Brought to you by Lesley Cordero and ADI
- 0.0 Setup
- 1.0 Background
- 2.0 Building a Neural Net
- 3.0 Python Modules
- 4.0 Feedforward Neural Networks
- 5.0 Recurrent Neural Networks
- 6.0 Convolution Neural Networks
- 7.0 Final Words
This guide was written in Python 3.5.
Let's install the modules we'll need for this tutorial. Open up your terminal and enter the following commands to install the needed python modules:
pip3 install sklearn
pip3 install lasagne
pip3 install theano
pip3 install keras
pip3 install tensorflow
pip3 install imutils
Deep Learning is a branch of machine learning that involves pattern recognition on unlabeled or unstructured data. It uses a model of computing inspired by the structure of the brain, which we call this model a neural network.
Neural networks get their representations from using layers of learning. The general structure of a neural network looks like this.
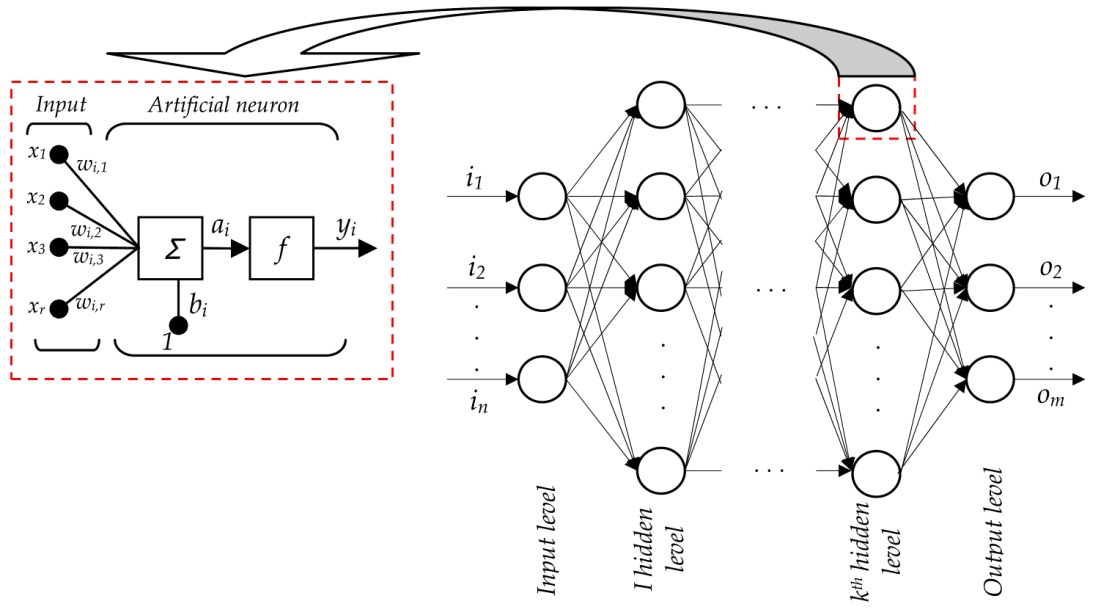{kind=link}
Meanwhile, a typical singular neuron looks like this.
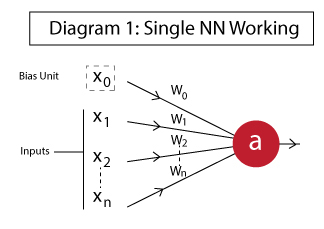{kind=link}
- The x1, x2,…, xN variables are the inputs. These can either be the actual observations from the input layer or an intermediate value from one of the hidden layers.
- x0 is the bias unit. This is a constant value added to the input of the activation function.
- w0,w1, w2,…,wN are the weights on each input - note that even the bias unit has a weight.
- a is the output of the neuron, which we calculate from this formula, where f is the activation function (you can find more on this in section 1.2.5)
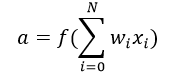{kind=link}
The first layer is a type of visible layer called an input layer. This layer contains an input node for each of the entries in our feature vector. From there, these nodes connect to a series of hidden layers.
