English Homepage | 中文文档 | 常见问题

Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models

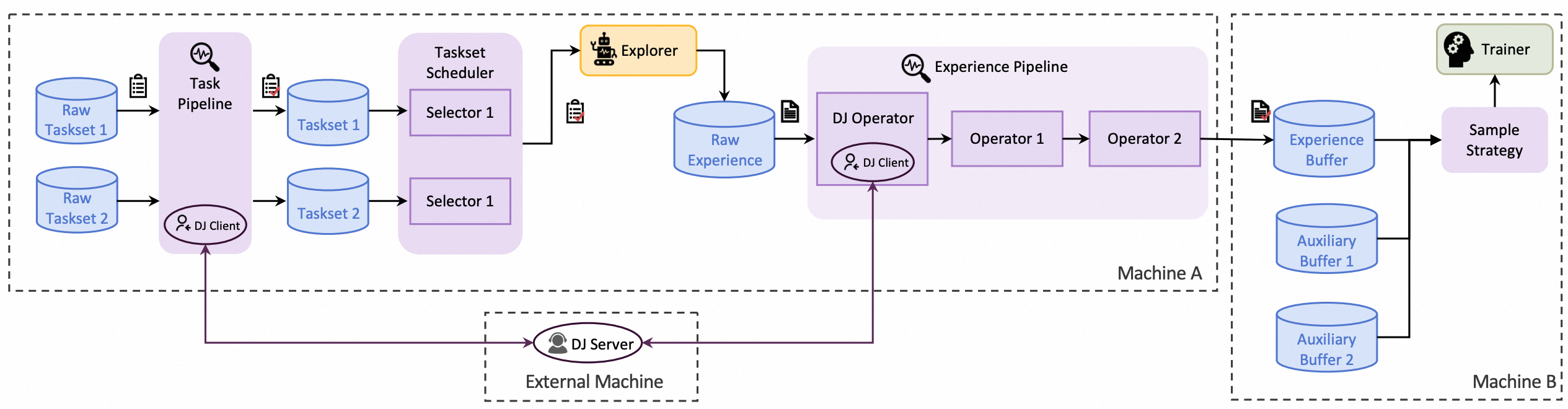
Trinity-RFT 是一个通用、灵活、用户友好的大语言模型(LLM)强化微调(RFT)框架。 其将 RFT 流程解耦为三个协同运行的关键模块:
-
Explorer 负责执行智能体-环境交互,并生成经验数据;
-
Trainer 在经验数据上最小化损失函数,以此更新模型参数;
-
Buffer 负责协调整个 RFT 生命周期中的数据处理流水线。
Trinity-RFT 面向不同背景和目标的用户提供相应功能:
-
🤖 智能体应用开发者: 训练智能体应用,以增强其在特定领域中完成任务的能力 [教程]
-
🧠 强化学习算法研究者: 通过定制化简洁、可插拔的模块,设计、实现与验证新的强化学习算法 [教程]
-
📊 数据工程师: 设计针对任务定制的数据集,构建处理流水线以支持数据清洗、增强以及人类参与场景 [教程]
- [2026-03] 🤖 Trinity-RFT 助力 CoPaw-Flash 训练,打造更懂本地化场景的智能体小模型。欢迎到 CoPaw 试用 CoPaw-Flash,模型下载请见 ModelScope 和 HuggingFace(新闻)。
- [2026-03] Trinity-RFT 现在已经支持 Qwen3.5 系列模型。
- [2026-02] [发布说明] Trinity-RFT v0.5.1 发布:增强 VLM 支持,改进日志系统,修复若干 Bug。
- [2026-02] [发布说明] Trinity-RFT v0.5.0 发布:单 GPU 场景下的 colocate 模式,trainer 驱动的权重同步,自动并行设置建议等新功能。
- [2026-01] 🎉 三篇论文被 ICLR 2026 接收:CHORD、BOTS 和 Group-relative REINFORCE 系列变种。在 Trinity-RFT 中尝试这些新算法吧!
- [2026-01] [发布说明] Trinity-RFT v0.4.1 发布:升级 verl 至 v0.7.0,Tinker 后端支持 OpenAI API,修复若干 Bug。
- [2026-01] 推出 R3L:基于反思-重试的强化学习机制,由自然语言反馈引导高效探索,并达成稳定的 off-policy 学习(论文)。
- [2025-12] [发布说明] Trinity-RFT v0.4.0 发布:新增Tinker 后端以支持在 无 GPU 的设备上训练,增加更多基准测试,增强在线 RL 等功能。
- [2025-12] Trinity-RFT 助力淘宝闪购医药健康业务,让 AI 智能体能够理解模糊症状、主动询问后续问题,并提供精准推荐(新闻)。
- [2025-11] [发布说明] Trinity-RFT v0.3.3 发布:修复若干 Bug。
- [2025-11] 推出 Learn-to-Ask:利用离线专家数据,训练具备主动问询能力的对话智能体(论文)。
More...
