diff --git a/docs/_include/card/timeseries-datashader.md b/docs/_include/card/timeseries-datashader.md
index 16b5096c..e3552055 100644
--- a/docs/_include/card/timeseries-datashader.md
+++ b/docs/_include/card/timeseries-datashader.md
@@ -10,9 +10,8 @@ points from your backend systems to the browser's glass.
This notebook plots the venerable NYC Taxi dataset after importing it
into a CrateDB Cloud database cluster.
-```{todo}
-🚧 This notebook is a work in progress. 🚧
-```
+**Note:** 🚧 This notebook is a work in progress. 🚧
+
{{ '{}[cloud-datashader-github]'.format(nb_github) }} {{ '{}[cloud-datashader-colab]'.format(nb_colab) }}
:::
diff --git a/docs/_include/links.md b/docs/_include/links.md
index 543604b5..cb9294ad 100644
--- a/docs/_include/links.md
+++ b/docs/_include/links.md
@@ -1,3 +1,4 @@
+
[Amazon DynamoDB Streams]: https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Streams.html
@@ -60,9 +61,10 @@
[query DSL based on JSON]: https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html
[RANK]: inv:crate-reference#window-functions-rank
[Relational Database]: https://cratedb.com/solutions/relational-database
+[Replicating CDC events from DynamoDB to CrateDB]: https://cratedb.com/blog/replicating-cdc-events-from-dynamodb-to-cratedb
+[Replicating CDC events to CrateDB using AWS DMS]: https://cratedb.com/blog/replicating-cdc-events-to-cratedb-using-aws-dms
[Replicating data to CrateDB with Debezium and Kafka]: https://community.cratedb.com/t/replicating-data-to-cratedb-with-debezium-and-kafka/1388
[TF–IDF]: https://en.wikipedia.org/wiki/Tf%E2%80%93idf
-[Replicating CDC events from DynamoDB to CrateDB]: https://cratedb.com/blog/replicating-cdc-events-from-dynamodb-to-cratedb
[timeseries-queries-and-visualization-colab]: https://colab.research.google.com/github/crate/cratedb-examples/blob/main/topic/timeseries/timeseries-queries-and-visualization.ipynb
[timeseries-queries-and-visualization-github]: https://github.com/crate/cratedb-examples/blob/main/topic/timeseries/timeseries-queries-and-visualization.ipynb
[Vector Database (Product)]: https://cratedb.com/solutions/vector-database
diff --git a/docs/_include/styles.html b/docs/_static/css/custom.css
similarity index 62%
rename from docs/_include/styles.html
rename to docs/_static/css/custom.css
index f3962cc4..56ac4537 100644
--- a/docs/_include/styles.html
+++ b/docs/_static/css/custom.css
@@ -1,10 +1,19 @@
-
-
+/* When a logo wants to be displayed next to the title */
+
+#main-content h1 {
+ display: inline-flex;
+ align-items: center;
+ gap: 0.5rem; /* space between logo and title */
+}
+/* Optional: ensure logos inside h1 scale and align nicely */
+#main-content h1 img {
+ vertical-align: middle;
+ max-height: 2rem; /* adjust as needed per design */
+}
diff --git a/docs/conf.py b/docs/conf.py
index 65727aed..62708699 100644
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -1,6 +1,8 @@
from crate.theme.rtd.conf.cratedb_guide import *
# Fallback guards, when parent theme does not introduce relevant variables.
+if "html_css_files" not in globals():
+ html_css_files = []
if "html_theme_options" not in globals():
html_theme_options = {}
if "intersphinx_mapping" not in globals():
@@ -94,3 +96,8 @@
"tutorial": "[]",
"readmore": "[]",
})
+
+
+html_css_files += [
+ 'css/custom.css',
+]
diff --git a/docs/connect/index.md b/docs/connect/index.md
index eabefec2..58e4e24b 100644
--- a/docs/connect/index.md
+++ b/docs/connect/index.md
@@ -3,8 +3,6 @@
:::{include} /_include/links.md
:::
-:::{include} /_include/styles.html
-:::
:::::{grid}
:padding: 0
diff --git a/docs/feature/blob/index.md b/docs/feature/blob/index.md
index 4bdf3bf0..5e3c8648 100644
--- a/docs/feature/blob/index.md
+++ b/docs/feature/blob/index.md
@@ -3,8 +3,6 @@
:::{include} /_include/links.md
:::
-:::{include} /_include/styles.html
-:::
:::::{grid}
diff --git a/docs/feature/ccr/index.md b/docs/feature/ccr/index.md
index 623cbfe3..869c2afe 100644
--- a/docs/feature/ccr/index.md
+++ b/docs/feature/ccr/index.md
@@ -3,8 +3,6 @@
:::{include} /_include/links.md
:::
-:::{include} /_include/styles.html
-:::
:::::{grid}
:padding: 0
diff --git a/docs/feature/cloud/index.md b/docs/feature/cloud/index.md
index 9e2d27d0..8ba7a419 100644
--- a/docs/feature/cloud/index.md
+++ b/docs/feature/cloud/index.md
@@ -3,8 +3,6 @@
:::{include} /_include/links.md
:::
-:::{include} /_include/styles.html
-:::
:::::{grid}
diff --git a/docs/feature/cluster/index.md b/docs/feature/cluster/index.md
index 03ef3287..835c8878 100644
--- a/docs/feature/cluster/index.md
+++ b/docs/feature/cluster/index.md
@@ -3,8 +3,6 @@
:::{include} /_include/links.md
:::
-:::{include} /_include/styles.html
-:::
:::::{grid}
diff --git a/docs/feature/document/index.md b/docs/feature/document/index.md
index 696b4769..dd513141 100644
--- a/docs/feature/document/index.md
+++ b/docs/feature/document/index.md
@@ -429,6 +429,3 @@ and about OBJECT indexing.
learn
```
-
-```{include} /_include/styles.html
-```
diff --git a/docs/feature/fdw/index.md b/docs/feature/fdw/index.md
index 2be224a6..3dcb5976 100644
--- a/docs/feature/fdw/index.md
+++ b/docs/feature/fdw/index.md
@@ -3,8 +3,6 @@
:::{include} /_include/links.md
:::
-:::{include} /_include/styles.html
-:::
:::::{grid}
:padding: 0
diff --git a/docs/feature/index.md b/docs/feature/index.md
index e9fc0117..cfe721c3 100644
--- a/docs/feature/index.md
+++ b/docs/feature/index.md
@@ -3,9 +3,6 @@
(all-features)=
# All Features
-:::{include} /_include/styles.html
-:::
-
All features of CrateDB at a glance.
:::::{grid} 1 3 3 3
diff --git a/docs/feature/index/index.md b/docs/feature/index/index.md
index f8b0cfe2..edbcfee0 100644
--- a/docs/feature/index/index.md
+++ b/docs/feature/index/index.md
@@ -3,8 +3,6 @@
:::{include} /_include/links.md
:::
-:::{include} /_include/styles.html
-:::
:::::{grid}
diff --git a/docs/feature/relational/index.md b/docs/feature/relational/index.md
index 9607b02e..16bdc9e8 100644
--- a/docs/feature/relational/index.md
+++ b/docs/feature/relational/index.md
@@ -5,8 +5,6 @@
:::{include} /_include/links.md
:::
-:::{include} /_include/styles.html
-:::
:::::{grid}
:padding: 0
diff --git a/docs/feature/search/fts/index.md b/docs/feature/search/fts/index.md
index 26e49cea..79f2de5b 100644
--- a/docs/feature/search/fts/index.md
+++ b/docs/feature/search/fts/index.md
@@ -7,8 +7,6 @@
:::{include} /_include/links.md
:::
-:::{include} /_include/styles.html
-:::
:::::{grid}
diff --git a/docs/feature/search/geo/index.md b/docs/feature/search/geo/index.md
index acc84e87..9ef1e3af 100644
--- a/docs/feature/search/geo/index.md
+++ b/docs/feature/search/geo/index.md
@@ -7,8 +7,6 @@
:::{include} /_include/links.md
:::
-:::{include} /_include/styles.html
-:::
:::::{grid}
diff --git a/docs/feature/search/hybrid/index.md b/docs/feature/search/hybrid/index.md
index 3f163f48..938cb55d 100644
--- a/docs/feature/search/hybrid/index.md
+++ b/docs/feature/search/hybrid/index.md
@@ -4,8 +4,6 @@
:::{include} /_include/links.md
:::
-:::{include} /_include/styles.html
-:::
:::::{grid}
:padding: 0
diff --git a/docs/feature/search/index.md b/docs/feature/search/index.md
index 99428622..7dca49a4 100644
--- a/docs/feature/search/index.md
+++ b/docs/feature/search/index.md
@@ -1,9 +1,6 @@
(search-overview)=
# Search
-:::{include} /_include/styles.html
-:::
-
Based on Apache Lucene, CrateDB offers native BM25 term search and vector
search, all using SQL. By combining it, also using SQL, you can implement
powerful single-query hybrid search.
diff --git a/docs/feature/search/vector/index.md b/docs/feature/search/vector/index.md
index 86f1b449..981693d0 100644
--- a/docs/feature/search/vector/index.md
+++ b/docs/feature/search/vector/index.md
@@ -6,8 +6,6 @@
:::{include} /_include/links.md
:::
-:::{include} /_include/styles.html
-:::
**Vector search on machine learning embeddings: CrateDB is all you need.**
diff --git a/docs/feature/snapshot/index.md b/docs/feature/snapshot/index.md
index 61d93ae6..7ebf24e2 100644
--- a/docs/feature/snapshot/index.md
+++ b/docs/feature/snapshot/index.md
@@ -4,9 +4,6 @@
:::{include} /_include/links.md
:::
-:::{include} /_include/styles.html
-:::
-
:::::{grid}
diff --git a/docs/feature/sql/index.md b/docs/feature/sql/index.md
index cf5459ea..bce7f50f 100644
--- a/docs/feature/sql/index.md
+++ b/docs/feature/sql/index.md
@@ -4,8 +4,6 @@
:::{include} /_include/links.md
:::
-:::{include} /_include/styles.html
-:::
:::::{grid}
:padding: 0
diff --git a/docs/feature/storage/index.md b/docs/feature/storage/index.md
index 48383cd9..42f81673 100644
--- a/docs/feature/storage/index.md
+++ b/docs/feature/storage/index.md
@@ -3,8 +3,6 @@
:::{include} /_include/links.md
:::
-:::{include} /_include/styles.html
-:::
The CrateDB storage layer is based on Lucene. By default, all fields are indexed,
nested or not, but the indexing can be turned off selectively.
diff --git a/docs/feature/udf/index.md b/docs/feature/udf/index.md
index fdf973e1..1a50452d 100644
--- a/docs/feature/udf/index.md
+++ b/docs/feature/udf/index.md
@@ -3,8 +3,6 @@
:::{include} /_include/links.md
:::
-:::{include} /_include/styles.html
-:::
:::::{grid}
diff --git a/docs/ingest/cdc/index.md b/docs/ingest/cdc/index.md
index f11a18c8..f3bb534f 100644
--- a/docs/ingest/cdc/index.md
+++ b/docs/ingest/cdc/index.md
@@ -5,23 +5,21 @@
:::
:::{div}
-Options to connect and integrate CrateDB with third-party
-CDC applications, mostly using [CrateDB's PostgreSQL interface].
-CrateDB also provides native adapter components to leverage advanced
-features.
-
-This documentation section lists CDC applications,
-frameworks, and solutions, which can be used together with CrateDB,
-and outlines how to use them optimally.
-Additionally, see support for {ref}`generic ETL ` solutions.
+Options to integrate CrateDB with third‑party CDC applications, typically via
+[CrateDB's PostgreSQL interface]. CrateDB also provides native adapter components
+to leverage advanced features.
+
+This section lists ETL applications and frameworks that work with CrateDB, and
+outlines how to use them effectively. Additionally, see support for
+{ref}`generic ETL ` solutions.
:::
## Connectors
-Native and specialized connectors for CrateDB, both managed and unmanaged.
+Native and specialized integration connectors for CrateDB, both managed and unmanaged.
-:::::{grid} 1
+:::::{grid} 3
:gutter: 2
::::{grid-item-card} Amazon DynamoDB
@@ -51,9 +49,10 @@ or multi-cloud.
## Platforms
-Support for data integration frameworks and platforms, both managed and unmanaged.
+CrateDB supports popular third-party data integration frameworks and platforms,
+both managed and unmanaged.
-:::::{grid} 1
+:::::{grid} 2
:gutter: 2
::::{grid-item-card} AWS DMS
diff --git a/docs/ingest/etl/index.md b/docs/ingest/etl/index.md
index bf864714..22fb6073 100644
--- a/docs/ingest/etl/index.md
+++ b/docs/ingest/etl/index.md
@@ -5,19 +5,14 @@
:::{include} /_include/links.md
:::
-:::{include} /_include/styles.html
-:::
:::{div}
-Options to connect and integrate CrateDB with third-party
-ETL applications, mostly using [CrateDB's PostgreSQL interface].
-CrateDB also provides native adapter components to leverage advanced
-features.
-
-This documentation section lists ETL applications and
-frameworks which can be used together with CrateDB, and outlines how
-to use them optimally.
-Additionally, see support for {ref}`cdc` solutions.
+Options to integrate CrateDB with third‑party ETL applications, typically via
+[CrateDB's PostgreSQL interface]. CrateDB also provides native adapter components
+to leverage advanced features.
+
+This section lists ETL applications and frameworks that work with CrateDB, and
+outlines how to use them effectively. Additionally, see support for {ref}`cdc` solutions.
:::
@@ -69,7 +64,7 @@ Additionally, see support for {ref}`cdc` solutions.
specification, including powerful data extraction and consolidation elements.
+++
-Data pipeline programming frameworks and platforms.
+Use data pipeline programming frameworks and platforms.
::::
@@ -97,7 +92,7 @@ Data pipeline programming frameworks and platforms.
applications.
+++
-Visual data flow and integration frameworks and platforms.
+Use visual data flow and integration frameworks and platforms.
::::
diff --git a/docs/ingest/index.md b/docs/ingest/index.md
index 56230b19..4b8610ce 100644
--- a/docs/ingest/index.md
+++ b/docs/ingest/index.md
@@ -1,9 +1,6 @@
(ingest)=
# CrateDB data ingestion
-:::{include} /_include/styles.html
-:::
-
All data ingestion methods for CrateDB at a glance.
:::::{grid} 1 2 2 2
diff --git a/docs/integrate/apache-airflow/index.md b/docs/integrate/apache-airflow/index.md
index e8baaecc..e2b6c462 100644
--- a/docs/integrate/apache-airflow/index.md
+++ b/docs/integrate/apache-airflow/index.md
@@ -6,43 +6,37 @@
:::{include} /_include/links.md
:::
+```{div} .float-right
+[{height=60px loading=lazy}][Apache Airflow]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-```{div}
-:style: "float: right"
-[{w=180px}](https://airflow.apache.org/)
-
-[{w=180px}](https://www.astronomer.io/)
-```
:::{div}
[Apache Airflow] is an open source software platform to programmatically author,
schedule, and monitor workflows, written in Python.
-[Astronomer] offers managed Airflow services on the cloud of your choice, in
-order to run Airflow with less overhead.
+[Astronomer] offers managed Airflow services on the cloud of your choice, to
+run Airflow with less overhead.
+:::
+:::{dropdown} **Details**
Airflow has a modular architecture and uses a message queue to orchestrate an
arbitrary number of workers. Pipelines are defined in Python, allowing for
dynamic pipeline generation and on-demand, code-driven pipeline invocation.
-Pipeline parametrization is using the powerful Jinja templating engine.
+Pipeline parameterization is using the powerful Jinja templating engine.
To extend the system, you can define your own operators and extend libraries
to fit the level of abstraction that suits your environment.
:::
-```{div}
-:style: "clear: both"
-```
-
-```{seealso}
-[CrateDB and Apache Airflow]
-```
-
:::{dropdown} **Managed Airflow**
```{div}
:style: "float: right"
-[{w=180px}](https://www.astronomer.io/)
+[{w=180px}](https://www.astronomer.io/)
```
[Astro][Astronomer] is the best managed service in the market for teams on any step of their data
@@ -59,44 +53,75 @@ journey. Spend time where it counts.
behind the project. Get world-class support, fast-tracked bug fixes, and same-day
access to new Airflow versions.
-```{div}
-:style: "clear: both"
+```{div} .clearfix
```
+
+:::
+
+
+:::{rubric} Learn: Starter Tutorials
+:::
+
+::::{grid} 2
+
+:::{grid-item-card} Tutorial: Import Parquet files
+:link: https://community.cratedb.com/t/automating-the-import-of-parquet-files-with-apache-airflow/1247
+:link-type: url
+Define an Airflow DAG to import a Parquet file from S3 into CrateDB.
+:::
+
+:::{grid-item-card} Tutorial: Load stock market data
+:link: https://community.cratedb.com/t/updating-stock-market-data-automatically-with-cratedb-and-apache-airflow/1304
+:link-type: url
+Define an Airflow DAG to download, process, and store stock market data
+into CrateDB.
:::
+::::
+
-:::{rubric} Learn
+:::{rubric} Learn: Advanced Tutorials
:::
-A set of starter tutorials.
+::::{grid} 3
+
+:::{grid-item-card} Tutorial: Export to S3
+:link: https://community.cratedb.com/t/cratedb-and-apache-airflow-automating-data-export-to-s3/901
+:link-type: url
+Recurrently export data from CrateDB to S3.
+:::
-- [Automating the import of Parquet files with Apache Airflow]
-- [Updating stock market data automatically with CrateDB and Apache Airflow]
-- [Automating stock data collection and storage with CrateDB and Apache Airflow]
+:::{grid-item-card} Tutorial: Implement a data retention policy
+:link: https://community.cratedb.com/t/implementing-a-data-retention-policy-in-cratedb-using-apache-airflow/913
+:link-type: url
+An effective retention policy for time-series data, relating to the practice of
+storing and managing data for a designated period of time.
+:::
-A set of elaborated tutorials, including blueprint implementations.
+:::{grid-item-card} Tutorial: Implement a hot and cold storage data retention policy
+:link: https://community.cratedb.com/t/cratedb-and-apache-airflow-building-a-hot-cold-storage-data-retention-policy/934
+:link-type: url
+A hot/cold storage strategy is often motivated by a tradeoff between performance
+and cost-effectiveness.
+:::
-- [Automating export of CrateDB data to S3 using Apache Airflow]
-- [Implementing a data retention policy in CrateDB using Apache Airflow]
-- [CrateDB and Apache Airflow: Building a data ingestion pipeline]
-- [Building a hot and cold storage data retention policy in CrateDB with Apache Airflow]
+::::
-Tutorials and resources about configuring the managed variants, Astro and CrateDB Cloud.
-- [ETL with Astro and CrateDB Cloud in 30min - fully up in the cloud]
-- [ETL pipeline using Apache Airflow with CrateDB (Source)]
-- [Run an ETL pipeline with CrateDB and data quality checks]
+```{seealso}
+**Repository:**
+
+**Product:** [CrateDB and Apache Airflow]
+
+**Web:**
+[ETL with Astro and CrateDB Cloud in 30min - fully up in the cloud] |
+[ETL pipeline using Apache Airflow with CrateDB (Source)] |
+[Run an ETL pipeline with CrateDB and data quality checks]
+```
-[Automating export of CrateDB data to S3 using Apache Airflow]: https://community.cratedb.com/t/cratedb-and-apache-airflow-automating-data-export-to-s3/901
-[Automating stock data collection and storage with CrateDB and Apache Airflow]: https://community.cratedb.com/t/automating-stock-data-collection-and-storage-with-cratedb-and-apache-airflow/990
-[Automating the import of Parquet files with Apache Airflow]: https://community.cratedb.com/t/automating-the-import-of-parquet-files-with-apache-airflow/1247
-[Building a hot and cold storage data retention policy in CrateDB with Apache Airflow]: https://community.cratedb.com/t/cratedb-and-apache-airflow-building-a-hot-cold-storage-data-retention-policy/934
[CrateDB and Apache Airflow]: https://cratedb.com/integrations/cratedb-and-apache-airflow
-[CrateDB and Apache Airflow: Building a data ingestion pipeline]: https://community.cratedb.com/t/cratedb-and-apache-airflow-building-a-data-ingestion-pipeline/926
[ETL pipeline using Apache Airflow with CrateDB (Source)]: https://github.com/astronomer/astro-cratedb-blogpost
[ETL with Astro and CrateDB Cloud in 30min - fully up in the cloud]: https://www.astronomer.io/blog/run-etlelt-with-airflow-and-cratedb/
-[Implementing a data retention policy in CrateDB using Apache Airflow]: https://community.cratedb.com/t/implementing-a-data-retention-policy-in-cratedb-using-apache-airflow/913
[Run an ETL pipeline with CrateDB and data quality checks]: https://registry.astronomer.io/dags/etl_pipeline/
-[Updating stock market data automatically with CrateDB and Apache Airflow]: https://community.cratedb.com/t/updating-stock-market-data-automatically-with-cratedb-and-apache-airflow/1304
diff --git a/docs/integrate/apache-flink/index.md b/docs/integrate/apache-flink/index.md
index 34744e6e..7ec42589 100644
--- a/docs/integrate/apache-flink/index.md
+++ b/docs/integrate/apache-flink/index.md
@@ -5,9 +5,13 @@
:::{include} /_include/links.md
:::
-```{div}
-:style: "float: right"
-[{w=180px}](https://flink.apache.org/)
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][Apache Flink]
+
+
+  +```
+```{div} .clearfix
```
[Apache Flink] is a programming framework and distributed processing engine
@@ -15,6 +19,8 @@ for stateful computations over unbounded and bounded data streams, written
in Java. It is a battle-hardened stream processor widely used for demanding
real-time applications.
+:::{dropdown} **Details**
+
Flink has been designed to run in all common cluster environments, perform
computations at in-memory speed and at any scale. It received the [2023 SIGMOD
Systems Award].
@@ -32,10 +38,6 @@ A few companies are specializing in offering managed Flink services.
see [Confluent Streaming Data Pipelines].
:::
-```{div}
-:style: "clear: both"
-```
-
## Connect
Flink's [JdbcSink] is a streaming connector that writes data to a JDBC database,
@@ -125,15 +127,38 @@ JdbcSink.sink(
:::{rubric} Tutorials
:::
-- [Build a data ingestion pipeline using Kafka, Flink, and CrateDB]
-:::{rubric} Development
+::::{grid}
+:gutter: 2
+
+:::{grid-item-card} Tutorial: Build a data ingestion pipeline
+:link: https://dev.to/crate/build-a-data-ingestion-pipeline-using-kafka-flink-and-cratedb-1h5o
+:link-type: url
+:columns: 12
+The tutorial explains how to build a data ingestion pipeline using three
+open-source tools: Apache Kafka, Flink, and CrateDB.
++++
+Example: Kafka receives telemetry messages from IoT sensors and devices. Flink
+consumes the data stream and stores it into CrateDB. All tools are distributed
+systems that provide elastic scaling, fault tolerance, high-throughput, and
+low-latency performance via parallel processing.
+:::
+
+:::{grid-item-card} Source: Executable Stack (Java)
+:link: https://github.com/crate/cratedb-examples/tree/main/framework/flink/kafka-jdbcsink-java
+:link-type: url
+An executable stack with Apache Kafka, Apache Flink, and CrateDB. Uses Java.
:::
-:::{div}
-- [Executable stack with Apache Kafka, Apache Flink, and CrateDB] (Java)
-- [Streaming data with Apache Kafka, Apache Flink and CrateDB] (Python)
+
+:::{grid-item-card} Source: Executable Stack (Python)
+:link: https://github.com/crate/cratedb-examples/tree/main/framework/flink/kafka-jdbcsink-python
+:link-type: url
+An executable stack with Apache Kafka, Apache Flink, and CrateDB. Uses Python.
:::
+::::
+
+
:::{rubric} Webinars
:::
diff --git a/docs/integrate/apache-hop/index.md b/docs/integrate/apache-hop/index.md
index 446699b8..5584ab8c 100644
--- a/docs/integrate/apache-hop/index.md
+++ b/docs/integrate/apache-hop/index.md
@@ -1,18 +1,21 @@
(apache-hop)=
# Apache Hop
+```{div} .float-right
+[{height=60px loading=lazy}][Apache Hop]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 0.3em"
-[{w=180px}](https://hop.apache.org/)
-```
-
[Apache Hop] aims to be a modern, open source data integration platform that is
easy to use, fast, and flexible. It facilitates all aspects of data and metadata
orchestration.
+:::{dropdown} **Details**
+
- **Visual development** enables developers to be more productive than they can
be through code.
@@ -23,22 +26,38 @@ orchestration.
- **Lifecycle Management** enables developers and administrators to switch between
projects, environments and purposes without leaving your train of thought.
-{h=120px}
-{h=120px}
-{h=120px}
+{h=120px}
+{h=120px}
+{h=120px}
+:::
:::{rubric} Learn
:::
+::::{grid}
+:gutter: 2
+
+:::{grid-item-card} Tutorial: Use Apache Hop with CrateDB
+:link: https://community.cratedb.com/t/using-apache-hop-with-cratedb/1754
+:link-type: url
+:columns: 12
+The tutorial explains how to deploy Apache Hop using Docker and connect it to CrateDB.
+:::
-- [Using Apache Hop with CrateDB]
-- [CrateDB dialect for Apache Hop]
-- [CrateDB Apache Hop Bulk Loader transform]
+:::{grid-item-card} Dialect
+:link: https://hop.apache.org/manual/latest/database/databases/cratedb.html
+:link-type: url
+CrateDB dialect for Apache Hop.
+:::
+
+:::{grid-item-card} Performance
+:link: https://hop.apache.org/manual/latest/pipeline/transforms/cratedb-bulkloader.html
+:link-type: url
+CrateDB Apache Hop Bulk Loader transform.
+:::
+::::
[Apache Hop]: https://hop.apache.org/
-[CrateDB Apache Hop Bulk Loader transform]: https://hop.apache.org/manual/latest/pipeline/transforms/cratedb-bulkloader.html
-[CrateDB dialect for Apache Hop]: https://hop.apache.org/manual/latest/database/databases/cratedb.html
-[Using Apache Hop with CrateDB]: https://community.cratedb.com/t/using-apache-hop-with-cratedb/1754
diff --git a/docs/integrate/apache-iceberg/index.md b/docs/integrate/apache-iceberg/index.md
index 12368135..9d5ecc2e 100644
--- a/docs/integrate/apache-iceberg/index.md
+++ b/docs/integrate/apache-iceberg/index.md
@@ -1,23 +1,34 @@
(apache-iceberg)=
# Apache Iceberg
+```{div} .float-right
+[{height=60px loading=lazy}][Apache Iceberg]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
[Apache Iceberg] is an open table format for analytic datasets.
-
The [Iceberg table format] is designed to manage a large, slow-changing collection
of files in a distributed file system or key-value store as a database table.
:::{rubric} Learn
:::
-CrateDB provides integration capabilities with Apache Iceberg implementations,
-see {ref}`risingwave-iceberg`.
-:::{todo}
-🚧 This page is a work in progress. 🚧
+::::{grid} 2
+:gutter: 2
+
+:::{grid-item-card} Tutorial: Use RisingWave to load Iceberg tables
+:link: risingwave-iceberg
+:link-type: ref
+The tutorial explains how to conduct stream processing from Apache
+Iceberg tables to CrateDB using RisingWave.
:::
+::::
+
[Apache Iceberg]: https://iceberg.apache.org/
[Iceberg table format]: https://iceberg.apache.org/spec/
diff --git a/docs/integrate/apache-kafka/index.md b/docs/integrate/apache-kafka/index.md
index c2a4b254..e3242ece 100644
--- a/docs/integrate/apache-kafka/index.md
+++ b/docs/integrate/apache-kafka/index.md
@@ -1,22 +1,25 @@
(apache-kafka)=
# Apache Kafka
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][Apache Kafka]
+
+```
+```{div} .clearfix
```
[Apache Flink] is a programming framework and distributed processing engine
@@ -15,6 +19,8 @@ for stateful computations over unbounded and bounded data streams, written
in Java. It is a battle-hardened stream processor widely used for demanding
real-time applications.
+:::{dropdown} **Details**
+
Flink has been designed to run in all common cluster environments, perform
computations at in-memory speed and at any scale. It received the [2023 SIGMOD
Systems Award].
@@ -32,10 +38,6 @@ A few companies are specializing in offering managed Flink services.
see [Confluent Streaming Data Pipelines].
:::
-```{div}
-:style: "clear: both"
-```
-
## Connect
Flink's [JdbcSink] is a streaming connector that writes data to a JDBC database,
@@ -125,15 +127,38 @@ JdbcSink.sink(
:::{rubric} Tutorials
:::
-- [Build a data ingestion pipeline using Kafka, Flink, and CrateDB]
-:::{rubric} Development
+::::{grid}
+:gutter: 2
+
+:::{grid-item-card} Tutorial: Build a data ingestion pipeline
+:link: https://dev.to/crate/build-a-data-ingestion-pipeline-using-kafka-flink-and-cratedb-1h5o
+:link-type: url
+:columns: 12
+The tutorial explains how to build a data ingestion pipeline using three
+open-source tools: Apache Kafka, Flink, and CrateDB.
++++
+Example: Kafka receives telemetry messages from IoT sensors and devices. Flink
+consumes the data stream and stores it into CrateDB. All tools are distributed
+systems that provide elastic scaling, fault tolerance, high-throughput, and
+low-latency performance via parallel processing.
+:::
+
+:::{grid-item-card} Source: Executable Stack (Java)
+:link: https://github.com/crate/cratedb-examples/tree/main/framework/flink/kafka-jdbcsink-java
+:link-type: url
+An executable stack with Apache Kafka, Apache Flink, and CrateDB. Uses Java.
:::
-:::{div}
-- [Executable stack with Apache Kafka, Apache Flink, and CrateDB] (Java)
-- [Streaming data with Apache Kafka, Apache Flink and CrateDB] (Python)
+
+:::{grid-item-card} Source: Executable Stack (Python)
+:link: https://github.com/crate/cratedb-examples/tree/main/framework/flink/kafka-jdbcsink-python
+:link-type: url
+An executable stack with Apache Kafka, Apache Flink, and CrateDB. Uses Python.
:::
+::::
+
+
:::{rubric} Webinars
:::
diff --git a/docs/integrate/apache-hop/index.md b/docs/integrate/apache-hop/index.md
index 446699b8..5584ab8c 100644
--- a/docs/integrate/apache-hop/index.md
+++ b/docs/integrate/apache-hop/index.md
@@ -1,18 +1,21 @@
(apache-hop)=
# Apache Hop
+```{div} .float-right
+[{height=60px loading=lazy}][Apache Hop]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 0.3em"
-[{w=180px}](https://hop.apache.org/)
-```
-
[Apache Hop] aims to be a modern, open source data integration platform that is
easy to use, fast, and flexible. It facilitates all aspects of data and metadata
orchestration.
+:::{dropdown} **Details**
+
- **Visual development** enables developers to be more productive than they can
be through code.
@@ -23,22 +26,38 @@ orchestration.