1.2.3 Hidden Layers
These are the intermediate layers between input and output which help the Neural Network learn the complicated relationships involved in data. The final hidden layer then connects to an output layer.
The final output is extracted from the previous two layers. This layer contains the output probabilities for each class label. For example, in the case of a classification problem with 5 classes, the output later will have 5 neurons, each with its respective probability. The output node that produces the largest probability is chosen as the overall classification.
The activation function allows the neural network to be flexible and have the capability to estimate complex non-linear relationships in data. It can be a gaussian function, logistic function, hyperbolic function or even a linear function in simple cases.
Feedforward Neural Networks are the simplest form of Artificial Neural Networks. These networks have the three types of layers we just discussed: Input layer, hidden layer and output layer.
Convolutional neural networks are a type of feed-forward network. What distinguishes ConVets are that the architectures make the explicit assumption that the inputs are images, allowing us to encode certain properties into the architecture. These then make the forward function more efficient to implement and vastly reduce the amount of parameters in the network.
A Recurrent Neural Network is a class of ANNs where connections between units form a directed cycle, as shown here.
{kind=link}
Back-propagation algorithms work by determining the loss (or error) at the output and then propagating it back into the network. The weights are updated to minimize the error resulting from each neuron, since the goal of learning is to assign correct weights for these edges.
In other words, backprop is one of the several ways in which an artificial neural network can be trained. It is a supervised training scheme, which means, it learns from labeled training data. To put in simple terms, BackProp learns from its mistakes by having the supervisor correct the ANN whenever it makes mistakes.
Note: To forward propagate is to get the output and compare it with the real value to get the error. To back propagate is to minimize the error by propagating backwards by finding the derivative of error with respect to each weight and the subtracting this value from the weight value.
Initially all the edge weights are randomly assigned. For every input in the training dataset, the ANN is activated and its output is observed. This output is compared with the desired output that we already know, and the error is "propagated" back to the previous layer. This error is noted and the weights are "adjusted" accordingly. This process is repeated until the output error is below a predetermined threshold.
Once the above algorithm terminates, we have a "learned" ANN which we consider ready to work with "new" inputs. This ANN is said to have learned from several examples (labeled data) and from its mistakes (error propagation).
Gradient descent is a standard tool for interactively optimizing complex functions. Given some arbitrary function, gradient descent's goal is to find a minimum. For some small subset of functions - those that are convex - there's just a single minimum which also happens to be global. But for most realistic functions, there may be many minima, so most minima are local.
The main premise of gradient descent is: given some current location x in the search space (the domain of the optimized function) we update x for the next step in the direction opposite to the gradient of the function computed at x.
The GPU’s advanced capabilities were originally used primarily for 3D game rendering, but are now being used more broadly to accelerate computational workloads in deep learning.
Architecturally, the CPU is composed of just a few cores with lots of cache memory that can handle a few software threads at a time. In contrast, a GPU is composed of hundreds of cores that can handle thousands of threads simultaneously.
A simple way to understand the difference between a GPU and a CPU is to compare how they process tasks. A CPU consists of a few cores optimized for sequential serial processing while a GPU has a massively parallel architecture consisting of thousands of smaller, more efficient cores designed for handling multiple tasks simultaneously.
First, we import all the needed modules.
import matplotlib.pyplot as plt
import numpy as np
import sklearn
import sklearn.datasets
import sklearn.linear_model
import matplotlibThe following just displays plots inline and changes default figure size
matplotlib.rcParams['figure.figsize'] = (10.0, 8.0)Let's start by generating a dataset to use. Fortunately, scikit-learn has some useful dataset generators, so we don't need to write the code ourselves and will go with the make_moons function instead.
np.random.seed(0)
X, y = sklearn.datasets.make_moons(200, noise=0.20)Using built-in scatter plot functions, we'll do a quick visualization of our data.
plt.scatter(X[:,0], X[:,1], s=40, c=y, cmap=plt.cm.Spectral)
plt.show()As you can see, the dataset we generated has two classes, plotted as red and blue points. Our goal is to train a Machine Learning classifier that predicts the correct class given the x and y coordinates.
Because the data is not linearly separable, we can't draw a straight line that separates the two classes, which means that linear classifiers, such as Logistic Regression, won't be able to fit the data. But that's one of the major advantages of Neural Networks - we won't need to worry about feature engineering because the hidden layer of a neural network will learn features for us.
To demonstrate this, let's train a Logistic Regression classifier. Its input will be the x and y values and the output the predicted class (0 or 1). Since scikit-learn has a logistic regression class built in, we'll go ahead and use that.
clf = sklearn.linear_model.LogisticRegressionCV()
clf.fit(X, y)Now we create a helper function to plot a decision boundary. If you don't fully understand this function don't worry, it just generates the contour plot below.
def plot_decision_boundary(pred_func):
# Set min and max values and give it some padding
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Predict the function value for the whole gid
Z = pred_func(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral)Now, let's plot the decision boundary
plot_decision_boundary(lambda x: clf.predict(x))
plt.title("Logistic Regression")
plt.show()As you can see, this logistic regression function isn't quite so good! It fails to capture the true form of the data.
In section 1, we briefly covered gradient descent and loss functions. Here, we'll actually implement these functions and use them to train our neural net. So let's start by defining some useful variables and parameters for gradient descent:
num_examples = len(X) # training set size
nn_input_dim = 2 # input layer dimensionality
nn_output_dim = 2 # output layer dimensionalityWe need to define the parameters for gradient descent, specifically the learning rate and the regularization strength.
The learning rate determines how fast or slow we will move towards the optimal weights. If the learning rate is too large the optimal solution will be skipped. But if it's too small we'll need too many iterations to converge to the best values. So using a good learning rate is crucial. Typically, a good technique is to adapt the value of learning rate in each iteration, but for this example, we'll just hand-pick one.
The regularization parameter, λ reduces overfitting, which reduces the variance of your estimated regression parameters. However, it does this at the expense of adding bias to your estimate - a common tradeoff you'll encounter in the field of machine learning.
One approach you can take is to randomly subsample your data a number of times and look at the variation in your estimate. Then repeat the process for a slightly larger value of lambda to see how it affects the variability of your estimate. Keep in mind that whatever value of lambda you decide is appropriate for your subsampled data, you can likely use a smaller value to achieve comparable regularization on the full data set.
With that said, in this exercise, I've just hand-picked a value.
Here are our hand-chosen rates:
epsilon = 0.01 # learning rate for gradient descent
reg_lambda = 0.01 # regularization strengthNext, we create a helper function to evaluate the total loss on the dataset.
def calculate_loss(model):
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# Forward propagation to calculate our predictions
z1 = X.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# Calculating the loss
corect_logprobs = -np.log(probs[range(num_examples), y])
data_loss = np.sum(corect_logprobs)
# Add regulatization term to loss
data_loss += reg_lambda/2 * (np.sum(np.square(W1)) + np.sum(np.square(W2)))
return (1./num_examples * data_loss)We also implement a helper function to calculate the output of the network. It does forward propagation as defined above and returns the class with the highest probability.
def predict(model, x):
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# Forward propagation
z1 = x.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
return (np.argmax(probs, axis=1))Finally, we train our Neural Network. Here, we implement batch gradient descent using the backpropagation derivates we found above.
