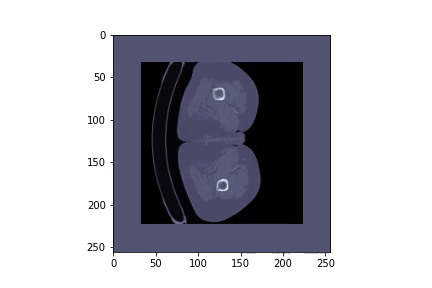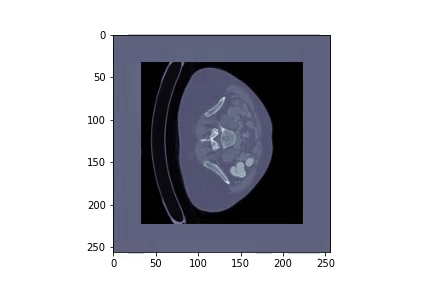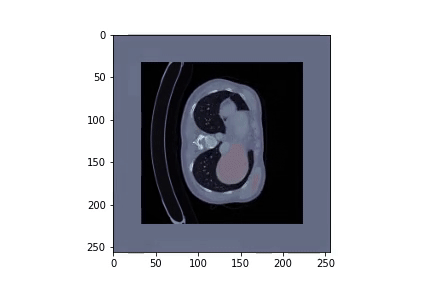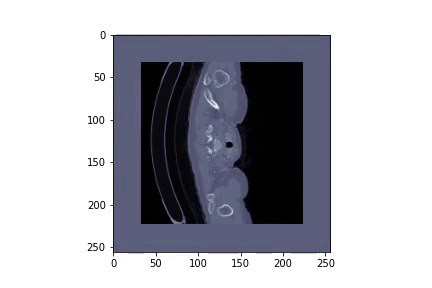
In this project we will download and preprocess the data for the liver and liver tumor segmentation:
The data is provided by the medical segmentation decathlon (http://medicaldecathlon.com/)
(Data License: https://creativecommons.org/licenses/by-sa/4.0/)
You can directly download the original cardiac MRIs and segmentation maps from:
https://drive.google.com/file/d/1g53iS9HCNXpbEpyOq2vYBZg_4P5ofSrl/view?usp=sharing
As this dataset has over 26GB we provide a resampled version of it. The new scans are of shape (256x256xZ), where Z is varying and reduce the size of the dataset to 2.5GB
We do not need to preprocess this dataset as the necessary steps are directly performed by torchio during training.

We will use the most famous architecture for this task, the U-NET (https://arxiv.org/abs/1505.04597).
The idea behind a UNET is the Encoder-Decoder architecture with additional skip-connctions on different levels:
The encoder reduces the size of the feature maps by using downconvolutional layers.
The decoder reconstructs a mask of the input shape over several layers by upsampling.
Additionally skip-connections allow a direct information flow from the encoder to the decoder on all intermediate levels of the UNET.
This allows for a high quality of the produced mask and simplifies the training process.

We can use the 2D-UNET architecture with some small changes(3D-UNET):
- Conv2d -> Conv3d
- MaxPool2d -> MaxPool3d
- "trilinear" upsampling method
- Three Output Channels instead of One to model background, liver and tumor
Additionally we drastically reduce the filters used in the convolutions to shrinken the network size
Regarding the processing, we use the CropOrPad functionality which crops or pads all images and masks to the same shape.
We use (
In order to help the segmentation network learn, we use the LabelSampler with p=0.2 for background, p=0.3 for liver and p=0.5 for liver tumors with a patch size of (
Then, we will create the queue to draw patches from.
The tio.Queue accepts a SubjectsDataset, a max_length argument describing the the number of patches that can be stored, the number of patches to draw from each subject, a sampler and the number of workers according to the hardware capability.
Finally we will create the Segmentation model.
We use the Adam optimizer with a learning rate of 1e-4 and a weighted cross-entropy loss, which assigns a threefold increased loss to tumorous voxels.
The model was trained in a patch wise manner as the full volumes are too large to be placed on a typical GPU.
But we still want to get a result for the whole volume.
torchio helps us doing so by performing Patch Aggregation
The goal of patch aggregation is to split the image into patches, then compute the segmentation for each patch and finally merge the predictions into the prediction for the full volume.
The pipeline is as follows:
- Define the GridSampler(subject, patch_size, patch_overlap) responsible for dividing the volume into patches. Each patch is defined by its location accesible via tio.LOCATION
- Define the GridAggregator(grid_sampler) which merges the predicted patches back together
- Compute the prediction on the patches and aggregate them via aggregator.add_batch(pred, location)
- Extract the full prediction via aggregator.get_output_tensor()
Additionally, we can leverage the DataLoader from pytorch to perform the prediction in a batch wise manner for a nice speed up.
Finally we can visualize the prediction: