diff --git a/.github/workflows/publish.yml b/.github/workflows/publish.yml
new file mode 100644
index 00000000..ce654236
--- /dev/null
+++ b/.github/workflows/publish.yml
@@ -0,0 +1,53 @@
+# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
+#
+# SPDX-License-Identifier: MIT
+
+name: "Publish to PyPI"
+
+on:
+ workflow_dispatch:
+ target:
+ inputs:
+ target:
+ description: 'Target'
+ required: true
+ default: 'PyPI'
+ type: choice
+ options:
+ - PyPI
+ - TestPyPi
+ # push:
+ # tags:
+ # # Publish on any tag starting with a `v`, e.g., v0.1.0
+ # - v*
+
+run-name: Publish to ${{ inputs.target }}
+
+jobs:
+ run:
+ runs-on: ubuntu-latest
+ environment:
+ name: pypi
+ permissions:
+ id-token: write
+ contents: read
+ steps:
+ - name: Checkout
+ uses: actions/checkout@v5
+ - name: Install uv
+ uses: astral-sh/setup-uv@v7
+ - name: Build
+ run: uv build
+ # Check that basic features work and we didn't miss to include crucial files
+ - name: Smoke test (wheel)
+ run: uv run --isolated --no-project --with dist/*.whl tests/smoke_test.py
+ - name: Smoke test (source distribution)
+ run: uv run --isolated --no-project --with dist/*.tar.gz tests/smoke_test.py
+ - name: Publish
+ run: uv publish ${{ inputs.target == 'TestPyPi' && '--index testpypi' || '' }}
+ - name: Summary
+ run: |
+ echo "### Published OpenTSLM to ${{ inputs.target }} :rocket:" >> $GITHUB_STEP_SUMMARY
+ echo "Version: `$(uv version --short)`" >> $GITHUB_STEP_SUMMARY
+ echo "URL: https://${{ inputs.target == 'TestPyPi' && 'test.' || '' }}pypi.org/project/opentslm/$(uv version --short)/" >>> $GITHUB_STEP_SUMMARY
\ No newline at end of file
diff --git a/.github/workflows/static-analysis.yml b/.github/workflows/static-analysis.yml
index e94f5b5b..91f26de0 100644
--- a/.github/workflows/static-analysis.yml
+++ b/.github/workflows/static-analysis.yml
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/.gitignore b/.gitignore
index 7c660ca3..3f42fb9d 100644
--- a/.gitignore
+++ b/.gitignore
@@ -1,18 +1,22 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
-venv
+.venv
+.vscode
__pycache__
.DS_STORE
-**/.DS_STORE
raw_data
+**/data/*
+!**/data/.gitkeep
*.ts
*.zip
-./__pycache__
upload_to_huggingface.py
+
+dist/
+
+*.license
\ No newline at end of file
diff --git a/.gitmodules b/.gitmodules
deleted file mode 100644
index a27cc5d4..00000000
--- a/.gitmodules
+++ /dev/null
@@ -1,12 +0,0 @@
-# This source file is part of the OpenTSLM open-source project
-#
-# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-#
-# SPDX-License-Identifier: MIT
-
-[submodule "open_flamingo"]
- path = open_flamingo
- url = https://github.com/mlfoundations/open_flamingo.git
-[submodule "src/open_flamingo"]
- path = src/open_flamingo
- url = https://github.com/mlfoundations/open_flamingo.git
diff --git a/.linkspector.yml b/.linkspector.yml
index 05471bf8..680e3f79 100644
--- a/.linkspector.yml
+++ b/.linkspector.yml
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/src/model/__init__.py b/.python-version
similarity index 69%
rename from src/model/__init__.py
rename to .python-version
index 266b1365..d66339f8 100644
--- a/src/model/__init__.py
+++ b/.python-version
@@ -1,5 +1,7 @@
-# This source file is part of the OpenTSLM open-source project
#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
#
# SPDX-License-Identifier: MIT
+#
+
+3.12
diff --git a/.reuse/templates/opentslm.jinja2 b/.reuse/templates/opentslm.jinja2
deleted file mode 100644
index 17928cd4..00000000
--- a/.reuse/templates/opentslm.jinja2
+++ /dev/null
@@ -1,9 +0,0 @@
-This source file is part of the OpenTSLM open-source project
-
-{% for line in copyright_lines %}
-{{ line }}
-{% endfor %}
-
-{% for expr in spdx_expressions %}
-SPDX-License-Identifier: {{ expr }}
-{% endfor %}
\ No newline at end of file
diff --git a/CONTRIBUTORS.md b/CONTRIBUTORS.md
index fa43bcdc..f908a9dc 100644
--- a/CONTRIBUTORS.md
+++ b/CONTRIBUTORS.md
@@ -1,7 +1,6 @@
diff --git a/README.md b/README.md
index 88abc42f..296bd7b5 100644
--- a/README.md
+++ b/README.md
@@ -1,12 +1,12 @@
# OpenTSLM: Time-Series Language Models for Reasoning over Multivariate Medical Text- and Time-Series Data
+[](https://pypi.org/project/opentslm)
[](https://doi.org/10.13140/RG.2.2.14827.60963)
[](https://github.com/StanfordBDHG/OpenTSLM/actions/workflows/static-analysis.yml)
@@ -14,7 +14,7 @@ SPDX-License-Identifier: MIT
Large Language Models (LLMs) have emerged as powerful tools for interpreting multimodal data (e.g., images, audio, text), often surpassing specialized models. In medicine, they hold particular promise for synthesizing large volumes of clinical information into actionable insights and patient-facing digital health applications. Yet, a major limitation remains their inability to handle time series data. To overcome this gap, we present OpenTSLM, a family of Time Series Language Models (TSLMs) created by integrating time series as a native modality to pretrained Large Language Models, enabling natural-language prompting and reasoning over multiple time series of any length [...] **[🔗 Read the full paper](https://doi.org/10.13140/RG.2.2.14827.60963)**
-
@@ -23,24 +23,17 @@ Large Language Models (LLMs) have emerged as powerful tools for interpreting mul
OpenTSLM models can reason over multiple time series of any length at once, generating findings, captions, and rationales in natural language. We tested these models across a wide range of tasks spanning Human Activity Recognition (HAR) from 3-axis acceleration data, sleep staging from EEG readings, 12-lead ECG question answering, and time series captioning. Some examples are shown below, more are available in the paper.
-
## Installation
-1. **Clone the Repository**
-
- ```bash
- git clone https://github.com/StanfordBDHG/OpenTSLM.git --recurse-submodules
- ```
-
-2. **Install Dependencies**
- ```bash
- pip install -r requirements.txt
- ```
+```bash
+pip install opentslm
+```
## LLM Setup
@@ -48,19 +41,19 @@ OpenTSLM models can reason over multiple time series of any length at once, gene
OpenTSLM is designed to work with Llama and Gemma models, with Llama 3.2 1B as the default. These models are stored in Hugging Face repositories which may require access permissions. Follow these steps to gain access and download:
1. **Request Access (for Llama models)**
- Visit the Llama model repository (e.g., https://huggingface.co/meta-llama/Llama-3.2-1B) or Gemma models repository (https://huggingface.co/google/gemma-3-270m) and request access from Meta.
+ Visit the Llama model repository (e.g., https://huggingface.co/meta-llama/Llama-3.2-1B) or Gemma models repository (https://huggingface.co/google/gemma-3-270m) and request access from Meta.
2. **Authenticate with Hugging Face**
- Log in to your Hugging Face account and configure the CLI:
+ Log in to your Hugging Face account and configure the CLI:
- ```bash
- huggingface-cli login
- ```
+ ```bash
+ huggingface-cli login
+ ```
3. **Create an API Token**
- - Go to your Hugging Face settings: https://huggingface.co/settings/tokens
- - Generate a new token with `read` scope.
- - Copy the token for CLI login.
+ - Go to your Hugging Face settings: https://huggingface.co/settings/tokens
+ - Generate a new token with `read` scope.
+ - Copy the token for CLI login.
### Supported Models
@@ -87,15 +80,11 @@ A factory class called `OpenTSLM` for easily loading pre-trained models from Hug
There are [demo scripts](demo/huggingface/) available which use the following minimal code. If you want to create your own applications, create a new file in **this repo folder** and use the following code as start:
```python
-import sys
-import os
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "src")))
-
-from model.llm.OpenTSLM import OpenTSLM
-from time_series_datasets.TSQADataset import TSQADataset
-from time_series_datasets.util import extend_time_series_to_match_patch_size_and_aggregate
+from opentslm import OpenTSLM
+from opentslm.time_series_datasets.TSQADataset import TSQADataset
+from opentslm.time_series_datasets.util import extend_time_series_to_match_patch_size_and_aggregate
from torch.utils.data import DataLoader
-from model_config import PATCH_SIZE
+from opentslm.model_config import PATCH_SIZE
REPO_ID = "OpenTSLM/llama-3.2-1b-tsqa-sp"
@@ -104,22 +93,41 @@ model = OpenTSLM.load_pretrained(REPO_ID, device="cuda" if torch.cuda.is_availab
test_dataset = TSQADataset("test", EOS_TOKEN=model.get_eos_token())
test_loader = DataLoader(
- test_dataset,
- shuffle=False,
- batch_size=1,
- collate_fn=lambda batch: extend_time_series_to_match_patch_size_and_aggregate(
- batch, patch_size=PATCH_SIZE
- ),
+ test_dataset,
+ shuffle=False,
+ batch_size=1,
+ collate_fn=lambda batch: extend_time_series_to_match_patch_size_and_aggregate(
+ batch, patch_size=PATCH_SIZE
+ ),
)
for i, batch in enumerate(test_loader):
- predictions = model.generate(batch, max_new_tokens=200)
- for sample, pred in zip(batch, predictions):
- print("Question:", sample.get("pre_prompt", "N/A"))
- print("Answer:", sample.get("answer", "N/A"))
- print("Output:", pred)
- if i >= 4:
- break
+ predictions = model.generate(batch, max_new_tokens=200)
+ for sample, pred in zip(batch, predictions):
+ print("Question:", sample.get("pre_prompt", "N/A"))
+ print("Answer:", sample.get("answer", "N/A"))
+ print("Output:", pred)
+ if i >= 4:
+ break
+```
+
+## Building and finetuning your own models
+
+To run the demos and use finetuning scripts **clone the repository** and set up all dependencies. We recommend using [uv](https://docs.astral.sh/uv/) to set up the environment, but you can also use pip:
+
+```bash
+git clone https://github.com/StanfordBDHG/OpenTSLM.git
+
+
+# uv environment management (recommended). Installs uv if it does not exist and creates the virtual environment
+command uv > /dev/null || curl -LsSf https://astral.sh/uv/install.sh | sh
+uv sync --all-groups
+source .venv/bin/activate
+
+
+# or alternatively install via pip:
+pip install -r requirements.txt
+
```
### HuggingFace Demo Scripts
@@ -166,9 +174,9 @@ REPO_ID = "OpenTSLM/llama-3.2-1b-tsqa-flamingo" # Flamingo model
All pretrained models are available under the `OpenTSLM` organization on HuggingFace Hub. Model names follow the pattern:
- `OpenTSLM/{base_model}-{dataset}-{model_type}`
- - `base_model`: `llama-3.2-1b`, `llama-3.2-3b`, `gemma-3-1b-pt`, `gemma-3-270m`
- - `dataset`: `tsqa`, `m4`, `har`, `sleep`, `ecg`
- - `model_type`: `sp` (Soft Prompt) or `flamingo` (Flamingo)
+ - `base_model`: `llama-3.2-1b`, `llama-3.2-3b`, `gemma-3-1b-pt`, `gemma-3-270m`
+ - `dataset`: `tsqa`, `m4`, `har`, `sleep`, `ecg`
+ - `model_type`: `sp` (Soft Prompt) or `flamingo` (Flamingo)
Example: `OpenTSLM/llama-3.2-1b-ecg-flamingo`
@@ -229,6 +237,24 @@ python curriculum_learning.py --model OpenTSLMFlamingo --eval_only
- `--gradient_checkpointing`: Enable gradient checkpointing for memory efficiency
- `--verbose`: Enable verbose logging
+### Helper Scripts
+
+Helper scripts for analysis, testing, and batch processing are available in the `scripts/` directory:
+
+**Shell Scripts:**
+- **`run_all_memory.sh`** - Run comprehensive memory usage analysis across all stages
+- **`run_all_memory_missing.sh`** - Run memory analysis for missing stages only
+
+**Python Scripts:**
+- **`create_doctor_eval_dataset.py`** - Create evaluation dataset for doctor assessments
+- **`get_memory_use.py`** - Analyze and report memory usage across stages
+- **`plot_memory_usage.py`** - Visualize memory usage patterns
+- **`plot_memory_simulation.py`** - Simulate and plot memory requirements
+- **`plot_memory_simulation_per_length.py`** - Analyze memory usage by sequence length
+- **`hf_test.py`** - Test HuggingFace model loading and inference
+
+These scripts can be customized by editing the parameters directly or by passing command-line arguments.
+
### Repository Naming Convention
- Repository IDs ending with `-sp` will load and return `OpenTSLMSP` models
@@ -335,22 +361,24 @@ For researchers and project partners interested in collaboration opportunities,
This project is licensed under the MIT License.
-We use the [REUSE specification](https://reuse.software/spec/) to ensure consistent and machine-readable licensing across the repository.
+OpenTSLM uses [REUSE specification](https://reuse.software/spec/) to ensure consistent and machine-readable licensing across the repository.
To add or update license headers, run:
```bash
reuse annotate --recursive \
- --template opentslm \
--copyright "Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)" \
+ --copyright "This source file is part of the OpenTSLM open-source project." \
--license MIT \
- --skip-unrecognised \
+ --skip-unrecognized \
.
```
+
+
diff --git a/REUSE.toml b/REUSE.toml
index 9016f084..f370d80b 100644
--- a/REUSE.toml
+++ b/REUSE.toml
@@ -1,6 +1,6 @@
version = 1
[[annotations]]
-path = ["data/**"]
+path = ["assets/**", "data/**", "**/*.png", "*.svg", "*.png", "**/*.pt", "**/*.jsonl", "**/*.json", ".gitignore", "**/uv.lock", "LICENSE.md", "**/requirements.txt"]
SPDX-FileCopyrightText = "2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)"
SPDX-License-Identifier = "MIT"
diff --git a/assets/ASL_Logo2.svg.license b/assets/ASL_Logo2.svg.license
deleted file mode 100644
index e83264aa..00000000
--- a/assets/ASL_Logo2.svg.license
+++ /dev/null
@@ -1,5 +0,0 @@
-This source file is part of the OpenTSLM open-source project
-
-SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-
-SPDX-License-Identifier: MIT
diff --git a/assets/ASLwhite.svg.license b/assets/ASLwhite.svg.license
deleted file mode 100644
index e83264aa..00000000
--- a/assets/ASLwhite.svg.license
+++ /dev/null
@@ -1,5 +0,0 @@
-This source file is part of the OpenTSLM open-source project
-
-SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-
-SPDX-License-Identifier: MIT
diff --git a/assets/CDHI_white.svg.license b/assets/CDHI_white.svg.license
deleted file mode 100644
index e83264aa..00000000
--- a/assets/CDHI_white.svg.license
+++ /dev/null
@@ -1,5 +0,0 @@
-This source file is part of the OpenTSLM open-source project
-
-SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-
-SPDX-License-Identifier: MIT
diff --git a/assets/cdhi_logo.png.license b/assets/cdhi_logo.png.license
deleted file mode 100644
index e83264aa..00000000
--- a/assets/cdhi_logo.png.license
+++ /dev/null
@@ -1,5 +0,0 @@
-This source file is part of the OpenTSLM open-source project
-
-SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-
-SPDX-License-Identifier: MIT
diff --git a/assets/ecg_rationale.png.license b/assets/ecg_rationale.png.license
deleted file mode 100644
index e83264aa..00000000
--- a/assets/ecg_rationale.png.license
+++ /dev/null
@@ -1,5 +0,0 @@
-This source file is part of the OpenTSLM open-source project
-
-SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-
-SPDX-License-Identifier: MIT
diff --git a/assets/eth_cdhi_logo.png.license b/assets/eth_cdhi_logo.png.license
deleted file mode 100644
index e83264aa..00000000
--- a/assets/eth_cdhi_logo.png.license
+++ /dev/null
@@ -1,5 +0,0 @@
-This source file is part of the OpenTSLM open-source project
-
-SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-
-SPDX-License-Identifier: MIT
diff --git a/assets/eth_logo.png.license b/assets/eth_logo.png.license
deleted file mode 100644
index e83264aa..00000000
--- a/assets/eth_logo.png.license
+++ /dev/null
@@ -1,5 +0,0 @@
-This source file is part of the OpenTSLM open-source project
-
-SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-
-SPDX-License-Identifier: MIT
diff --git a/assets/har_rationale.png.license b/assets/har_rationale.png.license
deleted file mode 100644
index e83264aa..00000000
--- a/assets/har_rationale.png.license
+++ /dev/null
@@ -1,5 +0,0 @@
-This source file is part of the OpenTSLM open-source project
-
-SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-
-SPDX-License-Identifier: MIT
diff --git a/assets/m4_caption.png.license b/assets/m4_caption.png.license
deleted file mode 100644
index e83264aa..00000000
--- a/assets/m4_caption.png.license
+++ /dev/null
@@ -1,5 +0,0 @@
-This source file is part of the OpenTSLM open-source project
-
-SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-
-SPDX-License-Identifier: MIT
diff --git a/assets/schematic_overview_2.png.license b/assets/schematic_overview_2.png.license
deleted file mode 100644
index e83264aa..00000000
--- a/assets/schematic_overview_2.png.license
+++ /dev/null
@@ -1,5 +0,0 @@
-This source file is part of the OpenTSLM open-source project
-
-SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-
-SPDX-License-Identifier: MIT
diff --git a/assets/schematic_overview_3.png.license b/assets/schematic_overview_3.png.license
deleted file mode 100644
index e83264aa..00000000
--- a/assets/schematic_overview_3.png.license
+++ /dev/null
@@ -1,5 +0,0 @@
-This source file is part of the OpenTSLM open-source project
-
-SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-
-SPDX-License-Identifier: MIT
diff --git a/assets/sleep_rationale.png.license b/assets/sleep_rationale.png.license
deleted file mode 100644
index e83264aa..00000000
--- a/assets/sleep_rationale.png.license
+++ /dev/null
@@ -1,5 +0,0 @@
-This source file is part of the OpenTSLM open-source project
-
-SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-
-SPDX-License-Identifier: MIT
diff --git a/assets/stanford_biodesign_logo.png.license b/assets/stanford_biodesign_logo.png.license
deleted file mode 100644
index e83264aa..00000000
--- a/assets/stanford_biodesign_logo.png.license
+++ /dev/null
@@ -1,5 +0,0 @@
-This source file is part of the OpenTSLM open-source project
-
-SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-
-SPDX-License-Identifier: MIT
diff --git a/curriculum_learning.py b/curriculum_learning.py
index a0d3b05b..4b25fe25 100644
--- a/curriculum_learning.py
+++ b/curriculum_learning.py
@@ -1,24 +1,21 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
-import sys
-import os
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "src")))
+import os
import json
import os as _os
import argparse
from typing import List, Optional, Dict, Any, Callable
-from time_series_datasets.TSQADataset import TSQADataset
-from time_series_datasets.m4.M4QADataset import M4QADataset
-from time_series_datasets.sleep.SleepEDFCoTQADataset import SleepEDFCoTQADataset
-from time_series_datasets.har_cot.HARCoTQADataset import HARCoTQADataset
-from time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
-from time_series_datasets.util import (
+from opentslm.time_series_datasets.TSQADataset import TSQADataset
+from opentslm.time_series_datasets.m4.M4QADataset import M4QADataset
+from opentslm.time_series_datasets.sleep.SleepEDFCoTQADataset import SleepEDFCoTQADataset
+from opentslm.time_series_datasets.har_cot.HARCoTQADataset import HARCoTQADataset
+from opentslm.time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
+from opentslm.time_series_datasets.util import (
extend_time_series_to_match_patch_size_and_aggregate,
)
import torch
@@ -40,14 +37,14 @@
from tqdm.auto import tqdm
from transformers import get_linear_schedule_with_warmup
-from model.encoder.TransformerCNNEncoder import TransformerCNNEncoder
-from model.llm.OpenTSLMFlamingo import OpenTSLMFlamingo
-from model.llm.OpenTSLMSP import OpenTSLMSP
-from model.projector.MLPProjector import MLPProjector
+from opentslm.model.encoder.TransformerCNNEncoder import TransformerCNNEncoder
+from opentslm.model.llm.OpenTSLMFlamingo import OpenTSLMFlamingo
+from opentslm.model.llm.OpenTSLMSP import OpenTSLMSP
+from opentslm.model.projector.MLPProjector import MLPProjector
import datetime
-from logger import get_logger, set_global_verbose
+from opentslm.logger import get_logger, set_global_verbose
-from model_config import (
+from opentslm.model_config import (
BATCH_SIZE,
EARLY_STOP_PAT,
GRAD_CLIP_NORM,
diff --git a/data/.gitignore b/data/.gitignore
deleted file mode 100644
index 2f75232d..00000000
--- a/data/.gitignore
+++ /dev/null
@@ -1,12 +0,0 @@
-# This source file is part of the OpenTSLM open-source project
-#
-# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-#
-# SPDX-License-Identifier: MIT
-
-*.csv
-*.json
-*.jsonl
-*.jsonl.gz
-*.jsonl.gz.part
-*.jsonl.gz.part.1
\ No newline at end of file
diff --git a/notebooks/.gitignore b/data/.gitkeep
similarity index 100%
rename from notebooks/.gitignore
rename to data/.gitkeep
diff --git a/demo/huggingface/.gitignore b/demo/huggingface/.gitignore
deleted file mode 100644
index 935582c2..00000000
--- a/demo/huggingface/.gitignore
+++ /dev/null
@@ -1,7 +0,0 @@
-# This source file is part of the OpenTSLM open-source project
-#
-# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-#
-# SPDX-License-Identifier: MIT
-
-data
\ No newline at end of file
diff --git a/demo/huggingface/01_test_hf_tsqa.py b/demo/huggingface/01_test_hf_tsqa.py
index eab54d1a..d4545587 100755
--- a/demo/huggingface/01_test_hf_tsqa.py
+++ b/demo/huggingface/01_test_hf_tsqa.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
"""
@@ -13,17 +12,11 @@
4. Prints model outputs
"""
-import sys
-import os
-
-# Add src to path
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "../../src")))
-
-from model.llm.OpenTSLM import OpenTSLM
-from time_series_datasets.TSQADataset import TSQADataset
-from time_series_datasets.util import extend_time_series_to_match_patch_size_and_aggregate
+from opentslm.model.llm.OpenTSLM import OpenTSLM
+from opentslm.time_series_datasets.TSQADataset import TSQADataset
+from opentslm.time_series_datasets.util import extend_time_series_to_match_patch_size_and_aggregate
from torch.utils.data import DataLoader
-from model_config import PATCH_SIZE
+from opentslm.model_config import PATCH_SIZE
import torch
# Model repository ID - change this to test different models
REPO_ID = "OpenTSLM/llama-3.2-1b-tsqa-sp"
diff --git a/demo/huggingface/02_test_hf_m4.py b/demo/huggingface/02_test_hf_m4.py
index ab010302..aa5e0672 100755
--- a/demo/huggingface/02_test_hf_m4.py
+++ b/demo/huggingface/02_test_hf_m4.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
"""
@@ -13,17 +12,11 @@
4. Prints model outputs
"""
-import sys
-import os
-
-# Add src to path
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "../../src")))
-
-from model.llm.OpenTSLM import OpenTSLM
-from time_series_datasets.m4.M4QADataset import M4QADataset
-from time_series_datasets.util import extend_time_series_to_match_patch_size_and_aggregate
+from opentslm.model.llm.OpenTSLM import OpenTSLM
+from opentslm.time_series_datasets.m4.M4QADataset import M4QADataset
+from opentslm.time_series_datasets.util import extend_time_series_to_match_patch_size_and_aggregate
from torch.utils.data import DataLoader
-from model_config import PATCH_SIZE
+from opentslm.model_config import PATCH_SIZE
import torch
# Model repository ID - change this to test different models
diff --git a/demo/huggingface/03_test_hf_har_cot.py b/demo/huggingface/03_test_hf_har_cot.py
index 762c0d5a..910f088d 100755
--- a/demo/huggingface/03_test_hf_har_cot.py
+++ b/demo/huggingface/03_test_hf_har_cot.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
"""
@@ -13,17 +12,11 @@
4. Prints model outputs
"""
-import sys
-import os
-
-# Add src to path
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "../../src")))
-
-from model.llm.OpenTSLM import OpenTSLM
-from time_series_datasets.har_cot.HARCoTQADataset import HARCoTQADataset
-from time_series_datasets.util import extend_time_series_to_match_patch_size_and_aggregate
+from opentslm.model.llm.OpenTSLM import OpenTSLM
+from opentslm.time_series_datasets.har_cot.HARCoTQADataset import HARCoTQADataset
+from opentslm.time_series_datasets.util import extend_time_series_to_match_patch_size_and_aggregate
from torch.utils.data import DataLoader
-from model_config import PATCH_SIZE
+from opentslm.model_config import PATCH_SIZE
import torch
# Model repository ID - change this to test different models
diff --git a/demo/huggingface/04_test_hf_sleep_cot.py b/demo/huggingface/04_test_hf_sleep_cot.py
index 1e7498a2..b878b0da 100755
--- a/demo/huggingface/04_test_hf_sleep_cot.py
+++ b/demo/huggingface/04_test_hf_sleep_cot.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
"""
@@ -13,17 +12,11 @@
4. Prints model outputs
"""
-import sys
-import os
-
-# Add src to path
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "../../src")))
-
-from model.llm.OpenTSLM import OpenTSLM
-from time_series_datasets.sleep.SleepEDFCoTQADataset import SleepEDFCoTQADataset
-from time_series_datasets.util import extend_time_series_to_match_patch_size_and_aggregate
+from opentslm.model.llm.OpenTSLM import OpenTSLM
+from opentslm.time_series_datasets.sleep.SleepEDFCoTQADataset import SleepEDFCoTQADataset
+from opentslm.time_series_datasets.util import extend_time_series_to_match_patch_size_and_aggregate
from torch.utils.data import DataLoader
-from model_config import PATCH_SIZE
+from opentslm.model_config import PATCH_SIZE
import torch
# Model repository ID - change this to test different models
diff --git a/demo/huggingface/05_test_hf_ecg_qa_cot.py b/demo/huggingface/05_test_hf_ecg_qa_cot.py
index c399b814..eacf2bfd 100755
--- a/demo/huggingface/05_test_hf_ecg_qa_cot.py
+++ b/demo/huggingface/05_test_hf_ecg_qa_cot.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
"""
@@ -13,17 +12,11 @@
4. Prints model outputs
"""
-import sys
-import os
-
-# Add src to path
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "../../src")))
-
-from model.llm.OpenTSLM import OpenTSLM
-from time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
-from time_series_datasets.util import extend_time_series_to_match_patch_size_and_aggregate
+from opentslm.model.llm.OpenTSLM import OpenTSLM
+from opentslm.time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
+from opentslm.time_series_datasets.util import extend_time_series_to_match_patch_size_and_aggregate
from torch.utils.data import DataLoader
-from model_config import PATCH_SIZE
+from opentslm.model_config import PATCH_SIZE
import torch
# Model repository ID - change this to test different models
diff --git a/evaluation/.gitignore b/evaluation/.gitignore
deleted file mode 100644
index b33036a5..00000000
--- a/evaluation/.gitignore
+++ /dev/null
@@ -1,7 +0,0 @@
-# This source file is part of the OpenTSLM open-source project
-#
-# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-#
-# SPDX-License-Identifier: MIT
-
-*.jsonl
\ No newline at end of file
diff --git a/evaluation/baseline/README.md b/evaluation/baseline/README.md
index c0bb9b3b..2a4c10e2 100644
--- a/evaluation/baseline/README.md
+++ b/evaluation/baseline/README.md
@@ -1,7 +1,6 @@
diff --git a/evaluation/baseline/common_evaluator.py b/evaluation/baseline/common_evaluator.py
index 56287d10..1c265421 100644
--- a/evaluation/baseline/common_evaluator.py
+++ b/evaluation/baseline/common_evaluator.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -21,13 +20,9 @@
import matplotlib.pyplot as plt
from time import sleep
-# Add src to path
-sys.path.insert(
- 0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..", "..", "src"))
-)
+from opentslm.logger import get_logger
-# Import OpenAIPipeline
-from openai_pipeline import OpenAIPipeline
+from .openai_pipeline import OpenAIPipeline
class CommonEvaluator:
@@ -101,7 +96,7 @@ def load_dataset(
print(f"Loading dataset: {dataset_class.__name__}")
# Import the gruver formatters
- from gruver_llmtime_tokenizer import gpt_formatter, llama_formatter
+ from .gruver_llmtime_tokenizer import gpt_formatter, llama_formatter
# Choose formatter based on model type
model_name = getattr(self, "current_model_name", None)
@@ -528,9 +523,6 @@ def _get_existing_results_count(self, model_name: str, dataset_name: str) -> int
)
if os.path.exists(jsonl_file):
- count = 0
- with open(jsonl_file, "r") as f:
- for line in f:
if line.strip():
count += 1
return count
diff --git a/evaluation/baseline/common_evaluator_plot.py b/evaluation/baseline/common_evaluator_plot.py
index fbe0c8f3..f2f80a71 100644
--- a/evaluation/baseline/common_evaluator_plot.py
+++ b/evaluation/baseline/common_evaluator_plot.py
@@ -1,12 +1,9 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
-import os
import io
-import sys
import base64
from typing import Type, Callable, Dict, List, Any, Optional
@@ -19,12 +16,7 @@
from PIL import Image
import pandas as pd
-# Add src to path
-sys.path.insert(
- 0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..", "..", "src"))
-)
-# Import OpenAIPipeline
from openai_pipeline import OpenAIPipeline
from common_evaluator import CommonEvaluator
diff --git a/evaluation/baseline/eval.sh b/evaluation/baseline/eval.sh
index eee8a90b..2924fca5 100755
--- a/evaluation/baseline/eval.sh
+++ b/evaluation/baseline/eval.sh
@@ -1,8 +1,7 @@
#!/usr/bin/env bash
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/evaluation/baseline/eval_remaining.sh b/evaluation/baseline/eval_remaining.sh
index c8d6e2ed..ce7095f2 100644
--- a/evaluation/baseline/eval_remaining.sh
+++ b/evaluation/baseline/eval_remaining.sh
@@ -1,8 +1,7 @@
#!/usr/bin/env bash
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/evaluation/baseline/evaluate_all.py b/evaluation/baseline/evaluate_all.py
index 6776ac41..db1a8914 100644
--- a/evaluation/baseline/evaluate_all.py
+++ b/evaluation/baseline/evaluate_all.py
@@ -1,14 +1,13 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
from typing import Dict, Any, Callable
from common_evaluator import CommonEvaluator
-from time_series_datasets.TSQADataset import TSQADataset
-from time_series_datasets.pamap2.PAMAP2AccQADataset import PAMAP2AccQADataset
-from time_series_datasets.pamap2.PAMAP2CoTQADataset import PAMAP2CoTQADataset
+from opentslm.time_series_datasets.TSQADataset import TSQADataset
+from opentslm.time_series_datasets.pamap2.PAMAP2AccQADataset import PAMAP2AccQADataset
+from opentslm.time_series_datasets.pamap2.PAMAP2CoTQADataset import PAMAP2CoTQADataset
# Import evaluation functions
from evaluate_tsqa import evaluate_tsqa
diff --git a/evaluation/baseline/evaluate_ecg_qa.py b/evaluation/baseline/evaluate_ecg_qa.py
index 9b4c3c5d..49eb8767 100644
--- a/evaluation/baseline/evaluate_ecg_qa.py
+++ b/evaluation/baseline/evaluate_ecg_qa.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -10,7 +9,7 @@
from common_evaluator import CommonEvaluator
-from time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
+from opentslm.time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
def extract_answer(text: str) -> str:
diff --git a/evaluation/baseline/evaluate_ecg_qa_plot.py b/evaluation/baseline/evaluate_ecg_qa_plot.py
index 305669e4..062c2302 100644
--- a/evaluation/baseline/evaluate_ecg_qa_plot.py
+++ b/evaluation/baseline/evaluate_ecg_qa_plot.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -15,7 +14,7 @@
import matplotlib.pyplot as plt
from common_evaluator_plot import CommonEvaluatorPlot
-from time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
+from opentslm.time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
def extract_answer(text: str) -> str:
diff --git a/evaluation/baseline/evaluate_har.py b/evaluation/baseline/evaluate_har.py
index 84dcf222..8892a9aa 100644
--- a/evaluation/baseline/evaluate_har.py
+++ b/evaluation/baseline/evaluate_har.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -8,7 +7,7 @@
import sys
from typing import Dict, Any
-from time_series_datasets.har_cot.HARCoTQADataset import HARCoTQADataset
+from opentslm.time_series_datasets.har_cot.HARCoTQADataset import HARCoTQADataset
def extract_label_from_prediction(prediction: str) -> str:
diff --git a/evaluation/baseline/evaluate_har_plot.py b/evaluation/baseline/evaluate_har_plot.py
index 73b2b51b..a5141fcb 100644
--- a/evaluation/baseline/evaluate_har_plot.py
+++ b/evaluation/baseline/evaluate_har_plot.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -14,8 +13,8 @@
import matplotlib.pyplot as plt
from common_evaluator_plot import CommonEvaluatorPlot
-from time_series_datasets.pamap2.PAMAP2AccQADataset import PAMAP2AccQADataset
-from time_series_datasets.har_cot.HARAccQADataset import HARAccQADataset
+from opentslm.time_series_datasets.pamap2.PAMAP2AccQADataset import PAMAP2AccQADataset
+from opentslm.time_series_datasets.har_cot.HARAccQADataset import HARAccQADataset
def extract_label_from_prediction(prediction: str) -> str:
"""
diff --git a/evaluation/baseline/evaluate_pamap.py b/evaluation/baseline/evaluate_pamap.py
index d966fa31..22eeeb58 100644
--- a/evaluation/baseline/evaluate_pamap.py
+++ b/evaluation/baseline/evaluate_pamap.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -9,7 +8,7 @@
from typing import Dict, Any
from common_evaluator import CommonEvaluator
-from time_series_datasets.pamap2.PAMAP2AccQADataset import PAMAP2AccQADataset
+from opentslm.time_series_datasets.pamap2.PAMAP2AccQADataset import PAMAP2AccQADataset
def extract_label_from_prediction(prediction: str) -> str:
diff --git a/evaluation/baseline/evaluate_sleep_cot.py b/evaluation/baseline/evaluate_sleep_cot.py
index 5d4058e8..8ed5087a 100644
--- a/evaluation/baseline/evaluate_sleep_cot.py
+++ b/evaluation/baseline/evaluate_sleep_cot.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -9,7 +8,7 @@
from typing import Dict, Any
from common_evaluator import CommonEvaluator
-from time_series_datasets.sleep.SleepEDFCoTQADataset import SleepEDFCoTQADataset
+from opentslm.time_series_datasets.sleep.SleepEDFCoTQADataset import SleepEDFCoTQADataset
def extract_sleep_stage_from_prediction(prediction: str) -> str:
diff --git a/evaluation/baseline/evaluate_sleep_plot.py b/evaluation/baseline/evaluate_sleep_plot.py
index 10029ba4..ea224088 100644
--- a/evaluation/baseline/evaluate_sleep_plot.py
+++ b/evaluation/baseline/evaluate_sleep_plot.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -14,7 +13,7 @@
import numpy as np
from common_evaluator_plot import CommonEvaluatorPlot
-from time_series_datasets.sleep.SleepEDFCoTQADataset import SleepEDFCoTQADataset
+from opentslm.time_series_datasets.sleep.SleepEDFCoTQADataset import SleepEDFCoTQADataset
def extract_label_from_text(text: str) -> str:
diff --git a/evaluation/baseline/evaluate_tsqa.py b/evaluation/baseline/evaluate_tsqa.py
index 96118bcf..157bb77a 100644
--- a/evaluation/baseline/evaluate_tsqa.py
+++ b/evaluation/baseline/evaluate_tsqa.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -9,7 +8,7 @@
from typing import Dict, Any
from common_evaluator import CommonEvaluator
-from time_series_datasets.TSQADataset import TSQADataset
+from opentslm.time_series_datasets.TSQADataset import TSQADataset
def evaluate_tsqa(ground_truth: str, prediction: str) -> Dict[str, Any]:
diff --git a/evaluation/baseline/evaluate_tsqa_plot.py b/evaluation/baseline/evaluate_tsqa_plot.py
index 07ff3253..8e4cba28 100644
--- a/evaluation/baseline/evaluate_tsqa_plot.py
+++ b/evaluation/baseline/evaluate_tsqa_plot.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -13,7 +12,7 @@
import matplotlib.pyplot as plt
from common_evaluator_plot import CommonEvaluatorPlot
-from time_series_datasets.TSQADataset import TSQADataset
+from opentslm.time_series_datasets.TSQADataset import TSQADataset
def evaluate_tsqa(ground_truth: str, prediction: str) -> Dict[str, Any]:
diff --git a/evaluation/baseline/gruver_llmtime_tokenizer.py b/evaluation/baseline/gruver_llmtime_tokenizer.py
index ad08cacd..3f82ee0c 100644
--- a/evaluation/baseline/gruver_llmtime_tokenizer.py
+++ b/evaluation/baseline/gruver_llmtime_tokenizer.py
@@ -1,10 +1,8 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
-import sys
import numpy as np
from functools import partial
from dataclasses import dataclass
diff --git a/evaluation/baseline/openai_pipeline.py b/evaluation/baseline/openai_pipeline.py
index e69588b6..1f4dd62a 100644
--- a/evaluation/baseline/openai_pipeline.py
+++ b/evaluation/baseline/openai_pipeline.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/evaluation/baseline/parse_predictions_baseline.py b/evaluation/baseline/parse_predictions_baseline.py
index a77e892f..93b83c32 100644
--- a/evaluation/baseline/parse_predictions_baseline.py
+++ b/evaluation/baseline/parse_predictions_baseline.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -15,13 +14,6 @@
from pathlib import Path
from typing import Dict, List
-import sys
-
-# Ensure repository root is on sys.path so 'evaluation' package is importable
-REPO_ROOT = Path(__file__).resolve().parents[2]
-if str(REPO_ROOT) not in sys.path:
- sys.path.insert(0, str(REPO_ROOT))
-
from evaluation.opentslm.parse_predictions import (
calculate_f1_score,
calculate_f1_stats,
diff --git a/evaluation/baseline/parse_predictions_sleep_baseline.py b/evaluation/baseline/parse_predictions_sleep_baseline.py
index 4e090919..7d7c2b3b 100644
--- a/evaluation/baseline/parse_predictions_sleep_baseline.py
+++ b/evaluation/baseline/parse_predictions_sleep_baseline.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -42,17 +41,6 @@
import json
from pathlib import Path
from typing import Dict, List
-import sys
-
-# Ensure repository root is on sys.path so 'evaluation' package is importable
-REPO_ROOT = Path(__file__).resolve().parents[2]
-if str(REPO_ROOT) not in sys.path:
- sys.path.insert(0, str(REPO_ROOT))
-
-# Also ensure 'src' is on sys.path if needed in the future
-SRC_ROOT = REPO_ROOT / "src"
-if str(SRC_ROOT) not in sys.path:
- sys.path.insert(0, str(SRC_ROOT))
# --- Inline minimal utilities (avoid importing modules that require extra packages) ---
import re
diff --git a/evaluation/baseline/parse_predictions_tsqa_baseline.py b/evaluation/baseline/parse_predictions_tsqa_baseline.py
index 5db56c79..33a289d8 100644
--- a/evaluation/baseline/parse_predictions_tsqa_baseline.py
+++ b/evaluation/baseline/parse_predictions_tsqa_baseline.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -43,12 +42,6 @@
import re
from pathlib import Path
from typing import Dict, List
-import sys
-
-# Ensure repository root is on sys.path so 'evaluation' package is importable
-REPO_ROOT = Path(__file__).resolve().parents[2]
-if str(REPO_ROOT) not in sys.path:
- sys.path.insert(0, str(REPO_ROOT))
from evaluation.opentslm.parse_predictions import (
calculate_f1_score,
diff --git a/evaluation/clinician_eval/create_doctor_eval_dataset.py b/evaluation/clinician_eval/create_doctor_eval_dataset.py
index 7cc2fa58..637dfa0d 100644
--- a/evaluation/clinician_eval/create_doctor_eval_dataset.py
+++ b/evaluation/clinician_eval/create_doctor_eval_dataset.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -14,22 +13,17 @@
import json
import os
-import sys
import re
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import wfdb
-from pathlib import Path
-from typing import Dict, List, Set, Tuple
+from typing import Dict, List, Tuple
from collections import defaultdict
from tqdm import tqdm
-import shutil
-# Add the src directory to the path
-sys.path.append(os.path.join(os.path.dirname(__file__), "src"))
-from time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
-from time_series_datasets.ecg_qa.plot_example import draw_ecg, get_ptbxl_ecg_path
+from opentslm.time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
+from opentslm.time_series_datasets.ecg_qa.plot_example import get_ptbxl_ecg_path
# Configuration
MODEL_PREDICTIONS_FILE = "/Users/planger/Development/EmbedHealth/evaluation/opentslm/ecg_qa_cot/llama3b_flamingo_predictions.jsonl"
diff --git a/evaluation/clinicianecg/.gitignore b/evaluation/clinicianecg/.gitignore
deleted file mode 100644
index 572e1fe4..00000000
--- a/evaluation/clinicianecg/.gitignore
+++ /dev/null
@@ -1,19 +0,0 @@
-# This source file is part of the OpenTSLM open-source project
-#
-# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-#
-# SPDX-License-Identifier: MIT
-
-.temp
-.venv
-venv
-__pycache__
-
-# ECG dataset - large files that should be stored separately (e.g., Git LFS, cloud storage)
-data/
-
-# Generated reviewer assignments and workbooks
-reviewer_workbooks/
-
-# Analysis results - these are generated and can be large
-analysis_results/
\ No newline at end of file
diff --git a/evaluation/clinicianecg/README.md b/evaluation/clinicianecg/README.md
index ed8bdbf6..95b9e2f4 100644
--- a/evaluation/clinicianecg/README.md
+++ b/evaluation/clinicianecg/README.md
@@ -1,7 +1,6 @@
diff --git a/evaluation/clinicianecg/REVIEWER_INSTRUCTIONS.md b/evaluation/clinicianecg/REVIEWER_INSTRUCTIONS.md
index b76b02e9..fbd9e849 100644
--- a/evaluation/clinicianecg/REVIEWER_INSTRUCTIONS.md
+++ b/evaluation/clinicianecg/REVIEWER_INSTRUCTIONS.md
@@ -1,7 +1,6 @@
diff --git a/evaluation/clinicianecg/pipeline/1_dataset_analyzer.py b/evaluation/clinicianecg/pipeline/1_dataset_analyzer.py
index 317d6dcf..e8f1f838 100644
--- a/evaluation/clinicianecg/pipeline/1_dataset_analyzer.py
+++ b/evaluation/clinicianecg/pipeline/1_dataset_analyzer.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/evaluation/clinicianecg/pipeline/2.5_demo_responses.py b/evaluation/clinicianecg/pipeline/2.5_demo_responses.py
index d174fa06..f022ad6d 100644
--- a/evaluation/clinicianecg/pipeline/2.5_demo_responses.py
+++ b/evaluation/clinicianecg/pipeline/2.5_demo_responses.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/evaluation/clinicianecg/pipeline/2_excel_generator.py b/evaluation/clinicianecg/pipeline/2_excel_generator.py
index 1dee6d31..a439abe8 100644
--- a/evaluation/clinicianecg/pipeline/2_excel_generator.py
+++ b/evaluation/clinicianecg/pipeline/2_excel_generator.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/evaluation/clinicianecg/pipeline/3_response_analyzer.py b/evaluation/clinicianecg/pipeline/3_response_analyzer.py
index 024c80f6..0b03f631 100644
--- a/evaluation/clinicianecg/pipeline/3_response_analyzer.py
+++ b/evaluation/clinicianecg/pipeline/3_response_analyzer.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/evaluation/clinicianecg/pipeline/config.json.license b/evaluation/clinicianecg/pipeline/config.json.license
deleted file mode 100644
index e83264aa..00000000
--- a/evaluation/clinicianecg/pipeline/config.json.license
+++ /dev/null
@@ -1,5 +0,0 @@
-This source file is part of the OpenTSLM open-source project
-
-SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-
-SPDX-License-Identifier: MIT
diff --git a/evaluation/clinicianecg/pipeline/requirements.txt b/evaluation/clinicianecg/pipeline/requirements.txt
index 17ad0aba..672d181a 100644
--- a/evaluation/clinicianecg/pipeline/requirements.txt
+++ b/evaluation/clinicianecg/pipeline/requirements.txt
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/evaluation/memory/get_memory_use.py b/evaluation/memory/get_memory_use.py
index c7cf943d..ec80ce1f 100644
--- a/evaluation/memory/get_memory_use.py
+++ b/evaluation/memory/get_memory_use.py
@@ -1,14 +1,11 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
import argparse
import csv
import os
-import sys
-import time
from datetime import datetime
from typing import Dict, List, Tuple
@@ -20,31 +17,22 @@
import pynvml # type: ignore
-_NVML_AVAILABLE = True
-
-
-# Ensure src is on path
-REPO_DIR = os.path.dirname(os.path.abspath(__file__))
-if REPO_DIR not in sys.path:
- sys.path.append(REPO_DIR)
-SRC_DIR = os.path.join(REPO_DIR, "src")
-if SRC_DIR not in sys.path:
- sys.path.append(SRC_DIR)
# Models
-from model.llm.OpenTSLMFlamingo import OpenTSLMFlamingo
-from model.llm.OpenTSLMSP import OpenTSLMSP
+from opentslm.model.llm.OpenTSLMFlamingo import OpenTSLMFlamingo
+from opentslm.model.llm.OpenTSLMSP import OpenTSLMSP
# Datasets
-from time_series_datasets.TSQADataset import TSQADataset
-from time_series_datasets.har_cot.HARCoTQADataset import HARCoTQADataset
-from time_series_datasets.sleep.SleepEDFCoTQADataset import SleepEDFCoTQADataset
-from time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
-from time_series_datasets.simulation.SimulationQADataset import SimulationQADataset
-from time_series_datasets.util import (
+from opentslm.time_series_datasets.TSQADataset import TSQADataset
+from opentslm.time_series_datasets.har_cot.HARCoTQADataset import HARCoTQADataset
+from opentslm.time_series_datasets.sleep.SleepEDFCoTQADataset import SleepEDFCoTQADataset
+from opentslm.time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
+from opentslm.time_series_datasets.simulation.SimulationQADataset import SimulationQADataset
+from opentslm.time_series_datasets.util import (
extend_time_series_to_match_patch_size_and_aggregate,
)
+_NVML_AVAILABLE = True
def get_device(device_arg: str | None) -> str:
if device_arg:
diff --git a/evaluation/memory/plot_memory_scaling.py b/evaluation/memory/plot_memory_scaling.py
index 93361a51..8d9c46ab 100644
--- a/evaluation/memory/plot_memory_scaling.py
+++ b/evaluation/memory/plot_memory_scaling.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/evaluation/memory/plot_memory_simulation.py b/evaluation/memory/plot_memory_simulation.py
index c431da01..44567200 100644
--- a/evaluation/memory/plot_memory_simulation.py
+++ b/evaluation/memory/plot_memory_simulation.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/evaluation/memory/plot_memory_simulation_per_length.py b/evaluation/memory/plot_memory_simulation_per_length.py
index cf3677a7..946394ad 100644
--- a/evaluation/memory/plot_memory_simulation_per_length.py
+++ b/evaluation/memory/plot_memory_simulation_per_length.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/evaluation/memory/plot_memory_usage.py b/evaluation/memory/plot_memory_usage.py
index d676a683..8d6b64b3 100644
--- a/evaluation/memory/plot_memory_usage.py
+++ b/evaluation/memory/plot_memory_usage.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/evaluation/memory/run_all_memory.sh b/evaluation/memory/run_all_memory.sh
index e743d1ee..cf58b050 100644
--- a/evaluation/memory/run_all_memory.sh
+++ b/evaluation/memory/run_all_memory.sh
@@ -1,8 +1,7 @@
#!/usr/bin/env bash
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/evaluation/opentslm/baseline_parse_predictions.py b/evaluation/opentslm/baseline_parse_predictions.py
index 4b90f925..940606f0 100644
--- a/evaluation/opentslm/baseline_parse_predictions.py
+++ b/evaluation/opentslm/baseline_parse_predictions.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -16,12 +15,8 @@
from collections import Counter
from tqdm import tqdm
-# Add the src directory to the path to import from the dataset class
-project_root = os.path.abspath(os.path.join(os.path.dirname(__file__), "..", ".."))
-sys.path.append(os.path.join(project_root, "src"))
-
# Import the dataset class to get labels
-from time_series_datasets.har_cot.HARCoTQADataset import HARCoTQADataset
+from opentslm.time_series_datasets.har_cot.HARCoTQADataset import HARCoTQADataset
# Get the supported labels from the dataset class
SUPPORTED_LABELS = HARCoTQADataset.get_labels()
diff --git a/evaluation/opentslm/ecg_qa_cot/parse_ecg_qa_cot_data.py b/evaluation/opentslm/ecg_qa_cot/parse_ecg_qa_cot_data.py
index bff237c1..c6b31115 100644
--- a/evaluation/opentslm/ecg_qa_cot/parse_ecg_qa_cot_data.py
+++ b/evaluation/opentslm/ecg_qa_cot/parse_ecg_qa_cot_data.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -16,9 +15,8 @@
from collections import Counter, defaultdict
from tqdm import tqdm
-# Add the src directory to the path to import from the dataset class
-sys.path.append(os.path.join(os.path.dirname(__file__), "..", "..", "..", "src"))
-from time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
+# Import dataset via package namespace
+from opentslm.time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
def calculate_f1_score(prediction, ground_truth, possible_answers):
diff --git a/evaluation/opentslm/get_pamap_cot_predictions.py b/evaluation/opentslm/get_pamap_cot_predictions.py
index 8db1ad4b..6d0c4540 100644
--- a/evaluation/opentslm/get_pamap_cot_predictions.py
+++ b/evaluation/opentslm/get_pamap_cot_predictions.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -22,26 +21,19 @@
- CSV file with time series data, ground truth labels, and rationale
"""
-import sys
-import os
import torch
import pandas as pd
-import numpy as np
import random
from typing import List, Dict, Any
import json
-# Add src to path
-sys.path.insert(
- 0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..", "..", "src"))
-)
-from model.llm.OpenTSLMFlamingo import OpenTSLMFlamingo
-from time_series_datasets.pamap2.PAMAP2CoTQADataset import PAMAP2CoTQADataset
-from prompt.full_prompt import FullPrompt
-from prompt.text_prompt import TextPrompt
-from prompt.text_time_series_prompt import TextTimeSeriesPrompt
-from time_series_datasets.util import (
+from opentslm.model.llm.OpenTSLMFlamingo import OpenTSLMFlamingo
+from opentslm.time_series_datasets.pamap2.PAMAP2CoTQADataset import PAMAP2CoTQADataset
+from opentslm.prompt.full_prompt import FullPrompt
+from opentslm.prompt.text_prompt import TextPrompt
+from opentslm.prompt.text_time_series_prompt import TextTimeSeriesPrompt
+from opentslm.time_series_datasets.util import (
extend_time_series_to_match_patch_size_and_aggregate,
)
diff --git a/evaluation/opentslm/parse_predictions.py b/evaluation/opentslm/parse_predictions.py
index fa0314ec..94802786 100644
--- a/evaluation/opentslm/parse_predictions.py
+++ b/evaluation/opentslm/parse_predictions.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -15,12 +14,8 @@
from pathlib import Path
from collections import Counter
-# Add the src directory to the path to import from the dataset class
-project_root = os.path.abspath(os.path.join(os.path.dirname(__file__), "..", ".."))
-sys.path.append(os.path.join(project_root, "src"))
-
# Import the dataset class to get labels
-from time_series_datasets.har_cot.HARCoTQADataset import HARCoTQADataset
+from opentslm.time_series_datasets.har_cot.HARCoTQADataset import HARCoTQADataset
# Get the supported labels from the dataset class
SUPPORTED_LABELS = HARCoTQADataset.get_labels()
diff --git a/evaluation/opentslm/sleep/baseline_parse_sleep_cot_data.py b/evaluation/opentslm/sleep/baseline_parse_sleep_cot_data.py
index 118a4879..7d756180 100644
--- a/evaluation/opentslm/sleep/baseline_parse_sleep_cot_data.py
+++ b/evaluation/opentslm/sleep/baseline_parse_sleep_cot_data.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -10,15 +9,10 @@
import json
import re
-import sys
-import os
from pathlib import Path
-from collections import Counter
from tqdm import tqdm
-# Add the src directory to the path to import from the dataset class
-sys.path.append(os.path.join(os.path.dirname(__file__), "..", "..", "..", "src"))
-from time_series_datasets.sleep.SleepEDFCoTQADataset import SleepEDFCoTQADataset
+from opentslm.time_series_datasets.sleep.SleepEDFCoTQADataset import SleepEDFCoTQADataset
# We'll determine supported labels dynamically from the actual ground truth data
# Start with the dataset class labels as a fallback
diff --git a/evaluation/opentslm/sleep/get_sleep_predictions.py b/evaluation/opentslm/sleep/get_sleep_predictions.py
index d7a524d6..bfb19356 100644
--- a/evaluation/opentslm/sleep/get_sleep_predictions.py
+++ b/evaluation/opentslm/sleep/get_sleep_predictions.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -22,26 +21,18 @@
- CSV file with time series data, ground truth labels, and rationale
"""
-import sys
-import os
import torch
import pandas as pd
-import numpy as np
import random
from typing import List, Dict, Any
import json
-# Add src to path
-sys.path.insert(
- 0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..", "..", "..", "src"))
-)
-
-from model.llm.OpenTSLMSP import OpenTSLMSP
-from time_series_datasets.sleep.SleepEDFCoTQADataset import SleepEDFCoTQADataset
-from prompt.full_prompt import FullPrompt
-from prompt.text_prompt import TextPrompt
-from prompt.text_time_series_prompt import TextTimeSeriesPrompt
-from time_series_datasets.util import (
+from opentslm.model.llm.OpenTSLMSP import OpenTSLMSP
+from opentslm.time_series_datasets.sleep.SleepEDFCoTQADataset import SleepEDFCoTQADataset
+from opentslm.prompt.full_prompt import FullPrompt
+from opentslm.prompt.text_prompt import TextPrompt
+from opentslm.prompt.text_time_series_prompt import TextTimeSeriesPrompt
+from opentslm.time_series_datasets.util import (
extend_time_series_to_match_patch_size_and_aggregate,
)
diff --git a/evaluation/opentslm/sleep/parse_sleep_cot_data.py b/evaluation/opentslm/sleep/parse_sleep_cot_data.py
index 4b4d6e4a..5eb9e6c8 100644
--- a/evaluation/opentslm/sleep/parse_sleep_cot_data.py
+++ b/evaluation/opentslm/sleep/parse_sleep_cot_data.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -16,9 +15,8 @@
from collections import Counter
from tqdm import tqdm
-# Add the src directory to the path to import from the dataset class
-sys.path.append(os.path.join(os.path.dirname(__file__), "..", "..", "..", "src"))
-from time_series_datasets.sleep.SleepEDFCoTQADataset import SleepEDFCoTQADataset
+# Import dataset via package namespace
+from opentslm.time_series_datasets.sleep.SleepEDFCoTQADataset import SleepEDFCoTQADataset
# We'll determine supported labels dynamically from the actual ground truth data
# Start with the dataset class labels as a fallback
diff --git a/evaluation/opentslm/sleep/plot_sleep_predictions.py b/evaluation/opentslm/sleep/plot_sleep_predictions.py
index d0da4653..675ebfd2 100644
--- a/evaluation/opentslm/sleep/plot_sleep_predictions.py
+++ b/evaluation/opentslm/sleep/plot_sleep_predictions.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/evaluation/opentslm/tsqa/baseline_parse_predictions.py b/evaluation/opentslm/tsqa/baseline_parse_predictions.py
index 3c5101ec..f44e2bc7 100644
--- a/evaluation/opentslm/tsqa/baseline_parse_predictions.py
+++ b/evaluation/opentslm/tsqa/baseline_parse_predictions.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/evaluation/opentslm/tsqa/parse_predictions.py b/evaluation/opentslm/tsqa/parse_predictions.py
index cf2d9ec7..36953143 100644
--- a/evaluation/opentslm/tsqa/parse_predictions.py
+++ b/evaluation/opentslm/tsqa/parse_predictions.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/pyproject.toml b/pyproject.toml
new file mode 100644
index 00000000..6f7056a0
--- /dev/null
+++ b/pyproject.toml
@@ -0,0 +1,102 @@
+# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
+#
+# SPDX-License-Identifier: MIT
+
+[project]
+name = "opentslm"
+version = "0.1.0"
+description = "OpenTSLM: Open Time Series Language Model - Curriculum Learning for Multimodal Time Series Understanding with Large Language Models"
+readme = "README.md"
+requires-python = ">=3.12"
+license = "MIT"
+authors = [
+ {name = "Patrick Langer"},
+ {name = "Thomas Kaar"},
+ {name = "Max Rosenblattl"},
+ {name = "Maxwell A. Xu"},
+ {name = "Winnie Chow"},
+ {name = "Martin Maritsch"},
+ {name = "Robert Jakob"},
+ {name = "Aradhana Verma"},
+ {name = "Brian Han"},
+ {name = "Daniel Seung Kim"},
+ {name = "Henry Chubb"},
+ {name = "Scott Ceresnak"},
+ {name = "Aydin Zahedivash"},
+ {name = "Alexander Tarlochan Singh Sandhu"},
+ {name = "Fatima Rodriguez"},
+ {name = "Daniel McDuff"},
+ {name = "Elgar Fleisch"},
+ {name = "Oliver Aalami"},
+ {name = "Filipe Barata"},
+ {name = "Paul Schmiedmayer"}
+]
+keywords = [
+ "time-series",
+ "large-language-models",
+ "curriculum-learning",
+ "multimodal",
+ "healthcare"
+]
+
+dependencies = [
+ "numpy>=1.21",
+ "pandas>=1.3",
+ "torch>=2.0",
+ "tqdm>=4.62",
+ "matplotlib>=3.3",
+ "scikit-learn>=1.0",
+ "transformers>=4.25",
+ "huggingface-hub>=0.16",
+ "datasets>=2.0",
+ "peft>=0.4",
+ "requests>=2.28",
+ "einops>=0.6",
+ "wfdb>=4.0",
+ "open-flamingo>=0.0.2",
+]
+
+[project.urls]
+Homepage = "https://opentslm.com"
+Repository = "https://github.com/StanfordBDHG/OpenTSLM"
+"Bug Tracker" = "https://github.com/StanfordBDHG/OpenTSLM/issues"
+
+[dependency-groups]
+dev = [
+ "reuse>=6.2.0",
+ "ruff>=0.14.0",
+]
+
+eval = [
+ "openai>=1.0",
+]
+
+notebook = [
+ "jupyter>=1.0",
+ "ipython>=8.0",
+ "seaborn>=0.13.2",
+]
+
+[build-system]
+requires = ["uv_build>=0.9.0,<0.10.0"]
+build-backend = "uv_build"
+
+[tool.uv]
+required-version = ">=0.9"
+
+[[tool.uv.index]]
+name = "testpypi"
+url = "https://test.pypi.org/simple/"
+publish-url = "https://test.pypi.org/legacy/"
+explicit = true
+
+[tool.uv.workspace]
+members = [
+ "test-install",
+]
+
+
+[tool.ruff]
+line-length = 120
+target-version = "py312"
diff --git a/requirements.txt b/requirements.txt
index 857847ad..097fbbe2 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,27 +1,20 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
-numpy
-pandas
-torch
-joblib
-argparse
-tqdm
-matplotlib
-scikit-learn
-torchinfo
-transformers
-chronos-forecasting
-huggingface-hub
-datasets
-peft
-requests
-open-clip-torch
-einops
-einops-exts
-pyvim
-openai
-wfdb
\ No newline at end of file
+numpy>=2.3.5
+pandas>=2.3.3
+torch>=2.9.1
+tqdm>=4.67.1
+matplotlib>=3.10.7
+scikit-learn>=1.7.2
+transformers>=4.57.3
+huggingface-hub>=0.36.0
+datasets>=4.4.1
+peft>=0.18.0
+requests>=2.32.5
+einops>=0.8.1
+wfdb>=4.3.0
+open-flamingo>=0.0.2
+-e .
\ No newline at end of file
diff --git a/create_doctor_eval_dataset.py b/scripts/create_doctor_eval_dataset.py
similarity index 97%
rename from create_doctor_eval_dataset.py
rename to scripts/create_doctor_eval_dataset.py
index 59473faa..a7776238 100644
--- a/create_doctor_eval_dataset.py
+++ b/scripts/create_doctor_eval_dataset.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
"""
@@ -11,22 +10,18 @@
import json
import os
-import sys
import re
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import wfdb
-from pathlib import Path
-from typing import Dict, List, Set, Tuple
+from typing import Dict, List, Tuple
from collections import defaultdict
from tqdm import tqdm
-import shutil
# Add the src directory to the path
-sys.path.append(os.path.join(os.path.dirname(__file__), 'src'))
-from time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
-from time_series_datasets.ecg_qa.plot_example import draw_ecg, get_ptbxl_ecg_path
+from opentslm.time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
+from opentslm.time_series_datasets.ecg_qa.plot_example import get_ptbxl_ecg_path
# Configuration
MODEL_PREDICTIONS_FILE = "/Users/planger/Development/EmbedHealth/evaluation/embedhealth/ecg_qa_cot/llama3b_flamingo_predictions.jsonl"
diff --git a/get_memory_use.py b/scripts/get_memory_use.py
similarity index 94%
rename from get_memory_use.py
rename to scripts/get_memory_use.py
index 852423e3..1995c689 100644
--- a/get_memory_use.py
+++ b/scripts/get_memory_use.py
@@ -1,13 +1,11 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
import argparse
import csv
import os
-import sys
import time
from datetime import datetime
from typing import Dict, List, Tuple
@@ -22,25 +20,17 @@
_NVML_AVAILABLE = True
-# Ensure src is on path
-REPO_DIR = os.path.dirname(os.path.abspath(__file__))
-if REPO_DIR not in sys.path:
- sys.path.append(REPO_DIR)
-SRC_DIR = os.path.join(REPO_DIR, "src")
-if SRC_DIR not in sys.path:
- sys.path.append(SRC_DIR)
-
# Models
-from model.llm.OpenTSLMFlamingo import OpenTSLMFlamingo
-from model.llm.OpenTSLMSP import OpenTSLMSP
+from opentslm.model.llm.OpenTSLMFlamingo import OpenTSLMFlamingo
+from opentslm.model.llm.OpenTSLMSP import OpenTSLMSP
# Datasets
-from time_series_datasets.TSQADataset import TSQADataset
-from time_series_datasets.har_cot.HARCoTQADataset import HARCoTQADataset
-from time_series_datasets.sleep.SleepEDFCoTQADataset import SleepEDFCoTQADataset
-from time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
-from time_series_datasets.simulation.SimulationQADataset import SimulationQADataset
-from time_series_datasets.util import (
+from opentslm.time_series_datasets.TSQADataset import TSQADataset
+from opentslm.time_series_datasets.har_cot.HARCoTQADataset import HARCoTQADataset
+from opentslm.time_series_datasets.sleep.SleepEDFCoTQADataset import SleepEDFCoTQADataset
+from opentslm.time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
+from opentslm.time_series_datasets.simulation.SimulationQADataset import SimulationQADataset
+from opentslm.time_series_datasets.util import (
extend_time_series_to_match_patch_size_and_aggregate,
)
diff --git a/hf_test.py b/scripts/hf_test.py
similarity index 78%
rename from hf_test.py
rename to scripts/hf_test.py
index 318d2012..ba1ac3c5 100644
--- a/hf_test.py
+++ b/scripts/hf_test.py
@@ -1,9 +1,9 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
-from src import OpenTSLM, TextPrompt, TextTimeSeriesPrompt, FullPrompt
+from opentslm import OpenTSLM
+from opentslm.prompt import TextPrompt, TextTimeSeriesPrompt, FullPrompt
# Load model
model = OpenTSLM.load_pretrained("OpenTSLM/gemma-3-270m-pt-har-flamingo")
diff --git a/plot_memory_simulation.py b/scripts/plot_memory_simulation.py
similarity index 98%
rename from plot_memory_simulation.py
rename to scripts/plot_memory_simulation.py
index d033b663..ee587a4e 100644
--- a/plot_memory_simulation.py
+++ b/scripts/plot_memory_simulation.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
"""
diff --git a/plot_memory_simulation_per_length.py b/scripts/plot_memory_simulation_per_length.py
similarity index 99%
rename from plot_memory_simulation_per_length.py
rename to scripts/plot_memory_simulation_per_length.py
index 409028d6..2f09ab10 100644
--- a/plot_memory_simulation_per_length.py
+++ b/scripts/plot_memory_simulation_per_length.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
"""
diff --git a/plot_memory_usage.py b/scripts/plot_memory_usage.py
similarity index 97%
rename from plot_memory_usage.py
rename to scripts/plot_memory_usage.py
index 344cfb31..0140e89f 100644
--- a/plot_memory_usage.py
+++ b/scripts/plot_memory_usage.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/run_all_memory.sh b/scripts/run_all_memory.sh
similarity index 96%
rename from run_all_memory.sh
rename to scripts/run_all_memory.sh
index e743d1ee..cf58b050 100644
--- a/run_all_memory.sh
+++ b/scripts/run_all_memory.sh
@@ -1,8 +1,7 @@
#!/usr/bin/env bash
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/run_all_memory_missing.sh b/scripts/run_all_memory_missing.sh
similarity index 97%
rename from run_all_memory_missing.sh
rename to scripts/run_all_memory_missing.sh
index a6c50ffe..7d0aa7b6 100644
--- a/run_all_memory_missing.sh
+++ b/scripts/run_all_memory_missing.sh
@@ -1,8 +1,7 @@
#!/usr/bin/env bash
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/src/model/projector/__init__.py b/src/model/projector/__init__.py
deleted file mode 100644
index 266b1365..00000000
--- a/src/model/projector/__init__.py
+++ /dev/null
@@ -1,5 +0,0 @@
-# This source file is part of the OpenTSLM open-source project
-#
-# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-#
-# SPDX-License-Identifier: MIT
diff --git a/src/open_flamingo b/src/open_flamingo
deleted file mode 160000
index 914076ee..00000000
--- a/src/open_flamingo
+++ /dev/null
@@ -1 +0,0 @@
-Subproject commit 914076ee07d0235943f1556e9aaf2fb974337f0e
diff --git a/src/opentslm/__init__.py b/src/opentslm/__init__.py
new file mode 100644
index 00000000..0078c70d
--- /dev/null
+++ b/src/opentslm/__init__.py
@@ -0,0 +1,8 @@
+# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
+#
+# SPDX-License-Identifier: MIT
+
+from opentslm.model.llm.OpenTSLM import OpenTSLM
+
+__all__ = ["OpenTSLM"]
\ No newline at end of file
diff --git a/src/data.py b/src/opentslm/data.py
similarity index 96%
rename from src/data.py
rename to src/opentslm/data.py
index 20459947..15338b0f 100644
--- a/src/data.py
+++ b/src/opentslm/data.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -10,7 +9,7 @@
import torch
from datasets import load_dataset
from torch.utils.data import DataLoader
-from src.model_config import *
+from opentslm.model_config import *
# ---------------------------
# Constants
diff --git a/src/logger.py b/src/opentslm/logger.py
similarity index 97%
rename from src/logger.py
rename to src/opentslm/logger.py
index 669165f2..8d720b86 100644
--- a/src/logger.py
+++ b/src/opentslm/logger.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/src/model/encoder/__init__.py b/src/opentslm/model/__init__.py
similarity index 60%
rename from src/model/encoder/__init__.py
rename to src/opentslm/model/__init__.py
index 266b1365..cbad1615 100644
--- a/src/model/encoder/__init__.py
+++ b/src/opentslm/model/__init__.py
@@ -1,5 +1,4 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/src/model/encoder/CNNTokenizer.py b/src/opentslm/model/encoder/CNNTokenizer.py
similarity index 91%
rename from src/model/encoder/CNNTokenizer.py
rename to src/opentslm/model/encoder/CNNTokenizer.py
index c622c0ab..be945cb0 100644
--- a/src/model/encoder/CNNTokenizer.py
+++ b/src/opentslm/model/encoder/CNNTokenizer.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -8,8 +7,8 @@
import torch.nn as nn
-from model_config import TRANSFORMER_INPUT_DIM, ENCODER_OUTPUT_DIM, PATCH_SIZE
-from model.encoder.TimeSeriesEncoderBase import TimeSeriesEncoderBase
+from opentslm.model_config import TRANSFORMER_INPUT_DIM, ENCODER_OUTPUT_DIM, PATCH_SIZE
+from opentslm.model.encoder.TimeSeriesEncoderBase import TimeSeriesEncoderBase
class CNNTokenizer(TimeSeriesEncoderBase):
diff --git a/src/model/encoder/TimeSeriesEncoderBase.py b/src/opentslm/model/encoder/TimeSeriesEncoderBase.py
similarity index 79%
rename from src/model/encoder/TimeSeriesEncoderBase.py
rename to src/opentslm/model/encoder/TimeSeriesEncoderBase.py
index e49a4c7c..99204152 100644
--- a/src/model/encoder/TimeSeriesEncoderBase.py
+++ b/src/opentslm/model/encoder/TimeSeriesEncoderBase.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -8,7 +7,7 @@
import torch
import torch.nn as nn
-from model_config import ENCODER_OUTPUT_DIM
+from opentslm.model_config import ENCODER_OUTPUT_DIM
class TimeSeriesEncoderBase(nn.Module):
diff --git a/src/model/encoder/TransformerCNNEncoder.py b/src/opentslm/model/encoder/TransformerCNNEncoder.py
similarity index 92%
rename from src/model/encoder/TransformerCNNEncoder.py
rename to src/opentslm/model/encoder/TransformerCNNEncoder.py
index f22306ce..6cd01b04 100644
--- a/src/model/encoder/TransformerCNNEncoder.py
+++ b/src/opentslm/model/encoder/TransformerCNNEncoder.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -8,8 +7,8 @@
import torch.nn as nn
-from model_config import TRANSFORMER_INPUT_DIM, ENCODER_OUTPUT_DIM, PATCH_SIZE
-from model.encoder.TimeSeriesEncoderBase import TimeSeriesEncoderBase
+from opentslm.model_config import TRANSFORMER_INPUT_DIM, ENCODER_OUTPUT_DIM, PATCH_SIZE
+from opentslm.model.encoder.TimeSeriesEncoderBase import TimeSeriesEncoderBase
class TransformerCNNEncoder(TimeSeriesEncoderBase):
diff --git a/src/model/encoder/TransformerMLPEncoder.py b/src/opentslm/model/encoder/TransformerMLPEncoder.py
similarity index 92%
rename from src/model/encoder/TransformerMLPEncoder.py
rename to src/opentslm/model/encoder/TransformerMLPEncoder.py
index bccc57f0..89403ea3 100644
--- a/src/model/encoder/TransformerMLPEncoder.py
+++ b/src/opentslm/model/encoder/TransformerMLPEncoder.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -8,8 +7,8 @@
import torch.nn as nn
-from src.model_config import TRANSFORMER_INPUT_DIM, ENCODER_OUTPUT_DIM, PATCH_SIZE
-from model.encoder.TimeSeriesEncoderBase import TimeSeriesEncoderBase
+from opentslm.model_config import TRANSFORMER_INPUT_DIM, ENCODER_OUTPUT_DIM, PATCH_SIZE
+from opentslm.model.encoder.TimeSeriesEncoderBase import TimeSeriesEncoderBase
class TransformerMLPEncoder(TimeSeriesEncoderBase):
diff --git a/__init__.py b/src/opentslm/model/encoder/__init__.py
similarity index 60%
rename from __init__.py
rename to src/opentslm/model/encoder/__init__.py
index 266b1365..cbad1615 100644
--- a/__init__.py
+++ b/src/opentslm/model/encoder/__init__.py
@@ -1,5 +1,4 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/src/model/llm/OpenTSLM.py b/src/opentslm/model/llm/OpenTSLM.py
similarity index 97%
rename from src/model/llm/OpenTSLM.py
rename to src/opentslm/model/llm/OpenTSLM.py
index 19806258..b7e56a20 100644
--- a/src/model/llm/OpenTSLM.py
+++ b/src/opentslm/model/llm/OpenTSLM.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
import torch
@@ -39,7 +38,7 @@ class OpenTSLM:
Example:
>>> model = OpenTSLM.load_pretrained("OpenTSLM/gemma-3-270m-pt-sleep-flamingo")
>>>
- >>> from prompt.full_prompt import FullPrompt
+ >>> from opentslm.prompt.full_prompt import FullPrompt
>>> prompt = FullPrompt(...)
>>> response = model.eval_prompt(prompt)
"""
diff --git a/src/model/llm/OpenTSLMFlamingo.py b/src/opentslm/model/llm/OpenTSLMFlamingo.py
similarity index 95%
rename from src/model/llm/OpenTSLMFlamingo.py
rename to src/opentslm/model/llm/OpenTSLMFlamingo.py
index 39e5101a..b0f5676b 100644
--- a/src/model/llm/OpenTSLMFlamingo.py
+++ b/src/opentslm/model/llm/OpenTSLMFlamingo.py
@@ -1,30 +1,29 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
from types import SimpleNamespace
-from model.encoder.CNNTokenizer import CNNTokenizer
-from model.llm.TimeSeriesFlamingoWithTrainableEncoder import (
+from opentslm.model.encoder.CNNTokenizer import CNNTokenizer
+from opentslm.model.llm.TimeSeriesFlamingoWithTrainableEncoder import (
TimeSeriesFlamingoWithTrainableEncoder,
)
-from open_flamingo.open_flamingo.src.flamingo_lm import FlamingoLMMixin
-from open_flamingo.open_flamingo.src.utils import extend_instance
+from open_flamingo.src.flamingo_lm import FlamingoLMMixin
+from open_flamingo.src.utils import extend_instance
import torch
import torch._dynamo
from typing import List, Dict, Tuple
from transformers import AutoTokenizer, AutoModelForCausalLM
-from model_config import ENCODER_OUTPUT_DIM
-from model.llm.TimeSeriesLLM import TimeSeriesLLM
-from prompt.full_prompt import FullPrompt
-from time_series_datasets.util import (
+from opentslm.model_config import ENCODER_OUTPUT_DIM
+from opentslm.model.llm.TimeSeriesLLM import TimeSeriesLLM
+from opentslm.prompt.full_prompt import FullPrompt
+from opentslm.time_series_datasets.util import (
extend_time_series_to_match_patch_size_and_aggregate,
)
# Monkey-patch FlamingoLayer to add attention_type property for compatibility with newer transformers
-from open_flamingo.open_flamingo.src.flamingo_lm import FlamingoLayer
+from open_flamingo.src.flamingo_lm import FlamingoLayer
def _attention_type_property(self):
@@ -33,7 +32,7 @@ def _attention_type_property(self):
# Add the attention_type property to FlamingoLayer
-FlamingoLayer.attention_type = property(_attention_type_property)
+FlamingoLayer.attention_type = property(_attention_type_property) # type: ignore
class OpenTSLMFlamingo(TimeSeriesLLM):
diff --git a/src/model/llm/OpenTSLMSP.py b/src/opentslm/model/llm/OpenTSLMSP.py
similarity index 98%
rename from src/model/llm/OpenTSLMSP.py
rename to src/opentslm/model/llm/OpenTSLMSP.py
index 59c290e5..4e7735d8 100644
--- a/src/model/llm/OpenTSLMSP.py
+++ b/src/opentslm/model/llm/OpenTSLMSP.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -18,12 +17,12 @@
PEFT_AVAILABLE = False
print("Warning: peft not available. LoRA fine-tuning will be disabled.")
-from model_config import ENCODER_OUTPUT_DIM
+from opentslm.model_config import ENCODER_OUTPUT_DIM
from .TimeSeriesLLM import TimeSeriesLLM
from ..encoder.TransformerCNNEncoder import TransformerCNNEncoder
from ..projector.MLPProjector import MLPProjector
-from prompt.full_prompt import FullPrompt
-from time_series_datasets.util import (
+from opentslm.prompt.full_prompt import FullPrompt
+from opentslm.time_series_datasets.util import (
extend_time_series_to_match_patch_size_and_aggregate,
)
diff --git a/src/model/llm/TimeSeriesFlamingoWithTrainableEncoder.py b/src/opentslm/model/llm/TimeSeriesFlamingoWithTrainableEncoder.py
similarity index 95%
rename from src/model/llm/TimeSeriesFlamingoWithTrainableEncoder.py
rename to src/opentslm/model/llm/TimeSeriesFlamingoWithTrainableEncoder.py
index 5ca67ebd..97a7b52e 100644
--- a/src/model/llm/TimeSeriesFlamingoWithTrainableEncoder.py
+++ b/src/opentslm/model/llm/TimeSeriesFlamingoWithTrainableEncoder.py
@@ -1,12 +1,11 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
import torch
from torch import nn
-from open_flamingo.open_flamingo.src.flamingo import Flamingo
+from open_flamingo import Flamingo
from einops import rearrange
diff --git a/src/model/llm/TimeSeriesLLM.py b/src/opentslm/model/llm/TimeSeriesLLM.py
similarity index 69%
rename from src/model/llm/TimeSeriesLLM.py
rename to src/opentslm/model/llm/TimeSeriesLLM.py
index 55af6d2b..b3a568d5 100644
--- a/src/model/llm/TimeSeriesLLM.py
+++ b/src/opentslm/model/llm/TimeSeriesLLM.py
@@ -1,17 +1,14 @@
-# This source file is part of the OpenTSLM open-source project
-#
+from typing import List, Dict, Any
+
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
import torch
import torch.nn as nn
-from typing import List, Dict, Tuple
-from transformers import AutoTokenizer, AutoModelForCausalLM
-from torch.nn.utils.rnn import pad_sequence
-from model_config import ENCODER_OUTPUT_DIM
-from prompt.full_prompt import FullPrompt
+from opentslm.prompt.full_prompt import FullPrompt
class TimeSeriesLLM(nn.Module):
def __init__(
@@ -23,12 +20,12 @@ def __init__(
def generate(
- self, batch: List[Dict[str, any]], max_new_tokens: int = 50, **generate_kwargs
+ self, batch: List[Dict[str, Any]], max_new_tokens: int = 50, **generate_kwargs
) -> List[str]:
raise NotImplementedError("Generate method should be implemented by the subclass")
- def compute_loss(self, batch: List[Dict[str, any]]) -> torch.Tensor:
+ def compute_loss(self, batch: List[Dict[str, Any]]) -> torch.Tensor:
"""
batch: same format as generate()
answers: List[str] of length B
diff --git a/src/model/llm/__init__.py b/src/opentslm/model/llm/__init__.py
similarity index 60%
rename from src/model/llm/__init__.py
rename to src/opentslm/model/llm/__init__.py
index 266b1365..cbad1615 100644
--- a/src/model/llm/__init__.py
+++ b/src/opentslm/model/llm/__init__.py
@@ -1,5 +1,4 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/src/model/projector/LinearProjector.py b/src/opentslm/model/projector/LinearProjector.py
similarity index 81%
rename from src/model/projector/LinearProjector.py
rename to src/opentslm/model/projector/LinearProjector.py
index 0e9c9e24..0dfab497 100644
--- a/src/model/projector/LinearProjector.py
+++ b/src/opentslm/model/projector/LinearProjector.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/src/model/projector/MLPProjector.py b/src/opentslm/model/projector/MLPProjector.py
similarity index 85%
rename from src/model/projector/MLPProjector.py
rename to src/opentslm/model/projector/MLPProjector.py
index af07ca90..e8c9a3a1 100644
--- a/src/model/projector/MLPProjector.py
+++ b/src/opentslm/model/projector/MLPProjector.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/src/opentslm/model/projector/__init__.py b/src/opentslm/model/projector/__init__.py
new file mode 100644
index 00000000..cbad1615
--- /dev/null
+++ b/src/opentslm/model/projector/__init__.py
@@ -0,0 +1,4 @@
+# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
+#
+# SPDX-License-Identifier: MIT
diff --git a/src/model_config.py b/src/opentslm/model_config.py
similarity index 87%
rename from src/model_config.py
rename to src/opentslm/model_config.py
index 0412f6b9..90228563 100644
--- a/src/model_config.py
+++ b/src/opentslm/model_config.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/src/opentslm/prompt/__init__.py b/src/opentslm/prompt/__init__.py
new file mode 100644
index 00000000..826feaad
--- /dev/null
+++ b/src/opentslm/prompt/__init__.py
@@ -0,0 +1,18 @@
+# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
+#
+# SPDX-License-Identifier: MIT
+
+from .prompt import Prompt
+from .full_prompt import FullPrompt
+from .text_prompt import TextPrompt
+from .text_time_series_prompt import TextTimeSeriesPrompt
+from .prompt_with_answer import PromptWithAnswer
+
+__all__ = [
+ "Prompt",
+ "FullPrompt",
+ "TextPrompt",
+ "TextTimeSeriesPrompt",
+ "PromptWithAnswer",
+]
diff --git a/src/prompt/full_prompt.py b/src/opentslm/prompt/full_prompt.py
similarity index 85%
rename from src/prompt/full_prompt.py
rename to src/opentslm/prompt/full_prompt.py
index 501d61f5..64ff6222 100644
--- a/src/prompt/full_prompt.py
+++ b/src/opentslm/prompt/full_prompt.py
@@ -1,12 +1,11 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
from typing import List
-from prompt.text_prompt import TextPrompt
-from prompt.text_time_series_prompt import TextTimeSeriesPrompt
+from opentslm.prompt.text_prompt import TextPrompt
+from opentslm.prompt.text_time_series_prompt import TextTimeSeriesPrompt
class FullPrompt:
diff --git a/src/prompt/prompt.py b/src/opentslm/prompt/prompt.py
similarity index 73%
rename from src/prompt/prompt.py
rename to src/opentslm/prompt/prompt.py
index 69b4fdd6..c57b6e64 100644
--- a/src/prompt/prompt.py
+++ b/src/opentslm/prompt/prompt.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/src/prompt/prompt_with_answer.py b/src/opentslm/prompt/prompt_with_answer.py
similarity index 87%
rename from src/prompt/prompt_with_answer.py
rename to src/opentslm/prompt/prompt_with_answer.py
index 9df2d024..1f6ba78d 100644
--- a/src/prompt/prompt_with_answer.py
+++ b/src/opentslm/prompt/prompt_with_answer.py
@@ -1,12 +1,11 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
from typing import List
-from prompt.text_prompt import TextPrompt
-from prompt.text_time_series_prompt import TextTimeSeriesPrompt
+from opentslm.prompt.text_prompt import TextPrompt
+from opentslm.prompt.text_time_series_prompt import TextTimeSeriesPrompt
class PromptWithAnswer:
diff --git a/src/prompt/text_prompt.py b/src/opentslm/prompt/text_prompt.py
similarity index 80%
rename from src/prompt/text_prompt.py
rename to src/opentslm/prompt/text_prompt.py
index 11c19450..5e0ae72d 100644
--- a/src/prompt/text_prompt.py
+++ b/src/opentslm/prompt/text_prompt.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/src/prompt/text_time_series_prompt.py b/src/opentslm/prompt/text_time_series_prompt.py
similarity index 93%
rename from src/prompt/text_time_series_prompt.py
rename to src/opentslm/prompt/text_time_series_prompt.py
index d38da3c9..bdcbadd8 100644
--- a/src/prompt/text_time_series_prompt.py
+++ b/src/opentslm/prompt/text_time_series_prompt.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/QADataset.py b/src/opentslm/time_series_datasets/QADataset.py
similarity index 94%
rename from src/time_series_datasets/QADataset.py
rename to src/opentslm/time_series_datasets/QADataset.py
index 8375b9c7..7e78fb02 100644
--- a/src/time_series_datasets/QADataset.py
+++ b/src/opentslm/time_series_datasets/QADataset.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -9,10 +8,9 @@
from typing import Callable, List, Literal, Tuple
import numpy as np
-import sys
-from prompt.prompt_with_answer import PromptWithAnswer
-from prompt.text_prompt import TextPrompt
-from prompt.text_time_series_prompt import TextTimeSeriesPrompt
+from opentslm.prompt.prompt_with_answer import PromptWithAnswer
+from opentslm.prompt.text_prompt import TextPrompt
+from opentslm.prompt.text_time_series_prompt import TextTimeSeriesPrompt
from torch.utils.data import Dataset
diff --git a/src/time_series_datasets/TSQADataset.py b/src/opentslm/time_series_datasets/TSQADataset.py
similarity index 92%
rename from src/time_series_datasets/TSQADataset.py
rename to src/opentslm/time_series_datasets/TSQADataset.py
index 9f1a4f3d..3b79e6d0 100644
--- a/src/time_series_datasets/TSQADataset.py
+++ b/src/opentslm/time_series_datasets/TSQADataset.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -9,9 +8,9 @@
from datasets import Dataset, load_dataset
-from prompt.text_time_series_prompt import TextTimeSeriesPrompt
-from time_series_datasets.QADataset import QADataset
-from time_series_datasets.util import (
+from opentslm.prompt.text_time_series_prompt import TextTimeSeriesPrompt
+from opentslm.time_series_datasets.QADataset import QADataset
+from opentslm.time_series_datasets.util import (
extend_time_series_to_match_patch_size_and_aggregate,
)
from torch.utils.data import DataLoader
diff --git a/src/opentslm/time_series_datasets/__init__.py b/src/opentslm/time_series_datasets/__init__.py
new file mode 100644
index 00000000..cbad1615
--- /dev/null
+++ b/src/opentslm/time_series_datasets/__init__.py
@@ -0,0 +1,4 @@
+# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
+#
+# SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/constants.py b/src/opentslm/time_series_datasets/constants.py
similarity index 78%
rename from src/time_series_datasets/constants.py
rename to src/opentslm/time_series_datasets/constants.py
index 97256616..0d160e1d 100644
--- a/src/time_series_datasets/constants.py
+++ b/src/opentslm/time_series_datasets/constants.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/ecg_qa/ECGQACoTQADataset.py b/src/opentslm/time_series_datasets/ecg_qa/ECGQACoTQADataset.py
similarity index 97%
rename from src/time_series_datasets/ecg_qa/ECGQACoTQADataset.py
rename to src/opentslm/time_series_datasets/ecg_qa/ECGQACoTQADataset.py
index 1f15da9f..2f779528 100644
--- a/src/time_series_datasets/ecg_qa/ECGQACoTQADataset.py
+++ b/src/opentslm/time_series_datasets/ecg_qa/ECGQACoTQADataset.py
@@ -1,17 +1,14 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
from datasets import Dataset
from typing import List, Tuple, Literal
-import sys
import os
-sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
-from prompt.text_time_series_prompt import TextTimeSeriesPrompt
-from time_series_datasets.QADataset import QADataset
-from time_series_datasets.ecg_qa.ecgqa_cot_loader import load_ecg_qa_cot_splits
+from opentslm.prompt.text_time_series_prompt import TextTimeSeriesPrompt
+from opentslm.time_series_datasets.QADataset import QADataset
+from opentslm.time_series_datasets.ecg_qa.ecgqa_cot_loader import load_ecg_qa_cot_splits
import numpy as np
class ECGQACoTQADataset(QADataset):
@@ -171,7 +168,7 @@ def _load_template_answers_cache(cls):
try:
import pandas as pd
import ast
- from time_series_datasets.ecg_qa.ecgqa_loader import ECG_QA_DIR
+ from opentslm.time_series_datasets.ecg_qa.ecgqa_loader import ECG_QA_DIR
# Load template answers directly
template_answers_path = os.path.join(ECG_QA_DIR, "ecgqa", "ptbxl", "answers_for_each_template.csv")
@@ -209,7 +206,7 @@ def get_labels() -> List[str]:
try:
import pandas as pd
import ast
- from time_series_datasets.ecg_qa.ecgqa_loader import ECG_QA_DIR
+ from opentslm.time_series_datasets.ecg_qa.ecgqa_loader import ECG_QA_DIR
template_answers_path = os.path.join(ECG_QA_DIR, "ecgqa", "ptbxl", "answers_for_each_template.csv")
df = pd.read_csv(template_answers_path)
@@ -299,7 +296,7 @@ def preload_ecg_data(cls, dataset_splits: List[Dataset]):
# Fallback: construct path from ecg_id
ecg_id = sample.get("ecg_id")
if ecg_id and isinstance(ecg_id, list) and len(ecg_id) > 0:
- from time_series_datasets.ecg_qa.ecgqa_loader import get_ptbxl_ecg_path
+ from opentslm.time_series_datasets.ecg_qa.ecgqa_loader import get_ptbxl_ecg_path
ecg_path = get_ptbxl_ecg_path(ecg_id[0]) + ".dat"
ecg_paths.add(ecg_path)
@@ -336,7 +333,7 @@ def preload_processed_ecg_data(cls, dataset_splits: List[Dataset]):
# Fallback: construct path from ecg_id
ecg_id = sample.get("ecg_id")
if ecg_id and isinstance(ecg_id, list) and len(ecg_id) > 0:
- from time_series_datasets.ecg_qa.ecgqa_loader import get_ptbxl_ecg_path
+ from opentslm.time_series_datasets.ecg_qa.ecgqa_loader import get_ptbxl_ecg_path
ecg_path = get_ptbxl_ecg_path(ecg_id[0]) + ".dat"
ecg_signal, _, _ = cls._load_ecg_data(ecg_path)
n_leads = ecg_signal.shape[1] if len(ecg_signal.shape) > 1 else 1
@@ -439,7 +436,7 @@ def _get_text_time_series_prompt_list(self, row) -> List[TextTimeSeriesPrompt]:
if not isinstance(ecg_id, list) or len(ecg_id) == 0:
raise ValueError(f"Sample 'ecg_id' must be a non-empty list: {ecg_id}")
- from time_series_datasets.ecg_qa.ecgqa_loader import get_ptbxl_ecg_path
+ from opentslm.time_series_datasets.ecg_qa.ecgqa_loader import get_ptbxl_ecg_path
ecg_path = get_ptbxl_ecg_path(ecg_id[0]) + ".dat"
ecg_paths = [ecg_path]
diff --git a/src/time_series_datasets/ecg_qa/ECGQADataset.py b/src/opentslm/time_series_datasets/ecg_qa/ECGQADataset.py
similarity index 97%
rename from src/time_series_datasets/ecg_qa/ECGQADataset.py
rename to src/opentslm/time_series_datasets/ecg_qa/ECGQADataset.py
index fc3c17b6..3a93319e 100644
--- a/src/time_series_datasets/ecg_qa/ECGQADataset.py
+++ b/src/opentslm/time_series_datasets/ecg_qa/ECGQADataset.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -18,9 +17,9 @@
"Please install it with: pip install wfdb"
)
-from prompt.text_time_series_prompt import TextTimeSeriesPrompt
-from time_series_datasets.QADataset import QADataset
-from time_series_datasets.ecg_qa.ecgqa_loader import (
+from opentslm.prompt.text_time_series_prompt import TextTimeSeriesPrompt
+from opentslm.time_series_datasets.QADataset import QADataset
+from opentslm.time_series_datasets.ecg_qa.ecgqa_loader import (
load_ecg_qa_ptbxl_splits,
load_ecg_qa_answers,
)
@@ -197,7 +196,7 @@ def get_possible_answers_for_template(self, template_id: int) -> List[str]:
try:
import pandas as pd
import ast
- from time_series_datasets.ecg_qa.ecgqa_loader import ECG_QA_DIR
+ from opentslm.time_series_datasets.ecg_qa.ecgqa_loader import ECG_QA_DIR
# Load template answers directly
template_answers_path = os.path.join(
@@ -231,7 +230,7 @@ def _get_text_time_series_prompt_list(self, row) -> List[TextTimeSeriesPrompt]:
# Fallback: single ECG path
ecg_id = row["ecg_id"][0] if row["ecg_id"] else None
if ecg_id:
- from time_series_datasets.ecg_qa.ecgqa_loader import get_ptbxl_ecg_path
+ from opentslm.time_series_datasets.ecg_qa.ecgqa_loader import get_ptbxl_ecg_path
ecg_path = get_ptbxl_ecg_path(ecg_id) + ".dat"
ecg_paths = [ecg_path]
diff --git a/src/time_series_datasets/ecg_qa/README.md b/src/opentslm/time_series_datasets/ecg_qa/README.md
similarity index 98%
rename from src/time_series_datasets/ecg_qa/README.md
rename to src/opentslm/time_series_datasets/ecg_qa/README.md
index 50a97ebf..7d9f7b43 100644
--- a/src/time_series_datasets/ecg_qa/README.md
+++ b/src/opentslm/time_series_datasets/ecg_qa/README.md
@@ -1,7 +1,6 @@
@@ -99,7 +98,7 @@ yes
## Quick Start
```python
-from time_series_datasets.ecg_qa.ECGQADataset import ECGQADataset
+from opentslm.time_series_datasets.ecg_qa.ECGQADataset import ECGQADataset
# Load ECG-QA splits (auto-downloads ~6GB of data on first run)
train_dataset = ECGQADataset(split="train", EOS_TOKEN="")
diff --git a/src/time_series_datasets/ecg_qa/__init__.py b/src/opentslm/time_series_datasets/ecg_qa/__init__.py
similarity index 89%
rename from src/time_series_datasets/ecg_qa/__init__.py
rename to src/opentslm/time_series_datasets/ecg_qa/__init__.py
index 4ba0c41a..277c1074 100644
--- a/src/time_series_datasets/ecg_qa/__init__.py
+++ b/src/opentslm/time_series_datasets/ecg_qa/__init__.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -15,7 +14,7 @@
https://github.com/Jwoo5/ecg-qa
Usage:
- from time_series_datasets.ecg_qa.ECGQADataset import ECGQADataset
+ from opentslm.time_series_datasets.ecg_qa.ECGQADataset import ECGQADataset
# Create dataset instance
dataset = ECGQADataset(split="train", EOS_TOKEN="")
diff --git a/src/time_series_datasets/ecg_qa/dataset_distribution.png b/src/opentslm/time_series_datasets/ecg_qa/dataset_distribution.png
similarity index 100%
rename from src/time_series_datasets/ecg_qa/dataset_distribution.png
rename to src/opentslm/time_series_datasets/ecg_qa/dataset_distribution.png
diff --git a/src/time_series_datasets/ecg_qa/ecg_example_real.png b/src/opentslm/time_series_datasets/ecg_qa/ecg_example_real.png
similarity index 100%
rename from src/time_series_datasets/ecg_qa/ecg_example_real.png
rename to src/opentslm/time_series_datasets/ecg_qa/ecg_example_real.png
diff --git a/src/time_series_datasets/ecg_qa/ecgqa_cot_loader.py b/src/opentslm/time_series_datasets/ecg_qa/ecgqa_cot_loader.py
similarity index 95%
rename from src/time_series_datasets/ecg_qa/ecgqa_cot_loader.py
rename to src/opentslm/time_series_datasets/ecg_qa/ecgqa_cot_loader.py
index b419d42d..b2cc38a0 100644
--- a/src/time_series_datasets/ecg_qa/ecgqa_cot_loader.py
+++ b/src/opentslm/time_series_datasets/ecg_qa/ecgqa_cot_loader.py
@@ -1,27 +1,18 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
-import os
import subprocess
-import json
import requests
import shutil
-import pandas as pd
-from pathlib import Path
from typing import Tuple, Dict, List
from datasets import Dataset
-import sys
import os
import zipfile
-import tempfile
-sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
-from time_series_datasets.constants import RAW_DATA as RAW_DATA_PATH
-from time_series_datasets.ecg_qa.ecgqa_loader import (
- load_ecg_qa_ptbxl_splits,
+from opentslm.time_series_datasets.constants import RAW_DATA as RAW_DATA_PATH
+from opentslm.time_series_datasets.ecg_qa.ecgqa_loader import (
download_ecg_qa_if_not_exists,
download_ptbxl_if_not_exists
)
@@ -150,7 +141,7 @@ def load_ecg_qa_cot_splits() -> Tuple[Dataset, Dataset, Dataset]:
download_ecg_qa_cot_if_not_exists()
import pandas as pd
- from time_series_datasets.ecg_qa.ecgqa_loader import get_ptbxl_ecg_path
+ from opentslm.time_series_datasets.ecg_qa.ecgqa_loader import get_ptbxl_ecg_path
def parse_ecg_id(ecg_id_raw: str) -> int:
if ecg_id_raw is None:
@@ -175,7 +166,7 @@ def load_split_from_csv(split_name: str) -> List[Dict]:
raise FileNotFoundError(f"CoT split file not found: {split_file}")
print(f"Loading CoT data for {split_name} split from {split_file}...")
- print(f"Reading CSV file...")
+ print("Reading CSV file...")
df = pd.read_csv(split_file)
print(f"CSV loaded: {len(df)} rows, {len(df.columns)} columns")
@@ -277,13 +268,13 @@ def get_label_distribution(dataset: Dataset) -> Dict[str, int]:
try:
train, val, test = load_ecg_qa_cot_splits()
- print(f"Loaded ECG-QA CoT dataset:")
+ print("Loaded ECG-QA CoT dataset:")
print(f" Train: {len(train)} samples")
print(f" Validation: {len(val)} samples")
print(f" Test: {len(test)} samples")
if len(train) > 0:
- print(f"\nSample from training set:")
+ print("\nSample from training set:")
sample = train[0]
for key, value in sample.items():
if isinstance(value, list) and len(value) > 3:
diff --git a/src/time_series_datasets/ecg_qa/ecgqa_loader.py b/src/opentslm/time_series_datasets/ecg_qa/ecgqa_loader.py
similarity index 98%
rename from src/time_series_datasets/ecg_qa/ecgqa_loader.py
rename to src/opentslm/time_series_datasets/ecg_qa/ecgqa_loader.py
index 5f112c98..36053da4 100644
--- a/src/time_series_datasets/ecg_qa/ecgqa_loader.py
+++ b/src/opentslm/time_series_datasets/ecg_qa/ecgqa_loader.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -14,11 +13,9 @@
from pathlib import Path
from typing import Tuple, Dict, List
from datasets import Dataset
-import sys
import os
-sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) )
-from time_series_datasets.constants import RAW_DATA as RAW_DATA_PATH
+from opentslm.time_series_datasets.constants import RAW_DATA as RAW_DATA_PATH
from tqdm import tqdm
diff --git a/src/time_series_datasets/ecg_qa/example_prompt.md b/src/opentslm/time_series_datasets/ecg_qa/example_prompt.md
similarity index 88%
rename from src/time_series_datasets/ecg_qa/example_prompt.md
rename to src/opentslm/time_series_datasets/ecg_qa/example_prompt.md
index 0fd3bd56..593ecb9a 100644
--- a/src/time_series_datasets/ecg_qa/example_prompt.md
+++ b/src/opentslm/time_series_datasets/ecg_qa/example_prompt.md
@@ -1,7 +1,6 @@
diff --git a/src/time_series_datasets/ecg_qa/plot_example.py b/src/opentslm/time_series_datasets/ecg_qa/plot_example.py
similarity index 96%
rename from src/time_series_datasets/ecg_qa/plot_example.py
rename to src/opentslm/time_series_datasets/ecg_qa/plot_example.py
index d04cfdc3..06898d91 100644
--- a/src/time_series_datasets/ecg_qa/plot_example.py
+++ b/src/opentslm/time_series_datasets/ecg_qa/plot_example.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -12,16 +11,12 @@
"""
import os
-import sys
import json
import matplotlib.pyplot as plt
import numpy as np
import wfdb
-# Add the src directory to path for imports
-sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
-
-from time_series_datasets.ecg_qa.ECGQADataset import ECGQADataset
+from opentslm.time_series_datasets.ecg_qa.ECGQADataset import ECGQADataset
# ECG plotting configuration
lead_names = ["I", "II", "III", "aVR", "aVL", "aVF", "V1", "V2", "V3", "V4", "V5", "V6"]
diff --git a/src/time_series_datasets/har_cot/HARAccQADataset.py b/src/opentslm/time_series_datasets/har_cot/HARAccQADataset.py
similarity index 91%
rename from src/time_series_datasets/har_cot/HARAccQADataset.py
rename to src/opentslm/time_series_datasets/har_cot/HARAccQADataset.py
index 7d0a71e7..d5db27e4 100644
--- a/src/time_series_datasets/har_cot/HARAccQADataset.py
+++ b/src/opentslm/time_series_datasets/har_cot/HARAccQADataset.py
@@ -1,19 +1,18 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
from datasets import Dataset
from typing import List, Tuple, Literal
-from prompt.text_time_series_prompt import TextTimeSeriesPrompt
-from time_series_datasets.QADataset import QADataset
-from time_series_datasets.har_cot.har_cot_loader import load_har_cot_splits
+from opentslm.prompt.text_time_series_prompt import TextTimeSeriesPrompt
+from opentslm.time_series_datasets.QADataset import QADataset
+from opentslm.time_series_datasets.har_cot.har_cot_loader import load_har_cot_splits
import torch
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
-from time_series_datasets.util import (
+from opentslm.time_series_datasets.util import (
extend_time_series_to_match_patch_size_and_aggregate,
)
diff --git a/src/time_series_datasets/har_cot/HARCoTQADataset.py b/src/opentslm/time_series_datasets/har_cot/HARCoTQADataset.py
similarity index 94%
rename from src/time_series_datasets/har_cot/HARCoTQADataset.py
rename to src/opentslm/time_series_datasets/har_cot/HARCoTQADataset.py
index 914018c8..da55653e 100644
--- a/src/time_series_datasets/har_cot/HARCoTQADataset.py
+++ b/src/opentslm/time_series_datasets/har_cot/HARCoTQADataset.py
@@ -1,21 +1,18 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
from datasets import Dataset
from typing import List, Tuple, Literal
-import sys
import os
-sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
-from prompt.text_time_series_prompt import TextTimeSeriesPrompt
-from time_series_datasets.QADataset import QADataset
-from time_series_datasets.har_cot.har_cot_loader import load_har_cot_splits
+from opentslm.prompt.text_time_series_prompt import TextTimeSeriesPrompt
+from opentslm.time_series_datasets.QADataset import QADataset
+from opentslm.time_series_datasets.har_cot.har_cot_loader import load_har_cot_splits
import torch
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
-from time_series_datasets.util import (
+from opentslm.time_series_datasets.util import (
extend_time_series_to_match_patch_size_and_aggregate,
)
import numpy as np
diff --git a/src/opentslm/time_series_datasets/har_cot/__init__.py b/src/opentslm/time_series_datasets/har_cot/__init__.py
new file mode 100644
index 00000000..cbad1615
--- /dev/null
+++ b/src/opentslm/time_series_datasets/har_cot/__init__.py
@@ -0,0 +1,4 @@
+# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
+#
+# SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/har_cot/har_cot_loader.py b/src/opentslm/time_series_datasets/har_cot/har_cot_loader.py
similarity index 96%
rename from src/time_series_datasets/har_cot/har_cot_loader.py
rename to src/opentslm/time_series_datasets/har_cot/har_cot_loader.py
index 4b0721ef..9d756359 100644
--- a/src/time_series_datasets/har_cot/har_cot_loader.py
+++ b/src/opentslm/time_series_datasets/har_cot/har_cot_loader.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -11,12 +10,10 @@
import ast
import urllib.request
import zipfile
-import sys
-sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
-from time_series_datasets.constants import RAW_DATA
+from opentslm.time_series_datasets.constants import RAW_DATA
from tqdm.auto import tqdm
import logging
-from logger import get_logger
+from opentslm.logger import get_logger
HAR_COT_DATA_DIR = os.path.join(RAW_DATA, "har_cot")
HAR_COT_ZIP = os.path.join(HAR_COT_DATA_DIR, "har_cot.zip")
diff --git a/src/time_series_datasets/m4/M4QADataset.py b/src/opentslm/time_series_datasets/m4/M4QADataset.py
similarity index 93%
rename from src/time_series_datasets/m4/M4QADataset.py
rename to src/opentslm/time_series_datasets/m4/M4QADataset.py
index 1613c656..5b567916 100644
--- a/src/time_series_datasets/m4/M4QADataset.py
+++ b/src/opentslm/time_series_datasets/m4/M4QADataset.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -17,9 +16,9 @@
import torch
from datasets import Dataset
-from prompt.text_time_series_prompt import TextTimeSeriesPrompt
-from time_series_datasets.QADataset import QADataset
-from time_series_datasets.m4.m4_loader import load_all_m4_data, create_combined_dataset
+from opentslm.prompt.text_time_series_prompt import TextTimeSeriesPrompt
+from opentslm.time_series_datasets.QADataset import QADataset
+from opentslm.time_series_datasets.m4.m4_loader import load_all_m4_data, create_combined_dataset
class M4QADataset(QADataset):
diff --git a/src/time_series_datasets/m4/__init__.py b/src/opentslm/time_series_datasets/m4/__init__.py
similarity index 79%
rename from src/time_series_datasets/m4/__init__.py
rename to src/opentslm/time_series_datasets/m4/__init__.py
index 5fadb4e6..2388535d 100644
--- a/src/time_series_datasets/m4/__init__.py
+++ b/src/opentslm/time_series_datasets/m4/__init__.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/m4/m4_loader.py b/src/opentslm/time_series_datasets/m4/m4_loader.py
similarity index 98%
rename from src/time_series_datasets/m4/m4_loader.py
rename to src/opentslm/time_series_datasets/m4/m4_loader.py
index df144274..1f03720b 100644
--- a/src/time_series_datasets/m4/m4_loader.py
+++ b/src/opentslm/time_series_datasets/m4/m4_loader.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -26,7 +25,7 @@
from typing import Dict, List, Literal, Optional, Tuple
from datasets import Dataset
from sklearn.model_selection import train_test_split
-from time_series_datasets.constants import RAW_DATA
+from opentslm.time_series_datasets.constants import RAW_DATA
# ---------------------------
# Constants
diff --git a/src/time_series_datasets/monash/MonashDataset.py b/src/opentslm/time_series_datasets/monash/MonashDataset.py
similarity index 93%
rename from src/time_series_datasets/monash/MonashDataset.py
rename to src/opentslm/time_series_datasets/monash/MonashDataset.py
index 7d10e37f..6d0e1eff 100644
--- a/src/time_series_datasets/monash/MonashDataset.py
+++ b/src/opentslm/time_series_datasets/monash/MonashDataset.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -12,7 +11,7 @@
from tqdm.auto import tqdm
-from time_series_datasets.monash.monash_utils import (
+from opentslm.time_series_datasets.monash.monash_utils import (
download_and_extract_monash_ucr,
load_from_tsfile_to_dataframe,
)
diff --git a/src/time_series_datasets/monash/MonashSPO2QADataset.py b/src/opentslm/time_series_datasets/monash/MonashSPO2QADataset.py
similarity index 86%
rename from src/time_series_datasets/monash/MonashSPO2QADataset.py
rename to src/opentslm/time_series_datasets/monash/MonashSPO2QADataset.py
index 2f22427a..f3c44f37 100644
--- a/src/time_series_datasets/monash/MonashSPO2QADataset.py
+++ b/src/opentslm/time_series_datasets/monash/MonashSPO2QADataset.py
@@ -1,15 +1,14 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
from typing import List, Literal, Optional, Tuple
from datasets import Dataset
-from prompt.text_time_series_prompt import TextTimeSeriesPrompt
-from time_series_datasets.monash.MonashDataset import MonashDataset
-from time_series_datasets.QADataset import QADataset
-from time_series_datasets.util import (
+from opentslm.prompt.text_time_series_prompt import TextTimeSeriesPrompt
+from opentslm.time_series_datasets.monash.MonashDataset import MonashDataset
+from opentslm.time_series_datasets.QADataset import QADataset
+from opentslm.time_series_datasets.util import (
extend_time_series_to_match_patch_size_and_aggregate,
)
import torch
diff --git a/src/opentslm/time_series_datasets/monash/__init__.py b/src/opentslm/time_series_datasets/monash/__init__.py
new file mode 100644
index 00000000..cbad1615
--- /dev/null
+++ b/src/opentslm/time_series_datasets/monash/__init__.py
@@ -0,0 +1,4 @@
+# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
+#
+# SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/monash/monash_utils.py b/src/opentslm/time_series_datasets/monash/monash_utils.py
similarity index 99%
rename from src/time_series_datasets/monash/monash_utils.py
rename to src/opentslm/time_series_datasets/monash/monash_utils.py
index f3d98e4a..cc6a5520 100644
--- a/src/time_series_datasets/monash/monash_utils.py
+++ b/src/opentslm/time_series_datasets/monash/monash_utils.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/pamap2/BalancedBatchSampler.py b/src/opentslm/time_series_datasets/pamap2/BalancedBatchSampler.py
similarity index 94%
rename from src/time_series_datasets/pamap2/BalancedBatchSampler.py
rename to src/opentslm/time_series_datasets/pamap2/BalancedBatchSampler.py
index 47a795e0..efc2bb97 100644
--- a/src/time_series_datasets/pamap2/BalancedBatchSampler.py
+++ b/src/opentslm/time_series_datasets/pamap2/BalancedBatchSampler.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/pamap2/PAMAP2AccQADataset.py b/src/opentslm/time_series_datasets/pamap2/PAMAP2AccQADataset.py
similarity index 89%
rename from src/time_series_datasets/pamap2/PAMAP2AccQADataset.py
rename to src/opentslm/time_series_datasets/pamap2/PAMAP2AccQADataset.py
index dea805eb..2dca534b 100644
--- a/src/time_series_datasets/pamap2/PAMAP2AccQADataset.py
+++ b/src/opentslm/time_series_datasets/pamap2/PAMAP2AccQADataset.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -8,11 +7,11 @@
from typing import List, Tuple
import numpy as np
-from prompt.text_time_series_prompt import TextTimeSeriesPrompt
-from time_series_datasets.QADataset import QADataset
-from time_series_datasets.pamap2.PAMAP2Dataset import PAMAP2Dataset, ACTIVITIY_ID_DICT
-from time_series_datasets.pamap2.pamap2_loader import PAMAP2_DIR
-from time_series_datasets.util import (
+from opentslm.prompt.text_time_series_prompt import TextTimeSeriesPrompt
+from opentslm.time_series_datasets.QADataset import QADataset
+from opentslm.time_series_datasets.pamap2.PAMAP2Dataset import PAMAP2Dataset, ACTIVITIY_ID_DICT
+from opentslm.time_series_datasets.pamap2.pamap2_loader import PAMAP2_DIR
+from opentslm.time_series_datasets.util import (
extend_time_series_to_match_patch_size_and_aggregate,
)
import torch
diff --git a/src/time_series_datasets/pamap2/PAMAP2CoTQADataset.py b/src/opentslm/time_series_datasets/pamap2/PAMAP2CoTQADataset.py
similarity index 94%
rename from src/time_series_datasets/pamap2/PAMAP2CoTQADataset.py
rename to src/opentslm/time_series_datasets/pamap2/PAMAP2CoTQADataset.py
index 1b6c5a5e..540903f4 100644
--- a/src/time_series_datasets/pamap2/PAMAP2CoTQADataset.py
+++ b/src/opentslm/time_series_datasets/pamap2/PAMAP2CoTQADataset.py
@@ -1,27 +1,24 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
from datasets import Dataset
from typing import List, Tuple, Literal
-import sys
import os
-sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
-from prompt.text_time_series_prompt import TextTimeSeriesPrompt
-from time_series_datasets.QADataset import QADataset
-from time_series_datasets.pamap2.pamap2_cot_loader import load_pamap2_cot_splits
+from opentslm.prompt.text_time_series_prompt import TextTimeSeriesPrompt
+from opentslm.time_series_datasets.QADataset import QADataset
+from opentslm.time_series_datasets.pamap2.pamap2_cot_loader import load_pamap2_cot_splits
import torch
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
-from time_series_datasets.util import (
+from opentslm.time_series_datasets.util import (
extend_time_series_to_match_patch_size_and_aggregate,
)
from collections import defaultdict
import numpy as np
from torch.utils.data import Sampler
-from time_series_datasets.pamap2.BalancedBatchSampler import BalancedBatchSampler
+from opentslm.time_series_datasets.pamap2.BalancedBatchSampler import BalancedBatchSampler
TIME_SERIES_LABELS = [
diff --git a/src/time_series_datasets/pamap2/PAMAP2Dataset.py b/src/opentslm/time_series_datasets/pamap2/PAMAP2Dataset.py
similarity index 97%
rename from src/time_series_datasets/pamap2/PAMAP2Dataset.py
rename to src/opentslm/time_series_datasets/pamap2/PAMAP2Dataset.py
index bf485a9d..3337c94b 100644
--- a/src/time_series_datasets/pamap2/PAMAP2Dataset.py
+++ b/src/opentslm/time_series_datasets/pamap2/PAMAP2Dataset.py
@@ -1,12 +1,11 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
from typing import Tuple
import pandas as pd
-from time_series_datasets.pamap2.pamap2_loader import ensure_pamap2_data
+from opentslm.time_series_datasets.pamap2.pamap2_loader import ensure_pamap2_data
from torch.utils.data import Dataset
ACTIVITIY_ID_DICT = {
diff --git a/src/opentslm/time_series_datasets/pamap2/__init__.py b/src/opentslm/time_series_datasets/pamap2/__init__.py
new file mode 100644
index 00000000..cbad1615
--- /dev/null
+++ b/src/opentslm/time_series_datasets/pamap2/__init__.py
@@ -0,0 +1,4 @@
+# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
+#
+# SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/pamap2/pamap2_cot_loader.py b/src/opentslm/time_series_datasets/pamap2/pamap2_cot_loader.py
similarity index 97%
rename from src/time_series_datasets/pamap2/pamap2_cot_loader.py
rename to src/opentslm/time_series_datasets/pamap2/pamap2_cot_loader.py
index de38ec0c..1e11d93a 100644
--- a/src/time_series_datasets/pamap2/pamap2_cot_loader.py
+++ b/src/opentslm/time_series_datasets/pamap2/pamap2_cot_loader.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -12,10 +11,10 @@
import urllib.request
import zipfile
import shutil
-from time_series_datasets.constants import RAW_DATA
+from opentslm.time_series_datasets.constants import RAW_DATA
import math
import logging
-from logger import get_logger
+from opentslm.logger import get_logger
PAMAP_DATA_DIR = os.path.join(RAW_DATA, "pamap")
diff --git a/src/time_series_datasets/pamap2/pamap2_loader.py b/src/opentslm/time_series_datasets/pamap2/pamap2_loader.py
similarity index 94%
rename from src/time_series_datasets/pamap2/pamap2_loader.py
rename to src/opentslm/time_series_datasets/pamap2/pamap2_loader.py
index 9f32ba0f..11361971 100644
--- a/src/time_series_datasets/pamap2/pamap2_loader.py
+++ b/src/opentslm/time_series_datasets/pamap2/pamap2_loader.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -8,7 +7,7 @@
import zipfile
import requests
-from time_series_datasets.constants import RAW_DATA as RAW_DATA_PATH
+from opentslm.time_series_datasets.constants import RAW_DATA as RAW_DATA_PATH
# ---------------------------
diff --git a/src/time_series_datasets/simulation/SimulationQADataset.py b/src/opentslm/time_series_datasets/simulation/SimulationQADataset.py
similarity index 96%
rename from src/time_series_datasets/simulation/SimulationQADataset.py
rename to src/opentslm/time_series_datasets/simulation/SimulationQADataset.py
index fb1fdbf6..7af24138 100644
--- a/src/time_series_datasets/simulation/SimulationQADataset.py
+++ b/src/opentslm/time_series_datasets/simulation/SimulationQADataset.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -9,8 +8,8 @@
from typing import List, Tuple
from datasets import Dataset
-from prompt.text_time_series_prompt import TextTimeSeriesPrompt
-from time_series_datasets.QADataset import QADataset
+from opentslm.prompt.text_time_series_prompt import TextTimeSeriesPrompt
+from opentslm.time_series_datasets.QADataset import QADataset
DATASET_SIZE = 200
diff --git a/src/time_series_datasets/sleep/SleepEDFCoTQADataset.py b/src/opentslm/time_series_datasets/sleep/SleepEDFCoTQADataset.py
similarity index 90%
rename from src/time_series_datasets/sleep/SleepEDFCoTQADataset.py
rename to src/opentslm/time_series_datasets/sleep/SleepEDFCoTQADataset.py
index 09217b6f..9dbdd257 100644
--- a/src/time_series_datasets/sleep/SleepEDFCoTQADataset.py
+++ b/src/opentslm/time_series_datasets/sleep/SleepEDFCoTQADataset.py
@@ -1,17 +1,14 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
from datasets import Dataset
from typing import List, Tuple, Literal
-import sys
import os
-sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) )
-from prompt.text_time_series_prompt import TextTimeSeriesPrompt
-from time_series_datasets.QADataset import QADataset
-from time_series_datasets.sleep.sleepedf_cot_loader import load_sleepedf_cot_splits
+from opentslm.prompt.text_time_series_prompt import TextTimeSeriesPrompt
+from opentslm.time_series_datasets.QADataset import QADataset
+from opentslm.time_series_datasets.sleep.sleepedf_cot_loader import load_sleepedf_cot_splits
import numpy as np
class SleepEDFCoTQADataset(QADataset):
diff --git a/src/time_series_datasets/sleep/SleepEDFQADataset.py b/src/opentslm/time_series_datasets/sleep/SleepEDFQADataset.py
similarity index 92%
rename from src/time_series_datasets/sleep/SleepEDFQADataset.py
rename to src/opentslm/time_series_datasets/sleep/SleepEDFQADataset.py
index bac0f4ea..75230e4e 100644
--- a/src/time_series_datasets/sleep/SleepEDFQADataset.py
+++ b/src/opentslm/time_series_datasets/sleep/SleepEDFQADataset.py
@@ -1,20 +1,14 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
from datasets import Dataset
from typing import List, Tuple, Literal
-import sys
import os
-
-sys.path.append(
- os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
-)
-from prompt.text_time_series_prompt import TextTimeSeriesPrompt
-from time_series_datasets.QADataset import QADataset
-from time_series_datasets.sleep.sleepedf_cot_loader import load_sleepedf_cot_splits
+from opentslm.prompt.text_time_series_prompt import TextTimeSeriesPrompt
+from opentslm.time_series_datasets.QADataset import QADataset
+from opentslm.time_series_datasets.sleep.sleepedf_cot_loader import load_sleepedf_cot_splits
import numpy as np
diff --git a/src/opentslm/time_series_datasets/sleep/__init__.py b/src/opentslm/time_series_datasets/sleep/__init__.py
new file mode 100644
index 00000000..cbad1615
--- /dev/null
+++ b/src/opentslm/time_series_datasets/sleep/__init__.py
@@ -0,0 +1,4 @@
+# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
+#
+# SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/sleep/sleepedf_cot_loader.py b/src/opentslm/time_series_datasets/sleep/sleepedf_cot_loader.py
similarity index 97%
rename from src/time_series_datasets/sleep/sleepedf_cot_loader.py
rename to src/opentslm/time_series_datasets/sleep/sleepedf_cot_loader.py
index c6f1db27..c11ca466 100644
--- a/src/time_series_datasets/sleep/sleepedf_cot_loader.py
+++ b/src/opentslm/time_series_datasets/sleep/sleepedf_cot_loader.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -10,7 +9,7 @@
from typing import Tuple, Dict
import ast
import urllib.request
-from time_series_datasets.constants import RAW_DATA
+from opentslm.time_series_datasets.constants import RAW_DATA
from tqdm.auto import tqdm
from sklearn.model_selection import train_test_split
diff --git a/src/time_series_datasets/ucr/__init__.py b/src/opentslm/time_series_datasets/ucr/__init__.py
similarity index 70%
rename from src/time_series_datasets/ucr/__init__.py
rename to src/opentslm/time_series_datasets/ucr/__init__.py
index 29c6eab4..5cd50446 100644
--- a/src/time_series_datasets/ucr/__init__.py
+++ b/src/opentslm/time_series_datasets/ucr/__init__.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/ucr/ucr_loader.py b/src/opentslm/time_series_datasets/ucr/ucr_loader.py
similarity index 98%
rename from src/time_series_datasets/ucr/ucr_loader.py
rename to src/opentslm/time_series_datasets/ucr/ucr_loader.py
index 285f8833..0ccf44d9 100644
--- a/src/time_series_datasets/ucr/ucr_loader.py
+++ b/src/opentslm/time_series_datasets/ucr/ucr_loader.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/util.py b/src/opentslm/time_series_datasets/util.py
similarity index 93%
rename from src/time_series_datasets/util.py
rename to src/opentslm/time_series_datasets/util.py
index 3afa6178..8b924db2 100644
--- a/src/time_series_datasets/util.py
+++ b/src/opentslm/time_series_datasets/util.py
@@ -1,12 +1,11 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
import math
from typing import List
-from model_config import PATCH_SIZE
+from opentslm.model_config import PATCH_SIZE
import torch.nn.functional as F
diff --git a/src/prompt/__init__.py b/src/prompt/__init__.py
deleted file mode 100644
index 6882dbc6..00000000
--- a/src/prompt/__init__.py
+++ /dev/null
@@ -1,11 +0,0 @@
-# This source file is part of the OpenTSLM open-source project
-#
-# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-#
-# SPDX-License-Identifier: MIT
-
-# from .prompt import Prompt
-# from .full_prompt import FullPrompt
-# from .text_prompt import TextPrompt
-# from .text_time_series_prompt import TextTimeSeriesPrompt
-# from .prompt_with_answer import PromptWithAnswer
diff --git a/src/time_series_datasets/__init__.py b/src/time_series_datasets/__init__.py
deleted file mode 100644
index 266b1365..00000000
--- a/src/time_series_datasets/__init__.py
+++ /dev/null
@@ -1,5 +0,0 @@
-# This source file is part of the OpenTSLM open-source project
-#
-# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-#
-# SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/ecg_qa/dataset_distribution.png.license b/src/time_series_datasets/ecg_qa/dataset_distribution.png.license
deleted file mode 100644
index e83264aa..00000000
--- a/src/time_series_datasets/ecg_qa/dataset_distribution.png.license
+++ /dev/null
@@ -1,5 +0,0 @@
-This source file is part of the OpenTSLM open-source project
-
-SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-
-SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/ecg_qa/ecg_example_real.png.license b/src/time_series_datasets/ecg_qa/ecg_example_real.png.license
deleted file mode 100644
index e83264aa..00000000
--- a/src/time_series_datasets/ecg_qa/ecg_example_real.png.license
+++ /dev/null
@@ -1,5 +0,0 @@
-This source file is part of the OpenTSLM open-source project
-
-SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-
-SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/har_cot/__init__.py b/src/time_series_datasets/har_cot/__init__.py
deleted file mode 100644
index 266b1365..00000000
--- a/src/time_series_datasets/har_cot/__init__.py
+++ /dev/null
@@ -1,5 +0,0 @@
-# This source file is part of the OpenTSLM open-source project
-#
-# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-#
-# SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/monash/__init__.py b/src/time_series_datasets/monash/__init__.py
deleted file mode 100644
index 266b1365..00000000
--- a/src/time_series_datasets/monash/__init__.py
+++ /dev/null
@@ -1,5 +0,0 @@
-# This source file is part of the OpenTSLM open-source project
-#
-# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-#
-# SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/pamap2/__init__.py b/src/time_series_datasets/pamap2/__init__.py
deleted file mode 100644
index 266b1365..00000000
--- a/src/time_series_datasets/pamap2/__init__.py
+++ /dev/null
@@ -1,5 +0,0 @@
-# This source file is part of the OpenTSLM open-source project
-#
-# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-#
-# SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/sleep/__init__.py b/src/time_series_datasets/sleep/__init__.py
deleted file mode 100644
index 266b1365..00000000
--- a/src/time_series_datasets/sleep/__init__.py
+++ /dev/null
@@ -1,5 +0,0 @@
-# This source file is part of the OpenTSLM open-source project
-#
-# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-#
-# SPDX-License-Identifier: MIT
diff --git a/src/time_series_datasets/tsqa.py b/src/time_series_datasets/tsqa.py
deleted file mode 100644
index 2657d4dd..00000000
--- a/src/time_series_datasets/tsqa.py
+++ /dev/null
@@ -1,25 +0,0 @@
-# This source file is part of the OpenTSLM open-source project
-#
-# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-#
-# SPDX-License-Identifier: MIT
-
-from typing import Literal, Optional
-
-from time_series_datasets.util import load_qa_dataset
-from datasets import load_dataset
-from src.model_config import *
-
-
-def get_tsqa_dataset(
- split: Literal["train", "validation", "test"] = "train",
- *,
- EOS_TOKEN,
- max_samples: Optional[int] = None,
-):
- return load_qa_dataset(
- load_dataset("ChengsenWang/TSQA", split="train"),
- split=split,
- max_samples=max_samples,
- EOS_TOKEN=EOS_TOKEN,
- )
diff --git a/test/.gitignore b/test/.gitignore
deleted file mode 100644
index 935582c2..00000000
--- a/test/.gitignore
+++ /dev/null
@@ -1,7 +0,0 @@
-# This source file is part of the OpenTSLM open-source project
-#
-# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
-#
-# SPDX-License-Identifier: MIT
-
-data
\ No newline at end of file
diff --git a/test/__init__.py b/test/__init__.py
index 266b1365..cbad1615 100644
--- a/test/__init__.py
+++ b/test/__init__.py
@@ -1,5 +1,4 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/test/ecg_qa_cot_test.py b/test/ecg_qa_cot_test.py
index f9a251d6..d7dff451 100644
--- a/test/ecg_qa_cot_test.py
+++ b/test/ecg_qa_cot_test.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -11,16 +10,12 @@
"""
import unittest
-import sys
-import os
-sys.path.append(os.path.join(os.path.dirname(__file__), '..', "src"))
-
-# Import and set up global logger with verbose mode
-from logger import get_logger, set_global_verbose
+from opentslm.time_series_datasets.ecg_qa.ECGQACoTQADataset import ECGQACoTQADataset
+from opentslm.logger import get_logger, set_global_verbose
def pretty_print_label_distribution(dataset, name):
"""Pretty print label distribution for a dataset."""
- from time_series_datasets.ecg_qa.ecgqa_cot_loader import get_label_distribution
+ from opentslm.time_series_datasets.ecg_qa.ecgqa_cot_loader import get_label_distribution
label_dist = get_label_distribution(dataset)
total = len(dataset)
print(f"\n{name} dataset:")
@@ -38,7 +33,7 @@ def setUp(self):
set_global_verbose(True)
self.logger = get_logger()
- from time_series_datasets.ecg_qa.ecgqa_cot_loader import load_ecg_qa_cot_splits
+ from opentslm.time_series_datasets.ecg_qa.ecgqa_cot_loader import load_ecg_qa_cot_splits
self.load_ecg_qa_cot_splits = load_ecg_qa_cot_splits
self.logger.loading("Loading ECG-QA CoT dataset splits...")
@@ -60,7 +55,7 @@ def test_label_distribution(self):
pretty_print_label_distribution(self.val, "Validation")
pretty_print_label_distribution(self.test, "Test")
- from time_series_datasets.ecg_qa.ecgqa_cot_loader import get_label_distribution
+ from opentslm.time_series_datasets.ecg_qa.ecgqa_cot_loader import get_label_distribution
train_dist = get_label_distribution(self.train)
val_dist = get_label_distribution(self.val)
test_dist = get_label_distribution(self.test)
@@ -192,7 +187,7 @@ def setUp(self):
set_global_verbose(True)
self.logger = get_logger()
- from time_series_datasets.ecg_qa import ECGQACoTQADataset
+ from opentslm.time_series_datasets.ecg_qa import ECGQACoTQADataset
self.ECGQACoTQADataset = ECGQACoTQADataset
self.logger.loading("Initializing ECGQACoTQADataset...")
@@ -387,7 +382,7 @@ def test_error_handling_missing_fields(self):
self.logger.info("Testing error handling for missing fields...")
# Create a sample with missing fields to test error handling
- from time_series_datasets.ecg_qa import ECGQACoTQADataset
+ from opentslm.time_series_datasets.ecg_qa import ECGQACoTQADataset
# This should work normally
try:
diff --git a/test/ecg_qa_test.py b/test/ecg_qa_test.py
index 2451c4df..82bfc304 100644
--- a/test/ecg_qa_test.py
+++ b/test/ecg_qa_test.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -18,17 +17,14 @@
Usage:
python test_ecgqa.py
"""
-
import sys
-import sys
-import os
-sys.path.append(os.path.join(os.path.dirname(__file__), '..', "src"))
+
def test_ecgqa_loader():
"""Test the ECG-QA loader functions."""
print("Testing ECG-QA loader...")
try:
- from time_series_datasets.ecg_qa.ecgqa_loader import (
+ from opentslm.time_series_datasets.ecg_qa.ecgqa_loader import (
does_ecg_qa_exist,
does_ptbxl_exist,
download_ecg_qa_if_not_exists,
@@ -57,7 +53,7 @@ def test_ecgqa_dataset():
print("\nTesting ECGQADataset...")
try:
- from time_series_datasets.ecg_qa.ECGQADataset import ECGQADataset
+ from opentslm.time_series_datasets.ecg_qa.ECGQADataset import ECGQADataset
# Try to create dataset instances with limited samples for faster testing
print("Creating dataset instances (limited to 5 samples each for testing)...")
diff --git a/test/elastic_ddp.py b/test/elastic_ddp.py
index 41ccbb6d..4d8fea5c 100644
--- a/test/elastic_ddp.py
+++ b/test/elastic_ddp.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
diff --git a/test/eval_EmbedHealthFlamingo.py b/test/eval_EmbedHealthFlamingo.py
index c92e4881..ecf9557c 100644
--- a/test/eval_EmbedHealthFlamingo.py
+++ b/test/eval_EmbedHealthFlamingo.py
@@ -1,23 +1,22 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
import json
from typing import List
-from time_series_datasets.TSQADataset import TSQADataset
-from time_series_datasets.monash.MonashSPO2QADataset import MonashSPO2QADataset
-from time_series_datasets.util import (
+from opentslm.time_series_datasets.TSQADataset import TSQADataset
+from opentslm.time_series_datasets.monash.MonashSPO2QADataset import MonashSPO2QADataset
+from opentslm.time_series_datasets.util import (
extend_time_series_to_match_patch_size_and_aggregate,
)
import torch
from torch.utils.data import ConcatDataset, DataLoader, Dataset
from tqdm.auto import tqdm
-from model.encoder.TransformerCNNEncoder import TransformerCNNEncoder
-from model.llm.OpenTSLMFlamingo import OpenTSLMFlamingo
-from src.model_config import (
+from opentslm.model.encoder.TransformerCNNEncoder import TransformerCNNEncoder
+from opentslm.model.llm.OpenTSLMFlamingo import OpenTSLMFlamingo
+from opentslm.model_config import (
PATCH_SIZE,
RESULTS_FILE,
)
diff --git a/test/har_cot_test.py b/test/har_cot_test.py
index 08de573e..017070e7 100644
--- a/test/har_cot_test.py
+++ b/test/har_cot_test.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -11,16 +10,13 @@
"""
import unittest
-import sys
-import os
-sys.path.append(os.path.join(os.path.dirname(__file__), '..', "src"))
# Import and set up global logger with verbose mode
-from logger import get_logger, set_global_verbose
+from opentslm.logger import get_logger, set_global_verbose
def pretty_print_label_distribution(dataset, name):
"""Pretty print label distribution for a dataset."""
- from time_series_datasets.har_cot.har_cot_loader import get_label_distribution
+ from opentslm.time_series_datasets.har_cot.har_cot_loader import get_label_distribution
label_dist = get_label_distribution(dataset)
total = len(dataset)
print(f"\n{name} dataset:")
@@ -38,7 +34,7 @@ def setUp(self):
set_global_verbose(True)
self.logger = get_logger()
- from time_series_datasets.har_cot.har_cot_loader import load_har_cot_splits
+ from opentslm.time_series_datasets.har_cot.har_cot_loader import load_har_cot_splits
self.load_har_cot_splits = load_har_cot_splits
self.logger.loading("Loading HAR CoT dataset splits...")
@@ -60,7 +56,7 @@ def test_label_distribution(self):
pretty_print_label_distribution(self.val, "Validation")
pretty_print_label_distribution(self.test, "Test")
- from time_series_datasets.har_cot.har_cot_loader import get_label_distribution
+ from opentslm.time_series_datasets.har_cot.har_cot_loader import get_label_distribution
train_dist = get_label_distribution(self.train)
val_dist = get_label_distribution(self.val)
test_dist = get_label_distribution(self.test)
@@ -150,7 +146,7 @@ def setUp(self):
set_global_verbose(True)
self.logger = get_logger()
- from time_series_datasets.har_cot.HARCoTQADataset import HARCoTQADataset
+ from opentslm.time_series_datasets.har_cot.HARCoTQADataset import HARCoTQADataset
self.HARCoTQADataset = HARCoTQADataset
self.logger.loading("Initializing HARCoTQADataset...")
diff --git a/test/m4_loader_test.py b/test/m4_loader_test.py
index 1df44235..dbc82f26 100644
--- a/test/m4_loader_test.py
+++ b/test/m4_loader_test.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -11,17 +10,14 @@
"""
import unittest
-import sys
-import os
-sys.path.append(os.path.join(os.path.dirname(__file__), '..', "src"))
+from opentslm.time_series_datasets.m4.M4QADataset import M4QADataset as _M4QADataset
class TestM4QADataset(unittest.TestCase):
"""
Unit tests for the M4QADataset class and loader.
"""
def setUp(self):
- from time_series_datasets.m4.M4QADataset import M4QADataset
- self.M4QADataset = M4QADataset
+ self.M4QADataset = _M4QADataset
self.train_dataset = self.M4QADataset("train", "")
self.val_dataset = self.M4QADataset("validation", "")
self.test_dataset = self.M4QADataset("test", "")
diff --git a/test/pamap_cot_loader_test.py b/test/pamap_cot_loader_test.py
index ab4f55bb..fdb2e5f3 100644
--- a/test/pamap_cot_loader_test.py
+++ b/test/pamap_cot_loader_test.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -11,13 +10,12 @@
"""
import unittest
-import sys
-import os
-sys.path.append(os.path.join(os.path.dirname(__file__), '..', "src"))
+from opentslm.logger import get_logger, set_global_verbose
+from opentslm.time_series_datasets.pamap2.BalancedBatchSampler import BalancedBatchSampler
# Import and set up global logger with verbose mode
-from logger import get_logger, set_global_verbose
-from time_series_datasets.pamap2.BalancedBatchSampler import BalancedBatchSampler
+from opentslm.logger import get_logger, set_global_verbose
+from opentslm.time_series_datasets.pamap2.BalancedBatchSampler import BalancedBatchSampler
class TestPAMAP2CoTLoader(unittest.TestCase):
"""
Unit tests for the PAMAP2 CoT loader functions.
@@ -27,7 +25,7 @@ def setUp(self):
set_global_verbose(True)
self.logger = get_logger()
- from time_series_datasets.pamap2.pamap2_cot_loader import load_pamap2_cot_splits
+ from opentslm.time_series_datasets.pamap2.pamap2_cot_loader import load_pamap2_cot_splits
self.load_pamap2_cot_splits = load_pamap2_cot_splits
self.logger.loading("Loading PAMAP2 CoT dataset splits...")
@@ -90,7 +88,7 @@ def setUp(self):
set_global_verbose(True)
self.logger = get_logger()
- from time_series_datasets.pamap2.PAMAP2CoTQADataset import PAMAP2CoTQADataset
+ from opentslm.time_series_datasets.pamap2.PAMAP2CoTQADataset import PAMAP2CoTQADataset
self.PAMAP2CoTQADataset = PAMAP2CoTQADataset
self.logger.loading("Initializing PAMAP2CoTQADataset...")
@@ -196,8 +194,8 @@ def test_balanced_batches_pamap2cot(self):
Test that BalancedBatchSampler produces balanced batches on the real PAMAP2CoTQADataset training split.
Prints batch labels and class counts for each batch.
"""
- from time_series_datasets.pamap2.PAMAP2CoTQADataset import PAMAP2CoTQADataset
- from time_series_datasets.pamap2.BalancedBatchSampler import BalancedBatchSampler
+ from opentslm.time_series_datasets.pamap2.PAMAP2CoTQADataset import PAMAP2CoTQADataset
+ from opentslm.time_series_datasets.pamap2.BalancedBatchSampler import BalancedBatchSampler
# Helper to extract label from answer string
def extract_label_from_answer(answer: str) -> str:
# Assumes answer ends with 'Answer: ' or 'Answer: .'
diff --git a/test/sleepedf_cot_loader_test.py b/test/sleepedf_cot_loader_test.py
index babd393a..878dd1cb 100644
--- a/test/sleepedf_cot_loader_test.py
+++ b/test/sleepedf_cot_loader_test.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -11,11 +10,7 @@
"""
import unittest
-import sys
-import os
-sys.path.append(os.path.join(os.path.dirname(__file__), '..', "src"))
-
-from time_series_datasets.sleep.sleepedf_cot_loader import load_sleepedf_cot_splits, get_label_distribution
+from opentslm.time_series_datasets.sleep.sleepedf_cot_loader import load_sleepedf_cot_splits, get_label_distribution
def pretty_print_label_distribution(dataset, name):
label_dist = get_label_distribution(dataset)
diff --git a/test/smoke_test.py b/test/smoke_test.py
new file mode 100644
index 00000000..686d5c55
--- /dev/null
+++ b/test/smoke_test.py
@@ -0,0 +1,16 @@
+# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
+#
+# SPDX-License-Identifier: MIT
+
+import importlib
+
+mods = [
+ "opentslm",
+ "opentslm.model.llm.OpenTSLM",
+ "opentslm.model.llm.OpenTSLMFlamingo",
+ "opentslm.prompt.full_prompt",
+]
+
+[importlib.import_module(m) for m in mods]
+print("Smoke test passed: all modules imported successfully.")
diff --git a/test/test_curriculum_trainer.py b/test/test_curriculum_trainer.py
index 22cd4d00..ff9af030 100644
--- a/test/test_curriculum_trainer.py
+++ b/test/test_curriculum_trainer.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -16,10 +15,8 @@
import sys
import torch
import json
-from unittest.mock import Mock, patch
# Add the parent directory to the path to import curriculum_learning
-sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from curriculum_learning import CurriculumTrainer
diff --git a/test/test_inference.py b/test/test_inference.py
index c6ff269d..6e067822 100644
--- a/test/test_inference.py
+++ b/test/test_inference.py
@@ -1,6 +1,5 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -8,20 +7,10 @@
import numpy as np
import pandas as pd
-import sys
-import os
-
-sys.path.insert(
- 0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..", "src"))
-)
-
-from model.llm.OpenTSLMFlamingo import OpenTSLMFlamingo
-from prompt.text_prompt import TextPrompt
-from prompt.text_time_series_prompt import TextTimeSeriesPrompt
-from prompt.full_prompt import FullPrompt
-from time_series_datasets.util import (
- extend_time_series_to_match_patch_size_and_aggregate,
-)
+from opentslm.model.llm.OpenTSLMFlamingo import OpenTSLMFlamingo
+from opentslm.prompt.text_prompt import TextPrompt
+from opentslm.prompt.text_time_series_prompt import TextTimeSeriesPrompt
+from opentslm.prompt.full_prompt import FullPrompt
# 1. Load the model
device = (
diff --git a/test/test_medgemma_support.py b/test/test_medgemma_support.py
index 5abc390a..9959e580 100644
--- a/test/test_medgemma_support.py
+++ b/test/test_medgemma_support.py
@@ -1,8 +1,7 @@
#!/usr/bin/env python3
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
@@ -10,13 +9,8 @@
Test script to verify MedGemma support in OpenTSLMFlamingo.
"""
-import sys
-import os
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "src")))
-
import torch
-from model.llm.OpenTSLMFlamingo import OpenTSLMFlamingo
+from opentslm.model.llm.OpenTSLMFlamingo import OpenTSLMFlamingo
def test_medgemma_support():
diff --git a/test/test_train_EmbedHealthFlamingo.py b/test/test_train_EmbedHealthFlamingo.py
index 90cd54f9..ab8b5d26 100644
--- a/test/test_train_EmbedHealthFlamingo.py
+++ b/test/test_train_EmbedHealthFlamingo.py
@@ -1,15 +1,14 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
import json
import os
from typing import List, Optional
-from time_series_datasets.TSQADataset import TSQADataset
-from time_series_datasets.monash.MonashSPO2QADataset import MonashSPO2QADataset
-from time_series_datasets.util import (
+from opentslm.time_series_datasets.TSQADataset import TSQADataset
+from opentslm.time_series_datasets.monash.MonashSPO2QADataset import MonashSPO2QADataset
+from opentslm.time_series_datasets.util import (
extend_time_series_to_match_patch_size_and_aggregate,
)
import torch
@@ -19,10 +18,10 @@
from tqdm.auto import tqdm
from transformers import get_linear_schedule_with_warmup
-from model.encoder.TransformerCNNEncoder import TransformerCNNEncoder
-from model.llm.OpenTSLMFlamingo import OpenTSLMFlamingo
-from model.projector.MLPProjector import MLPProjector
-from src.model_config import (
+from opentslm.model.encoder.TransformerCNNEncoder import TransformerCNNEncoder
+from opentslm.model.llm.OpenTSLMFlamingo import OpenTSLMFlamingo
+from opentslm.model.projector.MLPProjector import MLPProjector
+from opentslm.model_config import (
BATCH_SIZE,
EARLY_STOP_PAT,
GRAD_CLIP_NORM,
diff --git a/test/test_train_EmbedHealthSP.py b/test/test_train_EmbedHealthSP.py
index 1107739e..a493f16d 100644
--- a/test/test_train_EmbedHealthSP.py
+++ b/test/test_train_EmbedHealthSP.py
@@ -1,15 +1,14 @@
-# This source file is part of the OpenTSLM open-source project
-#
# SPDX-FileCopyrightText: 2025 Stanford University, ETH Zurich, and the project authors (see CONTRIBUTORS.md)
+# SPDX-FileCopyrightText: 2025 This source file is part of the OpenTSLM open-source project.
#
# SPDX-License-Identifier: MIT
import json
import os
from typing import List
-from time_series_datasets.TSQADataset import TSQADataset
-from time_series_datasets.monash.MonashSPO2QADataset import MonashSPO2QADataset
-from time_series_datasets.util import (
+from opentslm.time_series_datasets.TSQADataset import TSQADataset
+from opentslm.time_series_datasets.monash.MonashSPO2QADataset import MonashSPO2QADataset
+from opentslm.time_series_datasets.util import (
extend_time_series_to_match_patch_size_and_aggregate,
)
import torch
@@ -19,10 +18,10 @@
from tqdm.auto import tqdm
from transformers import get_linear_schedule_with_warmup
-from model.encoder.TransformerCNNEncoder import TransformerCNNEncoder
-from model.llm.OpenTSLMSP import OpenTSLMSP
-from model.projector.MLPProjector import MLPProjector
-from src.model_config import (
+from opentslm.model.encoder.TransformerCNNEncoder import TransformerCNNEncoder
+from opentslm.model.llm.OpenTSLMSP import OpenTSLMSP
+from opentslm.model.projector.MLPProjector import MLPProjector
+from opentslm.model_config import (
BATCH_SIZE,
EARLY_STOP_PAT,
GRAD_CLIP_NORM,
diff --git a/uv.lock b/uv.lock
new file mode 100644
index 00000000..f1efe58f
--- /dev/null
+++ b/uv.lock
@@ -0,0 +1,3990 @@
+version = 1
+revision = 3
+requires-python = ">=3.12"
+resolution-markers = [
+ "python_full_version >= '3.14' and sys_platform == 'linux'",
+ "python_full_version >= '3.14' and sys_platform != 'linux'",
+ "python_full_version < '3.14' and sys_platform == 'linux'",
+ "python_full_version < '3.14' and sys_platform != 'linux'",
+]
+
+[[package]]
+name = "accelerate"
+version = "1.12.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "huggingface-hub" },
+ { name = "numpy" },
+ { name = "packaging" },
+ { name = "psutil" },
+ { name = "pyyaml" },
+ { name = "safetensors" },
+ { name = "torch" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/4a/8e/ac2a9566747a93f8be36ee08532eb0160558b07630a081a6056a9f89bf1d/accelerate-1.12.0.tar.gz", hash = "sha256:70988c352feb481887077d2ab845125024b2a137a5090d6d7a32b57d03a45df6", size = 398399, upload-time = "2025-11-21T11:27:46.973Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/9f/d2/c581486aa6c4fbd7394c23c47b83fa1a919d34194e16944241daf9e762dd/accelerate-1.12.0-py3-none-any.whl", hash = "sha256:3e2091cd341423207e2f084a6654b1efcd250dc326f2a37d6dde446e07cabb11", size = 380935, upload-time = "2025-11-21T11:27:44.522Z" },
+]
+
+[[package]]
+name = "aiohappyeyeballs"
+version = "2.6.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/26/30/f84a107a9c4331c14b2b586036f40965c128aa4fee4dda5d3d51cb14ad54/aiohappyeyeballs-2.6.1.tar.gz", hash = "sha256:c3f9d0113123803ccadfdf3f0faa505bc78e6a72d1cc4806cbd719826e943558", size = 22760, upload-time = "2025-03-12T01:42:48.764Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/0f/15/5bf3b99495fb160b63f95972b81750f18f7f4e02ad051373b669d17d44f2/aiohappyeyeballs-2.6.1-py3-none-any.whl", hash = "sha256:f349ba8f4b75cb25c99c5c2d84e997e485204d2902a9597802b0371f09331fb8", size = 15265, upload-time = "2025-03-12T01:42:47.083Z" },
+]
+
+[[package]]
+name = "aiohttp"
+version = "3.13.2"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "aiohappyeyeballs" },
+ { name = "aiosignal" },
+ { name = "attrs" },
+ { name = "frozenlist" },
+ { name = "multidict" },
+ { name = "propcache" },
+ { name = "yarl" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/1c/ce/3b83ebba6b3207a7135e5fcaba49706f8a4b6008153b4e30540c982fae26/aiohttp-3.13.2.tar.gz", hash = "sha256:40176a52c186aefef6eb3cad2cdd30cd06e3afbe88fe8ab2af9c0b90f228daca", size = 7837994, upload-time = "2025-10-28T20:59:39.937Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/29/9b/01f00e9856d0a73260e86dd8ed0c2234a466c5c1712ce1c281548df39777/aiohttp-3.13.2-cp312-cp312-macosx_10_13_universal2.whl", hash = "sha256:b1e56bab2e12b2b9ed300218c351ee2a3d8c8fdab5b1ec6193e11a817767e47b", size = 737623, upload-time = "2025-10-28T20:56:30.797Z" },
+ { url = "https://files.pythonhosted.org/packages/5a/1b/4be39c445e2b2bd0aab4ba736deb649fabf14f6757f405f0c9685019b9e9/aiohttp-3.13.2-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:364e25edaabd3d37b1db1f0cbcee8c73c9a3727bfa262b83e5e4cf3489a2a9dc", size = 492664, upload-time = "2025-10-28T20:56:32.708Z" },
+ { url = "https://files.pythonhosted.org/packages/28/66/d35dcfea8050e131cdd731dff36434390479b4045a8d0b9d7111b0a968f1/aiohttp-3.13.2-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:c5c94825f744694c4b8db20b71dba9a257cd2ba8e010a803042123f3a25d50d7", size = 491808, upload-time = "2025-10-28T20:56:34.57Z" },
+ { url = "https://files.pythonhosted.org/packages/00/29/8e4609b93e10a853b65f8291e64985de66d4f5848c5637cddc70e98f01f8/aiohttp-3.13.2-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:ba2715d842ffa787be87cbfce150d5e88c87a98e0b62e0f5aa489169a393dbbb", size = 1738863, upload-time = "2025-10-28T20:56:36.377Z" },
+ { url = "https://files.pythonhosted.org/packages/9d/fa/4ebdf4adcc0def75ced1a0d2d227577cd7b1b85beb7edad85fcc87693c75/aiohttp-3.13.2-cp312-cp312-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:585542825c4bc662221fb257889e011a5aa00f1ae4d75d1d246a5225289183e3", size = 1700586, upload-time = "2025-10-28T20:56:38.034Z" },
+ { url = "https://files.pythonhosted.org/packages/da/04/73f5f02ff348a3558763ff6abe99c223381b0bace05cd4530a0258e52597/aiohttp-3.13.2-cp312-cp312-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:39d02cb6025fe1aabca329c5632f48c9532a3dabccd859e7e2f110668972331f", size = 1768625, upload-time = "2025-10-28T20:56:39.75Z" },
+ { url = "https://files.pythonhosted.org/packages/f8/49/a825b79ffec124317265ca7d2344a86bcffeb960743487cb11988ffb3494/aiohttp-3.13.2-cp312-cp312-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:e67446b19e014d37342f7195f592a2a948141d15a312fe0e700c2fd2f03124f6", size = 1867281, upload-time = "2025-10-28T20:56:41.471Z" },
+ { url = "https://files.pythonhosted.org/packages/b9/48/adf56e05f81eac31edcfae45c90928f4ad50ef2e3ea72cb8376162a368f8/aiohttp-3.13.2-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:4356474ad6333e41ccefd39eae869ba15a6c5299c9c01dfdcfdd5c107be4363e", size = 1752431, upload-time = "2025-10-28T20:56:43.162Z" },
+ { url = "https://files.pythonhosted.org/packages/30/ab/593855356eead019a74e862f21523db09c27f12fd24af72dbc3555b9bfd9/aiohttp-3.13.2-cp312-cp312-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:eeacf451c99b4525f700f078becff32c32ec327b10dcf31306a8a52d78166de7", size = 1562846, upload-time = "2025-10-28T20:56:44.85Z" },
+ { url = "https://files.pythonhosted.org/packages/39/0f/9f3d32271aa8dc35036e9668e31870a9d3b9542dd6b3e2c8a30931cb27ae/aiohttp-3.13.2-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:d8a9b889aeabd7a4e9af0b7f4ab5ad94d42e7ff679aaec6d0db21e3b639ad58d", size = 1699606, upload-time = "2025-10-28T20:56:46.519Z" },
+ { url = "https://files.pythonhosted.org/packages/2c/3c/52d2658c5699b6ef7692a3f7128b2d2d4d9775f2a68093f74bca06cf01e1/aiohttp-3.13.2-cp312-cp312-musllinux_1_2_armv7l.whl", hash = "sha256:fa89cb11bc71a63b69568d5b8a25c3ca25b6d54c15f907ca1c130d72f320b76b", size = 1720663, upload-time = "2025-10-28T20:56:48.528Z" },
+ { url = "https://files.pythonhosted.org/packages/9b/d4/8f8f3ff1fb7fb9e3f04fcad4e89d8a1cd8fc7d05de67e3de5b15b33008ff/aiohttp-3.13.2-cp312-cp312-musllinux_1_2_ppc64le.whl", hash = "sha256:8aa7c807df234f693fed0ecd507192fc97692e61fee5702cdc11155d2e5cadc8", size = 1737939, upload-time = "2025-10-28T20:56:50.77Z" },
+ { url = "https://files.pythonhosted.org/packages/03/d3/ddd348f8a27a634daae39a1b8e291ff19c77867af438af844bf8b7e3231b/aiohttp-3.13.2-cp312-cp312-musllinux_1_2_riscv64.whl", hash = "sha256:9eb3e33fdbe43f88c3c75fa608c25e7c47bbd80f48d012763cb67c47f39a7e16", size = 1555132, upload-time = "2025-10-28T20:56:52.568Z" },
+ { url = "https://files.pythonhosted.org/packages/39/b8/46790692dc46218406f94374903ba47552f2f9f90dad554eed61bfb7b64c/aiohttp-3.13.2-cp312-cp312-musllinux_1_2_s390x.whl", hash = "sha256:9434bc0d80076138ea986833156c5a48c9c7a8abb0c96039ddbb4afc93184169", size = 1764802, upload-time = "2025-10-28T20:56:54.292Z" },
+ { url = "https://files.pythonhosted.org/packages/ba/e4/19ce547b58ab2a385e5f0b8aa3db38674785085abcf79b6e0edd1632b12f/aiohttp-3.13.2-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:ff15c147b2ad66da1f2cbb0622313f2242d8e6e8f9b79b5206c84523a4473248", size = 1719512, upload-time = "2025-10-28T20:56:56.428Z" },
+ { url = "https://files.pythonhosted.org/packages/70/30/6355a737fed29dcb6dfdd48682d5790cb5eab050f7b4e01f49b121d3acad/aiohttp-3.13.2-cp312-cp312-win32.whl", hash = "sha256:27e569eb9d9e95dbd55c0fc3ec3a9335defbf1d8bc1d20171a49f3c4c607b93e", size = 426690, upload-time = "2025-10-28T20:56:58.736Z" },
+ { url = "https://files.pythonhosted.org/packages/0a/0d/b10ac09069973d112de6ef980c1f6bb31cb7dcd0bc363acbdad58f927873/aiohttp-3.13.2-cp312-cp312-win_amd64.whl", hash = "sha256:8709a0f05d59a71f33fd05c17fc11fcb8c30140506e13c2f5e8ee1b8964e1b45", size = 453465, upload-time = "2025-10-28T20:57:00.795Z" },
+ { url = "https://files.pythonhosted.org/packages/bf/78/7e90ca79e5aa39f9694dcfd74f4720782d3c6828113bb1f3197f7e7c4a56/aiohttp-3.13.2-cp313-cp313-macosx_10_13_universal2.whl", hash = "sha256:7519bdc7dfc1940d201651b52bf5e03f5503bda45ad6eacf64dda98be5b2b6be", size = 732139, upload-time = "2025-10-28T20:57:02.455Z" },
+ { url = "https://files.pythonhosted.org/packages/db/ed/1f59215ab6853fbaa5c8495fa6cbc39edfc93553426152b75d82a5f32b76/aiohttp-3.13.2-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:088912a78b4d4f547a1f19c099d5a506df17eacec3c6f4375e2831ec1d995742", size = 490082, upload-time = "2025-10-28T20:57:04.784Z" },
+ { url = "https://files.pythonhosted.org/packages/68/7b/fe0fe0f5e05e13629d893c760465173a15ad0039c0a5b0d0040995c8075e/aiohttp-3.13.2-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:5276807b9de9092af38ed23ce120539ab0ac955547b38563a9ba4f5b07b95293", size = 489035, upload-time = "2025-10-28T20:57:06.894Z" },
+ { url = "https://files.pythonhosted.org/packages/d2/04/db5279e38471b7ac801d7d36a57d1230feeee130bbe2a74f72731b23c2b1/aiohttp-3.13.2-cp313-cp313-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:1237c1375eaef0db4dcd7c2559f42e8af7b87ea7d295b118c60c36a6e61cb811", size = 1720387, upload-time = "2025-10-28T20:57:08.685Z" },
+ { url = "https://files.pythonhosted.org/packages/31/07/8ea4326bd7dae2bd59828f69d7fdc6e04523caa55e4a70f4a8725a7e4ed2/aiohttp-3.13.2-cp313-cp313-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:96581619c57419c3d7d78703d5b78c1e5e5fc0172d60f555bdebaced82ded19a", size = 1688314, upload-time = "2025-10-28T20:57:10.693Z" },
+ { url = "https://files.pythonhosted.org/packages/48/ab/3d98007b5b87ffd519d065225438cc3b668b2f245572a8cb53da5dd2b1bc/aiohttp-3.13.2-cp313-cp313-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:a2713a95b47374169409d18103366de1050fe0ea73db358fc7a7acb2880422d4", size = 1756317, upload-time = "2025-10-28T20:57:12.563Z" },
+ { url = "https://files.pythonhosted.org/packages/97/3d/801ca172b3d857fafb7b50c7c03f91b72b867a13abca982ed6b3081774ef/aiohttp-3.13.2-cp313-cp313-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:228a1cd556b3caca590e9511a89444925da87d35219a49ab5da0c36d2d943a6a", size = 1858539, upload-time = "2025-10-28T20:57:14.623Z" },
+ { url = "https://files.pythonhosted.org/packages/f7/0d/4764669bdf47bd472899b3d3db91fffbe925c8e3038ec591a2fd2ad6a14d/aiohttp-3.13.2-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:ac6cde5fba8d7d8c6ac963dbb0256a9854e9fafff52fbcc58fdf819357892c3e", size = 1739597, upload-time = "2025-10-28T20:57:16.399Z" },
+ { url = "https://files.pythonhosted.org/packages/c4/52/7bd3c6693da58ba16e657eb904a5b6decfc48ecd06e9ac098591653b1566/aiohttp-3.13.2-cp313-cp313-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:f2bef8237544f4e42878c61cef4e2839fee6346dc60f5739f876a9c50be7fcdb", size = 1555006, upload-time = "2025-10-28T20:57:18.288Z" },
+ { url = "https://files.pythonhosted.org/packages/48/30/9586667acec5993b6f41d2ebcf96e97a1255a85f62f3c653110a5de4d346/aiohttp-3.13.2-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:16f15a4eac3bc2d76c45f7ebdd48a65d41b242eb6c31c2245463b40b34584ded", size = 1683220, upload-time = "2025-10-28T20:57:20.241Z" },
+ { url = "https://files.pythonhosted.org/packages/71/01/3afe4c96854cfd7b30d78333852e8e851dceaec1c40fd00fec90c6402dd2/aiohttp-3.13.2-cp313-cp313-musllinux_1_2_armv7l.whl", hash = "sha256:bb7fb776645af5cc58ab804c58d7eba545a97e047254a52ce89c157b5af6cd0b", size = 1712570, upload-time = "2025-10-28T20:57:22.253Z" },
+ { url = "https://files.pythonhosted.org/packages/11/2c/22799d8e720f4697a9e66fd9c02479e40a49de3de2f0bbe7f9f78a987808/aiohttp-3.13.2-cp313-cp313-musllinux_1_2_ppc64le.whl", hash = "sha256:e1b4951125ec10c70802f2cb09736c895861cd39fd9dcb35107b4dc8ae6220b8", size = 1733407, upload-time = "2025-10-28T20:57:24.37Z" },
+ { url = "https://files.pythonhosted.org/packages/34/cb/90f15dd029f07cebbd91f8238a8b363978b530cd128488085b5703683594/aiohttp-3.13.2-cp313-cp313-musllinux_1_2_riscv64.whl", hash = "sha256:550bf765101ae721ee1d37d8095f47b1f220650f85fe1af37a90ce75bab89d04", size = 1550093, upload-time = "2025-10-28T20:57:26.257Z" },
+ { url = "https://files.pythonhosted.org/packages/69/46/12dce9be9d3303ecbf4d30ad45a7683dc63d90733c2d9fe512be6716cd40/aiohttp-3.13.2-cp313-cp313-musllinux_1_2_s390x.whl", hash = "sha256:fe91b87fc295973096251e2d25a811388e7d8adf3bd2b97ef6ae78bc4ac6c476", size = 1758084, upload-time = "2025-10-28T20:57:28.349Z" },
+ { url = "https://files.pythonhosted.org/packages/f9/c8/0932b558da0c302ffd639fc6362a313b98fdf235dc417bc2493da8394df7/aiohttp-3.13.2-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:e0c8e31cfcc4592cb200160344b2fb6ae0f9e4effe06c644b5a125d4ae5ebe23", size = 1716987, upload-time = "2025-10-28T20:57:30.233Z" },
+ { url = "https://files.pythonhosted.org/packages/5d/8b/f5bd1a75003daed099baec373aed678f2e9b34f2ad40d85baa1368556396/aiohttp-3.13.2-cp313-cp313-win32.whl", hash = "sha256:0740f31a60848d6edb296a0df827473eede90c689b8f9f2a4cdde74889eb2254", size = 425859, upload-time = "2025-10-28T20:57:32.105Z" },
+ { url = "https://files.pythonhosted.org/packages/5d/28/a8a9fc6957b2cee8902414e41816b5ab5536ecf43c3b1843c10e82c559b2/aiohttp-3.13.2-cp313-cp313-win_amd64.whl", hash = "sha256:a88d13e7ca367394908f8a276b89d04a3652044612b9a408a0bb22a5ed976a1a", size = 452192, upload-time = "2025-10-28T20:57:34.166Z" },
+ { url = "https://files.pythonhosted.org/packages/9b/36/e2abae1bd815f01c957cbf7be817b3043304e1c87bad526292a0410fdcf9/aiohttp-3.13.2-cp314-cp314-macosx_10_13_universal2.whl", hash = "sha256:2475391c29230e063ef53a66669b7b691c9bfc3f1426a0f7bcdf1216bdbac38b", size = 735234, upload-time = "2025-10-28T20:57:36.415Z" },
+ { url = "https://files.pythonhosted.org/packages/ca/e3/1ee62dde9b335e4ed41db6bba02613295a0d5b41f74a783c142745a12763/aiohttp-3.13.2-cp314-cp314-macosx_10_13_x86_64.whl", hash = "sha256:f33c8748abef4d8717bb20e8fb1b3e07c6adacb7fd6beaae971a764cf5f30d61", size = 490733, upload-time = "2025-10-28T20:57:38.205Z" },
+ { url = "https://files.pythonhosted.org/packages/1a/aa/7a451b1d6a04e8d15a362af3e9b897de71d86feac3babf8894545d08d537/aiohttp-3.13.2-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:ae32f24bbfb7dbb485a24b30b1149e2f200be94777232aeadba3eecece4d0aa4", size = 491303, upload-time = "2025-10-28T20:57:40.122Z" },
+ { url = "https://files.pythonhosted.org/packages/57/1e/209958dbb9b01174870f6a7538cd1f3f28274fdbc88a750c238e2c456295/aiohttp-3.13.2-cp314-cp314-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:5d7f02042c1f009ffb70067326ef183a047425bb2ff3bc434ead4dd4a4a66a2b", size = 1717965, upload-time = "2025-10-28T20:57:42.28Z" },
+ { url = "https://files.pythonhosted.org/packages/08/aa/6a01848d6432f241416bc4866cae8dc03f05a5a884d2311280f6a09c73d6/aiohttp-3.13.2-cp314-cp314-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:93655083005d71cd6c072cdab54c886e6570ad2c4592139c3fb967bfc19e4694", size = 1667221, upload-time = "2025-10-28T20:57:44.869Z" },
+ { url = "https://files.pythonhosted.org/packages/87/4f/36c1992432d31bbc789fa0b93c768d2e9047ec8c7177e5cd84ea85155f36/aiohttp-3.13.2-cp314-cp314-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:0db1e24b852f5f664cd728db140cf11ea0e82450471232a394b3d1a540b0f906", size = 1757178, upload-time = "2025-10-28T20:57:47.216Z" },
+ { url = "https://files.pythonhosted.org/packages/ac/b4/8e940dfb03b7e0f68a82b88fd182b9be0a65cb3f35612fe38c038c3112cf/aiohttp-3.13.2-cp314-cp314-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:b009194665bcd128e23eaddef362e745601afa4641930848af4c8559e88f18f9", size = 1838001, upload-time = "2025-10-28T20:57:49.337Z" },
+ { url = "https://files.pythonhosted.org/packages/d7/ef/39f3448795499c440ab66084a9db7d20ca7662e94305f175a80f5b7e0072/aiohttp-3.13.2-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:c038a8fdc8103cd51dbd986ecdce141473ffd9775a7a8057a6ed9c3653478011", size = 1716325, upload-time = "2025-10-28T20:57:51.327Z" },
+ { url = "https://files.pythonhosted.org/packages/d7/51/b311500ffc860b181c05d91c59a1313bdd05c82960fdd4035a15740d431e/aiohttp-3.13.2-cp314-cp314-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:66bac29b95a00db411cd758fea0e4b9bdba6d549dfe333f9a945430f5f2cc5a6", size = 1547978, upload-time = "2025-10-28T20:57:53.554Z" },
+ { url = "https://files.pythonhosted.org/packages/31/64/b9d733296ef79815226dab8c586ff9e3df41c6aff2e16c06697b2d2e6775/aiohttp-3.13.2-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:4ebf9cfc9ba24a74cf0718f04aac2a3bbe745902cc7c5ebc55c0f3b5777ef213", size = 1682042, upload-time = "2025-10-28T20:57:55.617Z" },
+ { url = "https://files.pythonhosted.org/packages/3f/30/43d3e0f9d6473a6db7d472104c4eff4417b1e9df01774cb930338806d36b/aiohttp-3.13.2-cp314-cp314-musllinux_1_2_armv7l.whl", hash = "sha256:a4b88ebe35ce54205c7074f7302bd08a4cb83256a3e0870c72d6f68a3aaf8e49", size = 1680085, upload-time = "2025-10-28T20:57:57.59Z" },
+ { url = "https://files.pythonhosted.org/packages/16/51/c709f352c911b1864cfd1087577760ced64b3e5bee2aa88b8c0c8e2e4972/aiohttp-3.13.2-cp314-cp314-musllinux_1_2_ppc64le.whl", hash = "sha256:98c4fb90bb82b70a4ed79ca35f656f4281885be076f3f970ce315402b53099ae", size = 1728238, upload-time = "2025-10-28T20:57:59.525Z" },
+ { url = "https://files.pythonhosted.org/packages/19/e2/19bd4c547092b773caeb48ff5ae4b1ae86756a0ee76c16727fcfd281404b/aiohttp-3.13.2-cp314-cp314-musllinux_1_2_riscv64.whl", hash = "sha256:ec7534e63ae0f3759df3a1ed4fa6bc8f75082a924b590619c0dd2f76d7043caa", size = 1544395, upload-time = "2025-10-28T20:58:01.914Z" },
+ { url = "https://files.pythonhosted.org/packages/cf/87/860f2803b27dfc5ed7be532832a3498e4919da61299b4a1f8eb89b8ff44d/aiohttp-3.13.2-cp314-cp314-musllinux_1_2_s390x.whl", hash = "sha256:5b927cf9b935a13e33644cbed6c8c4b2d0f25b713d838743f8fe7191b33829c4", size = 1742965, upload-time = "2025-10-28T20:58:03.972Z" },
+ { url = "https://files.pythonhosted.org/packages/67/7f/db2fc7618925e8c7a601094d5cbe539f732df4fb570740be88ed9e40e99a/aiohttp-3.13.2-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:88d6c017966a78c5265d996c19cdb79235be5e6412268d7e2ce7dee339471b7a", size = 1697585, upload-time = "2025-10-28T20:58:06.189Z" },
+ { url = "https://files.pythonhosted.org/packages/0c/07/9127916cb09bb38284db5036036042b7b2c514c8ebaeee79da550c43a6d6/aiohttp-3.13.2-cp314-cp314-win32.whl", hash = "sha256:f7c183e786e299b5d6c49fb43a769f8eb8e04a2726a2bd5887b98b5cc2d67940", size = 431621, upload-time = "2025-10-28T20:58:08.636Z" },
+ { url = "https://files.pythonhosted.org/packages/fb/41/554a8a380df6d3a2bba8a7726429a23f4ac62aaf38de43bb6d6cde7b4d4d/aiohttp-3.13.2-cp314-cp314-win_amd64.whl", hash = "sha256:fe242cd381e0fb65758faf5ad96c2e460df6ee5b2de1072fe97e4127927e00b4", size = 457627, upload-time = "2025-10-28T20:58:11Z" },
+ { url = "https://files.pythonhosted.org/packages/c7/8e/3824ef98c039d3951cb65b9205a96dd2b20f22241ee17d89c5701557c826/aiohttp-3.13.2-cp314-cp314t-macosx_10_13_universal2.whl", hash = "sha256:f10d9c0b0188fe85398c61147bbd2a657d616c876863bfeff43376e0e3134673", size = 767360, upload-time = "2025-10-28T20:58:13.358Z" },
+ { url = "https://files.pythonhosted.org/packages/a4/0f/6a03e3fc7595421274fa34122c973bde2d89344f8a881b728fa8c774e4f1/aiohttp-3.13.2-cp314-cp314t-macosx_10_13_x86_64.whl", hash = "sha256:e7c952aefdf2460f4ae55c5e9c3e80aa72f706a6317e06020f80e96253b1accd", size = 504616, upload-time = "2025-10-28T20:58:15.339Z" },
+ { url = "https://files.pythonhosted.org/packages/c6/aa/ed341b670f1bc8a6f2c6a718353d13b9546e2cef3544f573c6a1ff0da711/aiohttp-3.13.2-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:c20423ce14771d98353d2e25e83591fa75dfa90a3c1848f3d7c68243b4fbded3", size = 509131, upload-time = "2025-10-28T20:58:17.693Z" },
+ { url = "https://files.pythonhosted.org/packages/7f/f0/c68dac234189dae5c4bbccc0f96ce0cc16b76632cfc3a08fff180045cfa4/aiohttp-3.13.2-cp314-cp314t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:e96eb1a34396e9430c19d8338d2ec33015e4a87ef2b4449db94c22412e25ccdf", size = 1864168, upload-time = "2025-10-28T20:58:20.113Z" },
+ { url = "https://files.pythonhosted.org/packages/8f/65/75a9a76db8364b5d0e52a0c20eabc5d52297385d9af9c35335b924fafdee/aiohttp-3.13.2-cp314-cp314t-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:23fb0783bc1a33640036465019d3bba069942616a6a2353c6907d7fe1ccdaf4e", size = 1719200, upload-time = "2025-10-28T20:58:22.583Z" },
+ { url = "https://files.pythonhosted.org/packages/f5/55/8df2ed78d7f41d232f6bd3ff866b6f617026551aa1d07e2f03458f964575/aiohttp-3.13.2-cp314-cp314t-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:2e1a9bea6244a1d05a4e57c295d69e159a5c50d8ef16aa390948ee873478d9a5", size = 1843497, upload-time = "2025-10-28T20:58:24.672Z" },
+ { url = "https://files.pythonhosted.org/packages/e9/e0/94d7215e405c5a02ccb6a35c7a3a6cfff242f457a00196496935f700cde5/aiohttp-3.13.2-cp314-cp314t-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:0a3d54e822688b56e9f6b5816fb3de3a3a64660efac64e4c2dc435230ad23bad", size = 1935703, upload-time = "2025-10-28T20:58:26.758Z" },
+ { url = "https://files.pythonhosted.org/packages/0b/78/1eeb63c3f9b2d1015a4c02788fb543141aad0a03ae3f7a7b669b2483f8d4/aiohttp-3.13.2-cp314-cp314t-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:7a653d872afe9f33497215745da7a943d1dc15b728a9c8da1c3ac423af35178e", size = 1792738, upload-time = "2025-10-28T20:58:29.787Z" },
+ { url = "https://files.pythonhosted.org/packages/41/75/aaf1eea4c188e51538c04cc568040e3082db263a57086ea74a7d38c39e42/aiohttp-3.13.2-cp314-cp314t-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:56d36e80d2003fa3fc0207fac644216d8532e9504a785ef9a8fd013f84a42c61", size = 1624061, upload-time = "2025-10-28T20:58:32.529Z" },
+ { url = "https://files.pythonhosted.org/packages/9b/c2/3b6034de81fbcc43de8aeb209073a2286dfb50b86e927b4efd81cf848197/aiohttp-3.13.2-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:78cd586d8331fb8e241c2dd6b2f4061778cc69e150514b39a9e28dd050475661", size = 1789201, upload-time = "2025-10-28T20:58:34.618Z" },
+ { url = "https://files.pythonhosted.org/packages/c9/38/c15dcf6d4d890217dae79d7213988f4e5fe6183d43893a9cf2fe9e84ca8d/aiohttp-3.13.2-cp314-cp314t-musllinux_1_2_armv7l.whl", hash = "sha256:20b10bbfbff766294fe99987f7bb3b74fdd2f1a2905f2562132641ad434dcf98", size = 1776868, upload-time = "2025-10-28T20:58:38.835Z" },
+ { url = "https://files.pythonhosted.org/packages/04/75/f74fd178ac81adf4f283a74847807ade5150e48feda6aef024403716c30c/aiohttp-3.13.2-cp314-cp314t-musllinux_1_2_ppc64le.whl", hash = "sha256:9ec49dff7e2b3c85cdeaa412e9d438f0ecd71676fde61ec57027dd392f00c693", size = 1790660, upload-time = "2025-10-28T20:58:41.507Z" },
+ { url = "https://files.pythonhosted.org/packages/e7/80/7368bd0d06b16b3aba358c16b919e9c46cf11587dc572091031b0e9e3ef0/aiohttp-3.13.2-cp314-cp314t-musllinux_1_2_riscv64.whl", hash = "sha256:94f05348c4406450f9d73d38efb41d669ad6cd90c7ee194810d0eefbfa875a7a", size = 1617548, upload-time = "2025-10-28T20:58:43.674Z" },
+ { url = "https://files.pythonhosted.org/packages/7d/4b/a6212790c50483cb3212e507378fbe26b5086d73941e1ec4b56a30439688/aiohttp-3.13.2-cp314-cp314t-musllinux_1_2_s390x.whl", hash = "sha256:fa4dcb605c6f82a80c7f95713c2b11c3b8e9893b3ebd2bc9bde93165ed6107be", size = 1817240, upload-time = "2025-10-28T20:58:45.787Z" },
+ { url = "https://files.pythonhosted.org/packages/ff/f7/ba5f0ba4ea8d8f3c32850912944532b933acbf0f3a75546b89269b9b7dde/aiohttp-3.13.2-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:cf00e5db968c3f67eccd2778574cf64d8b27d95b237770aa32400bd7a1ca4f6c", size = 1762334, upload-time = "2025-10-28T20:58:47.936Z" },
+ { url = "https://files.pythonhosted.org/packages/7e/83/1a5a1856574588b1cad63609ea9ad75b32a8353ac995d830bf5da9357364/aiohttp-3.13.2-cp314-cp314t-win32.whl", hash = "sha256:d23b5fe492b0805a50d3371e8a728a9134d8de5447dce4c885f5587294750734", size = 464685, upload-time = "2025-10-28T20:58:50.642Z" },
+ { url = "https://files.pythonhosted.org/packages/9f/4d/d22668674122c08f4d56972297c51a624e64b3ed1efaa40187607a7cb66e/aiohttp-3.13.2-cp314-cp314t-win_amd64.whl", hash = "sha256:ff0a7b0a82a7ab905cbda74006318d1b12e37c797eb1b0d4eb3e316cf47f658f", size = 498093, upload-time = "2025-10-28T20:58:52.782Z" },
+]
+
+[[package]]
+name = "aiosignal"
+version = "1.4.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "frozenlist" },
+ { name = "typing-extensions", marker = "python_full_version < '3.13'" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/61/62/06741b579156360248d1ec624842ad0edf697050bbaf7c3e46394e106ad1/aiosignal-1.4.0.tar.gz", hash = "sha256:f47eecd9468083c2029cc99945502cb7708b082c232f9aca65da147157b251c7", size = 25007, upload-time = "2025-07-03T22:54:43.528Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/fb/76/641ae371508676492379f16e2fa48f4e2c11741bd63c48be4b12a6b09cba/aiosignal-1.4.0-py3-none-any.whl", hash = "sha256:053243f8b92b990551949e63930a839ff0cf0b0ebbe0597b0f3fb19e1a0fe82e", size = 7490, upload-time = "2025-07-03T22:54:42.156Z" },
+]
+
+[[package]]
+name = "annotated-types"
+version = "0.7.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/ee/67/531ea369ba64dcff5ec9c3402f9f51bf748cec26dde048a2f973a4eea7f5/annotated_types-0.7.0.tar.gz", hash = "sha256:aff07c09a53a08bc8cfccb9c85b05f1aa9a2a6f23728d790723543408344ce89", size = 16081, upload-time = "2024-05-20T21:33:25.928Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/78/b6/6307fbef88d9b5ee7421e68d78a9f162e0da4900bc5f5793f6d3d0e34fb8/annotated_types-0.7.0-py3-none-any.whl", hash = "sha256:1f02e8b43a8fbbc3f3e0d4f0f4bfc8131bcb4eebe8849b8e5c773f3a1c582a53", size = 13643, upload-time = "2024-05-20T21:33:24.1Z" },
+]
+
+[[package]]
+name = "anyio"
+version = "4.12.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "idna" },
+ { name = "typing-extensions", marker = "python_full_version < '3.13'" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/16/ce/8a777047513153587e5434fd752e89334ac33e379aa3497db860eeb60377/anyio-4.12.0.tar.gz", hash = "sha256:73c693b567b0c55130c104d0b43a9baf3aa6a31fc6110116509f27bf75e21ec0", size = 228266, upload-time = "2025-11-28T23:37:38.911Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/7f/9c/36c5c37947ebfb8c7f22e0eb6e4d188ee2d53aa3880f3f2744fb894f0cb1/anyio-4.12.0-py3-none-any.whl", hash = "sha256:dad2376a628f98eeca4881fc56cd06affd18f659b17a747d3ff0307ced94b1bb", size = 113362, upload-time = "2025-11-28T23:36:57.897Z" },
+]
+
+[[package]]
+name = "appnope"
+version = "0.1.4"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/35/5d/752690df9ef5b76e169e68d6a129fa6d08a7100ca7f754c89495db3c6019/appnope-0.1.4.tar.gz", hash = "sha256:1de3860566df9caf38f01f86f65e0e13e379af54f9e4bee1e66b48f2efffd1ee", size = 4170, upload-time = "2024-02-06T09:43:11.258Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/81/29/5ecc3a15d5a33e31b26c11426c45c501e439cb865d0bff96315d86443b78/appnope-0.1.4-py2.py3-none-any.whl", hash = "sha256:502575ee11cd7a28c0205f379b525beefebab9d161b7c964670864014ed7213c", size = 4321, upload-time = "2024-02-06T09:43:09.663Z" },
+]
+
+[[package]]
+name = "argon2-cffi"
+version = "25.1.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "argon2-cffi-bindings" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/0e/89/ce5af8a7d472a67cc819d5d998aa8c82c5d860608c4db9f46f1162d7dab9/argon2_cffi-25.1.0.tar.gz", hash = "sha256:694ae5cc8a42f4c4e2bf2ca0e64e51e23a040c6a517a85074683d3959e1346c1", size = 45706, upload-time = "2025-06-03T06:55:32.073Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/4f/d3/a8b22fa575b297cd6e3e3b0155c7e25db170edf1c74783d6a31a2490b8d9/argon2_cffi-25.1.0-py3-none-any.whl", hash = "sha256:fdc8b074db390fccb6eb4a3604ae7231f219aa669a2652e0f20e16ba513d5741", size = 14657, upload-time = "2025-06-03T06:55:30.804Z" },
+]
+
+[[package]]
+name = "argon2-cffi-bindings"
+version = "25.1.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "cffi" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/5c/2d/db8af0df73c1cf454f71b2bbe5e356b8c1f8041c979f505b3d3186e520a9/argon2_cffi_bindings-25.1.0.tar.gz", hash = "sha256:b957f3e6ea4d55d820e40ff76f450952807013d361a65d7f28acc0acbf29229d", size = 1783441, upload-time = "2025-07-30T10:02:05.147Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/60/97/3c0a35f46e52108d4707c44b95cfe2afcafc50800b5450c197454569b776/argon2_cffi_bindings-25.1.0-cp314-cp314t-macosx_10_13_universal2.whl", hash = "sha256:3d3f05610594151994ca9ccb3c771115bdb4daef161976a266f0dd8aa9996b8f", size = 54393, upload-time = "2025-07-30T10:01:40.97Z" },
+ { url = "https://files.pythonhosted.org/packages/9d/f4/98bbd6ee89febd4f212696f13c03ca302b8552e7dbf9c8efa11ea4a388c3/argon2_cffi_bindings-25.1.0-cp314-cp314t-macosx_10_13_x86_64.whl", hash = "sha256:8b8efee945193e667a396cbc7b4fb7d357297d6234d30a489905d96caabde56b", size = 29328, upload-time = "2025-07-30T10:01:41.916Z" },
+ { url = "https://files.pythonhosted.org/packages/43/24/90a01c0ef12ac91a6be05969f29944643bc1e5e461155ae6559befa8f00b/argon2_cffi_bindings-25.1.0-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:3c6702abc36bf3ccba3f802b799505def420a1b7039862014a65db3205967f5a", size = 31269, upload-time = "2025-07-30T10:01:42.716Z" },
+ { url = "https://files.pythonhosted.org/packages/d4/d3/942aa10782b2697eee7af5e12eeff5ebb325ccfb86dd8abda54174e377e4/argon2_cffi_bindings-25.1.0-cp314-cp314t-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:a1c70058c6ab1e352304ac7e3b52554daadacd8d453c1752e547c76e9c99ac44", size = 86558, upload-time = "2025-07-30T10:01:43.943Z" },
+ { url = "https://files.pythonhosted.org/packages/0d/82/b484f702fec5536e71836fc2dbc8c5267b3f6e78d2d539b4eaa6f0db8bf8/argon2_cffi_bindings-25.1.0-cp314-cp314t-manylinux_2_26_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:e2fd3bfbff3c5d74fef31a722f729bf93500910db650c925c2d6ef879a7e51cb", size = 92364, upload-time = "2025-07-30T10:01:44.887Z" },
+ { url = "https://files.pythonhosted.org/packages/c9/c1/a606ff83b3f1735f3759ad0f2cd9e038a0ad11a3de3b6c673aa41c24bb7b/argon2_cffi_bindings-25.1.0-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:c4f9665de60b1b0e99bcd6be4f17d90339698ce954cfd8d9cf4f91c995165a92", size = 85637, upload-time = "2025-07-30T10:01:46.225Z" },
+ { url = "https://files.pythonhosted.org/packages/44/b4/678503f12aceb0262f84fa201f6027ed77d71c5019ae03b399b97caa2f19/argon2_cffi_bindings-25.1.0-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:ba92837e4a9aa6a508c8d2d7883ed5a8f6c308c89a4790e1e447a220deb79a85", size = 91934, upload-time = "2025-07-30T10:01:47.203Z" },
+ { url = "https://files.pythonhosted.org/packages/f0/c7/f36bd08ef9bd9f0a9cff9428406651f5937ce27b6c5b07b92d41f91ae541/argon2_cffi_bindings-25.1.0-cp314-cp314t-win32.whl", hash = "sha256:84a461d4d84ae1295871329b346a97f68eade8c53b6ed9a7ca2d7467f3c8ff6f", size = 28158, upload-time = "2025-07-30T10:01:48.341Z" },
+ { url = "https://files.pythonhosted.org/packages/b3/80/0106a7448abb24a2c467bf7d527fe5413b7fdfa4ad6d6a96a43a62ef3988/argon2_cffi_bindings-25.1.0-cp314-cp314t-win_amd64.whl", hash = "sha256:b55aec3565b65f56455eebc9b9f34130440404f27fe21c3b375bf1ea4d8fbae6", size = 32597, upload-time = "2025-07-30T10:01:49.112Z" },
+ { url = "https://files.pythonhosted.org/packages/05/b8/d663c9caea07e9180b2cb662772865230715cbd573ba3b5e81793d580316/argon2_cffi_bindings-25.1.0-cp314-cp314t-win_arm64.whl", hash = "sha256:87c33a52407e4c41f3b70a9c2d3f6056d88b10dad7695be708c5021673f55623", size = 28231, upload-time = "2025-07-30T10:01:49.92Z" },
+ { url = "https://files.pythonhosted.org/packages/1d/57/96b8b9f93166147826da5f90376e784a10582dd39a393c99bb62cfcf52f0/argon2_cffi_bindings-25.1.0-cp39-abi3-macosx_10_9_universal2.whl", hash = "sha256:aecba1723ae35330a008418a91ea6cfcedf6d31e5fbaa056a166462ff066d500", size = 54121, upload-time = "2025-07-30T10:01:50.815Z" },
+ { url = "https://files.pythonhosted.org/packages/0a/08/a9bebdb2e0e602dde230bdde8021b29f71f7841bd54801bcfd514acb5dcf/argon2_cffi_bindings-25.1.0-cp39-abi3-macosx_10_9_x86_64.whl", hash = "sha256:2630b6240b495dfab90aebe159ff784d08ea999aa4b0d17efa734055a07d2f44", size = 29177, upload-time = "2025-07-30T10:01:51.681Z" },
+ { url = "https://files.pythonhosted.org/packages/b6/02/d297943bcacf05e4f2a94ab6f462831dc20158614e5d067c35d4e63b9acb/argon2_cffi_bindings-25.1.0-cp39-abi3-macosx_11_0_arm64.whl", hash = "sha256:7aef0c91e2c0fbca6fc68e7555aa60ef7008a739cbe045541e438373bc54d2b0", size = 31090, upload-time = "2025-07-30T10:01:53.184Z" },
+ { url = "https://files.pythonhosted.org/packages/c1/93/44365f3d75053e53893ec6d733e4a5e3147502663554b4d864587c7828a7/argon2_cffi_bindings-25.1.0-cp39-abi3-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:1e021e87faa76ae0d413b619fe2b65ab9a037f24c60a1e6cc43457ae20de6dc6", size = 81246, upload-time = "2025-07-30T10:01:54.145Z" },
+ { url = "https://files.pythonhosted.org/packages/09/52/94108adfdd6e2ddf58be64f959a0b9c7d4ef2fa71086c38356d22dc501ea/argon2_cffi_bindings-25.1.0-cp39-abi3-manylinux_2_26_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:d3e924cfc503018a714f94a49a149fdc0b644eaead5d1f089330399134fa028a", size = 87126, upload-time = "2025-07-30T10:01:55.074Z" },
+ { url = "https://files.pythonhosted.org/packages/72/70/7a2993a12b0ffa2a9271259b79cc616e2389ed1a4d93842fac5a1f923ffd/argon2_cffi_bindings-25.1.0-cp39-abi3-musllinux_1_2_aarch64.whl", hash = "sha256:c87b72589133f0346a1cb8d5ecca4b933e3c9b64656c9d175270a000e73b288d", size = 80343, upload-time = "2025-07-30T10:01:56.007Z" },
+ { url = "https://files.pythonhosted.org/packages/78/9a/4e5157d893ffc712b74dbd868c7f62365618266982b64accab26bab01edc/argon2_cffi_bindings-25.1.0-cp39-abi3-musllinux_1_2_x86_64.whl", hash = "sha256:1db89609c06afa1a214a69a462ea741cf735b29a57530478c06eb81dd403de99", size = 86777, upload-time = "2025-07-30T10:01:56.943Z" },
+ { url = "https://files.pythonhosted.org/packages/74/cd/15777dfde1c29d96de7f18edf4cc94c385646852e7c7b0320aa91ccca583/argon2_cffi_bindings-25.1.0-cp39-abi3-win32.whl", hash = "sha256:473bcb5f82924b1becbb637b63303ec8d10e84c8d241119419897a26116515d2", size = 27180, upload-time = "2025-07-30T10:01:57.759Z" },
+ { url = "https://files.pythonhosted.org/packages/e2/c6/a759ece8f1829d1f162261226fbfd2c6832b3ff7657384045286d2afa384/argon2_cffi_bindings-25.1.0-cp39-abi3-win_amd64.whl", hash = "sha256:a98cd7d17e9f7ce244c0803cad3c23a7d379c301ba618a5fa76a67d116618b98", size = 31715, upload-time = "2025-07-30T10:01:58.56Z" },
+ { url = "https://files.pythonhosted.org/packages/42/b9/f8d6fa329ab25128b7e98fd83a3cb34d9db5b059a9847eddb840a0af45dd/argon2_cffi_bindings-25.1.0-cp39-abi3-win_arm64.whl", hash = "sha256:b0fdbcf513833809c882823f98dc2f931cf659d9a1429616ac3adebb49f5db94", size = 27149, upload-time = "2025-07-30T10:01:59.329Z" },
+]
+
+[[package]]
+name = "arrow"
+version = "1.4.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "python-dateutil" },
+ { name = "tzdata" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/b9/33/032cdc44182491aa708d06a68b62434140d8c50820a087fac7af37703357/arrow-1.4.0.tar.gz", hash = "sha256:ed0cc050e98001b8779e84d461b0098c4ac597e88704a655582b21d116e526d7", size = 152931, upload-time = "2025-10-18T17:46:46.761Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/ed/c9/d7977eaacb9df673210491da99e6a247e93df98c715fc43fd136ce1d3d33/arrow-1.4.0-py3-none-any.whl", hash = "sha256:749f0769958ebdc79c173ff0b0670d59051a535fa26e8eba02953dc19eb43205", size = 68797, upload-time = "2025-10-18T17:46:45.663Z" },
+]
+
+[[package]]
+name = "asttokens"
+version = "3.0.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/be/a5/8e3f9b6771b0b408517c82d97aed8f2036509bc247d46114925e32fe33f0/asttokens-3.0.1.tar.gz", hash = "sha256:71a4ee5de0bde6a31d64f6b13f2293ac190344478f081c3d1bccfcf5eacb0cb7", size = 62308, upload-time = "2025-11-15T16:43:48.578Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/d2/39/e7eaf1799466a4aef85b6a4fe7bd175ad2b1c6345066aa33f1f58d4b18d0/asttokens-3.0.1-py3-none-any.whl", hash = "sha256:15a3ebc0f43c2d0a50eeafea25e19046c68398e487b9f1f5b517f7c0f40f976a", size = 27047, upload-time = "2025-11-15T16:43:16.109Z" },
+]
+
+[[package]]
+name = "async-lru"
+version = "2.0.5"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/b2/4d/71ec4d3939dc755264f680f6c2b4906423a304c3d18e96853f0a595dfe97/async_lru-2.0.5.tar.gz", hash = "sha256:481d52ccdd27275f42c43a928b4a50c3bfb2d67af4e78b170e3e0bb39c66e5bb", size = 10380, upload-time = "2025-03-16T17:25:36.919Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/03/49/d10027df9fce941cb8184e78a02857af36360d33e1721df81c5ed2179a1a/async_lru-2.0.5-py3-none-any.whl", hash = "sha256:ab95404d8d2605310d345932697371a5f40def0487c03d6d0ad9138de52c9943", size = 6069, upload-time = "2025-03-16T17:25:35.422Z" },
+]
+
+[[package]]
+name = "attrs"
+version = "25.4.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/6b/5c/685e6633917e101e5dcb62b9dd76946cbb57c26e133bae9e0cd36033c0a9/attrs-25.4.0.tar.gz", hash = "sha256:16d5969b87f0859ef33a48b35d55ac1be6e42ae49d5e853b597db70c35c57e11", size = 934251, upload-time = "2025-10-06T13:54:44.725Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/3a/2a/7cc015f5b9f5db42b7d48157e23356022889fc354a2813c15934b7cb5c0e/attrs-25.4.0-py3-none-any.whl", hash = "sha256:adcf7e2a1fb3b36ac48d97835bb6d8ade15b8dcce26aba8bf1d14847b57a3373", size = 67615, upload-time = "2025-10-06T13:54:43.17Z" },
+]
+
+[[package]]
+name = "babel"
+version = "2.17.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/7d/6b/d52e42361e1aa00709585ecc30b3f9684b3ab62530771402248b1b1d6240/babel-2.17.0.tar.gz", hash = "sha256:0c54cffb19f690cdcc52a3b50bcbf71e07a808d1c80d549f2459b9d2cf0afb9d", size = 9951852, upload-time = "2025-02-01T15:17:41.026Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/b7/b8/3fe70c75fe32afc4bb507f75563d39bc5642255d1d94f1f23604725780bf/babel-2.17.0-py3-none-any.whl", hash = "sha256:4d0b53093fdfb4b21c92b5213dba5a1b23885afa8383709427046b21c366e5f2", size = 10182537, upload-time = "2025-02-01T15:17:37.39Z" },
+]
+
+[[package]]
+name = "beautifulsoup4"
+version = "4.14.3"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "soupsieve" },
+ { name = "typing-extensions" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/c3/b0/1c6a16426d389813b48d95e26898aff79abbde42ad353958ad95cc8c9b21/beautifulsoup4-4.14.3.tar.gz", hash = "sha256:6292b1c5186d356bba669ef9f7f051757099565ad9ada5dd630bd9de5fa7fb86", size = 627737, upload-time = "2025-11-30T15:08:26.084Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/1a/39/47f9197bdd44df24d67ac8893641e16f386c984a0619ef2ee4c51fbbc019/beautifulsoup4-4.14.3-py3-none-any.whl", hash = "sha256:0918bfe44902e6ad8d57732ba310582e98da931428d231a5ecb9e7c703a735bb", size = 107721, upload-time = "2025-11-30T15:08:24.087Z" },
+]
+
+[[package]]
+name = "bleach"
+version = "6.3.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "webencodings" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/07/18/3c8523962314be6bf4c8989c79ad9531c825210dd13a8669f6b84336e8bd/bleach-6.3.0.tar.gz", hash = "sha256:6f3b91b1c0a02bb9a78b5a454c92506aa0fdf197e1d5e114d2e00c6f64306d22", size = 203533, upload-time = "2025-10-27T17:57:39.211Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/cd/3a/577b549de0cc09d95f11087ee63c739bba856cd3952697eec4c4bb91350a/bleach-6.3.0-py3-none-any.whl", hash = "sha256:fe10ec77c93ddf3d13a73b035abaac7a9f5e436513864ccdad516693213c65d6", size = 164437, upload-time = "2025-10-27T17:57:37.538Z" },
+]
+
+[package.optional-dependencies]
+css = [
+ { name = "tinycss2" },
+]
+
+[[package]]
+name = "boolean-py"
+version = "5.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/c4/cf/85379f13b76f3a69bca86b60237978af17d6aa0bc5998978c3b8cf05abb2/boolean_py-5.0.tar.gz", hash = "sha256:60cbc4bad079753721d32649545505362c754e121570ada4658b852a3a318d95", size = 37047, upload-time = "2025-04-03T10:39:49.734Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/e5/ca/78d423b324b8d77900030fa59c4aa9054261ef0925631cd2501dd015b7b7/boolean_py-5.0-py3-none-any.whl", hash = "sha256:ef28a70bd43115208441b53a045d1549e2f0ec6e3d08a9d142cbc41c1938e8d9", size = 26577, upload-time = "2025-04-03T10:39:48.449Z" },
+]
+
+[[package]]
+name = "braceexpand"
+version = "0.1.7"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/54/93/badd4f5ccf25209f3fef2573073da9fe4a45a3da99fca2f800f942130c0f/braceexpand-0.1.7.tar.gz", hash = "sha256:e6e539bd20eaea53547472ff94f4fb5c3d3bf9d0a89388c4b56663aba765f705", size = 7777, upload-time = "2021-05-07T13:49:07.323Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/fa/93/e8c04e80e82391a6e51f218ca49720f64236bc824e92152a2633b74cf7ab/braceexpand-0.1.7-py2.py3-none-any.whl", hash = "sha256:91332d53de7828103dcae5773fb43bc34950b0c8160e35e0f44c4427a3b85014", size = 5923, upload-time = "2021-05-07T13:49:05.146Z" },
+]
+
+[[package]]
+name = "certifi"
+version = "2025.11.12"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/a2/8c/58f469717fa48465e4a50c014a0400602d3c437d7c0c468e17ada824da3a/certifi-2025.11.12.tar.gz", hash = "sha256:d8ab5478f2ecd78af242878415affce761ca6bc54a22a27e026d7c25357c3316", size = 160538, upload-time = "2025-11-12T02:54:51.517Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/70/7d/9bc192684cea499815ff478dfcdc13835ddf401365057044fb721ec6bddb/certifi-2025.11.12-py3-none-any.whl", hash = "sha256:97de8790030bbd5c2d96b7ec782fc2f7820ef8dba6db909ccf95449f2d062d4b", size = 159438, upload-time = "2025-11-12T02:54:49.735Z" },
+]
+
+[[package]]
+name = "cffi"
+version = "2.0.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "pycparser", marker = "implementation_name != 'PyPy'" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/eb/56/b1ba7935a17738ae8453301356628e8147c79dbb825bcbc73dc7401f9846/cffi-2.0.0.tar.gz", hash = "sha256:44d1b5909021139fe36001ae048dbdde8214afa20200eda0f64c068cac5d5529", size = 523588, upload-time = "2025-09-08T23:24:04.541Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/ea/47/4f61023ea636104d4f16ab488e268b93008c3d0bb76893b1b31db1f96802/cffi-2.0.0-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:6d02d6655b0e54f54c4ef0b94eb6be0607b70853c45ce98bd278dc7de718be5d", size = 185271, upload-time = "2025-09-08T23:22:44.795Z" },
+ { url = "https://files.pythonhosted.org/packages/df/a2/781b623f57358e360d62cdd7a8c681f074a71d445418a776eef0aadb4ab4/cffi-2.0.0-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:8eca2a813c1cb7ad4fb74d368c2ffbbb4789d377ee5bb8df98373c2cc0dee76c", size = 181048, upload-time = "2025-09-08T23:22:45.938Z" },
+ { url = "https://files.pythonhosted.org/packages/ff/df/a4f0fbd47331ceeba3d37c2e51e9dfc9722498becbeec2bd8bc856c9538a/cffi-2.0.0-cp312-cp312-manylinux1_i686.manylinux2014_i686.manylinux_2_17_i686.manylinux_2_5_i686.whl", hash = "sha256:21d1152871b019407d8ac3985f6775c079416c282e431a4da6afe7aefd2bccbe", size = 212529, upload-time = "2025-09-08T23:22:47.349Z" },
+ { url = "https://files.pythonhosted.org/packages/d5/72/12b5f8d3865bf0f87cf1404d8c374e7487dcf097a1c91c436e72e6badd83/cffi-2.0.0-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.whl", hash = "sha256:b21e08af67b8a103c71a250401c78d5e0893beff75e28c53c98f4de42f774062", size = 220097, upload-time = "2025-09-08T23:22:48.677Z" },
+ { url = "https://files.pythonhosted.org/packages/c2/95/7a135d52a50dfa7c882ab0ac17e8dc11cec9d55d2c18dda414c051c5e69e/cffi-2.0.0-cp312-cp312-manylinux2014_ppc64le.manylinux_2_17_ppc64le.whl", hash = "sha256:1e3a615586f05fc4065a8b22b8152f0c1b00cdbc60596d187c2a74f9e3036e4e", size = 207983, upload-time = "2025-09-08T23:22:50.06Z" },
+ { url = "https://files.pythonhosted.org/packages/3a/c8/15cb9ada8895957ea171c62dc78ff3e99159ee7adb13c0123c001a2546c1/cffi-2.0.0-cp312-cp312-manylinux2014_s390x.manylinux_2_17_s390x.whl", hash = "sha256:81afed14892743bbe14dacb9e36d9e0e504cd204e0b165062c488942b9718037", size = 206519, upload-time = "2025-09-08T23:22:51.364Z" },
+ { url = "https://files.pythonhosted.org/packages/78/2d/7fa73dfa841b5ac06c7b8855cfc18622132e365f5b81d02230333ff26e9e/cffi-2.0.0-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:3e17ed538242334bf70832644a32a7aae3d83b57567f9fd60a26257e992b79ba", size = 219572, upload-time = "2025-09-08T23:22:52.902Z" },
+ { url = "https://files.pythonhosted.org/packages/07/e0/267e57e387b4ca276b90f0434ff88b2c2241ad72b16d31836adddfd6031b/cffi-2.0.0-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:3925dd22fa2b7699ed2617149842d2e6adde22b262fcbfada50e3d195e4b3a94", size = 222963, upload-time = "2025-09-08T23:22:54.518Z" },
+ { url = "https://files.pythonhosted.org/packages/b6/75/1f2747525e06f53efbd878f4d03bac5b859cbc11c633d0fb81432d98a795/cffi-2.0.0-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:2c8f814d84194c9ea681642fd164267891702542f028a15fc97d4674b6206187", size = 221361, upload-time = "2025-09-08T23:22:55.867Z" },
+ { url = "https://files.pythonhosted.org/packages/7b/2b/2b6435f76bfeb6bbf055596976da087377ede68df465419d192acf00c437/cffi-2.0.0-cp312-cp312-win32.whl", hash = "sha256:da902562c3e9c550df360bfa53c035b2f241fed6d9aef119048073680ace4a18", size = 172932, upload-time = "2025-09-08T23:22:57.188Z" },
+ { url = "https://files.pythonhosted.org/packages/f8/ed/13bd4418627013bec4ed6e54283b1959cf6db888048c7cf4b4c3b5b36002/cffi-2.0.0-cp312-cp312-win_amd64.whl", hash = "sha256:da68248800ad6320861f129cd9c1bf96ca849a2771a59e0344e88681905916f5", size = 183557, upload-time = "2025-09-08T23:22:58.351Z" },
+ { url = "https://files.pythonhosted.org/packages/95/31/9f7f93ad2f8eff1dbc1c3656d7ca5bfd8fb52c9d786b4dcf19b2d02217fa/cffi-2.0.0-cp312-cp312-win_arm64.whl", hash = "sha256:4671d9dd5ec934cb9a73e7ee9676f9362aba54f7f34910956b84d727b0d73fb6", size = 177762, upload-time = "2025-09-08T23:22:59.668Z" },
+ { url = "https://files.pythonhosted.org/packages/4b/8d/a0a47a0c9e413a658623d014e91e74a50cdd2c423f7ccfd44086ef767f90/cffi-2.0.0-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:00bdf7acc5f795150faa6957054fbbca2439db2f775ce831222b66f192f03beb", size = 185230, upload-time = "2025-09-08T23:23:00.879Z" },
+ { url = "https://files.pythonhosted.org/packages/4a/d2/a6c0296814556c68ee32009d9c2ad4f85f2707cdecfd7727951ec228005d/cffi-2.0.0-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:45d5e886156860dc35862657e1494b9bae8dfa63bf56796f2fb56e1679fc0bca", size = 181043, upload-time = "2025-09-08T23:23:02.231Z" },
+ { url = "https://files.pythonhosted.org/packages/b0/1e/d22cc63332bd59b06481ceaac49d6c507598642e2230f201649058a7e704/cffi-2.0.0-cp313-cp313-manylinux1_i686.manylinux2014_i686.manylinux_2_17_i686.manylinux_2_5_i686.whl", hash = "sha256:07b271772c100085dd28b74fa0cd81c8fb1a3ba18b21e03d7c27f3436a10606b", size = 212446, upload-time = "2025-09-08T23:23:03.472Z" },
+ { url = "https://files.pythonhosted.org/packages/a9/f5/a2c23eb03b61a0b8747f211eb716446c826ad66818ddc7810cc2cc19b3f2/cffi-2.0.0-cp313-cp313-manylinux2014_aarch64.manylinux_2_17_aarch64.whl", hash = "sha256:d48a880098c96020b02d5a1f7d9251308510ce8858940e6fa99ece33f610838b", size = 220101, upload-time = "2025-09-08T23:23:04.792Z" },
+ { url = "https://files.pythonhosted.org/packages/f2/7f/e6647792fc5850d634695bc0e6ab4111ae88e89981d35ac269956605feba/cffi-2.0.0-cp313-cp313-manylinux2014_ppc64le.manylinux_2_17_ppc64le.whl", hash = "sha256:f93fd8e5c8c0a4aa1f424d6173f14a892044054871c771f8566e4008eaa359d2", size = 207948, upload-time = "2025-09-08T23:23:06.127Z" },
+ { url = "https://files.pythonhosted.org/packages/cb/1e/a5a1bd6f1fb30f22573f76533de12a00bf274abcdc55c8edab639078abb6/cffi-2.0.0-cp313-cp313-manylinux2014_s390x.manylinux_2_17_s390x.whl", hash = "sha256:dd4f05f54a52fb558f1ba9f528228066954fee3ebe629fc1660d874d040ae5a3", size = 206422, upload-time = "2025-09-08T23:23:07.753Z" },
+ { url = "https://files.pythonhosted.org/packages/98/df/0a1755e750013a2081e863e7cd37e0cdd02664372c754e5560099eb7aa44/cffi-2.0.0-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:c8d3b5532fc71b7a77c09192b4a5a200ea992702734a2e9279a37f2478236f26", size = 219499, upload-time = "2025-09-08T23:23:09.648Z" },
+ { url = "https://files.pythonhosted.org/packages/50/e1/a969e687fcf9ea58e6e2a928ad5e2dd88cc12f6f0ab477e9971f2309b57c/cffi-2.0.0-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:d9b29c1f0ae438d5ee9acb31cadee00a58c46cc9c0b2f9038c6b0b3470877a8c", size = 222928, upload-time = "2025-09-08T23:23:10.928Z" },
+ { url = "https://files.pythonhosted.org/packages/36/54/0362578dd2c9e557a28ac77698ed67323ed5b9775ca9d3fe73fe191bb5d8/cffi-2.0.0-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:6d50360be4546678fc1b79ffe7a66265e28667840010348dd69a314145807a1b", size = 221302, upload-time = "2025-09-08T23:23:12.42Z" },
+ { url = "https://files.pythonhosted.org/packages/eb/6d/bf9bda840d5f1dfdbf0feca87fbdb64a918a69bca42cfa0ba7b137c48cb8/cffi-2.0.0-cp313-cp313-win32.whl", hash = "sha256:74a03b9698e198d47562765773b4a8309919089150a0bb17d829ad7b44b60d27", size = 172909, upload-time = "2025-09-08T23:23:14.32Z" },
+ { url = "https://files.pythonhosted.org/packages/37/18/6519e1ee6f5a1e579e04b9ddb6f1676c17368a7aba48299c3759bbc3c8b3/cffi-2.0.0-cp313-cp313-win_amd64.whl", hash = "sha256:19f705ada2530c1167abacb171925dd886168931e0a7b78f5bffcae5c6b5be75", size = 183402, upload-time = "2025-09-08T23:23:15.535Z" },
+ { url = "https://files.pythonhosted.org/packages/cb/0e/02ceeec9a7d6ee63bb596121c2c8e9b3a9e150936f4fbef6ca1943e6137c/cffi-2.0.0-cp313-cp313-win_arm64.whl", hash = "sha256:256f80b80ca3853f90c21b23ee78cd008713787b1b1e93eae9f3d6a7134abd91", size = 177780, upload-time = "2025-09-08T23:23:16.761Z" },
+ { url = "https://files.pythonhosted.org/packages/92/c4/3ce07396253a83250ee98564f8d7e9789fab8e58858f35d07a9a2c78de9f/cffi-2.0.0-cp314-cp314-macosx_10_13_x86_64.whl", hash = "sha256:fc33c5141b55ed366cfaad382df24fe7dcbc686de5be719b207bb248e3053dc5", size = 185320, upload-time = "2025-09-08T23:23:18.087Z" },
+ { url = "https://files.pythonhosted.org/packages/59/dd/27e9fa567a23931c838c6b02d0764611c62290062a6d4e8ff7863daf9730/cffi-2.0.0-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:c654de545946e0db659b3400168c9ad31b5d29593291482c43e3564effbcee13", size = 181487, upload-time = "2025-09-08T23:23:19.622Z" },
+ { url = "https://files.pythonhosted.org/packages/d6/43/0e822876f87ea8a4ef95442c3d766a06a51fc5298823f884ef87aaad168c/cffi-2.0.0-cp314-cp314-manylinux2014_aarch64.manylinux_2_17_aarch64.whl", hash = "sha256:24b6f81f1983e6df8db3adc38562c83f7d4a0c36162885ec7f7b77c7dcbec97b", size = 220049, upload-time = "2025-09-08T23:23:20.853Z" },
+ { url = "https://files.pythonhosted.org/packages/b4/89/76799151d9c2d2d1ead63c2429da9ea9d7aac304603de0c6e8764e6e8e70/cffi-2.0.0-cp314-cp314-manylinux2014_ppc64le.manylinux_2_17_ppc64le.whl", hash = "sha256:12873ca6cb9b0f0d3a0da705d6086fe911591737a59f28b7936bdfed27c0d47c", size = 207793, upload-time = "2025-09-08T23:23:22.08Z" },
+ { url = "https://files.pythonhosted.org/packages/bb/dd/3465b14bb9e24ee24cb88c9e3730f6de63111fffe513492bf8c808a3547e/cffi-2.0.0-cp314-cp314-manylinux2014_s390x.manylinux_2_17_s390x.whl", hash = "sha256:d9b97165e8aed9272a6bb17c01e3cc5871a594a446ebedc996e2397a1c1ea8ef", size = 206300, upload-time = "2025-09-08T23:23:23.314Z" },
+ { url = "https://files.pythonhosted.org/packages/47/d9/d83e293854571c877a92da46fdec39158f8d7e68da75bf73581225d28e90/cffi-2.0.0-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:afb8db5439b81cf9c9d0c80404b60c3cc9c3add93e114dcae767f1477cb53775", size = 219244, upload-time = "2025-09-08T23:23:24.541Z" },
+ { url = "https://files.pythonhosted.org/packages/2b/0f/1f177e3683aead2bb00f7679a16451d302c436b5cbf2505f0ea8146ef59e/cffi-2.0.0-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:737fe7d37e1a1bffe70bd5754ea763a62a066dc5913ca57e957824b72a85e205", size = 222828, upload-time = "2025-09-08T23:23:26.143Z" },
+ { url = "https://files.pythonhosted.org/packages/c6/0f/cafacebd4b040e3119dcb32fed8bdef8dfe94da653155f9d0b9dc660166e/cffi-2.0.0-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:38100abb9d1b1435bc4cc340bb4489635dc2f0da7456590877030c9b3d40b0c1", size = 220926, upload-time = "2025-09-08T23:23:27.873Z" },
+ { url = "https://files.pythonhosted.org/packages/3e/aa/df335faa45b395396fcbc03de2dfcab242cd61a9900e914fe682a59170b1/cffi-2.0.0-cp314-cp314-win32.whl", hash = "sha256:087067fa8953339c723661eda6b54bc98c5625757ea62e95eb4898ad5e776e9f", size = 175328, upload-time = "2025-09-08T23:23:44.61Z" },
+ { url = "https://files.pythonhosted.org/packages/bb/92/882c2d30831744296ce713f0feb4c1cd30f346ef747b530b5318715cc367/cffi-2.0.0-cp314-cp314-win_amd64.whl", hash = "sha256:203a48d1fb583fc7d78a4c6655692963b860a417c0528492a6bc21f1aaefab25", size = 185650, upload-time = "2025-09-08T23:23:45.848Z" },
+ { url = "https://files.pythonhosted.org/packages/9f/2c/98ece204b9d35a7366b5b2c6539c350313ca13932143e79dc133ba757104/cffi-2.0.0-cp314-cp314-win_arm64.whl", hash = "sha256:dbd5c7a25a7cb98f5ca55d258b103a2054f859a46ae11aaf23134f9cc0d356ad", size = 180687, upload-time = "2025-09-08T23:23:47.105Z" },
+ { url = "https://files.pythonhosted.org/packages/3e/61/c768e4d548bfa607abcda77423448df8c471f25dbe64fb2ef6d555eae006/cffi-2.0.0-cp314-cp314t-macosx_10_13_x86_64.whl", hash = "sha256:9a67fc9e8eb39039280526379fb3a70023d77caec1852002b4da7e8b270c4dd9", size = 188773, upload-time = "2025-09-08T23:23:29.347Z" },
+ { url = "https://files.pythonhosted.org/packages/2c/ea/5f76bce7cf6fcd0ab1a1058b5af899bfbef198bea4d5686da88471ea0336/cffi-2.0.0-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:7a66c7204d8869299919db4d5069a82f1561581af12b11b3c9f48c584eb8743d", size = 185013, upload-time = "2025-09-08T23:23:30.63Z" },
+ { url = "https://files.pythonhosted.org/packages/be/b4/c56878d0d1755cf9caa54ba71e5d049479c52f9e4afc230f06822162ab2f/cffi-2.0.0-cp314-cp314t-manylinux2014_aarch64.manylinux_2_17_aarch64.whl", hash = "sha256:7cc09976e8b56f8cebd752f7113ad07752461f48a58cbba644139015ac24954c", size = 221593, upload-time = "2025-09-08T23:23:31.91Z" },
+ { url = "https://files.pythonhosted.org/packages/e0/0d/eb704606dfe8033e7128df5e90fee946bbcb64a04fcdaa97321309004000/cffi-2.0.0-cp314-cp314t-manylinux2014_ppc64le.manylinux_2_17_ppc64le.whl", hash = "sha256:92b68146a71df78564e4ef48af17551a5ddd142e5190cdf2c5624d0c3ff5b2e8", size = 209354, upload-time = "2025-09-08T23:23:33.214Z" },
+ { url = "https://files.pythonhosted.org/packages/d8/19/3c435d727b368ca475fb8742ab97c9cb13a0de600ce86f62eab7fa3eea60/cffi-2.0.0-cp314-cp314t-manylinux2014_s390x.manylinux_2_17_s390x.whl", hash = "sha256:b1e74d11748e7e98e2f426ab176d4ed720a64412b6a15054378afdb71e0f37dc", size = 208480, upload-time = "2025-09-08T23:23:34.495Z" },
+ { url = "https://files.pythonhosted.org/packages/d0/44/681604464ed9541673e486521497406fadcc15b5217c3e326b061696899a/cffi-2.0.0-cp314-cp314t-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:28a3a209b96630bca57cce802da70c266eb08c6e97e5afd61a75611ee6c64592", size = 221584, upload-time = "2025-09-08T23:23:36.096Z" },
+ { url = "https://files.pythonhosted.org/packages/25/8e/342a504ff018a2825d395d44d63a767dd8ebc927ebda557fecdaca3ac33a/cffi-2.0.0-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:7553fb2090d71822f02c629afe6042c299edf91ba1bf94951165613553984512", size = 224443, upload-time = "2025-09-08T23:23:37.328Z" },
+ { url = "https://files.pythonhosted.org/packages/e1/5e/b666bacbbc60fbf415ba9988324a132c9a7a0448a9a8f125074671c0f2c3/cffi-2.0.0-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:6c6c373cfc5c83a975506110d17457138c8c63016b563cc9ed6e056a82f13ce4", size = 223437, upload-time = "2025-09-08T23:23:38.945Z" },
+ { url = "https://files.pythonhosted.org/packages/a0/1d/ec1a60bd1a10daa292d3cd6bb0b359a81607154fb8165f3ec95fe003b85c/cffi-2.0.0-cp314-cp314t-win32.whl", hash = "sha256:1fc9ea04857caf665289b7a75923f2c6ed559b8298a1b8c49e59f7dd95c8481e", size = 180487, upload-time = "2025-09-08T23:23:40.423Z" },
+ { url = "https://files.pythonhosted.org/packages/bf/41/4c1168c74fac325c0c8156f04b6749c8b6a8f405bbf91413ba088359f60d/cffi-2.0.0-cp314-cp314t-win_amd64.whl", hash = "sha256:d68b6cef7827e8641e8ef16f4494edda8b36104d79773a334beaa1e3521430f6", size = 191726, upload-time = "2025-09-08T23:23:41.742Z" },
+ { url = "https://files.pythonhosted.org/packages/ae/3a/dbeec9d1ee0844c679f6bb5d6ad4e9f198b1224f4e7a32825f47f6192b0c/cffi-2.0.0-cp314-cp314t-win_arm64.whl", hash = "sha256:0a1527a803f0a659de1af2e1fd700213caba79377e27e4693648c2923da066f9", size = 184195, upload-time = "2025-09-08T23:23:43.004Z" },
+]
+
+[[package]]
+name = "charset-normalizer"
+version = "3.4.4"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/13/69/33ddede1939fdd074bce5434295f38fae7136463422fe4fd3e0e89b98062/charset_normalizer-3.4.4.tar.gz", hash = "sha256:94537985111c35f28720e43603b8e7b43a6ecfb2ce1d3058bbe955b73404e21a", size = 129418, upload-time = "2025-10-14T04:42:32.879Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/f3/85/1637cd4af66fa687396e757dec650f28025f2a2f5a5531a3208dc0ec43f2/charset_normalizer-3.4.4-cp312-cp312-macosx_10_13_universal2.whl", hash = "sha256:0a98e6759f854bd25a58a73fa88833fba3b7c491169f86ce1180c948ab3fd394", size = 208425, upload-time = "2025-10-14T04:40:53.353Z" },
+ { url = "https://files.pythonhosted.org/packages/9d/6a/04130023fef2a0d9c62d0bae2649b69f7b7d8d24ea5536feef50551029df/charset_normalizer-3.4.4-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:b5b290ccc2a263e8d185130284f8501e3e36c5e02750fc6b6bdeb2e9e96f1e25", size = 148162, upload-time = "2025-10-14T04:40:54.558Z" },
+ { url = "https://files.pythonhosted.org/packages/78/29/62328d79aa60da22c9e0b9a66539feae06ca0f5a4171ac4f7dc285b83688/charset_normalizer-3.4.4-cp312-cp312-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:74bb723680f9f7a6234dcf67aea57e708ec1fbdf5699fb91dfd6f511b0a320ef", size = 144558, upload-time = "2025-10-14T04:40:55.677Z" },
+ { url = "https://files.pythonhosted.org/packages/86/bb/b32194a4bf15b88403537c2e120b817c61cd4ecffa9b6876e941c3ee38fe/charset_normalizer-3.4.4-cp312-cp312-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:f1e34719c6ed0b92f418c7c780480b26b5d9c50349e9a9af7d76bf757530350d", size = 161497, upload-time = "2025-10-14T04:40:57.217Z" },
+ { url = "https://files.pythonhosted.org/packages/19/89/a54c82b253d5b9b111dc74aca196ba5ccfcca8242d0fb64146d4d3183ff1/charset_normalizer-3.4.4-cp312-cp312-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:2437418e20515acec67d86e12bf70056a33abdacb5cb1655042f6538d6b085a8", size = 159240, upload-time = "2025-10-14T04:40:58.358Z" },
+ { url = "https://files.pythonhosted.org/packages/c0/10/d20b513afe03acc89ec33948320a5544d31f21b05368436d580dec4e234d/charset_normalizer-3.4.4-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:11d694519d7f29d6cd09f6ac70028dba10f92f6cdd059096db198c283794ac86", size = 153471, upload-time = "2025-10-14T04:40:59.468Z" },
+ { url = "https://files.pythonhosted.org/packages/61/fa/fbf177b55bdd727010f9c0a3c49eefa1d10f960e5f09d1d887bf93c2e698/charset_normalizer-3.4.4-cp312-cp312-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:ac1c4a689edcc530fc9d9aa11f5774b9e2f33f9a0c6a57864e90908f5208d30a", size = 150864, upload-time = "2025-10-14T04:41:00.623Z" },
+ { url = "https://files.pythonhosted.org/packages/05/12/9fbc6a4d39c0198adeebbde20b619790e9236557ca59fc40e0e3cebe6f40/charset_normalizer-3.4.4-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:21d142cc6c0ec30d2efee5068ca36c128a30b0f2c53c1c07bd78cb6bc1d3be5f", size = 150647, upload-time = "2025-10-14T04:41:01.754Z" },
+ { url = "https://files.pythonhosted.org/packages/ad/1f/6a9a593d52e3e8c5d2b167daf8c6b968808efb57ef4c210acb907c365bc4/charset_normalizer-3.4.4-cp312-cp312-musllinux_1_2_armv7l.whl", hash = "sha256:5dbe56a36425d26d6cfb40ce79c314a2e4dd6211d51d6d2191c00bed34f354cc", size = 145110, upload-time = "2025-10-14T04:41:03.231Z" },
+ { url = "https://files.pythonhosted.org/packages/30/42/9a52c609e72471b0fc54386dc63c3781a387bb4fe61c20231a4ebcd58bdd/charset_normalizer-3.4.4-cp312-cp312-musllinux_1_2_ppc64le.whl", hash = "sha256:5bfbb1b9acf3334612667b61bd3002196fe2a1eb4dd74d247e0f2a4d50ec9bbf", size = 162839, upload-time = "2025-10-14T04:41:04.715Z" },
+ { url = "https://files.pythonhosted.org/packages/c4/5b/c0682bbf9f11597073052628ddd38344a3d673fda35a36773f7d19344b23/charset_normalizer-3.4.4-cp312-cp312-musllinux_1_2_riscv64.whl", hash = "sha256:d055ec1e26e441f6187acf818b73564e6e6282709e9bcb5b63f5b23068356a15", size = 150667, upload-time = "2025-10-14T04:41:05.827Z" },
+ { url = "https://files.pythonhosted.org/packages/e4/24/a41afeab6f990cf2daf6cb8c67419b63b48cf518e4f56022230840c9bfb2/charset_normalizer-3.4.4-cp312-cp312-musllinux_1_2_s390x.whl", hash = "sha256:af2d8c67d8e573d6de5bc30cdb27e9b95e49115cd9baad5ddbd1a6207aaa82a9", size = 160535, upload-time = "2025-10-14T04:41:06.938Z" },
+ { url = "https://files.pythonhosted.org/packages/2a/e5/6a4ce77ed243c4a50a1fecca6aaaab419628c818a49434be428fe24c9957/charset_normalizer-3.4.4-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:780236ac706e66881f3b7f2f32dfe90507a09e67d1d454c762cf642e6e1586e0", size = 154816, upload-time = "2025-10-14T04:41:08.101Z" },
+ { url = "https://files.pythonhosted.org/packages/a8/ef/89297262b8092b312d29cdb2517cb1237e51db8ecef2e9af5edbe7b683b1/charset_normalizer-3.4.4-cp312-cp312-win32.whl", hash = "sha256:5833d2c39d8896e4e19b689ffc198f08ea58116bee26dea51e362ecc7cd3ed26", size = 99694, upload-time = "2025-10-14T04:41:09.23Z" },
+ { url = "https://files.pythonhosted.org/packages/3d/2d/1e5ed9dd3b3803994c155cd9aacb60c82c331bad84daf75bcb9c91b3295e/charset_normalizer-3.4.4-cp312-cp312-win_amd64.whl", hash = "sha256:a79cfe37875f822425b89a82333404539ae63dbdddf97f84dcbc3d339aae9525", size = 107131, upload-time = "2025-10-14T04:41:10.467Z" },
+ { url = "https://files.pythonhosted.org/packages/d0/d9/0ed4c7098a861482a7b6a95603edce4c0d9db2311af23da1fb2b75ec26fc/charset_normalizer-3.4.4-cp312-cp312-win_arm64.whl", hash = "sha256:376bec83a63b8021bb5c8ea75e21c4ccb86e7e45ca4eb81146091b56599b80c3", size = 100390, upload-time = "2025-10-14T04:41:11.915Z" },
+ { url = "https://files.pythonhosted.org/packages/97/45/4b3a1239bbacd321068ea6e7ac28875b03ab8bc0aa0966452db17cd36714/charset_normalizer-3.4.4-cp313-cp313-macosx_10_13_universal2.whl", hash = "sha256:e1f185f86a6f3403aa2420e815904c67b2f9ebc443f045edd0de921108345794", size = 208091, upload-time = "2025-10-14T04:41:13.346Z" },
+ { url = "https://files.pythonhosted.org/packages/7d/62/73a6d7450829655a35bb88a88fca7d736f9882a27eacdca2c6d505b57e2e/charset_normalizer-3.4.4-cp313-cp313-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:6b39f987ae8ccdf0d2642338faf2abb1862340facc796048b604ef14919e55ed", size = 147936, upload-time = "2025-10-14T04:41:14.461Z" },
+ { url = "https://files.pythonhosted.org/packages/89/c5/adb8c8b3d6625bef6d88b251bbb0d95f8205831b987631ab0c8bb5d937c2/charset_normalizer-3.4.4-cp313-cp313-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:3162d5d8ce1bb98dd51af660f2121c55d0fa541b46dff7bb9b9f86ea1d87de72", size = 144180, upload-time = "2025-10-14T04:41:15.588Z" },
+ { url = "https://files.pythonhosted.org/packages/91/ed/9706e4070682d1cc219050b6048bfd293ccf67b3d4f5a4f39207453d4b99/charset_normalizer-3.4.4-cp313-cp313-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:81d5eb2a312700f4ecaa977a8235b634ce853200e828fbadf3a9c50bab278328", size = 161346, upload-time = "2025-10-14T04:41:16.738Z" },
+ { url = "https://files.pythonhosted.org/packages/d5/0d/031f0d95e4972901a2f6f09ef055751805ff541511dc1252ba3ca1f80cf5/charset_normalizer-3.4.4-cp313-cp313-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:5bd2293095d766545ec1a8f612559f6b40abc0eb18bb2f5d1171872d34036ede", size = 158874, upload-time = "2025-10-14T04:41:17.923Z" },
+ { url = "https://files.pythonhosted.org/packages/f5/83/6ab5883f57c9c801ce5e5677242328aa45592be8a00644310a008d04f922/charset_normalizer-3.4.4-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:a8a8b89589086a25749f471e6a900d3f662d1d3b6e2e59dcecf787b1cc3a1894", size = 153076, upload-time = "2025-10-14T04:41:19.106Z" },
+ { url = "https://files.pythonhosted.org/packages/75/1e/5ff781ddf5260e387d6419959ee89ef13878229732732ee73cdae01800f2/charset_normalizer-3.4.4-cp313-cp313-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:bc7637e2f80d8530ee4a78e878bce464f70087ce73cf7c1caf142416923b98f1", size = 150601, upload-time = "2025-10-14T04:41:20.245Z" },
+ { url = "https://files.pythonhosted.org/packages/d7/57/71be810965493d3510a6ca79b90c19e48696fb1ff964da319334b12677f0/charset_normalizer-3.4.4-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:f8bf04158c6b607d747e93949aa60618b61312fe647a6369f88ce2ff16043490", size = 150376, upload-time = "2025-10-14T04:41:21.398Z" },
+ { url = "https://files.pythonhosted.org/packages/e5/d5/c3d057a78c181d007014feb7e9f2e65905a6c4ef182c0ddf0de2924edd65/charset_normalizer-3.4.4-cp313-cp313-musllinux_1_2_armv7l.whl", hash = "sha256:554af85e960429cf30784dd47447d5125aaa3b99a6f0683589dbd27e2f45da44", size = 144825, upload-time = "2025-10-14T04:41:22.583Z" },
+ { url = "https://files.pythonhosted.org/packages/e6/8c/d0406294828d4976f275ffbe66f00266c4b3136b7506941d87c00cab5272/charset_normalizer-3.4.4-cp313-cp313-musllinux_1_2_ppc64le.whl", hash = "sha256:74018750915ee7ad843a774364e13a3db91682f26142baddf775342c3f5b1133", size = 162583, upload-time = "2025-10-14T04:41:23.754Z" },
+ { url = "https://files.pythonhosted.org/packages/d7/24/e2aa1f18c8f15c4c0e932d9287b8609dd30ad56dbe41d926bd846e22fb8d/charset_normalizer-3.4.4-cp313-cp313-musllinux_1_2_riscv64.whl", hash = "sha256:c0463276121fdee9c49b98908b3a89c39be45d86d1dbaa22957e38f6321d4ce3", size = 150366, upload-time = "2025-10-14T04:41:25.27Z" },
+ { url = "https://files.pythonhosted.org/packages/e4/5b/1e6160c7739aad1e2df054300cc618b06bf784a7a164b0f238360721ab86/charset_normalizer-3.4.4-cp313-cp313-musllinux_1_2_s390x.whl", hash = "sha256:362d61fd13843997c1c446760ef36f240cf81d3ebf74ac62652aebaf7838561e", size = 160300, upload-time = "2025-10-14T04:41:26.725Z" },
+ { url = "https://files.pythonhosted.org/packages/7a/10/f882167cd207fbdd743e55534d5d9620e095089d176d55cb22d5322f2afd/charset_normalizer-3.4.4-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:9a26f18905b8dd5d685d6d07b0cdf98a79f3c7a918906af7cc143ea2e164c8bc", size = 154465, upload-time = "2025-10-14T04:41:28.322Z" },
+ { url = "https://files.pythonhosted.org/packages/89/66/c7a9e1b7429be72123441bfdbaf2bc13faab3f90b933f664db506dea5915/charset_normalizer-3.4.4-cp313-cp313-win32.whl", hash = "sha256:9b35f4c90079ff2e2edc5b26c0c77925e5d2d255c42c74fdb70fb49b172726ac", size = 99404, upload-time = "2025-10-14T04:41:29.95Z" },
+ { url = "https://files.pythonhosted.org/packages/c4/26/b9924fa27db384bdcd97ab83b4f0a8058d96ad9626ead570674d5e737d90/charset_normalizer-3.4.4-cp313-cp313-win_amd64.whl", hash = "sha256:b435cba5f4f750aa6c0a0d92c541fb79f69a387c91e61f1795227e4ed9cece14", size = 107092, upload-time = "2025-10-14T04:41:31.188Z" },
+ { url = "https://files.pythonhosted.org/packages/af/8f/3ed4bfa0c0c72a7ca17f0380cd9e4dd842b09f664e780c13cff1dcf2ef1b/charset_normalizer-3.4.4-cp313-cp313-win_arm64.whl", hash = "sha256:542d2cee80be6f80247095cc36c418f7bddd14f4a6de45af91dfad36d817bba2", size = 100408, upload-time = "2025-10-14T04:41:32.624Z" },
+ { url = "https://files.pythonhosted.org/packages/2a/35/7051599bd493e62411d6ede36fd5af83a38f37c4767b92884df7301db25d/charset_normalizer-3.4.4-cp314-cp314-macosx_10_13_universal2.whl", hash = "sha256:da3326d9e65ef63a817ecbcc0df6e94463713b754fe293eaa03da99befb9a5bd", size = 207746, upload-time = "2025-10-14T04:41:33.773Z" },
+ { url = "https://files.pythonhosted.org/packages/10/9a/97c8d48ef10d6cd4fcead2415523221624bf58bcf68a802721a6bc807c8f/charset_normalizer-3.4.4-cp314-cp314-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:8af65f14dc14a79b924524b1e7fffe304517b2bff5a58bf64f30b98bbc5079eb", size = 147889, upload-time = "2025-10-14T04:41:34.897Z" },
+ { url = "https://files.pythonhosted.org/packages/10/bf/979224a919a1b606c82bd2c5fa49b5c6d5727aa47b4312bb27b1734f53cd/charset_normalizer-3.4.4-cp314-cp314-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:74664978bb272435107de04e36db5a9735e78232b85b77d45cfb38f758efd33e", size = 143641, upload-time = "2025-10-14T04:41:36.116Z" },
+ { url = "https://files.pythonhosted.org/packages/ba/33/0ad65587441fc730dc7bd90e9716b30b4702dc7b617e6ba4997dc8651495/charset_normalizer-3.4.4-cp314-cp314-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:752944c7ffbfdd10c074dc58ec2d5a8a4cd9493b314d367c14d24c17684ddd14", size = 160779, upload-time = "2025-10-14T04:41:37.229Z" },
+ { url = "https://files.pythonhosted.org/packages/67/ed/331d6b249259ee71ddea93f6f2f0a56cfebd46938bde6fcc6f7b9a3d0e09/charset_normalizer-3.4.4-cp314-cp314-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:d1f13550535ad8cff21b8d757a3257963e951d96e20ec82ab44bc64aeb62a191", size = 159035, upload-time = "2025-10-14T04:41:38.368Z" },
+ { url = "https://files.pythonhosted.org/packages/67/ff/f6b948ca32e4f2a4576aa129d8bed61f2e0543bf9f5f2b7fc3758ed005c9/charset_normalizer-3.4.4-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:ecaae4149d99b1c9e7b88bb03e3221956f68fd6d50be2ef061b2381b61d20838", size = 152542, upload-time = "2025-10-14T04:41:39.862Z" },
+ { url = "https://files.pythonhosted.org/packages/16/85/276033dcbcc369eb176594de22728541a925b2632f9716428c851b149e83/charset_normalizer-3.4.4-cp314-cp314-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:cb6254dc36b47a990e59e1068afacdcd02958bdcce30bb50cc1700a8b9d624a6", size = 149524, upload-time = "2025-10-14T04:41:41.319Z" },
+ { url = "https://files.pythonhosted.org/packages/9e/f2/6a2a1f722b6aba37050e626530a46a68f74e63683947a8acff92569f979a/charset_normalizer-3.4.4-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:c8ae8a0f02f57a6e61203a31428fa1d677cbe50c93622b4149d5c0f319c1d19e", size = 150395, upload-time = "2025-10-14T04:41:42.539Z" },
+ { url = "https://files.pythonhosted.org/packages/60/bb/2186cb2f2bbaea6338cad15ce23a67f9b0672929744381e28b0592676824/charset_normalizer-3.4.4-cp314-cp314-musllinux_1_2_armv7l.whl", hash = "sha256:47cc91b2f4dd2833fddaedd2893006b0106129d4b94fdb6af1f4ce5a9965577c", size = 143680, upload-time = "2025-10-14T04:41:43.661Z" },
+ { url = "https://files.pythonhosted.org/packages/7d/a5/bf6f13b772fbb2a90360eb620d52ed8f796f3c5caee8398c3b2eb7b1c60d/charset_normalizer-3.4.4-cp314-cp314-musllinux_1_2_ppc64le.whl", hash = "sha256:82004af6c302b5d3ab2cfc4cc5f29db16123b1a8417f2e25f9066f91d4411090", size = 162045, upload-time = "2025-10-14T04:41:44.821Z" },
+ { url = "https://files.pythonhosted.org/packages/df/c5/d1be898bf0dc3ef9030c3825e5d3b83f2c528d207d246cbabe245966808d/charset_normalizer-3.4.4-cp314-cp314-musllinux_1_2_riscv64.whl", hash = "sha256:2b7d8f6c26245217bd2ad053761201e9f9680f8ce52f0fcd8d0755aeae5b2152", size = 149687, upload-time = "2025-10-14T04:41:46.442Z" },
+ { url = "https://files.pythonhosted.org/packages/a5/42/90c1f7b9341eef50c8a1cb3f098ac43b0508413f33affd762855f67a410e/charset_normalizer-3.4.4-cp314-cp314-musllinux_1_2_s390x.whl", hash = "sha256:799a7a5e4fb2d5898c60b640fd4981d6a25f1c11790935a44ce38c54e985f828", size = 160014, upload-time = "2025-10-14T04:41:47.631Z" },
+ { url = "https://files.pythonhosted.org/packages/76/be/4d3ee471e8145d12795ab655ece37baed0929462a86e72372fd25859047c/charset_normalizer-3.4.4-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:99ae2cffebb06e6c22bdc25801d7b30f503cc87dbd283479e7b606f70aff57ec", size = 154044, upload-time = "2025-10-14T04:41:48.81Z" },
+ { url = "https://files.pythonhosted.org/packages/b0/6f/8f7af07237c34a1defe7defc565a9bc1807762f672c0fde711a4b22bf9c0/charset_normalizer-3.4.4-cp314-cp314-win32.whl", hash = "sha256:f9d332f8c2a2fcbffe1378594431458ddbef721c1769d78e2cbc06280d8155f9", size = 99940, upload-time = "2025-10-14T04:41:49.946Z" },
+ { url = "https://files.pythonhosted.org/packages/4b/51/8ade005e5ca5b0d80fb4aff72a3775b325bdc3d27408c8113811a7cbe640/charset_normalizer-3.4.4-cp314-cp314-win_amd64.whl", hash = "sha256:8a6562c3700cce886c5be75ade4a5db4214fda19fede41d9792d100288d8f94c", size = 107104, upload-time = "2025-10-14T04:41:51.051Z" },
+ { url = "https://files.pythonhosted.org/packages/da/5f/6b8f83a55bb8278772c5ae54a577f3099025f9ade59d0136ac24a0df4bde/charset_normalizer-3.4.4-cp314-cp314-win_arm64.whl", hash = "sha256:de00632ca48df9daf77a2c65a484531649261ec9f25489917f09e455cb09ddb2", size = 100743, upload-time = "2025-10-14T04:41:52.122Z" },
+ { url = "https://files.pythonhosted.org/packages/0a/4c/925909008ed5a988ccbb72dcc897407e5d6d3bd72410d69e051fc0c14647/charset_normalizer-3.4.4-py3-none-any.whl", hash = "sha256:7a32c560861a02ff789ad905a2fe94e3f840803362c84fecf1851cb4cf3dc37f", size = 53402, upload-time = "2025-10-14T04:42:31.76Z" },
+]
+
+[[package]]
+name = "click"
+version = "8.3.1"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "colorama", marker = "sys_platform == 'win32'" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/3d/fa/656b739db8587d7b5dfa22e22ed02566950fbfbcdc20311993483657a5c0/click-8.3.1.tar.gz", hash = "sha256:12ff4785d337a1bb490bb7e9c2b1ee5da3112e94a8622f26a6c77f5d2fc6842a", size = 295065, upload-time = "2025-11-15T20:45:42.706Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/98/78/01c019cdb5d6498122777c1a43056ebb3ebfeef2076d9d026bfe15583b2b/click-8.3.1-py3-none-any.whl", hash = "sha256:981153a64e25f12d547d3426c367a4857371575ee7ad18df2a6183ab0545b2a6", size = 108274, upload-time = "2025-11-15T20:45:41.139Z" },
+]
+
+[[package]]
+name = "colorama"
+version = "0.4.6"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/d8/53/6f443c9a4a8358a93a6792e2acffb9d9d5cb0a5cfd8802644b7b1c9a02e4/colorama-0.4.6.tar.gz", hash = "sha256:08695f5cb7ed6e0531a20572697297273c47b8cae5a63ffc6d6ed5c201be6e44", size = 27697, upload-time = "2022-10-25T02:36:22.414Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/d1/d6/3965ed04c63042e047cb6a3e6ed1a63a35087b6a609aa3a15ed8ac56c221/colorama-0.4.6-py2.py3-none-any.whl", hash = "sha256:4f1d9991f5acc0ca119f9d443620b77f9d6b33703e51011c16baf57afb285fc6", size = 25335, upload-time = "2022-10-25T02:36:20.889Z" },
+]
+
+[[package]]
+name = "comm"
+version = "0.2.3"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/4c/13/7d740c5849255756bc17888787313b61fd38a0a8304fc4f073dfc46122aa/comm-0.2.3.tar.gz", hash = "sha256:2dc8048c10962d55d7ad693be1e7045d891b7ce8d999c97963a5e3e99c055971", size = 6319, upload-time = "2025-07-25T14:02:04.452Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/60/97/891a0971e1e4a8c5d2b20bbe0e524dc04548d2307fee33cdeba148fd4fc7/comm-0.2.3-py3-none-any.whl", hash = "sha256:c615d91d75f7f04f095b30d1c1711babd43bdc6419c1be9886a85f2f4e489417", size = 7294, upload-time = "2025-07-25T14:02:02.896Z" },
+]
+
+[[package]]
+name = "contourpy"
+version = "1.3.3"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "numpy" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/58/01/1253e6698a07380cd31a736d248a3f2a50a7c88779a1813da27503cadc2a/contourpy-1.3.3.tar.gz", hash = "sha256:083e12155b210502d0bca491432bb04d56dc3432f95a979b429f2848c3dbe880", size = 13466174, upload-time = "2025-07-26T12:03:12.549Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/be/45/adfee365d9ea3d853550b2e735f9d66366701c65db7855cd07621732ccfc/contourpy-1.3.3-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:b08a32ea2f8e42cf1d4be3169a98dd4be32bafe4f22b6c4cb4ba810fa9e5d2cb", size = 293419, upload-time = "2025-07-26T12:01:21.16Z" },
+ { url = "https://files.pythonhosted.org/packages/53/3e/405b59cfa13021a56bba395a6b3aca8cec012b45bf177b0eaf7a202cde2c/contourpy-1.3.3-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:556dba8fb6f5d8742f2923fe9457dbdd51e1049c4a43fd3986a0b14a1d815fc6", size = 273979, upload-time = "2025-07-26T12:01:22.448Z" },
+ { url = "https://files.pythonhosted.org/packages/d4/1c/a12359b9b2ca3a845e8f7f9ac08bdf776114eb931392fcad91743e2ea17b/contourpy-1.3.3-cp312-cp312-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:92d9abc807cf7d0e047b95ca5d957cf4792fcd04e920ca70d48add15c1a90ea7", size = 332653, upload-time = "2025-07-26T12:01:24.155Z" },
+ { url = "https://files.pythonhosted.org/packages/63/12/897aeebfb475b7748ea67b61e045accdfcf0d971f8a588b67108ed7f5512/contourpy-1.3.3-cp312-cp312-manylinux_2_26_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:b2e8faa0ed68cb29af51edd8e24798bb661eac3bd9f65420c1887b6ca89987c8", size = 379536, upload-time = "2025-07-26T12:01:25.91Z" },
+ { url = "https://files.pythonhosted.org/packages/43/8a/a8c584b82deb248930ce069e71576fc09bd7174bbd35183b7943fb1064fd/contourpy-1.3.3-cp312-cp312-manylinux_2_26_s390x.manylinux_2_28_s390x.whl", hash = "sha256:626d60935cf668e70a5ce6ff184fd713e9683fb458898e4249b63be9e28286ea", size = 384397, upload-time = "2025-07-26T12:01:27.152Z" },
+ { url = "https://files.pythonhosted.org/packages/cc/8f/ec6289987824b29529d0dfda0d74a07cec60e54b9c92f3c9da4c0ac732de/contourpy-1.3.3-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:4d00e655fcef08aba35ec9610536bfe90267d7ab5ba944f7032549c55a146da1", size = 362601, upload-time = "2025-07-26T12:01:28.808Z" },
+ { url = "https://files.pythonhosted.org/packages/05/0a/a3fe3be3ee2dceb3e615ebb4df97ae6f3828aa915d3e10549ce016302bd1/contourpy-1.3.3-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:451e71b5a7d597379ef572de31eeb909a87246974d960049a9848c3bc6c41bf7", size = 1331288, upload-time = "2025-07-26T12:01:31.198Z" },
+ { url = "https://files.pythonhosted.org/packages/33/1d/acad9bd4e97f13f3e2b18a3977fe1b4a37ecf3d38d815333980c6c72e963/contourpy-1.3.3-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:459c1f020cd59fcfe6650180678a9993932d80d44ccde1fa1868977438f0b411", size = 1403386, upload-time = "2025-07-26T12:01:33.947Z" },
+ { url = "https://files.pythonhosted.org/packages/cf/8f/5847f44a7fddf859704217a99a23a4f6417b10e5ab1256a179264561540e/contourpy-1.3.3-cp312-cp312-win32.whl", hash = "sha256:023b44101dfe49d7d53932be418477dba359649246075c996866106da069af69", size = 185018, upload-time = "2025-07-26T12:01:35.64Z" },
+ { url = "https://files.pythonhosted.org/packages/19/e8/6026ed58a64563186a9ee3f29f41261fd1828f527dd93d33b60feca63352/contourpy-1.3.3-cp312-cp312-win_amd64.whl", hash = "sha256:8153b8bfc11e1e4d75bcb0bff1db232f9e10b274e0929de9d608027e0d34ff8b", size = 226567, upload-time = "2025-07-26T12:01:36.804Z" },
+ { url = "https://files.pythonhosted.org/packages/d1/e2/f05240d2c39a1ed228d8328a78b6f44cd695f7ef47beb3e684cf93604f86/contourpy-1.3.3-cp312-cp312-win_arm64.whl", hash = "sha256:07ce5ed73ecdc4a03ffe3e1b3e3c1166db35ae7584be76f65dbbe28a7791b0cc", size = 193655, upload-time = "2025-07-26T12:01:37.999Z" },
+ { url = "https://files.pythonhosted.org/packages/68/35/0167aad910bbdb9599272bd96d01a9ec6852f36b9455cf2ca67bd4cc2d23/contourpy-1.3.3-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:177fb367556747a686509d6fef71d221a4b198a3905fe824430e5ea0fda54eb5", size = 293257, upload-time = "2025-07-26T12:01:39.367Z" },
+ { url = "https://files.pythonhosted.org/packages/96/e4/7adcd9c8362745b2210728f209bfbcf7d91ba868a2c5f40d8b58f54c509b/contourpy-1.3.3-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:d002b6f00d73d69333dac9d0b8d5e84d9724ff9ef044fd63c5986e62b7c9e1b1", size = 274034, upload-time = "2025-07-26T12:01:40.645Z" },
+ { url = "https://files.pythonhosted.org/packages/73/23/90e31ceeed1de63058a02cb04b12f2de4b40e3bef5e082a7c18d9c8ae281/contourpy-1.3.3-cp313-cp313-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:348ac1f5d4f1d66d3322420f01d42e43122f43616e0f194fc1c9f5d830c5b286", size = 334672, upload-time = "2025-07-26T12:01:41.942Z" },
+ { url = "https://files.pythonhosted.org/packages/ed/93/b43d8acbe67392e659e1d984700e79eb67e2acb2bd7f62012b583a7f1b55/contourpy-1.3.3-cp313-cp313-manylinux_2_26_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:655456777ff65c2c548b7c454af9c6f33f16c8884f11083244b5819cc214f1b5", size = 381234, upload-time = "2025-07-26T12:01:43.499Z" },
+ { url = "https://files.pythonhosted.org/packages/46/3b/bec82a3ea06f66711520f75a40c8fc0b113b2a75edb36aa633eb11c4f50f/contourpy-1.3.3-cp313-cp313-manylinux_2_26_s390x.manylinux_2_28_s390x.whl", hash = "sha256:644a6853d15b2512d67881586bd03f462c7ab755db95f16f14d7e238f2852c67", size = 385169, upload-time = "2025-07-26T12:01:45.219Z" },
+ { url = "https://files.pythonhosted.org/packages/4b/32/e0f13a1c5b0f8572d0ec6ae2f6c677b7991fafd95da523159c19eff0696a/contourpy-1.3.3-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:4debd64f124ca62069f313a9cb86656ff087786016d76927ae2cf37846b006c9", size = 362859, upload-time = "2025-07-26T12:01:46.519Z" },
+ { url = "https://files.pythonhosted.org/packages/33/71/e2a7945b7de4e58af42d708a219f3b2f4cff7386e6b6ab0a0fa0033c49a9/contourpy-1.3.3-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:a15459b0f4615b00bbd1e91f1b9e19b7e63aea7483d03d804186f278c0af2659", size = 1332062, upload-time = "2025-07-26T12:01:48.964Z" },
+ { url = "https://files.pythonhosted.org/packages/12/fc/4e87ac754220ccc0e807284f88e943d6d43b43843614f0a8afa469801db0/contourpy-1.3.3-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:ca0fdcd73925568ca027e0b17ab07aad764be4706d0a925b89227e447d9737b7", size = 1403932, upload-time = "2025-07-26T12:01:51.979Z" },
+ { url = "https://files.pythonhosted.org/packages/a6/2e/adc197a37443f934594112222ac1aa7dc9a98faf9c3842884df9a9d8751d/contourpy-1.3.3-cp313-cp313-win32.whl", hash = "sha256:b20c7c9a3bf701366556e1b1984ed2d0cedf999903c51311417cf5f591d8c78d", size = 185024, upload-time = "2025-07-26T12:01:53.245Z" },
+ { url = "https://files.pythonhosted.org/packages/18/0b/0098c214843213759692cc638fce7de5c289200a830e5035d1791d7a2338/contourpy-1.3.3-cp313-cp313-win_amd64.whl", hash = "sha256:1cadd8b8969f060ba45ed7c1b714fe69185812ab43bd6b86a9123fe8f99c3263", size = 226578, upload-time = "2025-07-26T12:01:54.422Z" },
+ { url = "https://files.pythonhosted.org/packages/8a/9a/2f6024a0c5995243cd63afdeb3651c984f0d2bc727fd98066d40e141ad73/contourpy-1.3.3-cp313-cp313-win_arm64.whl", hash = "sha256:fd914713266421b7536de2bfa8181aa8c699432b6763a0ea64195ebe28bff6a9", size = 193524, upload-time = "2025-07-26T12:01:55.73Z" },
+ { url = "https://files.pythonhosted.org/packages/c0/b3/f8a1a86bd3298513f500e5b1f5fd92b69896449f6cab6a146a5d52715479/contourpy-1.3.3-cp313-cp313t-macosx_10_13_x86_64.whl", hash = "sha256:88df9880d507169449d434c293467418b9f6cbe82edd19284aa0409e7fdb933d", size = 306730, upload-time = "2025-07-26T12:01:57.051Z" },
+ { url = "https://files.pythonhosted.org/packages/3f/11/4780db94ae62fc0c2053909b65dc3246bd7cecfc4f8a20d957ad43aa4ad8/contourpy-1.3.3-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:d06bb1f751ba5d417047db62bca3c8fde202b8c11fb50742ab3ab962c81e8216", size = 287897, upload-time = "2025-07-26T12:01:58.663Z" },
+ { url = "https://files.pythonhosted.org/packages/ae/15/e59f5f3ffdd6f3d4daa3e47114c53daabcb18574a26c21f03dc9e4e42ff0/contourpy-1.3.3-cp313-cp313t-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:e4e6b05a45525357e382909a4c1600444e2a45b4795163d3b22669285591c1ae", size = 326751, upload-time = "2025-07-26T12:02:00.343Z" },
+ { url = "https://files.pythonhosted.org/packages/0f/81/03b45cfad088e4770b1dcf72ea78d3802d04200009fb364d18a493857210/contourpy-1.3.3-cp313-cp313t-manylinux_2_26_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:ab3074b48c4e2cf1a960e6bbeb7f04566bf36b1861d5c9d4d8ac04b82e38ba20", size = 375486, upload-time = "2025-07-26T12:02:02.128Z" },
+ { url = "https://files.pythonhosted.org/packages/0c/ba/49923366492ffbdd4486e970d421b289a670ae8cf539c1ea9a09822b371a/contourpy-1.3.3-cp313-cp313t-manylinux_2_26_s390x.manylinux_2_28_s390x.whl", hash = "sha256:6c3d53c796f8647d6deb1abe867daeb66dcc8a97e8455efa729516b997b8ed99", size = 388106, upload-time = "2025-07-26T12:02:03.615Z" },
+ { url = "https://files.pythonhosted.org/packages/9f/52/5b00ea89525f8f143651f9f03a0df371d3cbd2fccd21ca9b768c7a6500c2/contourpy-1.3.3-cp313-cp313t-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:50ed930df7289ff2a8d7afeb9603f8289e5704755c7e5c3bbd929c90c817164b", size = 352548, upload-time = "2025-07-26T12:02:05.165Z" },
+ { url = "https://files.pythonhosted.org/packages/32/1d/a209ec1a3a3452d490f6b14dd92e72280c99ae3d1e73da74f8277d4ee08f/contourpy-1.3.3-cp313-cp313t-musllinux_1_2_aarch64.whl", hash = "sha256:4feffb6537d64b84877da813a5c30f1422ea5739566abf0bd18065ac040e120a", size = 1322297, upload-time = "2025-07-26T12:02:07.379Z" },
+ { url = "https://files.pythonhosted.org/packages/bc/9e/46f0e8ebdd884ca0e8877e46a3f4e633f6c9c8c4f3f6e72be3fe075994aa/contourpy-1.3.3-cp313-cp313t-musllinux_1_2_x86_64.whl", hash = "sha256:2b7e9480ffe2b0cd2e787e4df64270e3a0440d9db8dc823312e2c940c167df7e", size = 1391023, upload-time = "2025-07-26T12:02:10.171Z" },
+ { url = "https://files.pythonhosted.org/packages/b9/70/f308384a3ae9cd2209e0849f33c913f658d3326900d0ff5d378d6a1422d2/contourpy-1.3.3-cp313-cp313t-win32.whl", hash = "sha256:283edd842a01e3dcd435b1c5116798d661378d83d36d337b8dde1d16a5fc9ba3", size = 196157, upload-time = "2025-07-26T12:02:11.488Z" },
+ { url = "https://files.pythonhosted.org/packages/b2/dd/880f890a6663b84d9e34a6f88cded89d78f0091e0045a284427cb6b18521/contourpy-1.3.3-cp313-cp313t-win_amd64.whl", hash = "sha256:87acf5963fc2b34825e5b6b048f40e3635dd547f590b04d2ab317c2619ef7ae8", size = 240570, upload-time = "2025-07-26T12:02:12.754Z" },
+ { url = "https://files.pythonhosted.org/packages/80/99/2adc7d8ffead633234817ef8e9a87115c8a11927a94478f6bb3d3f4d4f7d/contourpy-1.3.3-cp313-cp313t-win_arm64.whl", hash = "sha256:3c30273eb2a55024ff31ba7d052dde990d7d8e5450f4bbb6e913558b3d6c2301", size = 199713, upload-time = "2025-07-26T12:02:14.4Z" },
+ { url = "https://files.pythonhosted.org/packages/72/8b/4546f3ab60f78c514ffb7d01a0bd743f90de36f0019d1be84d0a708a580a/contourpy-1.3.3-cp314-cp314-macosx_10_13_x86_64.whl", hash = "sha256:fde6c716d51c04b1c25d0b90364d0be954624a0ee9d60e23e850e8d48353d07a", size = 292189, upload-time = "2025-07-26T12:02:16.095Z" },
+ { url = "https://files.pythonhosted.org/packages/fd/e1/3542a9cb596cadd76fcef413f19c79216e002623158befe6daa03dbfa88c/contourpy-1.3.3-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:cbedb772ed74ff5be440fa8eee9bd49f64f6e3fc09436d9c7d8f1c287b121d77", size = 273251, upload-time = "2025-07-26T12:02:17.524Z" },
+ { url = "https://files.pythonhosted.org/packages/b1/71/f93e1e9471d189f79d0ce2497007731c1e6bf9ef6d1d61b911430c3db4e5/contourpy-1.3.3-cp314-cp314-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:22e9b1bd7a9b1d652cd77388465dc358dafcd2e217d35552424aa4f996f524f5", size = 335810, upload-time = "2025-07-26T12:02:18.9Z" },
+ { url = "https://files.pythonhosted.org/packages/91/f9/e35f4c1c93f9275d4e38681a80506b5510e9327350c51f8d4a5a724d178c/contourpy-1.3.3-cp314-cp314-manylinux_2_26_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:a22738912262aa3e254e4f3cb079a95a67132fc5a063890e224393596902f5a4", size = 382871, upload-time = "2025-07-26T12:02:20.418Z" },
+ { url = "https://files.pythonhosted.org/packages/b5/71/47b512f936f66a0a900d81c396a7e60d73419868fba959c61efed7a8ab46/contourpy-1.3.3-cp314-cp314-manylinux_2_26_s390x.manylinux_2_28_s390x.whl", hash = "sha256:afe5a512f31ee6bd7d0dda52ec9864c984ca3d66664444f2d72e0dc4eb832e36", size = 386264, upload-time = "2025-07-26T12:02:21.916Z" },
+ { url = "https://files.pythonhosted.org/packages/04/5f/9ff93450ba96b09c7c2b3f81c94de31c89f92292f1380261bd7195bea4ea/contourpy-1.3.3-cp314-cp314-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:f64836de09927cba6f79dcd00fdd7d5329f3fccc633468507079c829ca4db4e3", size = 363819, upload-time = "2025-07-26T12:02:23.759Z" },
+ { url = "https://files.pythonhosted.org/packages/3e/a6/0b185d4cc480ee494945cde102cb0149ae830b5fa17bf855b95f2e70ad13/contourpy-1.3.3-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:1fd43c3be4c8e5fd6e4f2baeae35ae18176cf2e5cced681cca908addf1cdd53b", size = 1333650, upload-time = "2025-07-26T12:02:26.181Z" },
+ { url = "https://files.pythonhosted.org/packages/43/d7/afdc95580ca56f30fbcd3060250f66cedbde69b4547028863abd8aa3b47e/contourpy-1.3.3-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:6afc576f7b33cf00996e5c1102dc2a8f7cc89e39c0b55df93a0b78c1bd992b36", size = 1404833, upload-time = "2025-07-26T12:02:28.782Z" },
+ { url = "https://files.pythonhosted.org/packages/e2/e2/366af18a6d386f41132a48f033cbd2102e9b0cf6345d35ff0826cd984566/contourpy-1.3.3-cp314-cp314-win32.whl", hash = "sha256:66c8a43a4f7b8df8b71ee1840e4211a3c8d93b214b213f590e18a1beca458f7d", size = 189692, upload-time = "2025-07-26T12:02:30.128Z" },
+ { url = "https://files.pythonhosted.org/packages/7d/c2/57f54b03d0f22d4044b8afb9ca0e184f8b1afd57b4f735c2fa70883dc601/contourpy-1.3.3-cp314-cp314-win_amd64.whl", hash = "sha256:cf9022ef053f2694e31d630feaacb21ea24224be1c3ad0520b13d844274614fd", size = 232424, upload-time = "2025-07-26T12:02:31.395Z" },
+ { url = "https://files.pythonhosted.org/packages/18/79/a9416650df9b525737ab521aa181ccc42d56016d2123ddcb7b58e926a42c/contourpy-1.3.3-cp314-cp314-win_arm64.whl", hash = "sha256:95b181891b4c71de4bb404c6621e7e2390745f887f2a026b2d99e92c17892339", size = 198300, upload-time = "2025-07-26T12:02:32.956Z" },
+ { url = "https://files.pythonhosted.org/packages/1f/42/38c159a7d0f2b7b9c04c64ab317042bb6952b713ba875c1681529a2932fe/contourpy-1.3.3-cp314-cp314t-macosx_10_13_x86_64.whl", hash = "sha256:33c82d0138c0a062380332c861387650c82e4cf1747aaa6938b9b6516762e772", size = 306769, upload-time = "2025-07-26T12:02:34.2Z" },
+ { url = "https://files.pythonhosted.org/packages/c3/6c/26a8205f24bca10974e77460de68d3d7c63e282e23782f1239f226fcae6f/contourpy-1.3.3-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:ea37e7b45949df430fe649e5de8351c423430046a2af20b1c1961cae3afcda77", size = 287892, upload-time = "2025-07-26T12:02:35.807Z" },
+ { url = "https://files.pythonhosted.org/packages/66/06/8a475c8ab718ebfd7925661747dbb3c3ee9c82ac834ccb3570be49d129f4/contourpy-1.3.3-cp314-cp314t-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:d304906ecc71672e9c89e87c4675dc5c2645e1f4269a5063b99b0bb29f232d13", size = 326748, upload-time = "2025-07-26T12:02:37.193Z" },
+ { url = "https://files.pythonhosted.org/packages/b4/a3/c5ca9f010a44c223f098fccd8b158bb1cb287378a31ac141f04730dc49be/contourpy-1.3.3-cp314-cp314t-manylinux_2_26_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:ca658cd1a680a5c9ea96dc61cdbae1e85c8f25849843aa799dfd3cb370ad4fbe", size = 375554, upload-time = "2025-07-26T12:02:38.894Z" },
+ { url = "https://files.pythonhosted.org/packages/80/5b/68bd33ae63fac658a4145088c1e894405e07584a316738710b636c6d0333/contourpy-1.3.3-cp314-cp314t-manylinux_2_26_s390x.manylinux_2_28_s390x.whl", hash = "sha256:ab2fd90904c503739a75b7c8c5c01160130ba67944a7b77bbf36ef8054576e7f", size = 388118, upload-time = "2025-07-26T12:02:40.642Z" },
+ { url = "https://files.pythonhosted.org/packages/40/52/4c285a6435940ae25d7410a6c36bda5145839bc3f0beb20c707cda18b9d2/contourpy-1.3.3-cp314-cp314t-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:b7301b89040075c30e5768810bc96a8e8d78085b47d8be6e4c3f5a0b4ed478a0", size = 352555, upload-time = "2025-07-26T12:02:42.25Z" },
+ { url = "https://files.pythonhosted.org/packages/24/ee/3e81e1dd174f5c7fefe50e85d0892de05ca4e26ef1c9a59c2a57e43b865a/contourpy-1.3.3-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:2a2a8b627d5cc6b7c41a4beff6c5ad5eb848c88255fda4a8745f7e901b32d8e4", size = 1322295, upload-time = "2025-07-26T12:02:44.668Z" },
+ { url = "https://files.pythonhosted.org/packages/3c/b2/6d913d4d04e14379de429057cd169e5e00f6c2af3bb13e1710bcbdb5da12/contourpy-1.3.3-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:fd6ec6be509c787f1caf6b247f0b1ca598bef13f4ddeaa126b7658215529ba0f", size = 1391027, upload-time = "2025-07-26T12:02:47.09Z" },
+ { url = "https://files.pythonhosted.org/packages/93/8a/68a4ec5c55a2971213d29a9374913f7e9f18581945a7a31d1a39b5d2dfe5/contourpy-1.3.3-cp314-cp314t-win32.whl", hash = "sha256:e74a9a0f5e3fff48fb5a7f2fd2b9b70a3fe014a67522f79b7cca4c0c7e43c9ae", size = 202428, upload-time = "2025-07-26T12:02:48.691Z" },
+ { url = "https://files.pythonhosted.org/packages/fa/96/fd9f641ffedc4fa3ace923af73b9d07e869496c9cc7a459103e6e978992f/contourpy-1.3.3-cp314-cp314t-win_amd64.whl", hash = "sha256:13b68d6a62db8eafaebb8039218921399baf6e47bf85006fd8529f2a08ef33fc", size = 250331, upload-time = "2025-07-26T12:02:50.137Z" },
+ { url = "https://files.pythonhosted.org/packages/ae/8c/469afb6465b853afff216f9528ffda78a915ff880ed58813ba4faf4ba0b6/contourpy-1.3.3-cp314-cp314t-win_arm64.whl", hash = "sha256:b7448cb5a725bb1e35ce88771b86fba35ef418952474492cf7c764059933ff8b", size = 203831, upload-time = "2025-07-26T12:02:51.449Z" },
+]
+
+[[package]]
+name = "cycler"
+version = "0.12.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/a9/95/a3dbbb5028f35eafb79008e7522a75244477d2838f38cbb722248dabc2a8/cycler-0.12.1.tar.gz", hash = "sha256:88bb128f02ba341da8ef447245a9e138fae777f6a23943da4540077d3601eb1c", size = 7615, upload-time = "2023-10-07T05:32:18.335Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/e7/05/c19819d5e3d95294a6f5947fb9b9629efb316b96de511b418c53d245aae6/cycler-0.12.1-py3-none-any.whl", hash = "sha256:85cef7cff222d8644161529808465972e51340599459b8ac3ccbac5a854e0d30", size = 8321, upload-time = "2023-10-07T05:32:16.783Z" },
+]
+
+[[package]]
+name = "datasets"
+version = "4.4.1"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "dill" },
+ { name = "filelock" },
+ { name = "fsspec", extra = ["http"] },
+ { name = "httpx" },
+ { name = "huggingface-hub" },
+ { name = "multiprocess" },
+ { name = "numpy" },
+ { name = "packaging" },
+ { name = "pandas" },
+ { name = "pyarrow" },
+ { name = "pyyaml" },
+ { name = "requests" },
+ { name = "tqdm" },
+ { name = "xxhash" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/93/bf/0dae295d6d1ba0b1a200a9dd216838464b5bbd05da01407cb1330b377445/datasets-4.4.1.tar.gz", hash = "sha256:80322699aa8c0bbbdb7caa87906da689c3c2e29523cff698775c67f28fdab1fc", size = 585341, upload-time = "2025-11-05T16:00:38.162Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/3b/5e/6f8d874366788ad5d549e9ba258037d974dda6e004843be1bda794571701/datasets-4.4.1-py3-none-any.whl", hash = "sha256:c1163de5211e42546079ab355cc0250c7e6db16eb209ac5ac6252f801f596c44", size = 511591, upload-time = "2025-11-05T16:00:36.365Z" },
+]
+
+[[package]]
+name = "debugpy"
+version = "1.8.17"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/15/ad/71e708ff4ca377c4230530d6a7aa7992592648c122a2cd2b321cf8b35a76/debugpy-1.8.17.tar.gz", hash = "sha256:fd723b47a8c08892b1a16b2c6239a8b96637c62a59b94bb5dab4bac592a58a8e", size = 1644129, upload-time = "2025-09-17T16:33:20.633Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/08/2b/9d8e65beb2751876c82e1aceb32f328c43ec872711fa80257c7674f45650/debugpy-1.8.17-cp312-cp312-macosx_15_0_universal2.whl", hash = "sha256:f14467edef672195c6f6b8e27ce5005313cb5d03c9239059bc7182b60c176e2d", size = 2549522, upload-time = "2025-09-17T16:33:38.466Z" },
+ { url = "https://files.pythonhosted.org/packages/b4/78/eb0d77f02971c05fca0eb7465b18058ba84bd957062f5eec82f941ac792a/debugpy-1.8.17-cp312-cp312-manylinux_2_34_x86_64.whl", hash = "sha256:24693179ef9dfa20dca8605905a42b392be56d410c333af82f1c5dff807a64cc", size = 4309417, upload-time = "2025-09-17T16:33:41.299Z" },
+ { url = "https://files.pythonhosted.org/packages/37/42/c40f1d8cc1fed1e75ea54298a382395b8b937d923fcf41ab0797a554f555/debugpy-1.8.17-cp312-cp312-win32.whl", hash = "sha256:6a4e9dacf2cbb60d2514ff7b04b4534b0139facbf2abdffe0639ddb6088e59cf", size = 5277130, upload-time = "2025-09-17T16:33:43.554Z" },
+ { url = "https://files.pythonhosted.org/packages/72/22/84263b205baad32b81b36eac076de0cdbe09fe2d0637f5b32243dc7c925b/debugpy-1.8.17-cp312-cp312-win_amd64.whl", hash = "sha256:e8f8f61c518952fb15f74a302e068b48d9c4691768ade433e4adeea961993464", size = 5319053, upload-time = "2025-09-17T16:33:53.033Z" },
+ { url = "https://files.pythonhosted.org/packages/50/76/597e5cb97d026274ba297af8d89138dfd9e695767ba0e0895edb20963f40/debugpy-1.8.17-cp313-cp313-macosx_15_0_universal2.whl", hash = "sha256:857c1dd5d70042502aef1c6d1c2801211f3ea7e56f75e9c335f434afb403e464", size = 2538386, upload-time = "2025-09-17T16:33:54.594Z" },
+ { url = "https://files.pythonhosted.org/packages/5f/60/ce5c34fcdfec493701f9d1532dba95b21b2f6394147234dce21160bd923f/debugpy-1.8.17-cp313-cp313-manylinux_2_34_x86_64.whl", hash = "sha256:3bea3b0b12f3946e098cce9b43c3c46e317b567f79570c3f43f0b96d00788088", size = 4292100, upload-time = "2025-09-17T16:33:56.353Z" },
+ { url = "https://files.pythonhosted.org/packages/e8/95/7873cf2146577ef71d2a20bf553f12df865922a6f87b9e8ee1df04f01785/debugpy-1.8.17-cp313-cp313-win32.whl", hash = "sha256:e34ee844c2f17b18556b5bbe59e1e2ff4e86a00282d2a46edab73fd7f18f4a83", size = 5277002, upload-time = "2025-09-17T16:33:58.231Z" },
+ { url = "https://files.pythonhosted.org/packages/46/11/18c79a1cee5ff539a94ec4aa290c1c069a5580fd5cfd2fb2e282f8e905da/debugpy-1.8.17-cp313-cp313-win_amd64.whl", hash = "sha256:6c5cd6f009ad4fca8e33e5238210dc1e5f42db07d4b6ab21ac7ffa904a196420", size = 5319047, upload-time = "2025-09-17T16:34:00.586Z" },
+ { url = "https://files.pythonhosted.org/packages/de/45/115d55b2a9da6de812696064ceb505c31e952c5d89c4ed1d9bb983deec34/debugpy-1.8.17-cp314-cp314-macosx_15_0_universal2.whl", hash = "sha256:045290c010bcd2d82bc97aa2daf6837443cd52f6328592698809b4549babcee1", size = 2536899, upload-time = "2025-09-17T16:34:02.657Z" },
+ { url = "https://files.pythonhosted.org/packages/5a/73/2aa00c7f1f06e997ef57dc9b23d61a92120bec1437a012afb6d176585197/debugpy-1.8.17-cp314-cp314-manylinux_2_34_x86_64.whl", hash = "sha256:b69b6bd9dba6a03632534cdf67c760625760a215ae289f7489a452af1031fe1f", size = 4268254, upload-time = "2025-09-17T16:34:04.486Z" },
+ { url = "https://files.pythonhosted.org/packages/86/b5/ed3e65c63c68a6634e3ba04bd10255c8e46ec16ebed7d1c79e4816d8a760/debugpy-1.8.17-cp314-cp314-win32.whl", hash = "sha256:5c59b74aa5630f3a5194467100c3b3d1c77898f9ab27e3f7dc5d40fc2f122670", size = 5277203, upload-time = "2025-09-17T16:34:06.65Z" },
+ { url = "https://files.pythonhosted.org/packages/b0/26/394276b71c7538445f29e792f589ab7379ae70fd26ff5577dfde71158e96/debugpy-1.8.17-cp314-cp314-win_amd64.whl", hash = "sha256:893cba7bb0f55161de4365584b025f7064e1f88913551bcd23be3260b231429c", size = 5318493, upload-time = "2025-09-17T16:34:08.483Z" },
+ { url = "https://files.pythonhosted.org/packages/b0/d0/89247ec250369fc76db477720a26b2fce7ba079ff1380e4ab4529d2fe233/debugpy-1.8.17-py2.py3-none-any.whl", hash = "sha256:60c7dca6571efe660ccb7a9508d73ca14b8796c4ed484c2002abba714226cfef", size = 5283210, upload-time = "2025-09-17T16:34:25.835Z" },
+]
+
+[[package]]
+name = "decorator"
+version = "5.2.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/43/fa/6d96a0978d19e17b68d634497769987b16c8f4cd0a7a05048bec693caa6b/decorator-5.2.1.tar.gz", hash = "sha256:65f266143752f734b0a7cc83c46f4618af75b8c5911b00ccb61d0ac9b6da0360", size = 56711, upload-time = "2025-02-24T04:41:34.073Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/4e/8c/f3147f5c4b73e7550fe5f9352eaa956ae838d5c51eb58e7a25b9f3e2643b/decorator-5.2.1-py3-none-any.whl", hash = "sha256:d316bb415a2d9e2d2b3abcc4084c6502fc09240e292cd76a76afc106a1c8e04a", size = 9190, upload-time = "2025-02-24T04:41:32.565Z" },
+]
+
+[[package]]
+name = "defusedxml"
+version = "0.7.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/0f/d5/c66da9b79e5bdb124974bfe172b4daf3c984ebd9c2a06e2b8a4dc7331c72/defusedxml-0.7.1.tar.gz", hash = "sha256:1bb3032db185915b62d7c6209c5a8792be6a32ab2fedacc84e01b52c51aa3e69", size = 75520, upload-time = "2021-03-08T10:59:26.269Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/07/6c/aa3f2f849e01cb6a001cd8554a88d4c77c5c1a31c95bdf1cf9301e6d9ef4/defusedxml-0.7.1-py2.py3-none-any.whl", hash = "sha256:a352e7e428770286cc899e2542b6cdaedb2b4953ff269a210103ec58f6198a61", size = 25604, upload-time = "2021-03-08T10:59:24.45Z" },
+]
+
+[[package]]
+name = "dill"
+version = "0.4.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/12/80/630b4b88364e9a8c8c5797f4602d0f76ef820909ee32f0bacb9f90654042/dill-0.4.0.tar.gz", hash = "sha256:0633f1d2df477324f53a895b02c901fb961bdbf65a17122586ea7019292cbcf0", size = 186976, upload-time = "2025-04-16T00:41:48.867Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/50/3d/9373ad9c56321fdab5b41197068e1d8c25883b3fea29dd361f9b55116869/dill-0.4.0-py3-none-any.whl", hash = "sha256:44f54bf6412c2c8464c14e8243eb163690a9800dbe2c367330883b19c7561049", size = 119668, upload-time = "2025-04-16T00:41:47.671Z" },
+]
+
+[[package]]
+name = "distro"
+version = "1.9.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/fc/f8/98eea607f65de6527f8a2e8885fc8015d3e6f5775df186e443e0964a11c3/distro-1.9.0.tar.gz", hash = "sha256:2fa77c6fd8940f116ee1d6b94a2f90b13b5ea8d019b98bc8bafdcabcdd9bdbed", size = 60722, upload-time = "2023-12-24T09:54:32.31Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/12/b3/231ffd4ab1fc9d679809f356cebee130ac7daa00d6d6f3206dd4fd137e9e/distro-1.9.0-py3-none-any.whl", hash = "sha256:7bffd925d65168f85027d8da9af6bddab658135b840670a223589bc0c8ef02b2", size = 20277, upload-time = "2023-12-24T09:54:30.421Z" },
+]
+
+[[package]]
+name = "einops"
+version = "0.8.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/e5/81/df4fbe24dff8ba3934af99044188e20a98ed441ad17a274539b74e82e126/einops-0.8.1.tar.gz", hash = "sha256:de5d960a7a761225532e0f1959e5315ebeafc0cd43394732f103ca44b9837e84", size = 54805, upload-time = "2025-02-09T03:17:00.434Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/87/62/9773de14fe6c45c23649e98b83231fffd7b9892b6cf863251dc2afa73643/einops-0.8.1-py3-none-any.whl", hash = "sha256:919387eb55330f5757c6bea9165c5ff5cfe63a642682ea788a6d472576d81737", size = 64359, upload-time = "2025-02-09T03:17:01.998Z" },
+]
+
+[[package]]
+name = "einops-exts"
+version = "0.0.4"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "einops" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/3e/cc/f2b03b24894faaaa425cf46508e6b1f449d908841f61aeb7c14f0b18a3f3/einops-exts-0.0.4.tar.gz", hash = "sha256:616f145b3411f8e9e3be5da5c968bbe372e55c249de11faa909c7a4b74580a6c", size = 3548, upload-time = "2023-01-05T20:02:43.986Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/78/01/8da8dd078b354a89602a875d310a0d725dad92b5b4d61069576e0a0e02e4/einops_exts-0.0.4-py3-none-any.whl", hash = "sha256:6d310a4c858e459ebff8288580f90255d354cfa3bde22a53b59baae64b48cb95", size = 3925, upload-time = "2023-01-05T20:02:42.796Z" },
+]
+
+[[package]]
+name = "executing"
+version = "2.2.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/cc/28/c14e053b6762b1044f34a13aab6859bbf40456d37d23aa286ac24cfd9a5d/executing-2.2.1.tar.gz", hash = "sha256:3632cc370565f6648cc328b32435bd120a1e4ebb20c77e3fdde9a13cd1e533c4", size = 1129488, upload-time = "2025-09-01T09:48:10.866Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/c1/ea/53f2148663b321f21b5a606bd5f191517cf40b7072c0497d3c92c4a13b1e/executing-2.2.1-py2.py3-none-any.whl", hash = "sha256:760643d3452b4d777d295bb167ccc74c64a81df23fb5e08eff250c425a4b2017", size = 28317, upload-time = "2025-09-01T09:48:08.5Z" },
+]
+
+[[package]]
+name = "fastjsonschema"
+version = "2.21.2"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/20/b5/23b216d9d985a956623b6bd12d4086b60f0059b27799f23016af04a74ea1/fastjsonschema-2.21.2.tar.gz", hash = "sha256:b1eb43748041c880796cd077f1a07c3d94e93ae84bba5ed36800a33554ae05de", size = 374130, upload-time = "2025-08-14T18:49:36.666Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/cb/a8/20d0723294217e47de6d9e2e40fd4a9d2f7c4b6ef974babd482a59743694/fastjsonschema-2.21.2-py3-none-any.whl", hash = "sha256:1c797122d0a86c5cace2e54bf4e819c36223b552017172f32c5c024a6b77e463", size = 24024, upload-time = "2025-08-14T18:49:34.776Z" },
+]
+
+[[package]]
+name = "filelock"
+version = "3.20.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/58/46/0028a82567109b5ef6e4d2a1f04a583fb513e6cf9527fcdd09afd817deeb/filelock-3.20.0.tar.gz", hash = "sha256:711e943b4ec6be42e1d4e6690b48dc175c822967466bb31c0c293f34334c13f4", size = 18922, upload-time = "2025-10-08T18:03:50.056Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/76/91/7216b27286936c16f5b4d0c530087e4a54eead683e6b0b73dd0c64844af6/filelock-3.20.0-py3-none-any.whl", hash = "sha256:339b4732ffda5cd79b13f4e2711a31b0365ce445d95d243bb996273d072546a2", size = 16054, upload-time = "2025-10-08T18:03:48.35Z" },
+]
+
+[[package]]
+name = "fonttools"
+version = "4.61.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/33/f9/0e84d593c0e12244150280a630999835a64f2852276161b62a0f98318de0/fonttools-4.61.0.tar.gz", hash = "sha256:ec520a1f0c7758d7a858a00f090c1745f6cde6a7c5e76fb70ea4044a15f712e7", size = 3561884, upload-time = "2025-11-28T17:05:49.491Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/00/5d/19e5939f773c7cb05480fe2e881d63870b63ee2b4bdb9a77d55b1d36c7b9/fonttools-4.61.0-cp312-cp312-macosx_10_13_universal2.whl", hash = "sha256:e24a1565c4e57111ec7f4915f8981ecbb61adf66a55f378fdc00e206059fcfef", size = 2846930, upload-time = "2025-11-28T17:04:46.639Z" },
+ { url = "https://files.pythonhosted.org/packages/25/b2/0658faf66f705293bd7e739a4f038302d188d424926be9c59bdad945664b/fonttools-4.61.0-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:e2bfacb5351303cae9f072ccf3fc6ecb437a6f359c0606bae4b1ab6715201d87", size = 2383016, upload-time = "2025-11-28T17:04:48.525Z" },
+ { url = "https://files.pythonhosted.org/packages/29/a3/1fa90b95b690f0d7541f48850adc40e9019374d896c1b8148d15012b2458/fonttools-4.61.0-cp312-cp312-manylinux1_x86_64.manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_5_x86_64.whl", hash = "sha256:0bdcf2e29d65c26299cc3d502f4612365e8b90a939f46cd92d037b6cb7bb544a", size = 4949425, upload-time = "2025-11-28T17:04:50.482Z" },
+ { url = "https://files.pythonhosted.org/packages/af/00/acf18c00f6c501bd6e05ee930f926186f8a8e268265407065688820f1c94/fonttools-4.61.0-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:e6cd0d9051b8ddaf7385f99dd82ec2a058e2b46cf1f1961e68e1ff20fcbb61af", size = 4999632, upload-time = "2025-11-28T17:04:52.508Z" },
+ { url = "https://files.pythonhosted.org/packages/5f/e0/19a2b86e54109b1d2ee8743c96a1d297238ae03243897bc5345c0365f34d/fonttools-4.61.0-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:e074bc07c31406f45c418e17c1722e83560f181d122c412fa9e815df0ff74810", size = 4939438, upload-time = "2025-11-28T17:04:54.437Z" },
+ { url = "https://files.pythonhosted.org/packages/04/35/7b57a5f57d46286360355eff8d6b88c64ab6331107f37a273a71c803798d/fonttools-4.61.0-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:5a9b78da5d5faa17e63b2404b77feeae105c1b7e75f26020ab7a27b76e02039f", size = 5088960, upload-time = "2025-11-28T17:04:56.348Z" },
+ { url = "https://files.pythonhosted.org/packages/3e/0e/6c5023eb2e0fe5d1ababc7e221e44acd3ff668781489cc1937a6f83d620a/fonttools-4.61.0-cp312-cp312-win32.whl", hash = "sha256:9821ed77bb676736b88fa87a737c97b6af06e8109667e625a4f00158540ce044", size = 2264404, upload-time = "2025-11-28T17:04:58.149Z" },
+ { url = "https://files.pythonhosted.org/packages/36/0b/63273128c7c5df19b1e4cd92e0a1e6ea5bb74a400c4905054c96ad60a675/fonttools-4.61.0-cp312-cp312-win_amd64.whl", hash = "sha256:0011d640afa61053bc6590f9a3394bd222de7cfde19346588beabac374e9d8ac", size = 2314427, upload-time = "2025-11-28T17:04:59.812Z" },
+ { url = "https://files.pythonhosted.org/packages/17/45/334f0d7f181e5473cfb757e1b60f4e60e7fc64f28d406e5d364a952718c0/fonttools-4.61.0-cp313-cp313-macosx_10_13_universal2.whl", hash = "sha256:ba774b8cbd8754f54b8eb58124e8bd45f736b2743325ab1a5229698942b9b433", size = 2841801, upload-time = "2025-11-28T17:05:01.621Z" },
+ { url = "https://files.pythonhosted.org/packages/cc/63/97b9c78e1f79bc741d4efe6e51f13872d8edb2b36e1b9fb2bab0d4491bb7/fonttools-4.61.0-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:c84b430616ed73ce46e9cafd0bf0800e366a3e02fb7e1ad7c1e214dbe3862b1f", size = 2379024, upload-time = "2025-11-28T17:05:03.668Z" },
+ { url = "https://files.pythonhosted.org/packages/4e/80/c87bc524a90dbeb2a390eea23eae448286983da59b7e02c67fa0ca96a8c5/fonttools-4.61.0-cp313-cp313-manylinux1_x86_64.manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_5_x86_64.whl", hash = "sha256:b2b734d8391afe3c682320840c8191de9bd24e7eb85768dd4dc06ed1b63dbb1b", size = 4923706, upload-time = "2025-11-28T17:05:05.494Z" },
+ { url = "https://files.pythonhosted.org/packages/6d/f6/a3b0374811a1de8c3f9207ec88f61ad1bb96f938ed89babae26c065c2e46/fonttools-4.61.0-cp313-cp313-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:a5c5fff72bf31b0e558ed085e4fd7ed96eb85881404ecc39ed2a779e7cf724eb", size = 4979751, upload-time = "2025-11-28T17:05:07.665Z" },
+ { url = "https://files.pythonhosted.org/packages/a5/3b/30f63b4308b449091573285f9d27619563a84f399946bca3eadc9554afbe/fonttools-4.61.0-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:14a290c5c93fcab76b7f451e6a4b7721b712d90b3b5ed6908f1abcf794e90d6d", size = 4921113, upload-time = "2025-11-28T17:05:09.551Z" },
+ { url = "https://files.pythonhosted.org/packages/41/6c/58e6e9b7d9d8bf2d7010bd7bb493060b39b02a12d1cda64a8bfb116ce760/fonttools-4.61.0-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:13e3e20a5463bfeb77b3557d04b30bd6a96a6bb5c15c7b2e7908903e69d437a0", size = 5063183, upload-time = "2025-11-28T17:05:11.677Z" },
+ { url = "https://files.pythonhosted.org/packages/3f/e3/52c790ab2b07492df059947a1fd7778e105aac5848c0473029a4d20481a2/fonttools-4.61.0-cp313-cp313-win32.whl", hash = "sha256:6781e7a4bb010be1cd69a29927b0305c86b843395f2613bdabe115f7d6ea7f34", size = 2263159, upload-time = "2025-11-28T17:05:13.292Z" },
+ { url = "https://files.pythonhosted.org/packages/e9/1f/116013b200fbeba871046554d5d2a45fefa69a05c40e9cdfd0d4fff53edc/fonttools-4.61.0-cp313-cp313-win_amd64.whl", hash = "sha256:c53b47834ae41e8e4829171cc44fec0fdf125545a15f6da41776b926b9645a9a", size = 2313530, upload-time = "2025-11-28T17:05:14.848Z" },
+ { url = "https://files.pythonhosted.org/packages/d3/99/59b1e25987787cb714aa9457cee4c9301b7c2153f0b673e2b8679d37669d/fonttools-4.61.0-cp314-cp314-macosx_10_15_universal2.whl", hash = "sha256:96dfc9bc1f2302224e48e6ee37e656eddbab810b724b52e9d9c13a57a6abad01", size = 2841429, upload-time = "2025-11-28T17:05:16.671Z" },
+ { url = "https://files.pythonhosted.org/packages/2b/b2/4c1911d4332c8a144bb3b44416e274ccca0e297157c971ea1b3fbb855590/fonttools-4.61.0-cp314-cp314-macosx_10_15_x86_64.whl", hash = "sha256:3b2065d94e5d63aafc2591c8b6ccbdb511001d9619f1bca8ad39b745ebeb5efa", size = 2378987, upload-time = "2025-11-28T17:05:18.69Z" },
+ { url = "https://files.pythonhosted.org/packages/24/b0/f442e90fde5d2af2ae0cb54008ab6411edc557ee33b824e13e1d04925ac9/fonttools-4.61.0-cp314-cp314-manylinux1_x86_64.manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_5_x86_64.whl", hash = "sha256:e0d87e81e4d869549585ba0beb3f033718501c1095004f5e6aef598d13ebc216", size = 4873270, upload-time = "2025-11-28T17:05:20.625Z" },
+ { url = "https://files.pythonhosted.org/packages/bb/04/f5d5990e33053c8a59b90b1d7e10ad9b97a73f42c745304da0e709635fab/fonttools-4.61.0-cp314-cp314-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:1cfa2eb9bae650e58f0e8ad53c49d19a844d6034d6b259f30f197238abc1ccee", size = 4968270, upload-time = "2025-11-28T17:05:22.515Z" },
+ { url = "https://files.pythonhosted.org/packages/94/9f/2091402e0d27c9c8c4bab5de0e5cd146d9609a2d7d1c666bbb75c0011c1a/fonttools-4.61.0-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:4238120002e68296d55e091411c09eab94e111c8ce64716d17df53fd0eb3bb3d", size = 4919799, upload-time = "2025-11-28T17:05:24.437Z" },
+ { url = "https://files.pythonhosted.org/packages/a8/72/86adab22fde710b829f8ffbc8f264df01928e5b7a8f6177fa29979ebf256/fonttools-4.61.0-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:b6ceac262cc62bec01b3bb59abccf41b24ef6580869e306a4e88b7e56bb4bdda", size = 5030966, upload-time = "2025-11-28T17:05:26.115Z" },
+ { url = "https://files.pythonhosted.org/packages/e8/a7/7c8e31b003349e845b853f5e0a67b95ff6b052fa4f5224f8b72624f5ac69/fonttools-4.61.0-cp314-cp314-win32.whl", hash = "sha256:adbb4ecee1a779469a77377bbe490565effe8fce6fb2e6f95f064de58f8bac85", size = 2267243, upload-time = "2025-11-28T17:05:27.807Z" },
+ { url = "https://files.pythonhosted.org/packages/20/ee/f434fe7749360497c52b7dcbcfdbccdaab0a71c59f19d572576066717122/fonttools-4.61.0-cp314-cp314-win_amd64.whl", hash = "sha256:02bdf8e04d1a70476564b8640380f04bb4ac74edc1fc71f1bacb840b3e398ee9", size = 2318822, upload-time = "2025-11-28T17:05:29.882Z" },
+ { url = "https://files.pythonhosted.org/packages/33/b3/c16255320255e5c1863ca2b2599bb61a46e2f566db0bbb9948615a8fe692/fonttools-4.61.0-cp314-cp314t-macosx_10_15_universal2.whl", hash = "sha256:627216062d90ab0d98215176d8b9562c4dd5b61271d35f130bcd30f6a8aaa33a", size = 2924917, upload-time = "2025-11-28T17:05:31.46Z" },
+ { url = "https://files.pythonhosted.org/packages/e2/b8/08067ae21de705a817777c02ef36ab0b953cbe91d8adf134f9c2da75ed6d/fonttools-4.61.0-cp314-cp314t-macosx_10_15_x86_64.whl", hash = "sha256:7b446623c9cd5f14a59493818eaa80255eec2468c27d2c01b56e05357c263195", size = 2413576, upload-time = "2025-11-28T17:05:33.343Z" },
+ { url = "https://files.pythonhosted.org/packages/42/f1/96ff43f92addce2356780fdc203f2966206f3d22ea20e242c27826fd7442/fonttools-4.61.0-cp314-cp314t-manylinux1_x86_64.manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_5_x86_64.whl", hash = "sha256:70e2a0c0182ee75e493ef33061bfebf140ea57e035481d2f95aa03b66c7a0e05", size = 4877447, upload-time = "2025-11-28T17:05:35.278Z" },
+ { url = "https://files.pythonhosted.org/packages/d0/1e/a3d8e51ed9ccfd7385e239ae374b78d258a0fb82d82cab99160a014a45d1/fonttools-4.61.0-cp314-cp314t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:9064b0f55b947e929ac669af5311ab1f26f750214db6dd9a0c97e091e918f486", size = 5095681, upload-time = "2025-11-28T17:05:37.142Z" },
+ { url = "https://files.pythonhosted.org/packages/eb/f6/d256bd6c1065c146a0bdddf1c62f542e08ae5b3405dbf3fcc52be272f674/fonttools-4.61.0-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:2cb5e45a824ce14b90510024d0d39dae51bd4fbb54c42a9334ea8c8cf4d95cbe", size = 4974140, upload-time = "2025-11-28T17:05:39.5Z" },
+ { url = "https://files.pythonhosted.org/packages/5d/0c/96633eb4b26f138cc48561c6e0c44b4ea48acea56b20b507d6b14f8e80ce/fonttools-4.61.0-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:6e5ca8c62efdec7972dfdfd454415c4db49b89aeaefaaacada432f3b7eea9866", size = 5001741, upload-time = "2025-11-28T17:05:41.424Z" },
+ { url = "https://files.pythonhosted.org/packages/6f/9a/3b536bad3be4f26186f296e749ff17bad3e6d57232c104d752d24b2e265b/fonttools-4.61.0-cp314-cp314t-win32.whl", hash = "sha256:63c7125d31abe3e61d7bb917329b5543c5b3448db95f24081a13aaf064360fc8", size = 2330707, upload-time = "2025-11-28T17:05:43.548Z" },
+ { url = "https://files.pythonhosted.org/packages/18/ea/e6b9ac610451ee9f04477c311ad126de971f6112cb579fa391d2a8edb00b/fonttools-4.61.0-cp314-cp314t-win_amd64.whl", hash = "sha256:67d841aa272be5500de7f447c40d1d8452783af33b4c3599899319f6ef9ad3c1", size = 2395950, upload-time = "2025-11-28T17:05:45.638Z" },
+ { url = "https://files.pythonhosted.org/packages/0c/14/634f7daea5ffe6a5f7a0322ba8e1a0e23c9257b80aa91458107896d1dfc7/fonttools-4.61.0-py3-none-any.whl", hash = "sha256:276f14c560e6f98d24ef7f5f44438e55ff5a67f78fa85236b218462c9f5d0635", size = 1144485, upload-time = "2025-11-28T17:05:47.573Z" },
+]
+
+[[package]]
+name = "fqdn"
