trace: clashing RPCs share the same traceID #182
Comments
|
/cc @bogdandrutu |
|
Hi @odeke-em, seems like you are using an older version of opencensus. Could you try the latest version 0.1.5 to see if the problem still exists? |
|
Thanks @liyanhui1228. Interestingly I had downloaded the latest from Github and was using it after running However, now the gRPC interceptor doesn't seem to be creating the parent span yet with |


|
And yes, I was able to reproduce it again just now by running multiple clients that clash e.g to the client.py I fed them a ~0.5MB file and made this #!/usr/bin/env python3
# Copyright 2018, OpenCensus Authors
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import time
import random
import grpc
import defs_pb2_grpc as proto
import defs_pb2 as pb
def main():
channel = grpc.insecure_channel('localhost:9778')
stub = proto.FetchStub(channel)
f = open('gulliversTravels.txt').read().split('\n')
while True:
lines = random.sample(f, 10)
for lineIn in lines:
capitalized = stub.Capitalize(pb.Payload(data=bytes(lineIn, encoding='utf-8')))
print('< %s\n'%(capitalized.data.decode('utf-8')))
time.sleep(random.random() * 8)
if __name__ == '__main__':
main()to give so the problem persists even on |

|
And actually able to produce many of them in succession |

|
And for a comparison, for about 15 minutes, I've been running the Java gRPC server https://github.com/orijtech/opencensus-for-grpc-java-developers receiving about 14 concurrent requests from the Python client with no problem at all, it produces the right results, right span names too |

|
I think this is due to a bug in how SpanDatas are converted into the legacy trace json format. This line incorrectly assumes that all spans passed to it are part of the same trace. We should either:
I'm OOO right now, but I can probably grab this when I get back. |
|
@odeke-em I think the problem is that in here a |
|
I have been tracking down an issue that sounds like it is exactly what @wkiser describes. The problem in my case is made much worse by using the BackgroundThreadTransport which virtually guarantees spans get mashed into exporter submissions for the wrong trace id |
|
So this is a GIGANTIC kludge and not even worth opening a PR over but I modified background_thread.py _Worker._thread_main() with the following to fix the mixed up spans issue: Just throwing it out there - may or may not be useful. As a side note, I also feel like |
Thank you for the response @liyanhui1228 and my apologies for the late reply, I've been swamped that I forgot to check here. I've tried just that right now but unfortunately the same problem even after trying out the change orijtech/opencensus-for-grpc-python-developers@93a5392 Please let me know what y'all think? I believe @wkiser and @dhendry have made some postulates in here that we could also try. |
|
Above is the latest output even after the change |

|
I am experiencing the same issue here as well, any update on a fix? |
|
It seems like the span context trace id for each trace is the same. Is this expected? For example I'm outputting this trace data when adding a Maybe my consumer code is incorrect? |
|
After more debugging, it seems like the tracer instance holds on to the same span context throughout its lifetime. I never see the span context get refreshed with a new trace id. Shouldn't the tracer be creating a new span context for each new trace? Or should a new tracer be created on each trace? |
|
Okay so it seems like the issue I'm experiencing is related to using the tornado web framework in conjunction with the opencensus interceptor. I've added an example to reproduce the issue I'm experiencing here: https://github.com/tab1293/opencensus-python/blob/a3bd681ab27fa161c6b398e43483d2385c85ee15/examples/trace/grpc/hello_world_tornado_client.py Running this example produces a trace that looks like this: I'm wondering if this issue has to do something with how threading is handled in this module? The example provided is not using the async transporter FWIW. Any help is appreciated, I'd be more that happy to provide a fix! Edit: It seems like you can also reproduce without tornado by just wrapping calls in a loop... diff --git a/examples/trace/grpc/hello_world_client.py b/examples/trace/grpc/hello_world_client.py
index 5752790..bc7037c 100644
--- a/examples/trace/grpc/hello_world_client.py
+++ b/examples/trace/grpc/hello_world_client.py
@@ -35,8 +35,9 @@ def main():
channel = grpc.insecure_channel(HOST_PORT)
channel = grpc.intercept_channel(channel, tracer_interceptor)
stub = hello_world_pb2_grpc.GreeterStub(channel)
- response = stub.SayHello(hello_world_pb2.HelloRequest(name='you'))
- print("Message received: " + response.message)
+ for i in range(5):
+ response = stub.SayHello(hello_world_pb2.HelloRequest(name='you'))
+ print("Message received: " + response.message)
if __name__ == '__main__':Gives this trace with all separate calls packed in to one trace: |


|
Hey @tab1293, thanks for the detailed report.
