introduced bugs immediately. Several bug\n"
+ ]
+ }
+ ],
+ "source": [
+ "search_result = retriever.invoke(\"How to find problems in code?\")\n",
+ "print(search_result[0].page_content[:100])"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3 (ipykernel)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.10.10"
+ },
+ "colab": {
+ "provenance": [],
+ "include_colab_link": true
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
From 6c28fcb5f4d6c22447f8ea825ec367e7c4f6fa68 Mon Sep 17 00:00:00 2001
From: Hyesoo Kim <100982596+duper203@users.noreply.github.com>
Date: Thu, 3 Oct 2024 09:25:13 -0700
Subject: [PATCH 2/7] Update 05_1_ChromaDB.ipynb
---
05_1_ChromaDB.ipynb | 12 +-----------
1 file changed, 1 insertion(+), 11 deletions(-)
diff --git a/05_1_ChromaDB.ipynb b/05_1_ChromaDB.ipynb
index b73d11c..f870983 100644
--- a/05_1_ChromaDB.ipynb
+++ b/05_1_ChromaDB.ipynb
@@ -1,15 +1,5 @@
{
"cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "view-in-github",
- "colab_type": "text"
- },
- "source": [
- "![]() "
- ]
- },
{
"cell_type": "markdown",
"metadata": {
@@ -433,4 +423,4 @@
},
"nbformat": 4,
"nbformat_minor": 0
-}
\ No newline at end of file
+}
From bc39bd432eebe4348dafee63fbab16d8b4d8b8bf Mon Sep 17 00:00:00 2001
From: Hyesoo Kim <100982596+duper203@users.noreply.github.com>
Date: Thu, 3 Oct 2024 09:47:00 -0700
Subject: [PATCH 3/7] Created using Colab
---
05_1_ChromaDB.ipynb | 77 +++++++++++++++++++++++++++++----------------
1 file changed, 50 insertions(+), 27 deletions(-)
diff --git a/05_1_ChromaDB.ipynb b/05_1_ChromaDB.ipynb
index f870983..037b959 100644
--- a/05_1_ChromaDB.ipynb
+++ b/05_1_ChromaDB.ipynb
@@ -1,5 +1,15 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "view-in-github",
+ "colab_type": "text"
+ },
+ "source": [
+ "
"
- ]
- },
{
"cell_type": "markdown",
"metadata": {
@@ -433,4 +423,4 @@
},
"nbformat": 4,
"nbformat_minor": 0
-}
\ No newline at end of file
+}
From bc39bd432eebe4348dafee63fbab16d8b4d8b8bf Mon Sep 17 00:00:00 2001
From: Hyesoo Kim <100982596+duper203@users.noreply.github.com>
Date: Thu, 3 Oct 2024 09:47:00 -0700
Subject: [PATCH 3/7] Created using Colab
---
05_1_ChromaDB.ipynb | 77 +++++++++++++++++++++++++++++----------------
1 file changed, 50 insertions(+), 27 deletions(-)
diff --git a/05_1_ChromaDB.ipynb b/05_1_ChromaDB.ipynb
index f870983..037b959 100644
--- a/05_1_ChromaDB.ipynb
+++ b/05_1_ChromaDB.ipynb
@@ -1,5 +1,15 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "view-in-github",
+ "colab_type": "text"
+ },
+ "source": [
+ "![]() "
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
@@ -63,7 +73,7 @@
},
{
"cell_type": "code",
- "execution_count": 6,
+ "execution_count": 2,
"metadata": {
"id": "KyP3R-L1aim4"
},
@@ -95,10 +105,10 @@
},
{
"cell_type": "code",
- "execution_count": 7,
+ "execution_count": 3,
"metadata": {
"id": "0DW5Q0Wkaim4",
- "outputId": "3ca329f1-407d-405a-fb1a-74f387754e3d",
+ "outputId": "df098096-582d-4f7e-a90c-affd61a68a77",
"colab": {
"base_uri": "https://localhost:8080/"
}
@@ -143,7 +153,7 @@
},
{
"cell_type": "code",
- "execution_count": 8,
+ "execution_count": 4,
"metadata": {
"id": "N_k9hEaUaim5"
},
@@ -160,10 +170,10 @@
},
{
"cell_type": "code",
- "execution_count": 9,
+ "execution_count": 5,
"metadata": {
"id": "9FlsMkYkaim5",
- "outputId": "e91437c5-3c0e-427c-816b-4769361a20aa",
+ "outputId": "8290c2c9-177c-4166-d7f3-368807ea2928",
"colab": {
"base_uri": "https://localhost:8080/"
}
@@ -177,7 +187,7 @@
]
},
"metadata": {},
- "execution_count": 9
+ "execution_count": 5
}
],
"source": [
@@ -186,10 +196,10 @@
},
{
"cell_type": "code",
- "execution_count": 10,
+ "execution_count": 6,
"metadata": {
"id": "wxndeR9Naim6",
- "outputId": "42148072-0dc8-4449-e33c-9d187f1b565a",
+ "outputId": "92e464f3-bee5-4048-96be-b6247c99cc79",
"colab": {
"base_uri": "https://localhost:8080/"
}
@@ -203,7 +213,7 @@
]
},
"metadata": {},
- "execution_count": 10
+ "execution_count": 6
}
],
"source": [
@@ -212,7 +222,7 @@
},
{
"cell_type": "code",
- "execution_count": 11,
+ "execution_count": 7,
"metadata": {
"id": "bmaZFuDWaim6"
},
@@ -227,10 +237,10 @@
},
{
"cell_type": "code",
- "execution_count": 12,
+ "execution_count": 8,
"metadata": {
"id": "A7KuZZqHaim6",
- "outputId": "4231f237-9132-489d-a6b1-5d601b07dfff",
+ "outputId": "5c1bbf0a-1844-4ede-e682-eed0f4a3f2b2",
"colab": {
"base_uri": "https://localhost:8080/"
}
@@ -280,9 +290,9 @@
"base_uri": "https://localhost:8080/"
},
"id": "lEqnFToCkZfH",
- "outputId": "8d5d9b42-27ea-4221-a21d-8de74fa3d3d9"
+ "outputId": "a22c8c5e-7d16-4c5e-ca9f-cb739dd42847"
},
- "execution_count": 13,
+ "execution_count": 9,
"outputs": [
{
"output_type": "stream",
@@ -295,11 +305,23 @@
},
{
"cell_type": "code",
- "execution_count": 14,
+ "execution_count": 10,
"metadata": {
- "id": "X1SWtlmkaim6"
+ "id": "X1SWtlmkaim6",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "06f4520e-ba67-4a13-a6d6-6222f67535a8"
},
- "outputs": [],
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "132\n"
+ ]
+ }
+ ],
"source": [
"from langchain_chroma import Chroma\n",
"from langchain_upstage import UpstageEmbeddings\n",
@@ -315,30 +337,31 @@
" simplified_metadata[key] = str(value)\n",
" return simplified_metadata\n",
"\n",
- "filtered_unique_splits = [\n",
+ "unique_splits = [\n",
" Document(page_content=split.page_content, metadata=simplify_metadata(split.metadata))\n",
" for split in unique_splits\n",
"]\n",
+ "print(len(unique_splits))\n",
"\n",
"# 3. Embed & indexing\n",
- "if len(filtered_unique_splits) > 0:\n",
+ "if len(unique_splits) > 0:\n",
" vectorstore = Chroma.from_documents(\n",
- " ids=[split.page_content for split in filtered_unique_splits],\n",
+ " ids=[split.page_content for split in unique_splits],\n",
" persist_directory=\"./chroma_db\",\n",
- " documents=filtered_unique_splits,\n",
+ " documents=unique_splits,\n",
" embedding=UpstageEmbeddings(model=\"solar-embedding-1-large\"),\n",
" )\n"
]
},
{
"cell_type": "code",
- "execution_count": 15,
+ "execution_count": 11,
"metadata": {
"id": "3kxYmiUcaim7",
"colab": {
"base_uri": "https://localhost:8080/"
},
- "outputId": "2c26682e-77db-44cd-fffb-68d8700fbd12"
+ "outputId": "a38c52fb-555c-4211-ffee-bee3e2c9d663"
},
"outputs": [
{
@@ -375,10 +398,10 @@
},
{
"cell_type": "code",
- "execution_count": 16,
+ "execution_count": 12,
"metadata": {
"id": "z5iN091Eaim7",
- "outputId": "46de4889-b8bb-4371-f6cc-0add345013ba",
+ "outputId": "341a58d6-fdd4-4b72-8924-19fa6e74e5ed",
"colab": {
"base_uri": "https://localhost:8080/"
}
@@ -423,4 +446,4 @@
},
"nbformat": 4,
"nbformat_minor": 0
-}
+}
\ No newline at end of file
From 64d81c4e9e15299e39a3381d724e5cc91f3b3fef Mon Sep 17 00:00:00 2001
From: Hyesoo Kim <100982596+duper203@users.noreply.github.com>
Date: Thu, 3 Oct 2024 09:47:54 -0700
Subject: [PATCH 4/7] Update 05_1_ChromaDB.ipynb
---
05_1_ChromaDB.ipynb | 12 +-----------
1 file changed, 1 insertion(+), 11 deletions(-)
diff --git a/05_1_ChromaDB.ipynb b/05_1_ChromaDB.ipynb
index 037b959..56aabd0 100644
--- a/05_1_ChromaDB.ipynb
+++ b/05_1_ChromaDB.ipynb
@@ -1,15 +1,5 @@
{
"cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "view-in-github",
- "colab_type": "text"
- },
- "source": [
- "
"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
@@ -63,7 +73,7 @@
},
{
"cell_type": "code",
- "execution_count": 6,
+ "execution_count": 2,
"metadata": {
"id": "KyP3R-L1aim4"
},
@@ -95,10 +105,10 @@
},
{
"cell_type": "code",
- "execution_count": 7,
+ "execution_count": 3,
"metadata": {
"id": "0DW5Q0Wkaim4",
- "outputId": "3ca329f1-407d-405a-fb1a-74f387754e3d",
+ "outputId": "df098096-582d-4f7e-a90c-affd61a68a77",
"colab": {
"base_uri": "https://localhost:8080/"
}
@@ -143,7 +153,7 @@
},
{
"cell_type": "code",
- "execution_count": 8,
+ "execution_count": 4,
"metadata": {
"id": "N_k9hEaUaim5"
},
@@ -160,10 +170,10 @@
},
{
"cell_type": "code",
- "execution_count": 9,
+ "execution_count": 5,
"metadata": {
"id": "9FlsMkYkaim5",
- "outputId": "e91437c5-3c0e-427c-816b-4769361a20aa",