- **Lifecycle Management** enables developers and administrators to switch between
projects, environments and purposes without leaving your train of thought.
-{h=120px}
-{h=120px}
-{h=120px}
+{h=120px}
+{h=120px}
+{h=120px}
+:::
:::{rubric} Learn
:::
+::::{grid}
+:gutter: 2
+
+:::{grid-item-card} Tutorial: Use Apache Hop with CrateDB
+:link: https://community.cratedb.com/t/using-apache-hop-with-cratedb/1754
+:link-type: url
+:columns: 12
+The tutorial explains how to deploy Apache Hop using Docker and connect it to CrateDB.
+:::
-- [Using Apache Hop with CrateDB]
-- [CrateDB dialect for Apache Hop]
-- [CrateDB Apache Hop Bulk Loader transform]
+:::{grid-item-card} Dialect
+:link: https://hop.apache.org/manual/latest/database/databases/cratedb.html
+:link-type: url
+CrateDB dialect for Apache Hop.
+:::
+
+:::{grid-item-card} Performance
+:link: https://hop.apache.org/manual/latest/pipeline/transforms/cratedb-bulkloader.html
+:link-type: url
+CrateDB Apache Hop Bulk Loader transform.
+:::
+::::
[Apache Hop]: https://hop.apache.org/
-[CrateDB Apache Hop Bulk Loader transform]: https://hop.apache.org/manual/latest/pipeline/transforms/cratedb-bulkloader.html
-[CrateDB dialect for Apache Hop]: https://hop.apache.org/manual/latest/database/databases/cratedb.html
-[Using Apache Hop with CrateDB]: https://community.cratedb.com/t/using-apache-hop-with-cratedb/1754
diff --git a/docs/integrate/apache-iceberg/index.md b/docs/integrate/apache-iceberg/index.md
index 12368135..9d5ecc2e 100644
--- a/docs/integrate/apache-iceberg/index.md
+++ b/docs/integrate/apache-iceberg/index.md
@@ -1,23 +1,34 @@
(apache-iceberg)=
# Apache Iceberg
+```{div} .float-right
+[{height=60px loading=lazy}][Apache Iceberg]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
[Apache Iceberg] is an open table format for analytic datasets.
-
The [Iceberg table format] is designed to manage a large, slow-changing collection
of files in a distributed file system or key-value store as a database table.
:::{rubric} Learn
:::
-CrateDB provides integration capabilities with Apache Iceberg implementations,
-see {ref}`risingwave-iceberg`.
-:::{todo}
-🚧 This page is a work in progress. 🚧
+::::{grid} 2
+:gutter: 2
+
+:::{grid-item-card} Tutorial: Use RisingWave to load Iceberg tables
+:link: risingwave-iceberg
+:link-type: ref
+The tutorial explains how to conduct stream processing from Apache
+Iceberg tables to CrateDB using RisingWave.
:::
+::::
+
[Apache Iceberg]: https://iceberg.apache.org/
[Iceberg table format]: https://iceberg.apache.org/spec/
diff --git a/docs/integrate/apache-kafka/index.md b/docs/integrate/apache-kafka/index.md
index c2a4b254..e3242ece 100644
--- a/docs/integrate/apache-kafka/index.md
+++ b/docs/integrate/apache-kafka/index.md
@@ -1,22 +1,25 @@
(apache-kafka)=
# Apache Kafka
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][Apache Kafka]
+
+
+
+```
+```{div} .clearfix
+```
+
:::{include} /_include/links.md
:::
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 2em"
-[{w=180px}](https://kafka.apache.org/)
-```
-
[Apache Kafka] is an open-source distributed event streaming platform used by
thousands of companies for high-performance data pipelines, streaming analytics,
data integration, and mission-critical applications.
-
:::{dropdown} **Managed Kafka**
Several companies provide managed Kafka services (see the [overview of managed Kafka offerings]
for a more complete list).
@@ -33,15 +36,31 @@ for a more complete list).
:::{rubric} Learn
:::
-:::{div}
-- {ref}`kafka-connect`
-- [Replicating data to CrateDB with Debezium and Kafka]
-- [Executable stack with Apache Kafka, Apache Flink, and CrateDB]
+::::{grid}
+
+:::{grid-item-card} Tutorial: Build a data ingestion pipeline
+:link: kafka-connect
+:link-type: ref
+The tutorial explains how to build a data ingestion pipeline using Apache
+Kafka, CrateDB, and the Confluent Kafka Connect JDBC connector.
:::
+:::{grid-item-card} Tutorial: Connect Debezium, Kafka, and CrateDB
+:link: https://community.cratedb.com/t/replicating-data-to-cratedb-with-debezium-and-kafka/1388
+:link-type: url
+Replicating data to CrateDB with Debezium and Kafka.
+:::
+
+:::{grid-item-card} Source: Executable Stack (Java)
+:link: https://github.com/crate/cratedb-examples/tree/main/framework/flink/kafka-jdbcsink-java
+:link-type: url
+An executable stack with Apache Kafka, Apache Flink, and CrateDB. Uses Java.
+:::
+
+::::
+
```{toctree}
:hidden:
-
kafka-connect
```
diff --git a/docs/integrate/apache-nifi/index.md b/docs/integrate/apache-nifi/index.md
index 389c417e..46550fd1 100644
--- a/docs/integrate/apache-nifi/index.md
+++ b/docs/integrate/apache-nifi/index.md
@@ -1,40 +1,55 @@
(apache-nifi)=
# Apache NiFi
+```{div} .float-right
+[{height=60px loading=lazy}][Apache NiFi]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 2em"
-[{w=180px}](https://nifi.apache.org/)
-```
-
[Apache NiFi] is an easy to use, powerful, and reliable system to process and
distribute data. NiFi automates cybersecurity, observability, event streams,
and generative AI data pipelines and distribution for thousands of companies
worldwide across every industry.
+:::{dropdown} **Details**
+
- **Data provenance tracking**: Complete lineage of information from beginning to end.
-- **Extensive configuration**: Loss-tolerant and guaranteed delivery, Low latency and
+- **Extensive configuration**: Loss-tolerant and guaranteed delivery, low latency and
high throughput, Dynamic prioritization, Runtime modification of flow configuration,
Back pressure control.
- **Browser-based user interface**: Seamless experience for design, control, feedback,
and monitoring
- **Secure communication**: HTTPS with configurable authentication strategies,
- Multi-tenant authorization and policy management, Standard protocols for encrypted
+ multi-tenant authorization and policy management, standard protocols for encrypted
communication including TLS and SSH.
-{h=120px}
-{h=120px}
-{h=120px}
+{height=120px loading=lazy}
+{height=120px loading=lazy}
+{height=120px loading=lazy}
+:::
:::{rubric} Learn
:::
-- [Connecting to CrateDB from Apache NiFi]
+::::{grid} 2
+
+:::{grid-item-card} Tutorial: Connect Apache NiFi and CrateDB
+:link: https://community.cratedb.com/t/connecting-to-cratedb-from-apache-nifi/647
+:link-type: url
+How to connect from Apache NiFi to CrateDB and ingest data from NiFi into CrateDB.
+:::
+::::
+
+```{seealso}
+[CrateDB and Apache NiFi]
+```
[Apache NiFi]: https://nifi.apache.org/
-[Connecting to CrateDB from Apache NiFi]: https://community.cratedb.com/t/connecting-to-cratedb-from-apache-nifi/647
+[CrateDB and Apache NiFi]: https://cratedb.com/integrations/cratedb-and-apache-nifi
diff --git a/docs/integrate/apache-superset/index.md b/docs/integrate/apache-superset/index.md
index 0e1940b8..dd230496 100644
--- a/docs/integrate/apache-superset/index.md
+++ b/docs/integrate/apache-superset/index.md
@@ -4,26 +4,27 @@
# Apache Superset / Preset
-```{div}
-:style: "float: right"
-[{w=180px}](https://superset.apache.org/)
-
-[{w=180px}](https://preset.io/)
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][Apache Superset]
+
+
+  +```
+```{div} .clearfix
```
[Apache Superset] is an open-source modern data exploration and visualization
platform, written in Python.
-
[Preset] offers a managed, elevated, and enterprise-grade SaaS for open-source
Apache Superset.
-{h=200px}
-{h=200px}
+{h=200px}
+{h=200px}
:::{dropdown} **Managed Superset**
```{div}
:style: "float: right"
-[{w=180px}](https://preset.io/)
+[{height=60px loading=lazy}][Preset Cloud]
```
[Preset Cloud] is a fully-managed, open-source BI for the modern data stack,
@@ -38,9 +39,9 @@ based on Apache Superset.
- **Control user roles and access:** Easily assign roles and fine-tune data access
using RBAC and row-level security (RLS).
-```{div}
-:style: "clear: both"
+```{div} .clearfix
```
+
:::
@@ -72,15 +73,22 @@ crate://:@.cratedb.net:4200/?ssl=true
:::{rubric} Tutorials
:::
-- [Introduction to time series visualization in CrateDB and Apache Superset (Blog)]
-- [Use CrateDB and Apache Superset for Open Source Data Warehousing and Visualization (Blog)]
-- [Introduction to time series Visualization in CrateDB and Apache Superset (Preset.io)]
-:::{rubric} Development
+::::{grid}
+
+:::{grid-item-card} Blog: Open‑source data warehousing and visualization
+:link: https://cratedb.com/blog/use-cratedb-and-apache-superset-for-open-source-data-warehousing-and-visualization
+:link-type: url
+Use CrateDB and Apache Superset for open-source data warehousing and visualization.
:::
-- [Set up Apache Superset with CrateDB]
-- [Set up an Apache Superset development sandbox with CrateDB]
-- [Verify Apache Superset with CrateDB]
+
+:::{grid-item-card} Blog: Time‑series visualization
+:link: https://preset.io/blog/timeseries-cratedb-superset/
+:link-type: url
+Introduction to time‑series visualization in CrateDB and Apache Superset.
+:::
+
+::::
:::{rubric} Webinars
@@ -135,24 +143,27 @@ from the time-series dataset.
::::
+:::{rubric} Development
+:::
+- [Set up Apache Superset with CrateDB]
+- [Set up an Apache Superset development sandbox with CrateDB]
+- [Verify Apache Superset with CrateDB]
+
+
```{seealso}
-[CrateDB and Superset]
+[CrateDB and Apache Superset]
```
[Apache Superset]: https://superset.apache.org/
-[CrateDB and Superset]: https://cratedb.com/integrations/cratedb-and-apache-superset
+[CrateDB and Apache Superset]: https://cratedb.com/integrations/cratedb-and-apache-superset
[CrateDB Cloud]: https://cratedb.com/product/cloud
[CrateDB connector package]: https://superset.apache.org/docs/configuration/databases#cratedb
[CrateDB Self-Managed]: https://cratedb.com/product/self-managed
[how to install database drivers in Docker Images]: https://superset.apache.org/docs/configuration/databases#installing-drivers-in-docker-images
-[Introduction to time series visualization in CrateDB and Apache Superset (Blog)]: https://community.cratedb.com/t/introduction-to-time-series-visualization-in-cratedb-and-superset/1041
-[Introduction to time series visualization in CrateDB and Apache Superset (Webinar)]: https://cratedb.com/resources/webinars/lp-wb-introduction-to-time-series-visualization-in-cratedb-apache-superset
-[Introduction to time series Visualization in CrateDB and Apache Superset (Preset.io)]: https://preset.io/blog/timeseries-cratedb-superset/
[Preset]: https://preset.io/
[Preset Cloud]: https://preset.io/product/
[Set up Apache Superset with CrateDB]: https://community.cratedb.com/t/set-up-apache-superset-with-cratedb/1716
[Set up an Apache Superset development sandbox with CrateDB]: https://community.cratedb.com/t/set-up-an-apache-superset-development-sandbox-with-cratedb/1163
-[Use CrateDB and Apache Superset for Open Source Data Warehousing and Visualization (Blog)]: https://cratedb.com/blog/use-cratedb-and-apache-superset-for-open-source-data-warehousing-and-visualization
[Verify Apache Superset with CrateDB]: https://github.com/crate/cratedb-examples/tree/main/application/apache-superset
diff --git a/docs/integrate/aws-dms/index.md b/docs/integrate/aws-dms/index.md
index d494cb1d..cd87543d 100644
--- a/docs/integrate/aws-dms/index.md
+++ b/docs/integrate/aws-dms/index.md
@@ -5,6 +5,12 @@
:::{include} /_include/links.md
:::
+```{div} .float-right
+[{height=60px loading=lazy}][AWS Database Migration Service (AWS DMS)]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
@@ -20,16 +26,36 @@ Amazon Aurora, Amazon DocumentDB, Amazon S3, IBM DB2, MariaDB, Azure SQL Databas
Microsoft SQL Server, MongoDB, MySQL, Oracle, PostgreSQL, SAP ASE.
:::
-:::{rubric} Learn
+:::{rubric} Synopsis
:::
-:::{div}
-The [AWS DMS Integration with CrateDB] uses Amazon Kinesis Data Streams as
-a DMS target, combined with a CrateDB-specific downstream processor element.
+```shell
+uvx 'cratedb-toolkit[kinesis]' load table \
+ "kinesis+dms:///arn:aws:kinesis:eu-central-1:831394476016:stream/testdrive" \
+ --cluster-url="crate://crate:crate@localhost:4200/testdrive"
+```
+:::{rubric} Learn
+:::
+
+::::{grid} 2
+
+:::{grid-item-card} AWS DMS Processor
+:link: ctk:io/dms/index
+:link-type: doc
+A full-load-and-cdc pipeline using AWS DMS and CrateDB, where an Amazon Kinesis Data
+Stream is selected as a DMS target, combined with a CrateDB-specific downstream
+processor element.
++++
+AWS DMS supports both `full-load` and continuous replication `cdc` operation modes,
+which are often combined (`full-load-and-cdc`).
CrateDB supports two ways to run AWS DMS migrations:
Either standalone/on‑premises, or fully managed with AWS and CrateDB Cloud.
+:::
+
+::::
+
-AWS DMS supports both `full-load` and `cdc` operation modes, which are often
-combined (`full-load-and-cdc`).
+:::{seealso}
+**Blog:** [Replicating CDC events to CrateDB using AWS DMS]
:::
diff --git a/docs/integrate/aws-dynamodb/index.md b/docs/integrate/aws-dynamodb/index.md
index a94ec33d..f7595910 100644
--- a/docs/integrate/aws-dynamodb/index.md
+++ b/docs/integrate/aws-dynamodb/index.md
@@ -5,23 +5,85 @@
:::{include} /_include/links.md
:::
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][DynamoDB]
+
+```
+```{div} .clearfix
```
[Apache Superset] is an open-source modern data exploration and visualization
platform, written in Python.
-
[Preset] offers a managed, elevated, and enterprise-grade SaaS for open-source
Apache Superset.
-{h=200px}
-{h=200px}
+{h=200px}
+{h=200px}
:::{dropdown} **Managed Superset**
```{div}
:style: "float: right"
-[{w=180px}](https://preset.io/)
+[{height=60px loading=lazy}][Preset Cloud]
```
[Preset Cloud] is a fully-managed, open-source BI for the modern data stack,
@@ -38,9 +39,9 @@ based on Apache Superset.
- **Control user roles and access:** Easily assign roles and fine-tune data access
using RBAC and row-level security (RLS).
-```{div}
-:style: "clear: both"
+```{div} .clearfix
```
+
:::
@@ -72,15 +73,22 @@ crate://:@.cratedb.net:4200/?ssl=true
:::{rubric} Tutorials
:::
-- [Introduction to time series visualization in CrateDB and Apache Superset (Blog)]
-- [Use CrateDB and Apache Superset for Open Source Data Warehousing and Visualization (Blog)]
-- [Introduction to time series Visualization in CrateDB and Apache Superset (Preset.io)]
-:::{rubric} Development
+::::{grid}
+
+:::{grid-item-card} Blog: Open‑source data warehousing and visualization
+:link: https://cratedb.com/blog/use-cratedb-and-apache-superset-for-open-source-data-warehousing-and-visualization
+:link-type: url
+Use CrateDB and Apache Superset for open-source data warehousing and visualization.
:::
-- [Set up Apache Superset with CrateDB]
-- [Set up an Apache Superset development sandbox with CrateDB]
-- [Verify Apache Superset with CrateDB]
+
+:::{grid-item-card} Blog: Time‑series visualization
+:link: https://preset.io/blog/timeseries-cratedb-superset/
+:link-type: url
+Introduction to time‑series visualization in CrateDB and Apache Superset.
+:::
+
+::::
:::{rubric} Webinars
@@ -135,24 +143,27 @@ from the time-series dataset.
::::
+:::{rubric} Development
+:::
+- [Set up Apache Superset with CrateDB]
+- [Set up an Apache Superset development sandbox with CrateDB]
+- [Verify Apache Superset with CrateDB]
+
+
```{seealso}
-[CrateDB and Superset]
+[CrateDB and Apache Superset]
```
[Apache Superset]: https://superset.apache.org/
-[CrateDB and Superset]: https://cratedb.com/integrations/cratedb-and-apache-superset
+[CrateDB and Apache Superset]: https://cratedb.com/integrations/cratedb-and-apache-superset
[CrateDB Cloud]: https://cratedb.com/product/cloud
[CrateDB connector package]: https://superset.apache.org/docs/configuration/databases#cratedb
[CrateDB Self-Managed]: https://cratedb.com/product/self-managed
[how to install database drivers in Docker Images]: https://superset.apache.org/docs/configuration/databases#installing-drivers-in-docker-images
-[Introduction to time series visualization in CrateDB and Apache Superset (Blog)]: https://community.cratedb.com/t/introduction-to-time-series-visualization-in-cratedb-and-superset/1041
-[Introduction to time series visualization in CrateDB and Apache Superset (Webinar)]: https://cratedb.com/resources/webinars/lp-wb-introduction-to-time-series-visualization-in-cratedb-apache-superset
-[Introduction to time series Visualization in CrateDB and Apache Superset (Preset.io)]: https://preset.io/blog/timeseries-cratedb-superset/
[Preset]: https://preset.io/
[Preset Cloud]: https://preset.io/product/
[Set up Apache Superset with CrateDB]: https://community.cratedb.com/t/set-up-apache-superset-with-cratedb/1716
[Set up an Apache Superset development sandbox with CrateDB]: https://community.cratedb.com/t/set-up-an-apache-superset-development-sandbox-with-cratedb/1163
-[Use CrateDB and Apache Superset for Open Source Data Warehousing and Visualization (Blog)]: https://cratedb.com/blog/use-cratedb-and-apache-superset-for-open-source-data-warehousing-and-visualization
[Verify Apache Superset with CrateDB]: https://github.com/crate/cratedb-examples/tree/main/application/apache-superset
diff --git a/docs/integrate/aws-dms/index.md b/docs/integrate/aws-dms/index.md
index d494cb1d..cd87543d 100644
--- a/docs/integrate/aws-dms/index.md
+++ b/docs/integrate/aws-dms/index.md
@@ -5,6 +5,12 @@
:::{include} /_include/links.md
:::
+```{div} .float-right
+[{height=60px loading=lazy}][AWS Database Migration Service (AWS DMS)]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
@@ -20,16 +26,36 @@ Amazon Aurora, Amazon DocumentDB, Amazon S3, IBM DB2, MariaDB, Azure SQL Databas
Microsoft SQL Server, MongoDB, MySQL, Oracle, PostgreSQL, SAP ASE.
:::
-:::{rubric} Learn
+:::{rubric} Synopsis
:::
-:::{div}
-The [AWS DMS Integration with CrateDB] uses Amazon Kinesis Data Streams as
-a DMS target, combined with a CrateDB-specific downstream processor element.
+```shell
+uvx 'cratedb-toolkit[kinesis]' load table \
+ "kinesis+dms:///arn:aws:kinesis:eu-central-1:831394476016:stream/testdrive" \
+ --cluster-url="crate://crate:crate@localhost:4200/testdrive"
+```
+:::{rubric} Learn
+:::
+
+::::{grid} 2
+
+:::{grid-item-card} AWS DMS Processor
+:link: ctk:io/dms/index
+:link-type: doc
+A full-load-and-cdc pipeline using AWS DMS and CrateDB, where an Amazon Kinesis Data
+Stream is selected as a DMS target, combined with a CrateDB-specific downstream
+processor element.
++++
+AWS DMS supports both `full-load` and continuous replication `cdc` operation modes,
+which are often combined (`full-load-and-cdc`).
CrateDB supports two ways to run AWS DMS migrations:
Either standalone/on‑premises, or fully managed with AWS and CrateDB Cloud.
+:::
+
+::::
+
-AWS DMS supports both `full-load` and `cdc` operation modes, which are often
-combined (`full-load-and-cdc`).
+:::{seealso}
+**Blog:** [Replicating CDC events to CrateDB using AWS DMS]
:::
diff --git a/docs/integrate/aws-dynamodb/index.md b/docs/integrate/aws-dynamodb/index.md
index a94ec33d..f7595910 100644
--- a/docs/integrate/aws-dynamodb/index.md
+++ b/docs/integrate/aws-dynamodb/index.md
@@ -5,23 +5,85 @@
:::{include} /_include/links.md
:::
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][DynamoDB]
+
+
+  +```
+```{div} .clearfix
+```
+
+:::::{grid}
+:padding: 0
+
+::::{grid-item}
+:columns: auto 9 9 9
+
:::{rubric} About
:::
:::{div}
-The [DynamoDB Table Loader] supports loading DynamoDB tables into CrateDB (full-load),
-while the [DynamoDB CDC Relay] pipeline uses [Amazon DynamoDB Streams] or [Amazon Kinesis
-Data Streams] to relay table change stream CDC events from a DynamoDB table into CrateDB.
+[DynamoDB] is a fully managed NoSQL database service provided by Amazon Web Services (AWS).
+It is designed for high-performance, scalable applications and offers key-value and
+document data structures. DynamoDB is serverless, meaning users don't need to manage
+servers or infrastructure.
+:::
+
+::::
+
+::::{grid-item}
+:columns: auto 3 3 3
+
+:::{rubric} Related
+:::
+- [Amazon DynamoDB Streams]
+- {ref}`aws-kinesis`
+- [Amazon Kinesis Data Streams]
+::::
+
+:::::
+
+
+:::{rubric} Synopsis
+:::
+
+```shell
+uvx 'cratedb-toolkit[kinesis]' load table \
+ "kinesis+dynamodb+cdc://${AWS_ACCESS_KEY_ID}:${AWS_SECRET_ACCESS_KEY}@aws/cdc-stream?region=eu-central-1" \
+ --cluster-url="crate://crate:crate@localhost:4200/testdrive/demo"
+```
:::{rubric} Learn
:::
-:::{div}
-It is a common application to relay DynamoDB table change stream events to a
+It is common practice to forward DynamoDB table change stream events to a
Kinesis Stream, and consume that from an adapter to write into an analytical
-or long-term storage consolidation database.
+or long-term storage consolidation database like CrateDB.
+
+::::{grid}
+
+:::{grid-item-card} DynamoDB Table Loader
+:link: ctk:dynamodb-loader
+:link-type: ref
+Load DynamoDB tables into CrateDB (`full-load`).
+:::
+
+:::{grid-item-card} DynamoDB CDC Relay
+:link: ctk:dynamodb-cdc
+:link-type: ref
+Relay table change stream CDC events from a DynamoDB table into CrateDB (`cdc`).
+:::
+
+:::{grid-item-card} DynamoDB CDC Relay using AWS Lambda
+:link: ctk:io/dynamodb/cdc-lambda
+:link-type: doc
+Use serverless replication based on AWS Lambda to
+relay CDC events into CrateDB (`cdc`).
+:::
+
+::::
-If you are looking into serverless replication using AWS Lambda:
-- [DynamoDB CDC Relay with AWS Lambda]
-- Blog: [Replicating CDC events from DynamoDB to CrateDB]
+:::{seealso}
+**Blog:** [Replicating CDC events from DynamoDB to CrateDB]
:::
diff --git a/docs/integrate/aws-kinesis/index.md b/docs/integrate/aws-kinesis/index.md
index 2c773669..272b87d4 100644
--- a/docs/integrate/aws-kinesis/index.md
+++ b/docs/integrate/aws-kinesis/index.md
@@ -4,9 +4,20 @@
:::{include} /_include/links.md
:::
+```{div} .float-right
+[{height=60px loading=lazy}][Amazon Kinesis Data Streams]
+```
+```{div} .clearfix
+```
+
+:::::{grid}
+:padding: 0
+
+::::{grid-item}
+:columns: auto 9 9 9
+
:::{rubric} About
:::
-
:::{div}
[Amazon Kinesis Data Streams] is a serverless streaming data service that
simplifies the capture, processing, and storage of data streams at any
@@ -17,12 +28,49 @@ You can use Amazon Kinesis Data Streams to collect and process large data
streams in real time. A typical application reads data from the stream as
records.
:::
+::::
+
+::::{grid-item}
+:class: rubric-slim
+:columns: auto 3 3 3
+
+:::{rubric} Related
+:::
+- {ref}`aws-dynamodb`
+- [Amazon DynamoDB Streams]
+::::
+
+:::::
+
+:::{rubric} Synopsis
+:::
+
+```shell
+uvx 'cratedb-toolkit[io-ingestr]' load table \
+ "kinesis://?aws_access_key_id=${AWS_ACCESS_KEY_ID}&aws_secret_access_key=${AWS_SECRET_ACCESS_KEY}®ion_name=eu-central-1&table=arn:aws:kinesis:eu-central-1:831394476016:stream/testdrive" \
+ --cluster-url="crate://crate:crate@localhost:4200/testdrive/kinesis_demo"
+```
:::{rubric} Learn
:::
-:::{div}
-The [DynamoDB CDC Relay] pipeline uses Amazon Kinesis to relay a table
-change stream from a DynamoDB table into a CrateDB table, see also
-{ref}`DynamoDB CDC `.
+::::{grid}
+
+:::{grid-item-card} Ingestr Table Loader
+:link: https://cratedb-toolkit.readthedocs.io/io/ingestr/#amazon-kinesis-to-cratedb
+:link-type: url
+Relay Kinesis stream into CrateDB.
+:::
+
+:::{grid-item-card} DynamoDB CDC Relay
+:link: ctk:dynamodb-cdc
+:link-type: ref
+Relay table change stream CDC events from DynamoDB into CrateDB, using Kinesis.
+:::
+
+::::
+
+
+:::{seealso}
+**Blog:** [Replicating CDC events from DynamoDB to CrateDB]
:::
diff --git a/docs/integrate/aws-lambda/index.md b/docs/integrate/aws-lambda/index.md
index e1746543..eba86e20 100644
--- a/docs/integrate/aws-lambda/index.md
+++ b/docs/integrate/aws-lambda/index.md
@@ -4,6 +4,12 @@
:::{include} /_include/links.md
:::
+```{div} .float-right
+[{height=60px loading=lazy}][AWS Lambda]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
@@ -16,8 +22,34 @@ Events can include state changes and updates.
:::{rubric} Learn
:::
-:::{div}
-Serverless replication from DynamoDB to CrateDB using AWS Lambda:
-- [DynamoDB CDC Relay with AWS Lambda]
-- Blog: [Replicating CDC events from DynamoDB to CrateDB]
+It is common practice to forward DynamoDB table change stream events to a
+Kinesis stream, and to consume that from an adapter to write into an analytical
+or long-term storage consolidation database like CrateDB.
+
+::::{grid}
+
+:::{grid-item-card} DynamoDB Table Loader
+:link: ctk:dynamodb-loader
+:link-type: ref
+Load DynamoDB tables into CrateDB (`full-load`).
+:::
+
+:::{grid-item-card} DynamoDB CDC Relay
+:link: ctk:dynamodb-cdc
+:link-type: ref
+Relay table change stream CDC events from a DynamoDB table into CrateDB (`cdc`).
+:::
+
+:::{grid-item-card} DynamoDB CDC Relay using AWS Lambda
+:link: ctk:io/dynamodb/cdc-lambda
+:link-type: doc
+Use serverless replication based on AWS Lambda to
+relay CDC events into CrateDB (`cdc`).
+:::
+
+::::
+
+
+:::{seealso}
+**Blog:** [Replicating CDC events from DynamoDB to CrateDB]
:::
diff --git a/docs/integrate/azure-functions/index.md b/docs/integrate/azure-functions/index.md
index 7c57fa7d..c3e192e5 100644
--- a/docs/integrate/azure-functions/index.md
+++ b/docs/integrate/azure-functions/index.md
@@ -4,16 +4,18 @@
:::{include} /_include/links.md
:::
-_Execute event-driven serverless code with an end-to-end development experience._
+```{div} .float-right
+[{height=60px loading=lazy}][Azure Functions]
+```
+```{div} .clearfix
+```
:::{rubric} About
:::
-[Azure Functions] is a serverless solution that allows you to build robust apps
-while using less code, and with less infrastructure and lower costs. Instead
-of worrying about deploying and maintaining servers, you can use the cloud
-infrastructure to provide all the up-to-date resources needed to keep your
-applications running.
+[Azure Functions] is an event-driven serverless code execution solution that
+allows you to build robust apps while using less code, and with less
+infrastructure and lower costs.
An Azure Function is a short-lived, serverless computation that is triggered
by external events. The trigger produces an input payload, which is delivered
@@ -24,12 +26,22 @@ services, or storage services. See also [What is Azure Functions?].
:::{rubric} Learn
:::
-A common pattern is to use an Azure Function to enrich and ingest data
-to a CrateDB instance by connecting that Azure Function to an IoT Hub's new
-messages trigger.
+::::{grid} 2
+
+:::{grid-item-card} Data Enrichment using IoT Hub, Azure Functions and CrateDB
+:link: azure-functions-learn
+:link-type: ref
+A common pattern uses an Azure Function to enrich and ingest data
+into a CrateDB instance by connecting the function to an IoT Hub
+new‑messages trigger.
+:::
+
+::::
+
:::{toctree}
:maxdepth: 1
+:hidden:
learn
:::
diff --git a/docs/integrate/cluvio/index.md b/docs/integrate/cluvio/index.md
index c360e3cb..507b7f96 100644
--- a/docs/integrate/cluvio/index.md
+++ b/docs/integrate/cluvio/index.md
@@ -1,32 +1,49 @@
(cluvio)=
# Cluvio
+```{div} .float-right
+[{height=60px loading=lazy}][Cluvio]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 1em"
-[{w=180px}](https://www.cluvio.com/)
-```
-
[Cluvio] is a programmable and interactive dashboarding platform — your analytics
cockpit. Run queries, filter your results, choose the most vivid way to display them,
and share them with your colleagues and partners without efforts.
+::::{dropdown} **Details**
Cluvio dashboards are interactive, so you can easily change aggregation, select a
specific timerange or filter dashboards by any individual attribute of your data.
Use SQL and R to analyze your data and create beautiful, interactive dashboards for
your entire company in few minutes.
-{h=200px}
-{h=200px}
+{h=200px loading=lazy}
+{h=200px loading=lazy}
+::::
:::{rubric} Learn
:::
-- [Data Analysis with Cluvio and CrateDB]
+::::{grid} 2
+
+:::{grid-item-card} Data Analysis with Cluvio and CrateDB
+:link: https://community.cratedb.com/t/data-analysis-with-cluvio-and-cratedb/1571
+:link-type: url
+Explore how to leverage the power of Cluvio, a modern data analysis platform
+with CrateDB Cloud as the underlying database.
+:::
+
+::::
+
+
+```{seealso}
+[CrateDB and Cluvio]
+```
[Cluvio]: https://www.cluvio.com/
-[Data Analysis with Cluvio and CrateDB]: https://community.cratedb.com/t/data-analysis-with-cluvio-and-cratedb/1571
+[CrateDB and Cluvio]: https://cratedb.com/integrations/cratedb-and-cluvio
diff --git a/docs/integrate/datagrip/index.md b/docs/integrate/datagrip/index.md
index b0a04d65..16be2667 100644
--- a/docs/integrate/datagrip/index.md
+++ b/docs/integrate/datagrip/index.md
@@ -4,21 +4,20 @@
:::{include} /_include/links.md
:::
-```{div}
-:style: "float: right; margin-left: 0.5em"
-[{w=120px}](https://www.jetbrains.com/datagrip/)
+```{div} .float-right
+:style: "margin-left: 0.5em"
+[{width=120px loading=lazy}][DataGrip]
```
-
+:::{div}
[DataGrip] is a cross-platform database IDE that is tailored to suit the
specific needs of professional SQL developers.
-It is available as a standalone application and is also included into
+It is available as a standalone application and is also included in
other JetBrains products like IntelliJ IDEA and PyCharm.
Connecting DataGrip to CrateDB uses the [CrateDB JDBC Driver].
-
-```{div}
-:style: "clear: both"
+:::
+```{div} .clearfix
```
@@ -30,8 +29,8 @@ For connecting to CrateDB, install the [CrateDB JDBC Driver]
using the "Custom JARs" option when adding a database driver.
:::
:::{grid-item}
-{h=180px}
-{h=180px}
+{height=180px loading=lazy}
+{height=180px loading=lazy}
:::
:::{grid-item}
[crate-jdbc-standalone] is the right choice here.
@@ -39,7 +38,7 @@ For example, download and use the [crate-jdbc-standalone-latest.jar] JAR file,
and select the driver class `io.crate.client.jdbc.CrateDriver`.
:::
:::{grid-item}
-{w=400px}
+{width=400px loading=lazy}
:::
::::
@@ -53,7 +52,7 @@ Now, you can add a Data Source using the CrateDB database driver.
Please specify database URL and credentials of your CrateDB cluster.
:::
:::{grid-item}
-{w=480px}
+{width=480px loading=lazy}
:::
:::{grid-item}
For connecting to [CrateDB Self-Managed] or [CrateDB Cloud],
@@ -63,7 +62,7 @@ jdbc:crate://:5432/
```
:::
:::{grid-item}
-{w=480px}
+{width=480px loading=lazy}
:::
::::
@@ -72,8 +71,8 @@ jdbc:crate://:5432/
## Usage
After refreshing, you can browse the data tree, and use the Query Console.
-{h=240px}
-{h=240px}
+{height=240px loading=lazy}
+{height=240px loading=lazy}
@@ -81,11 +80,18 @@ After refreshing, you can browse the data tree, and use the Query Console.
:::{rubric} Tutorials
:::
-- [Blog: Use CrateDB With DataGrip]
-:::{rubric} Product
+::::{grid}
+
+:::{grid-item-card} Blog: Use CrateDB With DataGrip
+:link: https://cratedb.com/blog/use-cratedb-with-datagrip-an-advanced-database-ide
+:link-type: url
+DataGrip is a cross-platform database IDE (Integrated Development Environment) that is
+tailored to suit the specific needs of professional SQL developers.
+With the help of the CrateDB JDBC Standalone Driver, you can use DataGrip with CrateDB.
:::
-- [CrateDB and DataGrip]
+
+::::
:::{rubric} Notes
:::
@@ -94,8 +100,11 @@ We are tracking interoperability issues per [Tool: DataGrip], and appreciate
any contributions and reports.
:::
+:::{seealso}
+[CrateDB and DataGrip]
+:::
+
-[Blog: Use CrateDB With DataGrip]: https://cratedb.com/blog/use-cratedb-with-datagrip-an-advanced-database-ide
[CrateDB and DataGrip]: https://cratedb.com/integrations/cratedb-and-datagrip
[DataGrip]: https://www.jetbrains.com/datagrip/
[Tool: DataGrip]: https://github.com/crate/crate/labels/tool%3A%20DataGrip
diff --git a/docs/integrate/dbeaver/index.md b/docs/integrate/dbeaver/index.md
index 40d14ad5..7f1f098a 100644
--- a/docs/integrate/dbeaver/index.md
+++ b/docs/integrate/dbeaver/index.md
@@ -4,9 +4,9 @@
:::{include} /_include/links.md
:::
-```{div}
-:style: "float: right; margin-left: 0.5em"
-[{w=120px}](https://dbeaver.io/)
+```{div} .float-right
+:style: "margin-left: 0.5em"
+[{w=120px loading=lazy}][DBeaver]
```
[DBeaver] is a multipurpose cross-platform database tool for developers,
@@ -39,7 +39,7 @@ jdbc:postgresql://.cratedb.net:5432/crate
:::
:::{grid-item}
:columns: 5
-{w=480px}
+{w=480px loading=lazy}
:::
::::
@@ -49,19 +49,25 @@ jdbc:postgresql://.cratedb.net:5432/crate
Use the tree menu on the left-hand pane to navigate to the `doc` schema and
its tables. Navigate to the Data tab to browse your table data.
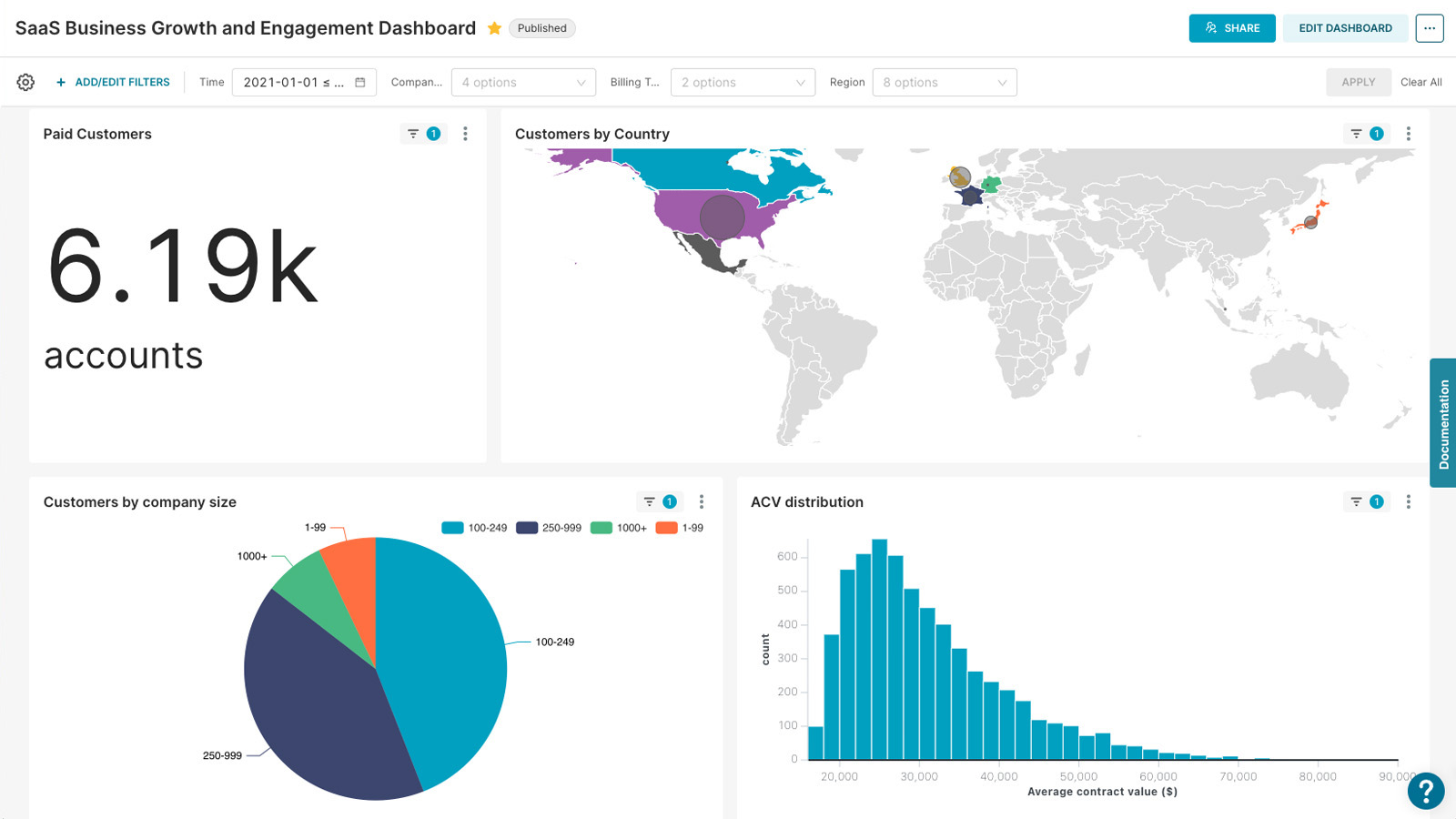
-{h=240px}
-{h=240px}
+{h=240px loading=lazy}
+{h=240px loading=lazy}
## Learn
:::{rubric} Tutorials
:::
-- [Blog: Use CrateDB With DBeaver]
-:::{rubric} Product
+::::{grid}
+
+:::{grid-item-card} Blog: Use CrateDB With DBeaver
+:link: https://cratedb.com/blog/cratedb-dbeaver
+:link-type: url
+DBeaver is a multipurpose database tool for developers and database administrators.
+With the help of the CrateDB JDBC Standalone Driver, you can use DBeaver with CrateDB.
:::
-- [CrateDB and DBeaver]
+
+::::
:::{rubric} Notes
:::
@@ -80,8 +86,11 @@ We are tracking interoperability issues per [Tool: DBeaver], and appreciate
any contributions and reports.
:::
+:::{seealso}
+[CrateDB and DBeaver]
+:::
+
-[Blog: Use CrateDB With DBeaver]: https://cratedb.com/blog/cratedb-dbeaver
[CrateDB and DBeaver]: https://cratedb.com/integrations/cratedb-and-dbeaver
[DBeaver]: https://dbeaver.io/
[Tool: DBeaver]: https://github.com/crate/crate/labels/tool%3A%20DBeaver
diff --git a/docs/integrate/dbt/index.md b/docs/integrate/dbt/index.md
index 060c8f32..f5933b31 100644
--- a/docs/integrate/dbt/index.md
+++ b/docs/integrate/dbt/index.md
@@ -4,17 +4,24 @@
:::{include} /_include/links.md
:::
-## About
-```{div}
-:style: "float: right"
-[{w=180px}](https://www.getdbt.com/)
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][dbt]
+
+```
+```{div} .clearfix
+```
+
+:::::{grid}
+:padding: 0
+
+::::{grid-item}
+:columns: auto 9 9 9
+
:::{rubric} About
:::
:::{div}
-The [DynamoDB Table Loader] supports loading DynamoDB tables into CrateDB (full-load),
-while the [DynamoDB CDC Relay] pipeline uses [Amazon DynamoDB Streams] or [Amazon Kinesis
-Data Streams] to relay table change stream CDC events from a DynamoDB table into CrateDB.
+[DynamoDB] is a fully managed NoSQL database service provided by Amazon Web Services (AWS).
+It is designed for high-performance, scalable applications and offers key-value and
+document data structures. DynamoDB is serverless, meaning users don't need to manage
+servers or infrastructure.
+:::
+
+::::
+
+::::{grid-item}
+:columns: auto 3 3 3
+
+:::{rubric} Related
+:::
+- [Amazon DynamoDB Streams]
+- {ref}`aws-kinesis`
+- [Amazon Kinesis Data Streams]
+::::
+
+:::::
+
+
+:::{rubric} Synopsis
+:::
+
+```shell
+uvx 'cratedb-toolkit[kinesis]' load table \
+ "kinesis+dynamodb+cdc://${AWS_ACCESS_KEY_ID}:${AWS_SECRET_ACCESS_KEY}@aws/cdc-stream?region=eu-central-1" \
+ --cluster-url="crate://crate:crate@localhost:4200/testdrive/demo"
+```
:::{rubric} Learn
:::
-:::{div}
-It is a common application to relay DynamoDB table change stream events to a
+It is common practice to forward DynamoDB table change stream events to a
Kinesis Stream, and consume that from an adapter to write into an analytical
-or long-term storage consolidation database.
+or long-term storage consolidation database like CrateDB.
+
+::::{grid}
+
+:::{grid-item-card} DynamoDB Table Loader
+:link: ctk:dynamodb-loader
+:link-type: ref
+Load DynamoDB tables into CrateDB (`full-load`).
+:::
+
+:::{grid-item-card} DynamoDB CDC Relay
+:link: ctk:dynamodb-cdc
+:link-type: ref
+Relay table change stream CDC events from a DynamoDB table into CrateDB (`cdc`).
+:::
+
+:::{grid-item-card} DynamoDB CDC Relay using AWS Lambda
+:link: ctk:io/dynamodb/cdc-lambda
+:link-type: doc
+Use serverless replication based on AWS Lambda to
+relay CDC events into CrateDB (`cdc`).
+:::
+
+::::
-If you are looking into serverless replication using AWS Lambda:
-- [DynamoDB CDC Relay with AWS Lambda]
-- Blog: [Replicating CDC events from DynamoDB to CrateDB]
+:::{seealso}
+**Blog:** [Replicating CDC events from DynamoDB to CrateDB]
:::
diff --git a/docs/integrate/aws-kinesis/index.md b/docs/integrate/aws-kinesis/index.md
index 2c773669..272b87d4 100644
--- a/docs/integrate/aws-kinesis/index.md
+++ b/docs/integrate/aws-kinesis/index.md
@@ -4,9 +4,20 @@
:::{include} /_include/links.md
:::
+```{div} .float-right
+[{height=60px loading=lazy}][Amazon Kinesis Data Streams]
+```
+```{div} .clearfix
+```
+
+:::::{grid}
+:padding: 0
+
+::::{grid-item}
+:columns: auto 9 9 9
+
:::{rubric} About
:::
-
:::{div}
[Amazon Kinesis Data Streams] is a serverless streaming data service that
simplifies the capture, processing, and storage of data streams at any
@@ -17,12 +28,49 @@ You can use Amazon Kinesis Data Streams to collect and process large data
streams in real time. A typical application reads data from the stream as
records.
:::
+::::
+
+::::{grid-item}
+:class: rubric-slim
+:columns: auto 3 3 3
+
+:::{rubric} Related
+:::
+- {ref}`aws-dynamodb`
+- [Amazon DynamoDB Streams]
+::::
+
+:::::
+
+:::{rubric} Synopsis
+:::
+
+```shell
+uvx 'cratedb-toolkit[io-ingestr]' load table \
+ "kinesis://?aws_access_key_id=${AWS_ACCESS_KEY_ID}&aws_secret_access_key=${AWS_SECRET_ACCESS_KEY}®ion_name=eu-central-1&table=arn:aws:kinesis:eu-central-1:831394476016:stream/testdrive" \
+ --cluster-url="crate://crate:crate@localhost:4200/testdrive/kinesis_demo"
+```
:::{rubric} Learn
:::
-:::{div}
-The [DynamoDB CDC Relay] pipeline uses Amazon Kinesis to relay a table
-change stream from a DynamoDB table into a CrateDB table, see also
-{ref}`DynamoDB CDC `.
+::::{grid}
+
+:::{grid-item-card} Ingestr Table Loader
+:link: https://cratedb-toolkit.readthedocs.io/io/ingestr/#amazon-kinesis-to-cratedb
+:link-type: url
+Relay Kinesis stream into CrateDB.
+:::
+
+:::{grid-item-card} DynamoDB CDC Relay
+:link: ctk:dynamodb-cdc
+:link-type: ref
+Relay table change stream CDC events from DynamoDB into CrateDB, using Kinesis.
+:::
+
+::::
+
+
+:::{seealso}
+**Blog:** [Replicating CDC events from DynamoDB to CrateDB]
:::
diff --git a/docs/integrate/aws-lambda/index.md b/docs/integrate/aws-lambda/index.md
index e1746543..eba86e20 100644
--- a/docs/integrate/aws-lambda/index.md
+++ b/docs/integrate/aws-lambda/index.md
@@ -4,6 +4,12 @@
:::{include} /_include/links.md
:::
+```{div} .float-right
+[{height=60px loading=lazy}][AWS Lambda]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
@@ -16,8 +22,34 @@ Events can include state changes and updates.
:::{rubric} Learn
:::
-:::{div}
-Serverless replication from DynamoDB to CrateDB using AWS Lambda:
-- [DynamoDB CDC Relay with AWS Lambda]
-- Blog: [Replicating CDC events from DynamoDB to CrateDB]
+It is common practice to forward DynamoDB table change stream events to a
+Kinesis stream, and to consume that from an adapter to write into an analytical
+or long-term storage consolidation database like CrateDB.
+
+::::{grid}
+
+:::{grid-item-card} DynamoDB Table Loader
+:link: ctk:dynamodb-loader
+:link-type: ref
+Load DynamoDB tables into CrateDB (`full-load`).
+:::
+
+:::{grid-item-card} DynamoDB CDC Relay
+:link: ctk:dynamodb-cdc
+:link-type: ref
+Relay table change stream CDC events from a DynamoDB table into CrateDB (`cdc`).
+:::
+
+:::{grid-item-card} DynamoDB CDC Relay using AWS Lambda
+:link: ctk:io/dynamodb/cdc-lambda
+:link-type: doc
+Use serverless replication based on AWS Lambda to
+relay CDC events into CrateDB (`cdc`).
+:::
+
+::::
+
+
+:::{seealso}
+**Blog:** [Replicating CDC events from DynamoDB to CrateDB]
:::
diff --git a/docs/integrate/azure-functions/index.md b/docs/integrate/azure-functions/index.md
index 7c57fa7d..c3e192e5 100644
--- a/docs/integrate/azure-functions/index.md
+++ b/docs/integrate/azure-functions/index.md
@@ -4,16 +4,18 @@
:::{include} /_include/links.md
:::
-_Execute event-driven serverless code with an end-to-end development experience._
+```{div} .float-right
+[{height=60px loading=lazy}][Azure Functions]
+```
+```{div} .clearfix
+```
:::{rubric} About
:::
-[Azure Functions] is a serverless solution that allows you to build robust apps
-while using less code, and with less infrastructure and lower costs. Instead
-of worrying about deploying and maintaining servers, you can use the cloud
-infrastructure to provide all the up-to-date resources needed to keep your
-applications running.
+[Azure Functions] is an event-driven serverless code execution solution that
+allows you to build robust apps while using less code, and with less
+infrastructure and lower costs.
An Azure Function is a short-lived, serverless computation that is triggered
by external events. The trigger produces an input payload, which is delivered
@@ -24,12 +26,22 @@ services, or storage services. See also [What is Azure Functions?].
:::{rubric} Learn
:::
-A common pattern is to use an Azure Function to enrich and ingest data
-to a CrateDB instance by connecting that Azure Function to an IoT Hub's new
-messages trigger.
+::::{grid} 2
+
+:::{grid-item-card} Data Enrichment using IoT Hub, Azure Functions and CrateDB
+:link: azure-functions-learn
+:link-type: ref
+A common pattern uses an Azure Function to enrich and ingest data
+into a CrateDB instance by connecting the function to an IoT Hub
+new‑messages trigger.
+:::
+
+::::
+
:::{toctree}
:maxdepth: 1
+:hidden:
learn
:::
diff --git a/docs/integrate/cluvio/index.md b/docs/integrate/cluvio/index.md
index c360e3cb..507b7f96 100644
--- a/docs/integrate/cluvio/index.md
+++ b/docs/integrate/cluvio/index.md
@@ -1,32 +1,49 @@
(cluvio)=
# Cluvio
+```{div} .float-right
+[{height=60px loading=lazy}][Cluvio]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 1em"
-[{w=180px}](https://www.cluvio.com/)
-```
-
[Cluvio] is a programmable and interactive dashboarding platform — your analytics
cockpit. Run queries, filter your results, choose the most vivid way to display them,
and share them with your colleagues and partners without efforts.
+::::{dropdown} **Details**
Cluvio dashboards are interactive, so you can easily change aggregation, select a
specific timerange or filter dashboards by any individual attribute of your data.
Use SQL and R to analyze your data and create beautiful, interactive dashboards for
your entire company in few minutes.
-{h=200px}
-{h=200px}
+{h=200px loading=lazy}
+{h=200px loading=lazy}
+::::
:::{rubric} Learn
:::
-- [Data Analysis with Cluvio and CrateDB]
+::::{grid} 2
+
+:::{grid-item-card} Data Analysis with Cluvio and CrateDB
+:link: https://community.cratedb.com/t/data-analysis-with-cluvio-and-cratedb/1571
+:link-type: url
+Explore how to leverage the power of Cluvio, a modern data analysis platform
+with CrateDB Cloud as the underlying database.
+:::
+
+::::
+
+
+```{seealso}
+[CrateDB and Cluvio]
+```
[Cluvio]: https://www.cluvio.com/
-[Data Analysis with Cluvio and CrateDB]: https://community.cratedb.com/t/data-analysis-with-cluvio-and-cratedb/1571
+[CrateDB and Cluvio]: https://cratedb.com/integrations/cratedb-and-cluvio
diff --git a/docs/integrate/datagrip/index.md b/docs/integrate/datagrip/index.md
index b0a04d65..16be2667 100644
--- a/docs/integrate/datagrip/index.md
+++ b/docs/integrate/datagrip/index.md
@@ -4,21 +4,20 @@
:::{include} /_include/links.md
:::
-```{div}
-:style: "float: right; margin-left: 0.5em"
-[{w=120px}](https://www.jetbrains.com/datagrip/)
+```{div} .float-right
+:style: "margin-left: 0.5em"
+[{width=120px loading=lazy}][DataGrip]
```
-
+:::{div}
[DataGrip] is a cross-platform database IDE that is tailored to suit the
specific needs of professional SQL developers.
-It is available as a standalone application and is also included into
+It is available as a standalone application and is also included in
other JetBrains products like IntelliJ IDEA and PyCharm.
Connecting DataGrip to CrateDB uses the [CrateDB JDBC Driver].
-
-```{div}
-:style: "clear: both"
+:::
+```{div} .clearfix
```
@@ -30,8 +29,8 @@ For connecting to CrateDB, install the [CrateDB JDBC Driver]
using the "Custom JARs" option when adding a database driver.
:::
:::{grid-item}
-{h=180px}
-{h=180px}
+{height=180px loading=lazy}
+{height=180px loading=lazy}
:::
:::{grid-item}
[crate-jdbc-standalone] is the right choice here.
@@ -39,7 +38,7 @@ For example, download and use the [crate-jdbc-standalone-latest.jar] JAR file,
and select the driver class `io.crate.client.jdbc.CrateDriver`.
:::
:::{grid-item}
-{w=400px}
+{width=400px loading=lazy}
:::
::::
@@ -53,7 +52,7 @@ Now, you can add a Data Source using the CrateDB database driver.
Please specify database URL and credentials of your CrateDB cluster.
:::
:::{grid-item}
-{w=480px}
+{width=480px loading=lazy}
:::
:::{grid-item}
For connecting to [CrateDB Self-Managed] or [CrateDB Cloud],
@@ -63,7 +62,7 @@ jdbc:crate://:5432/
```
:::
:::{grid-item}
-{w=480px}
+{width=480px loading=lazy}
:::
::::
@@ -72,8 +71,8 @@ jdbc:crate://:5432/
## Usage
After refreshing, you can browse the data tree, and use the Query Console.
-{h=240px}
-{h=240px}
+{height=240px loading=lazy}
+{height=240px loading=lazy}
@@ -81,11 +80,18 @@ After refreshing, you can browse the data tree, and use the Query Console.
:::{rubric} Tutorials
:::
-- [Blog: Use CrateDB With DataGrip]
-:::{rubric} Product
+::::{grid}
+
+:::{grid-item-card} Blog: Use CrateDB With DataGrip
+:link: https://cratedb.com/blog/use-cratedb-with-datagrip-an-advanced-database-ide
+:link-type: url
+DataGrip is a cross-platform database IDE (Integrated Development Environment) that is
+tailored to suit the specific needs of professional SQL developers.
+With the help of the CrateDB JDBC Standalone Driver, you can use DataGrip with CrateDB.
:::
-- [CrateDB and DataGrip]
+
+::::
:::{rubric} Notes
:::
@@ -94,8 +100,11 @@ We are tracking interoperability issues per [Tool: DataGrip], and appreciate
any contributions and reports.
:::
+:::{seealso}
+[CrateDB and DataGrip]
+:::
+
-[Blog: Use CrateDB With DataGrip]: https://cratedb.com/blog/use-cratedb-with-datagrip-an-advanced-database-ide
[CrateDB and DataGrip]: https://cratedb.com/integrations/cratedb-and-datagrip
[DataGrip]: https://www.jetbrains.com/datagrip/
[Tool: DataGrip]: https://github.com/crate/crate/labels/tool%3A%20DataGrip
diff --git a/docs/integrate/dbeaver/index.md b/docs/integrate/dbeaver/index.md
index 40d14ad5..7f1f098a 100644
--- a/docs/integrate/dbeaver/index.md
+++ b/docs/integrate/dbeaver/index.md
@@ -4,9 +4,9 @@
:::{include} /_include/links.md
:::
-```{div}
-:style: "float: right; margin-left: 0.5em"
-[{w=120px}](https://dbeaver.io/)
+```{div} .float-right
+:style: "margin-left: 0.5em"
+[{w=120px loading=lazy}][DBeaver]
```
[DBeaver] is a multipurpose cross-platform database tool for developers,
@@ -39,7 +39,7 @@ jdbc:postgresql://.cratedb.net:5432/crate
:::
:::{grid-item}
:columns: 5
-{w=480px}
+{w=480px loading=lazy}
:::
::::
@@ -49,19 +49,25 @@ jdbc:postgresql://.cratedb.net:5432/crate
Use the tree menu on the left-hand pane to navigate to the `doc` schema and
its tables. Navigate to the Data tab to browse your table data.
-{h=240px}
-{h=240px}
+{h=240px loading=lazy}
+{h=240px loading=lazy}
## Learn
:::{rubric} Tutorials
:::
-- [Blog: Use CrateDB With DBeaver]
-:::{rubric} Product
+::::{grid}
+
+:::{grid-item-card} Blog: Use CrateDB With DBeaver
+:link: https://cratedb.com/blog/cratedb-dbeaver
+:link-type: url
+DBeaver is a multipurpose database tool for developers and database administrators.
+With the help of the CrateDB JDBC Standalone Driver, you can use DBeaver with CrateDB.
:::
-- [CrateDB and DBeaver]
+
+::::
:::{rubric} Notes
:::
@@ -80,8 +86,11 @@ We are tracking interoperability issues per [Tool: DBeaver], and appreciate
any contributions and reports.
:::
+:::{seealso}
+[CrateDB and DBeaver]
+:::
+
-[Blog: Use CrateDB With DBeaver]: https://cratedb.com/blog/cratedb-dbeaver
[CrateDB and DBeaver]: https://cratedb.com/integrations/cratedb-and-dbeaver
[DBeaver]: https://dbeaver.io/
[Tool: DBeaver]: https://github.com/crate/crate/labels/tool%3A%20DBeaver
diff --git a/docs/integrate/dbt/index.md b/docs/integrate/dbt/index.md
index 060c8f32..f5933b31 100644
--- a/docs/integrate/dbt/index.md
+++ b/docs/integrate/dbt/index.md
@@ -4,17 +4,24 @@
:::{include} /_include/links.md
:::
-## About
-```{div}
-:style: "float: right"
-[{w=180px}](https://www.getdbt.com/)
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][dbt]
+
+
+  ```
+```{div} .clearfix
+```
+
+## About
[dbt] is a tool for transforming data in data warehouses using Python and SQL.
-It is an SQL-first transformation workflow platform that lets teams quickly and
+It is an SQL‑first transformation workflow platform that lets teams quickly and
collaboratively deploy analytics code following software engineering best practices
-like modularity, portability, CI/CD, and documentation.
+such as modularity, portability, CI/CD, and documentation.
+
+::::{dropdown} **Details**
> dbt enables data analysts and engineers to transform their data using the same
> practices that software engineers use to build applications.
@@ -31,10 +38,33 @@ Afterwards, data analysts can run their dbt projects against this data to produc
{h=120px}
{h=120px}
+:::{rubric} dbt's Features
+:::
+The data abstraction layer provided by [dbt-core] allows the decoupling of
+the models on which reports and dashboards rely from the source data. When
+business rules or source systems change, you can still maintain the same models
+as a stable interface.
+
+Some of the things that dbt can do include:
+
+* Import reference data from CSV files.
+* Track changes in source data with different strategies so that downstream
+ models do not need to be built every time from scratch.
+* Run tests on data, to confirm assumptions remain valid, and to validate
+ any changes made to the models' logic.
+
+:::{rubric} CrateDB's Benefits
+:::
+Due to its unique capabilities, CrateDB is an excellent warehouse choice for
+data transformation projects. It offers automatic indexing, fast aggregations,
+easy partitioning, and the ability to scale horizontally.
+
+::::
+
:::{dropdown} **Managed dbt**
```{div}
:style: "float: right"
-[{w=180px}](https://www.getdbt.com/product/dbt-cloud/)
+[{w=180px}](https://www.getdbt.com/product/dbt-cloud/)
```
With [dbt Cloud], you can ditch time-consuming setup, and the struggles
@@ -54,39 +84,17 @@ scale.
use dbt Cloud. They’ve used its convenient and collaboration-friendly interface to
eliminate the bottlenecks that keep growth limited.
-```{div}
-:style: "clear: both"
+```{div} .clearfix
```
:::
-### dbt's Features
-The data abstraction layer provided by [dbt-core] allows the decoupling of
-the models on which reports and dashboards rely from the source data. When
-business rules or source systems change, you can still maintain the same models
-as a stable interface.
-
-Some of the things that dbt can do include:
-
-* Import reference data from CSV files.
-* Track changes in source data with different strategies so that downstream
- models do not need to be built every time from scratch.
-* Run tests on data, to confirm assumptions remain valid, and to validate
- any changes made to the models' logic.
-
-### CrateDB's Benefits
-Due to its unique capabilities, CrateDB is an excellent warehouse choice for
-data transformation projects. It offers automatic indexing, fast aggregations,
-easy partitioning, and the ability to scale horizontally.
-
-
## Setup
Install the most recent version of the [dbt-cratedb2] Python package.
```shell
pip install --upgrade 'dbt-cratedb2'
```
-
## Configure
Because CrateDB is compatible with PostgreSQL, the same connectivity
options apply like outlined on the [dbt Postgres Setup] documentation
@@ -112,7 +120,7 @@ cratedb_analytics:
## Learn
-Learn how to use CrateDB with dbt by exploring concise examples.
+Learn how to use CrateDB with dbt by exploring a few examples.