def build_model(nn_hdim, num_passes=20000, print_loss=False):
np.random.seed(0)
W1 = np.random.randn(nn_input_dim, nn_hdim) / np.sqrt(nn_input_dim)
b1 = np.zeros((1, nn_hdim))
W2 = np.random.randn(nn_hdim, nn_output_dim) / np.sqrt(nn_hdim)
b2 = np.zeros((1, nn_output_dim))
model = {}
for i in range(0, num_passes):
z1 = X.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
delta3 = probs
delta3[range(num_examples), y] -= 1
dW2 = (a1.T).dot(delta3)
db2 = np.sum(delta3, axis=0, keepdims=True)
delta2 = delta3.dot(W2.T) * (1 - np.power(a1, 2))
dW1 = np.dot(X.T, delta2)
db1 = np.sum(delta2, axis=0)
dW2 += reg_lambda * W2
dW1 += reg_lambda * W1
W1 += -epsilon * dW1
b1 += -epsilon * db1
W2 += -epsilon * dW2
b2 += -epsilon * db2
model = { 'W1': W1, 'b1': b1, 'W2': W2, 'b2': b2}
if print_loss and i % 1000 == 0:
print("Loss after iteration %i: %f" %(i, calculate_loss(model)))
return (model)model = build_model(3, print_loss=True)Here, we're just plotting the decision boundary
plot_decision_boundary(lambda x: predict(model, x))
plt.title("Decision Boundary for hidden layer size 3")
plt.show()Let's see what happens if we train a network with a hidden layer size of 3.
plt.figure(figsize=(16, 32))
hidden_layer_dimensions = [1, 2, 3, 4, 5, 20, 50]
for i, nn_hdim in enumerate(hidden_layer_dimensions):
plt.subplot(5, 2, i+1)
plt.title('Hidden Layer size %d' % nn_hdim)
model = build_model(nn_hdim)
plot_decision_boundary(lambda x: predict(model, x))
plt.show()We can see that while a hidden layer of low dimensionality nicely captures the general trend of our data, but higher dimensionalities are prone to overfitting. They are "memorizing" the data as opposed to fitting the general shape. If we were to evaluate our model on a separate test set (and you should!) the model with a smaller hidden layer size would likely perform better because it generalizes better. We could counteract overfitting with stronger regularization, but picking the correct size for a hidden layer is a much more efficient solution.
Theano is a Python library that is used to define, optimize, and evaluate mathematical expressions with multi-dimensional arrays. Theano accomplishes this through its own data structures integrated with NumPy and the transparent use of the GPU. More specifically, Theano figures out which computational portions should be moved to the GPU.
Theano isn’t actually a machine learning library since it doesn’t provide you with pre-built models to train on your data. Instead, it's a mathematical library that provides you with tools to build your own machine learning models.
Simply put, Theano's strong suit is efficiency. Its primary purpose is to increase the speed of computation.
How does it accomplish this? Identifying 'small' changes like (x+y) + (x+y) to 2*(x+y), over time, make a substantial difference. Moreover, because it defines different mathematical expressions in C, it makes for much faster implementations. And because of this, Theano works well in high dimensionality problems. Lastly, it allows GPU implementation.
In Theano, all algorithms are defined symbolically, meaning that they don't have an explicit value.
To actually perform computations with Theano, you use symbolic functions, which can later be called with actual values. Symbolic functions allow us to automatically derive gradient expressions.
First, we import the needed libraries:
import theano
import numpyNext, we create the building blocks of our function. Here, x is a vector, W is an array we set up with numpy, and y is the function we'll use to compute the result.
x = theano.tensor.fvector('x')
W = theano.shared(numpy.asarray([0.2, 0.7]), 'W')
y = (x * W).sum()Finally, we actually perform the computation with Theano.
f = theano.function([x], y)
output = f([1.0, 1.0])If we print output, we get (0.2*1.0) + (0.7*1.0):
0.9
TensorFlow is an open source library for numerical computation using data flow graphs. Unlike Theano, however, TensorFlow handles distributed computing through the use of multiple-GPUs.
We'll go through a classic deep learning problem involving hand-written digit recognition, using the MNIST dataset. First, we'll implement the single layer version and follow up with a multi-layer model in section 5 of this workshop.
As always, we'll need to input the needed modules. input_data.py is available on the github link here - make sure to download it and include it in the same directory as your workspace. This will allow you to download the needed data.
import tensorflow as tf
import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)We'll need to create two variables to keep track of the weights and bias. Since we don't know those values yet, we initialize them to zeros.