+ "outputId": "8290c2c9-177c-4166-d7f3-368807ea2928",
"colab": {
"base_uri": "https://localhost:8080/"
}
@@ -177,7 +187,7 @@
]
},
"metadata": {},
- "execution_count": 9
+ "execution_count": 5
}
],
"source": [
@@ -186,10 +196,10 @@
},
{
"cell_type": "code",
- "execution_count": 10,
+ "execution_count": 6,
"metadata": {
"id": "wxndeR9Naim6",
- "outputId": "42148072-0dc8-4449-e33c-9d187f1b565a",
+ "outputId": "92e464f3-bee5-4048-96be-b6247c99cc79",
"colab": {
"base_uri": "https://localhost:8080/"
}
@@ -203,7 +213,7 @@
]
},
"metadata": {},
- "execution_count": 10
+ "execution_count": 6
}
],
"source": [
@@ -212,7 +222,7 @@
},
{
"cell_type": "code",
- "execution_count": 11,
+ "execution_count": 7,
"metadata": {
"id": "bmaZFuDWaim6"
},
@@ -227,10 +237,10 @@
},
{
"cell_type": "code",
- "execution_count": 12,
+ "execution_count": 8,
"metadata": {
"id": "A7KuZZqHaim6",
- "outputId": "4231f237-9132-489d-a6b1-5d601b07dfff",
+ "outputId": "5c1bbf0a-1844-4ede-e682-eed0f4a3f2b2",
"colab": {
"base_uri": "https://localhost:8080/"
}
@@ -280,9 +290,9 @@
"base_uri": "https://localhost:8080/"
},
"id": "lEqnFToCkZfH",
- "outputId": "8d5d9b42-27ea-4221-a21d-8de74fa3d3d9"
+ "outputId": "a22c8c5e-7d16-4c5e-ca9f-cb739dd42847"
},
- "execution_count": 13,
+ "execution_count": 9,
"outputs": [
{
"output_type": "stream",
@@ -295,11 +305,23 @@
},
{
"cell_type": "code",
- "execution_count": 14,
+ "execution_count": 10,
"metadata": {
- "id": "X1SWtlmkaim6"
+ "id": "X1SWtlmkaim6",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "06f4520e-ba67-4a13-a6d6-6222f67535a8"
},
- "outputs": [],
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "132\n"
+ ]
+ }
+ ],
"source": [
"from langchain_chroma import Chroma\n",
"from langchain_upstage import UpstageEmbeddings\n",
@@ -315,30 +337,31 @@
" simplified_metadata[key] = str(value)\n",
" return simplified_metadata\n",
"\n",
- "filtered_unique_splits = [\n",
+ "unique_splits = [\n",
" Document(page_content=split.page_content, metadata=simplify_metadata(split.metadata))\n",
" for split in unique_splits\n",
"]\n",
+ "print(len(unique_splits))\n",
"\n",
"# 3. Embed & indexing\n",
- "if len(filtered_unique_splits) > 0:\n",
+ "if len(unique_splits) > 0:\n",
" vectorstore = Chroma.from_documents(\n",
- " ids=[split.page_content for split in filtered_unique_splits],\n",
+ " ids=[split.page_content for split in unique_splits],\n",
" persist_directory=\"./chroma_db\",\n",
- " documents=filtered_unique_splits,\n",
+ " documents=unique_splits,\n",
" embedding=UpstageEmbeddings(model=\"solar-embedding-1-large\"),\n",
" )\n"
]
},
{
"cell_type": "code",
- "execution_count": 15,
+ "execution_count": 11,
"metadata": {
"id": "3kxYmiUcaim7",
"colab": {
"base_uri": "https://localhost:8080/"
},
- "outputId": "2c26682e-77db-44cd-fffb-68d8700fbd12"
+ "outputId": "a38c52fb-555c-4211-ffee-bee3e2c9d663"
},
"outputs": [
{
@@ -375,10 +398,10 @@
},
{
"cell_type": "code",
- "execution_count": 16,
+ "execution_count": 12,
"metadata": {
"id": "z5iN091Eaim7",
- "outputId": "46de4889-b8bb-4371-f6cc-0add345013ba",
+ "outputId": "341a58d6-fdd4-4b72-8924-19fa6e74e5ed",
"colab": {
"base_uri": "https://localhost:8080/"
}
@@ -423,4 +446,4 @@
},
"nbformat": 4,
"nbformat_minor": 0
-}
+}
\ No newline at end of file
From 64d81c4e9e15299e39a3381d724e5cc91f3b3fef Mon Sep 17 00:00:00 2001
From: Hyesoo Kim <100982596+duper203@users.noreply.github.com>
Date: Thu, 3 Oct 2024 09:47:54 -0700
Subject: [PATCH 4/7] Update 05_1_ChromaDB.ipynb
---
05_1_ChromaDB.ipynb | 12 +-----------
1 file changed, 1 insertion(+), 11 deletions(-)
diff --git a/05_1_ChromaDB.ipynb b/05_1_ChromaDB.ipynb
index 037b959..56aabd0 100644
--- a/05_1_ChromaDB.ipynb
+++ b/05_1_ChromaDB.ipynb
@@ -1,15 +1,5 @@
{
"cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "view-in-github",
- "colab_type": "text"
- },
- "source": [
- "![]() "
- ]
- },
{
"cell_type": "markdown",
"metadata": {
@@ -446,4 +436,4 @@
},
"nbformat": 4,
"nbformat_minor": 0
-}
\ No newline at end of file
+}
From c9feffcec34b0988cc6d40756aa64bb459461778 Mon Sep 17 00:00:00 2001
From: Hyesoo Kim <100982596+duper203@users.noreply.github.com>
Date: Thu, 3 Oct 2024 09:49:50 -0700
Subject: [PATCH 5/7] Delete Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb
---
Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb | 338 --------------------
1 file changed, 338 deletions(-)
delete mode 100644 Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb
diff --git a/Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb b/Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb
deleted file mode 100644
index 31c3408..0000000
--- a/Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb
+++ /dev/null
@@ -1,338 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "\n",
- "
"
- ]
- },
{
"cell_type": "markdown",
"metadata": {
@@ -446,4 +436,4 @@
},
"nbformat": 4,
"nbformat_minor": 0
-}
\ No newline at end of file
+}
From c9feffcec34b0988cc6d40756aa64bb459461778 Mon Sep 17 00:00:00 2001
From: Hyesoo Kim <100982596+duper203@users.noreply.github.com>
Date: Thu, 3 Oct 2024 09:49:50 -0700
Subject: [PATCH 5/7] Delete Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb
---
Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb | 338 --------------------
1 file changed, 338 deletions(-)
delete mode 100644 Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb
diff --git a/Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb b/Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb
deleted file mode 100644
index 31c3408..0000000
--- a/Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb
+++ /dev/null
@@ -1,338 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "\n",
- "![]() \n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "# 05-1.ChromaDB\n",
- "\n",
- "## Overview \n",
- "In this exercise, we will explore how to utilize ChromaDB to embed documents and construct a vectorspace. Additionally, we will gain insight into the creation of a Retriever object to facilitate efficient query searches within documents. This tutorial will guide you through the process of embedding documents and using a vectorspace for effective information retrieval.\n",
- " \n",
- "## Purpose of the Exercise\n",
- "The purpose of this exercise is to demonstrate the use of the Solar Embedding API to generate embeddings and create a vectorspace. By the end of this tutorial, users will be able to create a Retriever object and conduct efficient searches within the vectorspace, thereby enhancing the ability to retrieve relevant information from embedded documents.\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Keyword VS Semantic Search \n",
- "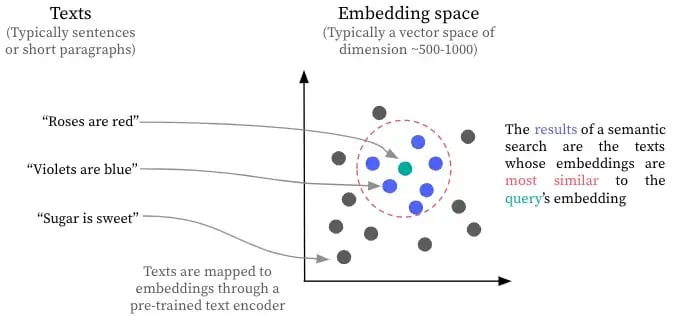\n",
- "\n",
- "from https://blog.dataiku.com/semantic-search-an-overlooked-nlp-superpower"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "\n",
- "\n",
- "from https://sreent.medium.com/llms-embeddings-and-vector-search-d4bd9362df56"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 1,
- "metadata": {},
- "outputs": [],
- "source": [
- "! pip3 install -qU markdownify langchain-upstage rank_bm25 python-dotenv"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 3,
- "metadata": {},
- "outputs": [],
- "source": [
- "# @title set API key\n",
- "import os\n",
- "import getpass\n",
- "from pprint import pprint\n",
- "import warnings\n",
- "\n",
- "warnings.filterwarnings(\"ignore\")\n",
- "\n",
- "from IPython import get_ipython\n",
- "\n",
- "if \"google.colab\" in str(get_ipython()):\n",
- " # Running in Google Colab. Please set the UPSTAGE_API_KEY in the Colab Secrets\n",
- " from google.colab import userdata\n",
- " os.environ[\"UPSTAGE_API_KEY\"] = userdata.get(\"UPSTAGE_API_KEY\")\n",
- "else:\n",
- " # Running locally. Please set the UPSTAGE_API_KEY in the .env file\n",
- " from dotenv import load_dotenv\n",
- "\n",
- " load_dotenv()\n",
- "\n",
- "if \"UPSTAGE_API_KEY\" not in os.environ:\n",
- " os.environ[\"UPSTAGE_API_KEY\"] = getpass.getpass(\"Enter your Upstage API key: \")\n"
-]
-
- },