+version = "1.5.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/30/3e/a80a8c077fd798951169626cde3e239adeba7dab75deb3555716415bd9b0/fqdn-1.5.1.tar.gz", hash = "sha256:105ed3677e767fb5ca086a0c1f4bb66ebc3c100be518f0e0d755d9eae164d89f", size = 6015, upload-time = "2021-03-11T07:16:29.08Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/cf/58/8acf1b3e91c58313ce5cb67df61001fc9dcd21be4fadb76c1a2d540e09ed/fqdn-1.5.1-py3-none-any.whl", hash = "sha256:3a179af3761e4df6eb2e026ff9e1a3033d3587bf980a0b1b2e1e5d08d7358014", size = 9121, upload-time = "2021-03-11T07:16:28.351Z" },
+]
+
+[[package]]
+name = "frozenlist"
+version = "1.8.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/2d/f5/c831fac6cc817d26fd54c7eaccd04ef7e0288806943f7cc5bbf69f3ac1f0/frozenlist-1.8.0.tar.gz", hash = "sha256:3ede829ed8d842f6cd48fc7081d7a41001a56f1f38603f9d49bf3020d59a31ad", size = 45875, upload-time = "2025-10-06T05:38:17.865Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/69/29/948b9aa87e75820a38650af445d2ef2b6b8a6fab1a23b6bb9e4ef0be2d59/frozenlist-1.8.0-cp312-cp312-macosx_10_13_universal2.whl", hash = "sha256:78f7b9e5d6f2fdb88cdde9440dc147259b62b9d3b019924def9f6478be254ac1", size = 87782, upload-time = "2025-10-06T05:36:06.649Z" },
+ { url = "https://files.pythonhosted.org/packages/64/80/4f6e318ee2a7c0750ed724fa33a4bdf1eacdc5a39a7a24e818a773cd91af/frozenlist-1.8.0-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:229bf37d2e4acdaf808fd3f06e854a4a7a3661e871b10dc1f8f1896a3b05f18b", size = 50594, upload-time = "2025-10-06T05:36:07.69Z" },
+ { url = "https://files.pythonhosted.org/packages/2b/94/5c8a2b50a496b11dd519f4a24cb5496cf125681dd99e94c604ccdea9419a/frozenlist-1.8.0-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:f833670942247a14eafbb675458b4e61c82e002a148f49e68257b79296e865c4", size = 50448, upload-time = "2025-10-06T05:36:08.78Z" },
+ { url = "https://files.pythonhosted.org/packages/6a/bd/d91c5e39f490a49df14320f4e8c80161cfcce09f1e2cde1edd16a551abb3/frozenlist-1.8.0-cp312-cp312-manylinux1_x86_64.manylinux_2_28_x86_64.manylinux_2_5_x86_64.whl", hash = "sha256:494a5952b1c597ba44e0e78113a7266e656b9794eec897b19ead706bd7074383", size = 242411, upload-time = "2025-10-06T05:36:09.801Z" },
+ { url = "https://files.pythonhosted.org/packages/8f/83/f61505a05109ef3293dfb1ff594d13d64a2324ac3482be2cedc2be818256/frozenlist-1.8.0-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:96f423a119f4777a4a056b66ce11527366a8bb92f54e541ade21f2374433f6d4", size = 243014, upload-time = "2025-10-06T05:36:11.394Z" },
+ { url = "https://files.pythonhosted.org/packages/d8/cb/cb6c7b0f7d4023ddda30cf56b8b17494eb3a79e3fda666bf735f63118b35/frozenlist-1.8.0-cp312-cp312-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:3462dd9475af2025c31cc61be6652dfa25cbfb56cbbf52f4ccfe029f38decaf8", size = 234909, upload-time = "2025-10-06T05:36:12.598Z" },
+ { url = "https://files.pythonhosted.org/packages/31/c5/cd7a1f3b8b34af009fb17d4123c5a778b44ae2804e3ad6b86204255f9ec5/frozenlist-1.8.0-cp312-cp312-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:c4c800524c9cd9bac5166cd6f55285957fcfc907db323e193f2afcd4d9abd69b", size = 250049, upload-time = "2025-10-06T05:36:14.065Z" },
+ { url = "https://files.pythonhosted.org/packages/c0/01/2f95d3b416c584a1e7f0e1d6d31998c4a795f7544069ee2e0962a4b60740/frozenlist-1.8.0-cp312-cp312-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:d6a5df73acd3399d893dafc71663ad22534b5aa4f94e8a2fabfe856c3c1b6a52", size = 256485, upload-time = "2025-10-06T05:36:15.39Z" },
+ { url = "https://files.pythonhosted.org/packages/ce/03/024bf7720b3abaebcff6d0793d73c154237b85bdf67b7ed55e5e9596dc9a/frozenlist-1.8.0-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:405e8fe955c2280ce66428b3ca55e12b3c4e9c336fb2103a4937e891c69a4a29", size = 237619, upload-time = "2025-10-06T05:36:16.558Z" },
+ { url = "https://files.pythonhosted.org/packages/69/fa/f8abdfe7d76b731f5d8bd217827cf6764d4f1d9763407e42717b4bed50a0/frozenlist-1.8.0-cp312-cp312-musllinux_1_2_armv7l.whl", hash = "sha256:908bd3f6439f2fef9e85031b59fd4f1297af54415fb60e4254a95f75b3cab3f3", size = 250320, upload-time = "2025-10-06T05:36:17.821Z" },
+ { url = "https://files.pythonhosted.org/packages/f5/3c/b051329f718b463b22613e269ad72138cc256c540f78a6de89452803a47d/frozenlist-1.8.0-cp312-cp312-musllinux_1_2_ppc64le.whl", hash = "sha256:294e487f9ec720bd8ffcebc99d575f7eff3568a08a253d1ee1a0378754b74143", size = 246820, upload-time = "2025-10-06T05:36:19.046Z" },
+ { url = "https://files.pythonhosted.org/packages/0f/ae/58282e8f98e444b3f4dd42448ff36fa38bef29e40d40f330b22e7108f565/frozenlist-1.8.0-cp312-cp312-musllinux_1_2_s390x.whl", hash = "sha256:74c51543498289c0c43656701be6b077f4b265868fa7f8a8859c197006efb608", size = 250518, upload-time = "2025-10-06T05:36:20.763Z" },
+ { url = "https://files.pythonhosted.org/packages/8f/96/007e5944694d66123183845a106547a15944fbbb7154788cbf7272789536/frozenlist-1.8.0-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:776f352e8329135506a1d6bf16ac3f87bc25b28e765949282dcc627af36123aa", size = 239096, upload-time = "2025-10-06T05:36:22.129Z" },
+ { url = "https://files.pythonhosted.org/packages/66/bb/852b9d6db2fa40be96f29c0d1205c306288f0684df8fd26ca1951d461a56/frozenlist-1.8.0-cp312-cp312-win32.whl", hash = "sha256:433403ae80709741ce34038da08511d4a77062aa924baf411ef73d1146e74faf", size = 39985, upload-time = "2025-10-06T05:36:23.661Z" },
+ { url = "https://files.pythonhosted.org/packages/b8/af/38e51a553dd66eb064cdf193841f16f077585d4d28394c2fa6235cb41765/frozenlist-1.8.0-cp312-cp312-win_amd64.whl", hash = "sha256:34187385b08f866104f0c0617404c8eb08165ab1272e884abc89c112e9c00746", size = 44591, upload-time = "2025-10-06T05:36:24.958Z" },
+ { url = "https://files.pythonhosted.org/packages/a7/06/1dc65480ab147339fecc70797e9c2f69d9cea9cf38934ce08df070fdb9cb/frozenlist-1.8.0-cp312-cp312-win_arm64.whl", hash = "sha256:fe3c58d2f5db5fbd18c2987cba06d51b0529f52bc3a6cdc33d3f4eab725104bd", size = 40102, upload-time = "2025-10-06T05:36:26.333Z" },
+ { url = "https://files.pythonhosted.org/packages/2d/40/0832c31a37d60f60ed79e9dfb5a92e1e2af4f40a16a29abcc7992af9edff/frozenlist-1.8.0-cp313-cp313-macosx_10_13_universal2.whl", hash = "sha256:8d92f1a84bb12d9e56f818b3a746f3efba93c1b63c8387a73dde655e1e42282a", size = 85717, upload-time = "2025-10-06T05:36:27.341Z" },
+ { url = "https://files.pythonhosted.org/packages/30/ba/b0b3de23f40bc55a7057bd38434e25c34fa48e17f20ee273bbde5e0650f3/frozenlist-1.8.0-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:96153e77a591c8adc2ee805756c61f59fef4cf4073a9275ee86fe8cba41241f7", size = 49651, upload-time = "2025-10-06T05:36:28.855Z" },
+ { url = "https://files.pythonhosted.org/packages/0c/ab/6e5080ee374f875296c4243c381bbdef97a9ac39c6e3ce1d5f7d42cb78d6/frozenlist-1.8.0-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:f21f00a91358803399890ab167098c131ec2ddd5f8f5fd5fe9c9f2c6fcd91e40", size = 49417, upload-time = "2025-10-06T05:36:29.877Z" },
+ { url = "https://files.pythonhosted.org/packages/d5/4e/e4691508f9477ce67da2015d8c00acd751e6287739123113a9fca6f1604e/frozenlist-1.8.0-cp313-cp313-manylinux1_x86_64.manylinux_2_28_x86_64.manylinux_2_5_x86_64.whl", hash = "sha256:fb30f9626572a76dfe4293c7194a09fb1fe93ba94c7d4f720dfae3b646b45027", size = 234391, upload-time = "2025-10-06T05:36:31.301Z" },
+ { url = "https://files.pythonhosted.org/packages/40/76/c202df58e3acdf12969a7895fd6f3bc016c642e6726aa63bd3025e0fc71c/frozenlist-1.8.0-cp313-cp313-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:eaa352d7047a31d87dafcacbabe89df0aa506abb5b1b85a2fb91bc3faa02d822", size = 233048, upload-time = "2025-10-06T05:36:32.531Z" },
+ { url = "https://files.pythonhosted.org/packages/f9/c0/8746afb90f17b73ca5979c7a3958116e105ff796e718575175319b5bb4ce/frozenlist-1.8.0-cp313-cp313-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:03ae967b4e297f58f8c774c7eabcce57fe3c2434817d4385c50661845a058121", size = 226549, upload-time = "2025-10-06T05:36:33.706Z" },
+ { url = "https://files.pythonhosted.org/packages/7e/eb/4c7eefc718ff72f9b6c4893291abaae5fbc0c82226a32dcd8ef4f7a5dbef/frozenlist-1.8.0-cp313-cp313-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:f6292f1de555ffcc675941d65fffffb0a5bcd992905015f85d0592201793e0e5", size = 239833, upload-time = "2025-10-06T05:36:34.947Z" },
+ { url = "https://files.pythonhosted.org/packages/c2/4e/e5c02187cf704224f8b21bee886f3d713ca379535f16893233b9d672ea71/frozenlist-1.8.0-cp313-cp313-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:29548f9b5b5e3460ce7378144c3010363d8035cea44bc0bf02d57f5a685e084e", size = 245363, upload-time = "2025-10-06T05:36:36.534Z" },
+ { url = "https://files.pythonhosted.org/packages/1f/96/cb85ec608464472e82ad37a17f844889c36100eed57bea094518bf270692/frozenlist-1.8.0-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:ec3cc8c5d4084591b4237c0a272cc4f50a5b03396a47d9caaf76f5d7b38a4f11", size = 229314, upload-time = "2025-10-06T05:36:38.582Z" },
+ { url = "https://files.pythonhosted.org/packages/5d/6f/4ae69c550e4cee66b57887daeebe006fe985917c01d0fff9caab9883f6d0/frozenlist-1.8.0-cp313-cp313-musllinux_1_2_armv7l.whl", hash = "sha256:517279f58009d0b1f2e7c1b130b377a349405da3f7621ed6bfae50b10adf20c1", size = 243365, upload-time = "2025-10-06T05:36:40.152Z" },
+ { url = "https://files.pythonhosted.org/packages/7a/58/afd56de246cf11780a40a2c28dc7cbabbf06337cc8ddb1c780a2d97e88d8/frozenlist-1.8.0-cp313-cp313-musllinux_1_2_ppc64le.whl", hash = "sha256:db1e72ede2d0d7ccb213f218df6a078a9c09a7de257c2fe8fcef16d5925230b1", size = 237763, upload-time = "2025-10-06T05:36:41.355Z" },
+ { url = "https://files.pythonhosted.org/packages/cb/36/cdfaf6ed42e2644740d4a10452d8e97fa1c062e2a8006e4b09f1b5fd7d63/frozenlist-1.8.0-cp313-cp313-musllinux_1_2_s390x.whl", hash = "sha256:b4dec9482a65c54a5044486847b8a66bf10c9cb4926d42927ec4e8fd5db7fed8", size = 240110, upload-time = "2025-10-06T05:36:42.716Z" },
+ { url = "https://files.pythonhosted.org/packages/03/a8/9ea226fbefad669f11b52e864c55f0bd57d3c8d7eb07e9f2e9a0b39502e1/frozenlist-1.8.0-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:21900c48ae04d13d416f0e1e0c4d81f7931f73a9dfa0b7a8746fb2fe7dd970ed", size = 233717, upload-time = "2025-10-06T05:36:44.251Z" },
+ { url = "https://files.pythonhosted.org/packages/1e/0b/1b5531611e83ba7d13ccc9988967ea1b51186af64c42b7a7af465dcc9568/frozenlist-1.8.0-cp313-cp313-win32.whl", hash = "sha256:8b7b94a067d1c504ee0b16def57ad5738701e4ba10cec90529f13fa03c833496", size = 39628, upload-time = "2025-10-06T05:36:45.423Z" },
+ { url = "https://files.pythonhosted.org/packages/d8/cf/174c91dbc9cc49bc7b7aab74d8b734e974d1faa8f191c74af9b7e80848e6/frozenlist-1.8.0-cp313-cp313-win_amd64.whl", hash = "sha256:878be833caa6a3821caf85eb39c5ba92d28e85df26d57afb06b35b2efd937231", size = 43882, upload-time = "2025-10-06T05:36:46.796Z" },
+ { url = "https://files.pythonhosted.org/packages/c1/17/502cd212cbfa96eb1388614fe39a3fc9ab87dbbe042b66f97acb57474834/frozenlist-1.8.0-cp313-cp313-win_arm64.whl", hash = "sha256:44389d135b3ff43ba8cc89ff7f51f5a0bb6b63d829c8300f79a2fe4fe61bcc62", size = 39676, upload-time = "2025-10-06T05:36:47.8Z" },
+ { url = "https://files.pythonhosted.org/packages/d2/5c/3bbfaa920dfab09e76946a5d2833a7cbdf7b9b4a91c714666ac4855b88b4/frozenlist-1.8.0-cp313-cp313t-macosx_10_13_universal2.whl", hash = "sha256:e25ac20a2ef37e91c1b39938b591457666a0fa835c7783c3a8f33ea42870db94", size = 89235, upload-time = "2025-10-06T05:36:48.78Z" },
+ { url = "https://files.pythonhosted.org/packages/d2/d6/f03961ef72166cec1687e84e8925838442b615bd0b8854b54923ce5b7b8a/frozenlist-1.8.0-cp313-cp313t-macosx_10_13_x86_64.whl", hash = "sha256:07cdca25a91a4386d2e76ad992916a85038a9b97561bf7a3fd12d5d9ce31870c", size = 50742, upload-time = "2025-10-06T05:36:49.837Z" },
+ { url = "https://files.pythonhosted.org/packages/1e/bb/a6d12b7ba4c3337667d0e421f7181c82dda448ce4e7ad7ecd249a16fa806/frozenlist-1.8.0-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:4e0c11f2cc6717e0a741f84a527c52616140741cd812a50422f83dc31749fb52", size = 51725, upload-time = "2025-10-06T05:36:50.851Z" },
+ { url = "https://files.pythonhosted.org/packages/bc/71/d1fed0ffe2c2ccd70b43714c6cab0f4188f09f8a67a7914a6b46ee30f274/frozenlist-1.8.0-cp313-cp313t-manylinux1_x86_64.manylinux_2_28_x86_64.manylinux_2_5_x86_64.whl", hash = "sha256:b3210649ee28062ea6099cfda39e147fa1bc039583c8ee4481cb7811e2448c51", size = 284533, upload-time = "2025-10-06T05:36:51.898Z" },
+ { url = "https://files.pythonhosted.org/packages/c9/1f/fb1685a7b009d89f9bf78a42d94461bc06581f6e718c39344754a5d9bada/frozenlist-1.8.0-cp313-cp313t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:581ef5194c48035a7de2aefc72ac6539823bb71508189e5de01d60c9dcd5fa65", size = 292506, upload-time = "2025-10-06T05:36:53.101Z" },
+ { url = "https://files.pythonhosted.org/packages/e6/3b/b991fe1612703f7e0d05c0cf734c1b77aaf7c7d321df4572e8d36e7048c8/frozenlist-1.8.0-cp313-cp313t-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:3ef2d026f16a2b1866e1d86fc4e1291e1ed8a387b2c333809419a2f8b3a77b82", size = 274161, upload-time = "2025-10-06T05:36:54.309Z" },
+ { url = "https://files.pythonhosted.org/packages/ca/ec/c5c618767bcdf66e88945ec0157d7f6c4a1322f1473392319b7a2501ded7/frozenlist-1.8.0-cp313-cp313t-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:5500ef82073f599ac84d888e3a8c1f77ac831183244bfd7f11eaa0289fb30714", size = 294676, upload-time = "2025-10-06T05:36:55.566Z" },
+ { url = "https://files.pythonhosted.org/packages/7c/ce/3934758637d8f8a88d11f0585d6495ef54b2044ed6ec84492a91fa3b27aa/frozenlist-1.8.0-cp313-cp313t-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:50066c3997d0091c411a66e710f4e11752251e6d2d73d70d8d5d4c76442a199d", size = 300638, upload-time = "2025-10-06T05:36:56.758Z" },
+ { url = "https://files.pythonhosted.org/packages/fc/4f/a7e4d0d467298f42de4b41cbc7ddaf19d3cfeabaf9ff97c20c6c7ee409f9/frozenlist-1.8.0-cp313-cp313t-musllinux_1_2_aarch64.whl", hash = "sha256:5c1c8e78426e59b3f8005e9b19f6ff46e5845895adbde20ece9218319eca6506", size = 283067, upload-time = "2025-10-06T05:36:57.965Z" },
+ { url = "https://files.pythonhosted.org/packages/dc/48/c7b163063d55a83772b268e6d1affb960771b0e203b632cfe09522d67ea5/frozenlist-1.8.0-cp313-cp313t-musllinux_1_2_armv7l.whl", hash = "sha256:eefdba20de0d938cec6a89bd4d70f346a03108a19b9df4248d3cf0d88f1b0f51", size = 292101, upload-time = "2025-10-06T05:36:59.237Z" },
+ { url = "https://files.pythonhosted.org/packages/9f/d0/2366d3c4ecdc2fd391e0afa6e11500bfba0ea772764d631bbf82f0136c9d/frozenlist-1.8.0-cp313-cp313t-musllinux_1_2_ppc64le.whl", hash = "sha256:cf253e0e1c3ceb4aaff6df637ce033ff6535fb8c70a764a8f46aafd3d6ab798e", size = 289901, upload-time = "2025-10-06T05:37:00.811Z" },
+ { url = "https://files.pythonhosted.org/packages/b8/94/daff920e82c1b70e3618a2ac39fbc01ae3e2ff6124e80739ce5d71c9b920/frozenlist-1.8.0-cp313-cp313t-musllinux_1_2_s390x.whl", hash = "sha256:032efa2674356903cd0261c4317a561a6850f3ac864a63fc1583147fb05a79b0", size = 289395, upload-time = "2025-10-06T05:37:02.115Z" },
+ { url = "https://files.pythonhosted.org/packages/e3/20/bba307ab4235a09fdcd3cc5508dbabd17c4634a1af4b96e0f69bfe551ebd/frozenlist-1.8.0-cp313-cp313t-musllinux_1_2_x86_64.whl", hash = "sha256:6da155091429aeba16851ecb10a9104a108bcd32f6c1642867eadaee401c1c41", size = 283659, upload-time = "2025-10-06T05:37:03.711Z" },
+ { url = "https://files.pythonhosted.org/packages/fd/00/04ca1c3a7a124b6de4f8a9a17cc2fcad138b4608e7a3fc5877804b8715d7/frozenlist-1.8.0-cp313-cp313t-win32.whl", hash = "sha256:0f96534f8bfebc1a394209427d0f8a63d343c9779cda6fc25e8e121b5fd8555b", size = 43492, upload-time = "2025-10-06T05:37:04.915Z" },
+ { url = "https://files.pythonhosted.org/packages/59/5e/c69f733a86a94ab10f68e496dc6b7e8bc078ebb415281d5698313e3af3a1/frozenlist-1.8.0-cp313-cp313t-win_amd64.whl", hash = "sha256:5d63a068f978fc69421fb0e6eb91a9603187527c86b7cd3f534a5b77a592b888", size = 48034, upload-time = "2025-10-06T05:37:06.343Z" },
+ { url = "https://files.pythonhosted.org/packages/16/6c/be9d79775d8abe79b05fa6d23da99ad6e7763a1d080fbae7290b286093fd/frozenlist-1.8.0-cp313-cp313t-win_arm64.whl", hash = "sha256:bf0a7e10b077bf5fb9380ad3ae8ce20ef919a6ad93b4552896419ac7e1d8e042", size = 41749, upload-time = "2025-10-06T05:37:07.431Z" },
+ { url = "https://files.pythonhosted.org/packages/f1/c8/85da824b7e7b9b6e7f7705b2ecaf9591ba6f79c1177f324c2735e41d36a2/frozenlist-1.8.0-cp314-cp314-macosx_10_13_universal2.whl", hash = "sha256:cee686f1f4cadeb2136007ddedd0aaf928ab95216e7691c63e50a8ec066336d0", size = 86127, upload-time = "2025-10-06T05:37:08.438Z" },
+ { url = "https://files.pythonhosted.org/packages/8e/e8/a1185e236ec66c20afd72399522f142c3724c785789255202d27ae992818/frozenlist-1.8.0-cp314-cp314-macosx_10_13_x86_64.whl", hash = "sha256:119fb2a1bd47307e899c2fac7f28e85b9a543864df47aa7ec9d3c1b4545f096f", size = 49698, upload-time = "2025-10-06T05:37:09.48Z" },
+ { url = "https://files.pythonhosted.org/packages/a1/93/72b1736d68f03fda5fdf0f2180fb6caaae3894f1b854d006ac61ecc727ee/frozenlist-1.8.0-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:4970ece02dbc8c3a92fcc5228e36a3e933a01a999f7094ff7c23fbd2beeaa67c", size = 49749, upload-time = "2025-10-06T05:37:10.569Z" },
+ { url = "https://files.pythonhosted.org/packages/a7/b2/fabede9fafd976b991e9f1b9c8c873ed86f202889b864756f240ce6dd855/frozenlist-1.8.0-cp314-cp314-manylinux1_x86_64.manylinux_2_28_x86_64.manylinux_2_5_x86_64.whl", hash = "sha256:cba69cb73723c3f329622e34bdbf5ce1f80c21c290ff04256cff1cd3c2036ed2", size = 231298, upload-time = "2025-10-06T05:37:11.993Z" },
+ { url = "https://files.pythonhosted.org/packages/3a/3b/d9b1e0b0eed36e70477ffb8360c49c85c8ca8ef9700a4e6711f39a6e8b45/frozenlist-1.8.0-cp314-cp314-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:778a11b15673f6f1df23d9586f83c4846c471a8af693a22e066508b77d201ec8", size = 232015, upload-time = "2025-10-06T05:37:13.194Z" },
+ { url = "https://files.pythonhosted.org/packages/dc/94/be719d2766c1138148564a3960fc2c06eb688da592bdc25adcf856101be7/frozenlist-1.8.0-cp314-cp314-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:0325024fe97f94c41c08872db482cf8ac4800d80e79222c6b0b7b162d5b13686", size = 225038, upload-time = "2025-10-06T05:37:14.577Z" },
+ { url = "https://files.pythonhosted.org/packages/e4/09/6712b6c5465f083f52f50cf74167b92d4ea2f50e46a9eea0523d658454ae/frozenlist-1.8.0-cp314-cp314-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:97260ff46b207a82a7567b581ab4190bd4dfa09f4db8a8b49d1a958f6aa4940e", size = 240130, upload-time = "2025-10-06T05:37:15.781Z" },
+ { url = "https://files.pythonhosted.org/packages/f8/d4/cd065cdcf21550b54f3ce6a22e143ac9e4836ca42a0de1022da8498eac89/frozenlist-1.8.0-cp314-cp314-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:54b2077180eb7f83dd52c40b2750d0a9f175e06a42e3213ce047219de902717a", size = 242845, upload-time = "2025-10-06T05:37:17.037Z" },
+ { url = "https://files.pythonhosted.org/packages/62/c3/f57a5c8c70cd1ead3d5d5f776f89d33110b1addae0ab010ad774d9a44fb9/frozenlist-1.8.0-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:2f05983daecab868a31e1da44462873306d3cbfd76d1f0b5b69c473d21dbb128", size = 229131, upload-time = "2025-10-06T05:37:18.221Z" },
+ { url = "https://files.pythonhosted.org/packages/6c/52/232476fe9cb64f0742f3fde2b7d26c1dac18b6d62071c74d4ded55e0ef94/frozenlist-1.8.0-cp314-cp314-musllinux_1_2_armv7l.whl", hash = "sha256:33f48f51a446114bc5d251fb2954ab0164d5be02ad3382abcbfe07e2531d650f", size = 240542, upload-time = "2025-10-06T05:37:19.771Z" },
+ { url = "https://files.pythonhosted.org/packages/5f/85/07bf3f5d0fb5414aee5f47d33c6f5c77bfe49aac680bfece33d4fdf6a246/frozenlist-1.8.0-cp314-cp314-musllinux_1_2_ppc64le.whl", hash = "sha256:154e55ec0655291b5dd1b8731c637ecdb50975a2ae70c606d100750a540082f7", size = 237308, upload-time = "2025-10-06T05:37:20.969Z" },
+ { url = "https://files.pythonhosted.org/packages/11/99/ae3a33d5befd41ac0ca2cc7fd3aa707c9c324de2e89db0e0f45db9a64c26/frozenlist-1.8.0-cp314-cp314-musllinux_1_2_s390x.whl", hash = "sha256:4314debad13beb564b708b4a496020e5306c7333fa9a3ab90374169a20ffab30", size = 238210, upload-time = "2025-10-06T05:37:22.252Z" },
+ { url = "https://files.pythonhosted.org/packages/b2/60/b1d2da22f4970e7a155f0adde9b1435712ece01b3cd45ba63702aea33938/frozenlist-1.8.0-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:073f8bf8becba60aa931eb3bc420b217bb7d5b8f4750e6f8b3be7f3da85d38b7", size = 231972, upload-time = "2025-10-06T05:37:23.5Z" },
+ { url = "https://files.pythonhosted.org/packages/3f/ab/945b2f32de889993b9c9133216c068b7fcf257d8595a0ac420ac8677cab0/frozenlist-1.8.0-cp314-cp314-win32.whl", hash = "sha256:bac9c42ba2ac65ddc115d930c78d24ab8d4f465fd3fc473cdedfccadb9429806", size = 40536, upload-time = "2025-10-06T05:37:25.581Z" },
+ { url = "https://files.pythonhosted.org/packages/59/ad/9caa9b9c836d9ad6f067157a531ac48b7d36499f5036d4141ce78c230b1b/frozenlist-1.8.0-cp314-cp314-win_amd64.whl", hash = "sha256:3e0761f4d1a44f1d1a47996511752cf3dcec5bbdd9cc2b4fe595caf97754b7a0", size = 44330, upload-time = "2025-10-06T05:37:26.928Z" },
+ { url = "https://files.pythonhosted.org/packages/82/13/e6950121764f2676f43534c555249f57030150260aee9dcf7d64efda11dd/frozenlist-1.8.0-cp314-cp314-win_arm64.whl", hash = "sha256:d1eaff1d00c7751b7c6662e9c5ba6eb2c17a2306ba5e2a37f24ddf3cc953402b", size = 40627, upload-time = "2025-10-06T05:37:28.075Z" },
+ { url = "https://files.pythonhosted.org/packages/c0/c7/43200656ecc4e02d3f8bc248df68256cd9572b3f0017f0a0c4e93440ae23/frozenlist-1.8.0-cp314-cp314t-macosx_10_13_universal2.whl", hash = "sha256:d3bb933317c52d7ea5004a1c442eef86f426886fba134ef8cf4226ea6ee1821d", size = 89238, upload-time = "2025-10-06T05:37:29.373Z" },
+ { url = "https://files.pythonhosted.org/packages/d1/29/55c5f0689b9c0fb765055629f472c0de484dcaf0acee2f7707266ae3583c/frozenlist-1.8.0-cp314-cp314t-macosx_10_13_x86_64.whl", hash = "sha256:8009897cdef112072f93a0efdce29cd819e717fd2f649ee3016efd3cd885a7ed", size = 50738, upload-time = "2025-10-06T05:37:30.792Z" },
+ { url = "https://files.pythonhosted.org/packages/ba/7d/b7282a445956506fa11da8c2db7d276adcbf2b17d8bb8407a47685263f90/frozenlist-1.8.0-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:2c5dcbbc55383e5883246d11fd179782a9d07a986c40f49abe89ddf865913930", size = 51739, upload-time = "2025-10-06T05:37:32.127Z" },
+ { url = "https://files.pythonhosted.org/packages/62/1c/3d8622e60d0b767a5510d1d3cf21065b9db874696a51ea6d7a43180a259c/frozenlist-1.8.0-cp314-cp314t-manylinux1_x86_64.manylinux_2_28_x86_64.manylinux_2_5_x86_64.whl", hash = "sha256:39ecbc32f1390387d2aa4f5a995e465e9e2f79ba3adcac92d68e3e0afae6657c", size = 284186, upload-time = "2025-10-06T05:37:33.21Z" },
+ { url = "https://files.pythonhosted.org/packages/2d/14/aa36d5f85a89679a85a1d44cd7a6657e0b1c75f61e7cad987b203d2daca8/frozenlist-1.8.0-cp314-cp314t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:92db2bf818d5cc8d9c1f1fc56b897662e24ea5adb36ad1f1d82875bd64e03c24", size = 292196, upload-time = "2025-10-06T05:37:36.107Z" },
+ { url = "https://files.pythonhosted.org/packages/05/23/6bde59eb55abd407d34f77d39a5126fb7b4f109a3f611d3929f14b700c66/frozenlist-1.8.0-cp314-cp314t-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:2dc43a022e555de94c3b68a4ef0b11c4f747d12c024a520c7101709a2144fb37", size = 273830, upload-time = "2025-10-06T05:37:37.663Z" },
+ { url = "https://files.pythonhosted.org/packages/d2/3f/22cff331bfad7a8afa616289000ba793347fcd7bc275f3b28ecea2a27909/frozenlist-1.8.0-cp314-cp314t-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:cb89a7f2de3602cfed448095bab3f178399646ab7c61454315089787df07733a", size = 294289, upload-time = "2025-10-06T05:37:39.261Z" },
+ { url = "https://files.pythonhosted.org/packages/a4/89/5b057c799de4838b6c69aa82b79705f2027615e01be996d2486a69ca99c4/frozenlist-1.8.0-cp314-cp314t-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:33139dc858c580ea50e7e60a1b0ea003efa1fd42e6ec7fdbad78fff65fad2fd2", size = 300318, upload-time = "2025-10-06T05:37:43.213Z" },
+ { url = "https://files.pythonhosted.org/packages/30/de/2c22ab3eb2a8af6d69dc799e48455813bab3690c760de58e1bf43b36da3e/frozenlist-1.8.0-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:168c0969a329b416119507ba30b9ea13688fafffac1b7822802537569a1cb0ef", size = 282814, upload-time = "2025-10-06T05:37:45.337Z" },
+ { url = "https://files.pythonhosted.org/packages/59/f7/970141a6a8dbd7f556d94977858cfb36fa9b66e0892c6dd780d2219d8cd8/frozenlist-1.8.0-cp314-cp314t-musllinux_1_2_armv7l.whl", hash = "sha256:28bd570e8e189d7f7b001966435f9dac6718324b5be2990ac496cf1ea9ddb7fe", size = 291762, upload-time = "2025-10-06T05:37:46.657Z" },
+ { url = "https://files.pythonhosted.org/packages/c1/15/ca1adae83a719f82df9116d66f5bb28bb95557b3951903d39135620ef157/frozenlist-1.8.0-cp314-cp314t-musllinux_1_2_ppc64le.whl", hash = "sha256:b2a095d45c5d46e5e79ba1e5b9cb787f541a8dee0433836cea4b96a2c439dcd8", size = 289470, upload-time = "2025-10-06T05:37:47.946Z" },
+ { url = "https://files.pythonhosted.org/packages/ac/83/dca6dc53bf657d371fbc88ddeb21b79891e747189c5de990b9dfff2ccba1/frozenlist-1.8.0-cp314-cp314t-musllinux_1_2_s390x.whl", hash = "sha256:eab8145831a0d56ec9c4139b6c3e594c7a83c2c8be25d5bcf2d86136a532287a", size = 289042, upload-time = "2025-10-06T05:37:49.499Z" },
+ { url = "https://files.pythonhosted.org/packages/96/52/abddd34ca99be142f354398700536c5bd315880ed0a213812bc491cff5e4/frozenlist-1.8.0-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:974b28cf63cc99dfb2188d8d222bc6843656188164848c4f679e63dae4b0708e", size = 283148, upload-time = "2025-10-06T05:37:50.745Z" },
+ { url = "https://files.pythonhosted.org/packages/af/d3/76bd4ed4317e7119c2b7f57c3f6934aba26d277acc6309f873341640e21f/frozenlist-1.8.0-cp314-cp314t-win32.whl", hash = "sha256:342c97bf697ac5480c0a7ec73cd700ecfa5a8a40ac923bd035484616efecc2df", size = 44676, upload-time = "2025-10-06T05:37:52.222Z" },
+ { url = "https://files.pythonhosted.org/packages/89/76/c615883b7b521ead2944bb3480398cbb07e12b7b4e4d073d3752eb721558/frozenlist-1.8.0-cp314-cp314t-win_amd64.whl", hash = "sha256:06be8f67f39c8b1dc671f5d83aaefd3358ae5cdcf8314552c57e7ed3e6475bdd", size = 49451, upload-time = "2025-10-06T05:37:53.425Z" },
+ { url = "https://files.pythonhosted.org/packages/e0/a3/5982da14e113d07b325230f95060e2169f5311b1017ea8af2a29b374c289/frozenlist-1.8.0-cp314-cp314t-win_arm64.whl", hash = "sha256:102e6314ca4da683dca92e3b1355490fed5f313b768500084fbe6371fddfdb79", size = 42507, upload-time = "2025-10-06T05:37:54.513Z" },
+ { url = "https://files.pythonhosted.org/packages/9a/9a/e35b4a917281c0b8419d4207f4334c8e8c5dbf4f3f5f9ada73958d937dcc/frozenlist-1.8.0-py3-none-any.whl", hash = "sha256:0c18a16eab41e82c295618a77502e17b195883241c563b00f0aa5106fc4eaa0d", size = 13409, upload-time = "2025-10-06T05:38:16.721Z" },
+]
+
+[[package]]
+name = "fsspec"
+version = "2025.10.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/24/7f/2747c0d332b9acfa75dc84447a066fdf812b5a6b8d30472b74d309bfe8cb/fsspec-2025.10.0.tar.gz", hash = "sha256:b6789427626f068f9a83ca4e8a3cc050850b6c0f71f99ddb4f542b8266a26a59", size = 309285, upload-time = "2025-10-30T14:58:44.036Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/eb/02/a6b21098b1d5d6249b7c5ab69dde30108a71e4e819d4a9778f1de1d5b70d/fsspec-2025.10.0-py3-none-any.whl", hash = "sha256:7c7712353ae7d875407f97715f0e1ffcc21e33d5b24556cb1e090ae9409ec61d", size = 200966, upload-time = "2025-10-30T14:58:42.53Z" },
+]
+
+[package.optional-dependencies]
+http = [
+ { name = "aiohttp" },
+]
+
+[[package]]
+name = "ftfy"
+version = "6.3.1"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "wcwidth" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/a5/d3/8650919bc3c7c6e90ee3fa7fd618bf373cbbe55dff043bd67353dbb20cd8/ftfy-6.3.1.tar.gz", hash = "sha256:9b3c3d90f84fb267fe64d375a07b7f8912d817cf86009ae134aa03e1819506ec", size = 308927, upload-time = "2024-10-26T00:50:35.149Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/ab/6e/81d47999aebc1b155f81eca4477a616a70f238a2549848c38983f3c22a82/ftfy-6.3.1-py3-none-any.whl", hash = "sha256:7c70eb532015cd2f9adb53f101fb6c7945988d023a085d127d1573dc49dd0083", size = 44821, upload-time = "2024-10-26T00:50:33.425Z" },
+]
+
+[[package]]
+name = "gitdb"
+version = "4.0.12"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "smmap" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/72/94/63b0fc47eb32792c7ba1fe1b694daec9a63620db1e313033d18140c2320a/gitdb-4.0.12.tar.gz", hash = "sha256:5ef71f855d191a3326fcfbc0d5da835f26b13fbcba60c32c21091c349ffdb571", size = 394684, upload-time = "2025-01-02T07:20:46.413Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/a0/61/5c78b91c3143ed5c14207f463aecfc8f9dbb5092fb2869baf37c273b2705/gitdb-4.0.12-py3-none-any.whl", hash = "sha256:67073e15955400952c6565cc3e707c554a4eea2e428946f7a4c162fab9bd9bcf", size = 62794, upload-time = "2025-01-02T07:20:43.624Z" },
+]
+
+[[package]]
+name = "gitpython"
+version = "3.1.45"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "gitdb" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/9a/c8/dd58967d119baab745caec2f9d853297cec1989ec1d63f677d3880632b88/gitpython-3.1.45.tar.gz", hash = "sha256:85b0ee964ceddf211c41b9f27a49086010a190fd8132a24e21f362a4b36a791c", size = 215076, upload-time = "2025-07-24T03:45:54.871Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/01/61/d4b89fec821f72385526e1b9d9a3a0385dda4a72b206d28049e2c7cd39b8/gitpython-3.1.45-py3-none-any.whl", hash = "sha256:8908cb2e02fb3b93b7eb0f2827125cb699869470432cc885f019b8fd0fccff77", size = 208168, upload-time = "2025-07-24T03:45:52.517Z" },
+]
+
+[[package]]
+name = "h11"
+version = "0.16.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/01/ee/02a2c011bdab74c6fb3c75474d40b3052059d95df7e73351460c8588d963/h11-0.16.0.tar.gz", hash = "sha256:4e35b956cf45792e4caa5885e69fba00bdbc6ffafbfa020300e549b208ee5ff1", size = 101250, upload-time = "2025-04-24T03:35:25.427Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/04/4b/29cac41a4d98d144bf5f6d33995617b185d14b22401f75ca86f384e87ff1/h11-0.16.0-py3-none-any.whl", hash = "sha256:63cf8bbe7522de3bf65932fda1d9c2772064ffb3dae62d55932da54b31cb6c86", size = 37515, upload-time = "2025-04-24T03:35:24.344Z" },
+]
+
+[[package]]
+name = "hf-xet"
+version = "1.2.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/5e/6e/0f11bacf08a67f7fb5ee09740f2ca54163863b07b70d579356e9222ce5d8/hf_xet-1.2.0.tar.gz", hash = "sha256:a8c27070ca547293b6890c4bf389f713f80e8c478631432962bb7f4bc0bd7d7f", size = 506020, upload-time = "2025-10-24T19:04:32.129Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/9e/a5/85ef910a0aa034a2abcfadc360ab5ac6f6bc4e9112349bd40ca97551cff0/hf_xet-1.2.0-cp313-cp313t-macosx_10_12_x86_64.whl", hash = "sha256:ceeefcd1b7aed4956ae8499e2199607765fbd1c60510752003b6cc0b8413b649", size = 2861870, upload-time = "2025-10-24T19:04:11.422Z" },
+ { url = "https://files.pythonhosted.org/packages/ea/40/e2e0a7eb9a51fe8828ba2d47fe22a7e74914ea8a0db68a18c3aa7449c767/hf_xet-1.2.0-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:b70218dd548e9840224df5638fdc94bd033552963cfa97f9170829381179c813", size = 2717584, upload-time = "2025-10-24T19:04:09.586Z" },
+ { url = "https://files.pythonhosted.org/packages/a5/7d/daf7f8bc4594fdd59a8a596f9e3886133fdc68e675292218a5e4c1b7e834/hf_xet-1.2.0-cp313-cp313t-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:7d40b18769bb9a8bc82a9ede575ce1a44c75eb80e7375a01d76259089529b5dc", size = 3315004, upload-time = "2025-10-24T19:04:00.314Z" },
+ { url = "https://files.pythonhosted.org/packages/b1/ba/45ea2f605fbf6d81c8b21e4d970b168b18a53515923010c312c06cd83164/hf_xet-1.2.0-cp313-cp313t-manylinux_2_28_aarch64.whl", hash = "sha256:cd3a6027d59cfb60177c12d6424e31f4b5ff13d8e3a1247b3a584bf8977e6df5", size = 3222636, upload-time = "2025-10-24T19:03:58.111Z" },
+ { url = "https://files.pythonhosted.org/packages/4a/1d/04513e3cab8f29ab8c109d309ddd21a2705afab9d52f2ba1151e0c14f086/hf_xet-1.2.0-cp313-cp313t-musllinux_1_2_aarch64.whl", hash = "sha256:6de1fc44f58f6dd937956c8d304d8c2dea264c80680bcfa61ca4a15e7b76780f", size = 3408448, upload-time = "2025-10-24T19:04:20.951Z" },
+ { url = "https://files.pythonhosted.org/packages/f0/7c/60a2756d7feec7387db3a1176c632357632fbe7849fce576c5559d4520c7/hf_xet-1.2.0-cp313-cp313t-musllinux_1_2_x86_64.whl", hash = "sha256:f182f264ed2acd566c514e45da9f2119110e48a87a327ca271027904c70c5832", size = 3503401, upload-time = "2025-10-24T19:04:22.549Z" },
+ { url = "https://files.pythonhosted.org/packages/4e/64/48fffbd67fb418ab07451e4ce641a70de1c40c10a13e25325e24858ebe5a/hf_xet-1.2.0-cp313-cp313t-win_amd64.whl", hash = "sha256:293a7a3787e5c95d7be1857358a9130694a9c6021de3f27fa233f37267174382", size = 2900866, upload-time = "2025-10-24T19:04:33.461Z" },
+ { url = "https://files.pythonhosted.org/packages/e2/51/f7e2caae42f80af886db414d4e9885fac959330509089f97cccb339c6b87/hf_xet-1.2.0-cp314-cp314t-macosx_10_12_x86_64.whl", hash = "sha256:10bfab528b968c70e062607f663e21e34e2bba349e8038db546646875495179e", size = 2861861, upload-time = "2025-10-24T19:04:19.01Z" },
+ { url = "https://files.pythonhosted.org/packages/6e/1d/a641a88b69994f9371bd347f1dd35e5d1e2e2460a2e350c8d5165fc62005/hf_xet-1.2.0-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:2a212e842647b02eb6a911187dc878e79c4aa0aa397e88dd3b26761676e8c1f8", size = 2717699, upload-time = "2025-10-24T19:04:17.306Z" },
+ { url = "https://files.pythonhosted.org/packages/df/e0/e5e9bba7d15f0318955f7ec3f4af13f92e773fbb368c0b8008a5acbcb12f/hf_xet-1.2.0-cp314-cp314t-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:30e06daccb3a7d4c065f34fc26c14c74f4653069bb2b194e7f18f17cbe9939c0", size = 3314885, upload-time = "2025-10-24T19:04:07.642Z" },
+ { url = "https://files.pythonhosted.org/packages/21/90/b7fe5ff6f2b7b8cbdf1bd56145f863c90a5807d9758a549bf3d916aa4dec/hf_xet-1.2.0-cp314-cp314t-manylinux_2_28_aarch64.whl", hash = "sha256:29c8fc913a529ec0a91867ce3d119ac1aac966e098cf49501800c870328cc090", size = 3221550, upload-time = "2025-10-24T19:04:05.55Z" },
+ { url = "https://files.pythonhosted.org/packages/6f/cb/73f276f0a7ce46cc6a6ec7d6c7d61cbfe5f2e107123d9bbd0193c355f106/hf_xet-1.2.0-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:66e159cbfcfbb29f920db2c09ed8b660eb894640d284f102ada929b6e3dc410a", size = 3408010, upload-time = "2025-10-24T19:04:28.598Z" },
+ { url = "https://files.pythonhosted.org/packages/b8/1e/d642a12caa78171f4be64f7cd9c40e3ca5279d055d0873188a58c0f5fbb9/hf_xet-1.2.0-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:9c91d5ae931510107f148874e9e2de8a16052b6f1b3ca3c1b12f15ccb491390f", size = 3503264, upload-time = "2025-10-24T19:04:30.397Z" },
+ { url = "https://files.pythonhosted.org/packages/17/b5/33764714923fa1ff922770f7ed18c2daae034d21ae6e10dbf4347c854154/hf_xet-1.2.0-cp314-cp314t-win_amd64.whl", hash = "sha256:210d577732b519ac6ede149d2f2f34049d44e8622bf14eb3d63bbcd2d4b332dc", size = 2901071, upload-time = "2025-10-24T19:04:37.463Z" },
+ { url = "https://files.pythonhosted.org/packages/96/2d/22338486473df5923a9ab7107d375dbef9173c338ebef5098ef593d2b560/hf_xet-1.2.0-cp37-abi3-macosx_10_12_x86_64.whl", hash = "sha256:46740d4ac024a7ca9b22bebf77460ff43332868b661186a8e46c227fdae01848", size = 2866099, upload-time = "2025-10-24T19:04:15.366Z" },
+ { url = "https://files.pythonhosted.org/packages/7f/8c/c5becfa53234299bc2210ba314eaaae36c2875e0045809b82e40a9544f0c/hf_xet-1.2.0-cp37-abi3-macosx_11_0_arm64.whl", hash = "sha256:27df617a076420d8845bea087f59303da8be17ed7ec0cd7ee3b9b9f579dff0e4", size = 2722178, upload-time = "2025-10-24T19:04:13.695Z" },
+ { url = "https://files.pythonhosted.org/packages/9a/92/cf3ab0b652b082e66876d08da57fcc6fa2f0e6c70dfbbafbd470bb73eb47/hf_xet-1.2.0-cp37-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:3651fd5bfe0281951b988c0facbe726aa5e347b103a675f49a3fa8144c7968fd", size = 3320214, upload-time = "2025-10-24T19:04:03.596Z" },
+ { url = "https://files.pythonhosted.org/packages/46/92/3f7ec4a1b6a65bf45b059b6d4a5d38988f63e193056de2f420137e3c3244/hf_xet-1.2.0-cp37-abi3-manylinux_2_28_aarch64.whl", hash = "sha256:d06fa97c8562fb3ee7a378dd9b51e343bc5bc8190254202c9771029152f5e08c", size = 3229054, upload-time = "2025-10-24T19:04:01.949Z" },
+ { url = "https://files.pythonhosted.org/packages/0b/dd/7ac658d54b9fb7999a0ccb07ad863b413cbaf5cf172f48ebcd9497ec7263/hf_xet-1.2.0-cp37-abi3-musllinux_1_2_aarch64.whl", hash = "sha256:4c1428c9ae73ec0939410ec73023c4f842927f39db09b063b9482dac5a3bb737", size = 3413812, upload-time = "2025-10-24T19:04:24.585Z" },
+ { url = "https://files.pythonhosted.org/packages/92/68/89ac4e5b12a9ff6286a12174c8538a5930e2ed662091dd2572bbe0a18c8a/hf_xet-1.2.0-cp37-abi3-musllinux_1_2_x86_64.whl", hash = "sha256:a55558084c16b09b5ed32ab9ed38421e2d87cf3f1f89815764d1177081b99865", size = 3508920, upload-time = "2025-10-24T19:04:26.927Z" },
+ { url = "https://files.pythonhosted.org/packages/cb/44/870d44b30e1dcfb6a65932e3e1506c103a8a5aea9103c337e7a53180322c/hf_xet-1.2.0-cp37-abi3-win_amd64.whl", hash = "sha256:e6584a52253f72c9f52f9e549d5895ca7a471608495c4ecaa6cc73dba2b24d69", size = 2905735, upload-time = "2025-10-24T19:04:35.928Z" },
+]
+
+[[package]]
+name = "httpcore"
+version = "1.0.9"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "certifi" },
+ { name = "h11" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/06/94/82699a10bca87a5556c9c59b5963f2d039dbd239f25bc2a63907a05a14cb/httpcore-1.0.9.tar.gz", hash = "sha256:6e34463af53fd2ab5d807f399a9b45ea31c3dfa2276f15a2c3f00afff6e176e8", size = 85484, upload-time = "2025-04-24T22:06:22.219Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/7e/f5/f66802a942d491edb555dd61e3a9961140fd64c90bce1eafd741609d334d/httpcore-1.0.9-py3-none-any.whl", hash = "sha256:2d400746a40668fc9dec9810239072b40b4484b640a8c38fd654a024c7a1bf55", size = 78784, upload-time = "2025-04-24T22:06:20.566Z" },
+]
+
+[[package]]
+name = "httpx"
+version = "0.28.1"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "anyio" },
+ { name = "certifi" },
+ { name = "httpcore" },
+ { name = "idna" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/b1/df/48c586a5fe32a0f01324ee087459e112ebb7224f646c0b5023f5e79e9956/httpx-0.28.1.tar.gz", hash = "sha256:75e98c5f16b0f35b567856f597f06ff2270a374470a5c2392242528e3e3e42fc", size = 141406, upload-time = "2024-12-06T15:37:23.222Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/2a/39/e50c7c3a983047577ee07d2a9e53faf5a69493943ec3f6a384bdc792deb2/httpx-0.28.1-py3-none-any.whl", hash = "sha256:d909fcccc110f8c7faf814ca82a9a4d816bc5a6dbfea25d6591d6985b8ba59ad", size = 73517, upload-time = "2024-12-06T15:37:21.509Z" },
+]
+
+[[package]]
+name = "huggingface-hub"
+version = "0.36.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "filelock" },
+ { name = "fsspec" },
+ { name = "hf-xet", marker = "platform_machine == 'aarch64' or platform_machine == 'amd64' or platform_machine == 'arm64' or platform_machine == 'x86_64'" },
+ { name = "packaging" },
+ { name = "pyyaml" },
+ { name = "requests" },
+ { name = "tqdm" },
+ { name = "typing-extensions" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/98/63/4910c5fa9128fdadf6a9c5ac138e8b1b6cee4ca44bf7915bbfbce4e355ee/huggingface_hub-0.36.0.tar.gz", hash = "sha256:47b3f0e2539c39bf5cde015d63b72ec49baff67b6931c3d97f3f84532e2b8d25", size = 463358, upload-time = "2025-10-23T12:12:01.413Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/cb/bd/1a875e0d592d447cbc02805fd3fe0f497714d6a2583f59d14fa9ebad96eb/huggingface_hub-0.36.0-py3-none-any.whl", hash = "sha256:7bcc9ad17d5b3f07b57c78e79d527102d08313caa278a641993acddcb894548d", size = 566094, upload-time = "2025-10-23T12:11:59.557Z" },
+]
+
+[[package]]
+name = "idna"
+version = "3.11"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/6f/6d/0703ccc57f3a7233505399edb88de3cbd678da106337b9fcde432b65ed60/idna-3.11.tar.gz", hash = "sha256:795dafcc9c04ed0c1fb032c2aa73654d8e8c5023a7df64a53f39190ada629902", size = 194582, upload-time = "2025-10-12T14:55:20.501Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/0e/61/66938bbb5fc52dbdf84594873d5b51fb1f7c7794e9c0f5bd885f30bc507b/idna-3.11-py3-none-any.whl", hash = "sha256:771a87f49d9defaf64091e6e6fe9c18d4833f140bd19464795bc32d966ca37ea", size = 71008, upload-time = "2025-10-12T14:55:18.883Z" },
+]
+
+[[package]]
+name = "inflection"
+version = "0.5.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/e1/7e/691d061b7329bc8d54edbf0ec22fbfb2afe61facb681f9aaa9bff7a27d04/inflection-0.5.1.tar.gz", hash = "sha256:1a29730d366e996aaacffb2f1f1cb9593dc38e2ddd30c91250c6dde09ea9b417", size = 15091, upload-time = "2020-08-22T08:16:29.139Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/59/91/aa6bde563e0085a02a435aa99b49ef75b0a4b062635e606dab23ce18d720/inflection-0.5.1-py2.py3-none-any.whl", hash = "sha256:f38b2b640938a4f35ade69ac3d053042959b62a0f1076a5bbaa1b9526605a8a2", size = 9454, upload-time = "2020-08-22T08:16:27.816Z" },
+]
+
+[[package]]
+name = "ipykernel"
+version = "7.1.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "appnope", marker = "sys_platform == 'darwin'" },
+ { name = "comm" },
+ { name = "debugpy" },
+ { name = "ipython" },
+ { name = "jupyter-client" },
+ { name = "jupyter-core" },
+ { name = "matplotlib-inline" },
+ { name = "nest-asyncio" },
+ { name = "packaging" },
+ { name = "psutil" },
+ { name = "pyzmq" },
+ { name = "tornado" },
+ { name = "traitlets" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/b9/a4/4948be6eb88628505b83a1f2f40d90254cab66abf2043b3c40fa07dfce0f/ipykernel-7.1.0.tar.gz", hash = "sha256:58a3fc88533d5930c3546dc7eac66c6d288acde4f801e2001e65edc5dc9cf0db", size = 174579, upload-time = "2025-10-27T09:46:39.471Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/a3/17/20c2552266728ceba271967b87919664ecc0e33efca29c3efc6baf88c5f9/ipykernel-7.1.0-py3-none-any.whl", hash = "sha256:763b5ec6c5b7776f6a8d7ce09b267693b4e5ce75cb50ae696aaefb3c85e1ea4c", size = 117968, upload-time = "2025-10-27T09:46:37.805Z" },
+]
+
+[[package]]
+name = "ipython"
+version = "9.8.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "colorama", marker = "sys_platform == 'win32'" },
+ { name = "decorator" },
+ { name = "ipython-pygments-lexers" },
+ { name = "jedi" },
+ { name = "matplotlib-inline" },
+ { name = "pexpect", marker = "sys_platform != 'emscripten' and sys_platform != 'win32'" },
+ { name = "prompt-toolkit" },
+ { name = "pygments" },
+ { name = "stack-data" },
+ { name = "traitlets" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/12/51/a703c030f4928646d390b4971af4938a1b10c9dfce694f0d99a0bb073cb2/ipython-9.8.0.tar.gz", hash = "sha256:8e4ce129a627eb9dd221c41b1d2cdaed4ef7c9da8c17c63f6f578fe231141f83", size = 4424940, upload-time = "2025-12-03T10:18:24.353Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/f1/df/8ee1c5dd1e3308b5d5b2f2dfea323bb2f3827da8d654abb6642051199049/ipython-9.8.0-py3-none-any.whl", hash = "sha256:ebe6d1d58d7d988fbf23ff8ff6d8e1622cfdb194daf4b7b73b792c4ec3b85385", size = 621374, upload-time = "2025-12-03T10:18:22.335Z" },
+]
+
+[[package]]
+name = "ipython-pygments-lexers"
+version = "1.1.1"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "pygments" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/ef/4c/5dd1d8af08107f88c7f741ead7a40854b8ac24ddf9ae850afbcf698aa552/ipython_pygments_lexers-1.1.1.tar.gz", hash = "sha256:09c0138009e56b6854f9535736f4171d855c8c08a563a0dcd8022f78355c7e81", size = 8393, upload-time = "2025-01-17T11:24:34.505Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/d9/33/1f075bf72b0b747cb3288d011319aaf64083cf2efef8354174e3ed4540e2/ipython_pygments_lexers-1.1.1-py3-none-any.whl", hash = "sha256:a9462224a505ade19a605f71f8fa63c2048833ce50abc86768a0d81d876dc81c", size = 8074, upload-time = "2025-01-17T11:24:33.271Z" },
+]
+
+[[package]]
+name = "ipywidgets"
+version = "8.1.8"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "comm" },
+ { name = "ipython" },
+ { name = "jupyterlab-widgets" },
+ { name = "traitlets" },
+ { name = "widgetsnbextension" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/4c/ae/c5ce1edc1afe042eadb445e95b0671b03cee61895264357956e61c0d2ac0/ipywidgets-8.1.8.tar.gz", hash = "sha256:61f969306b95f85fba6b6986b7fe45d73124d1d9e3023a8068710d47a22ea668", size = 116739, upload-time = "2025-11-01T21:18:12.393Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/56/6d/0d9848617b9f753b87f214f1c682592f7ca42de085f564352f10f0843026/ipywidgets-8.1.8-py3-none-any.whl", hash = "sha256:ecaca67aed704a338f88f67b1181b58f821ab5dc89c1f0f5ef99db43c1c2921e", size = 139808, upload-time = "2025-11-01T21:18:10.956Z" },
+]
+
+[[package]]
+name = "isoduration"
+version = "20.11.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "arrow" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/7c/1a/3c8edc664e06e6bd06cce40c6b22da5f1429aa4224d0c590f3be21c91ead/isoduration-20.11.0.tar.gz", hash = "sha256:ac2f9015137935279eac671f94f89eb00584f940f5dc49462a0c4ee692ba1bd9", size = 11649, upload-time = "2020-11-01T11:00:00.312Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/7b/55/e5326141505c5d5e34c5e0935d2908a74e4561eca44108fbfb9c13d2911a/isoduration-20.11.0-py3-none-any.whl", hash = "sha256:b2904c2a4228c3d44f409c8ae8e2370eb21a26f7ac2ec5446df141dde3452042", size = 11321, upload-time = "2020-11-01T10:59:58.02Z" },
+]
+
+[[package]]
+name = "jedi"
+version = "0.19.2"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "parso" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/72/3a/79a912fbd4d8dd6fbb02bf69afd3bb72cf0c729bb3063c6f4498603db17a/jedi-0.19.2.tar.gz", hash = "sha256:4770dc3de41bde3966b02eb84fbcf557fb33cce26ad23da12c742fb50ecb11f0", size = 1231287, upload-time = "2024-11-11T01:41:42.873Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/c0/5a/9cac0c82afec3d09ccd97c8b6502d48f165f9124db81b4bcb90b4af974ee/jedi-0.19.2-py2.py3-none-any.whl", hash = "sha256:a8ef22bde8490f57fe5c7681a3c83cb58874daf72b4784de3cce5b6ef6edb5b9", size = 1572278, upload-time = "2024-11-11T01:41:40.175Z" },
+]
+
+[[package]]
+name = "jinja2"
+version = "3.1.6"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "markupsafe" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/df/bf/f7da0350254c0ed7c72f3e33cef02e048281fec7ecec5f032d4aac52226b/jinja2-3.1.6.tar.gz", hash = "sha256:0137fb05990d35f1275a587e9aee6d56da821fc83491a0fb838183be43f66d6d", size = 245115, upload-time = "2025-03-05T20:05:02.478Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/62/a1/3d680cbfd5f4b8f15abc1d571870c5fc3e594bb582bc3b64ea099db13e56/jinja2-3.1.6-py3-none-any.whl", hash = "sha256:85ece4451f492d0c13c5dd7c13a64681a86afae63a5f347908daf103ce6d2f67", size = 134899, upload-time = "2025-03-05T20:05:00.369Z" },
+]
+
+[[package]]
+name = "jiter"
+version = "0.12.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/45/9d/e0660989c1370e25848bb4c52d061c71837239738ad937e83edca174c273/jiter-0.12.0.tar.gz", hash = "sha256:64dfcd7d5c168b38d3f9f8bba7fc639edb3418abcc74f22fdbe6b8938293f30b", size = 168294, upload-time = "2025-11-09T20:49:23.302Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/92/c9/5b9f7b4983f1b542c64e84165075335e8a236fa9e2ea03a0c79780062be8/jiter-0.12.0-cp312-cp312-macosx_10_12_x86_64.whl", hash = "sha256:305e061fa82f4680607a775b2e8e0bcb071cd2205ac38e6ef48c8dd5ebe1cf37", size = 314449, upload-time = "2025-11-09T20:47:22.999Z" },
+ { url = "https://files.pythonhosted.org/packages/98/6e/e8efa0e78de00db0aee82c0cf9e8b3f2027efd7f8a71f859d8f4be8e98ef/jiter-0.12.0-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:5c1860627048e302a528333c9307c818c547f214d8659b0705d2195e1a94b274", size = 319855, upload-time = "2025-11-09T20:47:24.779Z" },
+ { url = "https://files.pythonhosted.org/packages/20/26/894cd88e60b5d58af53bec5c6759d1292bd0b37a8b5f60f07abf7a63ae5f/jiter-0.12.0-cp312-cp312-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:df37577a4f8408f7e0ec3205d2a8f87672af8f17008358063a4d6425b6081ce3", size = 350171, upload-time = "2025-11-09T20:47:26.469Z" },
+ { url = "https://files.pythonhosted.org/packages/f5/27/a7b818b9979ac31b3763d25f3653ec3a954044d5e9f5d87f2f247d679fd1/jiter-0.12.0-cp312-cp312-manylinux_2_17_armv7l.manylinux2014_armv7l.whl", hash = "sha256:75fdd787356c1c13a4f40b43c2156276ef7a71eb487d98472476476d803fb2cf", size = 365590, upload-time = "2025-11-09T20:47:27.918Z" },
+ { url = "https://files.pythonhosted.org/packages/ba/7e/e46195801a97673a83746170b17984aa8ac4a455746354516d02ca5541b4/jiter-0.12.0-cp312-cp312-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:1eb5db8d9c65b112aacf14fcd0faae9913d07a8afea5ed06ccdd12b724e966a1", size = 479462, upload-time = "2025-11-09T20:47:29.654Z" },
+ { url = "https://files.pythonhosted.org/packages/ca/75/f833bfb009ab4bd11b1c9406d333e3b4357709ed0570bb48c7c06d78c7dd/jiter-0.12.0-cp312-cp312-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:73c568cc27c473f82480abc15d1301adf333a7ea4f2e813d6a2c7d8b6ba8d0df", size = 378983, upload-time = "2025-11-09T20:47:31.026Z" },
+ { url = "https://files.pythonhosted.org/packages/71/b3/7a69d77943cc837d30165643db753471aff5df39692d598da880a6e51c24/jiter-0.12.0-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:4321e8a3d868919bcb1abb1db550d41f2b5b326f72df29e53b2df8b006eb9403", size = 361328, upload-time = "2025-11-09T20:47:33.286Z" },
+ { url = "https://files.pythonhosted.org/packages/b0/ac/a78f90caf48d65ba70d8c6efc6f23150bc39dc3389d65bbec2a95c7bc628/jiter-0.12.0-cp312-cp312-manylinux_2_5_i686.manylinux1_i686.whl", hash = "sha256:0a51bad79f8cc9cac2b4b705039f814049142e0050f30d91695a2d9a6611f126", size = 386740, upload-time = "2025-11-09T20:47:34.703Z" },
+ { url = "https://files.pythonhosted.org/packages/39/b6/5d31c2cc8e1b6a6bcf3c5721e4ca0a3633d1ab4754b09bc7084f6c4f5327/jiter-0.12.0-cp312-cp312-musllinux_1_1_aarch64.whl", hash = "sha256:2a67b678f6a5f1dd6c36d642d7db83e456bc8b104788262aaefc11a22339f5a9", size = 520875, upload-time = "2025-11-09T20:47:36.058Z" },
+ { url = "https://files.pythonhosted.org/packages/30/b5/4df540fae4e9f68c54b8dab004bd8c943a752f0b00efd6e7d64aa3850339/jiter-0.12.0-cp312-cp312-musllinux_1_1_x86_64.whl", hash = "sha256:efe1a211fe1fd14762adea941e3cfd6c611a136e28da6c39272dbb7a1bbe6a86", size = 511457, upload-time = "2025-11-09T20:47:37.932Z" },
+ { url = "https://files.pythonhosted.org/packages/07/65/86b74010e450a1a77b2c1aabb91d4a91dd3cd5afce99f34d75fd1ac64b19/jiter-0.12.0-cp312-cp312-win32.whl", hash = "sha256:d779d97c834b4278276ec703dc3fc1735fca50af63eb7262f05bdb4e62203d44", size = 204546, upload-time = "2025-11-09T20:47:40.47Z" },
+ { url = "https://files.pythonhosted.org/packages/1c/c7/6659f537f9562d963488e3e55573498a442503ced01f7e169e96a6110383/jiter-0.12.0-cp312-cp312-win_amd64.whl", hash = "sha256:e8269062060212b373316fe69236096aaf4c49022d267c6736eebd66bbbc60bb", size = 205196, upload-time = "2025-11-09T20:47:41.794Z" },
+ { url = "https://files.pythonhosted.org/packages/21/f4/935304f5169edadfec7f9c01eacbce4c90bb9a82035ac1de1f3bd2d40be6/jiter-0.12.0-cp312-cp312-win_arm64.whl", hash = "sha256:06cb970936c65de926d648af0ed3d21857f026b1cf5525cb2947aa5e01e05789", size = 186100, upload-time = "2025-11-09T20:47:43.007Z" },
+ { url = "https://files.pythonhosted.org/packages/3d/a6/97209693b177716e22576ee1161674d1d58029eb178e01866a0422b69224/jiter-0.12.0-cp313-cp313-macosx_10_12_x86_64.whl", hash = "sha256:6cc49d5130a14b732e0612bc76ae8db3b49898732223ef8b7599aa8d9810683e", size = 313658, upload-time = "2025-11-09T20:47:44.424Z" },
+ { url = "https://files.pythonhosted.org/packages/06/4d/125c5c1537c7d8ee73ad3d530a442d6c619714b95027143f1b61c0b4dfe0/jiter-0.12.0-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:37f27a32ce36364d2fa4f7fdc507279db604d27d239ea2e044c8f148410defe1", size = 318605, upload-time = "2025-11-09T20:47:45.973Z" },
+ { url = "https://files.pythonhosted.org/packages/99/bf/a840b89847885064c41a5f52de6e312e91fa84a520848ee56c97e4fa0205/jiter-0.12.0-cp313-cp313-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:bbc0944aa3d4b4773e348cda635252824a78f4ba44328e042ef1ff3f6080d1cf", size = 349803, upload-time = "2025-11-09T20:47:47.535Z" },
+ { url = "https://files.pythonhosted.org/packages/8a/88/e63441c28e0db50e305ae23e19c1d8fae012d78ed55365da392c1f34b09c/jiter-0.12.0-cp313-cp313-manylinux_2_17_armv7l.manylinux2014_armv7l.whl", hash = "sha256:da25c62d4ee1ffbacb97fac6dfe4dcd6759ebdc9015991e92a6eae5816287f44", size = 365120, upload-time = "2025-11-09T20:47:49.284Z" },
+ { url = "https://files.pythonhosted.org/packages/0a/7c/49b02714af4343970eb8aca63396bc1c82fa01197dbb1e9b0d274b550d4e/jiter-0.12.0-cp313-cp313-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:048485c654b838140b007390b8182ba9774621103bd4d77c9c3f6f117474ba45", size = 479918, upload-time = "2025-11-09T20:47:50.807Z" },
+ { url = "https://files.pythonhosted.org/packages/69/ba/0a809817fdd5a1db80490b9150645f3aae16afad166960bcd562be194f3b/jiter-0.12.0-cp313-cp313-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:635e737fbb7315bef0037c19b88b799143d2d7d3507e61a76751025226b3ac87", size = 379008, upload-time = "2025-11-09T20:47:52.211Z" },
+ { url = "https://files.pythonhosted.org/packages/5f/c3/c9fc0232e736c8877d9e6d83d6eeb0ba4e90c6c073835cc2e8f73fdeef51/jiter-0.12.0-cp313-cp313-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:4e017c417b1ebda911bd13b1e40612704b1f5420e30695112efdbed8a4b389ed", size = 361785, upload-time = "2025-11-09T20:47:53.512Z" },
+ { url = "https://files.pythonhosted.org/packages/96/61/61f69b7e442e97ca6cd53086ddc1cf59fb830549bc72c0a293713a60c525/jiter-0.12.0-cp313-cp313-manylinux_2_5_i686.manylinux1_i686.whl", hash = "sha256:89b0bfb8b2bf2351fba36bb211ef8bfceba73ef58e7f0c68fb67b5a2795ca2f9", size = 386108, upload-time = "2025-11-09T20:47:54.893Z" },
+ { url = "https://files.pythonhosted.org/packages/e9/2e/76bb3332f28550c8f1eba3bf6e5efe211efda0ddbbaf24976bc7078d42a5/jiter-0.12.0-cp313-cp313-musllinux_1_1_aarch64.whl", hash = "sha256:f5aa5427a629a824a543672778c9ce0c5e556550d1569bb6ea28a85015287626", size = 519937, upload-time = "2025-11-09T20:47:56.253Z" },
+ { url = "https://files.pythonhosted.org/packages/84/d6/fa96efa87dc8bff2094fb947f51f66368fa56d8d4fc9e77b25d7fbb23375/jiter-0.12.0-cp313-cp313-musllinux_1_1_x86_64.whl", hash = "sha256:ed53b3d6acbcb0fd0b90f20c7cb3b24c357fe82a3518934d4edfa8c6898e498c", size = 510853, upload-time = "2025-11-09T20:47:58.32Z" },
+ { url = "https://files.pythonhosted.org/packages/8a/28/93f67fdb4d5904a708119a6ab58a8f1ec226ff10a94a282e0215402a8462/jiter-0.12.0-cp313-cp313-win32.whl", hash = "sha256:4747de73d6b8c78f2e253a2787930f4fffc68da7fa319739f57437f95963c4de", size = 204699, upload-time = "2025-11-09T20:47:59.686Z" },
+ { url = "https://files.pythonhosted.org/packages/c4/1f/30b0eb087045a0abe2a5c9c0c0c8da110875a1d3be83afd4a9a4e548be3c/jiter-0.12.0-cp313-cp313-win_amd64.whl", hash = "sha256:e25012eb0c456fcc13354255d0338cd5397cce26c77b2832b3c4e2e255ea5d9a", size = 204258, upload-time = "2025-11-09T20:48:01.01Z" },
+ { url = "https://files.pythonhosted.org/packages/2c/f4/2b4daf99b96bce6fc47971890b14b2a36aef88d7beb9f057fafa032c6141/jiter-0.12.0-cp313-cp313-win_arm64.whl", hash = "sha256:c97b92c54fe6110138c872add030a1f99aea2401ddcdaa21edf74705a646dd60", size = 185503, upload-time = "2025-11-09T20:48:02.35Z" },
+ { url = "https://files.pythonhosted.org/packages/39/ca/67bb15a7061d6fe20b9b2a2fd783e296a1e0f93468252c093481a2f00efa/jiter-0.12.0-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:53839b35a38f56b8be26a7851a48b89bc47e5d88e900929df10ed93b95fea3d6", size = 317965, upload-time = "2025-11-09T20:48:03.783Z" },
+ { url = "https://files.pythonhosted.org/packages/18/af/1788031cd22e29c3b14bc6ca80b16a39a0b10e611367ffd480c06a259831/jiter-0.12.0-cp313-cp313t-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:94f669548e55c91ab47fef8bddd9c954dab1938644e715ea49d7e117015110a4", size = 345831, upload-time = "2025-11-09T20:48:05.55Z" },
+ { url = "https://files.pythonhosted.org/packages/05/17/710bf8472d1dff0d3caf4ced6031060091c1320f84ee7d5dcbed1f352417/jiter-0.12.0-cp313-cp313t-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:351d54f2b09a41600ffea43d081522d792e81dcfb915f6d2d242744c1cc48beb", size = 361272, upload-time = "2025-11-09T20:48:06.951Z" },
+ { url = "https://files.pythonhosted.org/packages/fb/f1/1dcc4618b59761fef92d10bcbb0b038b5160be653b003651566a185f1a5c/jiter-0.12.0-cp313-cp313t-win_amd64.whl", hash = "sha256:2a5e90604620f94bf62264e7c2c038704d38217b7465b863896c6d7c902b06c7", size = 204604, upload-time = "2025-11-09T20:48:08.328Z" },
+ { url = "https://files.pythonhosted.org/packages/d9/32/63cb1d9f1c5c6632a783c0052cde9ef7ba82688f7065e2f0d5f10a7e3edb/jiter-0.12.0-cp313-cp313t-win_arm64.whl", hash = "sha256:88ef757017e78d2860f96250f9393b7b577b06a956ad102c29c8237554380db3", size = 185628, upload-time = "2025-11-09T20:48:09.572Z" },
+ { url = "https://files.pythonhosted.org/packages/a8/99/45c9f0dbe4a1416b2b9a8a6d1236459540f43d7fb8883cff769a8db0612d/jiter-0.12.0-cp314-cp314-macosx_10_12_x86_64.whl", hash = "sha256:c46d927acd09c67a9fb1416df45c5a04c27e83aae969267e98fba35b74e99525", size = 312478, upload-time = "2025-11-09T20:48:10.898Z" },
+ { url = "https://files.pythonhosted.org/packages/4c/a7/54ae75613ba9e0f55fcb0bc5d1f807823b5167cc944e9333ff322e9f07dd/jiter-0.12.0-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:774ff60b27a84a85b27b88cd5583899c59940bcc126caca97eb2a9df6aa00c49", size = 318706, upload-time = "2025-11-09T20:48:12.266Z" },
+ { url = "https://files.pythonhosted.org/packages/59/31/2aa241ad2c10774baf6c37f8b8e1f39c07db358f1329f4eb40eba179c2a2/jiter-0.12.0-cp314-cp314-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:c5433fab222fb072237df3f637d01b81f040a07dcac1cb4a5c75c7aa9ed0bef1", size = 351894, upload-time = "2025-11-09T20:48:13.673Z" },
+ { url = "https://files.pythonhosted.org/packages/54/4f/0f2759522719133a9042781b18cc94e335b6d290f5e2d3e6899d6af933e3/jiter-0.12.0-cp314-cp314-manylinux_2_17_armv7l.manylinux2014_armv7l.whl", hash = "sha256:f8c593c6e71c07866ec6bfb790e202a833eeec885022296aff6b9e0b92d6a70e", size = 365714, upload-time = "2025-11-09T20:48:15.083Z" },
+ { url = "https://files.pythonhosted.org/packages/dc/6f/806b895f476582c62a2f52c453151edd8a0fde5411b0497baaa41018e878/jiter-0.12.0-cp314-cp314-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:90d32894d4c6877a87ae00c6b915b609406819dce8bc0d4e962e4de2784e567e", size = 478989, upload-time = "2025-11-09T20:48:16.706Z" },
