-as |
. | . |
env |
variables, parameter-store, exported-variables, secrets-manager, git-credentials-helper |
. |
phases |
install, pre_build, build, post_build |
Every phase has a finally sectionFailed build transitions to post_build, all others to finalizing |
reports |
. | . |
artifacts, secondary-artifacts |
. | . |
cache |
paths |
. |
- Environment variables
- Can come from SSM/Secrets Manager
- Precendence:
start-build(CLI), project definition, buildspec.yml
- If there is build output and CodeBuild is not managed by CodePipeline
- Uploaded to S3, encrypted by default
- With default configuration, artifacts are overwritten each time
- Can provide Namespace type to save output to different location every time
- While build is running, the build environments sends information to CloudWatch and CodeBuild
- Can also use console, CLI, SDK to retrieve information about running build
AWS CodeCommit is a fully-managed source control service that hosts secure Git-based repositories. It makes it easy for teams to collaborate on code in a secure and highly scalable ecosystem. CodeCommit eliminates the need to operate your own source control system or worry about scaling its infrastructure. You can use CodeCommit to securely store anything from source code to binaries, and it works seamlessly with your existing Git tools.
- On AWS: Service - FAQs - User Guide
- Fully managed
- Highly available
- Faster development cycle
- Code lives close to actual environments
- Secure
- Encryption, IAM integration
- Collaborate on code
- Use existing tools
- CodeBuild, Jenkins, other CI tools
- Fully enabled for automation
- Provides notifacations and triggers for all repository events
Use IAM policy:
"Condition": {
"StringEqualsIfExists": {
"codecommit:References": [
"refs/heads/master"
]
},
"Null": {
"codecommit:References": false
}
}
- CodeStar Notifications integration
- Uses CloudWatch Events Rules under the hood
- Set up notification/notification rules:
- Pick triggering event (
on commit, ...,brunch updated) - Pick SNS topic as target
- Add subscriber to target
- Pick triggering event (
- Set up CloudWatch Events directly:
- Pick event source (AWS service)
- Pick event type (different types, also includes CloudTrail)
- Pick target (many different types, e.g. Lambda, SNS, SSM, Code*)
- Can trigger SNS or Lambda
- Up to 10 triggers
- Can be augmented with custom data (an uninterpreted string) that you can use to distinguish the trigger from others that run for the same event.
- More limited in scope than Notifications. Does not us CloudWatch Events under the hood.
AWS CodeDeploy is a fully managed deployment service that automates software deployments to a variety of compute services such as Amazon EC2, AWS Fargate, AWS Lambda, and your on-premises servers. AWS CodeDeploy makes it easier for you to rapidly release new features, helps you avoid downtime during application deployment, and handles the complexity of updating your applications. You can use AWS CodeDeploy to automate software deployments, eliminating the need for error-prone manual operations. The service scales to match your deployment needs.
- CodeDeploy can be chained into CodePipeline and can use artifacts from there
- CodeDeploy does not provision resources
- Automated deployments
- EC2, on-prem, (ASG), ECS, (Fargate), Lambda
- Minimize downtime
- Centralized control
- Easy to adopt
- Integrates with AWS SAM
- On AWS: Service - FAQs - User Guide
- Application
- The application that should be deployed
- Deployment
- Revision
- Specific version of deployable content, such as source code, post-build artifacts, web pages, executable files, and deployment scripts, along with an AppSpec file
- AppSpec File
- Environment variables are being exposed as well (e.g.
DEPLOYMENT_ID,DEPLOYMENT_GROUP_NAME), allow to implement logic in installation process. - Slightly different format for EC2/ECS/Lambda.
- Environment variables are being exposed as well (e.g.
- Deployment group
- Set of instances or Lambda functions, defined by tags, e.g. 'environment=prod'
- Can define multiple deployment groups with an application, such a prod or staging
- Can be associated with
- CloudWatch Alarms that would stop the deployment if triggered
- Triggers for notification
- Rollbacks
- Deployment configuration
- Specifies how the behavior for how deployment should proceed
CodeDeployDefault.OneAtATime, ...,CodeDeployDefault.LambdaCanary10Percent10Minutes- Can create own
- Define minimum healthy hosts by percentage or number
- E.g. 9 instances in total, 6 minimum healthy hosts, deploy 3 at a time. Deployment is successful after 6 hosts have been successfully deployed
- Revision
| EC2/On-Premises | ECS | Lambda |
|---|---|---|
version: 0.0os: operating-system-namefiles:source-destination-files-mappings permissions:permissions-specifications hooks:deployment-lifecycle-event-mappings |
version: 0.0resources: ecs-service-specificationshooks:deployment-lifecycle-event-mappings |
version: 0.0resources: lambda-function-specificationshooks:deployment-lifecycle-event-mappings |
hooks section contains mappings that link one or more scripts |
hooks section specifies Lambda validation functions |
hooks section specifies Lambda validation functions |
- CodeDeploy (Agent) continuously polls CodeDeploy
- CodeDeploy sends AppSpec file
- Revision is pulled from S3/GitHub/BitBucket
- Actual revison always comes from S3, needs IAM permissions for the bucket
- Run in phases
ApplicationStop, (DownloadBundle),BeforeInstall, (Install),AfterInstall,ApplicationStart,ValidateService - CodeDeploy (Agent) reports back success/failure
- CodeStar Notifications integration (goes out to SNS only)
- CloudWatch Event integration
- Deployment triggers can notify SNS
- Can trigger based on deployment or instance events
- CloudWatch Log Agent on machine can push logs to CloudWatch
- No logs for ECS/Lambda deploys
- Manual Rollback by simply deploying a previous version
- Automated Rollbacks
- Options
- When deployment fails
- Rollback when any deployments on any instance fails
- When alarm thresholds are met
- Add CloudWatch Alarm to deployment group
- When deployment fails
- Can define
cleanupfile to help removing already installed files
- Options
| Step | Comment |
|---|---|
| Create application | . |
| Specify deployment group | Tags and/or ASG name. |
| Specify deployment configuration | AllAtOnce,HalfAtATime,OneAtATime (default)In-place (default), Blue/green |
| Upload revison | . |
| Deploy | . |
| Check results | . |
| Redeploy as needed | . |
-
In-place
- The application on each instance in the deployment group is stopped
- The latest application revision is installed
- The new version of the application is started and validated.
- You can use a load balancer so that each instance is deregistered during its deployment and then restored to service after the deployment is complete.
- Only deployments that use the EC2/On-Premises compute platform can use in-place deployments.0
-
Blue/green
- Instances are provisioned for the replacement environment.
- The latest application revision is installed on the replacement instances.
- An optional wait time occurs for activities such as application testing and system verification.
- Instances in the replacement environment are registered with an Elastic Load Balancing load balancer, causing traffic to be rerouted to them.
- Instances in the original environment are deregistered and can be terminated or kept running for other uses.
- If you use an EC2/On-Premises compute platform, be aware that blue/green deployments work with Amazon EC2 instances only.
- During deployments, a load balancer prevents internet traffic from being routed to instances when they are not ready, are currently being deployed to, or are no longer needed as part of an environment.
- Blue/Green Deployments
- Allows traffic to be routed to the new instances in a deployment group that the latest application revision has been deployed to (the replacement environment), according to the rules you specify
- Blocks traffic from the old instances where the previous application revision was running (the original environment).
- After instances in a replacement environment are registered with a load balancer, instances from the original environment are deregistered and, if you choose, terminated.
- Specify a Classic Load Balancer, Application Load Balancer, or Network Load Balancer in your deployment group.
- In-Place Deployments
- Prevents internet traffic from being routed to an instance while it is being deployed to
- Makes the instance available for traffic again after the deployment to that instance is complete.
- If a load balancer isn't used during an in-place deployment, internet traffic may still be directed to an instance during the deployment process.
- When you use a load balancer with an in-place deployment, instances in a deployment group are deregistered from a load balancer, updated with the latest application revision, and then reregistered with the load balancer as part of the same deployment group after the deployment is successful.
- Specify a Classic Load Balancer, Application Load Balancer, or Network Load Balancer. You can specify the load balancer as part of the deployment group's configuration, or use a script provided by CodeDeploy to implement the load balancer.
- When new Amazon EC2 instances are launched as part of an Amazon EC2 Auto Scaling group, CodeDeploy can deploy your revisions to the new instances automatically.
- During blue/green deployments on an EC2/On-Premises compute platform, you have two options for adding instances to your replacement (green) environment:
- Use instances that already exist or that you create manually.
- Use settings from an Amazon EC2 Auto Scaling group that you specify to define and create instances in a new Amazon EC2 Auto Scaling group.
- If an Amazon EC2 Auto Scaling scale-up event occurs while a deployment is underway, the new instances will be updated with the application revision that was most recently deployed, not the application revision that is currently being deployed.
- Suspend scaling during rolling deploys
- Or redeploy
- Configure each on-premises instance, register it with CodeDeploy, and then tag it.
- Can create IAM User per instance
- Needs configuration file with AK/SAK
- Use
registerorregister-on-premises-instancescommand - Best for only few instances
- Can create IAM Role
- Needs credentials to call STS with
- Best for many instances, also more secure
- Setup more complicated
- Use
register-on-premises-instancescommand together with STS token service
- Can create IAM User per instance
- Need to install CodeDeploy agent, obviously
- On-prem instances cannot blue/green, as CodeDeploy cannot create new infrastructure
| Step | Comment |
|---|---|
| Create application | . |
| Specify deployment group | Only a name, Lambdas are specified in appspec |
| Specify deployment configuration | LambdaCanary10Percent5Minutes/10/15/30LambdaLinear10PercentEvery1Minute/2/3/10LambdaAllAtOnceonly Blue/green |
| Specify an AppSpec file | S3 (local with AWS CLI) |
| Deploy | . |
| Check results | . |
| Redeploy as needed | . |
- Lambda deploys a new version under an alias, and traffic is shifted between old and new version
- (Versions and Aliases are native Lambda features)
- Deploys new versions of your Lambda function, and automatically creates aliases that point to the new version.
- Gradually shifts customer traffic to the new version until you're satisfied that it's working as expected, or you roll back the update.
- Defines pre-traffic and post-traffic test functions to verify that the newly deployed code is configured correctly and your application operates as expected.
- Rolls back the deployment if CloudWatch alarms are triggered.
DeploymentPreference:
Type: Canary10Percent10Minutes
Alarms:
# A list of alarms that you want to monitor
- !Ref AliasErrorMetricGreaterThanZeroAlarm
Hooks:
# Validation Lambda functions that are run before & after traffic shifting
PreTraffic: !Ref PreTrafficLambdaFunction
PostTraffic: !Ref PostTrafficLambdaFunction
| Step | Comment |
|---|---|
| Create ECS service | Set its deployment controller to CodeDeploy |
| Create application | . |
| Specify deployment group | Specify * ECS cluster and service name * production listener, optional test listener, and target groups * deployment settings, such as when to reroute production traffic to the replacement ECS task * optional settings such as triggers, alarms and rollback behaviour |
| Specify deployment configuration | ECSCanary10Percent5Minutes/15LambdaLinear10PercentEvery1Minute/3ECSAllAtOnceonly Blue/green |
| Specify an AppSpec file | S3 (local with AWS CLI) |
| Deploy | . |
| Check results | . |
| Redeploy as needed | . |
- CodeDeploy reroutes traffic from the original version of a task set to a new, replacement task set
- Target groups specified in the deployment group are used to serve traffic to the original and replacement task sets
- After the deployment is complete, the original task set is terminated.
- Can specify an optional test listener to serve test traffic to your replacement version before traffic is rerouted to it
AWS CodePipeline is a fully managed continuous delivery service that helps you automate your release pipelines for fast and reliable application and infrastructure updates. CodePipeline automates the build, test, and deploy phases of your release process every time there is a code change, based on the release model you define. This enables you to rapidly and reliably deliver features and updates. You can easily integrate AWS CodePipeline with third-party services such as GitHub or with your own custom plugin. With AWS CodePipeline, you only pay for what you use. There are no upfront fees or long-term commitments.
- On AWS: Service - FAQs - User Guide
- Rapid delivery
- Configurable workflow
- Get started fast
- No CI/CD infastructue needs to be provisioned
- Easy to integrate
- Plugin concept to integrate with other components
- Integrates with CloudWatch Events
- CodeStar Notifications integration
- stage
- action group (run in sequence)
- action (run in sequence or parallel)
- Various action providers provide functionality
runOrderallows to decide about sequential and parallelregionreplicates source bucket into target region. This enables multi-region deploys- Can invoke Lambda as an almost arbitrary pipeline action
- action (run in sequence or parallel)
- action group (run in sequence)
- Stages create artifacts
- Stored in S3, passed on to the next stage
- Default setting for artifact store would create one bucket per pipe, can also specify Custom location
- Store must be in the same region as pipeline
- Always encrypted, default KMS or CMK
- Artifacts are the way different pipeline stages 'communicate' with each other
- CodePipeline artifacts are sightly different to CodeBuild artifacts
- Stored in S3, passed on to the next stage
- Source
- S3
- CodeCommit
- -> Must have one pipeline per branch!
- Change detection CloudWatch (recommended), or CodePipeline (poll periodically)
- Creates CloudWatch Events rule in the background
- Github
- ECR
- Build
- CodeBuild
- Jenkins
- TeamCity
- etc
- Test
- CodeBuild
- Jenkins
- Ghost Inspector
- Deploy
- CodeDeploy
- Can deploy into different region
- CloudFormation
- Beanstalk
- ECS
- ServiceCatalog
- etc
- CodeDeploy
- Invoke
- Lambda
- Approval
- SNS
CodePipeline with
- Amazon S3, AWS CodeCommit, and AWS CodeDeploy
- Third-party Action Providers (GitHub and Jenkins)
- AWS CodeStar to Build a Pipeline in a Code Project
- Compile, Build, and Test Code with CodeBuild
- Amazon ECS for Continuous Delivery of Container-Based Applications to the Cloud
- Elastic Beanstalk for Continuous Delivery of Web Applications to the Cloud
- AWS Lambda for Continuous Delivery of Lambda-Based and Serverless Applications
- AWS CloudFormation Templates for Continuous Delivery to the Cloud
AWS CodeStar enables you to quickly develop, build, and deploy applications on AWS. AWS CodeStar provides a unified user interface, enabling you to easily manage your software development activities in one place. With AWS CodeStar, you can set up your entire continuous delivery toolchain in minutes, allowing you to start releasing code faster. AWS CodeStar makes it easy for your whole team to work together securely, allowing you to easily manage access and add owners, contributors, and viewers to your projects. Each AWS CodeStar project comes with a project management dashboard, including an integrated issue tracking capability powered by Atlassian JIRA Software. With the AWS CodeStar project dashboard, you can easily track progress across your entire software development process, from your backlog of work items to teams’ recent code deployments.
- CodeStar provides a central console where you can assign project team members the roles they need to access tools and resources. These permissions are applied automatically across all AWS services used in your project, so you don't need to create or manage complex IAM policies.
owner,contributor,viewer
- On AWS: Service - FAQs - User Guide
- Start developing on AWS in minutes
- Manage software delivery in one place
- Work across your team securely
- Choose from a variety of project templates
Uses cfn-transform to generate cfn from template.yml
AWS Config is a service that enables you to assess, audit, and evaluate the configurations of your AWS resources. Config continuously monitors and records your AWS resource configurations and allows you to automate the evaluation of recorded configurations against desired configurations. With Config, you can review changes in configurations and relationships between AWS resources, dive into detailed resource configuration histories, and determine your overall compliance against the configurations specified in your internal guidelines. This enables you to simplify compliance auditing, security analysis, change management, and operational troubleshooting.
- Evaluate your AWS resource configurations for desired settings.
- Get a snapshot of the current configurations of the supported resources that are associated with your AWS account.
- Retrieve configurations of one or more resources that exist in your account.
- Retrieve historical configurations of one or more resources.
- Receive a notification whenever a resource is created, modified, or deleted.
- View relationships between resources. For example, you might want to find all resources that use a particular security group.
- On AWS: Service - FAQs - User Guide
- Evaluate the configuration settings of AWS resources
- A Config rule represents your ideal configuration settings
- Predefined rules called managed rules to help you get started
- Can also create custom rules
- AWS Config continuously tracks the configuration changes that occur among your resources
- Checks whether these changes violate any of the conditions in your rules.
- If a resource violates a rule, AWS Config flags the resource and the rule as noncompliant.
- Can remediate using AWS Systems Manager Automation Documents
- SNS notification on all Config events (cannot configure which events)
- CloudWatch Events to observe specific events/rules
An aggregator is an AWS Config resource type that collects AWS Config configuration and compliance data from the following:
- Multiple accounts and multiple regions.
- Single account and multiple regions.
- An organization in AWS Organizations and all the accounts in that organization.
- Is limited to 50 per account
- "We are unable to complete the request at this time. Try again later or contact AWS Support"
- Overview
- Keys and indexes
- Secondary indexes
- Capacity provisioning
- DynamoDB Accelerator (DAX)
- DynamoDB Streams
- Global Tables
Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It's a fully managed, multi region, multi master, durable database with built-in security, backup and restore, and in-memory caching for internet-scale applications. DynamoDB can handle more than 10 trillion requests per day and can support peaks of more than 20 million requests per second.
- Fully managed NoSQL database
- HA through different AZs, automatically spreads data and traffic accross servers
- 3 geographically distributed regions per table
- Can scale up and down depending on demand (no downtime, no performance degradation)
- Automatic or user-controlled read/write capacity provisioning
- No joins - create references to other tables manually (
table1#something) - Conditional updates and concurrency control (atomic counters)
- Option between eventual consistency or strongly consistency
- Built-in monitoring
- Big Data: Integrates with AWS Elastic MapReduce and Redshift
- Can configure TTL to expire table entries
- On AWS: Service - FAQs - User Guide
- See also: AWS Geek 2018
- See also: AWS Geek 2018
{kind=link}
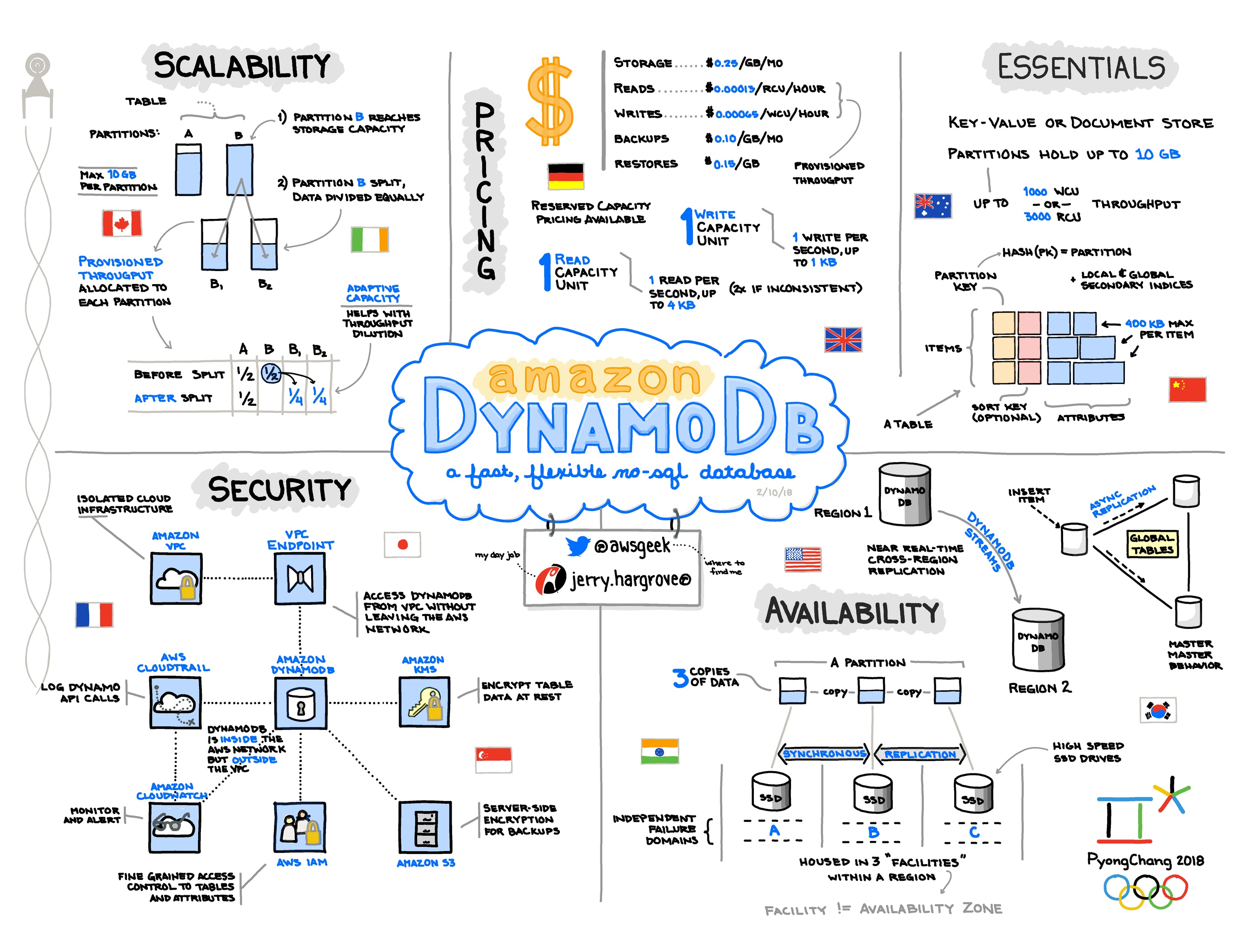{kind=link}
- Partition key is also called hash attribute or primary key
- Must be unique, used for internal hash function (unordered)
- Used to retrieve data
- You should design your application for uniform activity across all logical partition keys in the Table and its secondary indexes.
- Composite PK: index composed of hashed PK (unordered) and SK (ordered)
- Sort key is also called range attribute or range key
- Different items can have the same PK, must have different SK
- Associated with exactly one table, from which it obtains its data
- Allows to query or scan data by an alternate key (other than PK/SK)
- Only for
readoperations,writeis not supported.
- Attributes copied from the base table into an index
- Makes them queryable
- Different projection types
KEYS_ONLY- Only the index and primary keys are projected into the indexALL- All of the table attributes are projected into the indexINCLUDE- Only the specified table attributes are projected into the index
- Local as in "co-located on the same partition"
- Uses the same PK, but offers different SK
- Every partition of a local secondary index is scoped to a base table partition that has the same partition key value
- Local secondary indexes are extra tables that DynamoDB keeps in the background
- Can only by created together with the base table
- Can choose eventual consistency or strong consistency at creation time
- Can request not-projected attributes for query or scan operation
- Consumes read/write throughput from the original table.
- Global as in "over many partitions"
- Uses different PK and offers additional SK (or none).
- PK does not have to be unique (unlike base table)
- Queries on the global index can span all of the data in the base table, across all partitions
- Can be created after the base table has already been created.
- Only support eventual consistency
- Have their own provisioned read/write throughput
- Global secondary keys are distributed transactions across multiple partitions
- Cannot request not-projected attributes for query or scan operation
- Unit for operations:
- 1 strongly consistent
readper second (up to 4KB/s) - 2 eventual consistent
readper second (up to 8KB/s) - 1
writeper second (up to 1KB)
- 1 strongly consistent
- Algorithm
| . | . |
|---|---|
| . | 300 strongly consistent reads of 11KB per minute |
| Calculate read/writes per second | 300r/60s = 5r/s |
| Multiply with payload factor | 5r/s * (11KB/4KB) = 15cu |
| If eventual consistent, devide by 2 | 15cu / 2 = 8cu |
Amazon DynamoDB Accelerator (DAX) is a fully managed, highly available, in-memory cache for DynamoDB that delivers up to a 10x performance improvement – from milliseconds to microseconds – even at millions of requests per second. DAX does all the heavy lifting required to add in-memory acceleration to your DynamoDB tables, without requiring developers to manage cache invalidation, data population, or cluster management. Now you can focus on building great applications for your customers without worrying about performance at scale. You do not need to modify application logic, since DAX is compatible with existing DynamoDB API calls. You can enable DAX with just a few clicks in the AWS Management Console or using the AWS SDK. Just as with DynamoDB, you only pay for the capacity you provision.
DynamoDB Streams captures a time-ordered sequence of item-level modifications in any DynamoDB table and stores this information in a log for up to 24 hours. Applications can access this log and view the data items as they appeared before and after they were modified, in near-real time.
A DynamoDB stream is an ordered flow of information about changes to items in a DynamoDB table. When you enable a stream on a table, DynamoDB captures information about every modification to data items in the table.