- {
- "cell_type": "code",
- "execution_count": 22,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "[Document(page_content='Korea is a beautiful country to visit in the spring.'), Document(page_content='The best time to visit Korea is in the fall.'), Document(page_content='Best way to find bug is using unit test.'), Document(page_content='Python is a great programming language for beginners.'), Document(page_content='Sung Kim is a great teacher.')]\n"
- ]
- }
- ],
- "source": [
- "from langchain_chroma import Chroma\n",
- "from langchain_upstage import UpstageEmbeddings\n",
- "from langchain.docstore.document import Document\n",
- "\n",
- "from langchain_text_splitters import (\n",
- " Language,\n",
- " RecursiveCharacterTextSplitter,\n",
- ")\n",
- "\n",
- "sample_text = [\n",
- " \"Korea is a beautiful country to visit in the spring.\",\n",
- " \"The best time to visit Korea is in the fall.\",\n",
- " \"Best way to find bug is using unit test.\",\n",
- " \"Python is a great programming language for beginners.\",\n",
- " \"Sung Kim is a great teacher.\",\n",
- "]\n",
- "\n",
- "splits = RecursiveCharacterTextSplitter().create_documents(sample_text)\n",
- "\n",
- "print(splits)\n",
- "\n",
- "vectorstore = Chroma.from_documents(\n",
- " documents=splits,\n",
- " ids=[doc.page_content for doc in splits],\n",
- " embedding=UpstageEmbeddings(model=\"solar-embedding-1-large\"),\n",
- ")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 23,
- "metadata": {},
- "outputs": [],
- "source": [
- "# check if text is in the vector store\n",
- "def is_in_vectorstore(vectorstore, text):\n",
- " search_results = vectorstore.get(ids=[text])\n",
- " if search_results and search_results[\"ids\"]:\n",
- " return True\n",
- " else:\n",
- " return False"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 24,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- "False"
- ]
- },
- "execution_count": 24,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "is_in_vectorstore(vectorstore, \"Hello, new sentence\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 25,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- "True"
- ]
- },
- "execution_count": 25,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "is_in_vectorstore(vectorstore, splits[0].page_content)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 8,
- "metadata": {},
- "outputs": [],
- "source": [
- "from langchain_upstage import UpstageLayoutAnalysisLoader\n",
- "\n",
- "\n",
- "layzer = UpstageLayoutAnalysisLoader(\"pdfs/kim-tse-2008.pdf\", output_type=\"html\")\n",
- "# For improved memory efficiency, consider using the lazy_load method to load documents page by page.\n",
- "docs = layzer.load() # or layzer.lazy_load()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 9,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Splits: 125\n"
- ]
- }
- ],
- "source": [
- "from langchain_text_splitters import (\n",
- " Language,\n",
- " RecursiveCharacterTextSplitter,\n",
- ")\n",
- "\n",
- "# 2. Split\n",
- "text_splitter = RecursiveCharacterTextSplitter.from_language(\n",
- " chunk_size=1000, chunk_overlap=100, language=Language.HTML\n",
- ")\n",
- "splits = text_splitter.split_documents(docs)\n",
- "print(\"Splits:\", len(splits))"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 10,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "125\n"
- ]
- }
- ],
- "source": [
- "from langchain_chroma import Chroma\n",
- "\n",
- "vectorstore = Chroma(\n",
- " persist_directory=\"./chroma_db\",\n",
- " embedding_function=UpstageEmbeddings(model=\"solar-embedding-1-large\"),\n",
- ")\n",
- "retriever = vectorstore.as_retriever()\n",
- "\n",
- "\n",
- "unique_splits = [\n",
- " split for split in splits if not is_in_vectorstore(vectorstore, split.page_content)\n",
- "]\n",
- "print(len(unique_splits))\n",
- "\n",
- "# 3. Embed & indexing\n",
- "if len(unique_splits) > 0:\n",
- " vectorstore = Chroma.from_documents(\n",
- " ids=[split.page_content for split in unique_splits],\n",
- " persist_directory=\"./chroma_db\",\n",
- " documents=unique_splits,\n",
- " embedding=UpstageEmbeddings(model=\"solar-embedding-1-large\"),\n",
- " )"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 13,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "0\n"
- ]
- }
- ],
- "source": [
- "from langchain_chroma import Chroma\n",
- "\n",
- "vectorstore = Chroma(\n",
- " persist_directory=\"./chroma_db\",\n",
- " embedding_function=UpstageEmbeddings(model=\"solar-embedding-1-large\"),\n",
- ")\n",
- "retriever = vectorstore.as_retriever()\n",
- "\n",
- "unique_splits = [\n",
- " split for split in splits if not is_in_vectorstore(vectorstore, split.page_content)\n",
- "]\n",
- "print(len(unique_splits))\n",
- "\n",
- "# 3. Embed & indexing\n",
- "if len(unique_splits) > 0:\n",
- " vectorstore = Chroma.from_documents(\n",
- " ids=[split.page_content for split in unique_splits],\n",
- " persist_directory=\"./chroma_db\",\n",
- " documents=unique_splits,\n",
- " embedding=UpstageEmbeddings(model=\"solar-embedding-1-large\"),\n",
- " )"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 15,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "
\n",
- ""
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "# 05-1.ChromaDB\n",
- "\n",
- "## Overview \n",
- "In this exercise, we will explore how to utilize ChromaDB to embed documents and construct a vectorspace. Additionally, we will gain insight into the creation of a Retriever object to facilitate efficient query searches within documents. This tutorial will guide you through the process of embedding documents and using a vectorspace for effective information retrieval.\n",
- " \n",
- "## Purpose of the Exercise\n",
- "The purpose of this exercise is to demonstrate the use of the Solar Embedding API to generate embeddings and create a vectorspace. By the end of this tutorial, users will be able to create a Retriever object and conduct efficient searches within the vectorspace, thereby enhancing the ability to retrieve relevant information from embedded documents.\n",
- "\n"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "## Keyword VS Semantic Search \n",
- "\n",
- "\n",
- "from https://blog.dataiku.com/semantic-search-an-overlooked-nlp-superpower"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {},
- "source": [
- "\n",
- "\n",
- "from https://sreent.medium.com/llms-embeddings-and-vector-search-d4bd9362df56"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 1,
- "metadata": {},
- "outputs": [],
- "source": [
- "! pip3 install -qU markdownify langchain-upstage rank_bm25 python-dotenv"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 3,
- "metadata": {},
- "outputs": [],
- "source": [
- "# @title set API key\n",
- "import os\n",
- "import getpass\n",
- "from pprint import pprint\n",
- "import warnings\n",
- "\n",
- "warnings.filterwarnings(\"ignore\")\n",
- "\n",
- "from IPython import get_ipython\n",
- "\n",
- "if \"google.colab\" in str(get_ipython()):\n",
- " # Running in Google Colab. Please set the UPSTAGE_API_KEY in the Colab Secrets\n",
- " from google.colab import userdata\n",
- " os.environ[\"UPSTAGE_API_KEY\"] = userdata.get(\"UPSTAGE_API_KEY\")\n",
- "else:\n",
- " # Running locally. Please set the UPSTAGE_API_KEY in the .env file\n",
- " from dotenv import load_dotenv\n",
- "\n",
- " load_dotenv()\n",
- "\n",
- "if \"UPSTAGE_API_KEY\" not in os.environ:\n",
- " os.environ[\"UPSTAGE_API_KEY\"] = getpass.getpass(\"Enter your Upstage API key: \")\n"
-]
-
- },
- {
- "cell_type": "code",
- "execution_count": 22,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "[Document(page_content='Korea is a beautiful country to visit in the spring.'), Document(page_content='The best time to visit Korea is in the fall.'), Document(page_content='Best way to find bug is using unit test.'), Document(page_content='Python is a great programming language for beginners.'), Document(page_content='Sung Kim is a great teacher.')]\n"
- ]