:::{rubric} Tutorials
:::
diff --git a/docs/integrate/debezium/index.md b/docs/integrate/debezium/index.md
index 09355493..1802f6b3 100644
--- a/docs/integrate/debezium/index.md
+++ b/docs/integrate/debezium/index.md
@@ -1,25 +1,22 @@
(debezium)=
# Debezium
-:::{include} /_include/links.md
-:::
+```{div} .float-right
+[{height=60px loading=lazy}][Debezium]
+```
+```{div} .clearfix
+```
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 2em"
-[{w=180px}](https://debezium.io/)
-```
-
-[Debezium] is an open source distributed platform for change data capture. After
-pointing it at your databases, you can subscribe to the event stream of
+[Debezium] is an open source distributed platform for change data capture (CDC).
+After pointing it at your databases, you can subscribe to the event stream of
all database update operations.
-Debezium is an open source distributed platform for change data capture (CDC).
-It is built on top of Apache Kafka, a distributed streaming platform. It allows
-to capture changes on a source database system, mostly OLTP, and replicate them
-to another system, mostly to run OLAP workloads on the data.
+It is built on top of Apache Kafka, a distributed streaming platform.
+It allows capturing changes on a source database system (typically OLTP) and
+replicating them to another system, for example to run OLAP workloads on the data.
Debezium provides connectors for MySQL/MariaDB, MongoDB, PostgreSQL, Oracle,
SQL Server, IBM DB2, Cassandra, Vitess, Spanner, JDBC, and Informix.
@@ -27,11 +24,22 @@ SQL Server, IBM DB2, Cassandra, Vitess, Spanner, JDBC, and Informix.
:::{rubric} Learn
:::
-:::{div}
-- Tutorial: [Replicating data to CrateDB with Debezium and Kafka]
-- Webinar: [How to replicate data from other databases to CrateDB with Debezium and Kafka]
+::::{grid}
+
+:::{grid-item-card} Tutorial: Replicate data from MSSQL
+:link: https://community.cratedb.com/t/replicating-data-to-cratedb-with-debezium-and-kafka/1388
+:link-type: url
+Replicating data from MSSQL to CrateDB with Debezium and Kafka.
+:::
+
+:::{grid-item-card} Webinar: Replicate data from other databases
+:link: https://cratedb.com/resources/webinars/lp-wb-debezium-kafka
+:link-type: url
+How to replicate data from other databases to CrateDB with Debezium and Kafka.
:::
+::::
+
+
[Debezium]: https://debezium.io/
-[How to replicate data from other databases to CrateDB with Debezium and Kafka]: https://cratedb.com/resources/webinars/lp-wb-debezium-kafka
diff --git a/docs/integrate/django/index.md b/docs/integrate/django/index.md
index 9565a28e..691c5862 100644
--- a/docs/integrate/django/index.md
+++ b/docs/integrate/django/index.md
@@ -1,16 +1,21 @@
(django)=
# Django
+```{div} .float-right
+[{height=60px loading=lazy}][Django]
+
```
+```{div} .clearfix
+```
+
+## About
[dbt] is a tool for transforming data in data warehouses using Python and SQL.
-It is an SQL-first transformation workflow platform that lets teams quickly and
+It is an SQL‑first transformation workflow platform that lets teams quickly and
collaboratively deploy analytics code following software engineering best practices
-like modularity, portability, CI/CD, and documentation.
+such as modularity, portability, CI/CD, and documentation.
+
+::::{dropdown} **Details**
> dbt enables data analysts and engineers to transform their data using the same
> practices that software engineers use to build applications.
@@ -31,10 +38,33 @@ Afterwards, data analysts can run their dbt projects against this data to produc
{h=120px}
{h=120px}
+:::{rubric} dbt's Features
+:::
+The data abstraction layer provided by [dbt-core] allows the decoupling of
+the models on which reports and dashboards rely from the source data. When
+business rules or source systems change, you can still maintain the same models
+as a stable interface.
+
+Some of the things that dbt can do include:
+
+* Import reference data from CSV files.
+* Track changes in source data with different strategies so that downstream
+ models do not need to be built every time from scratch.
+* Run tests on data, to confirm assumptions remain valid, and to validate
+ any changes made to the models' logic.
+
+:::{rubric} CrateDB's Benefits
+:::
+Due to its unique capabilities, CrateDB is an excellent warehouse choice for
+data transformation projects. It offers automatic indexing, fast aggregations,
+easy partitioning, and the ability to scale horizontally.
+
+::::
+
:::{dropdown} **Managed dbt**
```{div}
:style: "float: right"
-[{w=180px}](https://www.getdbt.com/product/dbt-cloud/)
+[{w=180px}](https://www.getdbt.com/product/dbt-cloud/)
```
With [dbt Cloud], you can ditch time-consuming setup, and the struggles
@@ -54,39 +84,17 @@ scale.
use dbt Cloud. They’ve used its convenient and collaboration-friendly interface to
eliminate the bottlenecks that keep growth limited.
-```{div}
-:style: "clear: both"
+```{div} .clearfix
```
:::
-### dbt's Features
-The data abstraction layer provided by [dbt-core] allows the decoupling of
-the models on which reports and dashboards rely from the source data. When
-business rules or source systems change, you can still maintain the same models
-as a stable interface.
-
-Some of the things that dbt can do include:
-
-* Import reference data from CSV files.
-* Track changes in source data with different strategies so that downstream
- models do not need to be built every time from scratch.
-* Run tests on data, to confirm assumptions remain valid, and to validate
- any changes made to the models' logic.
-
-### CrateDB's Benefits
-Due to its unique capabilities, CrateDB is an excellent warehouse choice for
-data transformation projects. It offers automatic indexing, fast aggregations,
-easy partitioning, and the ability to scale horizontally.
-
-
## Setup
Install the most recent version of the [dbt-cratedb2] Python package.
```shell
pip install --upgrade 'dbt-cratedb2'
```
-
## Configure
Because CrateDB is compatible with PostgreSQL, the same connectivity
options apply like outlined on the [dbt Postgres Setup] documentation
@@ -112,7 +120,7 @@ cratedb_analytics:
## Learn
-Learn how to use CrateDB with dbt by exploring concise examples.
+Learn how to use CrateDB with dbt by exploring a few examples.
:::{rubric} Tutorials
:::
diff --git a/docs/integrate/debezium/index.md b/docs/integrate/debezium/index.md
index 09355493..1802f6b3 100644
--- a/docs/integrate/debezium/index.md
+++ b/docs/integrate/debezium/index.md
@@ -1,25 +1,22 @@
(debezium)=
# Debezium
-:::{include} /_include/links.md
-:::
+```{div} .float-right
+[{height=60px loading=lazy}][Debezium]
+```
+```{div} .clearfix
+```
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 2em"
-[{w=180px}](https://debezium.io/)
-```
-
-[Debezium] is an open source distributed platform for change data capture. After
-pointing it at your databases, you can subscribe to the event stream of
+[Debezium] is an open source distributed platform for change data capture (CDC).
+After pointing it at your databases, you can subscribe to the event stream of
all database update operations.
-Debezium is an open source distributed platform for change data capture (CDC).
-It is built on top of Apache Kafka, a distributed streaming platform. It allows
-to capture changes on a source database system, mostly OLTP, and replicate them
-to another system, mostly to run OLAP workloads on the data.
+It is built on top of Apache Kafka, a distributed streaming platform.
+It allows capturing changes on a source database system (typically OLTP) and
+replicating them to another system, for example to run OLAP workloads on the data.
Debezium provides connectors for MySQL/MariaDB, MongoDB, PostgreSQL, Oracle,
SQL Server, IBM DB2, Cassandra, Vitess, Spanner, JDBC, and Informix.
@@ -27,11 +24,22 @@ SQL Server, IBM DB2, Cassandra, Vitess, Spanner, JDBC, and Informix.
:::{rubric} Learn
:::
-:::{div}
-- Tutorial: [Replicating data to CrateDB with Debezium and Kafka]
-- Webinar: [How to replicate data from other databases to CrateDB with Debezium and Kafka]
+::::{grid}
+
+:::{grid-item-card} Tutorial: Replicate data from MSSQL
+:link: https://community.cratedb.com/t/replicating-data-to-cratedb-with-debezium-and-kafka/1388
+:link-type: url
+Replicating data from MSSQL to CrateDB with Debezium and Kafka.
+:::
+
+:::{grid-item-card} Webinar: Replicate data from other databases
+:link: https://cratedb.com/resources/webinars/lp-wb-debezium-kafka
+:link-type: url
+How to replicate data from other databases to CrateDB with Debezium and Kafka.
:::
+::::
+
+
[Debezium]: https://debezium.io/
-[How to replicate data from other databases to CrateDB with Debezium and Kafka]: https://cratedb.com/resources/webinars/lp-wb-debezium-kafka
diff --git a/docs/integrate/django/index.md b/docs/integrate/django/index.md
index 9565a28e..691c5862 100644
--- a/docs/integrate/django/index.md
+++ b/docs/integrate/django/index.md
@@ -1,16 +1,21 @@
(django)=
# Django
+```{div} .float-right
+[{height=60px loading=lazy}][Django]
+
+
+  +```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 2em"
-[{w=180px}](https://www.djangoproject.com/)
-```
-
[Django] makes it easier to build better web apps more quickly and with less code.
+::::{dropdown} **Details**
Django is a high-level Python web framework that encourages rapid development and
clean, pragmatic design. Built by experienced developers, it takes care of much of
the hassle of web development, so you can focus on writing your app without needing
@@ -24,13 +29,20 @@ to reinvent the wheel. It’s free and open source.
- **Exceedingly scalable**: Some of the busiest sites on the web leverage Django’s
ability to quickly and flexibly scale.
+::::
:::{rubric} Learn
:::
-- [CrateDB Django connector]: Connector backend to use CrateDB as a database in Django ORM.
+::::{grid} 2
+
+:::{grid-item-card} CrateDB Django connector
+:link: https://github.com/crate/cratedb-django
+:link-type: url
+Connector backend to use CrateDB as a database in Django ORM.
+:::
+::::
-[CrateDB Django connector]: https://github.com/crate/cratedb-django
[Django]: https://www.djangoproject.com/
diff --git a/docs/integrate/estuary/index.md b/docs/integrate/estuary/index.md
index 9113f024..70f71a8c 100644
--- a/docs/integrate/estuary/index.md
+++ b/docs/integrate/estuary/index.md
@@ -2,16 +2,21 @@
# Estuary
-```{div}
-:style: "float: right; margin-left: 0.5em"
-[{w=180px}](https://estuary.dev/)
+```{div} .float-right
+[{height=60px loading=lazy}][Estuary]
```
+```{div} .clearfix
+```
+
+:::{rubric} About
+:::
[Estuary] provides real-time data integration and modern ETL and ELT data pipelines.
Build scalable, fault-tolerant streaming data pipelines that seamlessly connect
to virtually any data source for data warehouses, real-time analytics, operations,
machine learning, and AI.
+:::{dropdown} **Details**
Estuary Flow is a real-time, reliable change data capture
(CDC) solution. It combines agentless CDC, zero-code pipelines,
and enterprise-grade governance to simplify data integration,
@@ -32,6 +37,7 @@ vendors, bearing a few excellent features:
> Build low-latency ETL and ELT pipelines using connectors for any database
> or data warehouse, leveraging Change Data Capture (CDC) to power your
> analytics, operations, and AI.
+:::
:::{dropdown} **Managed Estuary**
Estuary offers its solution as a [managed product][Estuary managed], available
@@ -40,31 +46,13 @@ organizational needs and security requirements: Public Deployment,
Private Deployment, and BYOC options.
:::
-```{div}
-:style: "clear: both"
-```
-## Learn
+:::{rubric} Start
+:::
::::{grid} 2
:gutter: 2
-:::{grid-item-card}
-:link: https://estuary.dev/blog/the-complete-introduction-to-change-data-capture-cdc/
-:link-type: url
-:link-alt: "Change Data Capture (CDC): The Complete Guide"
-:padding: 3
-:class-card: sd-text-center sd-pt-4
-:class-header: sd-fs-6
-:class-footer: text-smaller
-CDC: The Complete Guide
-^^^
-{material-outlined}`integration_instructions;4.5em`
-+++
-Understand what Change Data Capture (CDC) is, how it works, and when to use it.
-Compare top CDC tools like Estuary, Debezium, Fivetran & more.
-:::
-
:::{grid-item-card}
:link: https://estuary.dev/destination/cratedb/
:link-type: url
@@ -83,11 +71,29 @@ Continuously ingest and deliver both streaming and batch change data from
::::
-## Details
+
+:::{rubric} Learn
+:::
::::{grid} 2
:gutter: 2
+:::{grid-item-card}
+:link: https://estuary.dev/blog/the-complete-introduction-to-change-data-capture-cdc/
+:link-type: url
+:link-alt: "Change Data Capture (CDC): The Complete Guide"
+:padding: 3
+:class-card: sd-text-center sd-pt-4
+:class-header: sd-fs-6
+:class-footer: text-smaller
+CDC: The Complete Guide
+^^^
+{material-outlined}`integration_instructions;4.5em`
++++
+Understand what Change Data Capture (CDC) is, how it works, and when to use it.
+Compare top CDC tools like Estuary, Debezium, Fivetran & more.
+:::
+
:::{grid-item-card}
:link: https://github.com/crate/cratedb-estuary
:link-type: url
diff --git a/docs/integrate/explo/index.md b/docs/integrate/explo/index.md
index 173ef2cd..02fe5d21 100644
--- a/docs/integrate/explo/index.md
+++ b/docs/integrate/explo/index.md
@@ -1,36 +1,41 @@
(explo)=
# Explo
+```{div} .float-right
+[{height=60px loading=lazy}][Explo]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 1em"
-[{w=180px}](https://www.explo.co/)
-```
-
[Explo] is a software platform for personalized and real-time customer facing
analytics. Organizations use Explo’s platform services "Explore", "Host", "Report
builder", and "Email", to activate and share data with their customers.
+:::{dropdown} **Details**
[Explo Explore] integrates directly into your web portal or application and provides
your customers with a complete self-service data toolkit, which can also be used to
run white-labeled data portals.
-```{div}
-:style: "clear: both"
-```
+{h=200px}
+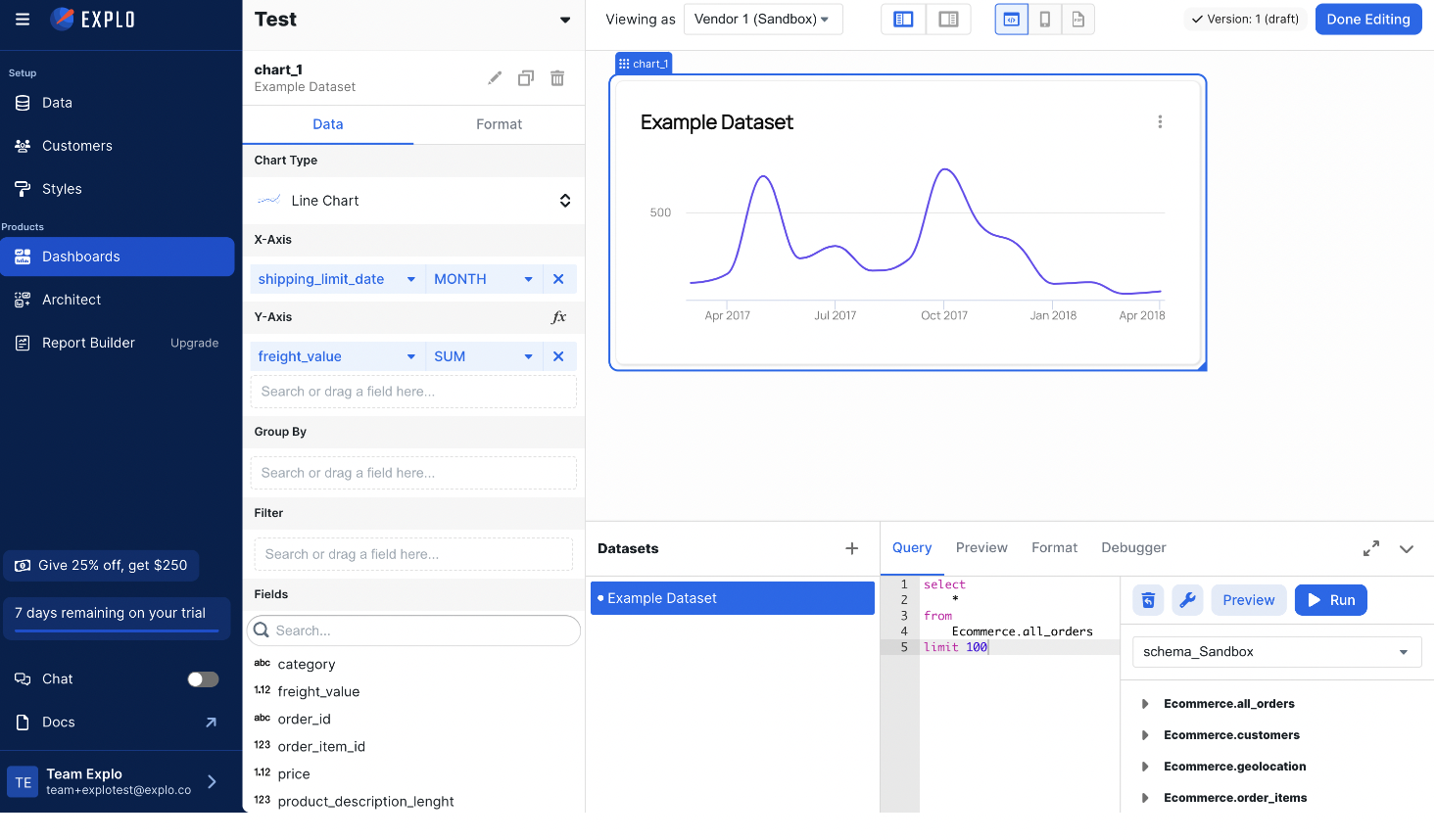{h=200px}
+:::
-{h=200px}
-{h=200px}
+:::{rubric} Learn
+:::
+::::{grid} 2
-:::{rubric} Learn
+:::{grid-item-card} Blog: Introduction to Time Series Visualization
+:link: https://cratedb.com/blog/introduction-to-time-series-visualization-in-cratedb-and-explo
+:link-type: url
+Introduction to Time Series Visualization in CrateDB and Explo.
:::
-- [Introduction to Time Series Visualization in CrateDB and Explo]
+::::
[Explo]: https://www.explo.co/
[Explo Explore]: https://www.explo.co/products/explore
-[Introduction to Time Series Visualization in CrateDB and Explo]: https://cratedb.com/blog/introduction-to-time-series-visualization-in-cratedb-and-explo
diff --git a/docs/integrate/gradio/index.md b/docs/integrate/gradio/index.md
index 7f606554..aa6742fc 100644
--- a/docs/integrate/gradio/index.md
+++ b/docs/integrate/gradio/index.md
@@ -1,27 +1,50 @@
(gradio)=
# Gradio
-```{div}
-:style: "float: right; margin-left: 0.5em"
-[{w=180px}](https://www.gradio.app/)
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][Gradio]
+
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 2em"
-[{w=180px}](https://www.djangoproject.com/)
-```
-
[Django] makes it easier to build better web apps more quickly and with less code.
+::::{dropdown} **Details**
Django is a high-level Python web framework that encourages rapid development and
clean, pragmatic design. Built by experienced developers, it takes care of much of
the hassle of web development, so you can focus on writing your app without needing
@@ -24,13 +29,20 @@ to reinvent the wheel. It’s free and open source.
- **Exceedingly scalable**: Some of the busiest sites on the web leverage Django’s
ability to quickly and flexibly scale.
+::::
:::{rubric} Learn
:::
-- [CrateDB Django connector]: Connector backend to use CrateDB as a database in Django ORM.
+::::{grid} 2
+
+:::{grid-item-card} CrateDB Django connector
+:link: https://github.com/crate/cratedb-django
+:link-type: url
+Connector backend to use CrateDB as a database in Django ORM.
+:::
+::::
-[CrateDB Django connector]: https://github.com/crate/cratedb-django
[Django]: https://www.djangoproject.com/
diff --git a/docs/integrate/estuary/index.md b/docs/integrate/estuary/index.md
index 9113f024..70f71a8c 100644
--- a/docs/integrate/estuary/index.md
+++ b/docs/integrate/estuary/index.md
@@ -2,16 +2,21 @@
# Estuary
-```{div}
-:style: "float: right; margin-left: 0.5em"
-[{w=180px}](https://estuary.dev/)
+```{div} .float-right
+[{height=60px loading=lazy}][Estuary]
```
+```{div} .clearfix
+```
+
+:::{rubric} About
+:::
[Estuary] provides real-time data integration and modern ETL and ELT data pipelines.
Build scalable, fault-tolerant streaming data pipelines that seamlessly connect
to virtually any data source for data warehouses, real-time analytics, operations,
machine learning, and AI.
+:::{dropdown} **Details**
Estuary Flow is a real-time, reliable change data capture
(CDC) solution. It combines agentless CDC, zero-code pipelines,
and enterprise-grade governance to simplify data integration,
@@ -32,6 +37,7 @@ vendors, bearing a few excellent features:
> Build low-latency ETL and ELT pipelines using connectors for any database
> or data warehouse, leveraging Change Data Capture (CDC) to power your
> analytics, operations, and AI.
+:::
:::{dropdown} **Managed Estuary**
Estuary offers its solution as a [managed product][Estuary managed], available
@@ -40,31 +46,13 @@ organizational needs and security requirements: Public Deployment,
Private Deployment, and BYOC options.
:::
-```{div}
-:style: "clear: both"
-```
-## Learn
+:::{rubric} Start
+:::
::::{grid} 2
:gutter: 2
-:::{grid-item-card}
-:link: https://estuary.dev/blog/the-complete-introduction-to-change-data-capture-cdc/
-:link-type: url
-:link-alt: "Change Data Capture (CDC): The Complete Guide"
-:padding: 3
-:class-card: sd-text-center sd-pt-4
-:class-header: sd-fs-6
-:class-footer: text-smaller
-CDC: The Complete Guide
-^^^
-{material-outlined}`integration_instructions;4.5em`
-+++
-Understand what Change Data Capture (CDC) is, how it works, and when to use it.
-Compare top CDC tools like Estuary, Debezium, Fivetran & more.
-:::
-
:::{grid-item-card}
:link: https://estuary.dev/destination/cratedb/
:link-type: url
@@ -83,11 +71,29 @@ Continuously ingest and deliver both streaming and batch change data from
::::
-## Details
+
+:::{rubric} Learn
+:::
::::{grid} 2
:gutter: 2
+:::{grid-item-card}
+:link: https://estuary.dev/blog/the-complete-introduction-to-change-data-capture-cdc/
+:link-type: url
+:link-alt: "Change Data Capture (CDC): The Complete Guide"
+:padding: 3
+:class-card: sd-text-center sd-pt-4
+:class-header: sd-fs-6
+:class-footer: text-smaller
+CDC: The Complete Guide
+^^^
+{material-outlined}`integration_instructions;4.5em`
++++
+Understand what Change Data Capture (CDC) is, how it works, and when to use it.
+Compare top CDC tools like Estuary, Debezium, Fivetran & more.
+:::
+
:::{grid-item-card}
:link: https://github.com/crate/cratedb-estuary
:link-type: url
diff --git a/docs/integrate/explo/index.md b/docs/integrate/explo/index.md
index 173ef2cd..02fe5d21 100644
--- a/docs/integrate/explo/index.md
+++ b/docs/integrate/explo/index.md
@@ -1,36 +1,41 @@
(explo)=
# Explo
+```{div} .float-right
+[{height=60px loading=lazy}][Explo]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 1em"
-[{w=180px}](https://www.explo.co/)
-```
-
[Explo] is a software platform for personalized and real-time customer facing
analytics. Organizations use Explo’s platform services "Explore", "Host", "Report
builder", and "Email", to activate and share data with their customers.
+:::{dropdown} **Details**
[Explo Explore] integrates directly into your web portal or application and provides
your customers with a complete self-service data toolkit, which can also be used to
run white-labeled data portals.
-```{div}
-:style: "clear: both"
-```
+{h=200px}
+{h=200px}
+:::
-{h=200px}
-{h=200px}
+:::{rubric} Learn
+:::
+::::{grid} 2
-:::{rubric} Learn
+:::{grid-item-card} Blog: Introduction to Time Series Visualization
+:link: https://cratedb.com/blog/introduction-to-time-series-visualization-in-cratedb-and-explo
+:link-type: url
+Introduction to Time Series Visualization in CrateDB and Explo.
:::
-- [Introduction to Time Series Visualization in CrateDB and Explo]
+::::
[Explo]: https://www.explo.co/
[Explo Explore]: https://www.explo.co/products/explore
-[Introduction to Time Series Visualization in CrateDB and Explo]: https://cratedb.com/blog/introduction-to-time-series-visualization-in-cratedb-and-explo
diff --git a/docs/integrate/gradio/index.md b/docs/integrate/gradio/index.md
index 7f606554..aa6742fc 100644
--- a/docs/integrate/gradio/index.md
+++ b/docs/integrate/gradio/index.md
@@ -1,27 +1,50 @@
(gradio)=
# Gradio
-```{div}
-:style: "float: right; margin-left: 0.5em"
-[{w=180px}](https://www.gradio.app/)
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][Gradio]
+
+
+  ```
+```{div} .clearfix
+```
+
+:::{rubric} About
+:::
[Gradio] is an open source programming framework for quickly creating and sharing
machine learning model demo applications, written in Python.
+::::{dropdown} **Details**
+
- Creating a user interface only requires adding a couple lines of code to your project.
- It does not require any experience with HTML/JS/CSS, or web hosting.
- Gradio can be embedded in Python notebooks, or presented as a web application.
- Once you've created an interface, you can permanently host it on [Hugging Face].
-```{div}
-:style: "clear: both"
+```{div} .clearfix
```
-
+
_How to Build Machine Learning APIs Using Gradio._
+::::
+
+:::{rubric} Learn
+:::
+
+::::{grid} 2
+
+:::{grid-item-card} Example
+:link: https://github.com/crate/cratedb-examples/tree/main/framework/gradio
+:link-type: url
+Example program using Gradio with CrateDB.
+:::
+
+::::
+
[Gradio]: https://www.gradio.app/
[Hugging Face]: https://en.wikipedia.org/wiki/Hugging_Face
diff --git a/docs/integrate/grafana/index.md b/docs/integrate/grafana/index.md
index bf34e025..d33113cc 100644
--- a/docs/integrate/grafana/index.md
+++ b/docs/integrate/grafana/index.md
@@ -1,35 +1,21 @@
(grafana)=
# Grafana
+```{div} .float-right
+[{height=60px loading=lazy}][Grafana OSS]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 1em"
-[{w=180px}](https://grafana.com/grafana/)
-```
-
[Grafana OSS] is the leading open-source metrics visualization tool that helps you
build real-time dashboards, graphs, and many other sorts of data visualizations.
[Grafana Cloud] is a fully-managed service offered by [Grafana Labs].
-Grafana complements CrateDB in monitoring and visualizing large volumes of machine
-data in real-time.
-
-Connecting to a CrateDB cluster will use the Grafana PostgreSQL data source adapter.
-The following tutorials outline how to configure Grafana to connect to CrateDB, and
-how to run a database query.
-
-{h=200px}
-{h=200px}
-
:::{dropdown} **Managed Grafana**
-```{div}
-:style: "float: right"
-[{w=180px}](https://grafana.com/grafana/)
-```
-
Get Grafana fully managed with [Grafana Cloud].
- Offered as a fully managed service, Grafana Cloud is the fastest way to adopt
@@ -38,18 +24,37 @@ Get Grafana fully managed with [Grafana Cloud].
individuals, teams, and large enterprises.
- Includes a robust free tier with access to 10k metrics, 50GB logs, 50GB traces,
50GB profiles, and 500VUh of k6 testing for 3 users.
-
-```{div}
-:style: "clear: both"
-```
:::
:::{rubric} Learn
:::
+::::{grid} 2
+
+:::{grid-item-card} Visualize data with Grafana
+:link: visualize-data-with-grafana
+:link-type: ref
+Grafana complements CrateDB in monitoring and visualizing large volumes of
+machine data in real-time.
+
+Select and import a dataset into CrateDB, connect Grafana to CrateDB,
+and create your first dashboard.
++++
+Connecting to a CrateDB cluster uses the Grafana PostgreSQL data source adapter.
+:::
+
+:::{grid-item}
+{h=200px}
+
+{h=200px}
+:::
+
+::::
+
+
:::{toctree}
:maxdepth: 1
-
+:hidden:
learn
:::
diff --git a/docs/integrate/index.md b/docs/integrate/index.md
index 5198fa3d..cc85f553 100644
--- a/docs/integrate/index.md
+++ b/docs/integrate/index.md
@@ -23,9 +23,9 @@ apache-iceberg/index
apache-kafka/index
apache-nifi/index
apache-superset/index
-aws-dms/index
aws-dynamodb/index
aws-kinesis/index
+aws-dms/index
aws-lambda/index
azure-functions/index
cluvio/index
@@ -40,6 +40,8 @@ gradio/index
grafana/index
influxdb/index
kestra/index
+langchain/index
+llamaindex/index
marquez/index
meltano/index
metabase/index
@@ -48,7 +50,7 @@ mysql/index
n8n/index
node-red/index
plotly/index
-powerbi/index
+Power BI
prometheus/index
pyviz/index
rill/index
diff --git a/docs/integrate/influxdb/index.md b/docs/integrate/influxdb/index.md
index a26c0774..fe19af66 100644
--- a/docs/integrate/influxdb/index.md
+++ b/docs/integrate/influxdb/index.md
@@ -6,6 +6,15 @@
:::{include} /_include/links.md
:::
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][InfluxDB]
+
```
+```{div} .clearfix
+```
+
+:::{rubric} About
+:::
[Gradio] is an open source programming framework for quickly creating and sharing
machine learning model demo applications, written in Python.
+::::{dropdown} **Details**
+
- Creating a user interface only requires adding a couple lines of code to your project.
- It does not require any experience with HTML/JS/CSS, or web hosting.
- Gradio can be embedded in Python notebooks, or presented as a web application.
- Once you've created an interface, you can permanently host it on [Hugging Face].
-```{div}
-:style: "clear: both"
+```{div} .clearfix
```
-
+
_How to Build Machine Learning APIs Using Gradio._
+::::
+
+:::{rubric} Learn
+:::
+
+::::{grid} 2
+
+:::{grid-item-card} Example
+:link: https://github.com/crate/cratedb-examples/tree/main/framework/gradio
+:link-type: url
+Example program using Gradio with CrateDB.
+:::
+
+::::
+
[Gradio]: https://www.gradio.app/
[Hugging Face]: https://en.wikipedia.org/wiki/Hugging_Face
diff --git a/docs/integrate/grafana/index.md b/docs/integrate/grafana/index.md
index bf34e025..d33113cc 100644
--- a/docs/integrate/grafana/index.md
+++ b/docs/integrate/grafana/index.md
@@ -1,35 +1,21 @@
(grafana)=
# Grafana
+```{div} .float-right
+[{height=60px loading=lazy}][Grafana OSS]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 1em"
-[{w=180px}](https://grafana.com/grafana/)
-```
-
[Grafana OSS] is the leading open-source metrics visualization tool that helps you
build real-time dashboards, graphs, and many other sorts of data visualizations.
[Grafana Cloud] is a fully-managed service offered by [Grafana Labs].
-Grafana complements CrateDB in monitoring and visualizing large volumes of machine
-data in real-time.
-
-Connecting to a CrateDB cluster will use the Grafana PostgreSQL data source adapter.
-The following tutorials outline how to configure Grafana to connect to CrateDB, and
-how to run a database query.
-
-{h=200px}
-{h=200px}
-
:::{dropdown} **Managed Grafana**
-```{div}
-:style: "float: right"
-[{w=180px}](https://grafana.com/grafana/)
-```
-
Get Grafana fully managed with [Grafana Cloud].
- Offered as a fully managed service, Grafana Cloud is the fastest way to adopt
@@ -38,18 +24,37 @@ Get Grafana fully managed with [Grafana Cloud].
individuals, teams, and large enterprises.
- Includes a robust free tier with access to 10k metrics, 50GB logs, 50GB traces,
50GB profiles, and 500VUh of k6 testing for 3 users.
-
-```{div}
-:style: "clear: both"
-```
:::
:::{rubric} Learn
:::
+::::{grid} 2
+
+:::{grid-item-card} Visualize data with Grafana
+:link: visualize-data-with-grafana
+:link-type: ref
+Grafana complements CrateDB in monitoring and visualizing large volumes of
+machine data in real-time.
+
+Select and import a dataset into CrateDB, connect Grafana to CrateDB,
+and create your first dashboard.
++++
+Connecting to a CrateDB cluster uses the Grafana PostgreSQL data source adapter.
+:::
+
+:::{grid-item}
+{h=200px}
+
+{h=200px}
+:::
+
+::::
+
+
:::{toctree}
:maxdepth: 1
-
+:hidden:
learn
:::
diff --git a/docs/integrate/index.md b/docs/integrate/index.md
index 5198fa3d..cc85f553 100644
--- a/docs/integrate/index.md
+++ b/docs/integrate/index.md
@@ -23,9 +23,9 @@ apache-iceberg/index
apache-kafka/index
apache-nifi/index
apache-superset/index
-aws-dms/index
aws-dynamodb/index
aws-kinesis/index
+aws-dms/index
aws-lambda/index
azure-functions/index
cluvio/index
@@ -40,6 +40,8 @@ gradio/index
grafana/index
influxdb/index
kestra/index
+langchain/index
+llamaindex/index
marquez/index
meltano/index
metabase/index
@@ -48,7 +50,7 @@ mysql/index
n8n/index
node-red/index
plotly/index
-powerbi/index
+Power BI
prometheus/index
pyviz/index
rill/index
diff --git a/docs/integrate/influxdb/index.md b/docs/integrate/influxdb/index.md
index a26c0774..fe19af66 100644
--- a/docs/integrate/influxdb/index.md
+++ b/docs/integrate/influxdb/index.md
@@ -6,6 +6,15 @@
:::{include} /_include/links.md
:::
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][InfluxDB]
+
+
+  +```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
@@ -16,10 +25,43 @@ and time series data. It is ideal for use cases that require real-time ingest an
fast query response times to build user interfaces, monitoring, and automation solutions.
:::
+
+:::{rubric} Synopsis
+:::
+
+```shell
+ctk load table \
+ "influxdb2://example:token@influxdb.example.org:8086/testdrive/demo" \
+ --cratedb-sqlalchemy-url="crate://user:password@cratedb.example.org:4200/testdrive/demo"
+```
+
+That's the blueprint for the InfluxDB URI:
+```text
+"influxdb2://{org}:{token}@influxdb.example.org:8086/{bucket}/{measurement}"
+```
+
:::{rubric} Learn
:::
+::::{grid}
+
+:::{grid-item-card} Tutorial: Import data from InfluxDB
+:link: influxdb-learn
+:link-type: ref
+How to load data from InfluxDB Server and files in InfluxDB line protocol
+format (ILP) into CrateDB.
+:::
+
+:::{grid-item-card} InfluxDB Table Loader
+:link: ctk:influxdb-loader
+:link-type: ref
+Load InfluxDB collections into CrateDB.
+:::
+
+::::
+
:::{toctree}
:maxdepth: 1
+:hidden:
learn
:::
diff --git a/docs/integrate/kestra/index.md b/docs/integrate/kestra/index.md
index f377d28a..1059177f 100644
--- a/docs/integrate/kestra/index.md
+++ b/docs/integrate/kestra/index.md
@@ -1,19 +1,22 @@
(kestra)=
# Kestra
+```{div} .float-right
+[{height=60px loading=lazy}][Kestra]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 2em"
-[{w=180px}](https://kestra.io/)
-```
-
[Kestra] is an open source workflow automation and orchestration toolkit with a rich
plugin ecosystem. It enables users to automate and manage complex workflows in a
streamlined and efficient manner, defining them both declaratively, or imperatively
using any scripting language like Python, Bash, or JavaScript.
+:::{dropdown} **Details**
+
Kestra comes with a user-friendly web-based interface including a live-updating DAG
view, allowing users to create, modify, and manage scheduled and event-driven flows
without the need for any coding skills.
@@ -22,14 +25,25 @@ Plugins are at the core of Kestra's extensibility. Many plugins are available fr
the Kestra core team, and creating your own is easy. With plugins, you can add new
functionality to Kestra.
-{h=120px}
-{h=120px}
-{h=120px}
+{height=120px loading=lazy}
+{height=120px loading=lazy}
+{height=120px loading=lazy}
+:::
+
:::{rubric} Learn
:::
-- [Setting up data pipelines with CrateDB and Kestra]
+::::{grid} 2
+
+:::{grid-item-card} Tutorial: Data pipeline to CrateDB
+:link: https://community.cratedb.com/t/setting-up-data-pipelines-with-cratedb-and-kestra-io/1400
+:link-type: url
+In this tutorial, we will show you how CrateDB integrates with Kestra using the
+PostgreSQL plugin to create an efficient and scalable data pipeline.
+:::
+
+::::
```{seealso}
@@ -37,7 +51,5 @@ functionality to Kestra.
```
-
[CrateDB and Kestra]: https://cratedb.com/integrations/cratedb-and-kestra
[Kestra]: https://kestra.io/
-[Setting up data pipelines with CrateDB and Kestra]: https://community.cratedb.com/t/setting-up-data-pipelines-with-cratedb-and-kestra-io/1400
diff --git a/docs/integrate/langchain/index.md b/docs/integrate/langchain/index.md
index 14e4ef85..f7e34db9 100644
--- a/docs/integrate/langchain/index.md
+++ b/docs/integrate/langchain/index.md
@@ -5,8 +5,8 @@
:::{include} /_include/links.md
:::
-```{div}
-:style: "float: right; font-size: 4em; margin-left: 0.3em"
+```{div} .float-right
+:style: "font-size: 4em; margin-left: 0.3em"
🦜️🔗
```
@@ -42,8 +42,7 @@ build using LLMs:
- [LangChain: Chatbots]
- [LangChain: Q&A with SQL]
-```{div}
-:style: "clear: both"
+```{div} .clearfix
```
diff --git a/docs/integrate/llamaindex/index.md b/docs/integrate/llamaindex/index.md
index 4455ca94..773bace0 100644
--- a/docs/integrate/llamaindex/index.md
+++ b/docs/integrate/llamaindex/index.md
@@ -4,8 +4,15 @@
:::{include} /_include/links.md
:::
-:::{rubric} About
-:::
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][LlamaIndex]
+
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
@@ -16,10 +25,43 @@ and time series data. It is ideal for use cases that require real-time ingest an
fast query response times to build user interfaces, monitoring, and automation solutions.
:::
+
+:::{rubric} Synopsis
+:::
+
+```shell
+ctk load table \
+ "influxdb2://example:token@influxdb.example.org:8086/testdrive/demo" \
+ --cratedb-sqlalchemy-url="crate://user:password@cratedb.example.org:4200/testdrive/demo"
+```
+
+That's the blueprint for the InfluxDB URI:
+```text
+"influxdb2://{org}:{token}@influxdb.example.org:8086/{bucket}/{measurement}"
+```
+
:::{rubric} Learn
:::
+::::{grid}
+
+:::{grid-item-card} Tutorial: Import data from InfluxDB
+:link: influxdb-learn
+:link-type: ref
+How to load data from InfluxDB Server and files in InfluxDB line protocol
+format (ILP) into CrateDB.
+:::
+
+:::{grid-item-card} InfluxDB Table Loader
+:link: ctk:influxdb-loader
+:link-type: ref
+Load InfluxDB collections into CrateDB.
+:::
+
+::::
+
:::{toctree}
:maxdepth: 1
+:hidden:
learn
:::
diff --git a/docs/integrate/kestra/index.md b/docs/integrate/kestra/index.md
index f377d28a..1059177f 100644
--- a/docs/integrate/kestra/index.md
+++ b/docs/integrate/kestra/index.md
@@ -1,19 +1,22 @@
(kestra)=
# Kestra
+```{div} .float-right
+[{height=60px loading=lazy}][Kestra]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 2em"
-[{w=180px}](https://kestra.io/)
-```
-
[Kestra] is an open source workflow automation and orchestration toolkit with a rich
plugin ecosystem. It enables users to automate and manage complex workflows in a
streamlined and efficient manner, defining them both declaratively, or imperatively
using any scripting language like Python, Bash, or JavaScript.
+:::{dropdown} **Details**
+
Kestra comes with a user-friendly web-based interface including a live-updating DAG
view, allowing users to create, modify, and manage scheduled and event-driven flows
without the need for any coding skills.
@@ -22,14 +25,25 @@ Plugins are at the core of Kestra's extensibility. Many plugins are available fr
the Kestra core team, and creating your own is easy. With plugins, you can add new
functionality to Kestra.
-{h=120px}
-{h=120px}
-{h=120px}
+{height=120px loading=lazy}
+{height=120px loading=lazy}
+{height=120px loading=lazy}
+:::
+
:::{rubric} Learn
:::
-- [Setting up data pipelines with CrateDB and Kestra]
+::::{grid} 2
+
+:::{grid-item-card} Tutorial: Data pipeline to CrateDB
+:link: https://community.cratedb.com/t/setting-up-data-pipelines-with-cratedb-and-kestra-io/1400
+:link-type: url
+In this tutorial, we will show you how CrateDB integrates with Kestra using the
+PostgreSQL plugin to create an efficient and scalable data pipeline.
+:::
+
+::::
```{seealso}
@@ -37,7 +51,5 @@ functionality to Kestra.
```
-
[CrateDB and Kestra]: https://cratedb.com/integrations/cratedb-and-kestra
[Kestra]: https://kestra.io/
-[Setting up data pipelines with CrateDB and Kestra]: https://community.cratedb.com/t/setting-up-data-pipelines-with-cratedb-and-kestra-io/1400
diff --git a/docs/integrate/langchain/index.md b/docs/integrate/langchain/index.md
index 14e4ef85..f7e34db9 100644
--- a/docs/integrate/langchain/index.md
+++ b/docs/integrate/langchain/index.md
@@ -5,8 +5,8 @@
:::{include} /_include/links.md
:::
-```{div}
-:style: "float: right; font-size: 4em; margin-left: 0.3em"
+```{div} .float-right
+:style: "font-size: 4em; margin-left: 0.3em"
🦜️🔗
```
@@ -42,8 +42,7 @@ build using LLMs:
- [LangChain: Chatbots]
- [LangChain: Q&A with SQL]
-```{div}
-:style: "clear: both"
+```{div} .clearfix
```
diff --git a/docs/integrate/llamaindex/index.md b/docs/integrate/llamaindex/index.md
index 4455ca94..773bace0 100644
--- a/docs/integrate/llamaindex/index.md
+++ b/docs/integrate/llamaindex/index.md
@@ -4,8 +4,15 @@
:::{include} /_include/links.md
:::
-:::{rubric} About
-:::
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][LlamaIndex]
+
+
+  +```
+```{div} .clearfix
+```
+
[LlamaIndex] is a data framework for Large Language Models (LLMs). It comes with
pre-trained models on massive public datasets such as GPT-4 or Llama 2, and
provides an interface to external data sources allowing for natural language
@@ -84,8 +91,7 @@ print("Answer was:", answer)
**Demo: Using LlamaIndex with OpenAI and CrateDB**
- Connect your CrateDB data to an LLM using OpenAI or Azure OpenAI.
-- Query the database in human language,
- i.e. query CrateDB in plain English.
+- Text-to-SQL / Talk to your data: Query the database in human language; query CrateDB in plain English.
{hyper-tutorial}`[LlamaIndex and CrateDB: Tutorial]`
[][LlamaIndex and CrateDB: Code Examples]
diff --git a/docs/integrate/marquez/data_ingestion.py b/docs/integrate/marquez/data_ingestion.py
new file mode 100644
index 00000000..5ad1499f
--- /dev/null
+++ b/docs/integrate/marquez/data_ingestion.py
@@ -0,0 +1,92 @@
+"""
+Airflow example DAG for reporting lineage to Marquez/OpenLineage while ingesting sample data into CrateDB.
+"""
+from datetime import datetime, timedelta
+
+from airflow.models.dag import DAG
+from airflow.providers.postgres.operators.postgres import SQLExecuteQueryOperator
+
+with DAG(
+ "lineage-reporting-cratedb",
+ start_date=datetime(2024, 6, 28),
+ max_active_runs=1,
+ schedule="@daily",
+ default_args={"retries": 1, "retry_delay": timedelta(minutes=1)},
+ catchup=False,
+):
+
+ ingest_customers = SQLExecuteQueryOperator(
+ task_id="ingest_customers",
+ conn_id="cratedb_default",
+ sql="""
+ INSERT INTO public.Customers (CustomerName,Country)
+ SELECT CONCAT(mountain,' Corp.'), country
+ FROM sys.summits
+ LIMIT 100;
+ """,
+ inlets=[{'namespace': 'example', 'name': 'sampledata'}],
+ outlets=[{'namespace': 'example', 'name': 'customers_table'}]
+ )
+
+ ingest_invoices = SQLExecuteQueryOperator(
+ task_id="ingest_invoices",
+ conn_id="cratedb_default",
+ sql="""
+ INSERT INTO public.Invoices(date,CustomerID)
+ SELECT
+ ('2022-01-01'::TIMESTAMP)+concat(floor(random()*1000),' DAYS')::INTERVAL,
+ (SELECT CustomerID FROM public.Customers ORDER BY random()+a.b LIMIT 1)
+ FROM GENERATE_SERIES(1,1000) a(b);
+ """,
+ inlets=[{'namespace': 'example', 'name': 'customers_table'}],
+ outlets=[{'namespace': 'example', 'name': 'invoices_table'}]
+ )
+
+ ingest_products = SQLExecuteQueryOperator(
+ task_id="ingest_products",
+ conn_id="cratedb_default",
+ sql="""
+ INSERT INTO public.Products(Description,applicable_tax_percentage)
+ SELECT
+ CONCAT('Product ',a.b),
+ (floor(random()*10)+15)/100.0
+ FROM GENERATE_SERIES(1,10) a(b);
+ """,
+ inlets=[{'namespace': 'example', 'name': 'more_sample_data'}],
+ outlets=[{'namespace': 'example', 'name': 'products_table'}]
+ )
+
+ ingest_invoice_items = SQLExecuteQueryOperator(
+ task_id="ingest_invoice_items",
+ conn_id="cratedb_default",
+ sql="""
+ INSERT INTO public.Invoice_items(InvoiceID,ProductID,quantity,unit_price)
+ SELECT InvoiceID, ProductID, 1+ceil(random()*4), random()*1000
+ FROM public.Invoices
+ INNER JOIN public.Products ON random()>0.5;
+ """,
+ inlets=[{'namespace': 'example', 'name': 'invoices_table'},{'namespace': 'example', 'name': 'products_table'}],
+ outlets=[{'namespace': 'example', 'name': 'invoice_items_table'}]
+ )
+
+ refresh_customer_table = SQLExecuteQueryOperator(
+ task_id="refresh_customer_table",
+ conn_id="cratedb_default",
+ sql="REFRESH TABLE public.Customers;",
+ )
+
+ refresh_invoices_table = SQLExecuteQueryOperator(
+ task_id="refresh_invoices_table",
+ conn_id="cratedb_default",
+ sql="REFRESH TABLE public.Invoices;",
+ )
+
+ refresh_products_table = SQLExecuteQueryOperator(
+ task_id="refresh_products_table",
+ conn_id="cratedb_default",
+ sql="REFRESH TABLE public.Products;",
+ )
+
+ ingest_customers >> refresh_customer_table >> ingest_invoices >> refresh_invoices_table
+ refresh_invoices_table >> ingest_invoice_items
+ ingest_products >> refresh_products_table >> ingest_invoice_items
diff --git a/docs/integrate/marquez/index.md b/docs/integrate/marquez/index.md
index 0f0d35be..4af0acab 100644
--- a/docs/integrate/marquez/index.md
+++ b/docs/integrate/marquez/index.md
@@ -4,6 +4,16 @@
:::{include} /_include/links.md
:::
+```{div} .float-right
+[{height=60px loading=lazy}][Marquez]
+```
+```{div} .clearfix
+```
+
+:::{rubric} About
+:::
+
+:::{div}
[OpenLineage] is an open source industry standard framework for data lineage.
It standardizes the definition of data lineage, the metadata that makes up
lineage data, and the approach for collecting lineage data from external systems.
@@ -13,248 +23,28 @@ Among other tools, OpenLineage integrates with [Apache Airflow] to collect
DAG lineage metadata so that inter-DAG dependencies are easily maintained
and viewable via a lineage graph, while also keeping a catalog of historical
runs of DAGs.
+:::
-This tutorial demonstrates how to run Airflow DAGs against a
-CrateDB database and view lineage data.
-
-## Setup
-
-We will need Docker Compose v2, to install it, make it available to all users in the system, check the installed version, or upgrade from v1, please refer to [the Docker documentation on this topic].
-
-Let's now start Marquez:
-
-```bash
-git clone https://github.com/MarquezProject/marquez && cd marquez
-sudo ./docker/up.sh
-```
-
-While Marquez starts, let's open another terminal and proceed installing the Astro CLI for Airflow:
-
-```bash
-curl -sSL install.astronomer.io | sudo bash -s
-```
-
-Let's initialize a project folder:
-
-```bash
-mkdir datalineageeval
-cd datalineageeval
-astro dev init
-```
-
-We will use the PostgreSQL wire protocol to connect to CrateDB:
-
-```bash
-echo 'apache-airflow-providers-postgres' >> requirements.txt
-```
-
-Let's now configure Airflow to use Marquez as the lineage repository and connect to it via the Docker bridge interface:
-
-```bash
-cat <>.env
-OPENLINEAGE_URL=http://172.17.0.1:5000
-OPENLINEAGE_NAMESPACE=example
-EOF
-```
-
-We will use the Airflow web interface, if you are running this on a headless system where you do not have access to a web browser you can run:
-
-```bash
-astro config set airflow.expose_port true
-```
-
-Astro also needs an internal PostgreSQL instance, but port 5432 is taken by Marquez's own internal database, so we will configure Astro to use port 5435 for its internal database:
-
-```bash
-astro config set postgres.port 5435
-sudo astro dev start
-```
-
-And we will start a single-node local CrateDB instance using port 5436 for the PostgreSQL wire protocol interface:
-
-```bash
-sudo docker run -d --name cratedb --publish=4200:4200 --publish=5436:5432 --env CRATE_HEAP_SIZE=1g crate/crate:5.9.5 -Cdiscovery.type=single-node
-```
-
-(NB this will return immediately once the image is downloaded but CrateDB may take a few seconds to start)
-
-
-Let's now use the CrateDB CLI to prepare the tables we will use for this example:
-
-```bash
-sudo apt install python3-pip
-sudo pip install crash
-crash
-```
-
-```sql
-CREATE TABLE public.Customers (
- CustomerID TEXT PRIMARY KEY NOT NULL DEFAULT gen_random_text_uuid()
- ,CustomerName TEXT NOT NULL
- ,Country TEXT
- );
-
-CREATE TABLE public.Invoices (
- InvoiceID TEXT PRIMARY KEY NOT NULL DEFAULT gen_random_text_uuid()
- ,date TIMESTAMP DEFAULT now()
- ,CustomerID TEXT
- );
-
-CREATE TABLE public.Products (
- ProductID TEXT PRIMARY KEY NOT NULL DEFAULT gen_random_text_uuid()
- ,Description TEXT
- ,applicable_tax_percentage REAL
- );
-
-CREATE TABLE public.Invoice_items (
- InvoiceID TEXT
- ,ProductID TEXT
- ,quantity SMALLINT
- ,unit_price REAL
- ,PRIMARY KEY (InvoiceID,ProductID)
- );
-```
-
-Now press Ctrl+D to exit the CrateDB Shell.
-
-## Usage
-
-We are now going to configure Airflow to connect to CrateDB.
-
-Open a web browser and navigate to port 8080 on the machine where you are running Astro, for instance `http://localhost:8080/`.
-Login with username `admin` and password `admin`.
-
-Under "Admin" select "Connections".
-Click the blue plus sign button to create a new connection and enter the following details:
-
-```
-Connection Id: cratedb_default
-Connection Type: Postgres
-Host: 172.17.0.1
-Login: crate
-Port: 5436
-```
-
-Click the Save button.
-
-Now we will create a DAG.
-Let's go back to the `datalineageeval` folder, and run the following:
-
-```bash
-cat <> dags/data_ingestion.py
-```
-
-```python
-from datetime import datetime, timedelta
-
-from airflow.models.dag import DAG
-from airflow.providers.postgres.operators.postgres import SQLExecuteQueryOperator
-
-with DAG(
- "lineage-reporting-cratedb",
- start_date=datetime(2024, 6, 28),
- max_active_runs=1,
- schedule="@daily",
- default_args={"retries": 1, "retry_delay": timedelta(minutes=1)},
- catchup=False,
-):
-
- ingest_customers = SQLExecuteQueryOperator(
- task_id="ingest_customers",
- conn_id="cratedb_default",
- sql="""
- INSERT INTO public.Customers (CustomerName,Country)
- SELECT CONCAT(mountain,' Corp.')
- ,country
- FROM sys.summits
- LIMIT 100;
- """,
- inlets=[{'namespace': 'example', 'name': 'sampledata'}],
- outlets=[{'namespace': 'example', 'name': 'customers_table'}]
- )
-
- ingest_invoices = SQLExecuteQueryOperator(
- task_id="ingest_invoices",
- conn_id="cratedb_default",
- sql="""
- INSERT INTO public.Invoices(date,CustomerID)
- SELECT ('2022-01-01'::TIMESTAMP)+concat(floor(random()*1000),' DAYS')::INTERVAL
- ,(SELECT CustomerID FROM public.Customers ORDER BY random()+a.b LIMIT 1)
- FROM GENERATE_SERIES(1,1000) a(b);
- """,
- inlets=[{'namespace': 'example', 'name': 'customers_table'}],
- outlets=[{'namespace': 'example', 'name': 'invoices_table'}]
- )
-
- ingest_products = SQLExecuteQueryOperator(
- task_id="ingest_products",
- conn_id="cratedb_default",
- sql="""
- INSERT INTO public.Products(Description,applicable_tax_percentage)
- SELECT CONCAT('Product ',a.b)
- ,(floor(random()*10)+15)/100.0
- FROM GENERATE_SERIES(1,10) a(b);
- """,
- inlets=[{'namespace': 'example', 'name': 'more_sample_data'}],
- outlets=[{'namespace': 'example', 'name': 'products_table'}]
- )
-
- ingest_invoice_items = SQLExecuteQueryOperator(
- task_id="ingest_invoice_items",
- conn_id="cratedb_default",
- sql="""
- INSERT INTO public.Invoice_items (InvoiceID,ProductID,quantity,unit_price)
- SELECT InvoiceID,ProductID
- ,1+ceiling(random()*4)
- ,random()*1000
- FROM public.Invoices
- INNER JOIN public.Products ON random()>0.5;
- """,
- inlets=[{'namespace': 'example', 'name': 'invoices_table'},{'namespace': 'example', 'name': 'products_table'}],
- outlets=[{'namespace': 'example', 'name': 'invoice_items_table'}]
- )
-
- refresh_customer_table = SQLExecuteQueryOperator(
- task_id="refresh_customer_table",
- conn_id="cratedb_default",
- sql="REFRESH TABLE public.Customers;",
- )
-
- refresh_invoices_table = SQLExecuteQueryOperator(
- task_id="refresh_invoices_table",
- conn_id="cratedb_default",
- sql="REFRESH TABLE public.Invoices;",
- )
-
- refresh_products_table = SQLExecuteQueryOperator(
- task_id="refresh_products_table",
- conn_id="cratedb_default",
- sql="REFRESH TABLE public.Products;",
- )
-
- ingest_customers >> refresh_customer_table >> ingest_invoices >> refresh_invoices_table
- refresh_invoices_table >> ingest_invoice_items
- ingest_products >> refresh_products_table >> ingest_invoice_items
-```
-
-```bash
-EOF
-sudo astro dev restart
-```
-
-Let's now go back to the Airflow web interface, navigate to "DAGs" on the top left corner, then identify the new `lineage-reporting-cratedb` DAG and use the "play" button to execute it.
-When the execution of the DAG completes, "Recent Tasks" should show 7 tasks with success status.
+:::{rubric} Learn
+:::
-Let's now navigate to the Marquez web interface at http://localhost:3000/ (replace localhost with the appropriate hostname if this is not running locally).
+::::{grid} 2
-On the upper right corner, select `example` instead of `default`.
+:::{grid-item-card} Tutorial: Use Marquez with CrateDB
+:link: marquez-learn
+:link-type: ref
+Demonstrate how to run Airflow DAGs against a
+CrateDB database and view lineage data in Marquez.
+:::
-You can now see all lineage graphs and events for this setup.
+::::
-{h=180px}
+:::{toctree}
+:hidden:
+learn
+:::
-[Marquez]: https://github.com/MarquezProject/marquez
+[Marquez]: https://marquezproject.ai/
[OpenLineage]: https://openlineage.io/
-[the Docker documentation on this topic]: https://docs.docker.com/compose/install/linux/
diff --git a/docs/integrate/marquez/learn.md b/docs/integrate/marquez/learn.md
new file mode 100644
index 00000000..63449015
--- /dev/null
+++ b/docs/integrate/marquez/learn.md
@@ -0,0 +1,164 @@
+(marquez-learn)=
+# Use Marquez with CrateDB
+
+This tutorial demonstrates how to run Airflow DAGs against a
+CrateDB database and view lineage data.
+
+## Setup
+
+We will need Docker Compose v2. To install it, make it available to all users,
+check the installed version, or upgrade from v1, refer to
+[the Docker documentation](https://docs.docker.com/compose/migrate/).
+
+Let's now start Marquez:
+
+```bash
+git clone https://github.com/MarquezProject/marquez && cd marquez
+sudo ./docker/up.sh
+```
+
+While Marquez starts, let's open another terminal and proceed installing the Astro CLI for Airflow:
+
+```bash
+curl -sSL https://install.astronomer.io | sudo bash -s
+```
+
+Let's initialize a project folder:
+
+```bash
+mkdir datalineageeval
+cd datalineageeval
+astro dev init
+```
+
+We will use the PostgreSQL wire protocol to connect to CrateDB:
+
+```bash
+echo 'apache-airflow-providers-postgres' >> requirements.txt
+```
+
+Let's now configure Airflow to use Marquez as the lineage repository and connect to it via the Docker bridge interface:
+
+```bash
+cat <>.env
+# Linux (Docker bridge):
+OPENLINEAGE_URL=http://172.17.0.1:5000
+# macOS/Windows (Docker Desktop):
+# OPENLINEAGE_URL=http://host.docker.internal:5000
+OPENLINEAGE_NAMESPACE=example
+EOF
+```
+
+We will use the Airflow web interface. If you are running headless (no local browser), enable port exposure:
+
+```bash
+astro config set airflow.expose_port true
+```
+
+Astro also needs an internal PostgreSQL instance, but port 5432 is taken by Marquez's own internal database, so we will configure Astro to use port 5435 for its internal database:
+
+```bash
+astro config set postgres.port 5435
+astro dev start
+```
+
+And we will start a single-node local CrateDB instance using port 5436 for the PostgreSQL wire protocol interface:
+
+```bash
+sudo docker run -d --name cratedb --publish=4200:4200 --publish=5436:5432 --env CRATE_HEAP_SIZE=1g crate/crate:5.9.5 -Cdiscovery.type=single-node
+```
+
+(NB this will return immediately once the image is downloaded but CrateDB may take a few seconds to start)
+
+
+Let's now use the CrateDB CLI to prepare the tables we will use for this example:
+
+Install `crash` using `pip`.
+```bash
+sudo apt install -y python3-pip
+sudo pip3 install --user crash
+crash
+```
+
+Alternatively, install `crash` using `pipx`.
+```bash
+sudo apt install -y pipx
+sudo pipx install crash
+```
+
+Connect using `crash`.
+```bash
+crash
+```
+
+```sql
+CREATE TABLE public.Customers (
+ CustomerID TEXT PRIMARY KEY NOT NULL DEFAULT gen_random_text_uuid(),
+ CustomerName TEXT NOT NULL,
+ Country TEXT
+);
+
+CREATE TABLE public.Invoices (
+ InvoiceID TEXT PRIMARY KEY NOT NULL DEFAULT gen_random_text_uuid(),
+ date TIMESTAMP DEFAULT now(),
+ CustomerID TEXT
+);
+
+CREATE TABLE public.Products (
+ ProductID TEXT PRIMARY KEY NOT NULL DEFAULT gen_random_text_uuid(),
+ Description TEXT,
+ applicable_tax_percentage REAL
+);
+
+CREATE TABLE public.Invoice_items (
+ InvoiceID TEXT,
+ ProductID TEXT,
+ quantity SMALLINT,
+ unit_price REAL,
+ PRIMARY KEY (InvoiceID,ProductID)
+);
+```
+
+Now press Ctrl+D to exit the CrateDB Shell.
+
+## Usage
+
+We are now going to configure Airflow to connect to CrateDB.
+
+Open a web browser and navigate to port 8080 on the machine where you are running Astro, for instance `http://localhost:8080/`.
+Login with username `admin` and password `admin`.
+
+Under "Admin" select "Connections".
+Click the blue plus sign button to create a new connection and enter the following details:
+
+```text
+Connection Id: cratedb_default
+Connection Type: Postgres
+Host: 172.17.0.1
+Login: crate
+Port: 5436
+```
+
+Click the Save button.
+
+Now we will create a DAG. From the `datalineageeval` folder, run:
+```bash
+cp data_ingestion.py dags/
+```
+
+Then, restart Airflow.
+```bash
+sudo astro dev restart
+```
+
+Let's now go back to the Airflow web interface, navigate to "DAGs" on the top left corner, then identify the new `lineage-reporting-cratedb` DAG and use the "play" button to execute it.
+
+When the DAG completes, "Recent Tasks" should show 7 successful tasks.
+
+Now navigate to the Marquez web interface at (replace localhost if this is not running locally).
+
+In the upper right corner, select `example` instead of `default`.
+
+You can now see all lineage graphs and events for this setup.
+
+{h=180px}
diff --git a/docs/integrate/meltano/index.md b/docs/integrate/meltano/index.md
index 893c0114..50ea4acd 100644
--- a/docs/integrate/meltano/index.md
+++ b/docs/integrate/meltano/index.md
@@ -1,47 +1,56 @@
(meltano)=
# Meltano
-:::{rubric} About
-:::
+```{div} .float-right
+[{w=180px}][Singer]
-```{div}
-:style: "float: right; margin-left: 0.3em"
-[{w=180px}](https://www.singer.io/)
-
-[{w=180px}](https://meltano.com/)
+[{w=180px}][Meltano]
+```
+```{div} .clearfix
```
+:::{rubric} About
+:::
+
[Meltano] is a declarative code-first data integration engine adhering to the Singer
specification.
[Singer] is a composable open source ETL framework and specification, including
powerful data extraction and consolidation elements.
-
[Meltano Hub] is the single source of truth to find any Meltano plugins as well
as Singer taps and targets.
-```{div}
-:style: "clear: both"
-```
:::{rubric} Learn
:::
-- [Examples about working with CrateDB and Meltano]
+::::{grid}
+
+:::{grid-item-card} Examples
+:link: https://github.com/crate/cratedb-examples/tree/amo/meltano/framework/singer-meltano
+:link-type: url
+Examples about working with CrateDB and Meltano.
+:::
-:::{rubric} Resources
+:::{grid-item-card} meltano-tap-cratedb
+:link: https://github.com/crate-workbench/meltano-tap-cratedb
+:link-type: url
+A Singer tap / Meltano extractor for CrateDB.
:::
-- [meltano-tap-cratedb]
-- [meltano-target-cratedb]
+:::{grid-item-card} meltano-target-cratedb
+:link: https://github.com/crate-workbench/meltano-target-cratedb
+:link-type: url
+A Singer target / Meltano loader for CrateDB.
+:::
+
+::::
+
:::{todo}
-🚧 These adapters are a work in progress. 🚧
+🚧 These adapters are a work in progress, contributions and interest are welcome. 🚧
:::
-[Examples about working with CrateDB and Meltano]: https://github.com/crate/cratedb-examples/tree/amo/meltano/framework/singer-meltano
[Meltano]: https://meltano.com/
[Meltano Hub]: https://hub.meltano.com/
-[meltano-tap-cratedb]: https://github.com/crate-workbench/meltano-tap-cratedb
-[meltano-target-cratedb]: https://github.com/crate-workbench/meltano-target-cratedb
[Singer]: https://www.singer.io/
diff --git a/docs/integrate/metabase/index.md b/docs/integrate/metabase/index.md
index 2563a645..bc9d1a8f 100644
--- a/docs/integrate/metabase/index.md
+++ b/docs/integrate/metabase/index.md
@@ -1,56 +1,74 @@
(metabase)=
# Metabase
-```{div}
-:style: "float: right; margin-left: 1em"
-[{w=180px}](https://www.metabase.com/cloud/)
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][Metabase]
+
+```
+```{div} .clearfix
+```
+
[LlamaIndex] is a data framework for Large Language Models (LLMs). It comes with
pre-trained models on massive public datasets such as GPT-4 or Llama 2, and
provides an interface to external data sources allowing for natural language
@@ -84,8 +91,7 @@ print("Answer was:", answer)
**Demo: Using LlamaIndex with OpenAI and CrateDB**
- Connect your CrateDB data to an LLM using OpenAI or Azure OpenAI.
-- Query the database in human language,
- i.e. query CrateDB in plain English.
+- Text-to-SQL / Talk to your data: Query the database in human language; query CrateDB in plain English.
{hyper-tutorial}`[LlamaIndex and CrateDB: Tutorial]`
[][LlamaIndex and CrateDB: Code Examples]
diff --git a/docs/integrate/marquez/data_ingestion.py b/docs/integrate/marquez/data_ingestion.py
new file mode 100644
index 00000000..5ad1499f
--- /dev/null
+++ b/docs/integrate/marquez/data_ingestion.py
@@ -0,0 +1,92 @@
+"""
+Airflow example DAG for reporting lineage to Marquez/OpenLineage while ingesting sample data into CrateDB.
+"""
+from datetime import datetime, timedelta
+
+from airflow.models.dag import DAG
+from airflow.providers.postgres.operators.postgres import SQLExecuteQueryOperator
+
+with DAG(
+ "lineage-reporting-cratedb",
+ start_date=datetime(2024, 6, 28),
+ max_active_runs=1,
+ schedule="@daily",
+ default_args={"retries": 1, "retry_delay": timedelta(minutes=1)},
+ catchup=False,
+):
+
+ ingest_customers = SQLExecuteQueryOperator(
+ task_id="ingest_customers",
+ conn_id="cratedb_default",
+ sql="""
+ INSERT INTO public.Customers (CustomerName,Country)
+ SELECT CONCAT(mountain,' Corp.'), country
+ FROM sys.summits
+ LIMIT 100;
+ """,
+ inlets=[{'namespace': 'example', 'name': 'sampledata'}],
+ outlets=[{'namespace': 'example', 'name': 'customers_table'}]
+ )
+
+ ingest_invoices = SQLExecuteQueryOperator(
+ task_id="ingest_invoices",
+ conn_id="cratedb_default",
+ sql="""
+ INSERT INTO public.Invoices(date,CustomerID)
+ SELECT
+ ('2022-01-01'::TIMESTAMP)+concat(floor(random()*1000),' DAYS')::INTERVAL,
+ (SELECT CustomerID FROM public.Customers ORDER BY random()+a.b LIMIT 1)
+ FROM GENERATE_SERIES(1,1000) a(b);
+ """,
+ inlets=[{'namespace': 'example', 'name': 'customers_table'}],
+ outlets=[{'namespace': 'example', 'name': 'invoices_table'}]
+ )
+
+ ingest_products = SQLExecuteQueryOperator(
+ task_id="ingest_products",
+ conn_id="cratedb_default",
+ sql="""
+ INSERT INTO public.Products(Description,applicable_tax_percentage)
+ SELECT
+ CONCAT('Product ',a.b),
+ (floor(random()*10)+15)/100.0
+ FROM GENERATE_SERIES(1,10) a(b);
+ """,
+ inlets=[{'namespace': 'example', 'name': 'more_sample_data'}],
+ outlets=[{'namespace': 'example', 'name': 'products_table'}]
+ )
+
+ ingest_invoice_items = SQLExecuteQueryOperator(
+ task_id="ingest_invoice_items",
+ conn_id="cratedb_default",
+ sql="""
+ INSERT INTO public.Invoice_items(InvoiceID,ProductID,quantity,unit_price)
+ SELECT InvoiceID, ProductID, 1+ceil(random()*4), random()*1000
+ FROM public.Invoices
+ INNER JOIN public.Products ON random()>0.5;
+ """,
+ inlets=[{'namespace': 'example', 'name': 'invoices_table'},{'namespace': 'example', 'name': 'products_table'}],
+ outlets=[{'namespace': 'example', 'name': 'invoice_items_table'}]
+ )
+
+ refresh_customer_table = SQLExecuteQueryOperator(
+ task_id="refresh_customer_table",
+ conn_id="cratedb_default",
+ sql="REFRESH TABLE public.Customers;",
+ )
+
+ refresh_invoices_table = SQLExecuteQueryOperator(
+ task_id="refresh_invoices_table",
+ conn_id="cratedb_default",
+ sql="REFRESH TABLE public.Invoices;",
+ )
+
+ refresh_products_table = SQLExecuteQueryOperator(
+ task_id="refresh_products_table",
+ conn_id="cratedb_default",
+ sql="REFRESH TABLE public.Products;",
+ )
+
+ ingest_customers >> refresh_customer_table >> ingest_invoices >> refresh_invoices_table
+ refresh_invoices_table >> ingest_invoice_items
+ ingest_products >> refresh_products_table >> ingest_invoice_items
diff --git a/docs/integrate/marquez/index.md b/docs/integrate/marquez/index.md
index 0f0d35be..4af0acab 100644
--- a/docs/integrate/marquez/index.md
+++ b/docs/integrate/marquez/index.md
@@ -4,6 +4,16 @@
:::{include} /_include/links.md
:::
+```{div} .float-right
+[{height=60px loading=lazy}][Marquez]
+```
+```{div} .clearfix
+```
+
+:::{rubric} About
+:::
+
+:::{div}
[OpenLineage] is an open source industry standard framework for data lineage.
It standardizes the definition of data lineage, the metadata that makes up
lineage data, and the approach for collecting lineage data from external systems.
@@ -13,248 +23,28 @@ Among other tools, OpenLineage integrates with [Apache Airflow] to collect
DAG lineage metadata so that inter-DAG dependencies are easily maintained
and viewable via a lineage graph, while also keeping a catalog of historical
runs of DAGs.
+:::
-This tutorial demonstrates how to run Airflow DAGs against a
-CrateDB database and view lineage data.
-
-## Setup
-
-We will need Docker Compose v2, to install it, make it available to all users in the system, check the installed version, or upgrade from v1, please refer to [the Docker documentation on this topic].
-
-Let's now start Marquez:
-
-```bash
-git clone https://github.com/MarquezProject/marquez && cd marquez
-sudo ./docker/up.sh
-```
-
-While Marquez starts, let's open another terminal and proceed installing the Astro CLI for Airflow:
-
-```bash
-curl -sSL install.astronomer.io | sudo bash -s
-```
-
-Let's initialize a project folder:
-
-```bash
-mkdir datalineageeval
-cd datalineageeval
-astro dev init
-```
-
-We will use the PostgreSQL wire protocol to connect to CrateDB:
-
-```bash
-echo 'apache-airflow-providers-postgres' >> requirements.txt
-```
-
-Let's now configure Airflow to use Marquez as the lineage repository and connect to it via the Docker bridge interface:
-
-```bash
-cat <>.env
-OPENLINEAGE_URL=http://172.17.0.1:5000
-OPENLINEAGE_NAMESPACE=example
-EOF
-```
-
-We will use the Airflow web interface, if you are running this on a headless system where you do not have access to a web browser you can run:
-
-```bash
-astro config set airflow.expose_port true
-```
-
-Astro also needs an internal PostgreSQL instance, but port 5432 is taken by Marquez's own internal database, so we will configure Astro to use port 5435 for its internal database:
-
-```bash
-astro config set postgres.port 5435
-sudo astro dev start
-```
-
-And we will start a single-node local CrateDB instance using port 5436 for the PostgreSQL wire protocol interface:
-
-```bash
-sudo docker run -d --name cratedb --publish=4200:4200 --publish=5436:5432 --env CRATE_HEAP_SIZE=1g crate/crate:5.9.5 -Cdiscovery.type=single-node
-```
-
-(NB this will return immediately once the image is downloaded but CrateDB may take a few seconds to start)
-
-
-Let's now use the CrateDB CLI to prepare the tables we will use for this example:
-
-```bash
-sudo apt install python3-pip
-sudo pip install crash
-crash
-```
-
-```sql
-CREATE TABLE public.Customers (
- CustomerID TEXT PRIMARY KEY NOT NULL DEFAULT gen_random_text_uuid()
- ,CustomerName TEXT NOT NULL
- ,Country TEXT
- );
-
-CREATE TABLE public.Invoices (
- InvoiceID TEXT PRIMARY KEY NOT NULL DEFAULT gen_random_text_uuid()
- ,date TIMESTAMP DEFAULT now()
- ,CustomerID TEXT
- );
-
-CREATE TABLE public.Products (
- ProductID TEXT PRIMARY KEY NOT NULL DEFAULT gen_random_text_uuid()
- ,Description TEXT
- ,applicable_tax_percentage REAL
- );
-
-CREATE TABLE public.Invoice_items (
- InvoiceID TEXT
- ,ProductID TEXT
- ,quantity SMALLINT
- ,unit_price REAL
- ,PRIMARY KEY (InvoiceID,ProductID)
- );
-```
-
-Now press Ctrl+D to exit the CrateDB Shell.
-
-## Usage
-
-We are now going to configure Airflow to connect to CrateDB.
-
-Open a web browser and navigate to port 8080 on the machine where you are running Astro, for instance `http://localhost:8080/`.
-Login with username `admin` and password `admin`.
-
-Under "Admin" select "Connections".
-Click the blue plus sign button to create a new connection and enter the following details:
-
-```
-Connection Id: cratedb_default
-Connection Type: Postgres
-Host: 172.17.0.1
-Login: crate
-Port: 5436
-```
-
-Click the Save button.
-
-Now we will create a DAG.
-Let's go back to the `datalineageeval` folder, and run the following:
-
-```bash
-cat <> dags/data_ingestion.py
-```
-
-```python
-from datetime import datetime, timedelta
-
-from airflow.models.dag import DAG
-from airflow.providers.postgres.operators.postgres import SQLExecuteQueryOperator
-
-with DAG(
- "lineage-reporting-cratedb",
- start_date=datetime(2024, 6, 28),
- max_active_runs=1,
- schedule="@daily",
- default_args={"retries": 1, "retry_delay": timedelta(minutes=1)},
- catchup=False,
-):
-
- ingest_customers = SQLExecuteQueryOperator(
- task_id="ingest_customers",
- conn_id="cratedb_default",
- sql="""
- INSERT INTO public.Customers (CustomerName,Country)
- SELECT CONCAT(mountain,' Corp.')
- ,country
- FROM sys.summits
- LIMIT 100;
- """,
- inlets=[{'namespace': 'example', 'name': 'sampledata'}],
- outlets=[{'namespace': 'example', 'name': 'customers_table'}]
- )
-
- ingest_invoices = SQLExecuteQueryOperator(
- task_id="ingest_invoices",
- conn_id="cratedb_default",
- sql="""
- INSERT INTO public.Invoices(date,CustomerID)
- SELECT ('2022-01-01'::TIMESTAMP)+concat(floor(random()*1000),' DAYS')::INTERVAL
- ,(SELECT CustomerID FROM public.Customers ORDER BY random()+a.b LIMIT 1)
- FROM GENERATE_SERIES(1,1000) a(b);
- """,
- inlets=[{'namespace': 'example', 'name': 'customers_table'}],
- outlets=[{'namespace': 'example', 'name': 'invoices_table'}]
- )
-
- ingest_products = SQLExecuteQueryOperator(
- task_id="ingest_products",
- conn_id="cratedb_default",
- sql="""
- INSERT INTO public.Products(Description,applicable_tax_percentage)
- SELECT CONCAT('Product ',a.b)
- ,(floor(random()*10)+15)/100.0
- FROM GENERATE_SERIES(1,10) a(b);
- """,
- inlets=[{'namespace': 'example', 'name': 'more_sample_data'}],
- outlets=[{'namespace': 'example', 'name': 'products_table'}]
- )
-
- ingest_invoice_items = SQLExecuteQueryOperator(
- task_id="ingest_invoice_items",
- conn_id="cratedb_default",
- sql="""
- INSERT INTO public.Invoice_items (InvoiceID,ProductID,quantity,unit_price)
- SELECT InvoiceID,ProductID
- ,1+ceiling(random()*4)
- ,random()*1000
- FROM public.Invoices
- INNER JOIN public.Products ON random()>0.5;
- """,
- inlets=[{'namespace': 'example', 'name': 'invoices_table'},{'namespace': 'example', 'name': 'products_table'}],
- outlets=[{'namespace': 'example', 'name': 'invoice_items_table'}]
- )
-
- refresh_customer_table = SQLExecuteQueryOperator(
- task_id="refresh_customer_table",
- conn_id="cratedb_default",
- sql="REFRESH TABLE public.Customers;",
- )
-
- refresh_invoices_table = SQLExecuteQueryOperator(
- task_id="refresh_invoices_table",
- conn_id="cratedb_default",
- sql="REFRESH TABLE public.Invoices;",
- )
-
- refresh_products_table = SQLExecuteQueryOperator(
- task_id="refresh_products_table",
- conn_id="cratedb_default",
- sql="REFRESH TABLE public.Products;",
- )
-
- ingest_customers >> refresh_customer_table >> ingest_invoices >> refresh_invoices_table
- refresh_invoices_table >> ingest_invoice_items
- ingest_products >> refresh_products_table >> ingest_invoice_items
-```
-
-```bash
-EOF
-sudo astro dev restart
-```
-
-Let's now go back to the Airflow web interface, navigate to "DAGs" on the top left corner, then identify the new `lineage-reporting-cratedb` DAG and use the "play" button to execute it.
-When the execution of the DAG completes, "Recent Tasks" should show 7 tasks with success status.
+:::{rubric} Learn
+:::
-Let's now navigate to the Marquez web interface at http://localhost:3000/ (replace localhost with the appropriate hostname if this is not running locally).
+::::{grid} 2
-On the upper right corner, select `example` instead of `default`.
+:::{grid-item-card} Tutorial: Use Marquez with CrateDB
+:link: marquez-learn
+:link-type: ref
+Demonstrate how to run Airflow DAGs against a
+CrateDB database and view lineage data in Marquez.
+:::
-You can now see all lineage graphs and events for this setup.
+::::
-{h=180px}
+:::{toctree}
+:hidden:
+learn
+:::
-[Marquez]: https://github.com/MarquezProject/marquez
+[Marquez]: https://marquezproject.ai/
[OpenLineage]: https://openlineage.io/
-[the Docker documentation on this topic]: https://docs.docker.com/compose/install/linux/
diff --git a/docs/integrate/marquez/learn.md b/docs/integrate/marquez/learn.md
new file mode 100644
index 00000000..63449015
--- /dev/null
+++ b/docs/integrate/marquez/learn.md
@@ -0,0 +1,164 @@
+(marquez-learn)=
+# Use Marquez with CrateDB
+
+This tutorial demonstrates how to run Airflow DAGs against a
+CrateDB database and view lineage data.
+
+## Setup
+
+We will need Docker Compose v2. To install it, make it available to all users,
+check the installed version, or upgrade from v1, refer to
+[the Docker documentation](https://docs.docker.com/compose/migrate/).
+
+Let's now start Marquez:
+
+```bash
+git clone https://github.com/MarquezProject/marquez && cd marquez
+sudo ./docker/up.sh
+```
+
+While Marquez starts, let's open another terminal and proceed installing the Astro CLI for Airflow:
+
+```bash
+curl -sSL https://install.astronomer.io | sudo bash -s
+```
+
+Let's initialize a project folder:
+
+```bash
+mkdir datalineageeval
+cd datalineageeval
+astro dev init
+```
+
+We will use the PostgreSQL wire protocol to connect to CrateDB:
+
+```bash
+echo 'apache-airflow-providers-postgres' >> requirements.txt
+```
+
+Let's now configure Airflow to use Marquez as the lineage repository and connect to it via the Docker bridge interface:
+
+```bash
+cat <>.env
+# Linux (Docker bridge):
+OPENLINEAGE_URL=http://172.17.0.1:5000
+# macOS/Windows (Docker Desktop):
+# OPENLINEAGE_URL=http://host.docker.internal:5000
+OPENLINEAGE_NAMESPACE=example
+EOF
+```
+
+We will use the Airflow web interface. If you are running headless (no local browser), enable port exposure:
+
+```bash
+astro config set airflow.expose_port true
+```
+
+Astro also needs an internal PostgreSQL instance, but port 5432 is taken by Marquez's own internal database, so we will configure Astro to use port 5435 for its internal database:
+
+```bash
+astro config set postgres.port 5435
+astro dev start
+```
+
+And we will start a single-node local CrateDB instance using port 5436 for the PostgreSQL wire protocol interface:
+
+```bash
+sudo docker run -d --name cratedb --publish=4200:4200 --publish=5436:5432 --env CRATE_HEAP_SIZE=1g crate/crate:5.9.5 -Cdiscovery.type=single-node
+```
+
+(NB this will return immediately once the image is downloaded but CrateDB may take a few seconds to start)
+
+
+Let's now use the CrateDB CLI to prepare the tables we will use for this example:
+
+Install `crash` using `pip`.
+```bash
+sudo apt install -y python3-pip
+sudo pip3 install --user crash
+crash
+```
+
+Alternatively, install `crash` using `pipx`.
+```bash
+sudo apt install -y pipx
+sudo pipx install crash
+```
+
+Connect using `crash`.
+```bash
+crash
+```
+
+```sql
+CREATE TABLE public.Customers (
+ CustomerID TEXT PRIMARY KEY NOT NULL DEFAULT gen_random_text_uuid(),
+ CustomerName TEXT NOT NULL,
+ Country TEXT
+);
+
+CREATE TABLE public.Invoices (
+ InvoiceID TEXT PRIMARY KEY NOT NULL DEFAULT gen_random_text_uuid(),
+ date TIMESTAMP DEFAULT now(),
+ CustomerID TEXT
+);
+
+CREATE TABLE public.Products (
+ ProductID TEXT PRIMARY KEY NOT NULL DEFAULT gen_random_text_uuid(),
+ Description TEXT,
+ applicable_tax_percentage REAL
+);
+
+CREATE TABLE public.Invoice_items (
+ InvoiceID TEXT,
+ ProductID TEXT,
+ quantity SMALLINT,
+ unit_price REAL,
+ PRIMARY KEY (InvoiceID,ProductID)
+);
+```
+
+Now press Ctrl+D to exit the CrateDB Shell.
+
+## Usage
+
+We are now going to configure Airflow to connect to CrateDB.
+
+Open a web browser and navigate to port 8080 on the machine where you are running Astro, for instance `http://localhost:8080/`.
+Login with username `admin` and password `admin`.
+
+Under "Admin" select "Connections".
+Click the blue plus sign button to create a new connection and enter the following details:
+
+```text
+Connection Id: cratedb_default
+Connection Type: Postgres
+Host: 172.17.0.1
+Login: crate
+Port: 5436
+```
+
+Click the Save button.
+
+Now we will create a DAG. From the `datalineageeval` folder, run:
+```bash
+cp data_ingestion.py dags/
+```
+
+Then, restart Airflow.
+```bash
+sudo astro dev restart
+```
+
+Let's now go back to the Airflow web interface, navigate to "DAGs" on the top left corner, then identify the new `lineage-reporting-cratedb` DAG and use the "play" button to execute it.
+
+When the DAG completes, "Recent Tasks" should show 7 successful tasks.
+
+Now navigate to the Marquez web interface at (replace localhost if this is not running locally).
+
+In the upper right corner, select `example` instead of `default`.
+
+You can now see all lineage graphs and events for this setup.
+
+{h=180px}
diff --git a/docs/integrate/meltano/index.md b/docs/integrate/meltano/index.md
index 893c0114..50ea4acd 100644
--- a/docs/integrate/meltano/index.md
+++ b/docs/integrate/meltano/index.md
@@ -1,47 +1,56 @@
(meltano)=
# Meltano
-:::{rubric} About
-:::
+```{div} .float-right
+[{w=180px}][Singer]
-```{div}
-:style: "float: right; margin-left: 0.3em"
-[{w=180px}](https://www.singer.io/)
-
-[{w=180px}](https://meltano.com/)
+[{w=180px}][Meltano]
+```
+```{div} .clearfix
```
+:::{rubric} About
+:::
+
[Meltano] is a declarative code-first data integration engine adhering to the Singer
specification.
[Singer] is a composable open source ETL framework and specification, including
powerful data extraction and consolidation elements.
-
[Meltano Hub] is the single source of truth to find any Meltano plugins as well
as Singer taps and targets.
-```{div}
-:style: "clear: both"
-```
:::{rubric} Learn
:::
-- [Examples about working with CrateDB and Meltano]
+::::{grid}
+
+:::{grid-item-card} Examples
+:link: https://github.com/crate/cratedb-examples/tree/amo/meltano/framework/singer-meltano
+:link-type: url
+Examples about working with CrateDB and Meltano.
+:::
-:::{rubric} Resources
+:::{grid-item-card} meltano-tap-cratedb
+:link: https://github.com/crate-workbench/meltano-tap-cratedb
+:link-type: url
+A Singer tap / Meltano extractor for CrateDB.
:::
-- [meltano-tap-cratedb]
-- [meltano-target-cratedb]
+:::{grid-item-card} meltano-target-cratedb
+:link: https://github.com/crate-workbench/meltano-target-cratedb
+:link-type: url
+A Singer target / Meltano loader for CrateDB.
+:::
+
+::::
+
:::{todo}
-🚧 These adapters are a work in progress. 🚧
+🚧 These adapters are a work in progress, contributions and interest are welcome. 🚧
:::
-[Examples about working with CrateDB and Meltano]: https://github.com/crate/cratedb-examples/tree/amo/meltano/framework/singer-meltano
[Meltano]: https://meltano.com/
[Meltano Hub]: https://hub.meltano.com/
-[meltano-tap-cratedb]: https://github.com/crate-workbench/meltano-tap-cratedb
-[meltano-target-cratedb]: https://github.com/crate-workbench/meltano-target-cratedb
[Singer]: https://www.singer.io/
diff --git a/docs/integrate/metabase/index.md b/docs/integrate/metabase/index.md
index 2563a645..bc9d1a8f 100644
--- a/docs/integrate/metabase/index.md
+++ b/docs/integrate/metabase/index.md
@@ -1,56 +1,74 @@
(metabase)=
# Metabase
-```{div}
-:style: "float: right; margin-left: 1em"
-[{w=180px}](https://www.metabase.com/cloud/)
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][Metabase]
+
+
+  ```
+```{div} .clearfix
+```
+
+:::{rubric} About
+:::
[Metabase] is the ultimate data analysis and visualization tool that unlocks the full
potential of your data. Built for data and made for everyone, Metabase can be leveraged
with no SQL required.
+:::{dropdown} **Details**
+
Fast analytics with the friendly UX and integrated tooling to let your company explore
data on their own.
-{h=140px}
-{h=140px}
-
+{h=140px}
+{h=140px}
+:::
:::{dropdown} **Managed Metabase**
-```{div}
-:style: "float: right"
-[{w=180px}](https://www.metabase.com/)
-```
With [Metabase Cloud], you will get a fast, reliable, and secure deployment
with none of the work or hidden costs that come with self-hosting.
-- **Save the time** needed for setup and maintenance of the platform, focusing only on the insights we can get from our data.
+- **Save time** on setup and maintenance; focus on the insights from your data.
- **Trustworthy, production-grade deployment** by people who do this stuff for a living.
With the infrastructure, specialists, and thousands of Metabases in our cloud, we've put a lot of thought and resources into optimizing hosting.
- **Upgrades:** Automatically upgrade to the current version, so you're always getting the latest and greatest of Metabase.
- **Backups:** The way they should be: there when you need them, out of sight and out of mind when you don't.
-- **SMTP server:** Even your alerts and dashboard subscriptions covered with a preconfigured and managed SMTP server.
+- **SMTP server:** Alerts and dashboard subscriptions are covered via a preconfigured and managed SMTP server.
-
-```{div}
-:style: "clear: both"
-```
:::
:::{rubric} Learn
:::
-- {ref}`integrations-metabase`
-- [Real-time data analytics with Metabase and CrateDB]
-- https://github.com/paoliniluis/metabase-cratedb
+::::{grid}
+
+:::{grid-item-card} Tutorial: Visualize data
+:link: integrations-metabase
+:link-type: ref
+Visualize data with CrateDB and Metabase.
+:::
+
+:::{grid-item-card} Blog: Real-time data analytics
+:link: https://www.metabase.com/community_posts/real-time-data-analytics-with-metabase-and-cratedb
+:link-type: url
+Real-time data analytics with Metabase and CrateDB.
+:::
+
+:::{grid-item-card} Demo: "metabase-cratedb"
+:link: https://github.com/paoliniluis/metabase-cratedb
+:link-type: url
+A fully working demo of Metabase connected to CrateDB.
+:::
+
+::::
:::{toctree}
:maxdepth: 1
:hidden:
-
learn
:::
@@ -62,5 +80,3 @@ learn
[CrateDB and Metabase]: https://cratedb.com/integrations/cratedb-and-metabase
[Metabase]: https://www.metabase.com/
[Metabase Cloud]: https://www.metabase.com/cloud/
-[Real-time data analytics with Metabase and CrateDB]: https://www.metabase.com/community_posts/real-time-data-analytics-with-metabase-and-cratedb
-[Using Metabase with CrateDB Cloud]: #integrations-metabase
diff --git a/docs/integrate/mongodb/index.md b/docs/integrate/mongodb/index.md
index 9f68789c..eb243dcf 100644
--- a/docs/integrate/mongodb/index.md
+++ b/docs/integrate/mongodb/index.md
@@ -4,6 +4,21 @@
:::{include} /_include/links.md
:::
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][MongoDB]
+
```
+```{div} .clearfix
+```
+
+:::{rubric} About
+:::
[Metabase] is the ultimate data analysis and visualization tool that unlocks the full
potential of your data. Built for data and made for everyone, Metabase can be leveraged
with no SQL required.
+:::{dropdown} **Details**
+
Fast analytics with the friendly UX and integrated tooling to let your company explore
data on their own.
-{h=140px}
-{h=140px}
-
+{h=140px}
+{h=140px}
+:::
:::{dropdown} **Managed Metabase**
-```{div}
-:style: "float: right"
-[{w=180px}](https://www.metabase.com/)
-```
With [Metabase Cloud], you will get a fast, reliable, and secure deployment
with none of the work or hidden costs that come with self-hosting.
-- **Save the time** needed for setup and maintenance of the platform, focusing only on the insights we can get from our data.
+- **Save time** on setup and maintenance; focus on the insights from your data.
- **Trustworthy, production-grade deployment** by people who do this stuff for a living.
With the infrastructure, specialists, and thousands of Metabases in our cloud, we've put a lot of thought and resources into optimizing hosting.
- **Upgrades:** Automatically upgrade to the current version, so you're always getting the latest and greatest of Metabase.
- **Backups:** The way they should be: there when you need them, out of sight and out of mind when you don't.
-- **SMTP server:** Even your alerts and dashboard subscriptions covered with a preconfigured and managed SMTP server.
+- **SMTP server:** Alerts and dashboard subscriptions are covered via a preconfigured and managed SMTP server.
-
-```{div}
-:style: "clear: both"
-```
:::
:::{rubric} Learn
:::
-- {ref}`integrations-metabase`
-- [Real-time data analytics with Metabase and CrateDB]
-- https://github.com/paoliniluis/metabase-cratedb
+::::{grid}
+
+:::{grid-item-card} Tutorial: Visualize data
+:link: integrations-metabase
+:link-type: ref
+Visualize data with CrateDB and Metabase.
+:::
+
+:::{grid-item-card} Blog: Real-time data analytics
+:link: https://www.metabase.com/community_posts/real-time-data-analytics-with-metabase-and-cratedb
+:link-type: url
+Real-time data analytics with Metabase and CrateDB.
+:::
+
+:::{grid-item-card} Demo: "metabase-cratedb"
+:link: https://github.com/paoliniluis/metabase-cratedb
+:link-type: url
+A fully working demo of Metabase connected to CrateDB.
+:::
+
+::::
:::{toctree}
:maxdepth: 1
:hidden:
-
learn
:::
@@ -62,5 +80,3 @@ learn
[CrateDB and Metabase]: https://cratedb.com/integrations/cratedb-and-metabase
[Metabase]: https://www.metabase.com/
[Metabase Cloud]: https://www.metabase.com/cloud/
-[Real-time data analytics with Metabase and CrateDB]: https://www.metabase.com/community_posts/real-time-data-analytics-with-metabase-and-cratedb
-[Using Metabase with CrateDB Cloud]: #integrations-metabase
diff --git a/docs/integrate/mongodb/index.md b/docs/integrate/mongodb/index.md
index 9f68789c..eb243dcf 100644
--- a/docs/integrate/mongodb/index.md
+++ b/docs/integrate/mongodb/index.md
@@ -4,6 +4,21 @@
:::{include} /_include/links.md
:::
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][MongoDB]
+
+
+  +```
+```{div} .clearfix
+```
+
+:::::{grid}
+:padding: 0
+
+::::{grid-item}
+:columns: auto 9 9 9
+
:::{rubric} About
:::
@@ -15,41 +30,75 @@ you need to build resilient and performant global applications on the cloud prov
of your choice.
:::
-:::{rubric} Learn
+::::
+
+::::{grid-item}
+:columns: auto 3 3 3
+
+:::{rubric} Related
:::
+- [MongoDB collections and databases]
+- [MongoDB Change Streams]
-:::{div}
-Explore support for loading [MongoDB collections and databases] into CrateDB (`full-load`),
-and [MongoDB Change Streams], to relay CDC events from MongoDB into CrateDB (`cdc`).
-:::
-
-:::{list-table}
-:header-rows: 1
-:widths: auto
-
-* - Feature
- - CrateDB
- - CrateDB Cloud
- - Description
-* - [MongoDB Table Loader]
- - ✅
- - ✅
- - CLI `ctk load table` for loading collections into CrateDB (`full-load`).
- Tutorial: {ref}`import-mongodb`
-* - [MongoDB CDC Relay]
- - ✅
- - ✅
- - CLI `ctk load table` for streaming changes of collections into CrateDB (`cdc`).
-* - {ref}`MongoDB CDC integration `
- - ❌
- - ✅
- - Managed data loading from MongoDB and MongoDB Atlas into CrateDB Cloud
- (`full-load` and `cdc`), including advanced data translation and compensation
- strategies.
+::::
+
+:::::
+
+
+:::{rubric} Managed
+:::
+MongoDB CDC is available as a managed service on CrateDB Cloud.
+
+::::{grid}
+
+:::{grid-item-card} MongoDB CDC integration
+:link: cloud:integrations-mongo-cdc
+:link-type: ref
+Managed data loading from MongoDB and MongoDB Atlas into CrateDB Cloud
+(`full-load` and `cdc`), including advanced data migration, translation
+and compensation strategies.
+:::
+
+::::
+
+:::{rubric} Standalone
+:::
+Data from MongoDB can also be loaded by other means.
+
+::::{grid}
+
+:::{grid-item-card} Tutorial: Import data from MongoDB
+:link: mongodb-learn
+:link-type: ref
+How to load data from MongoDB Server and MongoDB Atlas into CrateDB.
+:::
+
+:::{grid-item-card} MongoDB Table Loader
+:link: ctk:mongodb-loader
+:link-type: ref
+Standalone CLI `ctk load table` for loading MongoDB collections into CrateDB
+(`full-load`), optionally using transformations.
+:::
+
+:::{grid-item-card} MongoDB CDC Relay
+:link: ctk:mongodb-cdc-relay
+:link-type: ref
+Standalone CLI `ctk load table` for streaming changes of MongoDB collections
+into CrateDB (`cdc`), optionally using transformations.
:::
+::::
+
+
:::{toctree}
:maxdepth: 1
:hidden:
learn
:::
+
+
+:::{seealso}
+**Blog:** [Announcing MongoDB CDC Integration (Public Preview) in CrateDB Cloud]
+:::
+
+[Announcing MongoDB CDC Integration (Public Preview) in CrateDB Cloud]: https://cratedb.com/blog/announcing-mongodb-cdc-integration-public-preview-in-cratedb-cloud
diff --git a/docs/integrate/mysql/learn.rst b/docs/integrate/mysql/import-csv.rst
similarity index 97%
rename from docs/integrate/mysql/learn.rst
rename to docs/integrate/mysql/import-csv.rst
index e23c1293..6a8b29e0 100644
--- a/docs/integrate/mysql/learn.rst
+++ b/docs/integrate/mysql/import-csv.rst
@@ -2,10 +2,11 @@
.. _integrate-mysql:
.. _migrating-mysql:
+.. _mysql-import-csv:
-======================
-Import data from MySQL
-======================
+================================
+Import data from MySQL using CSV
+================================
Various ways exist to migrate your existing data from MySQL_ to CrateDB_.
However, these methods may differ in performance. A fast and reliable way to
diff --git a/docs/integrate/mysql/index.md b/docs/integrate/mysql/index.md
index 06d65dd1..8a648296 100644
--- a/docs/integrate/mysql/index.md
+++ b/docs/integrate/mysql/index.md
@@ -2,39 +2,63 @@
(mariadb)=
# MySQL and MariaDB
+```{div} .float-right
+[{height=60px loading=lazy}](https://www.mysql.com/)
+[{height=60px loading=lazy}](https://www.mariadb.com/)
+```
+```{div} .clearfix
+```
+
:::{include} /_include/links.md
:::
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 1em"
-
-[{w=180px}](https://www.mysql.com/)
-
+```
+```{div} .clearfix
+```
+
+:::::{grid}
+:padding: 0
+
+::::{grid-item}
+:columns: auto 9 9 9
+
:::{rubric} About
:::
@@ -15,41 +30,75 @@ you need to build resilient and performant global applications on the cloud prov
of your choice.
:::
-:::{rubric} Learn
+::::
+
+::::{grid-item}
+:columns: auto 3 3 3
+
+:::{rubric} Related
:::
+- [MongoDB collections and databases]
+- [MongoDB Change Streams]
-:::{div}
-Explore support for loading [MongoDB collections and databases] into CrateDB (`full-load`),
-and [MongoDB Change Streams], to relay CDC events from MongoDB into CrateDB (`cdc`).
-:::
-
-:::{list-table}
-:header-rows: 1
-:widths: auto
-
-* - Feature
- - CrateDB
- - CrateDB Cloud
- - Description
-* - [MongoDB Table Loader]
- - ✅
- - ✅
- - CLI `ctk load table` for loading collections into CrateDB (`full-load`).
- Tutorial: {ref}`import-mongodb`
-* - [MongoDB CDC Relay]
- - ✅
- - ✅
- - CLI `ctk load table` for streaming changes of collections into CrateDB (`cdc`).
-* - {ref}`MongoDB CDC integration `
- - ❌
- - ✅
- - Managed data loading from MongoDB and MongoDB Atlas into CrateDB Cloud
- (`full-load` and `cdc`), including advanced data translation and compensation
- strategies.
+::::
+
+:::::
+
+
+:::{rubric} Managed
+:::
+MongoDB CDC is available as a managed service on CrateDB Cloud.
+
+::::{grid}
+
+:::{grid-item-card} MongoDB CDC integration
+:link: cloud:integrations-mongo-cdc
+:link-type: ref
+Managed data loading from MongoDB and MongoDB Atlas into CrateDB Cloud
+(`full-load` and `cdc`), including advanced data migration, translation
+and compensation strategies.
+:::
+
+::::
+
+:::{rubric} Standalone
+:::
+Data from MongoDB can also be loaded by other means.
+
+::::{grid}
+
+:::{grid-item-card} Tutorial: Import data from MongoDB
+:link: mongodb-learn
+:link-type: ref
+How to load data from MongoDB Server and MongoDB Atlas into CrateDB.
+:::
+
+:::{grid-item-card} MongoDB Table Loader
+:link: ctk:mongodb-loader
+:link-type: ref
+Standalone CLI `ctk load table` for loading MongoDB collections into CrateDB
+(`full-load`), optionally using transformations.
+:::
+
+:::{grid-item-card} MongoDB CDC Relay
+:link: ctk:mongodb-cdc-relay
+:link-type: ref
+Standalone CLI `ctk load table` for streaming changes of MongoDB collections
+into CrateDB (`cdc`), optionally using transformations.
:::
+::::
+
+
:::{toctree}
:maxdepth: 1
:hidden:
learn
:::
+
+
+:::{seealso}
+**Blog:** [Announcing MongoDB CDC Integration (Public Preview) in CrateDB Cloud]
+:::
+
+[Announcing MongoDB CDC Integration (Public Preview) in CrateDB Cloud]: https://cratedb.com/blog/announcing-mongodb-cdc-integration-public-preview-in-cratedb-cloud
diff --git a/docs/integrate/mysql/learn.rst b/docs/integrate/mysql/import-csv.rst
similarity index 97%
rename from docs/integrate/mysql/learn.rst
rename to docs/integrate/mysql/import-csv.rst
index e23c1293..6a8b29e0 100644
--- a/docs/integrate/mysql/learn.rst
+++ b/docs/integrate/mysql/import-csv.rst
@@ -2,10 +2,11 @@
.. _integrate-mysql:
.. _migrating-mysql:
+.. _mysql-import-csv:
-======================
-Import data from MySQL
-======================
+================================
+Import data from MySQL using CSV
+================================
Various ways exist to migrate your existing data from MySQL_ to CrateDB_.
However, these methods may differ in performance. A fast and reliable way to
diff --git a/docs/integrate/mysql/index.md b/docs/integrate/mysql/index.md
index 06d65dd1..8a648296 100644
--- a/docs/integrate/mysql/index.md
+++ b/docs/integrate/mysql/index.md
@@ -2,39 +2,63 @@
(mariadb)=
# MySQL and MariaDB
+```{div} .float-right
+[{height=60px loading=lazy}](https://www.mysql.com/)
+[{height=60px loading=lazy}](https://www.mariadb.com/)
+```
+```{div} .clearfix
+```
+
:::{include} /_include/links.md
:::
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 1em"
-
-[{w=180px}](https://www.mysql.com/)
-
-[{w=180px}](https://www.mariadb.com/)
-```
-
[MySQL] and [MariaDB] are well-known free and open-source relational database
management systems (RDBMS), available as standalone and managed variants.
+:::{dropdown} **Details**
MySQL is a component of the LAMP web application software stack (and others),
which is an acronym for Linux, Apache, MySQL, Perl/PHP/Python.
-In 2010, when Oracle acquired Sun, Monty Widenius, MySQL's founder, forked the
+When Oracle acquired Sun in 2010, Monty Widenius, MySQL's founder, forked the
open-source MySQL project to create MariaDB.
+:::
+
+:::{rubric} Synopsis
+:::
-```{div}
-:style: "clear: both"
+```shell
+uvx 'cratedb-toolkit[io-ingestr]' load table \
+ "mysql://:@host:port/dbname?table=demo" \
+ --cluster-url="crate://crate:crate@localhost:4200/testdrive/mysql_demo"
```
:::{rubric} Learn
:::
+::::{grid}
+
+:::{grid-item-card} Ingestr Table Loader
+:link: https://cratedb-toolkit.readthedocs.io/io/ingestr/#mysql-to-cratedb
+:link-type: url
+Load MySQL table into CrateDB.
+:::
+
+:::{grid-item-card} Export/Import using CSV
+:link: mysql-import-csv
+:link-type: ref
+Manually export CSV from MySQL, and import into CrateDB.
+:::
+
+::::
+
+
:::{toctree}
:maxdepth: 1
-learn
+:hidden:
+import-csv
:::
diff --git a/docs/integrate/n8n/index.md b/docs/integrate/n8n/index.md
index 73aca93d..61eb2f0b 100644
--- a/docs/integrate/n8n/index.md
+++ b/docs/integrate/n8n/index.md
@@ -1,20 +1,36 @@
(n8n)=
# n8n
+```{div} .float-right .text-right
+[{height=60px loading=lazy}][n8n]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-[n8n] is a fair-code licensed workflow automation tool that combines AI capabilities
+[n8n] is a workflow automation tool that combines AI capabilities
with business process automation. It helps you connect any app with an API to
any other, and manipulate its data with little or no code.
:::{rubric} Learn
:::
-- [CrateDB and n8n integration]
-- [n8n CrateDB integration]
+::::{grid} 2
+
+:::{grid-item-card} n8n CrateDB integration
+:link: https://n8n.io/integrations/cratedb/
+:link-type: url
+Create workflows with CrateDB integrations.
+:::
+
+::::
+
+```{seealso}
+[CrateDB and n8n]
+```
-[CrateDB and n8n integration]: https://cratedb.com/integrations/cratedb-and-n8n
+[CrateDB and n8n]: https://cratedb.com/integrations/cratedb-and-n8n
[n8n]: https://docs.n8n.io/
-[n8n CrateDB integration]: https://n8n.io/integrations/cratedb/
diff --git a/docs/integrate/node-red/index.md b/docs/integrate/node-red/index.md
index ec7835ca..4bf2f3bf 100644
--- a/docs/integrate/node-red/index.md
+++ b/docs/integrate/node-red/index.md
@@ -1,14 +1,15 @@
(node-red)=
# Node-RED
+```{div} .float-right
+[{height=60px loading=lazy}](https://nodered.org/)
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 1em"
-[{w=180px}](https://nodered.org/)
-```
-
[Node-RED] is a programming tool for wiring together hardware devices, APIs
and online services within a low-code programming environment for event-driven
applications. It allows orchestrating message flows and transformations through
@@ -21,7 +22,7 @@ deployed to its runtime in a single-click.
:::{dropdown} **Managed Node-RED**
```{div}
:style: "float: right; margin: 0.5em"
-[{w=180px}](https://flowfuse.com/)
+[{w=180px}][FlowFuse]
```
With [FlowFuse], and [FlowFuse Cloud], essentially unmanaged and managed DevOps
@@ -45,8 +46,7 @@ collaborative, and secure manner.
You have the freedom to choose the deployment method that works best for your
organization.
-```{div}
-:style: "clear: both"
+```{div} .clearfix
```
:::
@@ -54,8 +54,21 @@ collaborative, and secure manner.
:::{rubric} Learn
:::
-- [Ingesting MQTT messages into CrateDB using Node-RED]
-- [Automating recurrent CrateDB queries using Node-RED]
+::::{grid} 2
+
+:::{grid-item-card} Tutorial: Ingest MQTT
+:link: https://community.cratedb.com/t/ingesting-mqtt-messages-into-cratedb-using-node-red/803
+:link-type: url
+Ingesting MQTT messages into CrateDB using Node-RED.
+:::
+
+:::{grid-item-card} Tutorial: Recurrent queries
+:link: https://community.cratedb.com/t/automating-recurrent-cratedb-queries/788
+:link-type: url
+Automating recurrent CrateDB queries using Node-RED.
+:::
+
+::::
```{seealso}
@@ -63,10 +76,8 @@ collaborative, and secure manner.
```
-[Automating recurrent CrateDB queries using Node-RED]: https://community.cratedb.com/t/automating-recurrent-cratedb-queries/788
[CrateDB and Node-RED]: https://cratedb.com/integrations/cratedb-and-node-red
[FlowFuse]: https://flowfuse.com/
[FlowFuse Cloud]: https://app.flowforge.com/
-[Ingesting MQTT messages into CrateDB using Node-RED]: https://community.cratedb.com/t/ingesting-mqtt-messages-into-cratedb-using-node-red/803
[Introduction to FlowFuse]: https://flowfuse.com/webinars/2023/introduction-to-flowforge/
[Node-RED]: https://nodered.org/
diff --git a/docs/integrate/plotly/index.md b/docs/integrate/plotly/index.md
index f4ca43cf..c81f27df 100644
--- a/docs/integrate/plotly/index.md
+++ b/docs/integrate/plotly/index.md
@@ -3,61 +3,47 @@
:::{include} /_include/links.md
:::
+```{div} .float-right
+[{height=60px loading=lazy}][Plotly]
+```
+```{div} .clearfix
+```
+
(plotly)=
## Plotly
-```{div}
-:style: "float: right"
-[{w=180px}](https://plotly.com/)
-```
-
[Plotly] Open Source Graphing Libraries make interactive, publication-quality graphs.
Line plots, scatter plots, area charts, bar charts, error bars, box plots, histograms,
heatmaps, subplots, multiple-axes, polar charts, bubble charts, and maps.
+:::{dropdown} **Details**
The supported programming languages / libraries / frameworks are Python, R, Julia,
JavaScript, ggplot2, F#, MATLAB®, and Dash.
Based on Plotly, [Dash] is a low-code framework for rapidly building data apps in Python.
-```{div}
-:style: "clear: both"
-```
-
-{h=200px}
-{h=200px}
-
+{h=200px}
+{h=200px}
+:::
(dash)=
## Dash
-```{div}
-:style: "float: right"
-[{w=180px}](https://dash.plotly.com/)
-```
-
[Dash] is a low-code framework for rapidly building data apps in Python,
based on [Plotly]. Built on top of Plotly.js, React and Flask, Dash ties
modern UI elements like dropdowns, sliders, and graphs, directly to your
analytical Python code.
+:::{dropdown} **Details**
Dash is a trusted Python framework for building ML & data science web apps. Many
specialized open-source Dash libraries exist that are tailored for building
domain-specific Dash components and applications.
-```{div}
-:style: "clear: both"
-```
+{h=200px}
+{h=200px}
:::
-{h=200px}
-{h=200px}
-
:::{dropdown} **Dash Enterprise**
-```{div}
-:style: "float: right"
-[{w=180px}](https://plotly.com/dash/)
-```
Dash Enterprise is Plotly’s paid product for building, testing, deploying, managing,
and scaling Dash applications organization-wide, advertised as the Premier Data App
@@ -74,24 +60,39 @@ cut it in today’s AI and ML driven world. Production-grade, low-code Python da
are needed to visualize the sophisticated data analytics and data pipelines that run
modern businesses.
-```{div}
-:style: "clear: both"
-```
-{h=200px}
-{h=200px}
+{h=200px}
+{h=200px}
:::
-
-
-_Plotly Dash Course - Session 1._
-
## Learn
:::{include} /_include/card/timeseries-explore.md
:::
+::::{info-card}
+
+:::{grid-item}
+:columns: auto auto 8 8
+**Plotly Dash Course - Session 1**
+
+This is the first session of the course on "Building Data Apps in Python and Plotly Dash".
+
Alternatively, you are welcome to explore the canonical [Dash Examples].
+:::
+
+:::{grid-item}
+:columns: auto auto 4 4
+
+
+
+_Plotly Dash Course - Session 1._
+
+{tags-primary}`Fundamentals` \
+{tags-secondary}`Plotly`
+:::
+
+::::
[Dash]: https://plotly.com/dash/
diff --git a/docs/integrate/powerbi/desktop.rst b/docs/integrate/powerbi/desktop.rst
index 6e6c27de..12e82687 100644
--- a/docs/integrate/powerbi/desktop.rst
+++ b/docs/integrate/powerbi/desktop.rst
@@ -1,14 +1,14 @@
.. _powerbi-desktop:
-=========================================
-Reports with CrateDB and Power BI Desktop
-=========================================
+=============================
+Reports with Power BI Desktop
+=============================
This integration document details how to create data-driven reports and
dashboards using CrateDB and Power BI Desktop.
-Abstract
-========
+Introduction
+------------
`Power BI Desktop`_ is a powerful `business intelligence`_ tool that provides
a set of data analytics and visualizations. Using Power BI Desktop, users can
@@ -23,12 +23,8 @@ This can be done by installing the `PostgreSQL ODBC driver`_, creating a
source.
-Implementation
-==============
-
-
-Set Up
-------
+Setup
+-----
For this implementation, we will be visualizing the data from the `World
Economic Outlook survey`_. In particular, we will use population figures,
@@ -51,8 +47,8 @@ Within the zip archive is an MSI installer. Execute it and follow the
instructions.
-CrateDB
--------
+Provision CrateDB
+-----------------
First, you need to create a table to hold the World Economic Outlook survey
data:
@@ -94,8 +90,8 @@ To insert the data into CrateDB::
.. _powerbi-desktop-dsn:
-Creating a DSN for CrateDB
---------------------------
+Create a DSN for CrateDB
+------------------------
First, verify that you have installed the PostgreSQL ODBC driver by searching
for and opening the ODBC Data Sources application for your architecture:
@@ -147,8 +143,8 @@ You can click *Test* to verify that the DSN is configured correctly. Once this
is done, click *Save* to save the DSN.
-Connecting Power BI to CrateDB
-------------------------------
+Connect Power BI to CrateDB
+---------------------------
Once you have created the DSN, open up Power BI and click *Get Data* from the
menu ribbon. Select *ODBC* from the list of available data sources:
@@ -171,8 +167,8 @@ From here you can transform the data as you wish, or click *Load* to load
the dataset.
-Data Visualization
-------------------
+Visualize Data
+--------------
Once the dataset has been added, you can visualize some of it. For example,
you can visualize the distribution of population by region.
diff --git a/docs/integrate/powerbi/index.md b/docs/integrate/powerbi/index.md
index 15097989..77784164 100644
--- a/docs/integrate/powerbi/index.md
+++ b/docs/integrate/powerbi/index.md
@@ -1,18 +1,20 @@
(powerbi)=
# Microsoft Power BI
+```{div} .float-right
+[{height=60px loading=lazy}][Power BI Desktop]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-```{div}
-:style: "float: right"
-[{w=180px}](https://powerbi.microsoft.com/en-us/desktop/)
-```
-
[Power BI Desktop] is a powerful business intelligence tool that provides a set of
data analytics and visualizations. Using Power BI Desktop, users can create reports
and dashboards from large datasets.
+:::{dropdown} **Details**
For connecting to CrateDB with Power BI, you can use the [Power Query PostgreSQL connector].
Earlier versions used the [PostgreSQL ODBC driver]. [](project:#powerbi-desktop) walks
you through the process of configuring that correctly.
@@ -21,19 +23,35 @@ you through the process of configuring that correctly.
possible to publish your dashboards, in order to share them with others.
[](project:#powerbi-service) has a corresponding tutorial.
-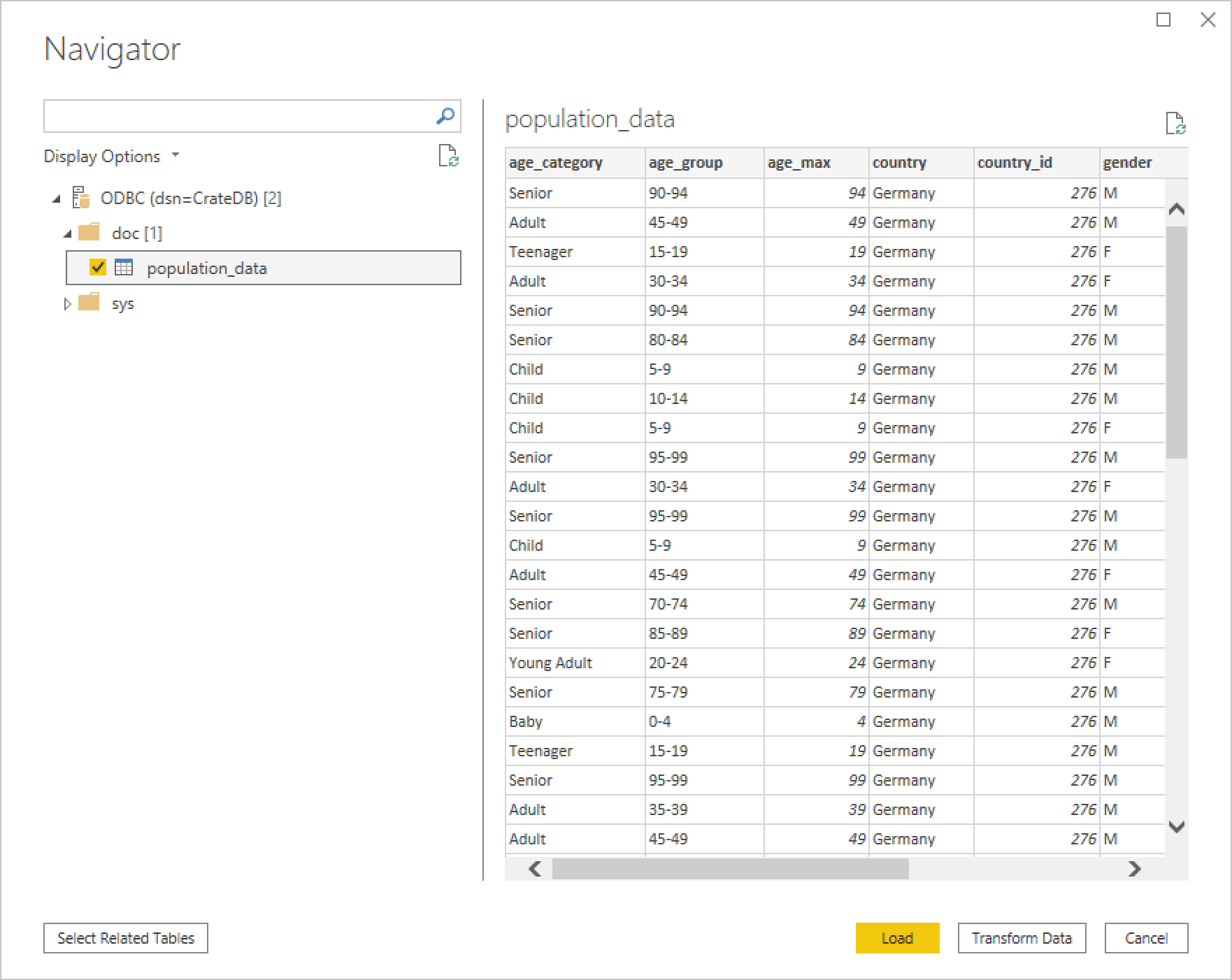{h=160px}
-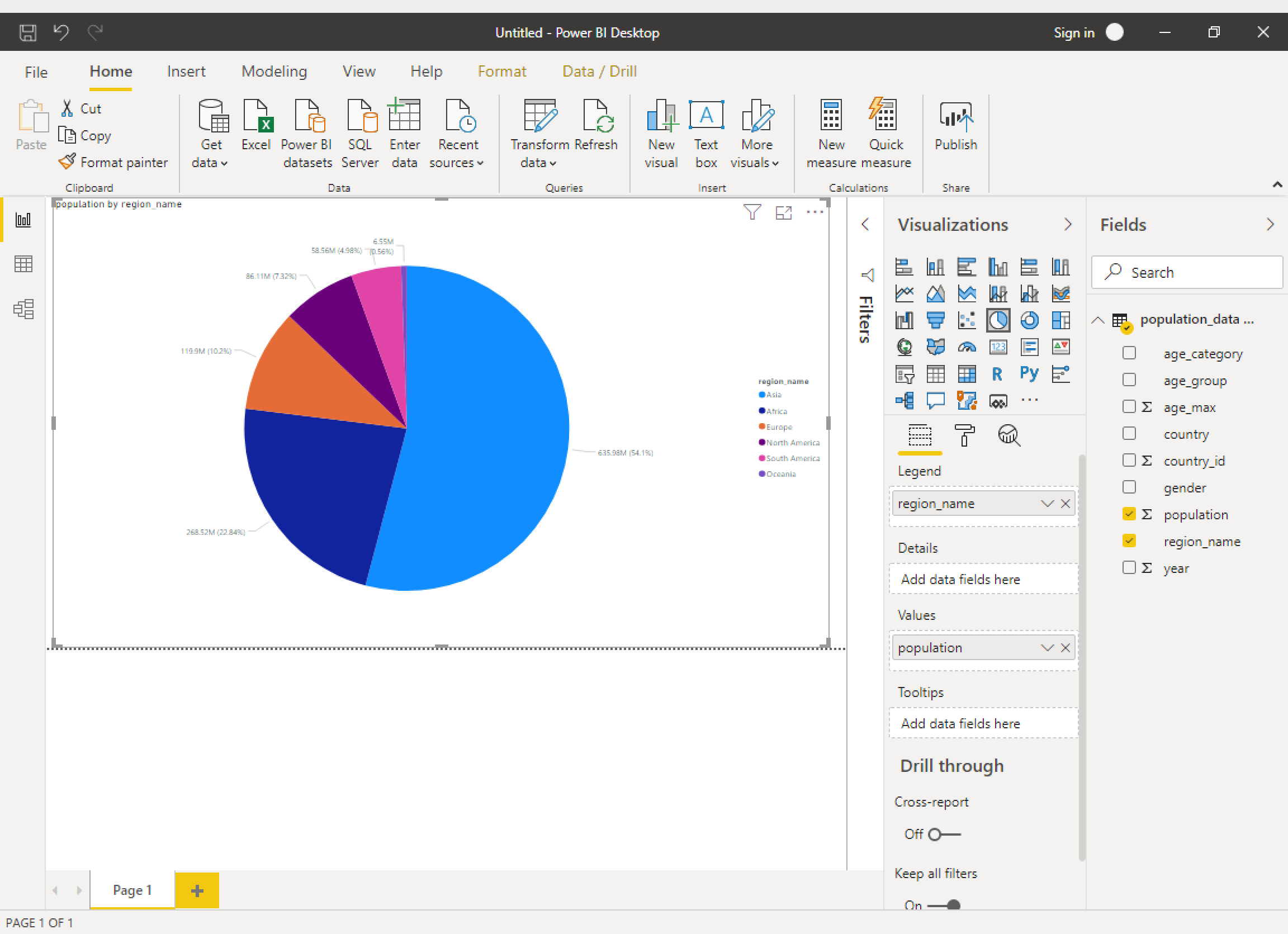{h=160px}
-{h=160px}
-
+{h=160px}
+{h=160px}
+{h=160px}
+:::
:::{rubric} Learn
:::
+::::{grid}
+
+:::{grid-item-card} Tutorial: Basic reports
+:link: powerbi-desktop
+:link-type: ref
+Reports with Power BI Desktop.
+:::
+
+:::{grid-item-card} Tutorial: Real Time Reports
+:link: powerbi-service
+:link-type: ref
+Real Time Reports using the Power BI service and the on-premises data gateway.
+:::
+
+::::
+
```{toctree}
:maxdepth: 1
-
-desktop
-gateway
+:hidden:
+Power BI Desktop
+Power BI Service
```
diff --git a/docs/integrate/powerbi/gateway.rst b/docs/integrate/powerbi/service.rst
similarity index 88%
rename from docs/integrate/powerbi/gateway.rst
rename to docs/integrate/powerbi/service.rst
index 6eefb2e5..70494c01 100644
--- a/docs/integrate/powerbi/gateway.rst
+++ b/docs/integrate/powerbi/service.rst
@@ -1,15 +1,14 @@
.. _powerbi-service:
-===========================================
-Real Time Reports with CrateDB and Power BI
-===========================================
+=======================================
+Real-time reports with Power BI Service
+=======================================
This integration document details how to create online data-driven reports
-and dashboards using CrateDB and Power BI.
+and dashboards using CrateDB and the Power BI service.
-
-Abstract
-========
+Introduction
+------------
The `Power BI service`_ is a powerful online data analysis and visualization
tool. When paired with CrateDB, users can construct reports backed by large
@@ -22,12 +21,8 @@ source on Power BI to refresh itself, using the gateway, on regular intervals
and on demand.