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))In this example, we also create a tensor of two dimensions to keep the information of the x points with the following line of code:
x = tf.placeholder("float", [None, 784])Next we multiply the image vector x and the weight matrix W, adding b:
y = tf.nn.softmax(tf.matmul(x,W) + b)Next, we create another placeholder for the correct labels.
y_ = tf.placeholder("float", [None,10])Here, we figure out our cost function.
cross_entropy = -tf.reduce_sum(y_*tf.log(y))Using the backpropogation algorithm, we minimize the cross-entropy using the gradient descent algorithm and a learning rate of 0.01:
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)Now we can start the computation by instantiating tf.Session(). This is in charge of executing the TensorFlow operations in the available CPUs or GPUs. Then, we can execute the operation initializing all the variables:
sess = tf.Session()
sess.run(tf.initialize_all_variables())Now, we can start training our model!
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})Lasagne is a lightweight library used to construct and train networks in Theano. Lasagne does this by providing an API for constructing layers of a network and getting theano expressions that represent output, loss, etc.
As always, we import the needed modules first:
import lasagne
import theano
import theano.tensor as TThen we begin by creating Theano variables for input and target minibatch:
input_var = T.tensor4('X')
target_var = T.ivector('y')Here, we create a small convolutional neural network:
from lasagne.nonlinearities import leaky_rectify, softmax
network = lasagne.layers.InputLayer((None, 3, 32, 32), input_var)
network = lasagne.layers.Conv2DLayer(network, 64, (3, 3),
nonlinearity=leaky_rectify)
network = lasagne.layers.Conv2DLayer(network, 32, (3, 3),
nonlinearity=leaky_rectify)
network = lasagne.layers.Pool2DLayer(network, (3, 3), stride=2, mode='max')
network = lasagne.layers.DenseLayer(lasagne.layers.dropout(network, 0.5),
128, nonlinearity=leaky_rectify,
W=lasagne.init.Orthogonal())
network = lasagne.layers.DenseLayer(lasagne.layers.dropout(network, 0.5),
10, nonlinearity=softmax)
And of course, our loss function:
prediction = lasagne.layers.get_output(network)
loss = lasagne.objectives.categorical_crossentropy(prediction, target_var)
loss = loss.mean() + 1e-4 * lasagne.regularization.regularize_network_params(
network, lasagne.regularization.l2)Next, we create parameter updating expressions:
params = lasagne.layers.get_all_params(network, trainable=True)
updates = lasagne.updates.nesterov_momentum(loss, params, learning_rate=0.01,
momentum=0.9)Next, we need to compile a training function that updates parameters and returns training loss:
train_fn = theano.function([input_var, target_var], loss, updates=updates)And finally, we train the network:
for epoch in range(100):
loss = 0
for input_batch, target_batch in training_data:
loss += train_fn(input_batch, target_batch)
print("Epoch %d: Loss %g" % (epoch + 1, loss / len(training_data)))
Now we use the trained network for predictions:
test_prediction = lasagne.layers.get_output(network, deterministic=True)
predict_fn = theano.function([input_var], T.argmax(test_prediction, axis=1))
print("Predicted class for first test input: %r" % predict_fn(test_data[0]))Keras is a super powerful, easy to use Python library for building neural networks and deep learning networks.
Caffe is a deep learning framework written in C++. We won't be going through an implementation of caffe, but it's important to note its existence in deep learning, as well as the advantages and disadvantages of using the module.
Let's begin with why we won't be going into details of caffe: it requires thorough knowledge of architecture, since it's written in C++. This makes it a lot harder to work with, especially as someone just entering the field of Deep Learning.
On the other hand, because caffe is written in C++, it's incredibly fast, even faster than theano, and provides access via the command line.
Feedforward Neural Networks are the simplest form of Artificial Neural Networks. These networks have the three types of layers we just discussed: Input layer, hidden layer and output layer. There are no backwards or inter-layer connections. Furthermore, the nodes in the layer are fully connected to the nodes in the next layer.
First, we import the needed modules.
from sklearn.preprocessing import LabelEncoder
from sklearn.cross_validation import train_test_split
from keras.models import Sequential
from keras.layers import Activation
from keras.optimizers import SGD
from keras.layers import Dense
from keras.utils import np_utils
from imutils import paths
import numpy as np
import argparse
import cv2
import osThis function resizes the image to a fixed size and then flattens it into a list of features (raw pixel intensities).
def image_to_feature_vector(image, size=(32, 32)):
return (cv2.resize(image, size).flatten())Here, we construct the argument parse and parse the arguments.
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset")
args = vars(ap.parse_args())So here we grab the list of images that we'll be describing and initialize the data matrix and labels list.
print("[INFO] describing images...")
imagePaths = list(paths.list_images(args["dataset"]))
data = []
labels = []Iterating over the input images, we load the image and extract the class label. Secondly, we construct a feature vector of raw pixel intensities and then update the matrix and list.
# loop over the input images
for (i, imagePath) in enumerate(imagePaths):
image = cv2.imread(imagePath)
label = imagePath.split(os.path.sep)[-1].split(".")[0]
features = image_to_feature_vector(image)
data.append(features)
labels.append(label)
# show an update every 1,000 images
if i > 0 and i % 1000 == 0:
print("[INFO] processed {}/{}".format(i, len(imagePaths)))le = LabelEncoder()
labels = le.fit_transform(labels)
data = np.array(data) / 255.0
labels = np_utils.to_categorical(labels, 2)
print("[INFO] constructing training/testing split...")
(trainData, testData, trainLabels, testLabels) = train_test_split(
data, labels, test_size=0.25, random_state=42)Here, we're just defining the architecture of the network
model = Sequential()
model.add(Dense(768, input_dim=3072, init="uniform",
activation="relu"))
model.add(Dense(384, init="uniform", activation="relu"))
model.add(Dense(2))
model.add(Activation("softmax"))Now, we begin training the model:
print("[INFO] compiling model...")
sgd = SGD(lr=0.01)
model.compile(loss="binary_crossentropy", optimizer=sgd,
metrics=["accuracy"])
model.fit(trainData, trainLabels, nb_epoch=50, batch_size=128)print("[INFO] evaluating on testing set...")
(loss, accuracy) = model.evaluate(testData, testLabels,
batch_size=128, verbose=1)
print("[INFO] loss={:.4f}, accuracy: {:.4f}%".format(loss,
accuracy * 100))As we said in section 1, a Recurrent Neural Network is a class of ANNs where connections between units form a directed cycle, as shown here.
Because recurrent neural networks form directed cycles, information is able to persist, meaning it can use its reasoning from previous events. A recurrent neural network can be thought of as multiple copies of the same network, each passing a message to a successor.
import copy, numpy as np
np.random.seed(0)This helper function just computes the sigmoid nonlinearity.
def sigmoid(x):
output = 1/(1+np.exp(-x))
return outputHere, this function converts the output of the sigmoid function to its derivative.
def sigmoid_output_to_derivative(output):
return output*(1-output)Obviously we need a dataset to train on, so this is where we generate that:
int2binary = {}
binary_dim = 8
largest_number = pow(2,binary_dim)
binary = np.unpackbits(
np.array([range(largest_number)],dtype=np.uint8).T,axis=1)
for i in range(largest_number):
int2binary[i] = binary[i]Here, we define our dimension variables!
alpha = 0.1
input_dim = 2
hidden_dim = 16
output_dim = 1And, as always, we initialize neural network weights:
synapse_0 = 2*np.random.random((input_dim,hidden_dim)) - 1
synapse_1 = 2*np.random.random((hidden_dim,output_dim)) - 1
synapse_h = 2*np.random.random((hidden_dim,hidden_dim)) - 1
synapse_0_update = np.zeros_like(synapse_0)
synapse_1_update = np.zeros_like(synapse_1)
synapse_h_update = np.zeros_like(synapse_h)Finally, we begin our training.