- }
- ],
- "source": [
- "from langchain_chroma import Chroma\n",
- "from langchain_upstage import UpstageEmbeddings\n",
- "from langchain.docstore.document import Document\n",
- "\n",
- "from langchain_text_splitters import (\n",
- " Language,\n",
- " RecursiveCharacterTextSplitter,\n",
- ")\n",
- "\n",
- "sample_text = [\n",
- " \"Korea is a beautiful country to visit in the spring.\",\n",
- " \"The best time to visit Korea is in the fall.\",\n",
- " \"Best way to find bug is using unit test.\",\n",
- " \"Python is a great programming language for beginners.\",\n",
- " \"Sung Kim is a great teacher.\",\n",
- "]\n",
- "\n",
- "splits = RecursiveCharacterTextSplitter().create_documents(sample_text)\n",
- "\n",
- "print(splits)\n",
- "\n",
- "vectorstore = Chroma.from_documents(\n",
- " documents=splits,\n",
- " ids=[doc.page_content for doc in splits],\n",
- " embedding=UpstageEmbeddings(model=\"solar-embedding-1-large\"),\n",
- ")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 23,
- "metadata": {},
- "outputs": [],
- "source": [
- "# check if text is in the vector store\n",
- "def is_in_vectorstore(vectorstore, text):\n",
- " search_results = vectorstore.get(ids=[text])\n",
- " if search_results and search_results[\"ids\"]:\n",
- " return True\n",
- " else:\n",
- " return False"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 24,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- "False"
- ]
- },
- "execution_count": 24,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "is_in_vectorstore(vectorstore, \"Hello, new sentence\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 25,
- "metadata": {},
- "outputs": [
- {
- "data": {
- "text/plain": [
- "True"
- ]
- },
- "execution_count": 25,
- "metadata": {},
- "output_type": "execute_result"
- }
- ],
- "source": [
- "is_in_vectorstore(vectorstore, splits[0].page_content)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 8,
- "metadata": {},
- "outputs": [],
- "source": [
- "from langchain_upstage import UpstageLayoutAnalysisLoader\n",
- "\n",
- "\n",
- "layzer = UpstageLayoutAnalysisLoader(\"pdfs/kim-tse-2008.pdf\", output_type=\"html\")\n",
- "# For improved memory efficiency, consider using the lazy_load method to load documents page by page.\n",
- "docs = layzer.load() # or layzer.lazy_load()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 9,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Splits: 125\n"
- ]
- }
- ],
- "source": [
- "from langchain_text_splitters import (\n",
- " Language,\n",
- " RecursiveCharacterTextSplitter,\n",
- ")\n",
- "\n",
- "# 2. Split\n",
- "text_splitter = RecursiveCharacterTextSplitter.from_language(\n",
- " chunk_size=1000, chunk_overlap=100, language=Language.HTML\n",
- ")\n",
- "splits = text_splitter.split_documents(docs)\n",
- "print(\"Splits:\", len(splits))"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 10,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "125\n"
- ]
- }
- ],
- "source": [
- "from langchain_chroma import Chroma\n",
- "\n",
- "vectorstore = Chroma(\n",
- " persist_directory=\"./chroma_db\",\n",
- " embedding_function=UpstageEmbeddings(model=\"solar-embedding-1-large\"),\n",
- ")\n",
- "retriever = vectorstore.as_retriever()\n",
- "\n",
- "\n",
- "unique_splits = [\n",
- " split for split in splits if not is_in_vectorstore(vectorstore, split.page_content)\n",
- "]\n",
- "print(len(unique_splits))\n",
- "\n",
- "# 3. Embed & indexing\n",
- "if len(unique_splits) > 0:\n",
- " vectorstore = Chroma.from_documents(\n",
- " ids=[split.page_content for split in unique_splits],\n",
- " persist_directory=\"./chroma_db\",\n",
- " documents=unique_splits,\n",
- " embedding=UpstageEmbeddings(model=\"solar-embedding-1-large\"),\n",
- " )"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 13,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "0\n"
- ]
- }
- ],
- "source": [
- "from langchain_chroma import Chroma\n",
- "\n",
- "vectorstore = Chroma(\n",
- " persist_directory=\"./chroma_db\",\n",