This looks like the problem to me. I would expect that after closing the root span we'd refresh the context and get a new trace ID, but instead we just null out the current context's span ID: opencensus-python/opencensus/trace/tracers/context_tracer.py Lines 111 to 113 in f029bcd So we're keeping the same trace ID around for the lifetime of the tracer. If you use a new tracer for each request everything works as expected: diff --git a/examples/trace/grpc/hello_world_client.py b/examples/trace/grpc/hello_world_client.py
index 5752790..14a9404 100644
--- a/examples/trace/grpc/hello_world_client.py
+++ b/examples/trace/grpc/hello_world_client.py
@@ -28,15 +28,15 @@ HOST_PORT = 'localhost:50051'
def main():
exporter = stackdriver_exporter.StackdriverExporter()
- tracer = Tracer(exporter=exporter)
- tracer_interceptor = client_interceptor.OpenCensusClientInterceptor(
- tracer,
- host_port=HOST_PORT)
- channel = grpc.insecure_channel(HOST_PORT)
- channel = grpc.intercept_channel(channel, tracer_interceptor)
- stub = hello_world_pb2_grpc.GreeterStub(channel)
- response = stub.SayHello(hello_world_pb2.HelloRequest(name='you'))
- print("Message received: " + response.message)
+ for ii in range(5):
+ tracer = Tracer(exporter=exporter)
+ tracer_interceptor = client_interceptor.OpenCensusClientInterceptor(
+ tracer, host_port=HOST_PORT)
+ channel = grpc.insecure_channel(HOST_PORT)
+ channel = grpc.intercept_channel(channel, tracer_interceptor)
+ stub = hello_world_pb2_grpc.GreeterStub(channel)
+ response = stub.SayHello(hello_world_pb2.HelloRequest(name='you'))
+ print("Message received: " + response.message)...but I doubt you want to do that, and I don't think that matches the behavior of the clients in other languages. Changing the tracer to use a new trace ID after closing the root span also fixes the problem, but may well break something else: diff --git a/opencensus/trace/tracers/context_tracer.py b/opencensus/trace/tracers/context_tracer.py
index 1cb0306..b8e579c 100644
--- a/opencensus/trace/tracers/context_tracer.py
+++ b/opencensus/trace/tracers/context_tracer.py
@@ -17,6 +17,7 @@ import threading
from opencensus.trace import execution_context
from opencensus.trace.span_context import SpanContext
+from opencensus.trace.span_context import generate_trace_id
from opencensus.trace import span as trace_span
from opencensus.trace import span_data as span_data_module
from opencensus.trace.exporters import print_exporter
@@ -116,6 +117,7 @@ class ContextTracer(base.Tracer):
execution_context.set_current_span(cur_span.parent_span)
else:
execution_context.set_current_span(None)
+ self.span_context.trace_id = generate_trace_id()
with self._spans_list_condition:
if cur_span in self._spans_list: |
@odeke-em this is surprising since it looks like the problem is on the client side. Running the java grpc server with the python client, I'd still expect all requests to have the same trace ID since we're setting it in the client and passing it along to the server in the context. What am I missing here? |
@tab1293 I'd be amazed if tornado didn't cause serious problems for opencensus since we're storing the current span in a threadlocal and (as I understand it) tornado uses a single-threaded event loop. For example, I'd expect this to report @gen.coroutine
def f1():
tracer = Tracer()
tracer.start_span('f1_span')
try:
r1 = yield expensive1()
raise gen.Return(r1)
finally:
tracer.end_span()
@gen.coroutine
def f2():
tracer = Tracer()
tracer.start_span('f2_span')
try:
r2 = yield expensive2()
raise gen.Return(r2)
finally:
tracer.end_span()
@gen.coroutine
def main():
yield f1()
yield f2()instead of reporting them as siblings, as would be the case if I haven't tried running this, so take it with a grain of salt. |
I don't think it makes any sense to do that, it would require creating a new GRPC channel for each trace. Channels are expensive to create and should be used across stubs as per grpc/grpc-java#3268 (comment). I don't understand the current design of having to create a new interceptor for each trace, is this just a flawed paradigm specific to the
That looks like a valid fix to me. Are there any cases when there can be multiple root spans in a single trace? What specifically are you worried about breaking?
Why is the local thread being used to store instances of spans and tracers? I'm confused to why the
Where in the code would |
I think this is just a bug, and that we should get a new trace ID or whole new span context on each call. This isn't specific to stackdriver, or even the grpc client interceptor.