- Typically targets Lambda function
- Only up to 2 Lambda functions on the same stream, throttling issues otherwise
- Underlying implementation is a Kinesis Stream
- Can enable Global Table
- Require DynamoDB streams and empty table
- Replicate table in different region (read and write)
Amazon DynamoDB global tables provide a fully managed solution for deploying a multi region, multi master database, without having to build and maintain your own replication solution. With global tables you can specify the AWS Regions where you want the table to be available. DynamoDB performs all of the necessary tasks to create identical tables in these Regions and propagate ongoing data changes to all of them.
- A global table is a collection of one or more replica tables, all owned by a single AWS account.
- A replica table is a single DynamoDB table that functions as a part of a global table. Each replica stores the same set of data items.
- When you create a DynamoDB global table, it consists of multiple replica tables (one per Region) that DynamoDB treats as a single unit. Every replica has the same table name and the same primary key schema. When an application writes data to a replica table in one Region, DynamoDB propagates the write to the other replica tables in the other AWS Regions automatically.
- You can add replica tables to the global table so that it can be available in additional Regions.
Amazon Elastic Container Service (Amazon ECS) is a highly scalable, fast, container management service that makes it easy to run, stop, and manage Docker containers on a cluster. You can host your cluster on a serverless infrastructure that is managed by Amazon ECS by launching your services or tasks using the Fargate launch type. For more control you can host your tasks on a cluster of Amazon Elastic Compute Cloud (Amazon EC2) instances that you manage by using the EC2 launch type.
- On AWS: Service - FAQs - User Guide
- See also: AWS Geek 2020
- See also: AWS Geek 2017
- See also: AWS Geek 2017
{kind=link}
{kind=link}
{kind=link}
- Containers without servers
- Containerize Everything
- Secure
- Performance at Scale
- AWS Integration
[Cluster
[Services
[Task Definitions
[Family]
[Task role/execution role]
[Network mode]
[Container Definitions
[Name/Image]
[Memory/Port Mappings]
[Health Check]
[Environment]
[Network Settings]
[Storage and Logging]
[Security]
[Resource Limit]
[Docker labels]
]
]
]
]
- Cluster
- Logical grouping of EC2 instances that you can place tasks on
- Instances run ECS agent as a Docker container
- Cluster is an Auto Scaling Group with a Launch Configuration using a special ECS AMI
- Service
- Runs and maintains a specified number of tasks simultaneously
- Created on cluster-level, launch type EC2 or Fargate
- Can be linked to ALB/NLB/ELB
- Service type
- Replica - places and maintains the desired number of tasks across your cluster
- Demon - deploys exactly one task on each active container instance that meets all of the task placement constraints
- Good for e.g. monitoring that should run on every container instance
- Deployment type
- Rolling
- Controlled by Amazon ECS
- Service scheduler replacing the current running version of the container with the latest version
- Blue/Green
- Controlled by CodeDeploy
- Allows to verify a new deployment of a service before sending production traffic to it
- Rolling
- Task Definition
- ECS allows to run and maintain a specified number containers in a task definition
- Group by responsility, e.g. separate task definitions for frontend and backend
- The task definition is a text file, in JSON format, that describes one or more containers, up to a maximum of ten, that form your application
- Specify various parameters, eg:
- Container image to use
- Port to be opened & networking
- Data volumes
- Either for ECS or Fargate
- ECS allows to run and maintain a specified number containers in a task definition
- Container Definitions
- Can mark container as essential - if that container fails or stops for any reason, all other containers that are part of the task are stopped
- Task
- A task is the instantiation of a task definition within a cluster
- If a task should fail or stop, the ECS scheduler launches another instance of the task definition to replace it and to maintain the desired count of tasks in service
- Static host port mapping: Only one task per container instance allowed, e.g. mapping host port 80 to container port
- Dynamic host port mapping: Uses randomized host ports, can work together with ALB to run multiple task instances per container instance
- Tasks can have individual IAM roles
-
Use Service Auto Scaling for
- Target Tracking Scaling Poilicy
- Step Scaling Policy
- Sdcheduled Scaling
-
For ECS, we also need to scale the cluster
- This is really tricky, but in essence there's an ASG around the EC2 instances that form the cluster
- Could use Fargate, obviously
- Or even Elastic Beanstalk
- For tasks, configure logging agent with task definition
- Typically CloudWatch, also supports Splunk
- For cluster instances, install CloudWatch Agent
- Various ECS-specific CloudWatch metrics available
- Various ECS-specific CloudWatch Events available
- Can enable CloudWatch Container Insights
- Sends per-container metrics into CloudWatch metrics
- Needs login
aws ecr get-login --no-include-email --region ap-south-2 docker pull aws_account_id.dkr.ecr.us-west-2.amazonaws.com/amazonlinux:latest
- Don't need to provision cluster
- Does not need EC2 instance roles to create cluster
- Requires VPC
AWS Elastic Beanstalk is an easy-to-use service for deploying and scaling web applications and
services developed with Java, .NET, PHP, Node.js, Python, Ruby, Go, and Docker on familiar servers
such as Apache, Nginx, Passenger, and IIS.
You can simply upload your code and Elastic Beanstalk automatically handles the deployment, from capacity provisioning, load balancing, auto-scaling to application health monitoring. At the same time, you retain full control over the AWS resources powering your application and can access the underlying resources at any time.
- Allows to deploy, monitor and scale applications quickly
- Focuses on components and performance, not configuration and specification
- Aims to simplify or even remove infrastructure management
- Provides different options for low cost and high availability quick starts
- Underlying instances can be automatically patched
- Platform-specific application source bundle (e.g. Java
warfor Tomcat)- Go
- Java SE/with Tomcat
- .NET on Windows Server with IIS
- Node.js
- PHP
- Python
- Ruby Stanalone/Puma
- Docker Single-/Multicontainer - runs on ECS
- Docker Preconfigured Glassfish/Python/Go
- On AWS: Service - FAQs - User Guide
- See also: AWS Geek 2019
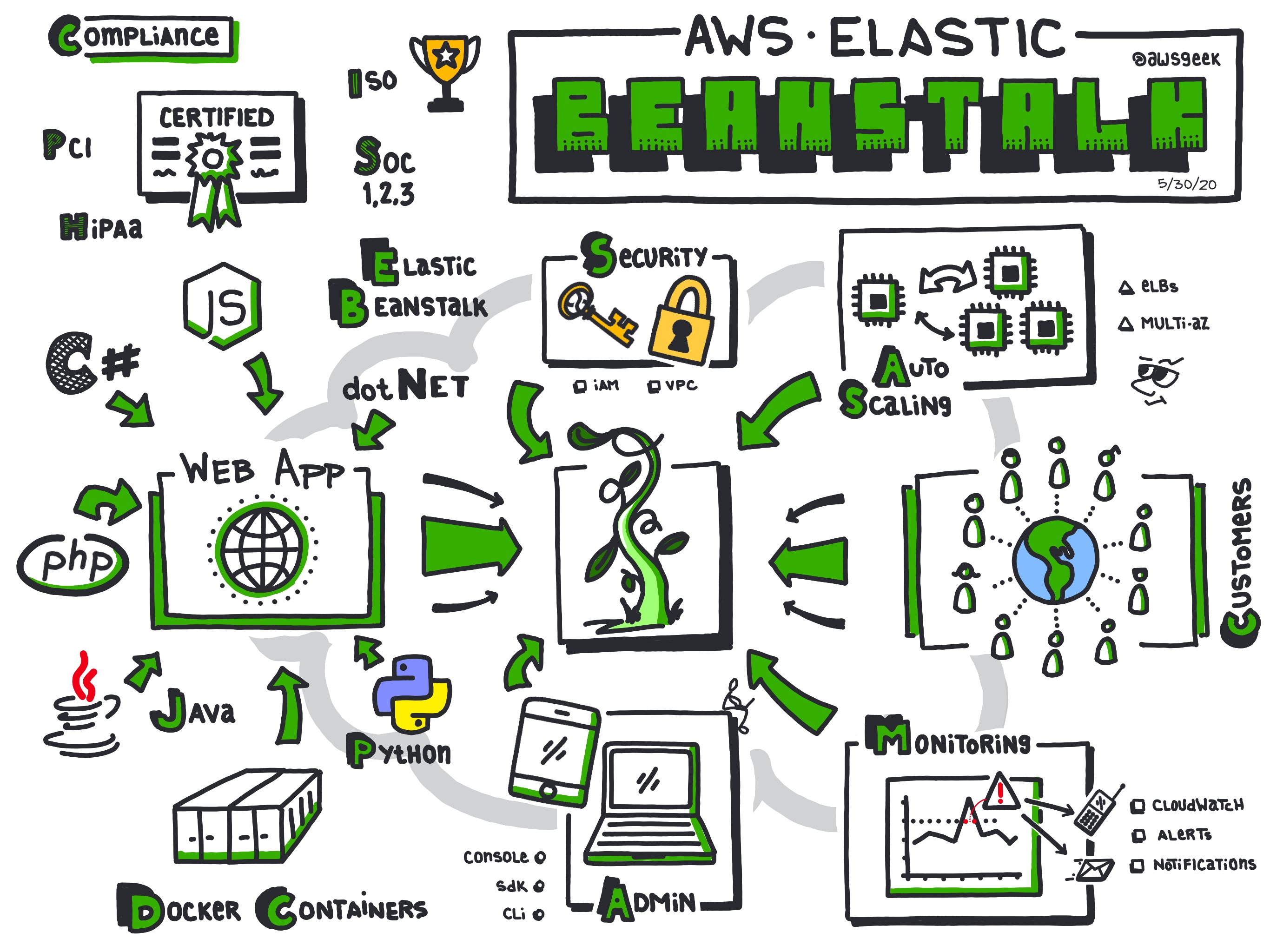{kind=link}
- Application
- A logical collection of Elastic Beanstalk components, including environments, versions, and environment configurations.
- An application is conceptually similar to a folder.
- Either application in the traditional sense
- Or application component, e.g. service, frontend, backend
- Application Version
- Refers to a specific, labeled iteration of deployable code for a web application
- Unique package that represents a version of the application
- Uploaded as a zipped application source bundle
- Each application can have many application versions
- Can be deployed to one or more environments within an application
- Limit of 1000 version -> can configure application version lifecycle management
- Environment
- Collection of AWS resources running an application version
- Isolated, self-contained set of components of infrastructure
- Single-instance or multi-instance scalable
- Application can have multiple environments
- Either represent development stages (PROD, STAGING, ...)
- ...or application component, e.g. service, frontend, backend
- Environment has one application
- Can be cloned as a whole environment
- Can rebuild environment - complete delete and rebuild
- Environment tier
- Designates the type of application that the environment runs, and determines what resources Elastic Beanstalk provisions to support it
- Type Web server environment tier
- Represents a web application
- Type Worker environment tier
- Act upon output created by another environment - pulls work from SQS queue
- Elastic Beanstalk is running a daemon process on each instance that reads from the queue
- Ideal for long running workloads
- Should only be loosely coupled to web server environments, eg. via SQS
- Can also be invoked on a schedule (
cron.yml)
- Act upon output created by another environment - pulls work from SQS queue
- Type Web server environment tier
- Designates the type of application that the environment runs, and determines what resources Elastic Beanstalk provisions to support it
- Environment configuration
- Identifies a collection of parameters and settings that define how an environment and its associated resources behave
- Saved configuration
- A template that you can use as a starting point for creating unique environment configurations
- Platform
- Combination of an operating system, programming language runtime, web server, application server, and Elastic Beanstalk components
| Web Application (non-docker) |
Web Application (docker, runs on ECS) |
Worker |
|---|---|---|
AWS::AutoScaling::AutoScalingGroup |
AWS::AutoScaling::AutoScalingGroup |
AWS::CloudFormation::WaitConditionHandle |
AWS::AutoScaling::LaunchConfiguration |
AWS::AutoScaling::LaunchConfiguration |
AWS::DynamoDB::Table |
AWS::AutoScaling::ScalingPolicy |
AWS::CloudFormation::WaitCondition |
AWS::EC2::SecurityGroup |
AWS::CloudFormation::WaitCondition |
AWS::CloudFormation::WaitConditionHandle |
AWS::SQS::Queue |
AWS::CloudFormation::WaitConditionHandle |
AWS::EC2::EIP |
. |
AWS::CloudWatch::Alarm |
AWS::EC2::SecurityGroup |
. |
AWS::EC2::SecurityGroup |
. | . |
AWS::EC2::SecurityGroupIngress |
. | . |
AWS::ElasticLoadBalancing::LoadBalancer |
. | . |
Configuration options, sorted by precedence:
Via console, eb-cli, ...