- " embedding_function=UpstageEmbeddings(model=\"solar-embedding-1-large\"),\n",
- ")\n",
- "retriever = vectorstore.as_retriever()\n",
- "\n",
- "unique_splits = [\n",
- " split for split in splits if not is_in_vectorstore(vectorstore, split.page_content)\n",
- "]\n",
- "print(len(unique_splits))\n",
- "\n",
- "# 3. Embed & indexing\n",
- "if len(unique_splits) > 0:\n",
- " vectorstore = Chroma.from_documents(\n",
- " ids=[split.page_content for split in unique_splits],\n",
- " persist_directory=\"./chroma_db\",\n",
- " documents=unique_splits,\n",
- " embedding=UpstageEmbeddings(model=\"solar-embedding-1-large\"),\n",
- " )"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 15,
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "
introduced bugs immediately. Several bug-finding techni-
ques c\n"
- ]
- }
- ],
- "source": [
- "search_result = retriever.invoke(\"How to find problems in code?\")\n",
- "print(search_result[0].page_content[:100])"
- ]
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "Python 3 (ipykernel)",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.10.10"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 4
-}
From 18541b1c86d9230bec2869de8a4ffbf71bfa497a Mon Sep 17 00:00:00 2001
From: Hyesoo Kim <100982596+duper203@users.noreply.github.com>
Date: Thu, 3 Oct 2024 09:50:02 -0700
Subject: [PATCH 6/7] update 05-1
---
.../05_1_ChromaDB.ipynb | 0
1 file changed, 0 insertions(+), 0 deletions(-)
rename 05_1_ChromaDB.ipynb => Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb (100%)
diff --git a/05_1_ChromaDB.ipynb b/Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb
similarity index 100%
rename from 05_1_ChromaDB.ipynb
rename to Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb
From 362f9ee8f01ab133c978bc3ecf0987e903b96146 Mon Sep 17 00:00:00 2001
From: Hyesoo Kim <100982596+duper203@users.noreply.github.com>
Date: Mon, 7 Oct 2024 09:50:02 -0700
Subject: [PATCH 7/7] Update 05_1_ChromaDB.ipynb : env setting
---
Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb | 46 ++++++++++-----------
1 file changed, 23 insertions(+), 23 deletions(-)
diff --git a/Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb b/Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb
index 56aabd0..0c369e2 100644
--- a/Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb
+++ b/Solar-Fullstack-LLM-101/05_1_ChromaDB.ipynb
@@ -69,29 +69,29 @@
},
"outputs": [],
"source": [
- "# @title set API key\n",
- "import os\n",
- "import getpass\n",
- "from pprint import pprint\n",
- "import warnings\n",
- "\n",
- "warnings.filterwarnings(\"ignore\")\n",
- "\n",
- "from IPython import get_ipython\n",
- "\n",
- "if \"google.colab\" in str(get_ipython()):\n",
- " # Running in Google Colab. Please set the UPSTAGE_API_KEY in the Colab Secrets\n",
- " from google.colab import userdata\n",
- " os.environ[\"UPSTAGE_API_KEY\"] = userdata.get(\"UPSTAGE_API_KEY\")\n",
- "else:\n",
- " # Running locally. Please set the UPSTAGE_API_KEY in the .env file\n",
- " from dotenv import load_dotenv\n",
- "\n",
- " load_dotenv()\n",
- "\n",
- "if \"UPSTAGE_API_KEY\" not in os.environ:\n",
- " os.environ[\"UPSTAGE_API_KEY\"] = getpass.getpass(\"Enter your Upstage API key: \")\n"
- ]
+ "# @title set API key\n",
+ "from pprint import pprint\n",
+ "import os\n",
+ "\n",
+ "import warnings\n",
+ "\n",
+ "warnings.filterwarnings(\"ignore\")\n",
+ "\n",
+ "if \"google.colab\" in str(get_ipython()):\n",
+ " # Running in Google Colab. Please set the UPSTAGE_API_KEY in the Colab Secrets\n",
+ " from google.colab import userdata\n",
+ "\n",
+ " os.environ[\"UPSTAGE_API_KEY\"] = userdata.get(\"UPSTAGE_API_KEY\")\n",
+ "else:\n",
+ " # Running locally. Please set the UPSTAGE_API_KEY in the .env file\n",
+ " from dotenv import load_dotenv\n",
+ "\n",
+ " load_dotenv()\n",
+ "\n",
+ "assert (\n",
+ " \"UPSTAGE_API_KEY\" in os.environ\n",
+ "), \"Please set the UPSTAGE_API_KEY environment variable\""
+ ]
},
{
"cell_type": "code",