Not as far as I know. I think this is the right fix too, I just need to verify it.
It's so you can start a span in one place and end it in another without passing the span or tracer around. It's not necessary if you're only using the grpc interceptors, but if you create a span in application code we need to attach it as a child of the span created by the interceptor. In that case we get the current span from the execution context.
I mean if you were using |
In a typical web server gRPC clients/channels are reused across multiple requests and hence across multiple traces. Previously the `OpenCensusClientInterceptor` was instantiated for each channel with the current tracer from the execution context. This would then lead to all rpcs going through that channel to have the same tracer, essentially grouping all rpcs under whatever happened to be the current trace when the channel was created. Instead instantiate `OpenCensusClientInterceptor` without a tracer by default. The current tracer will be retrieved from the execution context at the start of every rpc span. In addition `OpenCensusClientInterceptor` was manipulating thread-local state via the execution context. This seems unnecessary and misguided. The current span state is already managed by the spans/context tracers. Setting the tracer explicitly risks further subtle bugs. Also removes unused method `OpenCensusClientInterceptor._end_span_between_context`. Fixes census-instrumentation#182
In a typical web server gRPC clients/channels are reused across multiple requests and hence across multiple traces. Previously the `OpenCensusClientInterceptor` was instantiated for each channel with the current tracer from the execution context. This would then lead to all rpcs going through that channel to have the same tracer, essentially grouping all rpcs under whatever happened to be the current trace when the channel was created. Instead instantiate `OpenCensusClientInterceptor` without a tracer by default. The current tracer will be retrieved from the execution context at the start of every rpc span. In addition `OpenCensusClientInterceptor` was manipulating thread-local state via the execution context. This seems unnecessary and misguided. The current span state is already managed by the spans/context tracers. Setting the tracer explicitly risks further subtle bugs. Also removes unused method `OpenCensusClientInterceptor._end_span_between_context`. Fixes census-instrumentation#182
In a typical web server gRPC clients/channels are reused across multiple requests and hence across multiple traces. Previously the `OpenCensusClientInterceptor` was instantiated for each channel with the current tracer from the execution context. This would then lead to all rpcs going through that channel to have the same tracer, essentially grouping all rpcs under whatever happened to be the current trace when the channel was created. Instead instantiate `OpenCensusClientInterceptor` without a tracer by default. The current tracer will be