-Implementation
-==============
-
-
-Set Up
-------
+Setup
+-----
This implementation will demonstrate real-time reports with CrateDB and Power
BI by visualizing the data from the `World Economic Outlook survey`_.
@@ -58,12 +53,12 @@ should see something like the following status:
Ensure that the **Power BI** status for the gateway is **Ready**.
-Creating a Report With CrateDB and Power BI Desktop
----------------------------------------------------
+Create the report
+-----------------
Before you can publish your report, you need to have created it first.
You can do this using the data from CrateDB. Please follow the
-:ref:`CrateDB and PowerBI Desktop ` integration
+:ref:`CrateDB and Power BI Desktop ` integration
guide to do this.
After running through that guide, we should have the following report:
@@ -72,10 +67,10 @@ After running through that guide, we should have the following report:
:align: center
-Publishing the Report
----------------------
+Publish the report
+------------------
-With your report created on Power BI desktop, you can now publish it to the
+With your report created on Power BI Desktop, you can now publish it to the
online Power BI service. First, click the *Publish* button in the ribbon. Next,
choose a destination to publish to:
@@ -92,18 +87,18 @@ Power BI service:
:align: center
The report can now be shared via its URL. However, this is just a static
-snapshot of the data. Data may change over time as it is grows, is enriched
+snapshot of the data. Data may change over time as it grows, is enriched
or gets discarded, and your reports should reflect this changing data.
Power BI allows you to `refresh the datasets`_ your reports use. This
refreshing can be triggered manually or on a set schedule. It
does this by using the `On-Premises Data Gateway`_. The Gateway acts as a
bridge between the online report and your CrateDB data source, allowing the
-Power BI service to retrieve up to date datasets from CrateDB.
+Power BI service to retrieve up-to-date datasets from CrateDB.
-Configuring The Gateway
------------------------
+Configure the gateway
+---------------------
Within the Power BI service's settings, select *Manage Gateways*:
@@ -117,7 +112,7 @@ connections*, you should see your cluster has the 'Online' status:
:align: center
Click *Add data sources to use the gateway*. In the data source settings,
-name your datasource, select the **ODBC** type, and enter the connection
+name your data source, select the **ODBC** type, and enter the connection
ODBC connection string. The connection string will be whatever you named
the DSN when connecting Power BI Desktop to CrateDB. In this case, it was
``CrateDB``, so the ODBC connection string will be ``dsn=CrateDB``.
@@ -136,7 +131,7 @@ was successful:
Once successful, go to the *Users* tab and select the users you would like to
be able to access this data source to publish reports.
-Now, navigate back to the Power BI Service and click on the extra options
+Now, navigate back to the Power BI service and click on the extra options
for your ``population report`` data set, and click *Schedule refresh*.
.. figure:: /_assets/img/integrations/powerbi/powerbi-schedule-refresh.png
@@ -151,8 +146,8 @@ the dataset to use the data gateway you set up previously and click apply:
The report is now configured to use the gateway.
-Modifying the Data
-------------------
+Modify the data
+---------------
To demonstrate this refresh capability, you can modify the data in our CrateDB
source. For example, your business could no longer be interested in data
@@ -165,8 +160,8 @@ about Europe. You can delete this from your table via:
DELETE OK, 270990 rows affected (2.125 sec)
-Refreshing the Report
----------------------
+Refresh the report
+------------------
Now that the dataset powering our report has changed, you can refresh it. As
before, click on the extra settings for the ``population report`` dataset, and
diff --git a/docs/integrate/prometheus/index.md b/docs/integrate/prometheus/index.md
index cf40adda..1c70da47 100644
--- a/docs/integrate/prometheus/index.md
+++ b/docs/integrate/prometheus/index.md
@@ -1,16 +1,20 @@
(prometheus)=
# Prometheus
-:::{rubric} About
-:::
-
-```{div}
-:style: "float: right; margin-left: 0.3em"
-[{w=180px}](https://prometheus.io/)
+```{div} .float-right
+[{height=60px loading=lazy}][Prometheus]
+```
+```{div} .clearfix
```
+
+## About
+
[Prometheus] is an open-source systems monitoring and alerting toolkit
for collecting metrics data from applications and infrastructures.
+[CrateDB] can be used as a long-term storage for Prometheus metrics.
+
+::::{dropdown} **Details**
Prometheus collects and stores its metrics as time series data, i.e.
metrics information is stored with the timestamp at which it was recorded,
@@ -20,7 +24,7 @@ alongside optional key-value pairs called labels.
:::
Prometheus's main features are:
-- a multi-dimensional data model with time series data identified by metric name and key/value pairs
+- a multidimensional data model with time series data identified by metric name and key/value pairs
- PromQL, a flexible query language to leverage this dimensionality
- no reliance on distributed storage; single server nodes are autonomous
- time series collection happens via a pull model over HTTP
@@ -28,41 +32,91 @@ Prometheus's main features are:
- targets are discovered via service discovery or static configuration
- multiple modes of graphing and dashboarding support
+{h=200px}
+
+::::
+
+
+## Learn
:::{rubric} Remote Endpoints and Storage
:::
+
The [Prometheus remote endpoints and storage] subsystem, based on its
[remote write] and [remote read] features, allows to transparently
-send and receive metric samples. It is primarily intended for long term
+send and receive metric samples. It is primarily intended for long-term
storage.
-This is where CrateDB comes into place. Using the [CrateDB Prometheus
-Adapter], one can easily store the collected metrics data in CrateDB and
-take advantage of its high ingestion and query speed and friendly UI to
+This is where CrateDB comes into place: The [CrateDB Prometheus
+Adapter] stores collected metrics data into CrateDB and
+takes advantage of its high ingestion and query speed to
massively scale-out Prometheus.
-{h=200px}
+:::{rubric} Tutorials
+:::
+
+::::{grid}
-```{div}
-:style: "clear: both"
-```
+:::{grid-item-card} Blog: Getting started
+:link: https://cratedb.com/blog/getting-started-prometheus-cratedb-long-term-storage
+:link-type: url
+Getting started with Prometheus and CrateDB for long-term storage.
+:::
+
+:::{grid-item-card} Tutorial: Storing long-term metrics with Prometheus in CrateDB
+:link: https://community.cratedb.com/t/storing-long-term-metrics-with-prometheus-in-cratedb/1012
+:link-type: url
+Set up CrateDB as a long-term metrics store for Prometheus using Docker Compose.
+:::
+
+::::
-:::{rubric} Learn
+:::{rubric} Webinars
:::
-- [CrateDB as a long term metrics store for Prometheus](#metrics-store-prometheus)
-- [Webinar: Using Prometheus and Grafana with CrateDB Cloud]
+::::{info-card}
+
+:::{grid-item}
+:columns: 8
+
+{material-outlined}`manage_history;2em` **CrateDB as Prometheus Long-Term Storage**
+
+Learn how to start Prometheus, CrateDB, and the CrateDB Prometheus Adapter with
+Docker Compose, and how to configure Prometheus to use CrateDB as remote storage.
+
+This webinar accompanies the "Storing long-term metrics with Prometheus in CrateDB"
+tutorial.
+
+[Prometheus with CrateDB: Long-Term Metrics Storage]
+:::
+
+:::{grid-item}
+:columns: 4
+
+
+:::
+
+::::
+
+
+:::{rubric} Repositories
+:::
+
+[CrateDB] •
+[Prometheus] •
+[CrateDB Prometheus Adapter]
+
```{seealso}
-- [CrateDB and Prometheus]
-- [CrateDB Prometheus Adapter]
+[CrateDB and Prometheus]
```
+[CrateDB]: https://github.com/crate/crate
[CrateDB and Prometheus]: https://cratedb.com/integrations/cratedb-and-prometheus
[CrateDB Prometheus Adapter]: https://github.com/crate/cratedb-prometheus-adapter
-[Prometheus remote endpoints and storage]: https://prometheus.io/docs/operating/integrations/#remote-endpoints-and-storage
[Prometheus]: https://prometheus.io/
+[Prometheus remote endpoints and storage]: https://prometheus.io/docs/operating/integrations/#remote-endpoints-and-storage
+[Prometheus with CrateDB: Long-Term Metrics Storage]: https://youtu.be/EfIlRXVyfZM?feature=shared
[remote read]: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#remote_read
[remote write]: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#remote_write
-[Webinar: Using Prometheus and Grafana with CrateDB Cloud]: https://cratedb.com/resources/webinars/lp-wb-prometheus-grafana
diff --git a/docs/integrate/pyviz/index.md b/docs/integrate/pyviz/index.md
index fb58c910..f6aabda2 100644
--- a/docs/integrate/pyviz/index.md
+++ b/docs/integrate/pyviz/index.md
@@ -4,6 +4,13 @@
:::{include} /_include/links.md
:::
+```{div} .float-right
+[{height=60px loading=lazy}][hvPlot]
+[{height=60px loading=lazy}][Datashader]
+```
+```{div} .clearfix
+```
+
The PyViz.org website is an open platform for helping users decide on the best
open-source (OSS) Python data visualization tools.
@@ -11,15 +18,14 @@ open-source (OSS) Python data visualization tools.
(datashader)=
## hvPlot and Datashader
-```{div}
-:style: "float: right; margin-left: 1em"
-[{w=220px}](https://hvplot.holoviz.org/)
+:::::{grid}
+:padding: 0
-[{w=220px}](https://datashader.org/)
-```
+::::{grid-item}
+:columns: auto 8 8 8
[hvPlot] is a familiar and high-level API for data exploration and visualization.
-[Datashader][Datashader Homepage] is a graphics pipeline system for creating
+[Datashader] is a graphics pipeline system for creating
meaningful representations of large datasets quickly and flexibly.
It is used on behalf of the [hvPlot] package, which is based on [HoloViews], from the
@@ -29,25 +35,27 @@ With Datashader, you can "just plot" large datasets and explore them instantly,
parameter tweaking, magic numbers, subsampling, or approximation, up to the resolution
of the display.
-:::{div}
[hvPlot] sources its power in the [HoloViz] ecosystem. With [HoloViews], you get the
ability to easily layout and overlay plots, with [Panel], you can get more interactive
-control of your plots with widgets, with [DataShader][Datashader Homepage], you can
-visualize and interactively explore very large data, and with [GeoViews], you can
+control of your plots with widgets, with [DataShader], you can
+visualize and interactively explore large-scale datasets, and with [GeoViews], you can
create geographic plots.
-:::
+::::
-```{div}
-:style: "clear: both"
-```
+::::{grid-item}
+:columns: auto 4 4 4
-{h=200px}
-{h=200px}
+[![Datashader map aggregation example][ds1]][ds1]
+[![Datashader scatter/heat example][ds2]][ds2]
-
+[ds1]: https://github.com/crate/crate-clients-tools/assets/453543/7f38dff6-04bc-429e-9d31-6beeb9289c4b
+[ds2]: https://github.com/crate/crate-clients-tools/assets/453543/23561a87-fb4f-4154-9891-1b3068e40579
+
+::::
+
+:::::
-_hvPlot and Panel: Visualize all your data easily, from notebooks to dashboards | SciPy 2023._
## Learn
@@ -55,7 +63,29 @@ _hvPlot and Panel: Visualize all your data easily, from notebooks to dashboards
:::
-[Datashader Homepage]: https://datashader.org/
+:::{rubric} Webinars
+:::
+
+::::{info-card}
+
+:::{grid-item}
+:columns: 8
+
+{material-outlined}`manage_history;2em` **Presentation about hvPlot and Panel at SciPy 2023**
+
+_hvPlot and Panel: Visualize all your data easily, from notebooks to dashboards | SciPy 2023._
+:::
+
+:::{grid-item}
+:columns: 4
+
+
+:::
+
+::::
+
+
+
[GeoViews]: https://geoviews.org/
[HoloViz]: https://holoviz.org/
[hvPlot]: https://hvplot.holoviz.org/
diff --git a/docs/integrate/rill/index.md b/docs/integrate/rill/index.md
index d2d86847..4c59e07a 100644
--- a/docs/integrate/rill/index.md
+++ b/docs/integrate/rill/index.md
@@ -1,14 +1,16 @@
(rill)=
# Rill
+```{div} .float-right
+[{height=60px loading=lazy}][Rill]
+```
+```{div} .clearfix
+```
+
+
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 0.5em"
-[{w=180px}](https://www.rilldata.com/)
-```
-
[Rill] is an open-source operational BI framework for effortlessly transforming
data sets into powerful, opinionated dashboards using SQL.
@@ -16,6 +18,8 @@ Unlike most BI tools, Rill comes with its own embedded in-memory database. Data
and compute are co-located, and queries return in milliseconds. So you can pivot,
slice, and drill-down into your data instantly.
+::::{dropdown} **Details**
+
Rill takes a modern approach to Business Intelligence (BI), which is starting to
leverage software engineering principles by implementing the concept of BI as
code.
@@ -40,16 +44,23 @@ BI tools, also breaking down information and knowledge barriers.
- **Dashboards as code** – each step from data to dashboard has versioning, Git
sharing, and easy project rehydration
-{h=200px}
--p-3200.webp){h=200px}
+{h=200px}
+-p-3200.webp){h=200px}
+::::
:::{rubric} Learn
:::
-- [Introducing Rill and BI as Code with CrateDB Cloud]
+::::{grid} 2
+
+:::{grid-item-card} Rill and CrateDB
+:link: https://community.cratedb.com/t/introducing-rill-and-bi-as-code-with-cratedb-cloud/1718
+:link-type: url
+Introducing Rill and BI as Code with CrateDB Cloud.
+:::
-[Introducing Rill and BI as Code with CrateDB Cloud]: https://community.cratedb.com/t/introducing-rill-and-bi-as-code-with-cratedb-cloud/1718
+::::
[Rill]: https://www.rilldata.com/
diff --git a/docs/integrate/risingwave/index.md b/docs/integrate/risingwave/index.md
index c382efc9..7b226655 100644
--- a/docs/integrate/risingwave/index.md
+++ b/docs/integrate/risingwave/index.md
@@ -1,10 +1,15 @@
(risingwave)=
# RisingWave
-```{div}
-:style: "float: right; margin-left: 0.5em"
-[{w=180px}](https://www.risingwave.com/)
+```{div} .float-right
+[{height=60px loading=lazy}](https://www.risingwave.com/)
```
+```{div} .clearfix
+```
+
+
+:::{rubric} About
+:::
[RisingWave] is a stream processing and management platform that allows
configuring data sources, views on that data, and destinations where
@@ -12,12 +17,14 @@ results are materialized.
It provides both a Postgres-compatible SQL interface, like CrateDB,
and a DataFrame-style Python interface.
+:::{dropdown} **Details**
{h=200px}
> Deliver fresh, low-latency insights from real-time streams,
> database CDC, and time-series data. Bring streaming and batch together,
> let users join and analyze both live and historical data, and persist
> results in managed Apache Iceberg™ tables.
+:::
:::{dropdown} **Managed RisingWave**
RisingWave Labs offers [managed products][RisingWave pricing]
@@ -25,68 +32,78 @@ for building prototypes, production workloads, and enterprise-level, critical
applications.
:::
-```{div}
-:style: "clear: both"
-```
+:::{rubric} Synopsis
+:::
-## Synopsis
+:RisingWave:
+ Load an Apache Iceberg table, and serve it as a materialized view.
+ ```sql
+ CREATE SOURCE sensors_readings
+ WITH (
+ connector = 'iceberg',
+ database.name='db.db',
+ warehouse.path='s3://warehouse/',
+ table.name='sensors_readings',
+ s3.endpoint = '',
+ s3.access.key = '',
+ s3.secret.key = '',
+ s3.region = ''
+ );
+ ```
+ ```sql
+ CREATE MATERIALIZED VIEW average_sensor_readings AS
+ SELECT
+ sensor_id,
+ AVG(reading) AS average_reading
+ FROM sensors_readings
+ GROUP BY sensor_id;
+ ```
+:CrateDB:
+ Ingest it into a CrateDB table for long-term persistence and efficient querying,
+ even at large scale.
+ ```sql
+ CREATE TABLE public.average_sensor_readings (
+ sensor_id BIGINT PRIMARY KEY,
+ average_reading DOUBLE
+ );
+ ```
-:::{rubric} RisingWave
+:::{rubric} Learn
:::
-Load an Apache Iceberg table, and serve it as materialized view.
-```sql
-CREATE SOURCE sensors_readings
-WITH (
- connector = 'iceberg',
- database.name='db.db',
- warehouse.path='s3://warehouse/',
- table.name='sensors_readings',
- s3.endpoint = '',
- s3.access.key = '',
- s3.secret.key = '',
- s3.region = ''
-);
-```
-```sql
-CREATE MATERIALIZED VIEW average_sensor_readings AS
-SELECT
- sensor_id,
- AVG(reading) AS average_reading
-FROM sensors_readings
-GROUP BY sensor_id;
-```
-:::{rubric} CrateDB
+
+::::{grid} 2
+
+:::{grid-item-card} RisingWave Table Loader
+:link: risingwave-iceberg
+:link-type: ref
+Stream processing from Iceberg tables to CrateDB using RisingWave.
++++
+Full example tutorial, which is sourcing data from an Apache Iceberg table,
+and sinks it into CrateDB.
:::
-Converge into a CrateDB table for long-term persistence and efficient querying,
-even on large amounts of data.
-```sql
-CREATE TABLE public.average_sensor_readings (
- sensor_id BIGINT PRIMARY KEY,
- average_reading DOUBLE
-);
-```
+
+::::
+
+
+:::{rubric} Interoperability
+:::
+
:::{note}
The standard approach with RisingWave would be to use its [CREATE SINK] operation
to connect to an external target.
However, because this does not currently support CrateDB, a little Python event processor
is needed to relay the data. An example implementation can be found in the tutorial
-referenced below.
+referenced above.
:::
-## Learn
-
-Follow the full example tutorial sourcing data from an Apache Iceberg table,
-and sinking it into CrateDB. See {ref}`risingwave-iceberg`.
-
:::{note}
-We are tracking interoperability issues per [Tool: RisingWave] and appreciate
+We are tracking compatibility issues per [Tool: RisingWave] and appreciate
any contributions and reports.
:::
:::{toctree}
:maxdepth: 1
:hidden:
-
apache-iceberg
:::
diff --git a/docs/integrate/sql-server/index.md b/docs/integrate/sql-server/index.md
index 068b9fce..39fd9895 100644
--- a/docs/integrate/sql-server/index.md
+++ b/docs/integrate/sql-server/index.md
@@ -1,16 +1,16 @@
(sql-server)=
# SQL Server
+```{div} .float-right
+[{height=60px loading=lazy}](https://www.microsoft.com/)
+[{height=60px loading=lazy}][Microsoft SQL documentation]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 1em"
-[{w=180px}](https://www.microsoft.com/)
-
-[{w=180px}](https://learn.microsoft.com/en-us/sql/)
-```
-
Microsoft [SQL Server Integration Services] (SSIS) is a component of the Microsoft
SQL Server database software that can be used to perform a broad range of data
migration tasks.
@@ -28,21 +28,25 @@ Integration Services includes a rich set of built-in [tasks][ssis-tasks] and
[transformations][ssis-transformations], graphical tools for building packages, and
an SSIS Catalog database to store, run, and manage packages.
-```{div}
-:style: "clear: both"
-```
-
:::{rubric} Learn
:::
-A demo project which uses SSIS and ODBC to read and write data from CrateDB:
+::::{grid} 2
+
+:::{grid-item-card} SSIS and CrateDB
+:link: https://github.com/crate/cratedb-examples/tree/main/application/microsoft-ssis
+:link-type: url
+Using SQL Server Integration Services with CrateDB.
++++
+A demo project which uses SSIS and ODBC to read and write data from CrateDB.
+:::
-- [Using SQL Server Integration Services with CrateDB]
+::::
+[Microsoft SQL documentation]: https://learn.microsoft.com/en-us/sql/
[SQL Server Integration Services]: https://learn.microsoft.com/en-us/sql/integration-services/sql-server-integration-services
[SSIS]: https://en.wikipedia.org/wiki/SQL_Server_Integration_Services
[ssis-tasks]: https://learn.microsoft.com/en-us/sql/integration-services/control-flow/integration-services-tasks
[ssis-transformations]: https://learn.microsoft.com/en-us/sql/integration-services/data-flow/transformations/integration-services-transformations
-[Using SQL Server Integration Services with CrateDB]: https://github.com/crate/cratedb-examples/tree/main/application/microsoft-ssis
diff --git a/docs/integrate/streamlit/index.md b/docs/integrate/streamlit/index.md
index ee3e84c9..a12d969c 100644
--- a/docs/integrate/streamlit/index.md
+++ b/docs/integrate/streamlit/index.md
@@ -1,14 +1,20 @@
(streamlit)=
# Streamlit
-```{div}
-:style: "float: right; margin-left: 0.5em"
-[{w=180px}](https://streamlit.io/)
+```{div} .float-right
+[{height=60px loading=lazy}][Streamlit]
```
+```{div} .clearfix
+```
+
-[Streamlit] is an open source application programming framework for quickly sketching
+:::{rubric} About
+:::
+
+[Streamlit] is an open-source application programming framework for quickly sketching
out Python data applications. It provides fast, interactive prototyping, and live editing.
+:::{dropdown} **Details**
- Build dashboards, generate reports, or create chat apps using beautiful, easy-to-read code.
- No in-depth knowledge of HTML/JS/CSS needed, the framework offers elegant default
styling, which can be adjusted when applicable.
@@ -16,14 +22,44 @@ out Python data applications. It provides fast, interactive prototyping, and liv
- Build upon a range of [Streamlit components](https://streamlit.io/components).
- Optionally use their [Community Cloud platform](https://streamlit.io/cloud) to deploy,
manage, and share your application.
+:::
-```{div}
-:style: "clear: both"
-```
+:::{rubric} Learn
+:::
+
+::::{grid}
+
+:::{grid-item-card} Example
+:link: https://github.com/crate/cratedb-examples/tree/main/framework/streamlit
+:link-type: url
+Example program using Streamlit with CrateDB.
+:::
+
+::::
+
+
+:::{rubric} Webinars
+:::
+
+::::{info-card}
+
+:::{grid-item}
+:columns: 8
+
+{material-outlined}`manage_history;2em` **Streamlit 101 - A faster way to build and share data applications**
+
+Learn how to get started with Streamlit in building your own interactive data
+apps in no time. Streamlit is an open-source Python framework for data scientists
+and AI/ML engineers to deliver dynamic data apps – in only a few lines of code.
+:::
+
+:::{grid-item}
+:columns: 4
-
+
+:::
-_Streamlit 101 - A faster way to build and share data applications._
+::::
[Streamlit]: https://streamlit.io/
diff --git a/docs/integrate/streamsets/index.md b/docs/integrate/streamsets/index.md
index 2fecc23d..e1d17077 100644
--- a/docs/integrate/streamsets/index.md
+++ b/docs/integrate/streamsets/index.md
@@ -1,6 +1,13 @@
(streamsets)=
# StreamSets
+```{div} .float-right
+[{height=60px loading=lazy}][StreamSets Data Collector]
+```
+```{div} .clearfix
+```
+
+
:::{rubric} About
:::
@@ -15,8 +22,20 @@ It runs on-premises or in any cloud.
:::{rubric} Learn
:::
+::::{grid} 2
+
+:::{grid-item-card} Use StreamSet with CrateDB
+:link: streamsets-learn
+:link-type: ref
+Learn how to create data streaming pipelines
+using CrateDB and the StreamSets Data Collector.
+:::
+
+::::
+
:::{toctree}
:maxdepth: 1
+:hidden:
learn
:::
diff --git a/docs/integrate/tableau/index.md b/docs/integrate/tableau/index.md
index 3e445962..ad5f0235 100644
--- a/docs/integrate/tableau/index.md
+++ b/docs/integrate/tableau/index.md
@@ -1,36 +1,68 @@
(tableau)=
# Tableau
+```{div} .float-right
+[{height=60px loading=lazy}][Tableau]
+```
+```{div} .clearfix
+```
+
+
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 0.5em"
-[{w=180px}](https://www.tableau.com/)
-```
-
[Tableau] is a visual business intelligence and analytics software platform. It expresses
data by translating drag-and-drop actions into data queries through an intuitive interface.
-{h=200px}
+{h=200px}
:::{rubric} Learn
:::
-- [Connecting to CrateDB from Tableau with JDBC] and [Using CrateDB with Tableau]
- will guide you through the process of setting up Tableau correctly with CrateDB.
-- The [CrateDB Tableau Connector] unlocks advanced SQL functionality and
- resolves compatibility issues beyond standard usage.
+::::{grid} 2
+:gutter: 2
+
+:::{grid-item-card} Blog: Connecting to CrateDB from Tableau with JDBC
+:link: https://cratedb.com/blog/connecting-to-cratedb-from-tableau-with-jdbc
+:link-type: url
+In this tutorial, you will:
+- In CrateDB, create a table and provision the Iris dataset.
+- Set up the PostgreSQL JDBC driver for Tableau.
+- Connect to CrateDB from Tableau using PostgreSQL JDBC.
+- Make a simple visualization from your CrateDB table in Tableau.
+:::
+
+:::{grid-item-card} Article: Using CrateDB with Tableau
+:link: https://community.cratedb.com/t/using-cratedb-with-tableau/1192
+:link-type: url
+How to install the latest PostgreSQL JDBC driver (e.g.
+`postgresql-42.7.1.jar` or newer) for using Tableau.
+:::
+
+:::{grid-item-card} Repository: CrateDB Tableau Connector
+:link: https://github.com/crate/cratedb-tableau-connector
+:link-type: url
+:columns: 12
+The native Tableau connector for CrateDB unlocks advanced SQL functionality
+and resolves compatibility issues beyond standard usage.
+:::
+
+::::
+
+:::{rubric} Notes
+:::
+:::{note}
+We are tracking interoperability issues per [Tool: Tableau] and
+[Connector: Issues], and appreciate any contributions or reports.
+:::
```{seealso}
[CrateDB and Tableau]
```
-
-[Connecting to CrateDB from Tableau with JDBC]: https://cratedb.com/blog/connecting-to-cratedb-from-tableau-with-jdbc
+[Connector: Issues]: https://github.com/crate/cratedb-tableau-connector/issues
[CrateDB and Tableau]: https://cratedb.com/integrations/cratedb-and-tableau
-[CrateDB Tableau Connector]: https://github.com/crate/cratedb-tableau-connector
[Tableau]: https://www.tableau.com/
-[Using CrateDB with Tableau]: https://community.cratedb.com/t/using-cratedb-with-tableau/1192
+[Tool: Tableau]: https://github.com/crate/crate/labels/tool%3A%20Tableau
diff --git a/docs/integrate/telegraf/index.md b/docs/integrate/telegraf/index.md
index e1df987a..9f0429d0 100644
--- a/docs/integrate/telegraf/index.md
+++ b/docs/integrate/telegraf/index.md
@@ -1,14 +1,15 @@
(telegraf)=
# Telegraf
+```{div} .float-right
+[{width=180px loading=lazy}][Telegraf]
+```
+```{div} .clearfix
+```
+
:::{rubric} About
:::
-```{div}
-:style: "float: right; margin-left: 0.3em"
-[{w=180px}](https://www.influxdata.com/time-series-platform/telegraf/)
-```
-
[Telegraf] is a leading open source server agent to help you collect metrics
from your stacks, sensors, and systems. More than 200 adapters to connect
to other systems leaves nothing to be desired.
@@ -31,11 +32,8 @@ a very minimal memory footprint.
- **System telemetry**: Metrics from system telemetry like iptables, Netstat,
NGINX, and HAProxy help provide a full stack view of your apps.
-{h=200px}
+{height=200px loading=lazy}
-```{div}
-:style: "clear: both"
-```
:::{rubric} Learn
:::
diff --git a/docs/topic/index.md b/docs/topic/index.md
index eb9d12d7..f398be9b 100644
--- a/docs/topic/index.md
+++ b/docs/topic/index.md
@@ -76,7 +76,3 @@ or TensorFlow.
{ref}`Generated Columns ` •
{ref}`User-Defined Functions `
:::
-
-
-```{include} /_include/styles.html
-```
diff --git a/docs/topic/ml/index.md b/docs/topic/ml/index.md
index 5ae7d738..9f6a891e 100644
--- a/docs/topic/ml/index.md
+++ b/docs/topic/ml/index.md
@@ -5,8 +5,6 @@
:::{include} /_include/links.md
:::
-:::{include} /_include/styles.html
-:::
Machine learning applications and frameworks
which can be used together with CrateDB.
diff --git a/docs/topic/timeseries/index.md b/docs/topic/timeseries/index.md
index 196192a2..de888b5a 100644
--- a/docs/topic/timeseries/index.md
+++ b/docs/topic/timeseries/index.md
@@ -7,10 +7,6 @@ CrateDB is a distributed and scalable SQL database for storing and analyzing
massive amounts of data in near real-time, even with complex queries. It is
PostgreSQL-compatible, and based on Lucene.
-
-```{include} /_include/styles.html
-```
-
::::{grid} 1 2 2 2
:margin: 4 4 0 0
:padding: 0
diff --git a/docs/use/index.md b/docs/use/index.md
index 63b3040b..7a935468 100644
--- a/docs/use/index.md
+++ b/docs/use/index.md
@@ -76,7 +76,3 @@ industrial/index
telemetry/index
migrate/index
```
-
-
-```{include} /_include/styles.html
-```
diff --git a/docs/use/telemetry/index.md b/docs/use/telemetry/index.md
index 243e10b4..da3c6359 100644
--- a/docs/use/telemetry/index.md
+++ b/docs/use/telemetry/index.md
@@ -42,50 +42,11 @@ horizontal scalability as you go.
[Log Database]
-(metrics-store-prometheus)=
-
## Prometheus
-
-Using CrateDB as a long term storage for your Prometheus metrics.
-
-:Repositories:
- [CrateDB] •
- [Prometheus] •
- [CrateDB Prometheus Adapter]
-
-:Tutorial:
- [Storing long term metrics with Prometheus in CrateDB]
-
-:Blog:
- [Getting Started With Prometheus and CrateDB for Long Term Storage]
-
-
-::::{info-card}
-
-:::{grid-item}
-:columns: 8
-
-{material-outlined}`manage_history;2em` **CrateDB as Prometheus Long Term Storage**
-
-This video illustrates how to start Prometheus, CrateDB, and CrateDB
-Prometheus Adapter with Docker Compose, and how to configure Prometheus
-to use CrateDB as remote storage.
-
-[Prometheus with CrateDB: Long Term Metrics Storage]
-:::
-
-:::{grid-item}
-:columns: 4
-
-
-:::
-
-::::
-
+- {ref}`prometheus`
[CrateDB]: https://github.com/crate/crate
-[CrateDB Prometheus Adapter]: https://github.com/crate/cratedb-prometheus-adapter
[Getting Started With Prometheus and CrateDB for Long Term Storage]: https://cratedb.com/blog/getting-started-prometheus-cratedb-long-term-storage
[Log Database]: https://cratedb.com/solutions/log-database
[Prometheus]: https://github.com/prometheus/prometheus