- [2025-11] 推出 [BOTS](https://github.com/agentscope-ai/Trinity-RFT/tree/main/examples/bots):在线 RL 任务选择,实现高效 LLM 微调([论文](https://arxiv.org/pdf/2510.26374))。
- [2025-09] 我们的 [论文](https://arxiv.org/pdf/2509.24203) 揭示了 group-relative REINFORCE 及其变种(如 GRPO 和 AsymRE)的 off-policy 解释([代码](https://github.com/agentscope-ai/Trinity-RFT/tree/main/examples/rec_gsm8k))。
- [2025-08] 推出 [CHORD](https://github.com/agentscope-ai/Trinity-RFT/tree/main/examples/mix_chord):动态 SFT + RL 集成,实现进阶 LLM 微调([论文](https://arxiv.org/pdf/2508.11408))。
- [2025-11] Trinity-RFT v0.3.2 发布:修复若干 Bug 并支持进阶的任务选择和调度。
- [2025-10] Trinity-RFT v0.3.1 发布:多阶段训练支持、改进的智能体 RL 示例、LoRA 支持、调试模式和全新 RL 算法。
- [2025-09] Trinity-RFT v0.3.0 发布:增强的 Buffer、FSDP2 & Megatron 支持,多模态模型,以及全新 RL 算法/示例。
- [2025-08] Trinity-RFT v0.2.1 发布。
- [2025-07] Trinity-RFT v0.2.0 发布。
- [2025-07] 技术报告(arXiv v2)更新,包含新功能、示例和实验:[链接](https://arxiv.org/abs/2505.17826)。
- [2025-06] Trinity-RFT v0.1.1 发布。
- [2025-05] Trinity-RFT v0.1.0 发布,同时发布 [技术报告](https://arxiv.org/abs/2505.17826)。
- [2025-04] Trinity-RFT 开源。
| 类别 | 教程 / 指南 |
|---|---|
| 运行各种 RFT 模式 | + 快速开始:在 GSM8k 上运行 GRPO + Off-policy RFT + 全异步 RFT + 通过 DPO 或 SFT 进行离线学习 + 在无GPU环境下运行RFT训练(Tinker 后端) |
| 多轮智能体强化学习 | + 拼接多轮任务 + 通用多轮任务 + 调用智能体框架中的 ReAct 工作流 + 例子:训练一个网络搜索智能体 |
| 全生命周期的数据流水线 | + Rollout 任务混合与选取 + 在线任务选择 (📝 论文) + 研究项目:learn-to-ask (📝 论文) + 经验回放机制 + 高级数据处理能力 & Human-in-the-loop |
| 强化学习算法开发 | + 使用 Trinity-RFT 进行 RL 算法开发 (📝 论文) + 研究项目: R3L (基于反思-重试的强化学习) (📝 论文) + 研究项目: group-relative REINFORCE (📝 论文) + 不可验证的领域: RULER, 可训练 RULER, rubric-as-reward |
| 基准测试 | + 基准测试工具 (快速验证与实验) + Guru-Math 测试 & 对比 veRL + FrozenLake 测试 & 对比 rLLM + Alfworld 测试 & 对比 rLLM |
| 深入了解 Trinity-RFT | + 完整配置指南 + GPU 资源与训练配置对应指南 + 训练多模态模型 + 理解 explorer-trainer 同步逻辑 + 如何与 verl 对齐配置 |
Tip
推荐阅读顺序
🆕 新手入门: 安装 → 快速开始 (GSM8K) → 参数配置指南 → GPU 资源配置指南
🔬 算法研究者: 开发者指南 → 算法开发指南 → CHORD 算法示例
🤖 Agent 开发者: 开发者指南 → Workflow 开发 → 通用多轮 Workflow 示例
Note
更多教程请参考 Trinity-RFT 文档。
-
灵活的 RFT 模式:
- 支持同步/异步、on-policy/off-policy 以及在线/离线强化学习
- 采样与训练可分离运行,并可在多设备上独立扩展
- 支持经验回放,进一步提升样本与时间效率
-
Agentic RL 支持:
- 支持拼接式多轮和通用多轮交互
- 能够直接训练使用 AgentScope 等智能体框架开发的 Agent 应用
-
全生命周期的数据流水线:
- 支持 rollout 任务和经验数据的流水线处理
- 贯穿 RFT 生命周期的主动数据管理(优先级排序、清洗、增强等)
- 原生支持多任务联合训练与课程学习
-
用户友好的框架设计:
- 即插即用模块与解耦式架构,便于快速上手和二次开发
- 丰富的图形界面,支持低代码使用



下表列出了 Trinity-RFT 支持的算法,更多算法请参考 算法模块。您也可以通过自定义不同的模块来构建新算法,参见 教程。
| 算法 | 文档/示例 | 核心代码 | 关键配置 |
|---|---|---|---|
| PPO [论文] | [文档] [Countdown 示例] | [代码] | algorithm_type: ppo |
| GRPO [论文] | [文档] [GSM8K 示例] | [代码] | algorithm_type: grpo |
| SFT | [Mixture-of-Thoughts 示例] | [代码] | algorithm_type: sft |
| DPO [论文] | [HumanLike 示例] | [代码] | algorithm_type: dpo |
| CHORD 💡 [论文] | [文档] [ToolACE 示例] | [代码] | algorithm_type: mix_chord |
| REC Series 💡 [论文] | [GSM8K 示例] | [代码] | algorithm_type: rec |
| RLOO [论文] | - | [代码] | algorithm_type: rloo |
| REINFORCE++ [论文] | - | [代码] | algorithm_type: reinforceplusplus |
| GSPO [论文] | - | [代码] | algorithm_type: gspo |
| TOPR [论文] | [GSM8K 示例] | [代码] | algorithm_type: topr |
| sPPO [论文] | [GSM8K 示例] | [代码] | algorithm_type: sppo |
| AsymRE [论文] | [GSM8K 示例] | [代码] | algorithm_type: asymre |
| CISPO [论文] | - | [代码] | algorithm_type: cispo |
| SAPO [论文] | - | [代码] | algorithm_type: sapo |
| On-Policy Distillation [博客] [论文] | [GSM8K 示例] | [代码] | algorithm_type: on_policy_distill |
| JSD(Jensen-Shannon 散度) | [GSM8K 示例] | [代码] | algorithm_type: jsd |
Note
本项目正处于活跃开发阶段。欢迎提出意见和建议!
如果您没有 GPU,仍然可以通过 Tinker 后端体验 Trinity-RFT。
# 创建并激活环境
python3.10 -m venv .venv
source .venv/bin/activate
# 安装支持仅 CPU 后端的 Trinity-RFT
pip install -e ".[tinker]"运行一个简单示例:
trinity run --config examples/tinker/tinker.yaml该示例专为仅使用 CPU 的设备设计。更多细节请参见完整的 Tinker 训练示例。
如需在 GPU 设备上运行 Trinity-RFT,请按照以下步骤操作。
在安装之前,请确保您的系统满足以下要求:
- Python:版本 3.10 至 3.12(含)
- CUDA:版本 >= 12.8
- GPU: 至少一块 compute capability 为 8.0 或更高的 NVIDIA GPU(例如 RTX 30 系列、A100、H100)
推荐安装方式:
- 没有 GPU → 使用 Tinker 后端
- 希望快速搭建 → 使用 Docker
- 希望开发和贡献 → 使用 Conda / venv
如需修改、扩展 Trinity-RFT,推荐使用此方法。
首先,克隆仓库:
git clone https://github.com/agentscope-ai/Trinity-RFT
cd Trinity-RFT然后,通过以下任一方式构建环境:
使用预构建 Docker 镜像(推荐初学者使用该方法)
docker pull ghcr.io/agentscope-ai/trinity-rft:latest
# 将 <path_to_your_data_and_checkpoints> 替换为实际需要挂载的路径
docker run -it \
--gpus all \
--shm-size="64g" \
--rm \
-v $PWD:/workspace \
-v <path_to_your_data_and_checkpoints>:/data \
ghcr.io/agentscope-ai/trinity-rft:latest该镜像已经通过
uv安装了 Trinity-RFT 以及所有 GPU 相关依赖,且会自动激活虚拟环境(也可通过source /opt/venv/bin/activate手动激活)。必要时可使用uv pip install添加额外的包。
使用 Conda
conda create -n trinity python=3.12
conda activate trinity
pip install -e ".[vllm,flash_attn]"
# 如果没有GPU,可以注释上一行的命令,改为使用Tinker:
# pip install -e ".[tinker]"
# 如果安装 flash-attn 时遇到问题,可尝试:
# pip install flash-attn==2.8.1 --no-build-isolation
pip install -e ".[dev]" # 用于调试和开发使用 venv
python3.10 -m venv .venv
source .venv/bin/activate
pip install -e ".[vllm,flash_attn]"
# 如果没有GPU,可以注释上一行的命令,改为使用Tinker:
# pip install -e ".[tinker]"
# 如果安装 flash-attn 时遇到问题,可尝试:
# pip install flash-attn==2.8.1 --no-build-isolation
pip install -e ".[dev]" # 用于调试和开发使用 uv
uv 是现代的 Python 包管理工具。
uv sync --extra vllm --extra dev --extra flash_attn
# 如果没有GPU,可以改为使用Tinker:
# uv sync --extra tinker --extra dev如果您只需使用 Trinity-RFT 而不打算修改代码:
pip install trinity-rft
pip install flash-attn==2.8.1或使用 uv:
uv pip install trinity-rft
uv pip install flash-attn==2.8.1如需使用 Megatron-LM 进行训练,请参考 Megatron-LM 支持
Trinity-RFT 支持来自 Huggingface 和 ModelScope 的大多数数据集和模型。
准备模型,保存到本地目录 $MODEL_PATH/{model_name}:
# 使用 Huggingface
huggingface-cli download {model_name} --local-dir $MODEL_PATH/{model_name}
# 使用 ModelScope
modelscope download {model_name} --local_dir $MODEL_PATH/{model_name}更多关于模型下载的细节,请参考 Huggingface 或 ModelScope。
准备数据集,保存到本地目录 $DATASET_PATH/{dataset_name}:
# 使用 Huggingface
huggingface-cli download {dataset_name} --repo-type dataset --local-dir $DATASET_PATH/{dataset_name}
# 使用 ModelScope
modelscope download --dataset {dataset_name} --local_dir $DATASET_PATH/{dataset_name}更多关于数据集下载的细节,请参考 Huggingface 或 ModelScope。
Trinity-RFT 提供了一个 Web 界面来配置您的 RFT 流程。
Note
这是一个实验性功能,我们将持续改进。
要启动 Web 界面进行配置,您可以运行:
trinity studio --port 8080然后您可以在网页上配置您的 RFT 流程并生成一个配置文件。您可以保存该配置文件以备后用,或按照下一节的描述直接运行。
高阶用户也可以直接编辑配置文件。
我们在 examples 目录中提供了一些示例配置文件。
若需完整的 GUI 功能,请参考 Trinity-Studio 仓库。
示例:配置管理器 GUI

启动一个 Ray 集群:
# 在主节点上
ray start --head
# 在工作节点上
ray start --address=<master_address>(可选)您可以使用 Wandb / TensorBoard / MLFlow 等工具,更方便地监控训练流程。 相应的配置方法请参考 这个文档。 比如使用 Wandb 时,您需要先登录:
export WANDB_API_KEY=<your_api_key>
wandb login对于命令行用户,运行 RFT 流程:
trinity run --config <config_path>例如,以下是在 GSM8k 数据集上使用 GRPO 微调 Qwen2.5-1.5B-Instruct 的命令:
trinity run --config examples/grpo_gsm8k/gsm8k.yaml对于 Studio 用户,在 Web 界面中点击“运行”。
本项目正处于活跃开发阶段——点击 Star 关注本仓库以获取最新更新!
我们欢迎来自社区的各种贡献,包括:
- 文档改进
- 工作流、算法和数据处理流水线
- Bug 修复和性能优化
如果您是项目新手,文档和例子的更新是很好的入手点。
详细的贡献指南请参见 CONTRIBUTING.md,以及我们的 good-first-issue 列表。
本项目基于许多优秀的开源项目构建,包括:
- verl,FSDP 和 Megatron-LM 用于大模型训练;
- vLLM 用于大模型推理;
- Data-Juicer 用于数据处理流水线;
- AgentScope 用于智能体工作流;
- Ray 用于分布式系统;
- 我们也从 OpenRLHF、TRL、ChatLearn 和 rLLM 等框架中汲取了灵感;
- ......
@misc{trinity-rft,
title={Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models},
author={Xuchen Pan and Yanxi Chen and Yushuo Chen and Yuchang Sun and Daoyuan Chen and Wenhao Zhang and Yuexiang Xie and Yilun Huang and Yilei Zhang and Dawei Gao and Yaliang Li and Bolin Ding and Jingren Zhou},
year={2025},
eprint={2505.17826},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2505.17826},
}