- Can use
eb config ...to save/snapshot a configuration of an application - Saved into
.elasticbeanstalk- Only non-default values are being saved
- Format is
*.cfg.yml
- This can be modified, uploaded and applied
- Good to backup existing applications
- Can also be applied elsewhere, e.g. in a different region
- Folder is part of application source bundle
- Allows granular configuration & customisation of the EB environment and its resources
- Contains
*.configin YAML format with different sections like option_settings- Global configuration options
resources- Specify additional resources, allows granular configuration of these
- Put CloudFormation here, export outputs into beanstalk environment
- Good for e.g. DDB table, SNS topic, ...
- However, those resources are part of the environment and would be deleted with it
- If this is not desired, then create resources independently
- Usually best for e.g. databases
commands- Executed on ec2 instance
- Run before application and web server are being set up
container_commands- Executed on ec2 instance
- Affects application source code
- Run after application archive has been extracted, but before application version has been deployed
- Can use
leader_onlyto only run on a single instance. E.g. migrate database packages,sources,files,users,groups,service* Various package managers are being support (yum,rubygems, ...)- Applied with next
eb deploy
As the name says.
- Single instance deploys
- HA with Load Balancer
- All at once
- Rolling update
- Rolling with additional batches
- Immutable
- Adds new Auto Scaling Group to existing environment
- Blue/Green - not really supported, however
- Can manually create new environment
- Either use swap URL feature or manually create DNS
- Traffic Splitting via Application Load Balancer
- Can configure Elastic Beanstalk to ignore health checks during deployments
| . | . |
|---|---|
| Applications | 75 |
| Application Versions | 1000 |
| Configuration Templates | 2000 |
| Environments | 200 |
Amazon Elasticsearch Service is a fully managed service that makes it easy for you to deploy, secure, and run Elasticsearch cost effectively at scale. You can build, monitor, and troubleshoot your applications using the tools you love, at the scale you need. The service provides support for open source Elasticsearch APIs, managed Kibana, integration with Logstash and other AWS services, and built-in alerting and SQL querying. Amazon Elasticsearch Service lets you pay only for what you use – there are no upfront costs or usage requirements. With Amazon Elasticsearch Service, you get the ELK stack you need, without the operational overhead.
- Managed version of Elasticsearch
- Runs on servers
- Use cases:
- Log Analytics
- Real-time application monitoring
- Security analysis
- Full text search
- Clickstream analytics
- Indexing
- Not a good choice for record processing
- On AWS: Service - FAQs - User Guide
- Elasticsearch
- Provides search and indexing capabilities
- Logstash
- Log ingestion mechanism
- Agent-based
- Kibana
- Provides real-time dashboards on top of data in ES
DynamoDB -> DynamoDB Stream -> Lambda -> AWS ES
CloudWatch Logs -> Subscription Filter -> Lambda -> AWS ES (real time)
CloudWatch Logs -> Subscription Filter -> Kinesis Firehose -> AWS ES (near real time)
Amazon GuardDuty is a threat detection service that continuously monitors for malicious activity and unauthorized behavior to protect your AWS accounts and workloads. With the cloud, the collection and aggregation of account and network activities is simplified, but it can be time consuming for security teams to continuously analyze event log data for potential threats. With GuardDuty, you now have an intelligent and cost-effective option for continuous threat detection in the AWS Cloud. The service uses machine learning, anomaly detection, and integrated threat intelligence to identify and prioritize potential threats. GuardDuty analyzes tens of billions of events across multiple AWS data sources, such as AWS CloudTrail, Amazon VPC Flow Logs, and DNS log. With a few clicks in the AWS Management Console, GuardDuty can be enabled with no software or hardware to deploy or maintain. By integrating with Amazon CloudWatch Events, GuardDuty alerts are actionable, easy to aggregate across multiple accounts, and straightforward to push into existing event management and workflow systems.
- Integrates with CloudWatch Events
- On AWS: Service - FAQs - User Guide
- See also: AWS Geek 2020
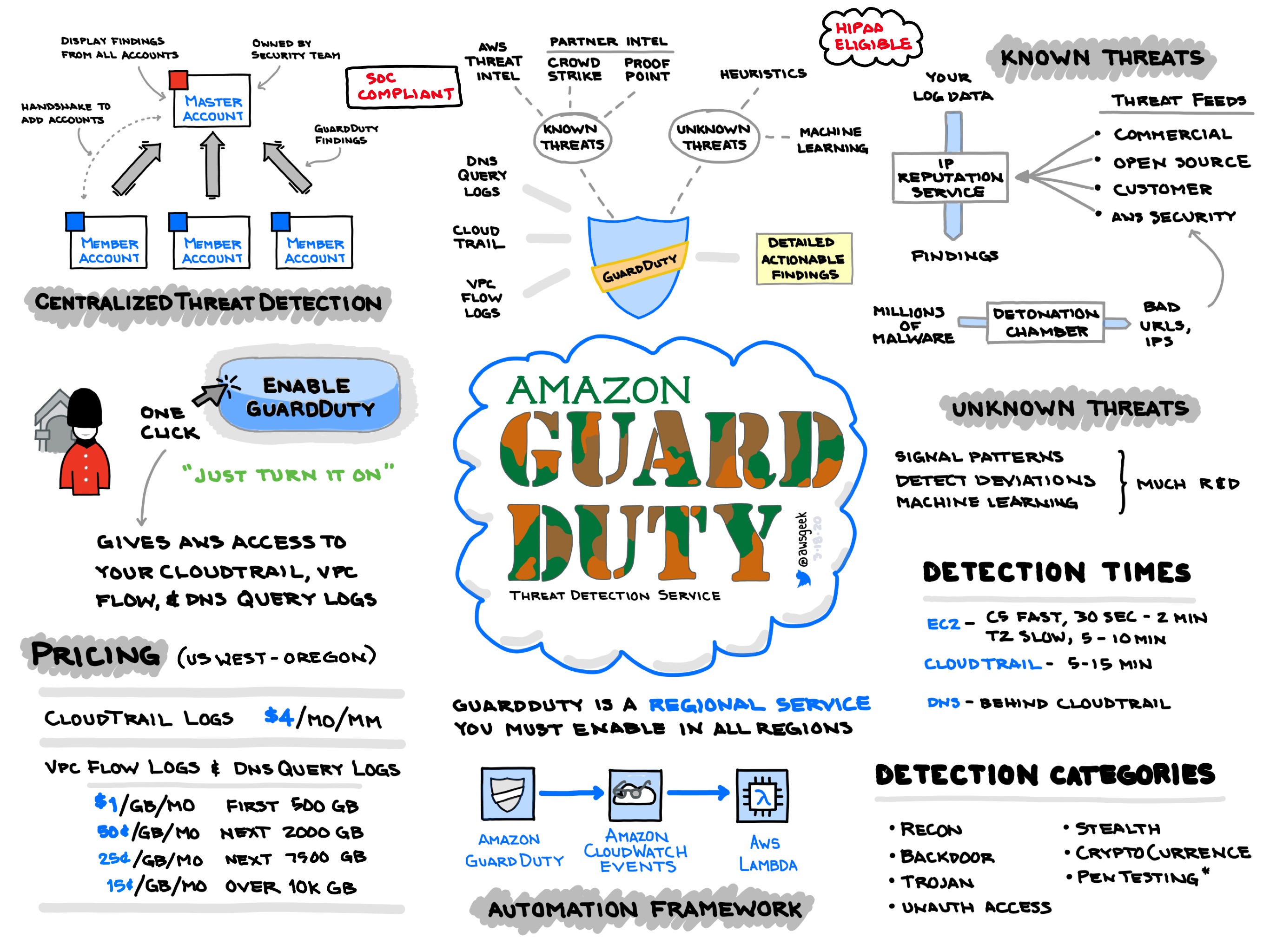{kind=link}
Amazon Kinesis makes it easy to collect, process, and analyze real-time, streaming data so you can get timely insights and react quickly to new information. Amazon Kinesis offers key capabilities to cost-effectively process streaming data at any scale, along with the flexibility to choose the tools that best suit the requirements of your application. With Amazon Kinesis, you can ingest real-time data such as video, audio, application logs, website clickstreams, and IoT telemetry data for machine learning, analytics, and other applications. Amazon Kinesis enables you to process and analyze data as it arrives and respond instantly instead of having to wait until all your data is collected before the processing can begin.
[various data sources]->Kinesis Streams->Kinesis Analytics->Kinesis Firehose->[S3]
- On AWS: Service - FAQs - User Guide
- Enables you to build custom applications that process or analyze streaming data for specialized needs
- Real-time data delivery
- Streams are devided into ordered shards/partitions
- Shards can evolve over time (reshard/merge)
- Records are ordered per shard (but not across shards)
- Data retention is 1 day (default), up to 7 days
- Ability to process/replay data
- Real-time processing
- Multiple applications can consume the same stream
- Once date is inserted into Kinesis, it can't be deleted (immutability)
- Records
Data Blob, up to 1MBRecord Key- helps grouping into shards, should be highly distributedSequence Number- unique identifier for each record put into shards
- Producers
- Kinesis SDK, Kinesis Producer Library (KPL), Kinesis Agent, CloudWatch Logs
- 3rd party libraries: Spark, Log4j Appenders, ...
- Consumers
- Kinesis SDK, Kinesis Client Library (KCL), Kinesis Connector Library, AWS Lambda
- 3rd party libraries: Spark, Log4j Appenders, ...
- The easiest way to load streaming data into data stores and analytics tools
- Near Real-time data delivery (~60 seconds)
- Automatic Scaling
- Can do data transformation through Lambda
- Supports compression for S3
- Pay for the amount of data going through Firehose
- Producers
- Kinesise Data Streams, CloudWatch Logs & Events, ...
- Consumers (data receivers)
- Redshift, S3, ElasticSearch, Splunk
| Kinesis Data Streams | Kinesis Firehose |
|---|---|
| Must manage scaling | Fully managed |
| Real time | Near real time |
| Data storage | No data storage |
| Can write custom code for consumers/producers | Serverless Lambda |
For real time delivery Kinesis data streams are the only option.
- The easiest way to analyze streaming data, gain actionable insights, and respond to your business and customer needs in real time
- Performing real time analytics on Kinesis Streams using SQL
- Managed, auto-scaling
- Can create Kinesis Streams in real-time
| . | . | .. |
|---|---|---|
| Kinesis Streams | . | . |
| . | Producer | 1MB/s or 1000 messages/s write per shard (->ProvisionedThroughputException) |
| . | Consumer Classic | 2MB/s write per shard |
| . | . | 5 API calls per second per shard |
| . | Data Retentions | 7 days |
AWS Lambda lets you run code without provisioning or managing servers. You pay only for the compute time you consume - there is no charge when your code is not running. With Lambda, you can run code for virtually any type of application or backend service - all with zero administration. Just upload your code and Lambda takes care of everything required to run and scale your code with high availability. You can set up your code to automatically trigger from other AWS services or call it directly from any web or mobile app.