+ { url = "https://files.pythonhosted.org/packages/86/6c/012d894dc6e1033acd8db2b8346add33e413ec1c7c002598915278a37f79/jiter-0.12.0-cp314-cp314-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:798e46eed9eb10c3adbbacbd3bdb5ecd4cf7064e453d00dbef08802dae6937ff", size = 378615, upload-time = "2025-11-09T20:48:18.614Z" },
+ { url = "https://files.pythonhosted.org/packages/87/30/d718d599f6700163e28e2c71c0bbaf6dace692e7df2592fd793ac9276717/jiter-0.12.0-cp314-cp314-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:b3f1368f0a6719ea80013a4eb90ba72e75d7ea67cfc7846db2ca504f3df0169a", size = 364745, upload-time = "2025-11-09T20:48:20.117Z" },
+ { url = "https://files.pythonhosted.org/packages/8f/85/315b45ce4b6ddc7d7fceca24068543b02bdc8782942f4ee49d652e2cc89f/jiter-0.12.0-cp314-cp314-manylinux_2_5_i686.manylinux1_i686.whl", hash = "sha256:65f04a9d0b4406f7e51279710b27484af411896246200e461d80d3ba0caa901a", size = 386502, upload-time = "2025-11-09T20:48:21.543Z" },
+ { url = "https://files.pythonhosted.org/packages/74/0b/ce0434fb40c5b24b368fe81b17074d2840748b4952256bab451b72290a49/jiter-0.12.0-cp314-cp314-musllinux_1_1_aarch64.whl", hash = "sha256:fd990541982a24281d12b67a335e44f117e4c6cbad3c3b75c7dea68bf4ce3a67", size = 519845, upload-time = "2025-11-09T20:48:22.964Z" },
+ { url = "https://files.pythonhosted.org/packages/e8/a3/7a7a4488ba052767846b9c916d208b3ed114e3eb670ee984e4c565b9cf0d/jiter-0.12.0-cp314-cp314-musllinux_1_1_x86_64.whl", hash = "sha256:b111b0e9152fa7df870ecaebb0bd30240d9f7fff1f2003bcb4ed0f519941820b", size = 510701, upload-time = "2025-11-09T20:48:24.483Z" },
+ { url = "https://files.pythonhosted.org/packages/c3/16/052ffbf9d0467b70af24e30f91e0579e13ded0c17bb4a8eb2aed3cb60131/jiter-0.12.0-cp314-cp314-win32.whl", hash = "sha256:a78befb9cc0a45b5a5a0d537b06f8544c2ebb60d19d02c41ff15da28a9e22d42", size = 205029, upload-time = "2025-11-09T20:48:25.749Z" },
+ { url = "https://files.pythonhosted.org/packages/e4/18/3cf1f3f0ccc789f76b9a754bdb7a6977e5d1d671ee97a9e14f7eb728d80e/jiter-0.12.0-cp314-cp314-win_amd64.whl", hash = "sha256:e1fe01c082f6aafbe5c8faf0ff074f38dfb911d53f07ec333ca03f8f6226debf", size = 204960, upload-time = "2025-11-09T20:48:27.415Z" },
+ { url = "https://files.pythonhosted.org/packages/02/68/736821e52ecfdeeb0f024b8ab01b5a229f6b9293bbdb444c27efade50b0f/jiter-0.12.0-cp314-cp314-win_arm64.whl", hash = "sha256:d72f3b5a432a4c546ea4bedc84cce0c3404874f1d1676260b9c7f048a9855451", size = 185529, upload-time = "2025-11-09T20:48:29.125Z" },
+ { url = "https://files.pythonhosted.org/packages/30/61/12ed8ee7a643cce29ac97c2281f9ce3956eb76b037e88d290f4ed0d41480/jiter-0.12.0-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:e6ded41aeba3603f9728ed2b6196e4df875348ab97b28fc8afff115ed42ba7a7", size = 318974, upload-time = "2025-11-09T20:48:30.87Z" },
+ { url = "https://files.pythonhosted.org/packages/2d/c6/f3041ede6d0ed5e0e79ff0de4c8f14f401bbf196f2ef3971cdbe5fd08d1d/jiter-0.12.0-cp314-cp314t-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:a947920902420a6ada6ad51892082521978e9dd44a802663b001436e4b771684", size = 345932, upload-time = "2025-11-09T20:48:32.658Z" },
+ { url = "https://files.pythonhosted.org/packages/d5/5d/4d94835889edd01ad0e2dbfc05f7bdfaed46292e7b504a6ac7839aa00edb/jiter-0.12.0-cp314-cp314t-manylinux_2_17_armv7l.manylinux2014_armv7l.whl", hash = "sha256:add5e227e0554d3a52cf390a7635edaffdf4f8fce4fdbcef3cc2055bb396a30c", size = 367243, upload-time = "2025-11-09T20:48:34.093Z" },
+ { url = "https://files.pythonhosted.org/packages/fd/76/0051b0ac2816253a99d27baf3dda198663aff882fa6ea7deeb94046da24e/jiter-0.12.0-cp314-cp314t-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:3f9b1cda8fcb736250d7e8711d4580ebf004a46771432be0ae4796944b5dfa5d", size = 479315, upload-time = "2025-11-09T20:48:35.507Z" },
+ { url = "https://files.pythonhosted.org/packages/70/ae/83f793acd68e5cb24e483f44f482a1a15601848b9b6f199dacb970098f77/jiter-0.12.0-cp314-cp314t-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:deeb12a2223fe0135c7ff1356a143d57f95bbf1f4a66584f1fc74df21d86b993", size = 380714, upload-time = "2025-11-09T20:48:40.014Z" },
+ { url = "https://files.pythonhosted.org/packages/b1/5e/4808a88338ad2c228b1126b93fcd8ba145e919e886fe910d578230dabe3b/jiter-0.12.0-cp314-cp314t-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:c596cc0f4cb574877550ce4ecd51f8037469146addd676d7c1a30ebe6391923f", size = 365168, upload-time = "2025-11-09T20:48:41.462Z" },
+ { url = "https://files.pythonhosted.org/packages/0c/d4/04619a9e8095b42aef436b5aeb4c0282b4ff1b27d1db1508df9f5dc82750/jiter-0.12.0-cp314-cp314t-manylinux_2_5_i686.manylinux1_i686.whl", hash = "sha256:5ab4c823b216a4aeab3fdbf579c5843165756bd9ad87cc6b1c65919c4715f783", size = 387893, upload-time = "2025-11-09T20:48:42.921Z" },
+ { url = "https://files.pythonhosted.org/packages/17/ea/d3c7e62e4546fdc39197fa4a4315a563a89b95b6d54c0d25373842a59cbe/jiter-0.12.0-cp314-cp314t-musllinux_1_1_aarch64.whl", hash = "sha256:e427eee51149edf962203ff8db75a7514ab89be5cb623fb9cea1f20b54f1107b", size = 520828, upload-time = "2025-11-09T20:48:44.278Z" },
+ { url = "https://files.pythonhosted.org/packages/cc/0b/c6d3562a03fd767e31cb119d9041ea7958c3c80cb3d753eafb19b3b18349/jiter-0.12.0-cp314-cp314t-musllinux_1_1_x86_64.whl", hash = "sha256:edb868841f84c111255ba5e80339d386d937ec1fdce419518ce1bd9370fac5b6", size = 511009, upload-time = "2025-11-09T20:48:45.726Z" },
+ { url = "https://files.pythonhosted.org/packages/aa/51/2cb4468b3448a8385ebcd15059d325c9ce67df4e2758d133ab9442b19834/jiter-0.12.0-cp314-cp314t-win32.whl", hash = "sha256:8bbcfe2791dfdb7c5e48baf646d37a6a3dcb5a97a032017741dea9f817dca183", size = 205110, upload-time = "2025-11-09T20:48:47.033Z" },
+ { url = "https://files.pythonhosted.org/packages/b2/c5/ae5ec83dec9c2d1af805fd5fe8f74ebded9c8670c5210ec7820ce0dbeb1e/jiter-0.12.0-cp314-cp314t-win_amd64.whl", hash = "sha256:2fa940963bf02e1d8226027ef461e36af472dea85d36054ff835aeed944dd873", size = 205223, upload-time = "2025-11-09T20:48:49.076Z" },
+ { url = "https://files.pythonhosted.org/packages/97/9a/3c5391907277f0e55195550cf3fa8e293ae9ee0c00fb402fec1e38c0c82f/jiter-0.12.0-cp314-cp314t-win_arm64.whl", hash = "sha256:506c9708dd29b27288f9f8f1140c3cb0e3d8ddb045956d7757b1fa0e0f39a473", size = 185564, upload-time = "2025-11-09T20:48:50.376Z" },
+ { url = "https://files.pythonhosted.org/packages/cb/f5/12efb8ada5f5c9edc1d4555fe383c1fb2eac05ac5859258a72d61981d999/jiter-0.12.0-graalpy312-graalpy250_312_native-macosx_10_12_x86_64.whl", hash = "sha256:e8547883d7b96ef2e5fe22b88f8a4c8725a56e7f4abafff20fd5272d634c7ecb", size = 309974, upload-time = "2025-11-09T20:49:17.187Z" },
+ { url = "https://files.pythonhosted.org/packages/85/15/d6eb3b770f6a0d332675141ab3962fd4a7c270ede3515d9f3583e1d28276/jiter-0.12.0-graalpy312-graalpy250_312_native-macosx_11_0_arm64.whl", hash = "sha256:89163163c0934854a668ed783a2546a0617f71706a2551a4a0666d91ab365d6b", size = 304233, upload-time = "2025-11-09T20:49:18.734Z" },
+ { url = "https://files.pythonhosted.org/packages/8c/3e/e7e06743294eea2cf02ced6aa0ff2ad237367394e37a0e2b4a1108c67a36/jiter-0.12.0-graalpy312-graalpy250_312_native-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:d96b264ab7d34bbb2312dedc47ce07cd53f06835eacbc16dde3761f47c3a9e7f", size = 338537, upload-time = "2025-11-09T20:49:20.317Z" },
+ { url = "https://files.pythonhosted.org/packages/2f/9c/6753e6522b8d0ef07d3a3d239426669e984fb0eba15a315cdbc1253904e4/jiter-0.12.0-graalpy312-graalpy250_312_native-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:c24e864cb30ab82311c6425655b0cdab0a98c5d973b065c66a3f020740c2324c", size = 346110, upload-time = "2025-11-09T20:49:21.817Z" },
+]
+
+[[package]]
+name = "joblib"
+version = "1.5.2"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/e8/5d/447af5ea094b9e4c4054f82e223ada074c552335b9b4b2d14bd9b35a67c4/joblib-1.5.2.tar.gz", hash = "sha256:3faa5c39054b2f03ca547da9b2f52fde67c06240c31853f306aea97f13647b55", size = 331077, upload-time = "2025-08-27T12:15:46.575Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/1e/e8/685f47e0d754320684db4425a0967f7d3fa70126bffd76110b7009a0090f/joblib-1.5.2-py3-none-any.whl", hash = "sha256:4e1f0bdbb987e6d843c70cf43714cb276623def372df3c22fe5266b2670bc241", size = 308396, upload-time = "2025-08-27T12:15:45.188Z" },
+]
+
+[[package]]
+name = "json5"
+version = "0.12.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/12/ae/929aee9619e9eba9015207a9d2c1c54db18311da7eb4dcf6d41ad6f0eb67/json5-0.12.1.tar.gz", hash = "sha256:b2743e77b3242f8d03c143dd975a6ec7c52e2f2afe76ed934e53503dd4ad4990", size = 52191, upload-time = "2025-08-12T19:47:42.583Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/85/e2/05328bd2621be49a6fed9e3030b1e51a2d04537d3f816d211b9cc53c5262/json5-0.12.1-py3-none-any.whl", hash = "sha256:d9c9b3bc34a5f54d43c35e11ef7cb87d8bdd098c6ace87117a7b7e83e705c1d5", size = 36119, upload-time = "2025-08-12T19:47:41.131Z" },
+]
+
+[[package]]
+name = "jsonpointer"
+version = "3.0.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/6a/0a/eebeb1fa92507ea94016a2a790b93c2ae41a7e18778f85471dc54475ed25/jsonpointer-3.0.0.tar.gz", hash = "sha256:2b2d729f2091522d61c3b31f82e11870f60b68f43fbc705cb76bf4b832af59ef", size = 9114, upload-time = "2024-06-10T19:24:42.462Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/71/92/5e77f98553e9e75130c78900d000368476aed74276eb8ae8796f65f00918/jsonpointer-3.0.0-py2.py3-none-any.whl", hash = "sha256:13e088adc14fca8b6aa8177c044e12701e6ad4b28ff10e65f2267a90109c9942", size = 7595, upload-time = "2024-06-10T19:24:40.698Z" },
+]
+
+[[package]]
+name = "jsonschema"
+version = "4.25.1"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "attrs" },
+ { name = "jsonschema-specifications" },
+ { name = "referencing" },
+ { name = "rpds-py" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/74/69/f7185de793a29082a9f3c7728268ffb31cb5095131a9c139a74078e27336/jsonschema-4.25.1.tar.gz", hash = "sha256:e4a9655ce0da0c0b67a085847e00a3a51449e1157f4f75e9fb5aa545e122eb85", size = 357342, upload-time = "2025-08-18T17:03:50.038Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/bf/9c/8c95d856233c1f82500c2450b8c68576b4cf1c871db3afac5c34ff84e6fd/jsonschema-4.25.1-py3-none-any.whl", hash = "sha256:3fba0169e345c7175110351d456342c364814cfcf3b964ba4587f22915230a63", size = 90040, upload-time = "2025-08-18T17:03:48.373Z" },
+]
+
+[package.optional-dependencies]
+format-nongpl = [
+ { name = "fqdn" },
+ { name = "idna" },
+ { name = "isoduration" },
+ { name = "jsonpointer" },
+ { name = "rfc3339-validator" },
+ { name = "rfc3986-validator" },
+ { name = "rfc3987-syntax" },
+ { name = "uri-template" },
+ { name = "webcolors" },
+]
+
+[[package]]
+name = "jsonschema-specifications"
+version = "2025.9.1"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "referencing" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/19/74/a633ee74eb36c44aa6d1095e7cc5569bebf04342ee146178e2d36600708b/jsonschema_specifications-2025.9.1.tar.gz", hash = "sha256:b540987f239e745613c7a9176f3edb72b832a4ac465cf02712288397832b5e8d", size = 32855, upload-time = "2025-09-08T01:34:59.186Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/41/45/1a4ed80516f02155c51f51e8cedb3c1902296743db0bbc66608a0db2814f/jsonschema_specifications-2025.9.1-py3-none-any.whl", hash = "sha256:98802fee3a11ee76ecaca44429fda8a41bff98b00a0f2838151b113f210cc6fe", size = 18437, upload-time = "2025-09-08T01:34:57.871Z" },
+]
+
+[[package]]
+name = "jupyter"
+version = "1.1.1"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "ipykernel" },
+ { name = "ipywidgets" },
+ { name = "jupyter-console" },
+ { name = "jupyterlab" },
+ { name = "nbconvert" },
+ { name = "notebook" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/58/f3/af28ea964ab8bc1e472dba2e82627d36d470c51f5cd38c37502eeffaa25e/jupyter-1.1.1.tar.gz", hash = "sha256:d55467bceabdea49d7e3624af7e33d59c37fff53ed3a350e1ac957bed731de7a", size = 5714959, upload-time = "2024-08-30T07:15:48.299Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/38/64/285f20a31679bf547b75602702f7800e74dbabae36ef324f716c02804753/jupyter-1.1.1-py2.py3-none-any.whl", hash = "sha256:7a59533c22af65439b24bbe60373a4e95af8f16ac65a6c00820ad378e3f7cc83", size = 2657, upload-time = "2024-08-30T07:15:47.045Z" },
+]
+
+[[package]]
+name = "jupyter-client"
+version = "8.6.3"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "jupyter-core" },
+ { name = "python-dateutil" },
+ { name = "pyzmq" },
+ { name = "tornado" },
+ { name = "traitlets" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/71/22/bf9f12fdaeae18019a468b68952a60fe6dbab5d67cd2a103cac7659b41ca/jupyter_client-8.6.3.tar.gz", hash = "sha256:35b3a0947c4a6e9d589eb97d7d4cd5e90f910ee73101611f01283732bd6d9419", size = 342019, upload-time = "2024-09-17T10:44:17.613Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/11/85/b0394e0b6fcccd2c1eeefc230978a6f8cb0c5df1e4cd3e7625735a0d7d1e/jupyter_client-8.6.3-py3-none-any.whl", hash = "sha256:e8a19cc986cc45905ac3362915f410f3af85424b4c0905e94fa5f2cb08e8f23f", size = 106105, upload-time = "2024-09-17T10:44:15.218Z" },
+]
+
+[[package]]
+name = "jupyter-console"
+version = "6.6.3"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "ipykernel" },
+ { name = "ipython" },
+ { name = "jupyter-client" },
+ { name = "jupyter-core" },
+ { name = "prompt-toolkit" },
+ { name = "pygments" },
+ { name = "pyzmq" },
+ { name = "traitlets" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/bd/2d/e2fd31e2fc41c14e2bcb6c976ab732597e907523f6b2420305f9fc7fdbdb/jupyter_console-6.6.3.tar.gz", hash = "sha256:566a4bf31c87adbfadf22cdf846e3069b59a71ed5da71d6ba4d8aaad14a53539", size = 34363, upload-time = "2023-03-06T14:13:31.02Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/ca/77/71d78d58f15c22db16328a476426f7ac4a60d3a5a7ba3b9627ee2f7903d4/jupyter_console-6.6.3-py3-none-any.whl", hash = "sha256:309d33409fcc92ffdad25f0bcdf9a4a9daa61b6f341177570fdac03de5352485", size = 24510, upload-time = "2023-03-06T14:13:28.229Z" },
+]
+
+[[package]]
+name = "jupyter-core"
+version = "5.9.1"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "platformdirs" },
+ { name = "traitlets" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/02/49/9d1284d0dc65e2c757b74c6687b6d319b02f822ad039e5c512df9194d9dd/jupyter_core-5.9.1.tar.gz", hash = "sha256:4d09aaff303b9566c3ce657f580bd089ff5c91f5f89cf7d8846c3cdf465b5508", size = 89814, upload-time = "2025-10-16T19:19:18.444Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/e7/e7/80988e32bf6f73919a113473a604f5a8f09094de312b9d52b79c2df7612b/jupyter_core-5.9.1-py3-none-any.whl", hash = "sha256:ebf87fdc6073d142e114c72c9e29a9d7ca03fad818c5d300ce2adc1fb0743407", size = 29032, upload-time = "2025-10-16T19:19:16.783Z" },
+]
+
+[[package]]
+name = "jupyter-events"
+version = "0.12.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "jsonschema", extra = ["format-nongpl"] },
+ { name = "packaging" },
+ { name = "python-json-logger" },
+ { name = "pyyaml" },
+ { name = "referencing" },
+ { name = "rfc3339-validator" },
+ { name = "rfc3986-validator" },
+ { name = "traitlets" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/9d/c3/306d090461e4cf3cd91eceaff84bede12a8e52cd821c2d20c9a4fd728385/jupyter_events-0.12.0.tar.gz", hash = "sha256:fc3fce98865f6784c9cd0a56a20644fc6098f21c8c33834a8d9fe383c17e554b", size = 62196, upload-time = "2025-02-03T17:23:41.485Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/e2/48/577993f1f99c552f18a0428731a755e06171f9902fa118c379eb7c04ea22/jupyter_events-0.12.0-py3-none-any.whl", hash = "sha256:6464b2fa5ad10451c3d35fabc75eab39556ae1e2853ad0c0cc31b656731a97fb", size = 19430, upload-time = "2025-02-03T17:23:38.643Z" },
+]
+
+[[package]]
+name = "jupyter-lsp"
+version = "2.3.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "jupyter-server" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/eb/5a/9066c9f8e94ee517133cd98dba393459a16cd48bba71a82f16a65415206c/jupyter_lsp-2.3.0.tar.gz", hash = "sha256:458aa59339dc868fb784d73364f17dbce8836e906cd75fd471a325cba02e0245", size = 54823, upload-time = "2025-08-27T17:47:34.671Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/1a/60/1f6cee0c46263de1173894f0fafcb3475ded276c472c14d25e0280c18d6d/jupyter_lsp-2.3.0-py3-none-any.whl", hash = "sha256:e914a3cb2addf48b1c7710914771aaf1819d46b2e5a79b0f917b5478ec93f34f", size = 76687, upload-time = "2025-08-27T17:47:33.15Z" },
+]
+
+[[package]]
+name = "jupyter-server"
+version = "2.17.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "anyio" },
+ { name = "argon2-cffi" },
+ { name = "jinja2" },
+ { name = "jupyter-client" },
+ { name = "jupyter-core" },
+ { name = "jupyter-events" },
+ { name = "jupyter-server-terminals" },
+ { name = "nbconvert" },
+ { name = "nbformat" },
+ { name = "packaging" },
+ { name = "prometheus-client" },
+ { name = "pywinpty", marker = "os_name == 'nt' and sys_platform != 'linux'" },
+ { name = "pyzmq" },
+ { name = "send2trash" },
+ { name = "terminado" },
+ { name = "tornado" },
+ { name = "traitlets" },
+ { name = "websocket-client" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/5b/ac/e040ec363d7b6b1f11304cc9f209dac4517ece5d5e01821366b924a64a50/jupyter_server-2.17.0.tar.gz", hash = "sha256:c38ea898566964c888b4772ae1ed58eca84592e88251d2cfc4d171f81f7e99d5", size = 731949, upload-time = "2025-08-21T14:42:54.042Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/92/80/a24767e6ca280f5a49525d987bf3e4d7552bf67c8be07e8ccf20271f8568/jupyter_server-2.17.0-py3-none-any.whl", hash = "sha256:e8cb9c7db4251f51ed307e329b81b72ccf2056ff82d50524debde1ee1870e13f", size = 388221, upload-time = "2025-08-21T14:42:52.034Z" },
+]
+
+[[package]]
+name = "jupyter-server-terminals"
+version = "0.5.3"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "pywinpty", marker = "os_name == 'nt' and sys_platform != 'linux'" },
+ { name = "terminado" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/fc/d5/562469734f476159e99a55426d697cbf8e7eb5efe89fb0e0b4f83a3d3459/jupyter_server_terminals-0.5.3.tar.gz", hash = "sha256:5ae0295167220e9ace0edcfdb212afd2b01ee8d179fe6f23c899590e9b8a5269", size = 31430, upload-time = "2024-03-12T14:37:03.049Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/07/2d/2b32cdbe8d2a602f697a649798554e4f072115438e92249624e532e8aca6/jupyter_server_terminals-0.5.3-py3-none-any.whl", hash = "sha256:41ee0d7dc0ebf2809c668e0fc726dfaf258fcd3e769568996ca731b6194ae9aa", size = 13656, upload-time = "2024-03-12T14:37:00.708Z" },
+]
+
+[[package]]
+name = "jupyterlab"
+version = "4.5.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "async-lru" },
+ { name = "httpx" },
+ { name = "ipykernel" },
+ { name = "jinja2" },
+ { name = "jupyter-core" },
+ { name = "jupyter-lsp" },
+ { name = "jupyter-server" },
+ { name = "jupyterlab-server" },
+ { name = "notebook-shim" },
+ { name = "packaging" },
+ { name = "setuptools" },
+ { name = "tornado" },
+ { name = "traitlets" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/df/e5/4fa382a796a6d8e2cd867816b64f1ff27f906e43a7a83ad9eb389e448cd8/jupyterlab-4.5.0.tar.gz", hash = "sha256:aec33d6d8f1225b495ee2cf20f0514f45e6df8e360bdd7ac9bace0b7ac5177ea", size = 23989880, upload-time = "2025-11-18T13:19:00.365Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/6c/1e/5a4d5498eba382fee667ed797cf64ae5d1b13b04356df62f067f48bb0f61/jupyterlab-4.5.0-py3-none-any.whl", hash = "sha256:88e157c75c1afff64c7dc4b801ec471450b922a4eae4305211ddd40da8201c8a", size = 12380641, upload-time = "2025-11-18T13:18:56.252Z" },
+]
+
+[[package]]
+name = "jupyterlab-pygments"
+version = "0.3.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/90/51/9187be60d989df97f5f0aba133fa54e7300f17616e065d1ada7d7646b6d6/jupyterlab_pygments-0.3.0.tar.gz", hash = "sha256:721aca4d9029252b11cfa9d185e5b5af4d54772bb8072f9b7036f4170054d35d", size = 512900, upload-time = "2023-11-23T09:26:37.44Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/b1/dd/ead9d8ea85bf202d90cc513b533f9c363121c7792674f78e0d8a854b63b4/jupyterlab_pygments-0.3.0-py3-none-any.whl", hash = "sha256:841a89020971da1d8693f1a99997aefc5dc424bb1b251fd6322462a1b8842780", size = 15884, upload-time = "2023-11-23T09:26:34.325Z" },
+]
+
+[[package]]
+name = "jupyterlab-server"
+version = "2.28.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "babel" },
+ { name = "jinja2" },
+ { name = "json5" },
+ { name = "jsonschema" },
+ { name = "jupyter-server" },
+ { name = "packaging" },
+ { name = "requests" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/d6/2c/90153f189e421e93c4bb4f9e3f59802a1f01abd2ac5cf40b152d7f735232/jupyterlab_server-2.28.0.tar.gz", hash = "sha256:35baa81898b15f93573e2deca50d11ac0ae407ebb688299d3a5213265033712c", size = 76996, upload-time = "2025-10-22T13:59:18.37Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/e0/07/a000fe835f76b7e1143242ab1122e6362ef1c03f23f83a045c38859c2ae0/jupyterlab_server-2.28.0-py3-none-any.whl", hash = "sha256:e4355b148fdcf34d312bbbc80f22467d6d20460e8b8736bf235577dd18506968", size = 59830, upload-time = "2025-10-22T13:59:16.767Z" },
+]
+
+[[package]]
+name = "jupyterlab-widgets"
+version = "3.0.16"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/26/2d/ef58fed122b268c69c0aa099da20bc67657cdfb2e222688d5731bd5b971d/jupyterlab_widgets-3.0.16.tar.gz", hash = "sha256:423da05071d55cf27a9e602216d35a3a65a3e41cdf9c5d3b643b814ce38c19e0", size = 897423, upload-time = "2025-11-01T21:11:29.724Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/ab/b5/36c712098e6191d1b4e349304ef73a8d06aed77e56ceaac8c0a306c7bda1/jupyterlab_widgets-3.0.16-py3-none-any.whl", hash = "sha256:45fa36d9c6422cf2559198e4db481aa243c7a32d9926b500781c830c80f7ecf8", size = 914926, upload-time = "2025-11-01T21:11:28.008Z" },
+]
+
+[[package]]
+name = "kiwisolver"
+version = "1.4.9"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/5c/3c/85844f1b0feb11ee581ac23fe5fce65cd049a200c1446708cc1b7f922875/kiwisolver-1.4.9.tar.gz", hash = "sha256:c3b22c26c6fd6811b0ae8363b95ca8ce4ea3c202d3d0975b2914310ceb1bcc4d", size = 97564, upload-time = "2025-08-10T21:27:49.279Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/86/c9/13573a747838aeb1c76e3267620daa054f4152444d1f3d1a2324b78255b5/kiwisolver-1.4.9-cp312-cp312-macosx_10_13_universal2.whl", hash = "sha256:ac5a486ac389dddcc5bef4f365b6ae3ffff2c433324fb38dd35e3fab7c957999", size = 123686, upload-time = "2025-08-10T21:26:10.034Z" },
+ { url = "https://files.pythonhosted.org/packages/51/ea/2ecf727927f103ffd1739271ca19c424d0e65ea473fbaeea1c014aea93f6/kiwisolver-1.4.9-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:f2ba92255faa7309d06fe44c3a4a97efe1c8d640c2a79a5ef728b685762a6fd2", size = 66460, upload-time = "2025-08-10T21:26:11.083Z" },
+ { url = "https://files.pythonhosted.org/packages/5b/5a/51f5464373ce2aeb5194508298a508b6f21d3867f499556263c64c621914/kiwisolver-1.4.9-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:4a2899935e724dd1074cb568ce7ac0dce28b2cd6ab539c8e001a8578eb106d14", size = 64952, upload-time = "2025-08-10T21:26:12.058Z" },
+ { url = "https://files.pythonhosted.org/packages/70/90/6d240beb0f24b74371762873e9b7f499f1e02166a2d9c5801f4dbf8fa12e/kiwisolver-1.4.9-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:f6008a4919fdbc0b0097089f67a1eb55d950ed7e90ce2cc3e640abadd2757a04", size = 1474756, upload-time = "2025-08-10T21:26:13.096Z" },
+ { url = "https://files.pythonhosted.org/packages/12/42/f36816eaf465220f683fb711efdd1bbf7a7005a2473d0e4ed421389bd26c/kiwisolver-1.4.9-cp312-cp312-manylinux_2_24_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:67bb8b474b4181770f926f7b7d2f8c0248cbcb78b660fdd41a47054b28d2a752", size = 1276404, upload-time = "2025-08-10T21:26:14.457Z" },
+ { url = "https://files.pythonhosted.org/packages/2e/64/bc2de94800adc830c476dce44e9b40fd0809cddeef1fde9fcf0f73da301f/kiwisolver-1.4.9-cp312-cp312-manylinux_2_24_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:2327a4a30d3ee07d2fbe2e7933e8a37c591663b96ce42a00bc67461a87d7df77", size = 1294410, upload-time = "2025-08-10T21:26:15.73Z" },
+ { url = "https://files.pythonhosted.org/packages/5f/42/2dc82330a70aa8e55b6d395b11018045e58d0bb00834502bf11509f79091/kiwisolver-1.4.9-cp312-cp312-manylinux_2_24_s390x.manylinux_2_28_s390x.whl", hash = "sha256:7a08b491ec91b1d5053ac177afe5290adacf1f0f6307d771ccac5de30592d198", size = 1343631, upload-time = "2025-08-10T21:26:17.045Z" },
+ { url = "https://files.pythonhosted.org/packages/22/fd/f4c67a6ed1aab149ec5a8a401c323cee7a1cbe364381bb6c9c0d564e0e20/kiwisolver-1.4.9-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:d8fc5c867c22b828001b6a38d2eaeb88160bf5783c6cb4a5e440efc981ce286d", size = 2224963, upload-time = "2025-08-10T21:26:18.737Z" },
+ { url = "https://files.pythonhosted.org/packages/45/aa/76720bd4cb3713314677d9ec94dcc21ced3f1baf4830adde5bb9b2430a5f/kiwisolver-1.4.9-cp312-cp312-musllinux_1_2_ppc64le.whl", hash = "sha256:3b3115b2581ea35bb6d1f24a4c90af37e5d9b49dcff267eeed14c3893c5b86ab", size = 2321295, upload-time = "2025-08-10T21:26:20.11Z" },
+ { url = "https://files.pythonhosted.org/packages/80/19/d3ec0d9ab711242f56ae0dc2fc5d70e298bb4a1f9dfab44c027668c673a1/kiwisolver-1.4.9-cp312-cp312-musllinux_1_2_s390x.whl", hash = "sha256:858e4c22fb075920b96a291928cb7dea5644e94c0ee4fcd5af7e865655e4ccf2", size = 2487987, upload-time = "2025-08-10T21:26:21.49Z" },
+ { url = "https://files.pythonhosted.org/packages/39/e9/61e4813b2c97e86b6fdbd4dd824bf72d28bcd8d4849b8084a357bc0dd64d/kiwisolver-1.4.9-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:ed0fecd28cc62c54b262e3736f8bb2512d8dcfdc2bcf08be5f47f96bf405b145", size = 2291817, upload-time = "2025-08-10T21:26:22.812Z" },
+ { url = "https://files.pythonhosted.org/packages/a0/41/85d82b0291db7504da3c2defe35c9a8a5c9803a730f297bd823d11d5fb77/kiwisolver-1.4.9-cp312-cp312-win_amd64.whl", hash = "sha256:f68208a520c3d86ea51acf688a3e3002615a7f0238002cccc17affecc86a8a54", size = 73895, upload-time = "2025-08-10T21:26:24.37Z" },
+ { url = "https://files.pythonhosted.org/packages/e2/92/5f3068cf15ee5cb624a0c7596e67e2a0bb2adee33f71c379054a491d07da/kiwisolver-1.4.9-cp312-cp312-win_arm64.whl", hash = "sha256:2c1a4f57df73965f3f14df20b80ee29e6a7930a57d2d9e8491a25f676e197c60", size = 64992, upload-time = "2025-08-10T21:26:25.732Z" },
+ { url = "https://files.pythonhosted.org/packages/31/c1/c2686cda909742ab66c7388e9a1a8521a59eb89f8bcfbee28fc980d07e24/kiwisolver-1.4.9-cp313-cp313-macosx_10_13_universal2.whl", hash = "sha256:a5d0432ccf1c7ab14f9949eec60c5d1f924f17c037e9f8b33352fa05799359b8", size = 123681, upload-time = "2025-08-10T21:26:26.725Z" },
+ { url = "https://files.pythonhosted.org/packages/ca/f0/f44f50c9f5b1a1860261092e3bc91ecdc9acda848a8b8c6abfda4a24dd5c/kiwisolver-1.4.9-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:efb3a45b35622bb6c16dbfab491a8f5a391fe0e9d45ef32f4df85658232ca0e2", size = 66464, upload-time = "2025-08-10T21:26:27.733Z" },
+ { url = "https://files.pythonhosted.org/packages/2d/7a/9d90a151f558e29c3936b8a47ac770235f436f2120aca41a6d5f3d62ae8d/kiwisolver-1.4.9-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:1a12cf6398e8a0a001a059747a1cbf24705e18fe413bc22de7b3d15c67cffe3f", size = 64961, upload-time = "2025-08-10T21:26:28.729Z" },
+ { url = "https://files.pythonhosted.org/packages/e9/e9/f218a2cb3a9ffbe324ca29a9e399fa2d2866d7f348ec3a88df87fc248fc5/kiwisolver-1.4.9-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:b67e6efbf68e077dd71d1a6b37e43e1a99d0bff1a3d51867d45ee8908b931098", size = 1474607, upload-time = "2025-08-10T21:26:29.798Z" },
+ { url = "https://files.pythonhosted.org/packages/d9/28/aac26d4c882f14de59041636292bc838db8961373825df23b8eeb807e198/kiwisolver-1.4.9-cp313-cp313-manylinux_2_24_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:5656aa670507437af0207645273ccdfee4f14bacd7f7c67a4306d0dcaeaf6eed", size = 1276546, upload-time = "2025-08-10T21:26:31.401Z" },
+ { url = "https://files.pythonhosted.org/packages/8b/ad/8bfc1c93d4cc565e5069162f610ba2f48ff39b7de4b5b8d93f69f30c4bed/kiwisolver-1.4.9-cp313-cp313-manylinux_2_24_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:bfc08add558155345129c7803b3671cf195e6a56e7a12f3dde7c57d9b417f525", size = 1294482, upload-time = "2025-08-10T21:26:32.721Z" },
+ { url = "https://files.pythonhosted.org/packages/da/f1/6aca55ff798901d8ce403206d00e033191f63d82dd708a186e0ed2067e9c/kiwisolver-1.4.9-cp313-cp313-manylinux_2_24_s390x.manylinux_2_28_s390x.whl", hash = "sha256:40092754720b174e6ccf9e845d0d8c7d8e12c3d71e7fc35f55f3813e96376f78", size = 1343720, upload-time = "2025-08-10T21:26:34.032Z" },
+ { url = "https://files.pythonhosted.org/packages/d1/91/eed031876c595c81d90d0f6fc681ece250e14bf6998c3d7c419466b523b7/kiwisolver-1.4.9-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:497d05f29a1300d14e02e6441cf0f5ee81c1ff5a304b0d9fb77423974684e08b", size = 2224907, upload-time = "2025-08-10T21:26:35.824Z" },
+ { url = "https://files.pythonhosted.org/packages/e9/ec/4d1925f2e49617b9cca9c34bfa11adefad49d00db038e692a559454dfb2e/kiwisolver-1.4.9-cp313-cp313-musllinux_1_2_ppc64le.whl", hash = "sha256:bdd1a81a1860476eb41ac4bc1e07b3f07259e6d55bbf739b79c8aaedcf512799", size = 2321334, upload-time = "2025-08-10T21:26:37.534Z" },
+ { url = "https://files.pythonhosted.org/packages/43/cb/450cd4499356f68802750c6ddc18647b8ea01ffa28f50d20598e0befe6e9/kiwisolver-1.4.9-cp313-cp313-musllinux_1_2_s390x.whl", hash = "sha256:e6b93f13371d341afee3be9f7c5964e3fe61d5fa30f6a30eb49856935dfe4fc3", size = 2488313, upload-time = "2025-08-10T21:26:39.191Z" },
+ { url = "https://files.pythonhosted.org/packages/71/67/fc76242bd99f885651128a5d4fa6083e5524694b7c88b489b1b55fdc491d/kiwisolver-1.4.9-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:d75aa530ccfaa593da12834b86a0724f58bff12706659baa9227c2ccaa06264c", size = 2291970, upload-time = "2025-08-10T21:26:40.828Z" },
+ { url = "https://files.pythonhosted.org/packages/75/bd/f1a5d894000941739f2ae1b65a32892349423ad49c2e6d0771d0bad3fae4/kiwisolver-1.4.9-cp313-cp313-win_amd64.whl", hash = "sha256:dd0a578400839256df88c16abddf9ba14813ec5f21362e1fe65022e00c883d4d", size = 73894, upload-time = "2025-08-10T21:26:42.33Z" },
+ { url = "https://files.pythonhosted.org/packages/95/38/dce480814d25b99a391abbddadc78f7c117c6da34be68ca8b02d5848b424/kiwisolver-1.4.9-cp313-cp313-win_arm64.whl", hash = "sha256:d4188e73af84ca82468f09cadc5ac4db578109e52acb4518d8154698d3a87ca2", size = 64995, upload-time = "2025-08-10T21:26:43.889Z" },
+ { url = "https://files.pythonhosted.org/packages/e2/37/7d218ce5d92dadc5ebdd9070d903e0c7cf7edfe03f179433ac4d13ce659c/kiwisolver-1.4.9-cp313-cp313t-macosx_10_13_universal2.whl", hash = "sha256:5a0f2724dfd4e3b3ac5a82436a8e6fd16baa7d507117e4279b660fe8ca38a3a1", size = 126510, upload-time = "2025-08-10T21:26:44.915Z" },
+ { url = "https://files.pythonhosted.org/packages/23/b0/e85a2b48233daef4b648fb657ebbb6f8367696a2d9548a00b4ee0eb67803/kiwisolver-1.4.9-cp313-cp313t-macosx_10_13_x86_64.whl", hash = "sha256:1b11d6a633e4ed84fc0ddafd4ebfd8ea49b3f25082c04ad12b8315c11d504dc1", size = 67903, upload-time = "2025-08-10T21:26:45.934Z" },
+ { url = "https://files.pythonhosted.org/packages/44/98/f2425bc0113ad7de24da6bb4dae1343476e95e1d738be7c04d31a5d037fd/kiwisolver-1.4.9-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:61874cdb0a36016354853593cffc38e56fc9ca5aa97d2c05d3dcf6922cd55a11", size = 66402, upload-time = "2025-08-10T21:26:47.101Z" },
+ { url = "https://files.pythonhosted.org/packages/98/d8/594657886df9f34c4177cc353cc28ca7e6e5eb562d37ccc233bff43bbe2a/kiwisolver-1.4.9-cp313-cp313t-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:60c439763a969a6af93b4881db0eed8fadf93ee98e18cbc35bc8da868d0c4f0c", size = 1582135, upload-time = "2025-08-10T21:26:48.665Z" },
+ { url = "https://files.pythonhosted.org/packages/5c/c6/38a115b7170f8b306fc929e166340c24958347308ea3012c2b44e7e295db/kiwisolver-1.4.9-cp313-cp313t-manylinux_2_24_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:92a2f997387a1b79a75e7803aa7ded2cfbe2823852ccf1ba3bcf613b62ae3197", size = 1389409, upload-time = "2025-08-10T21:26:50.335Z" },
+ { url = "https://files.pythonhosted.org/packages/bf/3b/e04883dace81f24a568bcee6eb3001da4ba05114afa622ec9b6fafdc1f5e/kiwisolver-1.4.9-cp313-cp313t-manylinux_2_24_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:a31d512c812daea6d8b3be3b2bfcbeb091dbb09177706569bcfc6240dcf8b41c", size = 1401763, upload-time = "2025-08-10T21:26:51.867Z" },
+ { url = "https://files.pythonhosted.org/packages/9f/80/20ace48e33408947af49d7d15c341eaee69e4e0304aab4b7660e234d6288/kiwisolver-1.4.9-cp313-cp313t-manylinux_2_24_s390x.manylinux_2_28_s390x.whl", hash = "sha256:52a15b0f35dad39862d376df10c5230155243a2c1a436e39eb55623ccbd68185", size = 1453643, upload-time = "2025-08-10T21:26:53.592Z" },
+ { url = "https://files.pythonhosted.org/packages/64/31/6ce4380a4cd1f515bdda976a1e90e547ccd47b67a1546d63884463c92ca9/kiwisolver-1.4.9-cp313-cp313t-musllinux_1_2_aarch64.whl", hash = "sha256:a30fd6fdef1430fd9e1ba7b3398b5ee4e2887783917a687d86ba69985fb08748", size = 2330818, upload-time = "2025-08-10T21:26:55.051Z" },
+ { url = "https://files.pythonhosted.org/packages/fa/e9/3f3fcba3bcc7432c795b82646306e822f3fd74df0ee81f0fa067a1f95668/kiwisolver-1.4.9-cp313-cp313t-musllinux_1_2_ppc64le.whl", hash = "sha256:cc9617b46837c6468197b5945e196ee9ca43057bb7d9d1ae688101e4e1dddf64", size = 2419963, upload-time = "2025-08-10T21:26:56.421Z" },
+ { url = "https://files.pythonhosted.org/packages/99/43/7320c50e4133575c66e9f7dadead35ab22d7c012a3b09bb35647792b2a6d/kiwisolver-1.4.9-cp313-cp313t-musllinux_1_2_s390x.whl", hash = "sha256:0ab74e19f6a2b027ea4f845a78827969af45ce790e6cb3e1ebab71bdf9f215ff", size = 2594639, upload-time = "2025-08-10T21:26:57.882Z" },
+ { url = "https://files.pythonhosted.org/packages/65/d6/17ae4a270d4a987ef8a385b906d2bdfc9fce502d6dc0d3aea865b47f548c/kiwisolver-1.4.9-cp313-cp313t-musllinux_1_2_x86_64.whl", hash = "sha256:dba5ee5d3981160c28d5490f0d1b7ed730c22470ff7f6cc26cfcfaacb9896a07", size = 2391741, upload-time = "2025-08-10T21:26:59.237Z" },
+ { url = "https://files.pythonhosted.org/packages/2a/8f/8f6f491d595a9e5912971f3f863d81baddccc8a4d0c3749d6a0dd9ffc9df/kiwisolver-1.4.9-cp313-cp313t-win_arm64.whl", hash = "sha256:0749fd8f4218ad2e851e11cc4dc05c7cbc0cbc4267bdfdb31782e65aace4ee9c", size = 68646, upload-time = "2025-08-10T21:27:00.52Z" },
+ { url = "https://files.pythonhosted.org/packages/6b/32/6cc0fbc9c54d06c2969faa9c1d29f5751a2e51809dd55c69055e62d9b426/kiwisolver-1.4.9-cp314-cp314-macosx_10_13_universal2.whl", hash = "sha256:9928fe1eb816d11ae170885a74d074f57af3a0d65777ca47e9aeb854a1fba386", size = 123806, upload-time = "2025-08-10T21:27:01.537Z" },
+ { url = "https://files.pythonhosted.org/packages/b2/dd/2bfb1d4a4823d92e8cbb420fe024b8d2167f72079b3bb941207c42570bdf/kiwisolver-1.4.9-cp314-cp314-macosx_10_13_x86_64.whl", hash = "sha256:d0005b053977e7b43388ddec89fa567f43d4f6d5c2c0affe57de5ebf290dc552", size = 66605, upload-time = "2025-08-10T21:27:03.335Z" },
+ { url = "https://files.pythonhosted.org/packages/f7/69/00aafdb4e4509c2ca6064646cba9cd4b37933898f426756adb2cb92ebbed/kiwisolver-1.4.9-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:2635d352d67458b66fd0667c14cb1d4145e9560d503219034a18a87e971ce4f3", size = 64925, upload-time = "2025-08-10T21:27:04.339Z" },
+ { url = "https://files.pythonhosted.org/packages/43/dc/51acc6791aa14e5cb6d8a2e28cefb0dc2886d8862795449d021334c0df20/kiwisolver-1.4.9-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:767c23ad1c58c9e827b649a9ab7809fd5fd9db266a9cf02b0e926ddc2c680d58", size = 1472414, upload-time = "2025-08-10T21:27:05.437Z" },
+ { url = "https://files.pythonhosted.org/packages/3d/bb/93fa64a81db304ac8a246f834d5094fae4b13baf53c839d6bb6e81177129/kiwisolver-1.4.9-cp314-cp314-manylinux_2_24_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:72d0eb9fba308b8311685c2268cf7d0a0639a6cd027d8128659f72bdd8a024b4", size = 1281272, upload-time = "2025-08-10T21:27:07.063Z" },
+ { url = "https://files.pythonhosted.org/packages/70/e6/6df102916960fb8d05069d4bd92d6d9a8202d5a3e2444494e7cd50f65b7a/kiwisolver-1.4.9-cp314-cp314-manylinux_2_24_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:f68e4f3eeca8fb22cc3d731f9715a13b652795ef657a13df1ad0c7dc0e9731df", size = 1298578, upload-time = "2025-08-10T21:27:08.452Z" },
+ { url = "https://files.pythonhosted.org/packages/7c/47/e142aaa612f5343736b087864dbaebc53ea8831453fb47e7521fa8658f30/kiwisolver-1.4.9-cp314-cp314-manylinux_2_24_s390x.manylinux_2_28_s390x.whl", hash = "sha256:d84cd4061ae292d8ac367b2c3fa3aad11cb8625a95d135fe93f286f914f3f5a6", size = 1345607, upload-time = "2025-08-10T21:27:10.125Z" },
+ { url = "https://files.pythonhosted.org/packages/54/89/d641a746194a0f4d1a3670fb900d0dbaa786fb98341056814bc3f058fa52/kiwisolver-1.4.9-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:a60ea74330b91bd22a29638940d115df9dc00af5035a9a2a6ad9399ffb4ceca5", size = 2230150, upload-time = "2025-08-10T21:27:11.484Z" },
+ { url = "https://files.pythonhosted.org/packages/aa/6b/5ee1207198febdf16ac11f78c5ae40861b809cbe0e6d2a8d5b0b3044b199/kiwisolver-1.4.9-cp314-cp314-musllinux_1_2_ppc64le.whl", hash = "sha256:ce6a3a4e106cf35c2d9c4fa17c05ce0b180db622736845d4315519397a77beaf", size = 2325979, upload-time = "2025-08-10T21:27:12.917Z" },
+ { url = "https://files.pythonhosted.org/packages/fc/ff/b269eefd90f4ae14dcc74973d5a0f6d28d3b9bb1afd8c0340513afe6b39a/kiwisolver-1.4.9-cp314-cp314-musllinux_1_2_s390x.whl", hash = "sha256:77937e5e2a38a7b48eef0585114fe7930346993a88060d0bf886086d2aa49ef5", size = 2491456, upload-time = "2025-08-10T21:27:14.353Z" },
+ { url = "https://files.pythonhosted.org/packages/fc/d4/10303190bd4d30de547534601e259a4fbf014eed94aae3e5521129215086/kiwisolver-1.4.9-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:24c175051354f4a28c5d6a31c93906dc653e2bf234e8a4bbfb964892078898ce", size = 2294621, upload-time = "2025-08-10T21:27:15.808Z" },
+ { url = "https://files.pythonhosted.org/packages/28/e0/a9a90416fce5c0be25742729c2ea52105d62eda6c4be4d803c2a7be1fa50/kiwisolver-1.4.9-cp314-cp314-win_amd64.whl", hash = "sha256:0763515d4df10edf6d06a3c19734e2566368980d21ebec439f33f9eb936c07b7", size = 75417, upload-time = "2025-08-10T21:27:17.436Z" },
+ { url = "https://files.pythonhosted.org/packages/1f/10/6949958215b7a9a264299a7db195564e87900f709db9245e4ebdd3c70779/kiwisolver-1.4.9-cp314-cp314-win_arm64.whl", hash = "sha256:0e4e2bf29574a6a7b7f6cb5fa69293b9f96c928949ac4a53ba3f525dffb87f9c", size = 66582, upload-time = "2025-08-10T21:27:18.436Z" },
+ { url = "https://files.pythonhosted.org/packages/ec/79/60e53067903d3bc5469b369fe0dfc6b3482e2133e85dae9daa9527535991/kiwisolver-1.4.9-cp314-cp314t-macosx_10_13_universal2.whl", hash = "sha256:d976bbb382b202f71c67f77b0ac11244021cfa3f7dfd9e562eefcea2df711548", size = 126514, upload-time = "2025-08-10T21:27:19.465Z" },
+ { url = "https://files.pythonhosted.org/packages/25/d1/4843d3e8d46b072c12a38c97c57fab4608d36e13fe47d47ee96b4d61ba6f/kiwisolver-1.4.9-cp314-cp314t-macosx_10_13_x86_64.whl", hash = "sha256:2489e4e5d7ef9a1c300a5e0196e43d9c739f066ef23270607d45aba368b91f2d", size = 67905, upload-time = "2025-08-10T21:27:20.51Z" },
+ { url = "https://files.pythonhosted.org/packages/8c/ae/29ffcbd239aea8b93108de1278271ae764dfc0d803a5693914975f200596/kiwisolver-1.4.9-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:e2ea9f7ab7fbf18fffb1b5434ce7c69a07582f7acc7717720f1d69f3e806f90c", size = 66399, upload-time = "2025-08-10T21:27:21.496Z" },
+ { url = "https://files.pythonhosted.org/packages/a1/ae/d7ba902aa604152c2ceba5d352d7b62106bedbccc8e95c3934d94472bfa3/kiwisolver-1.4.9-cp314-cp314t-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:b34e51affded8faee0dfdb705416153819d8ea9250bbbf7ea1b249bdeb5f1122", size = 1582197, upload-time = "2025-08-10T21:27:22.604Z" },
+ { url = "https://files.pythonhosted.org/packages/f2/41/27c70d427eddb8bc7e4f16420a20fefc6f480312122a59a959fdfe0445ad/kiwisolver-1.4.9-cp314-cp314t-manylinux_2_24_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:d8aacd3d4b33b772542b2e01beb50187536967b514b00003bdda7589722d2a64", size = 1390125, upload-time = "2025-08-10T21:27:24.036Z" },
+ { url = "https://files.pythonhosted.org/packages/41/42/b3799a12bafc76d962ad69083f8b43b12bf4fe78b097b12e105d75c9b8f1/kiwisolver-1.4.9-cp314-cp314t-manylinux_2_24_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:7cf974dd4e35fa315563ac99d6287a1024e4dc2077b8a7d7cd3d2fb65d283134", size = 1402612, upload-time = "2025-08-10T21:27:25.773Z" },
+ { url = "https://files.pythonhosted.org/packages/d2/b5/a210ea073ea1cfaca1bb5c55a62307d8252f531beb364e18aa1e0888b5a0/kiwisolver-1.4.9-cp314-cp314t-manylinux_2_24_s390x.manylinux_2_28_s390x.whl", hash = "sha256:85bd218b5ecfbee8c8a82e121802dcb519a86044c9c3b2e4aef02fa05c6da370", size = 1453990, upload-time = "2025-08-10T21:27:27.089Z" },
+ { url = "https://files.pythonhosted.org/packages/5f/ce/a829eb8c033e977d7ea03ed32fb3c1781b4fa0433fbadfff29e39c676f32/kiwisolver-1.4.9-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:0856e241c2d3df4efef7c04a1e46b1936b6120c9bcf36dd216e3acd84bc4fb21", size = 2331601, upload-time = "2025-08-10T21:27:29.343Z" },
+ { url = "https://files.pythonhosted.org/packages/e0/4b/b5e97eb142eb9cd0072dacfcdcd31b1c66dc7352b0f7c7255d339c0edf00/kiwisolver-1.4.9-cp314-cp314t-musllinux_1_2_ppc64le.whl", hash = "sha256:9af39d6551f97d31a4deebeac6f45b156f9755ddc59c07b402c148f5dbb6482a", size = 2422041, upload-time = "2025-08-10T21:27:30.754Z" },
+ { url = "https://files.pythonhosted.org/packages/40/be/8eb4cd53e1b85ba4edc3a9321666f12b83113a178845593307a3e7891f44/kiwisolver-1.4.9-cp314-cp314t-musllinux_1_2_s390x.whl", hash = "sha256:bb4ae2b57fc1d8cbd1cf7b1d9913803681ffa903e7488012be5b76dedf49297f", size = 2594897, upload-time = "2025-08-10T21:27:32.803Z" },
+ { url = "https://files.pythonhosted.org/packages/99/dd/841e9a66c4715477ea0abc78da039832fbb09dac5c35c58dc4c41a407b8a/kiwisolver-1.4.9-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:aedff62918805fb62d43a4aa2ecd4482c380dc76cd31bd7c8878588a61bd0369", size = 2391835, upload-time = "2025-08-10T21:27:34.23Z" },
+ { url = "https://files.pythonhosted.org/packages/0c/28/4b2e5c47a0da96896fdfdb006340ade064afa1e63675d01ea5ac222b6d52/kiwisolver-1.4.9-cp314-cp314t-win_amd64.whl", hash = "sha256:1fa333e8b2ce4d9660f2cda9c0e1b6bafcfb2457a9d259faa82289e73ec24891", size = 79988, upload-time = "2025-08-10T21:27:35.587Z" },
+ { url = "https://files.pythonhosted.org/packages/80/be/3578e8afd18c88cdf9cb4cffde75a96d2be38c5a903f1ed0ceec061bd09e/kiwisolver-1.4.9-cp314-cp314t-win_arm64.whl", hash = "sha256:4a48a2ce79d65d363597ef7b567ce3d14d68783d2b2263d98db3d9477805ba32", size = 70260, upload-time = "2025-08-10T21:27:36.606Z" },
+]
+
+[[package]]
+name = "lark"
+version = "1.3.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/da/34/28fff3ab31ccff1fd4f6c7c7b0ceb2b6968d8ea4950663eadcb5720591a0/lark-1.3.1.tar.gz", hash = "sha256:b426a7a6d6d53189d318f2b6236ab5d6429eaf09259f1ca33eb716eed10d2905", size = 382732, upload-time = "2025-10-27T18:25:56.653Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/82/3d/14ce75ef66813643812f3093ab17e46d3a206942ce7376d31ec2d36229e7/lark-1.3.1-py3-none-any.whl", hash = "sha256:c629b661023a014c37da873b4ff58a817398d12635d3bbb2c5a03be7fe5d1e12", size = 113151, upload-time = "2025-10-27T18:25:54.882Z" },
+]
+
+[[package]]
+name = "license-expression"
+version = "30.4.4"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "boolean-py" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/40/71/d89bb0e71b1415453980fd32315f2a037aad9f7f70f695c7cec7035feb13/license_expression-30.4.4.tar.gz", hash = "sha256:73448f0aacd8d0808895bdc4b2c8e01a8d67646e4188f887375398c761f340fd", size = 186402, upload-time = "2025-07-22T11:13:32.17Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/af/40/791891d4c0c4dab4c5e187c17261cedc26285fd41541577f900470a45a4d/license_expression-30.4.4-py3-none-any.whl", hash = "sha256:421788fdcadb41f049d2dc934ce666626265aeccefddd25e162a26f23bcbf8a4", size = 120615, upload-time = "2025-07-22T11:13:31.217Z" },
+]
+
+[[package]]
+name = "markupsafe"
+version = "3.0.3"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/7e/99/7690b6d4034fffd95959cbe0c02de8deb3098cc577c67bb6a24fe5d7caa7/markupsafe-3.0.3.tar.gz", hash = "sha256:722695808f4b6457b320fdc131280796bdceb04ab50fe1795cd540799ebe1698", size = 80313, upload-time = "2025-09-27T18:37:40.426Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/5a/72/147da192e38635ada20e0a2e1a51cf8823d2119ce8883f7053879c2199b5/markupsafe-3.0.3-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:d53197da72cc091b024dd97249dfc7794d6a56530370992a5e1a08983ad9230e", size = 11615, upload-time = "2025-09-27T18:36:30.854Z" },
+ { url = "https://files.pythonhosted.org/packages/9a/81/7e4e08678a1f98521201c3079f77db69fb552acd56067661f8c2f534a718/markupsafe-3.0.3-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:1872df69a4de6aead3491198eaf13810b565bdbeec3ae2dc8780f14458ec73ce", size = 12020, upload-time = "2025-09-27T18:36:31.971Z" },
+ { url = "https://files.pythonhosted.org/packages/1e/2c/799f4742efc39633a1b54a92eec4082e4f815314869865d876824c257c1e/markupsafe-3.0.3-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:3a7e8ae81ae39e62a41ec302f972ba6ae23a5c5396c8e60113e9066ef893da0d", size = 24332, upload-time = "2025-09-27T18:36:32.813Z" },
+ { url = "https://files.pythonhosted.org/packages/3c/2e/8d0c2ab90a8c1d9a24f0399058ab8519a3279d1bd4289511d74e909f060e/markupsafe-3.0.3-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:d6dd0be5b5b189d31db7cda48b91d7e0a9795f31430b7f271219ab30f1d3ac9d", size = 22947, upload-time = "2025-09-27T18:36:33.86Z" },
+ { url = "https://files.pythonhosted.org/packages/2c/54/887f3092a85238093a0b2154bd629c89444f395618842e8b0c41783898ea/markupsafe-3.0.3-cp312-cp312-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:94c6f0bb423f739146aec64595853541634bde58b2135f27f61c1ffd1cd4d16a", size = 21962, upload-time = "2025-09-27T18:36:35.099Z" },
+ { url = "https://files.pythonhosted.org/packages/c9/2f/336b8c7b6f4a4d95e91119dc8521402461b74a485558d8f238a68312f11c/markupsafe-3.0.3-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:be8813b57049a7dc738189df53d69395eba14fb99345e0a5994914a3864c8a4b", size = 23760, upload-time = "2025-09-27T18:36:36.001Z" },
+ { url = "https://files.pythonhosted.org/packages/32/43/67935f2b7e4982ffb50a4d169b724d74b62a3964bc1a9a527f5ac4f1ee2b/markupsafe-3.0.3-cp312-cp312-musllinux_1_2_riscv64.whl", hash = "sha256:83891d0e9fb81a825d9a6d61e3f07550ca70a076484292a70fde82c4b807286f", size = 21529, upload-time = "2025-09-27T18:36:36.906Z" },
+ { url = "https://files.pythonhosted.org/packages/89/e0/4486f11e51bbba8b0c041098859e869e304d1c261e59244baa3d295d47b7/markupsafe-3.0.3-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:77f0643abe7495da77fb436f50f8dab76dbc6e5fd25d39589a0f1fe6548bfa2b", size = 23015, upload-time = "2025-09-27T18:36:37.868Z" },
+ { url = "https://files.pythonhosted.org/packages/2f/e1/78ee7a023dac597a5825441ebd17170785a9dab23de95d2c7508ade94e0e/markupsafe-3.0.3-cp312-cp312-win32.whl", hash = "sha256:d88b440e37a16e651bda4c7c2b930eb586fd15ca7406cb39e211fcff3bf3017d", size = 14540, upload-time = "2025-09-27T18:36:38.761Z" },
+ { url = "https://files.pythonhosted.org/packages/aa/5b/bec5aa9bbbb2c946ca2733ef9c4ca91c91b6a24580193e891b5f7dbe8e1e/markupsafe-3.0.3-cp312-cp312-win_amd64.whl", hash = "sha256:26a5784ded40c9e318cfc2bdb30fe164bdb8665ded9cd64d500a34fb42067b1c", size = 15105, upload-time = "2025-09-27T18:36:39.701Z" },
+ { url = "https://files.pythonhosted.org/packages/e5/f1/216fc1bbfd74011693a4fd837e7026152e89c4bcf3e77b6692fba9923123/markupsafe-3.0.3-cp312-cp312-win_arm64.whl", hash = "sha256:35add3b638a5d900e807944a078b51922212fb3dedb01633a8defc4b01a3c85f", size = 13906, upload-time = "2025-09-27T18:36:40.689Z" },
+ { url = "https://files.pythonhosted.org/packages/38/2f/907b9c7bbba283e68f20259574b13d005c121a0fa4c175f9bed27c4597ff/markupsafe-3.0.3-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:e1cf1972137e83c5d4c136c43ced9ac51d0e124706ee1c8aa8532c1287fa8795", size = 11622, upload-time = "2025-09-27T18:36:41.777Z" },
+ { url = "https://files.pythonhosted.org/packages/9c/d9/5f7756922cdd676869eca1c4e3c0cd0df60ed30199ffd775e319089cb3ed/markupsafe-3.0.3-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:116bb52f642a37c115f517494ea5feb03889e04df47eeff5b130b1808ce7c219", size = 12029, upload-time = "2025-09-27T18:36:43.257Z" },
+ { url = "https://files.pythonhosted.org/packages/00/07/575a68c754943058c78f30db02ee03a64b3c638586fba6a6dd56830b30a3/markupsafe-3.0.3-cp313-cp313-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:133a43e73a802c5562be9bbcd03d090aa5a1fe899db609c29e8c8d815c5f6de6", size = 24374, upload-time = "2025-09-27T18:36:44.508Z" },
+ { url = "https://files.pythonhosted.org/packages/a9/21/9b05698b46f218fc0e118e1f8168395c65c8a2c750ae2bab54fc4bd4e0e8/markupsafe-3.0.3-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:ccfcd093f13f0f0b7fdd0f198b90053bf7b2f02a3927a30e63f3ccc9df56b676", size = 22980, upload-time = "2025-09-27T18:36:45.385Z" },
+ { url = "https://files.pythonhosted.org/packages/7f/71/544260864f893f18b6827315b988c146b559391e6e7e8f7252839b1b846a/markupsafe-3.0.3-cp313-cp313-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:509fa21c6deb7a7a273d629cf5ec029bc209d1a51178615ddf718f5918992ab9", size = 21990, upload-time = "2025-09-27T18:36:46.916Z" },
+ { url = "https://files.pythonhosted.org/packages/c2/28/b50fc2f74d1ad761af2f5dcce7492648b983d00a65b8c0e0cb457c82ebbe/markupsafe-3.0.3-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:a4afe79fb3de0b7097d81da19090f4df4f8d3a2b3adaa8764138aac2e44f3af1", size = 23784, upload-time = "2025-09-27T18:36:47.884Z" },
+ { url = "https://files.pythonhosted.org/packages/ed/76/104b2aa106a208da8b17a2fb72e033a5a9d7073c68f7e508b94916ed47a9/markupsafe-3.0.3-cp313-cp313-musllinux_1_2_riscv64.whl", hash = "sha256:795e7751525cae078558e679d646ae45574b47ed6e7771863fcc079a6171a0fc", size = 21588, upload-time = "2025-09-27T18:36:48.82Z" },
+ { url = "https://files.pythonhosted.org/packages/b5/99/16a5eb2d140087ebd97180d95249b00a03aa87e29cc224056274f2e45fd6/markupsafe-3.0.3-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:8485f406a96febb5140bfeca44a73e3ce5116b2501ac54fe953e488fb1d03b12", size = 23041, upload-time = "2025-09-27T18:36:49.797Z" },
+ { url = "https://files.pythonhosted.org/packages/19/bc/e7140ed90c5d61d77cea142eed9f9c303f4c4806f60a1044c13e3f1471d0/markupsafe-3.0.3-cp313-cp313-win32.whl", hash = "sha256:bdd37121970bfd8be76c5fb069c7751683bdf373db1ed6c010162b2a130248ed", size = 14543, upload-time = "2025-09-27T18:36:51.584Z" },
+ { url = "https://files.pythonhosted.org/packages/05/73/c4abe620b841b6b791f2edc248f556900667a5a1cf023a6646967ae98335/markupsafe-3.0.3-cp313-cp313-win_amd64.whl", hash = "sha256:9a1abfdc021a164803f4d485104931fb8f8c1efd55bc6b748d2f5774e78b62c5", size = 15113, upload-time = "2025-09-27T18:36:52.537Z" },
+ { url = "https://files.pythonhosted.org/packages/f0/3a/fa34a0f7cfef23cf9500d68cb7c32dd64ffd58a12b09225fb03dd37d5b80/markupsafe-3.0.3-cp313-cp313-win_arm64.whl", hash = "sha256:7e68f88e5b8799aa49c85cd116c932a1ac15caaa3f5db09087854d218359e485", size = 13911, upload-time = "2025-09-27T18:36:53.513Z" },
+ { url = "https://files.pythonhosted.org/packages/e4/d7/e05cd7efe43a88a17a37b3ae96e79a19e846f3f456fe79c57ca61356ef01/markupsafe-3.0.3-cp313-cp313t-macosx_10_13_x86_64.whl", hash = "sha256:218551f6df4868a8d527e3062d0fb968682fe92054e89978594c28e642c43a73", size = 11658, upload-time = "2025-09-27T18:36:54.819Z" },
+ { url = "https://files.pythonhosted.org/packages/99/9e/e412117548182ce2148bdeacdda3bb494260c0b0184360fe0d56389b523b/markupsafe-3.0.3-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:3524b778fe5cfb3452a09d31e7b5adefeea8c5be1d43c4f810ba09f2ceb29d37", size = 12066, upload-time = "2025-09-27T18:36:55.714Z" },
+ { url = "https://files.pythonhosted.org/packages/bc/e6/fa0ffcda717ef64a5108eaa7b4f5ed28d56122c9a6d70ab8b72f9f715c80/markupsafe-3.0.3-cp313-cp313t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:4e885a3d1efa2eadc93c894a21770e4bc67899e3543680313b09f139e149ab19", size = 25639, upload-time = "2025-09-27T18:36:56.908Z" },
+ { url = "https://files.pythonhosted.org/packages/96/ec/2102e881fe9d25fc16cb4b25d5f5cde50970967ffa5dddafdb771237062d/markupsafe-3.0.3-cp313-cp313t-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:8709b08f4a89aa7586de0aadc8da56180242ee0ada3999749b183aa23df95025", size = 23569, upload-time = "2025-09-27T18:36:57.913Z" },
+ { url = "https://files.pythonhosted.org/packages/4b/30/6f2fce1f1f205fc9323255b216ca8a235b15860c34b6798f810f05828e32/markupsafe-3.0.3-cp313-cp313t-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:b8512a91625c9b3da6f127803b166b629725e68af71f8184ae7e7d54686a56d6", size = 23284, upload-time = "2025-09-27T18:36:58.833Z" },
+ { url = "https://files.pythonhosted.org/packages/58/47/4a0ccea4ab9f5dcb6f79c0236d954acb382202721e704223a8aafa38b5c8/markupsafe-3.0.3-cp313-cp313t-musllinux_1_2_aarch64.whl", hash = "sha256:9b79b7a16f7fedff2495d684f2b59b0457c3b493778c9eed31111be64d58279f", size = 24801, upload-time = "2025-09-27T18:36:59.739Z" },
+ { url = "https://files.pythonhosted.org/packages/6a/70/3780e9b72180b6fecb83a4814d84c3bf4b4ae4bf0b19c27196104149734c/markupsafe-3.0.3-cp313-cp313t-musllinux_1_2_riscv64.whl", hash = "sha256:12c63dfb4a98206f045aa9563db46507995f7ef6d83b2f68eda65c307c6829eb", size = 22769, upload-time = "2025-09-27T18:37:00.719Z" },
+ { url = "https://files.pythonhosted.org/packages/98/c5/c03c7f4125180fc215220c035beac6b9cb684bc7a067c84fc69414d315f5/markupsafe-3.0.3-cp313-cp313t-musllinux_1_2_x86_64.whl", hash = "sha256:8f71bc33915be5186016f675cd83a1e08523649b0e33efdb898db577ef5bb009", size = 23642, upload-time = "2025-09-27T18:37:01.673Z" },
+ { url = "https://files.pythonhosted.org/packages/80/d6/2d1b89f6ca4bff1036499b1e29a1d02d282259f3681540e16563f27ebc23/markupsafe-3.0.3-cp313-cp313t-win32.whl", hash = "sha256:69c0b73548bc525c8cb9a251cddf1931d1db4d2258e9599c28c07ef3580ef354", size = 14612, upload-time = "2025-09-27T18:37:02.639Z" },
+ { url = "https://files.pythonhosted.org/packages/2b/98/e48a4bfba0a0ffcf9925fe2d69240bfaa19c6f7507b8cd09c70684a53c1e/markupsafe-3.0.3-cp313-cp313t-win_amd64.whl", hash = "sha256:1b4b79e8ebf6b55351f0d91fe80f893b4743f104bff22e90697db1590e47a218", size = 15200, upload-time = "2025-09-27T18:37:03.582Z" },
+ { url = "https://files.pythonhosted.org/packages/0e/72/e3cc540f351f316e9ed0f092757459afbc595824ca724cbc5a5d4263713f/markupsafe-3.0.3-cp313-cp313t-win_arm64.whl", hash = "sha256:ad2cf8aa28b8c020ab2fc8287b0f823d0a7d8630784c31e9ee5edea20f406287", size = 13973, upload-time = "2025-09-27T18:37:04.929Z" },
+ { url = "https://files.pythonhosted.org/packages/33/8a/8e42d4838cd89b7dde187011e97fe6c3af66d8c044997d2183fbd6d31352/markupsafe-3.0.3-cp314-cp314-macosx_10_13_x86_64.whl", hash = "sha256:eaa9599de571d72e2daf60164784109f19978b327a3910d3e9de8c97b5b70cfe", size = 11619, upload-time = "2025-09-27T18:37:06.342Z" },
+ { url = "https://files.pythonhosted.org/packages/b5/64/7660f8a4a8e53c924d0fa05dc3a55c9cee10bbd82b11c5afb27d44b096ce/markupsafe-3.0.3-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:c47a551199eb8eb2121d4f0f15ae0f923d31350ab9280078d1e5f12b249e0026", size = 12029, upload-time = "2025-09-27T18:37:07.213Z" },
+ { url = "https://files.pythonhosted.org/packages/da/ef/e648bfd021127bef5fa12e1720ffed0c6cbb8310c8d9bea7266337ff06de/markupsafe-3.0.3-cp314-cp314-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:f34c41761022dd093b4b6896d4810782ffbabe30f2d443ff5f083e0cbbb8c737", size = 24408, upload-time = "2025-09-27T18:37:09.572Z" },
+ { url = "https://files.pythonhosted.org/packages/41/3c/a36c2450754618e62008bf7435ccb0f88053e07592e6028a34776213d877/markupsafe-3.0.3-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:457a69a9577064c05a97c41f4e65148652db078a3a509039e64d3467b9e7ef97", size = 23005, upload-time = "2025-09-27T18:37:10.58Z" },
+ { url = "https://files.pythonhosted.org/packages/bc/20/b7fdf89a8456b099837cd1dc21974632a02a999ec9bf7ca3e490aacd98e7/markupsafe-3.0.3-cp314-cp314-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:e8afc3f2ccfa24215f8cb28dcf43f0113ac3c37c2f0f0806d8c70e4228c5cf4d", size = 22048, upload-time = "2025-09-27T18:37:11.547Z" },
+ { url = "https://files.pythonhosted.org/packages/9a/a7/591f592afdc734f47db08a75793a55d7fbcc6902a723ae4cfbab61010cc5/markupsafe-3.0.3-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:ec15a59cf5af7be74194f7ab02d0f59a62bdcf1a537677ce67a2537c9b87fcda", size = 23821, upload-time = "2025-09-27T18:37:12.48Z" },
+ { url = "https://files.pythonhosted.org/packages/7d/33/45b24e4f44195b26521bc6f1a82197118f74df348556594bd2262bda1038/markupsafe-3.0.3-cp314-cp314-musllinux_1_2_riscv64.whl", hash = "sha256:0eb9ff8191e8498cca014656ae6b8d61f39da5f95b488805da4bb029cccbfbaf", size = 21606, upload-time = "2025-09-27T18:37:13.485Z" },
+ { url = "https://files.pythonhosted.org/packages/ff/0e/53dfaca23a69fbfbbf17a4b64072090e70717344c52eaaaa9c5ddff1e5f0/markupsafe-3.0.3-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:2713baf880df847f2bece4230d4d094280f4e67b1e813eec43b4c0e144a34ffe", size = 23043, upload-time = "2025-09-27T18:37:14.408Z" },
+ { url = "https://files.pythonhosted.org/packages/46/11/f333a06fc16236d5238bfe74daccbca41459dcd8d1fa952e8fbd5dccfb70/markupsafe-3.0.3-cp314-cp314-win32.whl", hash = "sha256:729586769a26dbceff69f7a7dbbf59ab6572b99d94576a5592625d5b411576b9", size = 14747, upload-time = "2025-09-27T18:37:15.36Z" },
+ { url = "https://files.pythonhosted.org/packages/28/52/182836104b33b444e400b14f797212f720cbc9ed6ba34c800639d154e821/markupsafe-3.0.3-cp314-cp314-win_amd64.whl", hash = "sha256:bdc919ead48f234740ad807933cdf545180bfbe9342c2bb451556db2ed958581", size = 15341, upload-time = "2025-09-27T18:37:16.496Z" },
+ { url = "https://files.pythonhosted.org/packages/6f/18/acf23e91bd94fd7b3031558b1f013adfa21a8e407a3fdb32745538730382/markupsafe-3.0.3-cp314-cp314-win_arm64.whl", hash = "sha256:5a7d5dc5140555cf21a6fefbdbf8723f06fcd2f63ef108f2854de715e4422cb4", size = 14073, upload-time = "2025-09-27T18:37:17.476Z" },