retrieved from the execution context at the start of every rpc span. In addition `OpenCensusClientInterceptor` was manipulating thread-local state via the execution context. This seems unnecessary and misguided. The current span state is already managed by the spans/context tracers. Setting the tracer explicitly risks further subtle bugs. Also removes unused method `OpenCensusClientInterceptor._end_span_between_context`. Fixes census-instrumentation#182
|
I can trivially reproduce this bug with import requests
import time
import random
from opencensus.ext.ocagent import (
stats_exporter,
trace_exporter,
)
from opencensus.trace import config_integration
from opencensus.trace.samplers import AlwaysOnSampler
from opencensus.trace.status import Status
from opencensus.trace.tracer import Tracer
def main():
config_integration.trace_integrations(['requests'])
tracer = register_all('mediasearch-py')
while True:
query = input('Content to search$ ')
if query == '' or query == '\n':
return
print('query: "' + query + '"')
with tracer.span(name='SearchMedia') as span:
doSearch(tracer, query)
# span.finish()
# time.sleep(random.random() * 37)
def register_all(service_name):
texp = trace_exporter.TraceExporter(
service_name=service_name,
endpoint='localhost:55678')
return Tracer(exporter=texp, sampler=AlwaysOnSampler())
def doSearch(tracer, query):
with tracer.span(name='doSearch') as span:
res = requests.post('http://localhost:9778/search', json={'keywords': query})
pages = res.json()
if not pages:
return
for page in pages:
items = page['items']
for i, item in enumerate(items):
id = item['id']
if 'videoId' in id:
print('URL: https://youtu.be/{videoId}'.format(**item['id']))
elif 'channelId' in id:
print('ChannelURL: https://www.youtube.com/channel/{channelId}'.format(**item['id']))
snippet = item['snippet']
snippet.setdefault('description', 'Unknown')
print('Title: {title}\nDescription: {description}\n\n'.format(**snippet))
if __name__ == '__main__':
main()and even single trace shares the same TraceID, using the latest version of OpenCensus-Python aka v0.7.7 and ocagent version 0.0.1. Please re-open this bug. |
I built code for a demo for "OpenCensus for Python gRPC developers" at https://github.com/orijtech/opencensus-for-grpc-python-developers and blogpost https://medium.com/@orijtech/opencensus-for-python-grpc-developers-9e460e054395
Given this code below
Server
Client
However, while running multiple clients to simulate traffic and popularity of a service, I noticed that a bunch of traces were bunched up together as viewed in the Stackdriver UI
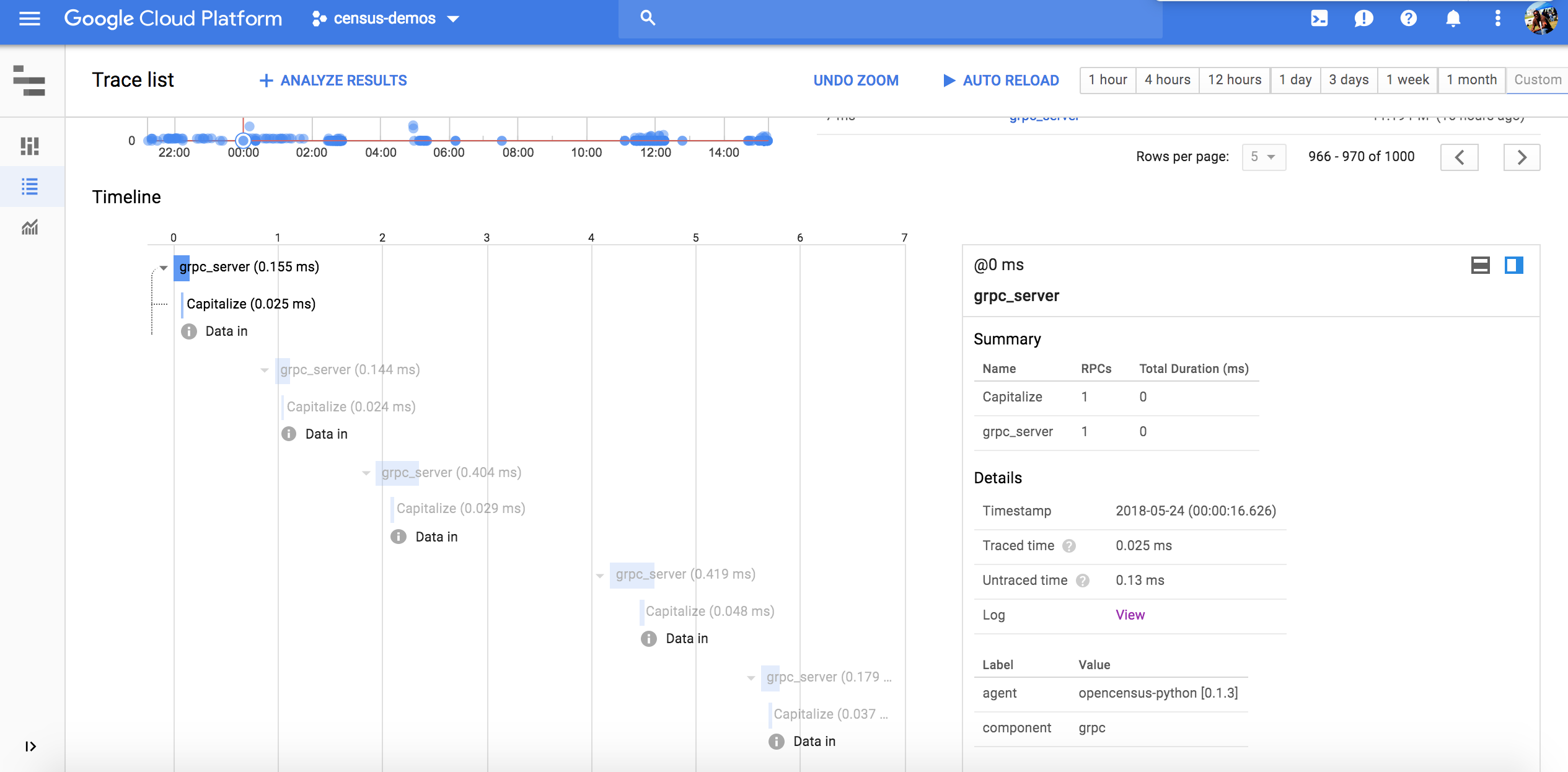
Bouncing around ideas with @sebright and @songy23, @sebright gave a postulation of perhaps the same traceID being shared which alas seems to the be problem, as per our log examinations
This has a problem of bunching up totally different traces from different clients that are concurrently occuring and seems perhaps like a bug?
The text was updated successfully, but these errors were encountered: