|
1 | | -# 实验1 Python数据分析环境设置 |
2 | | -## 实验目的 |
3 | | -1. 掌握Anaconda的安装和配置 |
4 | | -2. 熟悉JupyterNotebook、Spyder工具的使用 |
5 | | -3. 编写和执行Python源文件程序 |
6 | | -4. 在线帮助和相关资源 |
7 | | - |
8 | | -## 实验时间和地点 |
9 | | -2课时,计算机机房 |
10 | | - |
11 | | -## 实验内容 |
12 | | -1. 安装Anaconda; |
13 | | -2. 扩展库的安装; |
14 | | -3. 熟悉Jupyter Notebook编程环境。 |
15 | | -4. 熟悉Spyder环境 |
16 | | -5. 编写第一个Python程序 |
17 | | - |
18 | | -## 实验步骤 |
19 | | -1. 下载Anaconda |
20 | | - 1. 从官网https://www.anaconda.com/products/individual 或https://anaconda.org/ 或下载最新版Anaconda3,需要根据安装的OS来进行选择。 |
21 | | - 2. 具体的安装环境要求可以查看官网的文档说明。 |
22 | | - 3. 如果需要,从 www.python.org 官网上下载Python。 |
23 | | - |
24 | | -2. 安装anaconda |
25 | | - 1. 安装时选择定制安装,建议不要把Anaconda安装在C盘上,安装路径最好不要有中文。 |
26 | | - 2. 安装时选择针对所有用户。 |
27 | | - 3. 可以把Anaconda自带的Python解释器加入到path中。 |
28 | | - 4. 如果想要单独使用Python解释器,可以专门下载Python,安装后设置Path。 |
29 | | - |
30 | | -3. 安装第三方库 |
31 | | - 1. 在Dos界面输入conda list查看已经安装的库和包 |
32 | | - 2. 如果没有scrapy包,输入conda install scrapy进行安装 |
33 | | - |
34 | | -4. 启动Spyder |
35 | | - 1. 【开始 】-->【所有程序】-->【anaconda】-->【Spyder(anaconda3】。 |
36 | | - 2. 观察Spyder界面,打开【tools】-->【Preferences】。 |
37 | | - 3. 可以在【current working directory】设置默认的启动目录等。其他设置使用习惯自己摸索。截图记录 |
38 | | - 4. 将下列代码录入、保存并执行。观察文件夹、文件创建情况,打开文件。 |
39 | | - 5. 使用“Variarible explorer” 观察变量,双击answer,观察变量的变化过程并截图保存。 |
40 | | - ```python |
41 | | - #Febonacci swquence |
42 | | - ''' |
43 | | - 斐波那契数列 |
44 | | - 输入:项数n |
45 | | - 输出:前n项 |
46 | | - ''' |
47 | | - import os |
48 | | - def fibo(n): |
49 | | - numbers=[1,1] |
50 | | - for i in range(n-2): |
51 | | - numbers.append(number[i]+numbers[i+1]) |
52 | | - return numbers |
53 | | - answer=fibo(10) |
54 | | - print(answer) |
55 | | - if not os.path.exists('result'): |
56 | | - os.mkdir('result') |
57 | | - file=open('result/fibo.txt','w') |
58 | | - for num in answer: |
59 | | - file.write(str(num)+' ') |
60 | | - file.close() |
61 | | - ``` |
62 | | - |
63 | | -5. 完成下面代码并观察输出和plot |
64 | | -```python |
65 | | -import matplotlib.pyplot as plt |
66 | | -import random |
67 | | -gradewords=('优秀','良好','中等','及格','不及格') |
68 | | -testwords=[random.choice(gradewords) for i in range(1000)] |
69 | | -result=dict() |
70 | | -for item in testwords: |
71 | | - if item in testwords: |
72 | | - result[item]=result.get(item,0)+1 |
73 | | -for key,v,int result.items(): |
74 | | - print(key,v,sep='--->') |
75 | | -plt.pie(result.values(),labels=result.keys(),autopct='%.2f%%') |
76 | | -plt.show() |
77 | | -``` |
78 | | -6. 启动Jupyter Notebook |
79 | | - 1. 【开始】-->【所有程序】-->【anaconda】-->【Jupyter Notebook】,如果打不开,选择复制链接。 |
80 | | - 2. 单击【new】--->“Python 3”,进入Python脚本编辑界面。 |
81 | | - |
82 | | -7. 编写第一个Python程序 |
83 | | - 输入:姓名 |
84 | | - 输出:“我是XX,这是我的第一个Python程序。” |
85 | | - |
86 | | -## 实验注意事项 |
87 | | -1. Python是解释型语言,需要Python解释器支持。 |
88 | | -2. 可以使用.tab来获取对象的属性,使用函数名?获取函数帮助信息,??函数名获取函数源码。 |
89 | | - |
90 | | -## 实验报告要求 |
91 | | -实验报告以电子文档形式提交。 |
92 | | -实验报告主要内容:anaconda安装过程、第三方扩展库的安装、Python程序基本结构,运行结果和过程记录、实验总结。 |
| 1 | +# 实验 1 Python 数据分析环境设置 |
| 2 | + |
| 3 | +### 实验目的 |
| 4 | + |
| 5 | +1. 掌握 Anaconda 的安装和配置 |
| 6 | +1. 熟悉 JupyterNotebook、Spyder 工具的使用 |
| 7 | +1. 编写和执行 Python 源文件程序 |
| 8 | +1. 在线帮助和相关资源 |
| 9 | + |
| 10 | +### 实验时间和地点 |
| 11 | + |
| 12 | +2 课时,计算机机房 |
| 13 | + |
| 14 | +实验内容 |
| 15 | + |
| 16 | +1. 安装 Anaconda; |
| 17 | +1. 扩展库的安装; |
| 18 | + |
| 19 | +2、熟悉 Jupyter Notebook 编程环境。 |
| 20 | +3、熟悉 Spyder 环境 |
| 21 | +4、编写第一个 Python 程序 |
| 22 | + |
| 23 | +### 实验步骤 |
| 24 | + |
| 25 | +1. 下载 Anaconda |
| 26 | + |
| 27 | +1. 从官网[https://www.anaconda.com/products/individual](https://www.anaconda.com/products/individual) 或[https://anaconda.org/](https://anaconda.org/)或下载最新版 Anaconda3,需要根据安装的 OS 来进行选择。 |
| 28 | +1. 具体的安装环境要求可以查看官网的文档说明。 |
| 29 | +1. 如果需要,从www.python.org官网上下载Python。 |
| 30 | +1. 安装 anaconda |
| 31 | +1. 安装时选择定制安装,建议不要把 Anaconda 安装在 C 盘上,安装路径最好不要有中文。 |
| 32 | +1. 安装时选择针对所有用户。 |
| 33 | +1. 可以把 Anaconda 自带的 Python 解释器加入到 path 中。 |
| 34 | +1. 如果想要单独使用 Python 解释器,可以专门下载 Python,安装后设置 Path。 |
| 35 | +1. 安装第三方库 |
| 36 | +1. 在 Dos 界面输入 conda list 查看已经安装的库和包 |
| 37 | +1. 如果没有 scrapy 包,输入 conda install scrapy 进行安装 |
| 38 | +1. 启动 Spyder |
| 39 | + |
| 40 | +1) 【开始 】-->【所有程序】-->【anaconda】-->【Spyder(anaconda3】。 |
| 41 | + |
| 42 | +1. 观察 Spyder 界面,打开【tools】🡪【Preferences】。 |
| 43 | +1. 可以在【current working directory】设置默认的启动目录等。其他设置使用习惯自己摸索。截图记录 |
| 44 | +1. 将下列代码录入、保存并执行。观察文件夹、文件创建情况,打开文件。 |
| 45 | +1. 使用“Variarible explorer” 观察变量,双击 answer,观察变量的变化过程并截图保存。 |
| 46 | + |
| 47 | +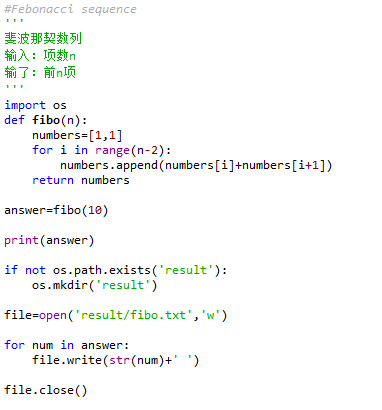 |
| 48 | + |
| 49 | +1. 完成下面代码并观察输出和 plot |
| 50 | + |
| 51 | +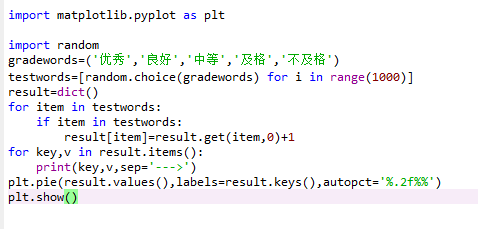 |
| 52 | + |
| 53 | +1. 启动 Jupyter Notebook |
| 54 | + 1. 【开始 】-->【所有程序】-->【anaconda】-->【Jupyter Notebook】,如果打不开,选择复制链接。 |
| 55 | +1. 单击【new】--->“Python 3”,进入 Python 脚本编辑界面。 |
| 56 | + |
| 57 | +1. 编写第一个 Python 程序 |
| 58 | + |
| 59 | + 输入:姓名 |
| 60 | + |
| 61 | + 输出:“我是 XX,这是我的第一个 Python 程序。” |
| 62 | + |
| 63 | +### 实验注意事项 |
| 64 | + |
| 65 | +1)Python 是解释型语言,需要 Python 解释器支持。 |
| 66 | +2)可以使用.tab 来获取对象的属性,使用函数名?获取函数帮助信息,??函数名获取函数源码。 |
| 67 | + |
| 68 | +### 实验报告要求 |
| 69 | + |
| 70 | + 实验报告以电子文档形式提交。 |
| 71 | + |
| 72 | +实验报告主要内容:anaconda 安装过程、第三方扩展库的安装、Python 程序基本结构,运行结果和过程记录、**实验总结。** |
0 commit comments