for j in range(10000):
a_int = np.random.randint(largest_number/2)
a = int2binary[a_int]
b_int = np.random.randint(largest_number/2)
b = int2binary[b_int]
c_int = a_int + b_int
c = int2binary[c_int]
d = np.zeros_like(c)
overallError = 0
layer_2_deltas = list()
layer_1_values = list()
layer_1_values.append(np.zeros(hidden_dim))
for position in range(binary_dim):
# generate input and output
X = np.array([[a[binary_dim - position - 1],b[binary_dim - position - 1]]])
y = np.array([[c[binary_dim - position - 1]]]).T
# hidden layer (input ~+ prev_hidden)
layer_1 = sigmoid(np.dot(X,synapse_0) + np.dot(layer_1_values[-1],synapse_h))
# output layer (new binary representation)
layer_2 = sigmoid(np.dot(layer_1,synapse_1))
layer_2_error = y - layer_2
layer_2_deltas.append((layer_2_error)*sigmoid_output_to_derivative(layer_2))
overallError += np.abs(layer_2_error[0])
d[binary_dim - position - 1] = np.round(layer_2[0][0])
# store hidden layer so we can use it in the next timestep
layer_1_values.append(copy.deepcopy(layer_1))
future_layer_1_delta = np.zeros(hidden_dim)
for position in range(binary_dim):
X = np.array([[a[position],b[position]]])
layer_1 = layer_1_values[-position-1]
prev_layer_1 = layer_1_values[-position-2]
# error at output layer
layer_2_delta = layer_2_deltas[-position-1]
# error at hidden layer
layer_1_delta = (future_layer_1_delta.dot(synapse_h.T) + layer_2_delta.dot(synapse_1.T)) * sigmoid_output_to_derivative(layer_1)
# update weights for back-propagation
synapse_1_update += np.atleast_2d(layer_1).T.dot(layer_2_delta)
synapse_h_update += np.atleast_2d(prev_layer_1).T.dot(layer_1_delta)
synapse_0_update += X.T.dot(layer_1_delta)
future_layer_1_delta = layer_1_delta
synapse_0 += synapse_0_update * alpha
synapse_1 += synapse_1_update * alpha
synapse_h += synapse_h_update * alpha
synapse_0_update *= 0
synapse_1_update *= 0
synapse_h_update *= 0
# print out progress
if(j % 1000 == 0):
print "Error:" + str(overallError)
print "Pred:" + str(d)
print "True:" + str(c)
out = 0
for index,x in enumerate(reversed(d)):
out += x*pow(2,index)
print str(a_int) + " + " + str(b_int) + " = " + str(out)
print "------------"Convolutional neural networks are a type of feed-forward networks, which perform very well on visual recognition tasks.
A typical feature of CNN’s is that they nearly always have images as inputs, this allows for more efficient implementation and a reduction in the number of required parameters.
There are two basic principles that define convolution neural networks: filters and characteristic maps.
The main purpose of a convolutional layer is to detect characteristics or visual features in the images, such as edges, lines, colors, etc. This is done by a hidden layer connected to the input layer.
This step, called the convolution step, can be shown here. In CNNs, the 3×3 matrix is called the 'filter' or 'kernel' and the matrix formed by sliding the filter over the image and computing the dot product is called the ‘Convolved Feature’ or ‘Activation Map’ or the ‘Feature Map‘. It is important to note that filters act as feature detectors from the original input image.