+ { url = "https://files.pythonhosted.org/packages/3c/f0/57689aa4076e1b43b15fdfa646b04653969d50cf30c32a102762be2485da/markupsafe-3.0.3-cp314-cp314t-macosx_10_13_x86_64.whl", hash = "sha256:1353ef0c1b138e1907ae78e2f6c63ff67501122006b0f9abad68fda5f4ffc6ab", size = 11661, upload-time = "2025-09-27T18:37:18.453Z" },
+ { url = "https://files.pythonhosted.org/packages/89/c3/2e67a7ca217c6912985ec766c6393b636fb0c2344443ff9d91404dc4c79f/markupsafe-3.0.3-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:1085e7fbddd3be5f89cc898938f42c0b3c711fdcb37d75221de2666af647c175", size = 12069, upload-time = "2025-09-27T18:37:19.332Z" },
+ { url = "https://files.pythonhosted.org/packages/f0/00/be561dce4e6ca66b15276e184ce4b8aec61fe83662cce2f7d72bd3249d28/markupsafe-3.0.3-cp314-cp314t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:1b52b4fb9df4eb9ae465f8d0c228a00624de2334f216f178a995ccdcf82c4634", size = 25670, upload-time = "2025-09-27T18:37:20.245Z" },
+ { url = "https://files.pythonhosted.org/packages/50/09/c419f6f5a92e5fadde27efd190eca90f05e1261b10dbd8cbcb39cd8ea1dc/markupsafe-3.0.3-cp314-cp314t-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:fed51ac40f757d41b7c48425901843666a6677e3e8eb0abcff09e4ba6e664f50", size = 23598, upload-time = "2025-09-27T18:37:21.177Z" },
+ { url = "https://files.pythonhosted.org/packages/22/44/a0681611106e0b2921b3033fc19bc53323e0b50bc70cffdd19f7d679bb66/markupsafe-3.0.3-cp314-cp314t-manylinux_2_31_riscv64.manylinux_2_39_riscv64.whl", hash = "sha256:f190daf01f13c72eac4efd5c430a8de82489d9cff23c364c3ea822545032993e", size = 23261, upload-time = "2025-09-27T18:37:22.167Z" },
+ { url = "https://files.pythonhosted.org/packages/5f/57/1b0b3f100259dc9fffe780cfb60d4be71375510e435efec3d116b6436d43/markupsafe-3.0.3-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:e56b7d45a839a697b5eb268c82a71bd8c7f6c94d6fd50c3d577fa39a9f1409f5", size = 24835, upload-time = "2025-09-27T18:37:23.296Z" },
+ { url = "https://files.pythonhosted.org/packages/26/6a/4bf6d0c97c4920f1597cc14dd720705eca0bf7c787aebc6bb4d1bead5388/markupsafe-3.0.3-cp314-cp314t-musllinux_1_2_riscv64.whl", hash = "sha256:f3e98bb3798ead92273dc0e5fd0f31ade220f59a266ffd8a4f6065e0a3ce0523", size = 22733, upload-time = "2025-09-27T18:37:24.237Z" },
+ { url = "https://files.pythonhosted.org/packages/14/c7/ca723101509b518797fedc2fdf79ba57f886b4aca8a7d31857ba3ee8281f/markupsafe-3.0.3-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:5678211cb9333a6468fb8d8be0305520aa073f50d17f089b5b4b477ea6e67fdc", size = 23672, upload-time = "2025-09-27T18:37:25.271Z" },
+ { url = "https://files.pythonhosted.org/packages/fb/df/5bd7a48c256faecd1d36edc13133e51397e41b73bb77e1a69deab746ebac/markupsafe-3.0.3-cp314-cp314t-win32.whl", hash = "sha256:915c04ba3851909ce68ccc2b8e2cd691618c4dc4c4232fb7982bca3f41fd8c3d", size = 14819, upload-time = "2025-09-27T18:37:26.285Z" },
+ { url = "https://files.pythonhosted.org/packages/1a/8a/0402ba61a2f16038b48b39bccca271134be00c5c9f0f623208399333c448/markupsafe-3.0.3-cp314-cp314t-win_amd64.whl", hash = "sha256:4faffd047e07c38848ce017e8725090413cd80cbc23d86e55c587bf979e579c9", size = 15426, upload-time = "2025-09-27T18:37:27.316Z" },
+ { url = "https://files.pythonhosted.org/packages/70/bc/6f1c2f612465f5fa89b95bead1f44dcb607670fd42891d8fdcd5d039f4f4/markupsafe-3.0.3-cp314-cp314t-win_arm64.whl", hash = "sha256:32001d6a8fc98c8cb5c947787c5d08b0a50663d139f1305bac5885d98d9b40fa", size = 14146, upload-time = "2025-09-27T18:37:28.327Z" },
+]
+
+[[package]]
+name = "matplotlib"
+version = "3.10.7"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "contourpy" },
+ { name = "cycler" },
+ { name = "fonttools" },
+ { name = "kiwisolver" },
+ { name = "numpy" },
+ { name = "packaging" },
+ { name = "pillow" },
+ { name = "pyparsing" },
+ { name = "python-dateutil" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/ae/e2/d2d5295be2f44c678ebaf3544ba32d20c1f9ef08c49fe47f496180e1db15/matplotlib-3.10.7.tar.gz", hash = "sha256:a06ba7e2a2ef9131c79c49e63dad355d2d878413a0376c1727c8b9335ff731c7", size = 34804865, upload-time = "2025-10-09T00:28:00.669Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/be/b3/09eb0f7796932826ec20c25b517d568627754f6c6462fca19e12c02f2e12/matplotlib-3.10.7-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:7a0edb7209e21840e8361e91ea84ea676658aa93edd5f8762793dec77a4a6748", size = 8272389, upload-time = "2025-10-09T00:26:42.474Z" },
+ { url = "https://files.pythonhosted.org/packages/11/0b/1ae80ddafb8652fd8046cb5c8460ecc8d4afccb89e2c6d6bec61e04e1eaf/matplotlib-3.10.7-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:c380371d3c23e0eadf8ebff114445b9f970aff2010198d498d4ab4c3b41eea4f", size = 8128247, upload-time = "2025-10-09T00:26:44.77Z" },
+ { url = "https://files.pythonhosted.org/packages/7d/18/95ae2e242d4a5c98bd6e90e36e128d71cf1c7e39b0874feaed3ef782e789/matplotlib-3.10.7-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:d5f256d49fea31f40f166a5e3131235a5d2f4b7f44520b1cf0baf1ce568ccff0", size = 8696996, upload-time = "2025-10-09T00:26:46.792Z" },
+ { url = "https://files.pythonhosted.org/packages/7e/3d/5b559efc800bd05cb2033aa85f7e13af51958136a48327f7c261801ff90a/matplotlib-3.10.7-cp312-cp312-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:11ae579ac83cdf3fb72573bb89f70e0534de05266728740d478f0f818983c695", size = 9530153, upload-time = "2025-10-09T00:26:49.07Z" },
+ { url = "https://files.pythonhosted.org/packages/88/57/eab4a719fd110312d3c220595d63a3c85ec2a39723f0f4e7fa7e6e3f74ba/matplotlib-3.10.7-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:4c14b6acd16cddc3569a2d515cfdd81c7a68ac5639b76548cfc1a9e48b20eb65", size = 9593093, upload-time = "2025-10-09T00:26:51.067Z" },
+ { url = "https://files.pythonhosted.org/packages/31/3c/80816f027b3a4a28cd2a0a6ef7f89a2db22310e945cd886ec25bfb399221/matplotlib-3.10.7-cp312-cp312-win_amd64.whl", hash = "sha256:0d8c32b7ea6fb80b1aeff5a2ceb3fb9778e2759e899d9beff75584714afcc5ee", size = 8122771, upload-time = "2025-10-09T00:26:53.296Z" },
+ { url = "https://files.pythonhosted.org/packages/de/77/ef1fc78bfe99999b2675435cc52120887191c566b25017d78beaabef7f2d/matplotlib-3.10.7-cp312-cp312-win_arm64.whl", hash = "sha256:5f3f6d315dcc176ba7ca6e74c7768fb7e4cf566c49cb143f6bc257b62e634ed8", size = 7992812, upload-time = "2025-10-09T00:26:54.882Z" },
+ { url = "https://files.pythonhosted.org/packages/02/9c/207547916a02c78f6bdd83448d9b21afbc42f6379ed887ecf610984f3b4e/matplotlib-3.10.7-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:1d9d3713a237970569156cfb4de7533b7c4eacdd61789726f444f96a0d28f57f", size = 8273212, upload-time = "2025-10-09T00:26:56.752Z" },
+ { url = "https://files.pythonhosted.org/packages/bc/d0/b3d3338d467d3fc937f0bb7f256711395cae6f78e22cef0656159950adf0/matplotlib-3.10.7-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:37a1fea41153dd6ee061d21ab69c9cf2cf543160b1b85d89cd3d2e2a7902ca4c", size = 8128713, upload-time = "2025-10-09T00:26:59.001Z" },
+ { url = "https://files.pythonhosted.org/packages/22/ff/6425bf5c20d79aa5b959d1ce9e65f599632345391381c9a104133fe0b171/matplotlib-3.10.7-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:b3c4ea4948d93c9c29dc01c0c23eef66f2101bf75158c291b88de6525c55c3d1", size = 8698527, upload-time = "2025-10-09T00:27:00.69Z" },
+ { url = "https://files.pythonhosted.org/packages/d0/7f/ccdca06f4c2e6c7989270ed7829b8679466682f4cfc0f8c9986241c023b6/matplotlib-3.10.7-cp313-cp313-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:22df30ffaa89f6643206cf13877191c63a50e8f800b038bc39bee9d2d4957632", size = 9529690, upload-time = "2025-10-09T00:27:02.664Z" },
+ { url = "https://files.pythonhosted.org/packages/b8/95/b80fc2c1f269f21ff3d193ca697358e24408c33ce2b106a7438a45407b63/matplotlib-3.10.7-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:b69676845a0a66f9da30e87f48be36734d6748024b525ec4710be40194282c84", size = 9593732, upload-time = "2025-10-09T00:27:04.653Z" },
+ { url = "https://files.pythonhosted.org/packages/e1/b6/23064a96308b9aeceeffa65e96bcde459a2ea4934d311dee20afde7407a0/matplotlib-3.10.7-cp313-cp313-win_amd64.whl", hash = "sha256:744991e0cc863dd669c8dc9136ca4e6e0082be2070b9d793cbd64bec872a6815", size = 8122727, upload-time = "2025-10-09T00:27:06.814Z" },
+ { url = "https://files.pythonhosted.org/packages/b3/a6/2faaf48133b82cf3607759027f82b5c702aa99cdfcefb7f93d6ccf26a424/matplotlib-3.10.7-cp313-cp313-win_arm64.whl", hash = "sha256:fba2974df0bf8ce3c995fa84b79cde38326e0f7b5409e7a3a481c1141340bcf7", size = 7992958, upload-time = "2025-10-09T00:27:08.567Z" },
+ { url = "https://files.pythonhosted.org/packages/4a/f0/b018fed0b599bd48d84c08794cb242227fe3341952da102ee9d9682db574/matplotlib-3.10.7-cp313-cp313t-macosx_10_13_x86_64.whl", hash = "sha256:932c55d1fa7af4423422cb6a492a31cbcbdbe68fd1a9a3f545aa5e7a143b5355", size = 8316849, upload-time = "2025-10-09T00:27:10.254Z" },
+ { url = "https://files.pythonhosted.org/packages/b0/b7/bb4f23856197659f275e11a2a164e36e65e9b48ea3e93c4ec25b4f163198/matplotlib-3.10.7-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:5e38c2d581d62ee729a6e144c47a71b3f42fb4187508dbbf4fe71d5612c3433b", size = 8178225, upload-time = "2025-10-09T00:27:12.241Z" },
+ { url = "https://files.pythonhosted.org/packages/62/56/0600609893ff277e6f3ab3c0cef4eafa6e61006c058e84286c467223d4d5/matplotlib-3.10.7-cp313-cp313t-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:786656bb13c237bbcebcd402f65f44dd61ead60ee3deb045af429d889c8dbc67", size = 8711708, upload-time = "2025-10-09T00:27:13.879Z" },
+ { url = "https://files.pythonhosted.org/packages/d8/1a/6bfecb0cafe94d6658f2f1af22c43b76cf7a1c2f0dc34ef84cbb6809617e/matplotlib-3.10.7-cp313-cp313t-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:09d7945a70ea43bf9248f4b6582734c2fe726723204a76eca233f24cffc7ef67", size = 9541409, upload-time = "2025-10-09T00:27:15.684Z" },
+ { url = "https://files.pythonhosted.org/packages/08/50/95122a407d7f2e446fd865e2388a232a23f2b81934960ea802f3171518e4/matplotlib-3.10.7-cp313-cp313t-musllinux_1_2_x86_64.whl", hash = "sha256:d0b181e9fa8daf1d9f2d4c547527b167cb8838fc587deabca7b5c01f97199e84", size = 9594054, upload-time = "2025-10-09T00:27:17.547Z" },
+ { url = "https://files.pythonhosted.org/packages/13/76/75b194a43b81583478a81e78a07da8d9ca6ddf50dd0a2ccabf258059481d/matplotlib-3.10.7-cp313-cp313t-win_amd64.whl", hash = "sha256:31963603041634ce1a96053047b40961f7a29eb8f9a62e80cc2c0427aa1d22a2", size = 8200100, upload-time = "2025-10-09T00:27:20.039Z" },
+ { url = "https://files.pythonhosted.org/packages/f5/9e/6aefebdc9f8235c12bdeeda44cc0383d89c1e41da2c400caf3ee2073a3ce/matplotlib-3.10.7-cp313-cp313t-win_arm64.whl", hash = "sha256:aebed7b50aa6ac698c90f60f854b47e48cd2252b30510e7a1feddaf5a3f72cbf", size = 8042131, upload-time = "2025-10-09T00:27:21.608Z" },
+ { url = "https://files.pythonhosted.org/packages/0d/4b/e5bc2c321b6a7e3a75638d937d19ea267c34bd5a90e12bee76c4d7c7a0d9/matplotlib-3.10.7-cp314-cp314-macosx_10_13_x86_64.whl", hash = "sha256:d883460c43e8c6b173fef244a2341f7f7c0e9725c7fe68306e8e44ed9c8fb100", size = 8273787, upload-time = "2025-10-09T00:27:23.27Z" },
+ { url = "https://files.pythonhosted.org/packages/86/ad/6efae459c56c2fbc404da154e13e3a6039129f3c942b0152624f1c621f05/matplotlib-3.10.7-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:07124afcf7a6504eafcb8ce94091c5898bbdd351519a1beb5c45f7a38c67e77f", size = 8131348, upload-time = "2025-10-09T00:27:24.926Z" },
+ { url = "https://files.pythonhosted.org/packages/a6/5a/a4284d2958dee4116359cc05d7e19c057e64ece1b4ac986ab0f2f4d52d5a/matplotlib-3.10.7-cp314-cp314-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:c17398b709a6cce3d9fdb1595c33e356d91c098cd9486cb2cc21ea2ea418e715", size = 9533949, upload-time = "2025-10-09T00:27:26.704Z" },
+ { url = "https://files.pythonhosted.org/packages/de/ff/f3781b5057fa3786623ad8976fc9f7b0d02b2f28534751fd5a44240de4cf/matplotlib-3.10.7-cp314-cp314-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:7146d64f561498764561e9cd0ed64fcf582e570fc519e6f521e2d0cfd43365e1", size = 9804247, upload-time = "2025-10-09T00:27:28.514Z" },
+ { url = "https://files.pythonhosted.org/packages/47/5a/993a59facb8444efb0e197bf55f545ee449902dcee86a4dfc580c3b61314/matplotlib-3.10.7-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:90ad854c0a435da3104c01e2c6f0028d7e719b690998a2333d7218db80950722", size = 9595497, upload-time = "2025-10-09T00:27:30.418Z" },
+ { url = "https://files.pythonhosted.org/packages/0d/a5/77c95aaa9bb32c345cbb49626ad8eb15550cba2e6d4c88081a6c2ac7b08d/matplotlib-3.10.7-cp314-cp314-win_amd64.whl", hash = "sha256:4645fc5d9d20ffa3a39361fcdbcec731382763b623b72627806bf251b6388866", size = 8252732, upload-time = "2025-10-09T00:27:32.332Z" },
+ { url = "https://files.pythonhosted.org/packages/74/04/45d269b4268d222390d7817dae77b159651909669a34ee9fdee336db5883/matplotlib-3.10.7-cp314-cp314-win_arm64.whl", hash = "sha256:9257be2f2a03415f9105c486d304a321168e61ad450f6153d77c69504ad764bb", size = 8124240, upload-time = "2025-10-09T00:27:33.94Z" },
+ { url = "https://files.pythonhosted.org/packages/4b/c7/ca01c607bb827158b439208c153d6f14ddb9fb640768f06f7ca3488ae67b/matplotlib-3.10.7-cp314-cp314t-macosx_10_13_x86_64.whl", hash = "sha256:1e4bbad66c177a8fdfa53972e5ef8be72a5f27e6a607cec0d8579abd0f3102b1", size = 8316938, upload-time = "2025-10-09T00:27:35.534Z" },
+ { url = "https://files.pythonhosted.org/packages/84/d2/5539e66e9f56d2fdec94bb8436f5e449683b4e199bcc897c44fbe3c99e28/matplotlib-3.10.7-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:d8eb7194b084b12feb19142262165832fc6ee879b945491d1c3d4660748020c4", size = 8178245, upload-time = "2025-10-09T00:27:37.334Z" },
+ { url = "https://files.pythonhosted.org/packages/77/b5/e6ca22901fd3e4fe433a82e583436dd872f6c966fca7e63cf806b40356f8/matplotlib-3.10.7-cp314-cp314t-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:b4d41379b05528091f00e1728004f9a8d7191260f3862178b88e8fd770206318", size = 9541411, upload-time = "2025-10-09T00:27:39.387Z" },
+ { url = "https://files.pythonhosted.org/packages/9e/99/a4524db57cad8fee54b7237239a8f8360bfcfa3170d37c9e71c090c0f409/matplotlib-3.10.7-cp314-cp314t-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:4a74f79fafb2e177f240579bc83f0b60f82cc47d2f1d260f422a0627207008ca", size = 9803664, upload-time = "2025-10-09T00:27:41.492Z" },
+ { url = "https://files.pythonhosted.org/packages/e6/a5/85e2edf76ea0ad4288d174926d9454ea85f3ce5390cc4e6fab196cbf250b/matplotlib-3.10.7-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:702590829c30aada1e8cef0568ddbffa77ca747b4d6e36c6d173f66e301f89cc", size = 9594066, upload-time = "2025-10-09T00:27:43.694Z" },
+ { url = "https://files.pythonhosted.org/packages/39/69/9684368a314f6d83fe5c5ad2a4121a3a8e03723d2e5c8ea17b66c1bad0e7/matplotlib-3.10.7-cp314-cp314t-win_amd64.whl", hash = "sha256:f79d5de970fc90cd5591f60053aecfce1fcd736e0303d9f0bf86be649fa68fb8", size = 8342832, upload-time = "2025-10-09T00:27:45.543Z" },
+ { url = "https://files.pythonhosted.org/packages/04/5f/e22e08da14bc1a0894184640d47819d2338b792732e20d292bf86e5ab785/matplotlib-3.10.7-cp314-cp314t-win_arm64.whl", hash = "sha256:cb783436e47fcf82064baca52ce748af71725d0352e1d31564cbe9c95df92b9c", size = 8172585, upload-time = "2025-10-09T00:27:47.185Z" },
+]
+
+[[package]]
+name = "matplotlib-inline"
+version = "0.2.1"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "traitlets" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/c7/74/97e72a36efd4ae2bccb3463284300f8953f199b5ffbc04cbbb0ec78f74b1/matplotlib_inline-0.2.1.tar.gz", hash = "sha256:e1ee949c340d771fc39e241ea75683deb94762c8fa5f2927ec57c83c4dffa9fe", size = 8110, upload-time = "2025-10-23T09:00:22.126Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/af/33/ee4519fa02ed11a94aef9559552f3b17bb863f2ecfe1a35dc7f548cde231/matplotlib_inline-0.2.1-py3-none-any.whl", hash = "sha256:d56ce5156ba6085e00a9d54fead6ed29a9c47e215cd1bba2e976ef39f5710a76", size = 9516, upload-time = "2025-10-23T09:00:20.675Z" },
+]
+
+[[package]]
+name = "mistune"
+version = "3.1.4"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/d7/02/a7fb8b21d4d55ac93cdcde9d3638da5dd0ebdd3a4fed76c7725e10b81cbe/mistune-3.1.4.tar.gz", hash = "sha256:b5a7f801d389f724ec702840c11d8fc48f2b33519102fc7ee739e8177b672164", size = 94588, upload-time = "2025-08-29T07:20:43.594Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/7a/f0/8282d9641415e9e33df173516226b404d367a0fc55e1a60424a152913abc/mistune-3.1.4-py3-none-any.whl", hash = "sha256:93691da911e5d9d2e23bc54472892aff676df27a75274962ff9edc210364266d", size = 53481, upload-time = "2025-08-29T07:20:42.218Z" },
+]
+
+[[package]]
+name = "more-itertools"
+version = "10.8.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/ea/5d/38b681d3fce7a266dd9ab73c66959406d565b3e85f21d5e66e1181d93721/more_itertools-10.8.0.tar.gz", hash = "sha256:f638ddf8a1a0d134181275fb5d58b086ead7c6a72429ad725c67503f13ba30bd", size = 137431, upload-time = "2025-09-02T15:23:11.018Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/a4/8e/469e5a4a2f5855992e425f3cb33804cc07bf18d48f2db061aec61ce50270/more_itertools-10.8.0-py3-none-any.whl", hash = "sha256:52d4362373dcf7c52546bc4af9a86ee7c4579df9a8dc268be0a2f949d376cc9b", size = 69667, upload-time = "2025-09-02T15:23:09.635Z" },
+]
+
+[[package]]
+name = "mpmath"
+version = "1.3.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/e0/47/dd32fa426cc72114383ac549964eecb20ecfd886d1e5ccf5340b55b02f57/mpmath-1.3.0.tar.gz", hash = "sha256:7a28eb2a9774d00c7bc92411c19a89209d5da7c4c9a9e227be8330a23a25b91f", size = 508106, upload-time = "2023-03-07T16:47:11.061Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/43/e3/7d92a15f894aa0c9c4b49b8ee9ac9850d6e63b03c9c32c0367a13ae62209/mpmath-1.3.0-py3-none-any.whl", hash = "sha256:a0b2b9fe80bbcd81a6647ff13108738cfb482d481d826cc0e02f5b35e5c88d2c", size = 536198, upload-time = "2023-03-07T16:47:09.197Z" },
+]
+
+[[package]]
+name = "multidict"
+version = "6.7.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/80/1e/5492c365f222f907de1039b91f922b93fa4f764c713ee858d235495d8f50/multidict-6.7.0.tar.gz", hash = "sha256:c6e99d9a65ca282e578dfea819cfa9c0a62b2499d8677392e09feaf305e9e6f5", size = 101834, upload-time = "2025-10-06T14:52:30.657Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/c2/9e/9f61ac18d9c8b475889f32ccfa91c9f59363480613fc807b6e3023d6f60b/multidict-6.7.0-cp312-cp312-macosx_10_13_universal2.whl", hash = "sha256:8a3862568a36d26e650a19bb5cbbba14b71789032aebc0423f8cc5f150730184", size = 76877, upload-time = "2025-10-06T14:49:20.884Z" },
+ { url = "https://files.pythonhosted.org/packages/38/6f/614f09a04e6184f8824268fce4bc925e9849edfa654ddd59f0b64508c595/multidict-6.7.0-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:960c60b5849b9b4f9dcc9bea6e3626143c252c74113df2c1540aebce70209b45", size = 45467, upload-time = "2025-10-06T14:49:22.054Z" },
+ { url = "https://files.pythonhosted.org/packages/b3/93/c4f67a436dd026f2e780c433277fff72be79152894d9fc36f44569cab1a6/multidict-6.7.0-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:2049be98fb57a31b4ccf870bf377af2504d4ae35646a19037ec271e4c07998aa", size = 43834, upload-time = "2025-10-06T14:49:23.566Z" },
+ { url = "https://files.pythonhosted.org/packages/7f/f5/013798161ca665e4a422afbc5e2d9e4070142a9ff8905e482139cd09e4d0/multidict-6.7.0-cp312-cp312-manylinux1_i686.manylinux_2_28_i686.manylinux_2_5_i686.whl", hash = "sha256:0934f3843a1860dd465d38895c17fce1f1cb37295149ab05cd1b9a03afacb2a7", size = 250545, upload-time = "2025-10-06T14:49:24.882Z" },
+ { url = "https://files.pythonhosted.org/packages/71/2f/91dbac13e0ba94669ea5119ba267c9a832f0cb65419aca75549fcf09a3dc/multidict-6.7.0-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:b3e34f3a1b8131ba06f1a73adab24f30934d148afcd5f5de9a73565a4404384e", size = 258305, upload-time = "2025-10-06T14:49:26.778Z" },
+ { url = "https://files.pythonhosted.org/packages/ef/b0/754038b26f6e04488b48ac621f779c341338d78503fb45403755af2df477/multidict-6.7.0-cp312-cp312-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:efbb54e98446892590dc2458c19c10344ee9a883a79b5cec4bc34d6656e8d546", size = 242363, upload-time = "2025-10-06T14:49:28.562Z" },
+ { url = "https://files.pythonhosted.org/packages/87/15/9da40b9336a7c9fa606c4cf2ed80a649dffeb42b905d4f63a1d7eb17d746/multidict-6.7.0-cp312-cp312-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:a35c5fc61d4f51eb045061e7967cfe3123d622cd500e8868e7c0c592a09fedc4", size = 268375, upload-time = "2025-10-06T14:49:29.96Z" },
+ { url = "https://files.pythonhosted.org/packages/82/72/c53fcade0cc94dfaad583105fd92b3a783af2091eddcb41a6d5a52474000/multidict-6.7.0-cp312-cp312-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:29fe6740ebccba4175af1b9b87bf553e9c15cd5868ee967e010efcf94e4fd0f1", size = 269346, upload-time = "2025-10-06T14:49:31.404Z" },
+ { url = "https://files.pythonhosted.org/packages/0d/e2/9baffdae21a76f77ef8447f1a05a96ec4bc0a24dae08767abc0a2fe680b8/multidict-6.7.0-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:123e2a72e20537add2f33a79e605f6191fba2afda4cbb876e35c1a7074298a7d", size = 256107, upload-time = "2025-10-06T14:49:32.974Z" },
+ { url = "https://files.pythonhosted.org/packages/3c/06/3f06f611087dc60d65ef775f1fb5aca7c6d61c6db4990e7cda0cef9b1651/multidict-6.7.0-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:b284e319754366c1aee2267a2036248b24eeb17ecd5dc16022095e747f2f4304", size = 253592, upload-time = "2025-10-06T14:49:34.52Z" },
+ { url = "https://files.pythonhosted.org/packages/20/24/54e804ec7945b6023b340c412ce9c3f81e91b3bf5fa5ce65558740141bee/multidict-6.7.0-cp312-cp312-musllinux_1_2_armv7l.whl", hash = "sha256:803d685de7be4303b5a657b76e2f6d1240e7e0a8aa2968ad5811fa2285553a12", size = 251024, upload-time = "2025-10-06T14:49:35.956Z" },
+ { url = "https://files.pythonhosted.org/packages/14/48/011cba467ea0b17ceb938315d219391d3e421dfd35928e5dbdc3f4ae76ef/multidict-6.7.0-cp312-cp312-musllinux_1_2_i686.whl", hash = "sha256:c04a328260dfd5db8c39538f999f02779012268f54614902d0afc775d44e0a62", size = 251484, upload-time = "2025-10-06T14:49:37.631Z" },
+ { url = "https://files.pythonhosted.org/packages/0d/2f/919258b43bb35b99fa127435cfb2d91798eb3a943396631ef43e3720dcf4/multidict-6.7.0-cp312-cp312-musllinux_1_2_ppc64le.whl", hash = "sha256:8a19cdb57cd3df4cd865849d93ee14920fb97224300c88501f16ecfa2604b4e0", size = 263579, upload-time = "2025-10-06T14:49:39.502Z" },
+ { url = "https://files.pythonhosted.org/packages/31/22/a0e884d86b5242b5a74cf08e876bdf299e413016b66e55511f7a804a366e/multidict-6.7.0-cp312-cp312-musllinux_1_2_s390x.whl", hash = "sha256:9b2fd74c52accced7e75de26023b7dccee62511a600e62311b918ec5c168fc2a", size = 259654, upload-time = "2025-10-06T14:49:41.32Z" },
+ { url = "https://files.pythonhosted.org/packages/b2/e5/17e10e1b5c5f5a40f2fcbb45953c9b215f8a4098003915e46a93f5fcaa8f/multidict-6.7.0-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:3e8bfdd0e487acf992407a140d2589fe598238eaeffa3da8448d63a63cd363f8", size = 251511, upload-time = "2025-10-06T14:49:46.021Z" },
+ { url = "https://files.pythonhosted.org/packages/e3/9a/201bb1e17e7af53139597069c375e7b0dcbd47594604f65c2d5359508566/multidict-6.7.0-cp312-cp312-win32.whl", hash = "sha256:dd32a49400a2c3d52088e120ee00c1e3576cbff7e10b98467962c74fdb762ed4", size = 41895, upload-time = "2025-10-06T14:49:48.718Z" },
+ { url = "https://files.pythonhosted.org/packages/46/e2/348cd32faad84eaf1d20cce80e2bb0ef8d312c55bca1f7fa9865e7770aaf/multidict-6.7.0-cp312-cp312-win_amd64.whl", hash = "sha256:92abb658ef2d7ef22ac9f8bb88e8b6c3e571671534e029359b6d9e845923eb1b", size = 46073, upload-time = "2025-10-06T14:49:50.28Z" },
+ { url = "https://files.pythonhosted.org/packages/25/ec/aad2613c1910dce907480e0c3aa306905830f25df2e54ccc9dea450cb5aa/multidict-6.7.0-cp312-cp312-win_arm64.whl", hash = "sha256:490dab541a6a642ce1a9d61a4781656b346a55c13038f0b1244653828e3a83ec", size = 43226, upload-time = "2025-10-06T14:49:52.304Z" },
+ { url = "https://files.pythonhosted.org/packages/d2/86/33272a544eeb36d66e4d9a920602d1a2f57d4ebea4ef3cdfe5a912574c95/multidict-6.7.0-cp313-cp313-macosx_10_13_universal2.whl", hash = "sha256:bee7c0588aa0076ce77c0ea5d19a68d76ad81fcd9fe8501003b9a24f9d4000f6", size = 76135, upload-time = "2025-10-06T14:49:54.26Z" },
+ { url = "https://files.pythonhosted.org/packages/91/1c/eb97db117a1ebe46d457a3d235a7b9d2e6dcab174f42d1b67663dd9e5371/multidict-6.7.0-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:7ef6b61cad77091056ce0e7ce69814ef72afacb150b7ac6a3e9470def2198159", size = 45117, upload-time = "2025-10-06T14:49:55.82Z" },
+ { url = "https://files.pythonhosted.org/packages/f1/d8/6c3442322e41fb1dd4de8bd67bfd11cd72352ac131f6368315617de752f1/multidict-6.7.0-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:9c0359b1ec12b1d6849c59f9d319610b7f20ef990a6d454ab151aa0e3b9f78ca", size = 43472, upload-time = "2025-10-06T14:49:57.048Z" },
+ { url = "https://files.pythonhosted.org/packages/75/3f/e2639e80325af0b6c6febdf8e57cc07043ff15f57fa1ef808f4ccb5ac4cd/multidict-6.7.0-cp313-cp313-manylinux1_i686.manylinux_2_28_i686.manylinux_2_5_i686.whl", hash = "sha256:cd240939f71c64bd658f186330603aac1a9a81bf6273f523fca63673cb7378a8", size = 249342, upload-time = "2025-10-06T14:49:58.368Z" },
+ { url = "https://files.pythonhosted.org/packages/5d/cc/84e0585f805cbeaa9cbdaa95f9a3d6aed745b9d25700623ac89a6ecff400/multidict-6.7.0-cp313-cp313-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:a60a4d75718a5efa473ebd5ab685786ba0c67b8381f781d1be14da49f1a2dc60", size = 257082, upload-time = "2025-10-06T14:49:59.89Z" },
+ { url = "https://files.pythonhosted.org/packages/b0/9c/ac851c107c92289acbbf5cfb485694084690c1b17e555f44952c26ddc5bd/multidict-6.7.0-cp313-cp313-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:53a42d364f323275126aff81fb67c5ca1b7a04fda0546245730a55c8c5f24bc4", size = 240704, upload-time = "2025-10-06T14:50:01.485Z" },
+ { url = "https://files.pythonhosted.org/packages/50/cc/5f93e99427248c09da95b62d64b25748a5f5c98c7c2ab09825a1d6af0e15/multidict-6.7.0-cp313-cp313-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:3b29b980d0ddbecb736735ee5bef69bb2ddca56eff603c86f3f29a1128299b4f", size = 266355, upload-time = "2025-10-06T14:50:02.955Z" },
+ { url = "https://files.pythonhosted.org/packages/ec/0c/2ec1d883ceb79c6f7f6d7ad90c919c898f5d1c6ea96d322751420211e072/multidict-6.7.0-cp313-cp313-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:f8a93b1c0ed2d04b97a5e9336fd2d33371b9a6e29ab7dd6503d63407c20ffbaf", size = 267259, upload-time = "2025-10-06T14:50:04.446Z" },
+ { url = "https://files.pythonhosted.org/packages/c6/2d/f0b184fa88d6630aa267680bdb8623fb69cb0d024b8c6f0d23f9a0f406d3/multidict-6.7.0-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:9ff96e8815eecacc6645da76c413eb3b3d34cfca256c70b16b286a687d013c32", size = 254903, upload-time = "2025-10-06T14:50:05.98Z" },
+ { url = "https://files.pythonhosted.org/packages/06/c9/11ea263ad0df7dfabcad404feb3c0dd40b131bc7f232d5537f2fb1356951/multidict-6.7.0-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:7516c579652f6a6be0e266aec0acd0db80829ca305c3d771ed898538804c2036", size = 252365, upload-time = "2025-10-06T14:50:07.511Z" },
+ { url = "https://files.pythonhosted.org/packages/41/88/d714b86ee2c17d6e09850c70c9d310abac3d808ab49dfa16b43aba9d53fd/multidict-6.7.0-cp313-cp313-musllinux_1_2_armv7l.whl", hash = "sha256:040f393368e63fb0f3330e70c26bfd336656bed925e5cbe17c9da839a6ab13ec", size = 250062, upload-time = "2025-10-06T14:50:09.074Z" },
+ { url = "https://files.pythonhosted.org/packages/15/fe/ad407bb9e818c2b31383f6131ca19ea7e35ce93cf1310fce69f12e89de75/multidict-6.7.0-cp313-cp313-musllinux_1_2_i686.whl", hash = "sha256:b3bc26a951007b1057a1c543af845f1c7e3e71cc240ed1ace7bf4484aa99196e", size = 249683, upload-time = "2025-10-06T14:50:10.714Z" },
+ { url = "https://files.pythonhosted.org/packages/8c/a4/a89abdb0229e533fb925e7c6e5c40201c2873efebc9abaf14046a4536ee6/multidict-6.7.0-cp313-cp313-musllinux_1_2_ppc64le.whl", hash = "sha256:7b022717c748dd1992a83e219587aabe45980d88969f01b316e78683e6285f64", size = 261254, upload-time = "2025-10-06T14:50:12.28Z" },
+ { url = "https://files.pythonhosted.org/packages/8d/aa/0e2b27bd88b40a4fb8dc53dd74eecac70edaa4c1dd0707eb2164da3675b3/multidict-6.7.0-cp313-cp313-musllinux_1_2_s390x.whl", hash = "sha256:9600082733859f00d79dee64effc7aef1beb26adb297416a4ad2116fd61374bd", size = 257967, upload-time = "2025-10-06T14:50:14.16Z" },
+ { url = "https://files.pythonhosted.org/packages/d0/8e/0c67b7120d5d5f6d874ed85a085f9dc770a7f9d8813e80f44a9fec820bb7/multidict-6.7.0-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:94218fcec4d72bc61df51c198d098ce2b378e0ccbac41ddbed5ef44092913288", size = 250085, upload-time = "2025-10-06T14:50:15.639Z" },
+ { url = "https://files.pythonhosted.org/packages/ba/55/b73e1d624ea4b8fd4dd07a3bb70f6e4c7c6c5d9d640a41c6ffe5cdbd2a55/multidict-6.7.0-cp313-cp313-win32.whl", hash = "sha256:a37bd74c3fa9d00be2d7b8eca074dc56bd8077ddd2917a839bd989612671ed17", size = 41713, upload-time = "2025-10-06T14:50:17.066Z" },
+ { url = "https://files.pythonhosted.org/packages/32/31/75c59e7d3b4205075b4c183fa4ca398a2daf2303ddf616b04ae6ef55cffe/multidict-6.7.0-cp313-cp313-win_amd64.whl", hash = "sha256:30d193c6cc6d559db42b6bcec8a5d395d34d60c9877a0b71ecd7c204fcf15390", size = 45915, upload-time = "2025-10-06T14:50:18.264Z" },
+ { url = "https://files.pythonhosted.org/packages/31/2a/8987831e811f1184c22bc2e45844934385363ee61c0a2dcfa8f71b87e608/multidict-6.7.0-cp313-cp313-win_arm64.whl", hash = "sha256:ea3334cabe4d41b7ccd01e4d349828678794edbc2d3ae97fc162a3312095092e", size = 43077, upload-time = "2025-10-06T14:50:19.853Z" },
+ { url = "https://files.pythonhosted.org/packages/e8/68/7b3a5170a382a340147337b300b9eb25a9ddb573bcdfff19c0fa3f31ffba/multidict-6.7.0-cp313-cp313t-macosx_10_13_universal2.whl", hash = "sha256:ad9ce259f50abd98a1ca0aa6e490b58c316a0fce0617f609723e40804add2c00", size = 83114, upload-time = "2025-10-06T14:50:21.223Z" },
+ { url = "https://files.pythonhosted.org/packages/55/5c/3fa2d07c84df4e302060f555bbf539310980362236ad49f50eeb0a1c1eb9/multidict-6.7.0-cp313-cp313t-macosx_10_13_x86_64.whl", hash = "sha256:07f5594ac6d084cbb5de2df218d78baf55ef150b91f0ff8a21cc7a2e3a5a58eb", size = 48442, upload-time = "2025-10-06T14:50:22.871Z" },
+ { url = "https://files.pythonhosted.org/packages/fc/56/67212d33239797f9bd91962bb899d72bb0f4c35a8652dcdb8ed049bef878/multidict-6.7.0-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:0591b48acf279821a579282444814a2d8d0af624ae0bc600aa4d1b920b6e924b", size = 46885, upload-time = "2025-10-06T14:50:24.258Z" },
+ { url = "https://files.pythonhosted.org/packages/46/d1/908f896224290350721597a61a69cd19b89ad8ee0ae1f38b3f5cd12ea2ac/multidict-6.7.0-cp313-cp313t-manylinux1_i686.manylinux_2_28_i686.manylinux_2_5_i686.whl", hash = "sha256:749a72584761531d2b9467cfbdfd29487ee21124c304c4b6cb760d8777b27f9c", size = 242588, upload-time = "2025-10-06T14:50:25.716Z" },
+ { url = "https://files.pythonhosted.org/packages/ab/67/8604288bbd68680eee0ab568fdcb56171d8b23a01bcd5cb0c8fedf6e5d99/multidict-6.7.0-cp313-cp313t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:6b4c3d199f953acd5b446bf7c0de1fe25d94e09e79086f8dc2f48a11a129cdf1", size = 249966, upload-time = "2025-10-06T14:50:28.192Z" },
+ { url = "https://files.pythonhosted.org/packages/20/33/9228d76339f1ba51e3efef7da3ebd91964d3006217aae13211653193c3ff/multidict-6.7.0-cp313-cp313t-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:9fb0211dfc3b51efea2f349ec92c114d7754dd62c01f81c3e32b765b70c45c9b", size = 228618, upload-time = "2025-10-06T14:50:29.82Z" },
+ { url = "https://files.pythonhosted.org/packages/f8/2d/25d9b566d10cab1c42b3b9e5b11ef79c9111eaf4463b8c257a3bd89e0ead/multidict-6.7.0-cp313-cp313t-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:a027ec240fe73a8d6281872690b988eed307cd7d91b23998ff35ff577ca688b5", size = 257539, upload-time = "2025-10-06T14:50:31.731Z" },
+ { url = "https://files.pythonhosted.org/packages/b6/b1/8d1a965e6637fc33de3c0d8f414485c2b7e4af00f42cab3d84e7b955c222/multidict-6.7.0-cp313-cp313t-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:d1d964afecdf3a8288789df2f5751dc0a8261138c3768d9af117ed384e538fad", size = 256345, upload-time = "2025-10-06T14:50:33.26Z" },
+ { url = "https://files.pythonhosted.org/packages/ba/0c/06b5a8adbdeedada6f4fb8d8f193d44a347223b11939b42953eeb6530b6b/multidict-6.7.0-cp313-cp313t-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:caf53b15b1b7df9fbd0709aa01409000a2b4dd03a5f6f5cc548183c7c8f8b63c", size = 247934, upload-time = "2025-10-06T14:50:34.808Z" },
+ { url = "https://files.pythonhosted.org/packages/8f/31/b2491b5fe167ca044c6eb4b8f2c9f3b8a00b24c432c365358eadac5d7625/multidict-6.7.0-cp313-cp313t-musllinux_1_2_aarch64.whl", hash = "sha256:654030da3197d927f05a536a66186070e98765aa5142794c9904555d3a9d8fb5", size = 245243, upload-time = "2025-10-06T14:50:36.436Z" },
+ { url = "https://files.pythonhosted.org/packages/61/1a/982913957cb90406c8c94f53001abd9eafc271cb3e70ff6371590bec478e/multidict-6.7.0-cp313-cp313t-musllinux_1_2_armv7l.whl", hash = "sha256:2090d3718829d1e484706a2f525e50c892237b2bf9b17a79b059cb98cddc2f10", size = 235878, upload-time = "2025-10-06T14:50:37.953Z" },
+ { url = "https://files.pythonhosted.org/packages/be/c0/21435d804c1a1cf7a2608593f4d19bca5bcbd7a81a70b253fdd1c12af9c0/multidict-6.7.0-cp313-cp313t-musllinux_1_2_i686.whl", hash = "sha256:2d2cfeec3f6f45651b3d408c4acec0ebf3daa9bc8a112a084206f5db5d05b754", size = 243452, upload-time = "2025-10-06T14:50:39.574Z" },
+ { url = "https://files.pythonhosted.org/packages/54/0a/4349d540d4a883863191be6eb9a928846d4ec0ea007d3dcd36323bb058ac/multidict-6.7.0-cp313-cp313t-musllinux_1_2_ppc64le.whl", hash = "sha256:4ef089f985b8c194d341eb2c24ae6e7408c9a0e2e5658699c92f497437d88c3c", size = 252312, upload-time = "2025-10-06T14:50:41.612Z" },
+ { url = "https://files.pythonhosted.org/packages/26/64/d5416038dbda1488daf16b676e4dbfd9674dde10a0cc8f4fc2b502d8125d/multidict-6.7.0-cp313-cp313t-musllinux_1_2_s390x.whl", hash = "sha256:e93a0617cd16998784bf4414c7e40f17a35d2350e5c6f0bd900d3a8e02bd3762", size = 246935, upload-time = "2025-10-06T14:50:43.972Z" },
+ { url = "https://files.pythonhosted.org/packages/9f/8c/8290c50d14e49f35e0bd4abc25e1bc7711149ca9588ab7d04f886cdf03d9/multidict-6.7.0-cp313-cp313t-musllinux_1_2_x86_64.whl", hash = "sha256:f0feece2ef8ebc42ed9e2e8c78fc4aa3cf455733b507c09ef7406364c94376c6", size = 243385, upload-time = "2025-10-06T14:50:45.648Z" },
+ { url = "https://files.pythonhosted.org/packages/ef/a0/f83ae75e42d694b3fbad3e047670e511c138be747bc713cf1b10d5096416/multidict-6.7.0-cp313-cp313t-win32.whl", hash = "sha256:19a1d55338ec1be74ef62440ca9e04a2f001a04d0cc49a4983dc320ff0f3212d", size = 47777, upload-time = "2025-10-06T14:50:47.154Z" },
+ { url = "https://files.pythonhosted.org/packages/dc/80/9b174a92814a3830b7357307a792300f42c9e94664b01dee8e457551fa66/multidict-6.7.0-cp313-cp313t-win_amd64.whl", hash = "sha256:3da4fb467498df97e986af166b12d01f05d2e04f978a9c1c680ea1988e0bc4b6", size = 53104, upload-time = "2025-10-06T14:50:48.851Z" },
+ { url = "https://files.pythonhosted.org/packages/cc/28/04baeaf0428d95bb7a7bea0e691ba2f31394338ba424fb0679a9ed0f4c09/multidict-6.7.0-cp313-cp313t-win_arm64.whl", hash = "sha256:b4121773c49a0776461f4a904cdf6264c88e42218aaa8407e803ca8025872792", size = 45503, upload-time = "2025-10-06T14:50:50.16Z" },
+ { url = "https://files.pythonhosted.org/packages/e2/b1/3da6934455dd4b261d4c72f897e3a5728eba81db59959f3a639245891baa/multidict-6.7.0-cp314-cp314-macosx_10_13_universal2.whl", hash = "sha256:3bab1e4aff7adaa34410f93b1f8e57c4b36b9af0426a76003f441ee1d3c7e842", size = 75128, upload-time = "2025-10-06T14:50:51.92Z" },
+ { url = "https://files.pythonhosted.org/packages/14/2c/f069cab5b51d175a1a2cb4ccdf7a2c2dabd58aa5bd933fa036a8d15e2404/multidict-6.7.0-cp314-cp314-macosx_10_13_x86_64.whl", hash = "sha256:b8512bac933afc3e45fb2b18da8e59b78d4f408399a960339598374d4ae3b56b", size = 44410, upload-time = "2025-10-06T14:50:53.275Z" },
+ { url = "https://files.pythonhosted.org/packages/42/e2/64bb41266427af6642b6b128e8774ed84c11b80a90702c13ac0a86bb10cc/multidict-6.7.0-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:79dcf9e477bc65414ebfea98ffd013cb39552b5ecd62908752e0e413d6d06e38", size = 43205, upload-time = "2025-10-06T14:50:54.911Z" },
+ { url = "https://files.pythonhosted.org/packages/02/68/6b086fef8a3f1a8541b9236c594f0c9245617c29841f2e0395d979485cde/multidict-6.7.0-cp314-cp314-manylinux1_i686.manylinux_2_28_i686.manylinux_2_5_i686.whl", hash = "sha256:31bae522710064b5cbeddaf2e9f32b1abab70ac6ac91d42572502299e9953128", size = 245084, upload-time = "2025-10-06T14:50:56.369Z" },
+ { url = "https://files.pythonhosted.org/packages/15/ee/f524093232007cd7a75c1d132df70f235cfd590a7c9eaccd7ff422ef4ae8/multidict-6.7.0-cp314-cp314-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:4a0df7ff02397bb63e2fd22af2c87dfa39e8c7f12947bc524dbdc528282c7e34", size = 252667, upload-time = "2025-10-06T14:50:57.991Z" },
+ { url = "https://files.pythonhosted.org/packages/02/a5/eeb3f43ab45878f1895118c3ef157a480db58ede3f248e29b5354139c2c9/multidict-6.7.0-cp314-cp314-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:7a0222514e8e4c514660e182d5156a415c13ef0aabbd71682fc714e327b95e99", size = 233590, upload-time = "2025-10-06T14:50:59.589Z" },
+ { url = "https://files.pythonhosted.org/packages/6a/1e/76d02f8270b97269d7e3dbd45644b1785bda457b474315f8cf999525a193/multidict-6.7.0-cp314-cp314-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:2397ab4daaf2698eb51a76721e98db21ce4f52339e535725de03ea962b5a3202", size = 264112, upload-time = "2025-10-06T14:51:01.183Z" },
+ { url = "https://files.pythonhosted.org/packages/76/0b/c28a70ecb58963847c2a8efe334904cd254812b10e535aefb3bcce513918/multidict-6.7.0-cp314-cp314-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:8891681594162635948a636c9fe0ff21746aeb3dd5463f6e25d9bea3a8a39ca1", size = 261194, upload-time = "2025-10-06T14:51:02.794Z" },
+ { url = "https://files.pythonhosted.org/packages/b4/63/2ab26e4209773223159b83aa32721b4021ffb08102f8ac7d689c943fded1/multidict-6.7.0-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:18706cc31dbf402a7945916dd5cddf160251b6dab8a2c5f3d6d5a55949f676b3", size = 248510, upload-time = "2025-10-06T14:51:04.724Z" },
+ { url = "https://files.pythonhosted.org/packages/93/cd/06c1fa8282af1d1c46fd55c10a7930af652afdce43999501d4d68664170c/multidict-6.7.0-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:f844a1bbf1d207dd311a56f383f7eda2d0e134921d45751842d8235e7778965d", size = 248395, upload-time = "2025-10-06T14:51:06.306Z" },
+ { url = "https://files.pythonhosted.org/packages/99/ac/82cb419dd6b04ccf9e7e61befc00c77614fc8134362488b553402ecd55ce/multidict-6.7.0-cp314-cp314-musllinux_1_2_armv7l.whl", hash = "sha256:d4393e3581e84e5645506923816b9cc81f5609a778c7e7534054091acc64d1c6", size = 239520, upload-time = "2025-10-06T14:51:08.091Z" },
+ { url = "https://files.pythonhosted.org/packages/fa/f3/a0f9bf09493421bd8716a362e0cd1d244f5a6550f5beffdd6b47e885b331/multidict-6.7.0-cp314-cp314-musllinux_1_2_i686.whl", hash = "sha256:fbd18dc82d7bf274b37aa48d664534330af744e03bccf696d6f4c6042e7d19e7", size = 245479, upload-time = "2025-10-06T14:51:10.365Z" },
+ { url = "https://files.pythonhosted.org/packages/8d/01/476d38fc73a212843f43c852b0eee266b6971f0e28329c2184a8df90c376/multidict-6.7.0-cp314-cp314-musllinux_1_2_ppc64le.whl", hash = "sha256:b6234e14f9314731ec45c42fc4554b88133ad53a09092cc48a88e771c125dadb", size = 258903, upload-time = "2025-10-06T14:51:12.466Z" },
+ { url = "https://files.pythonhosted.org/packages/49/6d/23faeb0868adba613b817d0e69c5f15531b24d462af8012c4f6de4fa8dc3/multidict-6.7.0-cp314-cp314-musllinux_1_2_s390x.whl", hash = "sha256:08d4379f9744d8f78d98c8673c06e202ffa88296f009c71bbafe8a6bf847d01f", size = 252333, upload-time = "2025-10-06T14:51:14.48Z" },
+ { url = "https://files.pythonhosted.org/packages/1e/cc/48d02ac22b30fa247f7dad82866e4b1015431092f4ba6ebc7e77596e0b18/multidict-6.7.0-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:9fe04da3f79387f450fd0061d4dd2e45a72749d31bf634aecc9e27f24fdc4b3f", size = 243411, upload-time = "2025-10-06T14:51:16.072Z" },
+ { url = "https://files.pythonhosted.org/packages/4a/03/29a8bf5a18abf1fe34535c88adbdfa88c9fb869b5a3b120692c64abe8284/multidict-6.7.0-cp314-cp314-win32.whl", hash = "sha256:fbafe31d191dfa7c4c51f7a6149c9fb7e914dcf9ffead27dcfd9f1ae382b3885", size = 40940, upload-time = "2025-10-06T14:51:17.544Z" },
+ { url = "https://files.pythonhosted.org/packages/82/16/7ed27b680791b939de138f906d5cf2b4657b0d45ca6f5dd6236fdddafb1a/multidict-6.7.0-cp314-cp314-win_amd64.whl", hash = "sha256:2f67396ec0310764b9222a1728ced1ab638f61aadc6226f17a71dd9324f9a99c", size = 45087, upload-time = "2025-10-06T14:51:18.875Z" },
+ { url = "https://files.pythonhosted.org/packages/cd/3c/e3e62eb35a1950292fe39315d3c89941e30a9d07d5d2df42965ab041da43/multidict-6.7.0-cp314-cp314-win_arm64.whl", hash = "sha256:ba672b26069957ee369cfa7fc180dde1fc6f176eaf1e6beaf61fbebbd3d9c000", size = 42368, upload-time = "2025-10-06T14:51:20.225Z" },
+ { url = "https://files.pythonhosted.org/packages/8b/40/cd499bd0dbc5f1136726db3153042a735fffd0d77268e2ee20d5f33c010f/multidict-6.7.0-cp314-cp314t-macosx_10_13_universal2.whl", hash = "sha256:c1dcc7524066fa918c6a27d61444d4ee7900ec635779058571f70d042d86ed63", size = 82326, upload-time = "2025-10-06T14:51:21.588Z" },
+ { url = "https://files.pythonhosted.org/packages/13/8a/18e031eca251c8df76daf0288e6790561806e439f5ce99a170b4af30676b/multidict-6.7.0-cp314-cp314t-macosx_10_13_x86_64.whl", hash = "sha256:27e0b36c2d388dc7b6ced3406671b401e84ad7eb0656b8f3a2f46ed0ce483718", size = 48065, upload-time = "2025-10-06T14:51:22.93Z" },
+ { url = "https://files.pythonhosted.org/packages/40/71/5e6701277470a87d234e433fb0a3a7deaf3bcd92566e421e7ae9776319de/multidict-6.7.0-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:2a7baa46a22e77f0988e3b23d4ede5513ebec1929e34ee9495be535662c0dfe2", size = 46475, upload-time = "2025-10-06T14:51:24.352Z" },
+ { url = "https://files.pythonhosted.org/packages/fe/6a/bab00cbab6d9cfb57afe1663318f72ec28289ea03fd4e8236bb78429893a/multidict-6.7.0-cp314-cp314t-manylinux1_i686.manylinux_2_28_i686.manylinux_2_5_i686.whl", hash = "sha256:7bf77f54997a9166a2f5675d1201520586439424c2511723a7312bdb4bcc034e", size = 239324, upload-time = "2025-10-06T14:51:25.822Z" },
+ { url = "https://files.pythonhosted.org/packages/2a/5f/8de95f629fc22a7769ade8b41028e3e5a822c1f8904f618d175945a81ad3/multidict-6.7.0-cp314-cp314t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:e011555abada53f1578d63389610ac8a5400fc70ce71156b0aa30d326f1a5064", size = 246877, upload-time = "2025-10-06T14:51:27.604Z" },
+ { url = "https://files.pythonhosted.org/packages/23/b4/38881a960458f25b89e9f4a4fdcb02ac101cfa710190db6e5528841e67de/multidict-6.7.0-cp314-cp314t-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:28b37063541b897fd6a318007373930a75ca6d6ac7c940dbe14731ffdd8d498e", size = 225824, upload-time = "2025-10-06T14:51:29.664Z" },
+ { url = "https://files.pythonhosted.org/packages/1e/39/6566210c83f8a261575f18e7144736059f0c460b362e96e9cf797a24b8e7/multidict-6.7.0-cp314-cp314t-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:05047ada7a2fde2631a0ed706f1fd68b169a681dfe5e4cf0f8e4cb6618bbc2cd", size = 253558, upload-time = "2025-10-06T14:51:31.684Z" },
+ { url = "https://files.pythonhosted.org/packages/00/a3/67f18315100f64c269f46e6c0319fa87ba68f0f64f2b8e7fd7c72b913a0b/multidict-6.7.0-cp314-cp314t-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:716133f7d1d946a4e1b91b1756b23c088881e70ff180c24e864c26192ad7534a", size = 252339, upload-time = "2025-10-06T14:51:33.699Z" },
+ { url = "https://files.pythonhosted.org/packages/c8/2a/1cb77266afee2458d82f50da41beba02159b1d6b1f7973afc9a1cad1499b/multidict-6.7.0-cp314-cp314t-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:d1bed1b467ef657f2a0ae62844a607909ef1c6889562de5e1d505f74457d0b96", size = 244895, upload-time = "2025-10-06T14:51:36.189Z" },
+ { url = "https://files.pythonhosted.org/packages/dd/72/09fa7dd487f119b2eb9524946ddd36e2067c08510576d43ff68469563b3b/multidict-6.7.0-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:ca43bdfa5d37bd6aee89d85e1d0831fb86e25541be7e9d376ead1b28974f8e5e", size = 241862, upload-time = "2025-10-06T14:51:41.291Z" },
+ { url = "https://files.pythonhosted.org/packages/65/92/bc1f8bd0853d8669300f732c801974dfc3702c3eeadae2f60cef54dc69d7/multidict-6.7.0-cp314-cp314t-musllinux_1_2_armv7l.whl", hash = "sha256:44b546bd3eb645fd26fb949e43c02a25a2e632e2ca21a35e2e132c8105dc8599", size = 232376, upload-time = "2025-10-06T14:51:43.55Z" },
+ { url = "https://files.pythonhosted.org/packages/09/86/ac39399e5cb9d0c2ac8ef6e10a768e4d3bc933ac808d49c41f9dc23337eb/multidict-6.7.0-cp314-cp314t-musllinux_1_2_i686.whl", hash = "sha256:a6ef16328011d3f468e7ebc326f24c1445f001ca1dec335b2f8e66bed3006394", size = 240272, upload-time = "2025-10-06T14:51:45.265Z" },
+ { url = "https://files.pythonhosted.org/packages/3d/b6/fed5ac6b8563ec72df6cb1ea8dac6d17f0a4a1f65045f66b6d3bf1497c02/multidict-6.7.0-cp314-cp314t-musllinux_1_2_ppc64le.whl", hash = "sha256:5aa873cbc8e593d361ae65c68f85faadd755c3295ea2c12040ee146802f23b38", size = 248774, upload-time = "2025-10-06T14:51:46.836Z" },
+ { url = "https://files.pythonhosted.org/packages/6b/8d/b954d8c0dc132b68f760aefd45870978deec6818897389dace00fcde32ff/multidict-6.7.0-cp314-cp314t-musllinux_1_2_s390x.whl", hash = "sha256:3d7b6ccce016e29df4b7ca819659f516f0bc7a4b3efa3bb2012ba06431b044f9", size = 242731, upload-time = "2025-10-06T14:51:48.541Z" },
+ { url = "https://files.pythonhosted.org/packages/16/9d/a2dac7009125d3540c2f54e194829ea18ac53716c61b655d8ed300120b0f/multidict-6.7.0-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:171b73bd4ee683d307599b66793ac80981b06f069b62eea1c9e29c9241aa66b0", size = 240193, upload-time = "2025-10-06T14:51:50.355Z" },
+ { url = "https://files.pythonhosted.org/packages/39/ca/c05f144128ea232ae2178b008d5011d4e2cea86e4ee8c85c2631b1b94802/multidict-6.7.0-cp314-cp314t-win32.whl", hash = "sha256:b2d7f80c4e1fd010b07cb26820aae86b7e73b681ee4889684fb8d2d4537aab13", size = 48023, upload-time = "2025-10-06T14:51:51.883Z" },
+ { url = "https://files.pythonhosted.org/packages/ba/8f/0a60e501584145588be1af5cc829265701ba3c35a64aec8e07cbb71d39bb/multidict-6.7.0-cp314-cp314t-win_amd64.whl", hash = "sha256:09929cab6fcb68122776d575e03c6cc64ee0b8fca48d17e135474b042ce515cd", size = 53507, upload-time = "2025-10-06T14:51:53.672Z" },
+ { url = "https://files.pythonhosted.org/packages/7f/ae/3148b988a9c6239903e786eac19c889fab607c31d6efa7fb2147e5680f23/multidict-6.7.0-cp314-cp314t-win_arm64.whl", hash = "sha256:cc41db090ed742f32bd2d2c721861725e6109681eddf835d0a82bd3a5c382827", size = 44804, upload-time = "2025-10-06T14:51:55.415Z" },
+ { url = "https://files.pythonhosted.org/packages/b7/da/7d22601b625e241d4f23ef1ebff8acfc60da633c9e7e7922e24d10f592b3/multidict-6.7.0-py3-none-any.whl", hash = "sha256:394fc5c42a333c9ffc3e421a4c85e08580d990e08b99f6bf35b4132114c5dcb3", size = 12317, upload-time = "2025-10-06T14:52:29.272Z" },
+]
+
+[[package]]
+name = "multiprocess"
+version = "0.70.18"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "dill" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/72/fd/2ae3826f5be24c6ed87266bc4e59c46ea5b059a103f3d7e7eb76a52aeecb/multiprocess-0.70.18.tar.gz", hash = "sha256:f9597128e6b3e67b23956da07cf3d2e5cba79e2f4e0fba8d7903636663ec6d0d", size = 1798503, upload-time = "2025-04-17T03:11:27.742Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/ba/d8/0cba6cf51a1a31f20471fbc823a716170c73012ddc4fb85d706630ed6e8f/multiprocess-0.70.18-py310-none-any.whl", hash = "sha256:60c194974c31784019c1f459d984e8f33ee48f10fcf42c309ba97b30d9bd53ea", size = 134948, upload-time = "2025-04-17T03:11:20.223Z" },
+ { url = "https://files.pythonhosted.org/packages/4b/88/9039f2fed1012ef584751d4ceff9ab4a51e5ae264898f0b7cbf44340a859/multiprocess-0.70.18-py311-none-any.whl", hash = "sha256:5aa6eef98e691281b3ad923be2832bf1c55dd2c859acd73e5ec53a66aae06a1d", size = 144462, upload-time = "2025-04-17T03:11:21.657Z" },
+ { url = "https://files.pythonhosted.org/packages/bf/b6/5f922792be93b82ec6b5f270bbb1ef031fd0622847070bbcf9da816502cc/multiprocess-0.70.18-py312-none-any.whl", hash = "sha256:9b78f8e5024b573730bfb654783a13800c2c0f2dfc0c25e70b40d184d64adaa2", size = 150287, upload-time = "2025-04-17T03:11:22.69Z" },
+ { url = "https://files.pythonhosted.org/packages/ee/25/7d7e78e750bc1aecfaf0efbf826c69a791d2eeaf29cf20cba93ff4cced78/multiprocess-0.70.18-py313-none-any.whl", hash = "sha256:871743755f43ef57d7910a38433cfe41319e72be1bbd90b79c7a5ac523eb9334", size = 151917, upload-time = "2025-04-17T03:11:24.044Z" },
+ { url = "https://files.pythonhosted.org/packages/3b/c3/ca84c19bd14cdfc21c388fdcebf08b86a7a470ebc9f5c3c084fc2dbc50f7/multiprocess-0.70.18-py38-none-any.whl", hash = "sha256:dbf705e52a154fe5e90fb17b38f02556169557c2dd8bb084f2e06c2784d8279b", size = 132636, upload-time = "2025-04-17T03:11:24.936Z" },
+ { url = "https://files.pythonhosted.org/packages/6c/28/dd72947e59a6a8c856448a5e74da6201cb5502ddff644fbc790e4bd40b9a/multiprocess-0.70.18-py39-none-any.whl", hash = "sha256:e78ca805a72b1b810c690b6b4cc32579eba34f403094bbbae962b7b5bf9dfcb8", size = 133478, upload-time = "2025-04-17T03:11:26.253Z" },
+]
+
+[[package]]
+name = "nbclient"
+version = "0.10.2"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "jupyter-client" },
+ { name = "jupyter-core" },
+ { name = "nbformat" },
+ { name = "traitlets" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/87/66/7ffd18d58eae90d5721f9f39212327695b749e23ad44b3881744eaf4d9e8/nbclient-0.10.2.tar.gz", hash = "sha256:90b7fc6b810630db87a6d0c2250b1f0ab4cf4d3c27a299b0cde78a4ed3fd9193", size = 62424, upload-time = "2024-12-19T10:32:27.164Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/34/6d/e7fa07f03a4a7b221d94b4d586edb754a9b0dc3c9e2c93353e9fa4e0d117/nbclient-0.10.2-py3-none-any.whl", hash = "sha256:4ffee11e788b4a27fabeb7955547e4318a5298f34342a4bfd01f2e1faaeadc3d", size = 25434, upload-time = "2024-12-19T10:32:24.139Z" },
+]
+
+[[package]]
+name = "nbconvert"
+version = "7.16.6"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "beautifulsoup4" },
+ { name = "bleach", extra = ["css"] },
+ { name = "defusedxml" },
+ { name = "jinja2" },
+ { name = "jupyter-core" },
+ { name = "jupyterlab-pygments" },
+ { name = "markupsafe" },
+ { name = "mistune" },
+ { name = "nbclient" },
+ { name = "nbformat" },
+ { name = "packaging" },
+ { name = "pandocfilters" },
+ { name = "pygments" },
+ { name = "traitlets" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/a3/59/f28e15fc47ffb73af68a8d9b47367a8630d76e97ae85ad18271b9db96fdf/nbconvert-7.16.6.tar.gz", hash = "sha256:576a7e37c6480da7b8465eefa66c17844243816ce1ccc372633c6b71c3c0f582", size = 857715, upload-time = "2025-01-28T09:29:14.724Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/cc/9a/cd673b2f773a12c992f41309ef81b99da1690426bd2f96957a7ade0d3ed7/nbconvert-7.16.6-py3-none-any.whl", hash = "sha256:1375a7b67e0c2883678c48e506dc320febb57685e5ee67faa51b18a90f3a712b", size = 258525, upload-time = "2025-01-28T09:29:12.551Z" },
+]
+
+[[package]]
+name = "nbformat"
+version = "5.10.4"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "fastjsonschema" },
+ { name = "jsonschema" },
+ { name = "jupyter-core" },
+ { name = "traitlets" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/6d/fd/91545e604bc3dad7dca9ed03284086039b294c6b3d75c0d2fa45f9e9caf3/nbformat-5.10.4.tar.gz", hash = "sha256:322168b14f937a5d11362988ecac2a4952d3d8e3a2cbeb2319584631226d5b3a", size = 142749, upload-time = "2024-04-04T11:20:37.371Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/a9/82/0340caa499416c78e5d8f5f05947ae4bc3cba53c9f038ab6e9ed964e22f1/nbformat-5.10.4-py3-none-any.whl", hash = "sha256:3b48d6c8fbca4b299bf3982ea7db1af21580e4fec269ad087b9e81588891200b", size = 78454, upload-time = "2024-04-04T11:20:34.895Z" },
+]
+
+[[package]]
+name = "nest-asyncio"
+version = "1.6.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/83/f8/51569ac65d696c8ecbee95938f89d4abf00f47d58d48f6fbabfe8f0baefe/nest_asyncio-1.6.0.tar.gz", hash = "sha256:6f172d5449aca15afd6c646851f4e31e02c598d553a667e38cafa997cfec55fe", size = 7418, upload-time = "2024-01-21T14:25:19.227Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/a0/c4/c2971a3ba4c6103a3d10c4b0f24f461ddc027f0f09763220cf35ca1401b3/nest_asyncio-1.6.0-py3-none-any.whl", hash = "sha256:87af6efd6b5e897c81050477ef65c62e2b2f35d51703cae01aff2905b1852e1c", size = 5195, upload-time = "2024-01-21T14:25:17.223Z" },
+]
+
+[[package]]
+name = "networkx"
+version = "3.6.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/6a/51/63fe664f3908c97be9d2e4f1158eb633317598cfa6e1fc14af5383f17512/networkx-3.6.1.tar.gz", hash = "sha256:26b7c357accc0c8cde558ad486283728b65b6a95d85ee1cd66bafab4c8168509", size = 2517025, upload-time = "2025-12-08T17:02:39.908Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/9e/c9/b2622292ea83fbb4ec318f5b9ab867d0a28ab43c5717bb85b0a5f6b3b0a4/networkx-3.6.1-py3-none-any.whl", hash = "sha256:d47fbf302e7d9cbbb9e2555a0d267983d2aa476bac30e90dfbe5669bd57f3762", size = 2068504, upload-time = "2025-12-08T17:02:38.159Z" },
+]
+
+[[package]]
+name = "nltk"
+version = "3.9.2"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "click" },
+ { name = "joblib" },
+ { name = "regex" },
+ { name = "tqdm" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/f9/76/3a5e4312c19a028770f86fd7c058cf9f4ec4321c6cf7526bab998a5b683c/nltk-3.9.2.tar.gz", hash = "sha256:0f409e9b069ca4177c1903c3e843eef90c7e92992fa4931ae607da6de49e1419", size = 2887629, upload-time = "2025-10-01T07:19:23.764Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/60/90/81ac364ef94209c100e12579629dc92bf7a709a84af32f8c551b02c07e94/nltk-3.9.2-py3-none-any.whl", hash = "sha256:1e209d2b3009110635ed9709a67a1a3e33a10f799490fa71cf4bec218c11c88a", size = 1513404, upload-time = "2025-10-01T07:19:21.648Z" },
+]
+
+[[package]]
+name = "notebook"
+version = "7.5.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "jupyter-server" },
+ { name = "jupyterlab" },
+ { name = "jupyterlab-server" },
+ { name = "notebook-shim" },
+ { name = "tornado" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/89/ac/a97041621250a4fc5af379fb377942841eea2ca146aab166b8fcdfba96c2/notebook-7.5.0.tar.gz", hash = "sha256:3b27eaf9913033c28dde92d02139414c608992e1df4b969c843219acf2ff95e4", size = 14052074, upload-time = "2025-11-19T08:36:20.093Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/73/96/00df2a4760f10f5af0f45c4955573cae6189931f9a30265a35865f8c1031/notebook-7.5.0-py3-none-any.whl", hash = "sha256:3300262d52905ca271bd50b22617681d95f08a8360d099e097726e6d2efb5811", size = 14460968, upload-time = "2025-11-19T08:36:15.869Z" },
+]
+
+[[package]]
+name = "notebook-shim"
+version = "0.2.4"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "jupyter-server" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/54/d2/92fa3243712b9a3e8bafaf60aac366da1cada3639ca767ff4b5b3654ec28/notebook_shim-0.2.4.tar.gz", hash = "sha256:b4b2cfa1b65d98307ca24361f5b30fe785b53c3fd07b7a47e89acb5e6ac638cb", size = 13167, upload-time = "2024-02-14T23:35:18.353Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/f9/33/bd5b9137445ea4b680023eb0469b2bb969d61303dedb2aac6560ff3d14a1/notebook_shim-0.2.4-py3-none-any.whl", hash = "sha256:411a5be4e9dc882a074ccbcae671eda64cceb068767e9a3419096986560e1cef", size = 13307, upload-time = "2024-02-14T23:35:16.286Z" },
+]
+
+[[package]]
+name = "numpy"
+version = "2.3.5"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/76/65/21b3bc86aac7b8f2862db1e808f1ea22b028e30a225a34a5ede9bf8678f2/numpy-2.3.5.tar.gz", hash = "sha256:784db1dcdab56bf0517743e746dfb0f885fc68d948aba86eeec2cba234bdf1c0", size = 20584950, upload-time = "2025-11-16T22:52:42.067Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/44/37/e669fe6cbb2b96c62f6bbedc6a81c0f3b7362f6a59230b23caa673a85721/numpy-2.3.5-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:74ae7b798248fe62021dbf3c914245ad45d1a6b0cb4a29ecb4b31d0bfbc4cc3e", size = 16733873, upload-time = "2025-11-16T22:49:49.84Z" },
+ { url = "https://files.pythonhosted.org/packages/c5/65/df0db6c097892c9380851ab9e44b52d4f7ba576b833996e0080181c0c439/numpy-2.3.5-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:ee3888d9ff7c14604052b2ca5535a30216aa0a58e948cdd3eeb8d3415f638769", size = 12259838, upload-time = "2025-11-16T22:49:52.863Z" },
+ { url = "https://files.pythonhosted.org/packages/5b/e1/1ee06e70eb2136797abe847d386e7c0e830b67ad1d43f364dd04fa50d338/numpy-2.3.5-cp312-cp312-macosx_14_0_arm64.whl", hash = "sha256:612a95a17655e213502f60cfb9bf9408efdc9eb1d5f50535cc6eb365d11b42b5", size = 5088378, upload-time = "2025-11-16T22:49:55.055Z" },
+ { url = "https://files.pythonhosted.org/packages/6d/9c/1ca85fb86708724275103b81ec4cf1ac1d08f465368acfc8da7ab545bdae/numpy-2.3.5-cp312-cp312-macosx_14_0_x86_64.whl", hash = "sha256:3101e5177d114a593d79dd79658650fe28b5a0d8abeb8ce6f437c0e6df5be1a4", size = 6628559, upload-time = "2025-11-16T22:49:57.371Z" },
+ { url = "https://files.pythonhosted.org/packages/74/78/fcd41e5a0ce4f3f7b003da85825acddae6d7ecb60cf25194741b036ca7d6/numpy-2.3.5-cp312-cp312-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:8b973c57ff8e184109db042c842423ff4f60446239bd585a5131cc47f06f789d", size = 14250702, upload-time = "2025-11-16T22:49:59.632Z" },
+ { url = "https://files.pythonhosted.org/packages/b6/23/2a1b231b8ff672b4c450dac27164a8b2ca7d9b7144f9c02d2396518352eb/numpy-2.3.5-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:0d8163f43acde9a73c2a33605353a4f1bc4798745a8b1d73183b28e5b435ae28", size = 16606086, upload-time = "2025-11-16T22:50:02.127Z" },
+ { url = "https://files.pythonhosted.org/packages/a0/c5/5ad26fbfbe2012e190cc7d5003e4d874b88bb18861d0829edc140a713021/numpy-2.3.5-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:51c1e14eb1e154ebd80e860722f9e6ed6ec89714ad2db2d3aa33c31d7c12179b", size = 16025985, upload-time = "2025-11-16T22:50:04.536Z" },