- Features
- No servers
- Continuous scaling
- Cold Start - if no idle container is available to run the Lambda
- Very cheap
- Can give more RAM which will proportionaly increase CPU as well
- Supported languages
nodejs,Java,C#/PowerShell,Python,Golang,Ruby
- Can pass in environment variables
- These can be KMS-encrypted as well (need SDK to decrypt)
- On AWS: Service - FAQs - User Guide
- See also: AWS Geek 2020
- See also: AWS Geek 2020
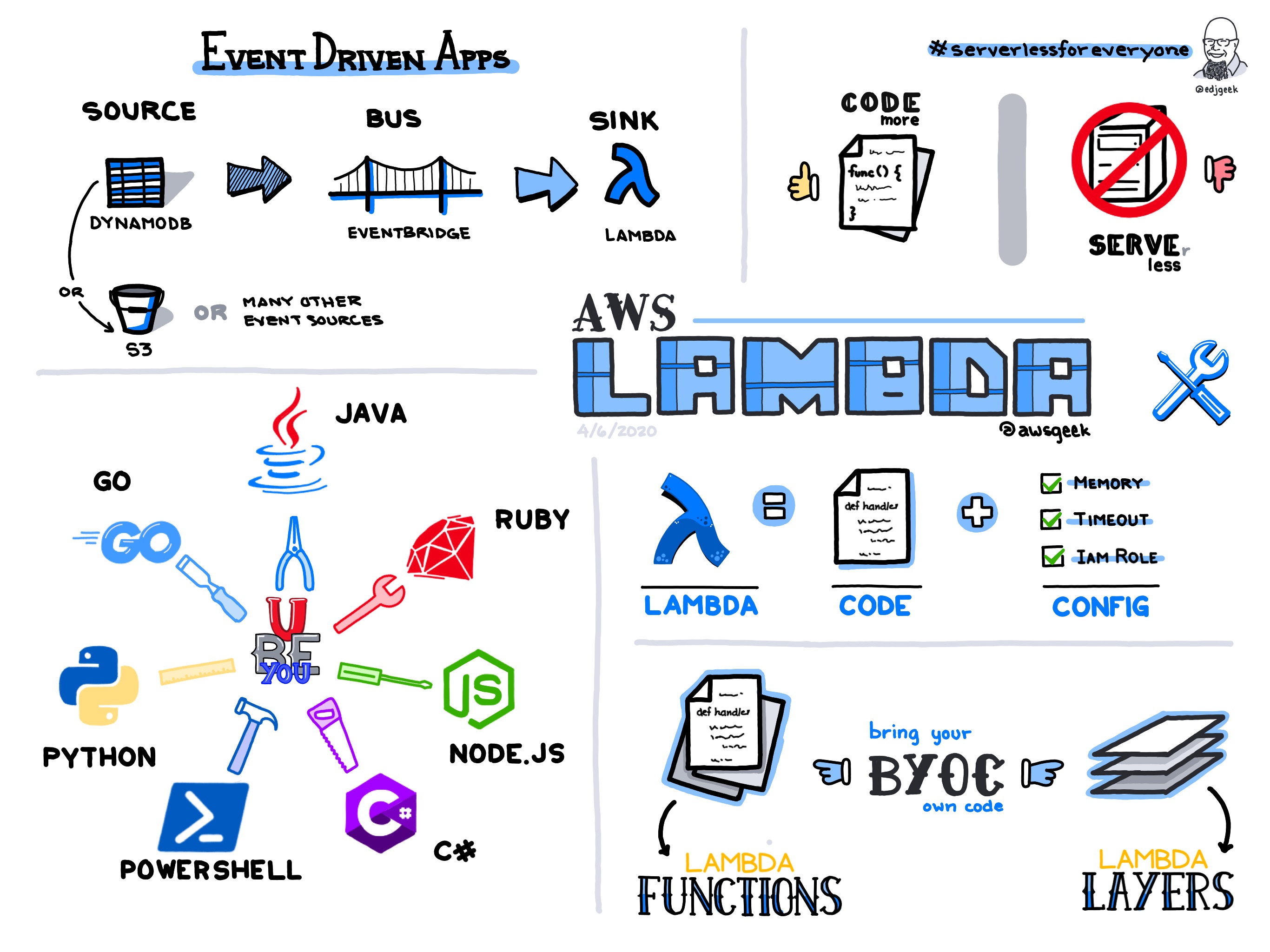{kind=link}
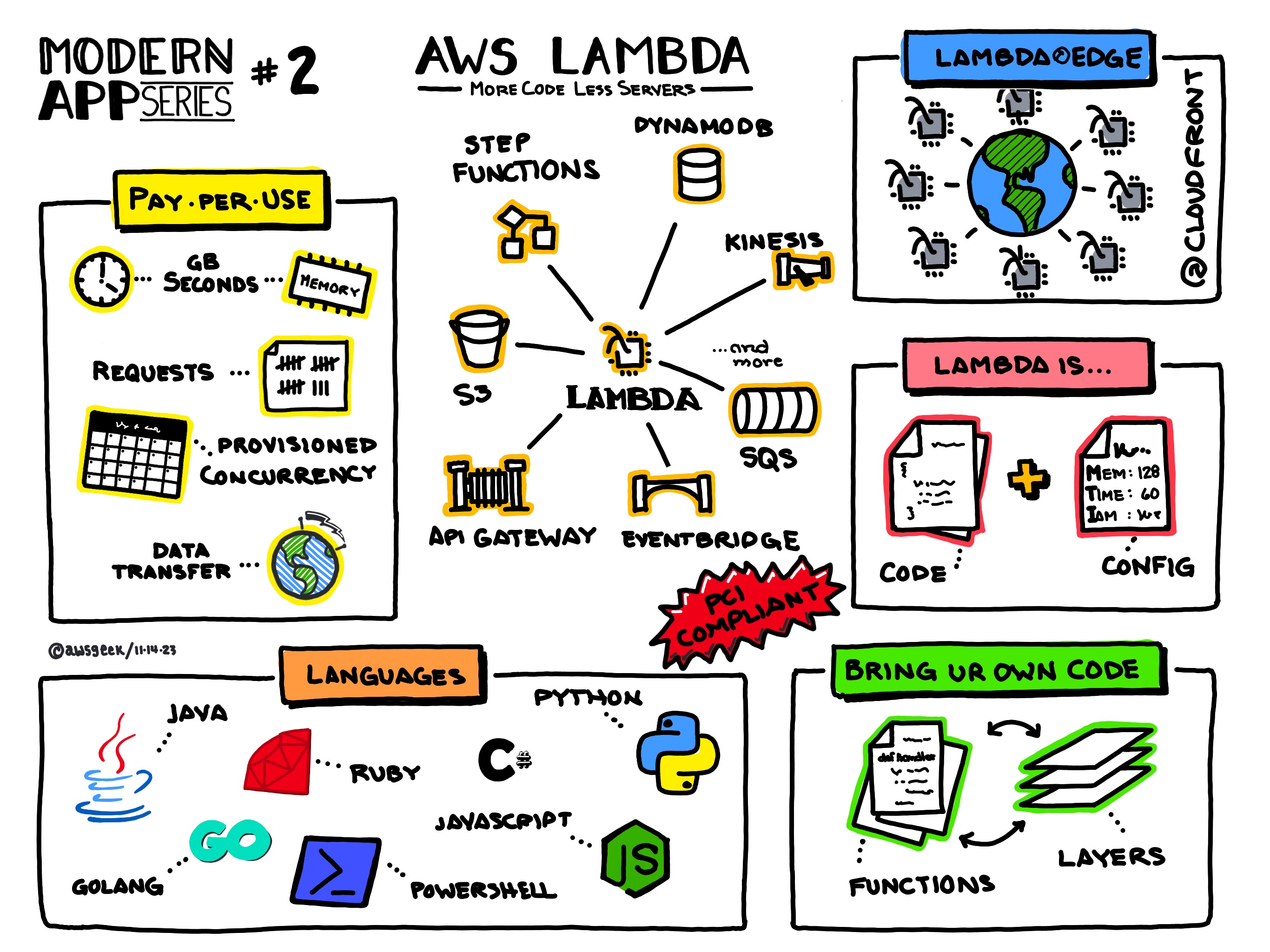{kind=link}
triggers -> function & layers -> destinations
- If you work on a Lambda function, you work on
$LATEST - The system creates a new version of your Lambda function each time that you publish the function. The new version is a copy of the unpublished version of the function.
- Version is code and configuration
- Versions are immutable, you can change the function code and settings only on the unpublished version of a function.
- Each version gets its own ARN
- You can create one or more aliases for your AWS Lambda function. A Lambda alias is like a pointer to a specific Lambda function version.
- Aliases are mutable
- Users can access the function version using the alias ARN.
- Can create e.g.
dev,testandprod.- Aliases can point to multiple versions with a weight - for canary-style deployments
- You can configure your Lambda function to pull in additional code and content in the form of layers.
- A layer is a ZIP archive that contains libraries, a custom runtime, or other dependencies.
- With layers, you can use libraries in your function without needing to include them in your deployment package.
- You can configure a function to connect to private subnets in a VPC in your account.
- Use VPC to create a private network for resources such as databases, cache instances, or internal services.
- Connect your function to the VPC to access private resources during execution.
- Provisioning process for Lambda takes longer
- You can use the Lambda console to create an RDS database proxy for your function.
- A database proxy manages a pool of database connections and relays queries from a function.
- This enables a function to reach high concurrency levels without exhausting database connections.
- When you invoke a function synchronously, Lambda runs the function and waits for a response.
- -> API Gateway, ALB, Cognito, Lex, Alexa, CloudFront (Lambda@Edge), Kinesis Data Firehose
- When you invoke a function asynchronously, Lambda sends the event to a queue. A separate
process reads events from the queue and runs your function.
- Lambda manages the function's asynchronous invocation queue and attempts to retry failed events automatically. If the function returns an error, Lambda attempts to run it two more times
- When all attempts to process an asynchronous invocation fail, Lambda can send the event to an Amazon SQS queue or an Amazon SNS topic.
- -> S3, SNS, SES, CloudFormation, CloudWatch Logs & Events, CodeCommit, Config
- An event source mapping is an AWS Lambda resource that reads from an event source and invokes a Lambda function.
- -> Kinesis, DynamoDB, SQS
- The first time you invoke your function, AWS Lambda creates an instance of the function and runs
its handler method to process the event.
- When the function returns a response, it sticks around to process additional events.
- If you invoke the function again while the first event is being processed, Lambda creates another instance.
- This continues until there are enough instances to serve all requests, or a concurrency limit is reached.
- When the number of requests decreases, Lambda stops unused instances to free up scaling capacity for other functions.
- Concurrency is
invocations/s * runtime(eg. 10/s * 4s = 40)- Can configure reservered concurrency
- No other function can use that concurrency
- Can configure provisioned concurrency before an increase in invocations
- Can ensure that all requests are served by initialized instances with very low latency.
- Can configure reservered concurrency
- Default Burst concurrency limits
3000– US West (Oregon), US East (N. Virginia), Europe (Ireland)1000– Asia Pacific (Tokyo), Europe (Frankfurt)500– Other Regions
- AWS Lambda automatically monitors Lambda functions on your behalf and reports metrics through Amazon CloudWatch. To help you monitor your code as it executes, Lambda automatically tracks the number of requests, the execution duration per request, and the number of requests that result in an error.
- It also publishes the associated CloudWatch metrics.
- Need custom metric for memory usage
AWS License Manager makes it easier to manage your software licenses from software vendors such as Microsoft, SAP, Oracle, and IBM across AWS and on-premises environments. AWS License Manager lets administrators create customized licensing rules that emulate the terms of their licensing agreements, and then enforces these rules when an instance of EC2 gets launched. Administrators can use these rules to help prevent licensing violations, such as using more licenses than an agreement stipulates. The rules in AWS License Manager enable you to help prevent a licensing breach by stopping the instance from launching or by notifying administrators about the infringement. Administrators gain control and visibility of all their licenses with the AWS License Manager dashboard and reduce the risk of non-compliance, misreporting, and additional costs due to licensing overages.
- On AWS: Service - FAQs - User Guide
Amazon Macie is a security service that uses machine learning to automatically discover, classify, and protect sensitive data in AWS. Amazon Macie recognizes sensitive data such as personally identifiable information (PII) or intellectual property, and provides you with dashboards and alerts that give visibility into how this data is being accessed or moved. The fully managed service continuously monitors data access activity for anomalies, and generates detailed alerts when it detects risk of unauthorized access or inadvertent data leaks. Amazon Macie is available to protect data stored in Amazon S3.
- Data Sources
- AWS CloudTrail event logs, including Amazon S3 object-level API activity
- S3
- On AWS: Service - FAQs - User Guide
- See also: AWS Geek 2019
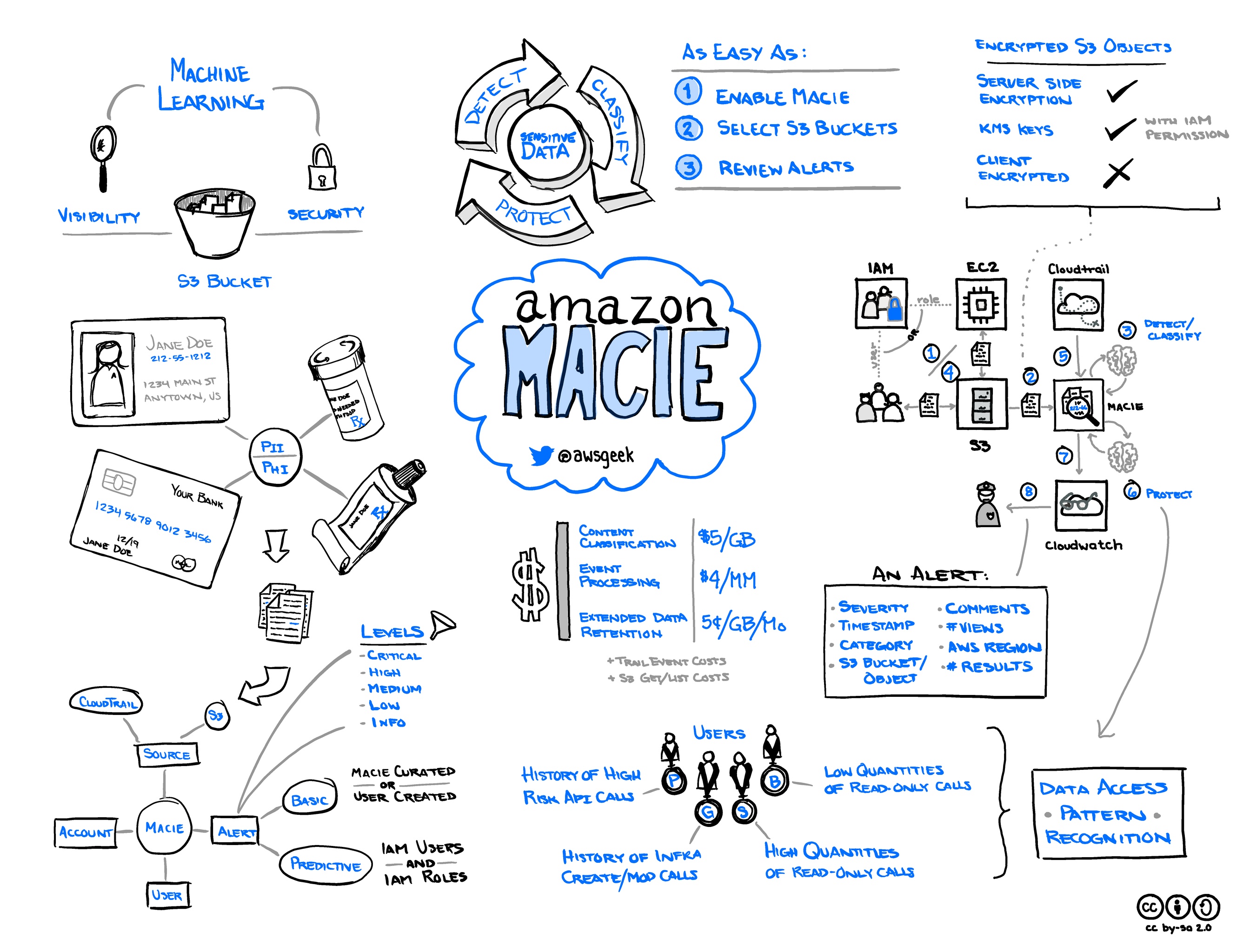{kind=link}
As enterprise customers move towards adopting the cloud at scale, some find their people need help and time to gain AWS skills and experience. AWS Managed Services (AMS) operates AWS on your behalf, providing a secure and compliant AWS Landing Zone, a proven enterprise operating model, on-going cost optimization, and day-to-day infrastructure management. By implementing best practices to maintain your infrastructure, AWS Managed Services helps to reduce your operational overhead and risk. AWS Managed Services automates common activities, such as change requests, monitoring, patch management, security, and backup services, and provides full-lifecycle services to provision, run, and support your infrastructure. AWS Managed Services unburdens you from infrastructure operations so you can direct resources toward differentiating your business.
- On AWS: Service - FAQs - User Guide
AWS OpsWorks is a configuration management service that provides managed instances of Chef and Puppet. Chef and Puppet are automation platforms that allow you to use code to automate the configurations of your servers. OpsWorks lets you use Chef and Puppet to automate how servers are configured, deployed, and managed across your Amazon EC2 instances or on-premises compute environments.
- Declarative desired state engine
- Automate, monitor and maintain deployments
- AWS' implementation of Chef
- Original Chef
- AWS-bespoke orchestration components
- Cookbooks define recipes
- OpsWorks has three offerings:
- AWS OpsWorks Stacks (<- exam relevant)
- AWS Opsworks for Chef Automate
- AWS OpsWorks for Puppet Enterprise
- For Chef 11, BerkShelf is often used
- Allows to use external cookbooks
- On AWS: Service - FAQs - User Guide
- Stack
- Set of resources that are managed as a group * Need to enable custom cookbooks, this has to be enabled on stack level
- Layer
- Represent and configure components of a stack
- Share common configuration elements
- E.g. load balancer layer, app layer, db layer
- Type: OpsWorks, ECS or RDS
- If a layer has auto healing enabled—the default setting—AWS OpsWorks Stacks automatically replaces the layer's failed instances * After 5 minutes a non-responsive instance becomes failed.
- Instance
- Units of compute within the platform
- Must be associated with at least one layer
- Linux or Windows, but not both
- Can run
- 24/7
- Load-based
- Time-based
- Servers have to exist and to be pre-assigned to be e.g. load-based. So they are not created on demand.
- App
- Applications that are deployed on one or more instances
- Deployed through source code repo or S3
- Deployments
- Deploy application code and related files to application server instances
- Deployment operation is handled by each instance's Deploy recipes, which are determined by the instance's layer
- Can rollback up to 4 versions
- Each layer has a set of five lifecycle events, each of which has an associated set of recipes that are specific to the layer
- When an event occurs on a layer's instance, AWS OpsWorks Stacks automatically runs the appropriate set of recipes
| . | . |
|---|---|
| Setup | Occurs after a started instance has finished booting |
| Configure | Occurs on all of the stack's instances when one of the following occurs: * An instance enters or leaves the online state. * You associate an Elastic IP address with an instance or disassociate one from an instance. * You attach an Elastic Load Balancing load balancer to a layer, or detach one from a layer. |
| Deploy | Occurs when you run a Deploy command. |
| Undeploy | Occurs when you run a Undeploy command |
| Shutdown | Occurs after you direct AWS OpsWorks Stacks to shut an instance down but before the associated Amazon EC2 instance is actually terminated. |
- CloudWatch Events integration
- Can configure event rules to trigger alarms
- Under the hood
- OpsWorks agent
- Configuration of machines
- OpsWorks automation engine
- Create, update & delete of various AWS components
- Handles load balancing, auto scaling and auto healing
- Supports lifecycle events
- OpsWorks agent
- BerkShelf
- Addresses an OpsWorks shortcoming from old versions - only one repository for recipes
- Was added in OpsWorks 11.10 and allows to install cookbooks from many repositories
AWS Organizations offers policy-based management for multiple AWS accounts. With Organizations, you can create groups of accounts, automate account creation, apply and manage policies for those groups. Organizations enables you to centrally manage policies across multiple accounts, without requiring custom scripts and manual processes.
Using AWS Organizations, you can create Service Control Policies (SCPs) that centrally control AWS service use across multiple AWS accounts. You can also use Organizations to help automate the creation of new accounts through APIs. Organizations helps simplify the billing for multiple accounts by enabling you to setup a single payment method for all the accounts in your organization through consolidated billing. AWS Organizations is available to all AWS customers at no additional charge.
- On AWS: Service - FAQs - User Guide
- Centrally manage policies across multiple accounts
- Control access to AWS services
- Automate AWS account creation and management
- Consolidated billing
- One paying account linked to many linked accounts
- Pricing benefits (Volumes, Storage, Instances)
- Create account hierachy with Organizational Units (OUs)
- Apply SCPs across the hierachy
- Apply Tag Policies across the hierachy
Service control policies (SCPs) are one type of policy that you can use to manage your organization. SCPs offer central control over the maximum available permissions for all accounts in your organization, allowing you to ensure your accounts stay within your organization’s access control guidelines. SCPs are available only in an organization that has all features enabled. SCPs aren't available if your organization has enabled only the consolidated billing features. SCPs do not apply for the master account itself.
Tag policies are a type of policy that can help you standardize tags across resources in your organization's accounts. In a tag policy, you specify tagging rules applicable to resources when they are tagged.
| . | . |
|---|---|
| Maximum linked accounts | 20 |
AWS Personal Health Dashboard provides alerts and remediation guidance when AWS is experiencing events that may impact you. While the Service Health Dashboard displays the general status of AWS services, Personal Health Dashboard gives you a personalized view into the performance and availability of the AWS services underlying your AWS resources.
The dashboard displays relevant and timely information to help you manage events in progress, and provides proactive notification to help you plan for scheduled activities. With Personal Health Dashboard, alerts are triggered by changes in the health of AWS resources, giving you event visibility, and guidance to help quickly diagnose and resolve issues.
Amazon QuickSight is a fast, cloud-powered business intelligence service that makes it easy to deliver insights to everyone in your organization.
As a fully managed service, QuickSight lets you easily create and publish interactive dashboards that include ML Insights. Dashboards can then be accessed from any device, and embedded into your applications, portals, and websites.
- Data sources
- Amazon Athena
- Amazon Aurora
- Amazon Redshift
- Amazon S3
- Various SQL databases. Snowflake
- On AWS: Service - FAQs - User Guide
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. An Amazon Redshift data warehouse is a collection of computing resources called nodes, which are organized into a group called a cluster. Each cluster runs an Amazon Redshift engine and contains one or more databases.
- Queries are written in SQL
Amazon Relational Database Service (Amazon RDS) makes it easy to set up, operate, and scale a relational database in the cloud. It provides cost-efficient and resizable capacity while automating time-consuming administration tasks such as hardware provisioning, database setup, patching and backups. It frees you to focus on your applications so you can give them the fast performance, high availability, security and compatibility they need.
Amazon RDS is available on several database instance types - optimized for memory, performance or I/O - and provides you with six familiar database engines to choose from, including Amazon Aurora, PostgreSQL, MySQL, MariaDB, Oracle Database, and SQL Server. You can use the AWS Database Migration Service to easily migrate or replicate your existing databases to Amazon RDS.
- Automated backups
- Enabled by default
- Allow to recover database within a retention period (1d - 35d)
- Transactional storage engine recommended as DB engine
- Will take daily snapshot and use transaction logs
- PITR down to 1 second (within retention period)
- Backups are taken within defined window
- Degrades performance if multi-AZ is not enabled!
- Taken from slave if multi-AZ is enabled
- Backups are stored internaly on S3
- Free storage space equal to DB size
- Deleting an instance deletes all automated backups
- Cannot be shared with other accounts (need to be turned into manual snapshots first
- Database Snapshots
- Only manually, always user initiated
- Won't be deleted with DB instance
Provide enhanced availability for database instances within a single AWS Region.
- Meant for disaster recover, not for performance improvement (-> Read Replica)
- Configure RDS for multi-AZ deployments and turn replication on
- Keeps a synchronous standby replica in a different AZ
- Automatic failover in case of planned or unplanned outage of the first AZ
- Most likely still has downtime
- Can force failover by rebooting
- Other benefits
- Patching
- Backups
- Aurora can replicate accross 3 AZs
- Read queries are routed to read replicas, reducing load on primary db instance (source instance)
- To create read replicas, AWS initally creates a snapshot of the source instance
- Multi-AZ failover instance (if enabled) is used for snapshotting
- After that all read queries are then asynchronously copied to read replica
- Implies data latency, which typically is acceptable.
ReplicaLagcan be monitored and CloudWatch alarms can be configured
- No AWS charges for data replication in same region
- A single master can have up to 5 read replicas
- Can be in different regions
- Can have Multi-AZ enabled themselves
- Read replicas are not the same as multi-AZ failover instances which
- are synchronously updated
- are designed to handle failover
- don't receive any load unless failover actually happens
- Often it is beneficial to have both read replicas and multi-AZ failover instances
- Read replicas can be promoted to normal instances
- E.g. use read replica to implement bigger changes on db level, after these have been finished promote to master instance
- This will break replication
Amazon Route 53 is a highly available and scalable Domain Name System (DNS) web service. You can use Route 53 to perform three main functions in any combination: domain registration, DNS routing, and health checking. If you choose to use Route 53 for all three functions, perform the steps in this order:
- Register domain names
- Your website needs a name, such as example.com. Route 53 lets you register a name for your website or web application, known as a domain name.
- Route internet traffic to the resources for your domain
- When a user opens a web browser and enters your domain name (example.com) or subdomain name acme.example.com) in the address bar, Route 53 helps connect the browser with your website or web application.
- Check the health of your resources
- Route 53 sends automated requests over the internet to a resource, such as a web server, to verify that it's reachable, available, and functional. You also can choose to receive notifications when a resource becomes unavailable and choose to route internet traffic away from unhealthy resources.