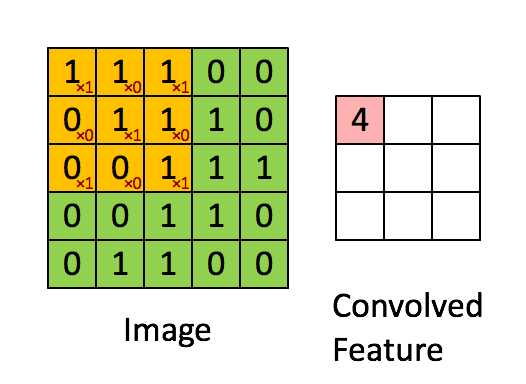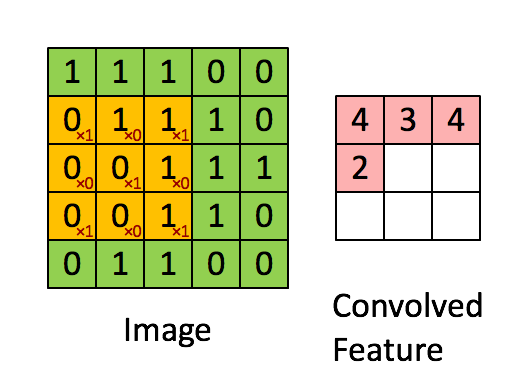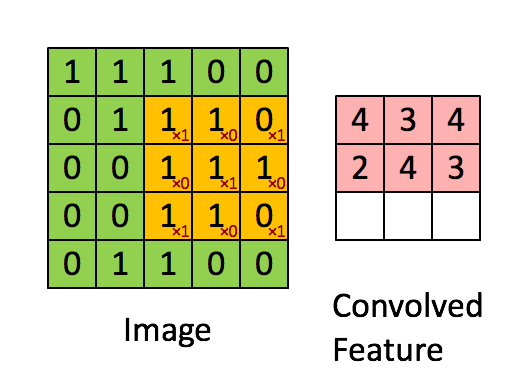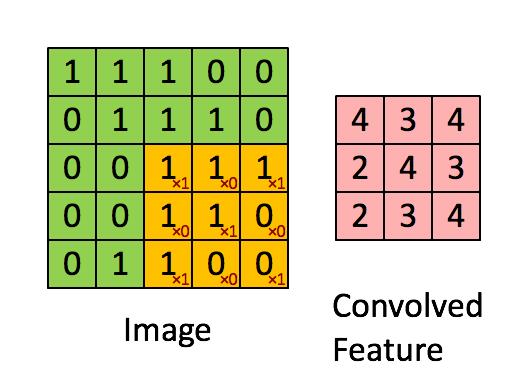{kind=link}
Now, let’s begin our MNIST digit recognition example. So naturally, first we import the needed modules:
import tensorflow as tf
import input_dataAnd of course, the actual dataset:
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)As before, we'll define the placeholders using TensorFlow as we did in the exercise in section 3.2.
x = tf.placeholder("float", shape=[None, 784])
y_ = tf.placeholder("float", shape=[None, 10])We can reconstruct the original shape of the images of the input data. We can do this as follows:
x_image = tf.reshape(x, [-1,28,28,1])In order to simplify the code, I define the following two functions related to the weight matrix and bias:
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)Similar to above, we define these two generic functions to be able to write a cleaner code that involves convolutions and max-pooling.
Spatial Pooling reduces the dimensionality of each feature map but retains the most important information. In case of Max Pooling, a type of spatial pooling, we define a spatial neighborhood and take the largest element from the rectified feature map within that window.
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')Now it is time to implement the first convolutional layer followed by a pooling layer.
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])As a final step, we apply max-pooling to the output:
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)When constructing a deep neural network, we can stack several layers on top of each other.
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])Now, we want to flatten the tensor into a vector.
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)Now we are ready to train the model that we have just defined by adjusting all the weights in the convolution, and fully connected layers to obtain the predictions of the images.
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess = tf.Session()
sess.run(tf.initialize_all_variables())
for i in range(200):
batch = mnist.train.next_batch(50)
if i%10 == 0:
train_accuracy = sess.run( accuracy, feed_dict={ x:batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g"%(i, train_accuracy))
sess.run(train_step,feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print("test accuracy %g"% sess.run(accuracy, feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))Deep Learning is a math intensive field of machine learning - in this tutorial, we omit a lot of the mathematical concepts, so I recommend going through these details on your own so you can gain a better understanding of why these algorithms work the way they do.
Complete Deep Learning Book
Deep Learning in Neural Networks