- Hosts - Computers or services accessible within a domain
- Name Server - Translates domain names into IP addresses
- Zone File - Text file that contains mappings between domain names and IP addresses
- Records - Entries in zone file, mappings beween resources and names
Root Server -> TLD Server -> Domain-Level Name Server -> Zone File
Zone file stores records. Various records exists:
| Type | Definition | Example |
|---|---|---|
| SOA | State of Authority - Mandatory first entry, defines various things, eg name servers & admin contact |
ns1.dnsimple.com admin.dnsimple.com 2013022001 86400 7200 604800 300 |
| A | Map host name to ip4 address | px01.vc.example.com. 198.51.100.40 |
| AAAA | Map host name to ip6 address | px01.vc.example.com. 2a00:1450:4014:80c:0:0:0:2004 |
| CNAME | Defines alias for host name (maps one domain name to another) |
www.dnsimple.com. dnsimple.com. |
| MX | Defines mail exchange | example.com. 1800 MX mail1.example.com. 10 |
| PTR | Maps ip4 address to host name (inverse to A record) | 10.27/1.168.192.in-addr.arpa. 1800 PTR mail.example.com. |
| SVR | Points one domain to another domain name using a specific destination port | _sip._tcp.example.com. 86400 IN SRV 0 5 5060 sipserver.example.com. |
Route53 specific:
- Alias record
- Amazon Route 53 alias records provide a Route 53–specific extension to DNS functionality. Alias records let you route traffic to selected AWS resources, such as CloudFront distributions and Amazon S3 bucket. They also let you route traffic from one record in a hosted zone to another record.
- Unlike a CNAME record, you can create an alias record at the top node of a DNS namespace, also known as the zone apex. For example, if you register the DNS name example.com, the zone apex is example.com. You can't create a CNAME record for example.com, but you can create an alias record for example.com that routes traffic to www.example.com
- Preferred choice over CNAME (TODO: why?)
- Simple
- Default policy, typically used if only a single resource performs functionality
- Weighted
- Control distribution of traffic with DNS entries
- This can be based on a certain percentage
- Set routing policy to weighted (instead of failover)
- Control distribution of traffic with DNS entries
- Latency
- Control distribution of traffic based on latency.
- Failover
- Can set up health checks for endpoints or domains from within Route53
- Route 53 has health checkers in locations around the world. When you create a health check that monitors an endpoint, health checkers start to send requests to the endpoint that you specify to determine whether the endpoint is healthy.
evaluate target health
- DNS entries are then being associated with health checks and can be configured to failover as well (1 primary and n secondary recordsets)
- Can set up health checks for endpoints or domains from within Route53
- Geolocation
- Geolocation routing lets you choose the resources that serve your traffic based on the geographic location of your users, meaning the location that DNS queries originate from. For example, you might want all queries from Europe to be routed to an ELB load balancer in the Frankfurt region.
- Geoproximity Routing (Traffic Flow Only)
- Geoproximity routing lets Amazon Route 53 route traffic to your resources based on the geographic location of your users and your resources. You can also optionally choose to route more traffic or less to a given resource by specifying a value, known as a bias. A bias expands or shrinks the size of the geographic region from which traffic is routed to a resource.
- Multivalue Answer Routing
- Multivalue answer routing lets you configure Amazon Route 53 to return multiple values, such as IP addresses for your web servers, in response to DNS queries. You can specify multiple values for almost any record, but multivalue answer routing also lets you check the health of each resource, so Route 53 returns only values for healthy resources. It's not a substitute for a load balancer, but the ability to return multiple health-checkable IP addresses is a way to use DNS to improve availability and load balancing.
Amazon Simple Storage Service (S3) is object storage with a simple web service interface to store and retrieve any amount of data from anywhere on the web. It is designed to deliver 11x9 durability and scale past trillions of objects worldwide.
- Key-value storage (folder-like structure is only a UI representation)
- Bucket size is unlimited. Objects from 0B to 5TB.
- HA and scalable, transparent data partitioning
- Data is automatically replicated to at least 3 separate data centers in the same region
- Bucket lifecycle events can trigger SNS, SQS or AWS Lambda
- New object created events
- Object removal events
- Reduced Redundancy Storage (RRS) object lost event
- Buckets are per region, but AWS console is global (displaying all bucket for that account)
- Bucket names have to be globally unique, should comply with DNS naming conventions.
- On AWS: Service - FAQs - User Guide
- See also: AWS Geek 2018
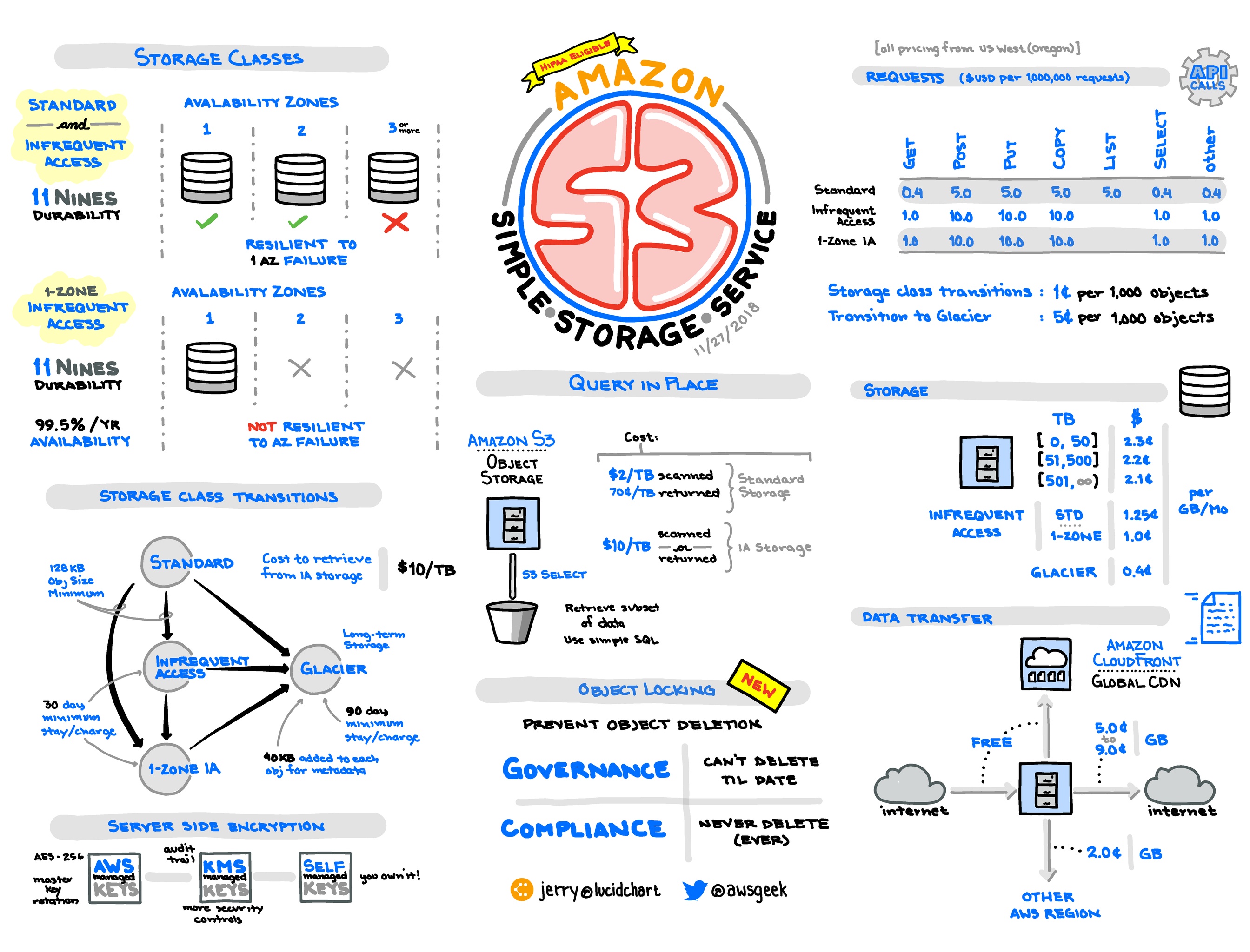{kind=link}
- Works on bucket level (for all objects)
- Versioning can either be unversioned (default), enabled or suspended
- Version ids are automatically assigned to objects
- AWS CloudTrail logs S3-API calls for bucket-level operations (and many other information) and stores them in an S3 bucket. Could also send email notifications or trigger SNS notifications for specific events.
- S3 Server Access Logs log on object level.
- Provide detailed records for the requests that are made to a bucket
- Needs to be enabled on bucket level
- Buckets must be in different regions
- Can replicate cross-account
- Must have versioning enabled
- Only new/changed objects will be replicated
| . | Durability | Availability | AZs | Costs per GB | Retrieval Fee | . |
|---|---|---|---|---|---|---|
| S3 Standard | 11x9 | 4x9 | >=3 | $0.023 | No | . |
| S3 Intelligent Tiering | 11x9 | 3x9 | >=3 | $0.023 | No | Automatically moves objects between two access tiers based on changing access patterns |
| S3 IA (infrequent access) | 11x9 | 3x9 | >=3 | $0.0125 | Yes | For data that is accessed less frequently, but requires rapid access when needed |
| S3 One Zone IA (infrequent access) | 11x9 | 99.5 | 1 | $0.01 | Yes | For data that is accessed less frequently, but requires rapid access when needed |
| Glacier | 11x9 | . | >=3 | . | Yes | For archival only, comes as expedited, standard or bulk |
| Glacier Deep Archive | 11x9 | . | >=3 | . | Yes | Longer time span to retrieve |
| 4x9 | 4x9 | >=3 | $0.024 | . | Deprecated |
- Effect – This can be either allow or deny
- Principal – Account or user who is allowed access to the actions and resources in the statement
- Actions – For each resource, S3 supports a set of operations
- Resources – Buckets and objects are the resources
- Authorization works as a union of IAM & bucket policies and bucket ACLs
- Bucket is owned by the AWS account that created it
- Ownership refers to the identity and email address used to create the account
- Bucket ownership is not transferable
- Ownership refers to the identity and email address used to create the account
- Bucket owner gets full permission (ACL)
- The person paying the bills always has full control.
- A person uploading an object into a bucket owns it by default.
- IAM policies (in general) specify what actions are allowed or denied on what AWS resources
- Defined as JSON
- Attached to IAM users, groups, or roles (so they cannot grant access to anonymous users)
- Use if you’re more interested in “What can this user do in AWS?”
- Specify what actions are allowed or denied for which principals on the bucket that the policy is attached to
- Defined as JSON
- Attached only to S3 buckets. Can however effect object in buckets.
- Contain principal element (unnecessary for IAM)
- Use if you’re more interested in “Who can access this S3 bucket?”
- Easiest way to grant cross-account permissions for all
s3:*permission. (Cannot do this with ACLs.)
- Defined as XML. Legacy, not recomended any more.
- Can
- be attached to individual objects (bucket policies only bucket level)
- control access to object uploaded into a bucket from a different account.
- Cannot..
- have conditions
- cannot explicitely deny actions
- grant permission to bucket sub-resources (eg. lifecycle or static website configurations)
- Other than object ACLs there are bucket ACLs as well - only for writing access log objects to a bucket.
AWS Secrets Manager helps you protect secrets needed to access your applications, services, and IT resources. The service enables you to easily rotate, manage, and retrieve database credentials, API keys, and other secrets throughout their lifecycle. Users and applications retrieve secrets with a call to Secrets Manager APIs, eliminating the need to hardcode sensitive information in plain text. Secrets Manager offers secret rotation with built-in integration for Amazon RDS, Amazon Redshift, and Amazon DocumentDB. Also, the service is extensible to other types of secrets, including API keys and OAuth tokens. In addition, Secrets Manager enables you to control access to secrets using fine-grained permissions and audit secret rotation centrally for resources in the AWS Cloud, third-party services, and on-premises.
- Allows for easier rotation than SSM Parameter Store
- Can trigger Lambda
- Deeply integrates into RDS
- On AWS: Service - FAQs - User Guide
- Define and implement rotation with an AWS Lambda function
- Creates a new version of the secret.
- Stores the secret in Secrets Manager.
- Configures the protected service to use the new version.
- Verifies the new version.
- Marks the new version as production ready.
AWS Service Catalog allows organizations to create and manage catalogs of IT services that are approved for use on AWS. These IT services can include everything from virtual machine images, servers, software, and databases to complete multi-tier application architectures. AWS Service Catalog allows you to centrally manage commonly deployed IT services, and helps you achieve consistent governance and meet your compliance requirements, while enabling users to quickly deploy only the approved IT services they need.
- Ensure compliance with corporate standards
- Help employees quickly find and deploy approved IT services
- Centrally manage IT service lifecycle
- Connect with ITSM/ITOM software
- Self-service for user
- Integrates with self-service portals like ServiceNow
- Users of Service Catalog only required IAM permissions for the product, but not the underlying services
- On AWS: Service - FAQs - User Guide
- Admins define
- Product
- Defined in CloudFormation
- Can be versioned
- Portfolio
- Collection of products
- IAM permissions to govern access
- Product
- Users choose
- from product list
- launches automatically
AWS Step Functions is a web service that enables you to coordinate the components of distributed applications and microservices using visual workflows. You build applications from individual components that each perform a discrete function, or task, allowing you to scale and change applications quickly.
Step Functions provides a reliable way to coordinate components and step through the functions of your application. Step Functions offers a graphical console to visualize the components of your application as a series of steps. It automatically triggers and tracks each step, and retries when there are errors, so your application executes in order and as expected, every time. Step Functions logs the state of each step, so when things go wrong, you can diagnose and debug problems quickly.
Step Functions manages the operations and underlying infrastructure for you to ensure your application is available at any scale.
- On AWS: Service - FAQs - User Guide
| . | . | . |
|---|---|---|
Pass |
Passes its input to its output, without performing work | . |
Task |
Represents a single unit of work performed by a state machine | Can Retry after error |
Choice |
Adds branching logic | . |
Wait |
Delays the state machine from continuing for a specified time | . |
Succeed |
Stops an execution successfully | . |
Fail |
Stops the execution of the state machine and marks it as a failure | . |
Parallel |
Create parallel branches of execution | Can Retry after error |
Map |
Run a set of steps for each element of an input array | . |
InputPath- Selects which parts of the JSON input to pass to the task of the Task state
OutputPath- Filter the JSON output to further limit the information that's passed to the output
ResultPath- Selects what combination of the state input and the task result to pass to the output.
Parameters- Collection of key-value pairs that are passed as input
- By default, when a state reports an error, AWS Step Functions causes the execution to fail entirely.
TaskandParallelstates can have a field named Retry, whose value must be an array of objects known as retriers.- An individual retrier represents a certain number of retries, usually at increasing time intervals.
- ErrorEquals (Required)
- IntervalSeconds (Optional)
- MaxAttempts (Optional)
- BackoffRate (Optional)
- Use Timeouts to Avoid Stuck Executions
- Specify a reasonable timeout when you create a task in your state machine
- Use ARNs Instead of Passing Large Payloads
- Avoid Reaching the History Quota
- Hard quota of 25,000 entries in the execution history. To avoid reaching this quota for long-running executions, implement a pattern that uses an AWS Lambda function that can start a new execution of your state machine to split ongoing work across multiple workflow executions
- Handle Lambda Service Exceptions
- Lambda can occasionally experience transient service errors - proactively handle these exceptions in your state machine
- Avoid Latency When Polling for Activity Tasks
- Choosing Standard or Express Workflows
- Choose Standard Workflows when you need long-running, durable, and auditable workflows,
- Choose Express Workflows for high-volume, event processing workloads.
AWS Systems Manager gives you visibility and control of your infrastructure on AWS. Systems Manager provides a unified user interface so you can view operational data from multiple AWS services and allows you to automate operational tasks across your AWS resources. With Systems Manager, you can group resources, like Amazon EC2 instances, Amazon S3 buckets, or Amazon RDS instances, by application, view operational data for monitoring and troubleshooting, and take action on your groups of resources. Systems Manager simplifies resource and application management, shortens the time to detect and resolve operational problems, and makes it easy to operate and manage your infrastructure securely at scale.
Group resources -> Visualize data -> Take action
- Manage EC2 and on-prem instances at scale
- On-prem requires generation of secret activation code/activation id
- Get operational insights of infrastructure
- Easily detect problems
- Patching automation for enhanced compliance
- Both Linux and Windows
- Tightly integrated with CloudWatch, AWS Config
- Free service
- SSM Agent
- Installed on instances
- Need correct IAM permissions, then shows up on SSM dashboard
- On AWS: Service - FAQs - User Guide
- Organize your AWS resources.
- Make it easier to manage, monitor, and automate tasks on large numbers of resources at one time.
- Define groups based on tags or on CloudFormation stacks
- Same region only
- Define groups based on tags or on CloudFormation stacks
- Insights dashboards
- Automatically aggregates and displays operational data for each resource group
- Inventory
- Discover and audit the software installed
- Configuration Compliance
- Scan your fleet of managed instances for patch compliance and configuration inconsistencies
- Centralized store to manage your configuration data, whether plain-text data such as database strings or secrets such as passwords
- Automation
- Simplifies common maintenance and deployment tasks of EC2 instances and other AWS resources.
- Build Automation workflows to configure and manage instances and AWS resources.
- Create custom workflows or use pre-defined workflows maintained by AWS.
- Receive notifications about Automation tasks and workflows by using Amazon CloudWatch Events.
- Monitor Automation progress and execution details by using the Amazon EC2 or the AWS Systems Manager console.
- Can integrate manual approval step
- Complete list of tasks, unlike run command which is a one-off
- E.g. create Golden AMi
- Maintenance windows
- Define a schedule for when to perform potentially disruptive actions on your instances
- Change Calendar
- Set up date and time ranges when actions you specify may or may not be performed in your AWS account
- Run command
- Lets you remotely and securely manage the configuration of your managed instances
- Commands are in document format
- Can run on resource group, individually or tag-based
- Session manager
- Fully managed AWS Systems Manager capability that lets you manage your EC2 instances, on-premises instances, and virtual machines (VMs) through an interactive one-click browser-based shell or through the AWS CLI.
- Session Manager provides secure and auditable instance management without the need to open inbound ports, maintain bastion hosts, or manage SSH keys
- Patch manager
- Automates the process of patching managed instances with both security related and other types of updates
- AWS predefined patch baselines per operating system
- Can also define own patch baselines
- Patch items in approved or rejected list, e.g. 'CVE-2020-1234567'
- Can define own patch source
- Can also define own patch baselines
- Define Maintenance Window when patches are possibly executed
- Use
AWS-RunPatchBaselinerun command - Can also evaluate compliance without applying patches
- State manager
- Secure and scalable configuration management service that automates the process of keeping your Amazon EC2 and hybrid infrastructure in a state that you define
- SSM Documents
- JSON format
- Different types:
- Command
- Automation
- Policy
- Session
- AWS Trusted Advisor is an online tool that provides you real time guidance to help you provision your resources following AWS best practices. Whether establishing new workflows, developing applications, or as part of ongoing improvement, take advantage of the recommendations provided by Trusted Advisor on a regular basis to help keep your solutions provisioned optimally.
- Global service
- Creates recommendations for
- Cost optimization
- Performance
- Security
- Fault tolerance
- Service limits
- Trusted Advisor check results are raised as CloudWatch Events
- Automate by triggering Lambdas
- Events are only available in
us-east-1
- Checks are refreshed on visits to the dashboard (max every 5 minutes)
- Otherwise weekly
- Can trigger refresh via API
- On AWS: Service - FAQs - User Guide
AWS X-Ray helps developers analyze and debug production, distributed applications, such as those built using a microservices architecture. With X-Ray, you can understand how your application and its underlying services are performing to identify and troubleshoot the root cause of performance issues and errors. X-Ray provides an end-to-end view of requests as they travel through your application, and shows a map of your application’s underlying components. You can use X-Ray to analyze both applications in development and in production, from simple three-tier applications to complex microservices applications consisting of thousands of services.
- X-Ray demon would run on EC2-instances/Elastic Beanstalk instances/ECS
- X-Ray SDK to send signals
- X-Ray API collects information
- Automation could base on regular polling of
GetServiceGraph
- Automation could base on regular polling of
- X-Ray Console displays information in service map
- On AWS: Service - FAQs - User Guide
--
- Aurora
- CloudFront
- CloudWatch Metrics
- CodeBuild
- CodeCommit
- CodePipeline
- Cognito
- Direct Connect
- EBS
- EC2
- Elastic Beanstalk
- Elastic Load Balancing
- ECR
- Fargate
- GitHub
- IAM
- Kinesis Data Streams
- Personal Health Dashboard
- RDS
- S3
- Secrets Manager
- Server Migration Service
- SQS
- Trusted Advisor
- SSO
- Can have up to 15 read replicas
- Can have a Global Database, spawning across multiple regions
- Available for both MySQL and PostgreSQL
- Can have 'Reader Endpoint' - load-balances connections to available Aurora Replicas in an Aurora DB cluster
- You must ensure that the certificate you wish to associate with your Alternate Domain Name is from a trusted CA, has a valid date and is formatted correctly. Wildcard certificates do work with Alternate Domain Names providing they match the main domain, and they also work with valid Third Party certificates. If all of these elements are correct, it may be that there was an internal CloudFront HTTP 500 being generated at the time of configuration, which should be transient and will resolve if you try again.
aws cfn put-metric-data- Publishes metric data points to Amazon CloudWatch- Use
EstimatedChargesmetric to track your estimated AWS charges
CODEBUILD_SOURCE_VERSION- For CodeCommit, it is the commit ID or branch name associated with the version of the source code to be built.MSBuildcontainer image is required for building .NET applications
- Value for local ssh-config needs to match SSH key id from IAM Security Credentials
CodePipeline Pipeline Execution State Change.is the detail-type of the CloudWatch Event raised for pipeline failures- AWS DeviceFarm is an action provider
- Amazon Cognito provides authentication, authorization, and user management for your web and mobile apps. Your users can sign in directly with a user name and password, or through a third party such as Facebook, Amazon, Google or Apple.
- Direct Connect is the only way to access your AWS resources from a Data Center without traversing the internet
- In order to encrypt a EBS snapshot, copy the unencrypted snapshot and tick the checkbox to encrypt the target
- Amazon Data Lifecycle Manager (DLM) for EBS Snapshots provides a simple, automated way to back up data stored on Amazon EBS volumes. You can define backup and retention schedules for EBS snapshots by creating lifecycle policies based on tags.
- In order to get access to the CPU sockets for billing purposes, you need to use EC2 Dedicated Hosts
- To maximise networking performance, Jumbo frames (9001 MTU) allow more than 1500 bytes of data
Dockerrun.aws.jsonv2 is the file to configure a multi-container Docker environment
IPv6is only supported by Application Load Balancers, not NLB, not Classic- Network Load Balancers do not use security groups. This is different from Classic Load Balancer or Application Load Balancer.
- Adding the SHA256 to a docker image URL makes sure that ECS get the latest images. Otherwise, it might still get the previous
:latest.
- If a container image requires many network connections (e.g. Websocket) it's better installed as multiple tasks across an ECS Cluster
- One ENI per task
- ECS: ENIs come from underlying instance
- The number of OAUTH tokens is limited and CodePipeline might stop working with older tokens
- Create and configure an IAM SAML Identity Provider, create a role with a SAML Trusted Entity, Configure AD, Configure ADFS with Relay Party, Create Custom Claim Rules
- Can store server certificates - only recommended for regions that don't support ACM
- Access Advisor show last services accessed per OU
- When using KCL, make sure
getRecordsis not throwing unhandled exceptions - Ensure the
maxRecordsvalue for theGetRecordscall isn't set below the default setting - When resharding, sometimes a small shard is left over
- This occurs when the width of a shard is very small in size in relation to other shards in the stream. This is resolved by merging with any adjacent shard.
- The
AWS_RISK_CREDENTIALS_EXPOSEDis exposed by the Personal Health Dashboard service. - Integrates with CloudWatch Events, but cannot send notifications directly
EngineVersion- The version number of the database engine to use.
- When encrypting at rest,
SSE-S3is more performant asSSE-KMS, as the latter gets throttled above 10,000 objects per seconds - The Amazon S3 notification feature enables you to receive notifications when certain events happen in your bucket.
- Length of a secret - 65,536 bytes
- You should ask the external party for a DB user with at least two credential sets or the ability to create new users yourself. Otherwise, you might encounter client sign-on failures. The risk is because of the time lag that can occur between the change of the actual password and - when using Secrets Manager - the change in the corresponding secret that tells the client which password to use.
- The Server Migration Service replication job generates an AMI after the job is finished. However, it does not automatically launch EC2 instances.
- You can use Amazon S3 and the Amazon SQS Extended Client Library for Java to manage Amazon SQS messages. This is especially useful for storing and consuming messages up to 2 GB in size.
- In CloudWatch Events, use
check item refresh statusto only observe some events
- You can use the User Principal Name (UPN) or the DOMAIN\UserName format to authenticate with AD, but you can't use the UPN format if you have two-step verification and Context-aware verification enabled.
- AWS Organisations and the AWS Managed Microsoft AD must be in the same account and the same region
- AD Connector is a directory gateway with which you can redirect directory requests to your on-premises Microsoft Active Directory without caching any information in the cloud.