+ { url = "https://files.pythonhosted.org/packages/d2/fa/dd48e225c46c819288148d9d060b047fd2a6fb1eb37eae25112ee4cb4453/numpy-2.3.5-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:b46b4ec24f7293f23adcd2d146960559aaf8020213de8ad1909dba6c013bf89c", size = 18542976, upload-time = "2025-11-16T22:50:07.557Z" },
+ { url = "https://files.pythonhosted.org/packages/05/79/ccbd23a75862d95af03d28b5c6901a1b7da4803181513d52f3b86ed9446e/numpy-2.3.5-cp312-cp312-win32.whl", hash = "sha256:3997b5b3c9a771e157f9aae01dd579ee35ad7109be18db0e85dbdbe1de06e952", size = 6285274, upload-time = "2025-11-16T22:50:10.746Z" },
+ { url = "https://files.pythonhosted.org/packages/2d/57/8aeaf160312f7f489dea47ab61e430b5cb051f59a98ae68b7133ce8fa06a/numpy-2.3.5-cp312-cp312-win_amd64.whl", hash = "sha256:86945f2ee6d10cdfd67bcb4069c1662dd711f7e2a4343db5cecec06b87cf31aa", size = 12782922, upload-time = "2025-11-16T22:50:12.811Z" },
+ { url = "https://files.pythonhosted.org/packages/78/a6/aae5cc2ca78c45e64b9ef22f089141d661516856cf7c8a54ba434576900d/numpy-2.3.5-cp312-cp312-win_arm64.whl", hash = "sha256:f28620fe26bee16243be2b7b874da327312240a7cdc38b769a697578d2100013", size = 10194667, upload-time = "2025-11-16T22:50:16.16Z" },
+ { url = "https://files.pythonhosted.org/packages/db/69/9cde09f36da4b5a505341180a3f2e6fadc352fd4d2b7096ce9778db83f1a/numpy-2.3.5-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:d0f23b44f57077c1ede8c5f26b30f706498b4862d3ff0a7298b8411dd2f043ff", size = 16728251, upload-time = "2025-11-16T22:50:19.013Z" },
+ { url = "https://files.pythonhosted.org/packages/79/fb/f505c95ceddd7027347b067689db71ca80bd5ecc926f913f1a23e65cf09b/numpy-2.3.5-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:aa5bc7c5d59d831d9773d1170acac7893ce3a5e130540605770ade83280e7188", size = 12254652, upload-time = "2025-11-16T22:50:21.487Z" },
+ { url = "https://files.pythonhosted.org/packages/78/da/8c7738060ca9c31b30e9301ee0cf6c5ffdbf889d9593285a1cead337f9a5/numpy-2.3.5-cp313-cp313-macosx_14_0_arm64.whl", hash = "sha256:ccc933afd4d20aad3c00bcef049cb40049f7f196e0397f1109dba6fed63267b0", size = 5083172, upload-time = "2025-11-16T22:50:24.562Z" },
+ { url = "https://files.pythonhosted.org/packages/a4/b4/ee5bb2537fb9430fd2ef30a616c3672b991a4129bb1c7dcc42aa0abbe5d7/numpy-2.3.5-cp313-cp313-macosx_14_0_x86_64.whl", hash = "sha256:afaffc4393205524af9dfa400fa250143a6c3bc646c08c9f5e25a9f4b4d6a903", size = 6622990, upload-time = "2025-11-16T22:50:26.47Z" },
+ { url = "https://files.pythonhosted.org/packages/95/03/dc0723a013c7d7c19de5ef29e932c3081df1c14ba582b8b86b5de9db7f0f/numpy-2.3.5-cp313-cp313-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:9c75442b2209b8470d6d5d8b1c25714270686f14c749028d2199c54e29f20b4d", size = 14248902, upload-time = "2025-11-16T22:50:28.861Z" },
+ { url = "https://files.pythonhosted.org/packages/f5/10/ca162f45a102738958dcec8023062dad0cbc17d1ab99d68c4e4a6c45fb2b/numpy-2.3.5-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:11e06aa0af8c0f05104d56450d6093ee639e15f24ecf62d417329d06e522e017", size = 16597430, upload-time = "2025-11-16T22:50:31.56Z" },
+ { url = "https://files.pythonhosted.org/packages/2a/51/c1e29be863588db58175175f057286900b4b3327a1351e706d5e0f8dd679/numpy-2.3.5-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:ed89927b86296067b4f81f108a2271d8926467a8868e554eaf370fc27fa3ccaf", size = 16024551, upload-time = "2025-11-16T22:50:34.242Z" },
+ { url = "https://files.pythonhosted.org/packages/83/68/8236589d4dbb87253d28259d04d9b814ec0ecce7cb1c7fed29729f4c3a78/numpy-2.3.5-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:51c55fe3451421f3a6ef9a9c1439e82101c57a2c9eab9feb196a62b1a10b58ce", size = 18533275, upload-time = "2025-11-16T22:50:37.651Z" },
+ { url = "https://files.pythonhosted.org/packages/40/56/2932d75b6f13465239e3b7b7e511be27f1b8161ca2510854f0b6e521c395/numpy-2.3.5-cp313-cp313-win32.whl", hash = "sha256:1978155dd49972084bd6ef388d66ab70f0c323ddee6f693d539376498720fb7e", size = 6277637, upload-time = "2025-11-16T22:50:40.11Z" },
+ { url = "https://files.pythonhosted.org/packages/0c/88/e2eaa6cffb115b85ed7c7c87775cb8bcf0816816bc98ca8dbfa2ee33fe6e/numpy-2.3.5-cp313-cp313-win_amd64.whl", hash = "sha256:00dc4e846108a382c5869e77c6ed514394bdeb3403461d25a829711041217d5b", size = 12779090, upload-time = "2025-11-16T22:50:42.503Z" },
+ { url = "https://files.pythonhosted.org/packages/8f/88/3f41e13a44ebd4034ee17baa384acac29ba6a4fcc2aca95f6f08ca0447d1/numpy-2.3.5-cp313-cp313-win_arm64.whl", hash = "sha256:0472f11f6ec23a74a906a00b48a4dcf3849209696dff7c189714511268d103ae", size = 10194710, upload-time = "2025-11-16T22:50:44.971Z" },
+ { url = "https://files.pythonhosted.org/packages/13/cb/71744144e13389d577f867f745b7df2d8489463654a918eea2eeb166dfc9/numpy-2.3.5-cp313-cp313t-macosx_10_13_x86_64.whl", hash = "sha256:414802f3b97f3c1eef41e530aaba3b3c1620649871d8cb38c6eaff034c2e16bd", size = 16827292, upload-time = "2025-11-16T22:50:47.715Z" },
+ { url = "https://files.pythonhosted.org/packages/71/80/ba9dc6f2a4398e7f42b708a7fdc841bb638d353be255655498edbf9a15a8/numpy-2.3.5-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:5ee6609ac3604fa7780e30a03e5e241a7956f8e2fcfe547d51e3afa5247ac47f", size = 12378897, upload-time = "2025-11-16T22:50:51.327Z" },
+ { url = "https://files.pythonhosted.org/packages/2e/6d/db2151b9f64264bcceccd51741aa39b50150de9b602d98ecfe7e0c4bff39/numpy-2.3.5-cp313-cp313t-macosx_14_0_arm64.whl", hash = "sha256:86d835afea1eaa143012a2d7a3f45a3adce2d7adc8b4961f0b362214d800846a", size = 5207391, upload-time = "2025-11-16T22:50:54.542Z" },
+ { url = "https://files.pythonhosted.org/packages/80/ae/429bacace5ccad48a14c4ae5332f6aa8ab9f69524193511d60ccdfdc65fa/numpy-2.3.5-cp313-cp313t-macosx_14_0_x86_64.whl", hash = "sha256:30bc11310e8153ca664b14c5f1b73e94bd0503681fcf136a163de856f3a50139", size = 6721275, upload-time = "2025-11-16T22:50:56.794Z" },
+ { url = "https://files.pythonhosted.org/packages/74/5b/1919abf32d8722646a38cd527bc3771eb229a32724ee6ba340ead9b92249/numpy-2.3.5-cp313-cp313t-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:1062fde1dcf469571705945b0f221b73928f34a20c904ffb45db101907c3454e", size = 14306855, upload-time = "2025-11-16T22:50:59.208Z" },
+ { url = "https://files.pythonhosted.org/packages/a5/87/6831980559434973bebc30cd9c1f21e541a0f2b0c280d43d3afd909b66d0/numpy-2.3.5-cp313-cp313t-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:ce581db493ea1a96c0556360ede6607496e8bf9b3a8efa66e06477267bc831e9", size = 16657359, upload-time = "2025-11-16T22:51:01.991Z" },
+ { url = "https://files.pythonhosted.org/packages/dd/91/c797f544491ee99fd00495f12ebb7802c440c1915811d72ac5b4479a3356/numpy-2.3.5-cp313-cp313t-musllinux_1_2_aarch64.whl", hash = "sha256:cc8920d2ec5fa99875b670bb86ddeb21e295cb07aa331810d9e486e0b969d946", size = 16093374, upload-time = "2025-11-16T22:51:05.291Z" },
+ { url = "https://files.pythonhosted.org/packages/74/a6/54da03253afcbe7a72785ec4da9c69fb7a17710141ff9ac5fcb2e32dbe64/numpy-2.3.5-cp313-cp313t-musllinux_1_2_x86_64.whl", hash = "sha256:9ee2197ef8c4f0dfe405d835f3b6a14f5fee7782b5de51ba06fb65fc9b36e9f1", size = 18594587, upload-time = "2025-11-16T22:51:08.585Z" },
+ { url = "https://files.pythonhosted.org/packages/80/e9/aff53abbdd41b0ecca94285f325aff42357c6b5abc482a3fcb4994290b18/numpy-2.3.5-cp313-cp313t-win32.whl", hash = "sha256:70b37199913c1bd300ff6e2693316c6f869c7ee16378faf10e4f5e3275b299c3", size = 6405940, upload-time = "2025-11-16T22:51:11.541Z" },
+ { url = "https://files.pythonhosted.org/packages/d5/81/50613fec9d4de5480de18d4f8ef59ad7e344d497edbef3cfd80f24f98461/numpy-2.3.5-cp313-cp313t-win_amd64.whl", hash = "sha256:b501b5fa195cc9e24fe102f21ec0a44dffc231d2af79950b451e0d99cea02234", size = 12920341, upload-time = "2025-11-16T22:51:14.312Z" },
+ { url = "https://files.pythonhosted.org/packages/bb/ab/08fd63b9a74303947f34f0bd7c5903b9c5532c2d287bead5bdf4c556c486/numpy-2.3.5-cp313-cp313t-win_arm64.whl", hash = "sha256:a80afd79f45f3c4a7d341f13acbe058d1ca8ac017c165d3fa0d3de6bc1a079d7", size = 10262507, upload-time = "2025-11-16T22:51:16.846Z" },
+ { url = "https://files.pythonhosted.org/packages/ba/97/1a914559c19e32d6b2e233cf9a6a114e67c856d35b1d6babca571a3e880f/numpy-2.3.5-cp314-cp314-macosx_10_15_x86_64.whl", hash = "sha256:bf06bc2af43fa8d32d30fae16ad965663e966b1a3202ed407b84c989c3221e82", size = 16735706, upload-time = "2025-11-16T22:51:19.558Z" },
+ { url = "https://files.pythonhosted.org/packages/57/d4/51233b1c1b13ecd796311216ae417796b88b0616cfd8a33ae4536330748a/numpy-2.3.5-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:052e8c42e0c49d2575621c158934920524f6c5da05a1d3b9bab5d8e259e045f0", size = 12264507, upload-time = "2025-11-16T22:51:22.492Z" },
+ { url = "https://files.pythonhosted.org/packages/45/98/2fe46c5c2675b8306d0b4a3ec3494273e93e1226a490f766e84298576956/numpy-2.3.5-cp314-cp314-macosx_14_0_arm64.whl", hash = "sha256:1ed1ec893cff7040a02c8aa1c8611b94d395590d553f6b53629a4461dc7f7b63", size = 5093049, upload-time = "2025-11-16T22:51:25.171Z" },
+ { url = "https://files.pythonhosted.org/packages/ce/0e/0698378989bb0ac5f1660c81c78ab1fe5476c1a521ca9ee9d0710ce54099/numpy-2.3.5-cp314-cp314-macosx_14_0_x86_64.whl", hash = "sha256:2dcd0808a421a482a080f89859a18beb0b3d1e905b81e617a188bd80422d62e9", size = 6626603, upload-time = "2025-11-16T22:51:27Z" },
+ { url = "https://files.pythonhosted.org/packages/5e/a6/9ca0eecc489640615642a6cbc0ca9e10df70df38c4d43f5a928ff18d8827/numpy-2.3.5-cp314-cp314-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:727fd05b57df37dc0bcf1a27767a3d9a78cbbc92822445f32cc3436ba797337b", size = 14262696, upload-time = "2025-11-16T22:51:29.402Z" },
+ { url = "https://files.pythonhosted.org/packages/c8/f6/07ec185b90ec9d7217a00eeeed7383b73d7e709dae2a9a021b051542a708/numpy-2.3.5-cp314-cp314-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:fffe29a1ef00883599d1dc2c51aa2e5d80afe49523c261a74933df395c15c520", size = 16597350, upload-time = "2025-11-16T22:51:32.167Z" },
+ { url = "https://files.pythonhosted.org/packages/75/37/164071d1dde6a1a84c9b8e5b414fa127981bad47adf3a6b7e23917e52190/numpy-2.3.5-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:8f7f0e05112916223d3f438f293abf0727e1181b5983f413dfa2fefc4098245c", size = 16040190, upload-time = "2025-11-16T22:51:35.403Z" },
+ { url = "https://files.pythonhosted.org/packages/08/3c/f18b82a406b04859eb026d204e4e1773eb41c5be58410f41ffa511d114ae/numpy-2.3.5-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:2e2eb32ddb9ccb817d620ac1d8dae7c3f641c1e5f55f531a33e8ab97960a75b8", size = 18536749, upload-time = "2025-11-16T22:51:39.698Z" },
+ { url = "https://files.pythonhosted.org/packages/40/79/f82f572bf44cf0023a2fe8588768e23e1592585020d638999f15158609e1/numpy-2.3.5-cp314-cp314-win32.whl", hash = "sha256:66f85ce62c70b843bab1fb14a05d5737741e74e28c7b8b5a064de10142fad248", size = 6335432, upload-time = "2025-11-16T22:51:42.476Z" },
+ { url = "https://files.pythonhosted.org/packages/a3/2e/235b4d96619931192c91660805e5e49242389742a7a82c27665021db690c/numpy-2.3.5-cp314-cp314-win_amd64.whl", hash = "sha256:e6a0bc88393d65807d751a614207b7129a310ca4fe76a74e5c7da5fa5671417e", size = 12919388, upload-time = "2025-11-16T22:51:45.275Z" },
+ { url = "https://files.pythonhosted.org/packages/07/2b/29fd75ce45d22a39c61aad74f3d718e7ab67ccf839ca8b60866054eb15f8/numpy-2.3.5-cp314-cp314-win_arm64.whl", hash = "sha256:aeffcab3d4b43712bb7a60b65f6044d444e75e563ff6180af8f98dd4b905dfd2", size = 10476651, upload-time = "2025-11-16T22:51:47.749Z" },
+ { url = "https://files.pythonhosted.org/packages/17/e1/f6a721234ebd4d87084cfa68d081bcba2f5cfe1974f7de4e0e8b9b2a2ba1/numpy-2.3.5-cp314-cp314t-macosx_10_15_x86_64.whl", hash = "sha256:17531366a2e3a9e30762c000f2c43a9aaa05728712e25c11ce1dbe700c53ad41", size = 16834503, upload-time = "2025-11-16T22:51:50.443Z" },
+ { url = "https://files.pythonhosted.org/packages/5c/1c/baf7ffdc3af9c356e1c135e57ab7cf8d247931b9554f55c467efe2c69eff/numpy-2.3.5-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:d21644de1b609825ede2f48be98dfde4656aefc713654eeee280e37cadc4e0ad", size = 12381612, upload-time = "2025-11-16T22:51:53.609Z" },
+ { url = "https://files.pythonhosted.org/packages/74/91/f7f0295151407ddc9ba34e699013c32c3c91944f9b35fcf9281163dc1468/numpy-2.3.5-cp314-cp314t-macosx_14_0_arm64.whl", hash = "sha256:c804e3a5aba5460c73955c955bdbd5c08c354954e9270a2c1565f62e866bdc39", size = 5210042, upload-time = "2025-11-16T22:51:56.213Z" },
+ { url = "https://files.pythonhosted.org/packages/2e/3b/78aebf345104ec50dd50a4d06ddeb46a9ff5261c33bcc58b1c4f12f85ec2/numpy-2.3.5-cp314-cp314t-macosx_14_0_x86_64.whl", hash = "sha256:cc0a57f895b96ec78969c34f682c602bf8da1a0270b09bc65673df2e7638ec20", size = 6724502, upload-time = "2025-11-16T22:51:58.584Z" },
+ { url = "https://files.pythonhosted.org/packages/02/c6/7c34b528740512e57ef1b7c8337ab0b4f0bddf34c723b8996c675bc2bc91/numpy-2.3.5-cp314-cp314t-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:900218e456384ea676e24ea6a0417f030a3b07306d29d7ad843957b40a9d8d52", size = 14308962, upload-time = "2025-11-16T22:52:01.698Z" },
+ { url = "https://files.pythonhosted.org/packages/80/35/09d433c5262bc32d725bafc619e095b6a6651caf94027a03da624146f655/numpy-2.3.5-cp314-cp314t-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:09a1bea522b25109bf8e6f3027bd810f7c1085c64a0c7ce050c1676ad0ba010b", size = 16655054, upload-time = "2025-11-16T22:52:04.267Z" },
+ { url = "https://files.pythonhosted.org/packages/7a/ab/6a7b259703c09a88804fa2430b43d6457b692378f6b74b356155283566ac/numpy-2.3.5-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:04822c00b5fd0323c8166d66c701dc31b7fbd252c100acd708c48f763968d6a3", size = 16091613, upload-time = "2025-11-16T22:52:08.651Z" },
+ { url = "https://files.pythonhosted.org/packages/c2/88/330da2071e8771e60d1038166ff9d73f29da37b01ec3eb43cb1427464e10/numpy-2.3.5-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:d6889ec4ec662a1a37eb4b4fb26b6100841804dac55bd9df579e326cdc146227", size = 18591147, upload-time = "2025-11-16T22:52:11.453Z" },
+ { url = "https://files.pythonhosted.org/packages/51/41/851c4b4082402d9ea860c3626db5d5df47164a712cb23b54be028b184c1c/numpy-2.3.5-cp314-cp314t-win32.whl", hash = "sha256:93eebbcf1aafdf7e2ddd44c2923e2672e1010bddc014138b229e49725b4d6be5", size = 6479806, upload-time = "2025-11-16T22:52:14.641Z" },
+ { url = "https://files.pythonhosted.org/packages/90/30/d48bde1dfd93332fa557cff1972fbc039e055a52021fbef4c2c4b1eefd17/numpy-2.3.5-cp314-cp314t-win_amd64.whl", hash = "sha256:c8a9958e88b65c3b27e22ca2a076311636850b612d6bbfb76e8d156aacde2aaf", size = 13105760, upload-time = "2025-11-16T22:52:17.975Z" },
+ { url = "https://files.pythonhosted.org/packages/2d/fd/4b5eb0b3e888d86aee4d198c23acec7d214baaf17ea93c1adec94c9518b9/numpy-2.3.5-cp314-cp314t-win_arm64.whl", hash = "sha256:6203fdf9f3dc5bdaed7319ad8698e685c7a3be10819f41d32a0723e611733b42", size = 10545459, upload-time = "2025-11-16T22:52:20.55Z" },
+]
+
+[[package]]
+name = "nvidia-cublas-cu12"
+version = "12.8.4.1"
+source = { registry = "https://pypi.org/simple" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/dc/61/e24b560ab2e2eaeb3c839129175fb330dfcfc29e5203196e5541a4c44682/nvidia_cublas_cu12-12.8.4.1-py3-none-manylinux_2_27_x86_64.whl", hash = "sha256:8ac4e771d5a348c551b2a426eda6193c19aa630236b418086020df5ba9667142", size = 594346921, upload-time = "2025-03-07T01:44:31.254Z" },
+]
+
+[[package]]
+name = "nvidia-cuda-cupti-cu12"
+version = "12.8.90"
+source = { registry = "https://pypi.org/simple" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/f8/02/2adcaa145158bf1a8295d83591d22e4103dbfd821bcaf6f3f53151ca4ffa/nvidia_cuda_cupti_cu12-12.8.90-py3-none-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:ea0cb07ebda26bb9b29ba82cda34849e73c166c18162d3913575b0c9db9a6182", size = 10248621, upload-time = "2025-03-07T01:40:21.213Z" },
+]
+
+[[package]]
+name = "nvidia-cuda-nvrtc-cu12"
+version = "12.8.93"
+source = { registry = "https://pypi.org/simple" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/05/6b/32f747947df2da6994e999492ab306a903659555dddc0fbdeb9d71f75e52/nvidia_cuda_nvrtc_cu12-12.8.93-py3-none-manylinux2010_x86_64.manylinux_2_12_x86_64.whl", hash = "sha256:a7756528852ef889772a84c6cd89d41dfa74667e24cca16bb31f8f061e3e9994", size = 88040029, upload-time = "2025-03-07T01:42:13.562Z" },
+]
+
+[[package]]
+name = "nvidia-cuda-runtime-cu12"
+version = "12.8.90"
+source = { registry = "https://pypi.org/simple" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/0d/9b/a997b638fcd068ad6e4d53b8551a7d30fe8b404d6f1804abf1df69838932/nvidia_cuda_runtime_cu12-12.8.90-py3-none-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:adade8dcbd0edf427b7204d480d6066d33902cab2a4707dcfc48a2d0fd44ab90", size = 954765, upload-time = "2025-03-07T01:40:01.615Z" },
+]
+
+[[package]]
+name = "nvidia-cudnn-cu12"
+version = "9.10.2.21"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "nvidia-cublas-cu12", marker = "sys_platform == 'linux'" },
+]
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/ba/51/e123d997aa098c61d029f76663dedbfb9bc8dcf8c60cbd6adbe42f76d049/nvidia_cudnn_cu12-9.10.2.21-py3-none-manylinux_2_27_x86_64.whl", hash = "sha256:949452be657fa16687d0930933f032835951ef0892b37d2d53824d1a84dc97a8", size = 706758467, upload-time = "2025-06-06T21:54:08.597Z" },
+]
+
+[[package]]
+name = "nvidia-cufft-cu12"
+version = "11.3.3.83"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "nvidia-nvjitlink-cu12", marker = "sys_platform == 'linux'" },
+]
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/1f/13/ee4e00f30e676b66ae65b4f08cb5bcbb8392c03f54f2d5413ea99a5d1c80/nvidia_cufft_cu12-11.3.3.83-py3-none-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:4d2dd21ec0b88cf61b62e6b43564355e5222e4a3fb394cac0db101f2dd0d4f74", size = 193118695, upload-time = "2025-03-07T01:45:27.821Z" },
+]
+
+[[package]]
+name = "nvidia-cufile-cu12"
+version = "1.13.1.3"
+source = { registry = "https://pypi.org/simple" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/bb/fe/1bcba1dfbfb8d01be8d93f07bfc502c93fa23afa6fd5ab3fc7c1df71038a/nvidia_cufile_cu12-1.13.1.3-py3-none-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:1d069003be650e131b21c932ec3d8969c1715379251f8d23a1860554b1cb24fc", size = 1197834, upload-time = "2025-03-07T01:45:50.723Z" },
+]
+
+[[package]]
+name = "nvidia-curand-cu12"
+version = "10.3.9.90"
+source = { registry = "https://pypi.org/simple" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/fb/aa/6584b56dc84ebe9cf93226a5cde4d99080c8e90ab40f0c27bda7a0f29aa1/nvidia_curand_cu12-10.3.9.90-py3-none-manylinux_2_27_x86_64.whl", hash = "sha256:b32331d4f4df5d6eefa0554c565b626c7216f87a06a4f56fab27c3b68a830ec9", size = 63619976, upload-time = "2025-03-07T01:46:23.323Z" },
+]
+
+[[package]]
+name = "nvidia-cusolver-cu12"
+version = "11.7.3.90"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "nvidia-cublas-cu12", marker = "sys_platform == 'linux'" },
+ { name = "nvidia-cusparse-cu12", marker = "sys_platform == 'linux'" },
+ { name = "nvidia-nvjitlink-cu12", marker = "sys_platform == 'linux'" },
+]
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/85/48/9a13d2975803e8cf2777d5ed57b87a0b6ca2cc795f9a4f59796a910bfb80/nvidia_cusolver_cu12-11.7.3.90-py3-none-manylinux_2_27_x86_64.whl", hash = "sha256:4376c11ad263152bd50ea295c05370360776f8c3427b30991df774f9fb26c450", size = 267506905, upload-time = "2025-03-07T01:47:16.273Z" },
+]
+
+[[package]]
+name = "nvidia-cusparse-cu12"
+version = "12.5.8.93"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "nvidia-nvjitlink-cu12", marker = "sys_platform == 'linux'" },
+]
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/c2/f5/e1854cb2f2bcd4280c44736c93550cc300ff4b8c95ebe370d0aa7d2b473d/nvidia_cusparse_cu12-12.5.8.93-py3-none-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:1ec05d76bbbd8b61b06a80e1eaf8cf4959c3d4ce8e711b65ebd0443bb0ebb13b", size = 288216466, upload-time = "2025-03-07T01:48:13.779Z" },
+]
+
+[[package]]
+name = "nvidia-cusparselt-cu12"
+version = "0.7.1"
+source = { registry = "https://pypi.org/simple" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/56/79/12978b96bd44274fe38b5dde5cfb660b1d114f70a65ef962bcbbed99b549/nvidia_cusparselt_cu12-0.7.1-py3-none-manylinux2014_x86_64.whl", hash = "sha256:f1bb701d6b930d5a7cea44c19ceb973311500847f81b634d802b7b539dc55623", size = 287193691, upload-time = "2025-02-26T00:15:44.104Z" },
+]
+
+[[package]]
+name = "nvidia-nccl-cu12"
+version = "2.27.5"
+source = { registry = "https://pypi.org/simple" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/6e/89/f7a07dc961b60645dbbf42e80f2bc85ade7feb9a491b11a1e973aa00071f/nvidia_nccl_cu12-2.27.5-py3-none-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:ad730cf15cb5d25fe849c6e6ca9eb5b76db16a80f13f425ac68d8e2e55624457", size = 322348229, upload-time = "2025-06-26T04:11:28.385Z" },
+]
+
+[[package]]
+name = "nvidia-nvjitlink-cu12"
+version = "12.8.93"
+source = { registry = "https://pypi.org/simple" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/f6/74/86a07f1d0f42998ca31312f998bd3b9a7eff7f52378f4f270c8679c77fb9/nvidia_nvjitlink_cu12-12.8.93-py3-none-manylinux2010_x86_64.manylinux_2_12_x86_64.whl", hash = "sha256:81ff63371a7ebd6e6451970684f916be2eab07321b73c9d244dc2b4da7f73b88", size = 39254836, upload-time = "2025-03-07T01:49:55.661Z" },
+]
+
+[[package]]
+name = "nvidia-nvshmem-cu12"
+version = "3.3.20"
+source = { registry = "https://pypi.org/simple" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/3b/6c/99acb2f9eb85c29fc6f3a7ac4dccfd992e22666dd08a642b303311326a97/nvidia_nvshmem_cu12-3.3.20-py3-none-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:d00f26d3f9b2e3c3065be895e3059d6479ea5c638a3f38c9fec49b1b9dd7c1e5", size = 124657145, upload-time = "2025-08-04T20:25:19.995Z" },
+]
+
+[[package]]
+name = "nvidia-nvtx-cu12"
+version = "12.8.90"
+source = { registry = "https://pypi.org/simple" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/a2/eb/86626c1bbc2edb86323022371c39aa48df6fd8b0a1647bc274577f72e90b/nvidia_nvtx_cu12-12.8.90-py3-none-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:5b17e2001cc0d751a5bc2c6ec6d26ad95913324a4adb86788c944f8ce9ba441f", size = 89954, upload-time = "2025-03-07T01:42:44.131Z" },
+]
+
+[[package]]
+name = "open-clip-torch"
+version = "3.2.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "ftfy" },
+ { name = "huggingface-hub" },
+ { name = "regex" },
+ { name = "safetensors" },
+ { name = "timm" },
+ { name = "torch" },
+ { name = "torchvision" },
+ { name = "tqdm" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/30/46/fb8be250fa7fcfc56fbeb41583645e18d868268f67fbbbeb8ed62a8ff18a/open_clip_torch-3.2.0.tar.gz", hash = "sha256:62b7743012ccc40fb7c64819fa762fba0a13dd74585ac733babe58c2974c2506", size = 1502853, upload-time = "2025-09-21T17:32:08.289Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/94/91/397327cc1597fa317942cc15bef414175eee4b3c2263b34407c57f3521f9/open_clip_torch-3.2.0-py3-none-any.whl", hash = "sha256:e1f5b3ecbadb6d8ea64b1f887db23efee9739e7c0d0075a8a2a3cabae8fed8d1", size = 1546677, upload-time = "2025-09-21T17:32:06.269Z" },
+]
+
+[[package]]
+name = "open-flamingo"
+version = "0.0.2"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "braceexpand" },
+ { name = "datasets" },
+ { name = "einops" },
+ { name = "einops-exts" },
+ { name = "inflection" },
+ { name = "more-itertools" },
+ { name = "nltk" },
+ { name = "open-clip-torch" },
+ { name = "pillow" },
+ { name = "scipy" },
+ { name = "sentencepiece" },
+ { name = "torch" },
+ { name = "torchvision" },
+ { name = "transformers" },
+ { name = "wandb" },
+ { name = "webdataset" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/33/85/4d67a8e21fd6e5268a65e3be8d456c1d20b838d9af53d3712e4a277752b8/open_flamingo-0.0.2.tar.gz", hash = "sha256:bf211a6901fb624faa1bc449ee5d49fb66ef798fc74a7c3a8d0931355904d826", size = 52873, upload-time = "2023-03-29T22:51:29.56Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/10/97/a4caf7e1f6887d91268ca97de2f81cd09dee99ae430830c90ba778739ee3/open_flamingo-0.0.2-py3-none-any.whl", hash = "sha256:9827197142828599458f95d8f46f48ba8732a986b2e3af5fe302e9c6741a8f32", size = 57515, upload-time = "2023-03-29T22:51:27.282Z" },
+]
+
+[[package]]
+name = "openai"
+version = "2.9.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "anyio" },
+ { name = "distro" },
+ { name = "httpx" },
+ { name = "jiter" },
+ { name = "pydantic" },
+ { name = "sniffio" },
+ { name = "tqdm" },
+ { name = "typing-extensions" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/09/48/516290f38745cc1e72856f50e8afed4a7f9ac396a5a18f39e892ab89dfc2/openai-2.9.0.tar.gz", hash = "sha256:b52ec65727fc8f1eed2fbc86c8eac0998900c7ef63aa2eb5c24b69717c56fa5f", size = 608202, upload-time = "2025-12-04T18:15:09.01Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/59/fd/ae2da789cd923dd033c99b8d544071a827c92046b150db01cfa5cea5b3fd/openai-2.9.0-py3-none-any.whl", hash = "sha256:0d168a490fbb45630ad508a6f3022013c155a68fd708069b6a1a01a5e8f0ffad", size = 1030836, upload-time = "2025-12-04T18:15:07.063Z" },
+]
+
+[[package]]
+name = "opentslm"
+version = "0.1.0"
+source = { editable = "." }
+dependencies = [
+ { name = "datasets" },
+ { name = "einops" },
+ { name = "huggingface-hub" },
+ { name = "matplotlib" },
+ { name = "numpy" },
+ { name = "open-flamingo" },
+ { name = "pandas" },
+ { name = "peft" },
+ { name = "requests" },
+ { name = "scikit-learn" },
+ { name = "torch" },
+ { name = "tqdm" },
+ { name = "transformers" },
+ { name = "wfdb" },
+]
+
+[package.dev-dependencies]
+dev = [
+ { name = "reuse" },
+ { name = "ruff" },
+]
+eval = [
+ { name = "openai" },
+]
+notebook = [
+ { name = "ipython" },
+ { name = "jupyter" },
+ { name = "seaborn" },
+]
+
+[package.metadata]
+requires-dist = [
+ { name = "datasets", specifier = ">=2.0" },
+ { name = "einops", specifier = ">=0.6" },
+ { name = "huggingface-hub", specifier = ">=0.16" },
+ { name = "matplotlib", specifier = ">=3.3" },
+ { name = "numpy", specifier = ">=1.21" },
+ { name = "open-flamingo", specifier = ">=0.0.2" },
+ { name = "pandas", specifier = ">=1.3" },
+ { name = "peft", specifier = ">=0.4" },
+ { name = "requests", specifier = ">=2.28" },
+ { name = "scikit-learn", specifier = ">=1.0" },
+ { name = "torch", specifier = ">=2.0" },
+ { name = "tqdm", specifier = ">=4.62" },
+ { name = "transformers", specifier = ">=4.25" },
+ { name = "wfdb", specifier = ">=4.0" },
+]
+
+[package.metadata.requires-dev]
+dev = [
+ { name = "reuse", specifier = ">=6.2.0" },
+ { name = "ruff", specifier = ">=0.14.0" },
+]
+eval = [{ name = "openai", specifier = ">=1.0" }]
+notebook = [
+ { name = "ipython", specifier = ">=8.0" },
+ { name = "jupyter", specifier = ">=1.0" },
+ { name = "seaborn", specifier = ">=0.13.2" },
+]
+
+[[package]]
+name = "packaging"
+version = "25.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/a1/d4/1fc4078c65507b51b96ca8f8c3ba19e6a61c8253c72794544580a7b6c24d/packaging-25.0.tar.gz", hash = "sha256:d443872c98d677bf60f6a1f2f8c1cb748e8fe762d2bf9d3148b5599295b0fc4f", size = 165727, upload-time = "2025-04-19T11:48:59.673Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/20/12/38679034af332785aac8774540895e234f4d07f7545804097de4b666afd8/packaging-25.0-py3-none-any.whl", hash = "sha256:29572ef2b1f17581046b3a2227d5c611fb25ec70ca1ba8554b24b0e69331a484", size = 66469, upload-time = "2025-04-19T11:48:57.875Z" },
+]
+
+[[package]]
+name = "pandas"
+version = "2.3.3"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "numpy" },
+ { name = "python-dateutil" },
+ { name = "pytz" },
+ { name = "tzdata" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/33/01/d40b85317f86cf08d853a4f495195c73815fdf205eef3993821720274518/pandas-2.3.3.tar.gz", hash = "sha256:e05e1af93b977f7eafa636d043f9f94c7ee3ac81af99c13508215942e64c993b", size = 4495223, upload-time = "2025-09-29T23:34:51.853Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/9c/fb/231d89e8637c808b997d172b18e9d4a4bc7bf31296196c260526055d1ea0/pandas-2.3.3-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:6d21f6d74eb1725c2efaa71a2bfc661a0689579b58e9c0ca58a739ff0b002b53", size = 11597846, upload-time = "2025-09-29T23:19:48.856Z" },
+ { url = "https://files.pythonhosted.org/packages/5c/bd/bf8064d9cfa214294356c2d6702b716d3cf3bb24be59287a6a21e24cae6b/pandas-2.3.3-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:3fd2f887589c7aa868e02632612ba39acb0b8948faf5cc58f0850e165bd46f35", size = 10729618, upload-time = "2025-09-29T23:39:08.659Z" },
+ { url = "https://files.pythonhosted.org/packages/57/56/cf2dbe1a3f5271370669475ead12ce77c61726ffd19a35546e31aa8edf4e/pandas-2.3.3-cp312-cp312-manylinux_2_24_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:ecaf1e12bdc03c86ad4a7ea848d66c685cb6851d807a26aa245ca3d2017a1908", size = 11737212, upload-time = "2025-09-29T23:19:59.765Z" },
+ { url = "https://files.pythonhosted.org/packages/e5/63/cd7d615331b328e287d8233ba9fdf191a9c2d11b6af0c7a59cfcec23de68/pandas-2.3.3-cp312-cp312-manylinux_2_24_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:b3d11d2fda7eb164ef27ffc14b4fcab16a80e1ce67e9f57e19ec0afaf715ba89", size = 12362693, upload-time = "2025-09-29T23:20:14.098Z" },
+ { url = "https://files.pythonhosted.org/packages/a6/de/8b1895b107277d52f2b42d3a6806e69cfef0d5cf1d0ba343470b9d8e0a04/pandas-2.3.3-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:a68e15f780eddf2b07d242e17a04aa187a7ee12b40b930bfdd78070556550e98", size = 12771002, upload-time = "2025-09-29T23:20:26.76Z" },
+ { url = "https://files.pythonhosted.org/packages/87/21/84072af3187a677c5893b170ba2c8fbe450a6ff911234916da889b698220/pandas-2.3.3-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:371a4ab48e950033bcf52b6527eccb564f52dc826c02afd9a1bc0ab731bba084", size = 13450971, upload-time = "2025-09-29T23:20:41.344Z" },
+ { url = "https://files.pythonhosted.org/packages/86/41/585a168330ff063014880a80d744219dbf1dd7a1c706e75ab3425a987384/pandas-2.3.3-cp312-cp312-win_amd64.whl", hash = "sha256:a16dcec078a01eeef8ee61bf64074b4e524a2a3f4b3be9326420cabe59c4778b", size = 10992722, upload-time = "2025-09-29T23:20:54.139Z" },
+ { url = "https://files.pythonhosted.org/packages/cd/4b/18b035ee18f97c1040d94debd8f2e737000ad70ccc8f5513f4eefad75f4b/pandas-2.3.3-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:56851a737e3470de7fa88e6131f41281ed440d29a9268dcbf0002da5ac366713", size = 11544671, upload-time = "2025-09-29T23:21:05.024Z" },
+ { url = "https://files.pythonhosted.org/packages/31/94/72fac03573102779920099bcac1c3b05975c2cb5f01eac609faf34bed1ca/pandas-2.3.3-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:bdcd9d1167f4885211e401b3036c0c8d9e274eee67ea8d0758a256d60704cfe8", size = 10680807, upload-time = "2025-09-29T23:21:15.979Z" },
+ { url = "https://files.pythonhosted.org/packages/16/87/9472cf4a487d848476865321de18cc8c920b8cab98453ab79dbbc98db63a/pandas-2.3.3-cp313-cp313-manylinux_2_24_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:e32e7cc9af0f1cc15548288a51a3b681cc2a219faa838e995f7dc53dbab1062d", size = 11709872, upload-time = "2025-09-29T23:21:27.165Z" },
+ { url = "https://files.pythonhosted.org/packages/15/07/284f757f63f8a8d69ed4472bfd85122bd086e637bf4ed09de572d575a693/pandas-2.3.3-cp313-cp313-manylinux_2_24_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:318d77e0e42a628c04dc56bcef4b40de67918f7041c2b061af1da41dcff670ac", size = 12306371, upload-time = "2025-09-29T23:21:40.532Z" },
+ { url = "https://files.pythonhosted.org/packages/33/81/a3afc88fca4aa925804a27d2676d22dcd2031c2ebe08aabd0ae55b9ff282/pandas-2.3.3-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:4e0a175408804d566144e170d0476b15d78458795bb18f1304fb94160cabf40c", size = 12765333, upload-time = "2025-09-29T23:21:55.77Z" },
+ { url = "https://files.pythonhosted.org/packages/8d/0f/b4d4ae743a83742f1153464cf1a8ecfafc3ac59722a0b5c8602310cb7158/pandas-2.3.3-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:93c2d9ab0fc11822b5eece72ec9587e172f63cff87c00b062f6e37448ced4493", size = 13418120, upload-time = "2025-09-29T23:22:10.109Z" },
+ { url = "https://files.pythonhosted.org/packages/4f/c7/e54682c96a895d0c808453269e0b5928a07a127a15704fedb643e9b0a4c8/pandas-2.3.3-cp313-cp313-win_amd64.whl", hash = "sha256:f8bfc0e12dc78f777f323f55c58649591b2cd0c43534e8355c51d3fede5f4dee", size = 10993991, upload-time = "2025-09-29T23:25:04.889Z" },
+ { url = "https://files.pythonhosted.org/packages/f9/ca/3f8d4f49740799189e1395812f3bf23b5e8fc7c190827d55a610da72ce55/pandas-2.3.3-cp313-cp313t-macosx_10_13_x86_64.whl", hash = "sha256:75ea25f9529fdec2d2e93a42c523962261e567d250b0013b16210e1d40d7c2e5", size = 12048227, upload-time = "2025-09-29T23:22:24.343Z" },
+ { url = "https://files.pythonhosted.org/packages/0e/5a/f43efec3e8c0cc92c4663ccad372dbdff72b60bdb56b2749f04aa1d07d7e/pandas-2.3.3-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:74ecdf1d301e812db96a465a525952f4dde225fdb6d8e5a521d47e1f42041e21", size = 11411056, upload-time = "2025-09-29T23:22:37.762Z" },
+ { url = "https://files.pythonhosted.org/packages/46/b1/85331edfc591208c9d1a63a06baa67b21d332e63b7a591a5ba42a10bb507/pandas-2.3.3-cp313-cp313t-manylinux_2_24_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:6435cb949cb34ec11cc9860246ccb2fdc9ecd742c12d3304989017d53f039a78", size = 11645189, upload-time = "2025-09-29T23:22:51.688Z" },
+ { url = "https://files.pythonhosted.org/packages/44/23/78d645adc35d94d1ac4f2a3c4112ab6f5b8999f4898b8cdf01252f8df4a9/pandas-2.3.3-cp313-cp313t-manylinux_2_24_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:900f47d8f20860de523a1ac881c4c36d65efcb2eb850e6948140fa781736e110", size = 12121912, upload-time = "2025-09-29T23:23:05.042Z" },
+ { url = "https://files.pythonhosted.org/packages/53/da/d10013df5e6aaef6b425aa0c32e1fc1f3e431e4bcabd420517dceadce354/pandas-2.3.3-cp313-cp313t-musllinux_1_2_aarch64.whl", hash = "sha256:a45c765238e2ed7d7c608fc5bc4a6f88b642f2f01e70c0c23d2224dd21829d86", size = 12712160, upload-time = "2025-09-29T23:23:28.57Z" },
+ { url = "https://files.pythonhosted.org/packages/bd/17/e756653095a083d8a37cbd816cb87148debcfcd920129b25f99dd8d04271/pandas-2.3.3-cp313-cp313t-musllinux_1_2_x86_64.whl", hash = "sha256:c4fc4c21971a1a9f4bdb4c73978c7f7256caa3e62b323f70d6cb80db583350bc", size = 13199233, upload-time = "2025-09-29T23:24:24.876Z" },
+ { url = "https://files.pythonhosted.org/packages/04/fd/74903979833db8390b73b3a8a7d30d146d710bd32703724dd9083950386f/pandas-2.3.3-cp314-cp314-macosx_10_13_x86_64.whl", hash = "sha256:ee15f284898e7b246df8087fc82b87b01686f98ee67d85a17b7ab44143a3a9a0", size = 11540635, upload-time = "2025-09-29T23:25:52.486Z" },
+ { url = "https://files.pythonhosted.org/packages/21/00/266d6b357ad5e6d3ad55093a7e8efc7dd245f5a842b584db9f30b0f0a287/pandas-2.3.3-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:1611aedd912e1ff81ff41c745822980c49ce4a7907537be8692c8dbc31924593", size = 10759079, upload-time = "2025-09-29T23:26:33.204Z" },
+ { url = "https://files.pythonhosted.org/packages/ca/05/d01ef80a7a3a12b2f8bbf16daba1e17c98a2f039cbc8e2f77a2c5a63d382/pandas-2.3.3-cp314-cp314-manylinux_2_24_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:6d2cefc361461662ac48810cb14365a365ce864afe85ef1f447ff5a1e99ea81c", size = 11814049, upload-time = "2025-09-29T23:27:15.384Z" },
+ { url = "https://files.pythonhosted.org/packages/15/b2/0e62f78c0c5ba7e3d2c5945a82456f4fac76c480940f805e0b97fcbc2f65/pandas-2.3.3-cp314-cp314-manylinux_2_24_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:ee67acbbf05014ea6c763beb097e03cd629961c8a632075eeb34247120abcb4b", size = 12332638, upload-time = "2025-09-29T23:27:51.625Z" },
+ { url = "https://files.pythonhosted.org/packages/c5/33/dd70400631b62b9b29c3c93d2feee1d0964dc2bae2e5ad7a6c73a7f25325/pandas-2.3.3-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:c46467899aaa4da076d5abc11084634e2d197e9460643dd455ac3db5856b24d6", size = 12886834, upload-time = "2025-09-29T23:28:21.289Z" },
+ { url = "https://files.pythonhosted.org/packages/d3/18/b5d48f55821228d0d2692b34fd5034bb185e854bdb592e9c640f6290e012/pandas-2.3.3-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:6253c72c6a1d990a410bc7de641d34053364ef8bcd3126f7e7450125887dffe3", size = 13409925, upload-time = "2025-09-29T23:28:58.261Z" },
+ { url = "https://files.pythonhosted.org/packages/a6/3d/124ac75fcd0ecc09b8fdccb0246ef65e35b012030defb0e0eba2cbbbe948/pandas-2.3.3-cp314-cp314-win_amd64.whl", hash = "sha256:1b07204a219b3b7350abaae088f451860223a52cfb8a6c53358e7948735158e5", size = 11109071, upload-time = "2025-09-29T23:32:27.484Z" },
+ { url = "https://files.pythonhosted.org/packages/89/9c/0e21c895c38a157e0faa1fb64587a9226d6dd46452cac4532d80c3c4a244/pandas-2.3.3-cp314-cp314t-macosx_10_13_x86_64.whl", hash = "sha256:2462b1a365b6109d275250baaae7b760fd25c726aaca0054649286bcfbb3e8ec", size = 12048504, upload-time = "2025-09-29T23:29:31.47Z" },
+ { url = "https://files.pythonhosted.org/packages/d7/82/b69a1c95df796858777b68fbe6a81d37443a33319761d7c652ce77797475/pandas-2.3.3-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:0242fe9a49aa8b4d78a4fa03acb397a58833ef6199e9aa40a95f027bb3a1b6e7", size = 11410702, upload-time = "2025-09-29T23:29:54.591Z" },
+ { url = "https://files.pythonhosted.org/packages/f9/88/702bde3ba0a94b8c73a0181e05144b10f13f29ebfc2150c3a79062a8195d/pandas-2.3.3-cp314-cp314t-manylinux_2_24_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:a21d830e78df0a515db2b3d2f5570610f5e6bd2e27749770e8bb7b524b89b450", size = 11634535, upload-time = "2025-09-29T23:30:21.003Z" },
+ { url = "https://files.pythonhosted.org/packages/a4/1e/1bac1a839d12e6a82ec6cb40cda2edde64a2013a66963293696bbf31fbbb/pandas-2.3.3-cp314-cp314t-manylinux_2_24_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:2e3ebdb170b5ef78f19bfb71b0dc5dc58775032361fa188e814959b74d726dd5", size = 12121582, upload-time = "2025-09-29T23:30:43.391Z" },
+ { url = "https://files.pythonhosted.org/packages/44/91/483de934193e12a3b1d6ae7c8645d083ff88dec75f46e827562f1e4b4da6/pandas-2.3.3-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:d051c0e065b94b7a3cea50eb1ec32e912cd96dba41647eb24104b6c6c14c5788", size = 12699963, upload-time = "2025-09-29T23:31:10.009Z" },
+ { url = "https://files.pythonhosted.org/packages/70/44/5191d2e4026f86a2a109053e194d3ba7a31a2d10a9c2348368c63ed4e85a/pandas-2.3.3-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:3869faf4bd07b3b66a9f462417d0ca3a9df29a9f6abd5d0d0dbab15dac7abe87", size = 13202175, upload-time = "2025-09-29T23:31:59.173Z" },
+]
+
+[[package]]
+name = "pandocfilters"
+version = "1.5.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/70/6f/3dd4940bbe001c06a65f88e36bad298bc7a0de5036115639926b0c5c0458/pandocfilters-1.5.1.tar.gz", hash = "sha256:002b4a555ee4ebc03f8b66307e287fa492e4a77b4ea14d3f934328297bb4939e", size = 8454, upload-time = "2024-01-18T20:08:13.726Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/ef/af/4fbc8cab944db5d21b7e2a5b8e9211a03a79852b1157e2c102fcc61ac440/pandocfilters-1.5.1-py2.py3-none-any.whl", hash = "sha256:93be382804a9cdb0a7267585f157e5d1731bbe5545a85b268d6f5fe6232de2bc", size = 8663, upload-time = "2024-01-18T20:08:11.28Z" },
+]
+
+[[package]]
+name = "parso"
+version = "0.8.5"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/d4/de/53e0bcf53d13e005bd8c92e7855142494f41171b34c2536b86187474184d/parso-0.8.5.tar.gz", hash = "sha256:034d7354a9a018bdce352f48b2a8a450f05e9d6ee85db84764e9b6bd96dafe5a", size = 401205, upload-time = "2025-08-23T15:15:28.028Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/16/32/f8e3c85d1d5250232a5d3477a2a28cc291968ff175caeadaf3cc19ce0e4a/parso-0.8.5-py2.py3-none-any.whl", hash = "sha256:646204b5ee239c396d040b90f9e272e9a8017c630092bf59980beb62fd033887", size = 106668, upload-time = "2025-08-23T15:15:25.663Z" },
+]
+
+[[package]]
+name = "peft"
+version = "0.18.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "accelerate" },
+ { name = "huggingface-hub" },
+ { name = "numpy" },
+ { name = "packaging" },
+ { name = "psutil" },
+ { name = "pyyaml" },
+ { name = "safetensors" },
+ { name = "torch" },
+ { name = "tqdm" },
+ { name = "transformers" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/4b/0c/f2938db546ac7fc961ab5917cd50fcf5d0d70b406de93e3faccaa504e152/peft-0.18.0.tar.gz", hash = "sha256:c81c80b2056ab40c23d58ef25f74daab417ac653970718589a11a8af28218588", size = 634141, upload-time = "2025-11-13T11:13:06.603Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/0f/55/481bf25613d40ef53534f664deba7b138fe566356b6ca10304e2b3b2529c/peft-0.18.0-py3-none-any.whl", hash = "sha256:624f69ca6393b765ccc6734adda7ca57d80b238f0900a42c357d8b67a03d62ff", size = 556427, upload-time = "2025-11-13T11:13:03.664Z" },
+]
+
+[[package]]
+name = "pexpect"
+version = "4.9.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "ptyprocess" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/42/92/cc564bf6381ff43ce1f4d06852fc19a2f11d180f23dc32d9588bee2f149d/pexpect-4.9.0.tar.gz", hash = "sha256:ee7d41123f3c9911050ea2c2dac107568dc43b2d3b0c7557a33212c398ead30f", size = 166450, upload-time = "2023-11-25T09:07:26.339Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/9e/c3/059298687310d527a58bb01f3b1965787ee3b40dce76752eda8b44e9a2c5/pexpect-4.9.0-py2.py3-none-any.whl", hash = "sha256:7236d1e080e4936be2dc3e326cec0af72acf9212a7e1d060210e70a47e253523", size = 63772, upload-time = "2023-11-25T06:56:14.81Z" },
+]
+
+[[package]]
+name = "pillow"
+version = "12.0.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/5a/b0/cace85a1b0c9775a9f8f5d5423c8261c858760e2466c79b2dd184638b056/pillow-12.0.0.tar.gz", hash = "sha256:87d4f8125c9988bfbed67af47dd7a953e2fc7b0cc1e7800ec6d2080d490bb353", size = 47008828, upload-time = "2025-10-15T18:24:14.008Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/2c/90/4fcce2c22caf044e660a198d740e7fbc14395619e3cb1abad12192c0826c/pillow-12.0.0-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:53561a4ddc36facb432fae7a9d8afbfaf94795414f5cdc5fc52f28c1dca90371", size = 5249377, upload-time = "2025-10-15T18:22:05.993Z" },
+ { url = "https://files.pythonhosted.org/packages/fd/e0/ed960067543d080691d47d6938ebccbf3976a931c9567ab2fbfab983a5dd/pillow-12.0.0-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:71db6b4c1653045dacc1585c1b0d184004f0d7e694c7b34ac165ca70c0838082", size = 4650343, upload-time = "2025-10-15T18:22:07.718Z" },
+ { url = "https://files.pythonhosted.org/packages/e7/a1/f81fdeddcb99c044bf7d6faa47e12850f13cee0849537a7d27eeab5534d4/pillow-12.0.0-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.whl", hash = "sha256:2fa5f0b6716fc88f11380b88b31fe591a06c6315e955c096c35715788b339e3f", size = 6232981, upload-time = "2025-10-15T18:22:09.287Z" },
+ { url = "https://files.pythonhosted.org/packages/88/e1/9098d3ce341a8750b55b0e00c03f1630d6178f38ac191c81c97a3b047b44/pillow-12.0.0-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:82240051c6ca513c616f7f9da06e871f61bfd7805f566275841af15015b8f98d", size = 8041399, upload-time = "2025-10-15T18:22:10.872Z" },
+ { url = "https://files.pythonhosted.org/packages/a7/62/a22e8d3b602ae8cc01446d0c57a54e982737f44b6f2e1e019a925143771d/pillow-12.0.0-cp312-cp312-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:55f818bd74fe2f11d4d7cbc65880a843c4075e0ac7226bc1a23261dbea531953", size = 6347740, upload-time = "2025-10-15T18:22:12.769Z" },
+ { url = "https://files.pythonhosted.org/packages/4f/87/424511bdcd02c8d7acf9f65caa09f291a519b16bd83c3fb3374b3d4ae951/pillow-12.0.0-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:b87843e225e74576437fd5b6a4c2205d422754f84a06942cfaf1dc32243e45a8", size = 7040201, upload-time = "2025-10-15T18:22:14.813Z" },
+ { url = "https://files.pythonhosted.org/packages/dc/4d/435c8ac688c54d11755aedfdd9f29c9eeddf68d150fe42d1d3dbd2365149/pillow-12.0.0-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:c607c90ba67533e1b2355b821fef6764d1dd2cbe26b8c1005ae84f7aea25ff79", size = 6462334, upload-time = "2025-10-15T18:22:16.375Z" },
+ { url = "https://files.pythonhosted.org/packages/2b/f2/ad34167a8059a59b8ad10bc5c72d4d9b35acc6b7c0877af8ac885b5f2044/pillow-12.0.0-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:21f241bdd5080a15bc86d3466a9f6074a9c2c2b314100dd896ac81ee6db2f1ba", size = 7134162, upload-time = "2025-10-15T18:22:17.996Z" },
+ { url = "https://files.pythonhosted.org/packages/0c/b1/a7391df6adacf0a5c2cf6ac1cf1fcc1369e7d439d28f637a847f8803beb3/pillow-12.0.0-cp312-cp312-win32.whl", hash = "sha256:dd333073e0cacdc3089525c7df7d39b211bcdf31fc2824e49d01c6b6187b07d0", size = 6298769, upload-time = "2025-10-15T18:22:19.923Z" },
+ { url = "https://files.pythonhosted.org/packages/a2/0b/d87733741526541c909bbf159e338dcace4f982daac6e5a8d6be225ca32d/pillow-12.0.0-cp312-cp312-win_amd64.whl", hash = "sha256:9fe611163f6303d1619bbcb653540a4d60f9e55e622d60a3108be0d5b441017a", size = 7001107, upload-time = "2025-10-15T18:22:21.644Z" },
+ { url = "https://files.pythonhosted.org/packages/bc/96/aaa61ce33cc98421fb6088af2a03be4157b1e7e0e87087c888e2370a7f45/pillow-12.0.0-cp312-cp312-win_arm64.whl", hash = "sha256:7dfb439562f234f7d57b1ac6bc8fe7f838a4bd49c79230e0f6a1da93e82f1fad", size = 2436012, upload-time = "2025-10-15T18:22:23.621Z" },
+ { url = "https://files.pythonhosted.org/packages/62/f2/de993bb2d21b33a98d031ecf6a978e4b61da207bef02f7b43093774c480d/pillow-12.0.0-cp313-cp313-ios_13_0_arm64_iphoneos.whl", hash = "sha256:0869154a2d0546545cde61d1789a6524319fc1897d9ee31218eae7a60ccc5643", size = 4045493, upload-time = "2025-10-15T18:22:25.758Z" },
+ { url = "https://files.pythonhosted.org/packages/0e/b6/bc8d0c4c9f6f111a783d045310945deb769b806d7574764234ffd50bc5ea/pillow-12.0.0-cp313-cp313-ios_13_0_arm64_iphonesimulator.whl", hash = "sha256:a7921c5a6d31b3d756ec980f2f47c0cfdbce0fc48c22a39347a895f41f4a6ea4", size = 4120461, upload-time = "2025-10-15T18:22:27.286Z" },
+ { url = "https://files.pythonhosted.org/packages/5d/57/d60d343709366a353dc56adb4ee1e7d8a2cc34e3fbc22905f4167cfec119/pillow-12.0.0-cp313-cp313-ios_13_0_x86_64_iphonesimulator.whl", hash = "sha256:1ee80a59f6ce048ae13cda1abf7fbd2a34ab9ee7d401c46be3ca685d1999a399", size = 3576912, upload-time = "2025-10-15T18:22:28.751Z" },
+ { url = "https://files.pythonhosted.org/packages/a4/a4/a0a31467e3f83b94d37568294b01d22b43ae3c5d85f2811769b9c66389dd/pillow-12.0.0-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:c50f36a62a22d350c96e49ad02d0da41dbd17ddc2e29750dbdba4323f85eb4a5", size = 5249132, upload-time = "2025-10-15T18:22:30.641Z" },
+ { url = "https://files.pythonhosted.org/packages/83/06/48eab21dd561de2914242711434c0c0eb992ed08ff3f6107a5f44527f5e9/pillow-12.0.0-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:5193fde9a5f23c331ea26d0cf171fbf67e3f247585f50c08b3e205c7aeb4589b", size = 4650099, upload-time = "2025-10-15T18:22:32.73Z" },
+ { url = "https://files.pythonhosted.org/packages/fc/bd/69ed99fd46a8dba7c1887156d3572fe4484e3f031405fcc5a92e31c04035/pillow-12.0.0-cp313-cp313-manylinux2014_aarch64.manylinux_2_17_aarch64.whl", hash = "sha256:bde737cff1a975b70652b62d626f7785e0480918dece11e8fef3c0cf057351c3", size = 6230808, upload-time = "2025-10-15T18:22:34.337Z" },
+ { url = "https://files.pythonhosted.org/packages/ea/94/8fad659bcdbf86ed70099cb60ae40be6acca434bbc8c4c0d4ef356d7e0de/pillow-12.0.0-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:a6597ff2b61d121172f5844b53f21467f7082f5fb385a9a29c01414463f93b07", size = 8037804, upload-time = "2025-10-15T18:22:36.402Z" },
+ { url = "https://files.pythonhosted.org/packages/20/39/c685d05c06deecfd4e2d1950e9a908aa2ca8bc4e6c3b12d93b9cafbd7837/pillow-12.0.0-cp313-cp313-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:0b817e7035ea7f6b942c13aa03bb554fc44fea70838ea21f8eb31c638326584e", size = 6345553, upload-time = "2025-10-15T18:22:38.066Z" },
+ { url = "https://files.pythonhosted.org/packages/38/57/755dbd06530a27a5ed74f8cb0a7a44a21722ebf318edbe67ddbd7fb28f88/pillow-12.0.0-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:f4f1231b7dec408e8670264ce63e9c71409d9583dd21d32c163e25213ee2a344", size = 7037729, upload-time = "2025-10-15T18:22:39.769Z" },
+ { url = "https://files.pythonhosted.org/packages/ca/b6/7e94f4c41d238615674d06ed677c14883103dce1c52e4af16f000338cfd7/pillow-12.0.0-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:6e51b71417049ad6ab14c49608b4a24d8fb3fe605e5dfabfe523b58064dc3d27", size = 6459789, upload-time = "2025-10-15T18:22:41.437Z" },
+ { url = "https://files.pythonhosted.org/packages/9c/14/4448bb0b5e0f22dd865290536d20ec8a23b64e2d04280b89139f09a36bb6/pillow-12.0.0-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:d120c38a42c234dc9a8c5de7ceaaf899cf33561956acb4941653f8bdc657aa79", size = 7130917, upload-time = "2025-10-15T18:22:43.152Z" },
+ { url = "https://files.pythonhosted.org/packages/dd/ca/16c6926cc1c015845745d5c16c9358e24282f1e588237a4c36d2b30f182f/pillow-12.0.0-cp313-cp313-win32.whl", hash = "sha256:4cc6b3b2efff105c6a1656cfe59da4fdde2cda9af1c5e0b58529b24525d0a098", size = 6302391, upload-time = "2025-10-15T18:22:44.753Z" },
+ { url = "https://files.pythonhosted.org/packages/6d/2a/dd43dcfd6dae9b6a49ee28a8eedb98c7d5ff2de94a5d834565164667b97b/pillow-12.0.0-cp313-cp313-win_amd64.whl", hash = "sha256:4cf7fed4b4580601c4345ceb5d4cbf5a980d030fd5ad07c4d2ec589f95f09905", size = 7007477, upload-time = "2025-10-15T18:22:46.838Z" },
+ { url = "https://files.pythonhosted.org/packages/77/f0/72ea067f4b5ae5ead653053212af05ce3705807906ba3f3e8f58ddf617e6/pillow-12.0.0-cp313-cp313-win_arm64.whl", hash = "sha256:9f0b04c6b8584c2c193babcccc908b38ed29524b29dd464bc8801bf10d746a3a", size = 2435918, upload-time = "2025-10-15T18:22:48.399Z" },
+ { url = "https://files.pythonhosted.org/packages/f5/5e/9046b423735c21f0487ea6cb5b10f89ea8f8dfbe32576fe052b5ba9d4e5b/pillow-12.0.0-cp313-cp313t-macosx_10_13_x86_64.whl", hash = "sha256:7fa22993bac7b77b78cae22bad1e2a987ddf0d9015c63358032f84a53f23cdc3", size = 5251406, upload-time = "2025-10-15T18:22:49.905Z" },
+ { url = "https://files.pythonhosted.org/packages/12/66/982ceebcdb13c97270ef7a56c3969635b4ee7cd45227fa707c94719229c5/pillow-12.0.0-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:f135c702ac42262573fe9714dfe99c944b4ba307af5eb507abef1667e2cbbced", size = 4653218, upload-time = "2025-10-15T18:22:51.587Z" },
+ { url = "https://files.pythonhosted.org/packages/16/b3/81e625524688c31859450119bf12674619429cab3119eec0e30a7a1029cb/pillow-12.0.0-cp313-cp313t-manylinux2014_aarch64.manylinux_2_17_aarch64.whl", hash = "sha256:c85de1136429c524e55cfa4e033b4a7940ac5c8ee4d9401cc2d1bf48154bbc7b", size = 6266564, upload-time = "2025-10-15T18:22:53.215Z" },
+ { url = "https://files.pythonhosted.org/packages/98/59/dfb38f2a41240d2408096e1a76c671d0a105a4a8471b1871c6902719450c/pillow-12.0.0-cp313-cp313t-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:38df9b4bfd3db902c9c2bd369bcacaf9d935b2fff73709429d95cc41554f7b3d", size = 8069260, upload-time = "2025-10-15T18:22:54.933Z" },
+ { url = "https://files.pythonhosted.org/packages/dc/3d/378dbea5cd1874b94c312425ca77b0f47776c78e0df2df751b820c8c1d6c/pillow-12.0.0-cp313-cp313t-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:7d87ef5795da03d742bf49439f9ca4d027cde49c82c5371ba52464aee266699a", size = 6379248, upload-time = "2025-10-15T18:22:56.605Z" },
+ { url = "https://files.pythonhosted.org/packages/84/b0/d525ef47d71590f1621510327acec75ae58c721dc071b17d8d652ca494d8/pillow-12.0.0-cp313-cp313t-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:aff9e4d82d082ff9513bdd6acd4f5bd359f5b2c870907d2b0a9c5e10d40c88fe", size = 7066043, upload-time = "2025-10-15T18:22:58.53Z" },
+ { url = "https://files.pythonhosted.org/packages/61/2c/aced60e9cf9d0cde341d54bf7932c9ffc33ddb4a1595798b3a5150c7ec4e/pillow-12.0.0-cp313-cp313t-musllinux_1_2_aarch64.whl", hash = "sha256:8d8ca2b210ada074d57fcee40c30446c9562e542fc46aedc19baf758a93532ee", size = 6490915, upload-time = "2025-10-15T18:23:00.582Z" },
+ { url = "https://files.pythonhosted.org/packages/ef/26/69dcb9b91f4e59f8f34b2332a4a0a951b44f547c4ed39d3e4dcfcff48f89/pillow-12.0.0-cp313-cp313t-musllinux_1_2_x86_64.whl", hash = "sha256:99a7f72fb6249302aa62245680754862a44179b545ded638cf1fef59befb57ef", size = 7157998, upload-time = "2025-10-15T18:23:02.627Z" },
+ { url = "https://files.pythonhosted.org/packages/61/2b/726235842220ca95fa441ddf55dd2382b52ab5b8d9c0596fe6b3f23dafe8/pillow-12.0.0-cp313-cp313t-win32.whl", hash = "sha256:4078242472387600b2ce8d93ade8899c12bf33fa89e55ec89fe126e9d6d5d9e9", size = 6306201, upload-time = "2025-10-15T18:23:04.709Z" },
+ { url = "https://files.pythonhosted.org/packages/c0/3d/2afaf4e840b2df71344ababf2f8edd75a705ce500e5dc1e7227808312ae1/pillow-12.0.0-cp313-cp313t-win_amd64.whl", hash = "sha256:2c54c1a783d6d60595d3514f0efe9b37c8808746a66920315bfd34a938d7994b", size = 7013165, upload-time = "2025-10-15T18:23:06.46Z" },
+ { url = "https://files.pythonhosted.org/packages/6f/75/3fa09aa5cf6ed04bee3fa575798ddf1ce0bace8edb47249c798077a81f7f/pillow-12.0.0-cp313-cp313t-win_arm64.whl", hash = "sha256:26d9f7d2b604cd23aba3e9faf795787456ac25634d82cd060556998e39c6fa47", size = 2437834, upload-time = "2025-10-15T18:23:08.194Z" },
+ { url = "https://files.pythonhosted.org/packages/54/2a/9a8c6ba2c2c07b71bec92cf63e03370ca5e5f5c5b119b742bcc0cde3f9c5/pillow-12.0.0-cp314-cp314-ios_13_0_arm64_iphoneos.whl", hash = "sha256:beeae3f27f62308f1ddbcfb0690bf44b10732f2ef43758f169d5e9303165d3f9", size = 4045531, upload-time = "2025-10-15T18:23:10.121Z" },
+ { url = "https://files.pythonhosted.org/packages/84/54/836fdbf1bfb3d66a59f0189ff0b9f5f666cee09c6188309300df04ad71fa/pillow-12.0.0-cp314-cp314-ios_13_0_arm64_iphonesimulator.whl", hash = "sha256:d4827615da15cd59784ce39d3388275ec093ae3ee8d7f0c089b76fa87af756c2", size = 4120554, upload-time = "2025-10-15T18:23:12.14Z" },
+ { url = "https://files.pythonhosted.org/packages/0d/cd/16aec9f0da4793e98e6b54778a5fbce4f375c6646fe662e80600b8797379/pillow-12.0.0-cp314-cp314-ios_13_0_x86_64_iphonesimulator.whl", hash = "sha256:3e42edad50b6909089750e65c91aa09aaf1e0a71310d383f11321b27c224ed8a", size = 3576812, upload-time = "2025-10-15T18:23:13.962Z" },
+ { url = "https://files.pythonhosted.org/packages/f6/b7/13957fda356dc46339298b351cae0d327704986337c3c69bb54628c88155/pillow-12.0.0-cp314-cp314-macosx_10_15_x86_64.whl", hash = "sha256:e5d8efac84c9afcb40914ab49ba063d94f5dbdf5066db4482c66a992f47a3a3b", size = 5252689, upload-time = "2025-10-15T18:23:15.562Z" },
+ { url = "https://files.pythonhosted.org/packages/fc/f5/eae31a306341d8f331f43edb2e9122c7661b975433de5e447939ae61c5da/pillow-12.0.0-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:266cd5f2b63ff316d5a1bba46268e603c9caf5606d44f38c2873c380950576ad", size = 4650186, upload-time = "2025-10-15T18:23:17.379Z" },
+ { url = "https://files.pythonhosted.org/packages/86/62/2a88339aa40c4c77e79108facbd307d6091e2c0eb5b8d3cf4977cfca2fe6/pillow-12.0.0-cp314-cp314-manylinux2014_aarch64.manylinux_2_17_aarch64.whl", hash = "sha256:58eea5ebe51504057dd95c5b77d21700b77615ab0243d8152793dc00eb4faf01", size = 6230308, upload-time = "2025-10-15T18:23:18.971Z" },
+ { url = "https://files.pythonhosted.org/packages/c7/33/5425a8992bcb32d1cb9fa3dd39a89e613d09a22f2c8083b7bf43c455f760/pillow-12.0.0-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:f13711b1a5ba512d647a0e4ba79280d3a9a045aaf7e0cc6fbe96b91d4cdf6b0c", size = 8039222, upload-time = "2025-10-15T18:23:20.909Z" },
+ { url = "https://files.pythonhosted.org/packages/d8/61/3f5d3b35c5728f37953d3eec5b5f3e77111949523bd2dd7f31a851e50690/pillow-12.0.0-cp314-cp314-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:6846bd2d116ff42cba6b646edf5bf61d37e5cbd256425fa089fee4ff5c07a99e", size = 6346657, upload-time = "2025-10-15T18:23:23.077Z" },
+ { url = "https://files.pythonhosted.org/packages/3a/be/ee90a3d79271227e0f0a33c453531efd6ed14b2e708596ba5dd9be948da3/pillow-12.0.0-cp314-cp314-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:c98fa880d695de164b4135a52fd2e9cd7b7c90a9d8ac5e9e443a24a95ef9248e", size = 7038482, upload-time = "2025-10-15T18:23:25.005Z" },
+ { url = "https://files.pythonhosted.org/packages/44/34/a16b6a4d1ad727de390e9bd9f19f5f669e079e5826ec0f329010ddea492f/pillow-12.0.0-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:fa3ed2a29a9e9d2d488b4da81dcb54720ac3104a20bf0bd273f1e4648aff5af9", size = 6461416, upload-time = "2025-10-15T18:23:27.009Z" },
+ { url = "https://files.pythonhosted.org/packages/b6/39/1aa5850d2ade7d7ba9f54e4e4c17077244ff7a2d9e25998c38a29749eb3f/pillow-12.0.0-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:d034140032870024e6b9892c692fe2968493790dd57208b2c37e3fb35f6df3ab", size = 7131584, upload-time = "2025-10-15T18:23:29.752Z" },
+ { url = "https://files.pythonhosted.org/packages/bf/db/4fae862f8fad0167073a7733973bfa955f47e2cac3dc3e3e6257d10fab4a/pillow-12.0.0-cp314-cp314-win32.whl", hash = "sha256:1b1b133e6e16105f524a8dec491e0586d072948ce15c9b914e41cdadd209052b", size = 6400621, upload-time = "2025-10-15T18:23:32.06Z" },
+ { url = "https://files.pythonhosted.org/packages/2b/24/b350c31543fb0107ab2599464d7e28e6f856027aadda995022e695313d94/pillow-12.0.0-cp314-cp314-win_amd64.whl", hash = "sha256:8dc232e39d409036af549c86f24aed8273a40ffa459981146829a324e0848b4b", size = 7142916, upload-time = "2025-10-15T18:23:34.71Z" },
+ { url = "https://files.pythonhosted.org/packages/0f/9b/0ba5a6fd9351793996ef7487c4fdbde8d3f5f75dbedc093bb598648fddf0/pillow-12.0.0-cp314-cp314-win_arm64.whl", hash = "sha256:d52610d51e265a51518692045e372a4c363056130d922a7351429ac9f27e70b0", size = 2523836, upload-time = "2025-10-15T18:23:36.967Z" },
+ { url = "https://files.pythonhosted.org/packages/f5/7a/ceee0840aebc579af529b523d530840338ecf63992395842e54edc805987/pillow-12.0.0-cp314-cp314t-macosx_10_15_x86_64.whl", hash = "sha256:1979f4566bb96c1e50a62d9831e2ea2d1211761e5662afc545fa766f996632f6", size = 5255092, upload-time = "2025-10-15T18:23:38.573Z" },
+ { url = "https://files.pythonhosted.org/packages/44/76/20776057b4bfd1aef4eeca992ebde0f53a4dce874f3ae693d0ec90a4f79b/pillow-12.0.0-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:b2e4b27a6e15b04832fe9bf292b94b5ca156016bbc1ea9c2c20098a0320d6cf6", size = 4653158, upload-time = "2025-10-15T18:23:40.238Z" },
+ { url = "https://files.pythonhosted.org/packages/82/3f/d9ff92ace07be8836b4e7e87e6a4c7a8318d47c2f1463ffcf121fc57d9cb/pillow-12.0.0-cp314-cp314t-manylinux2014_aarch64.manylinux_2_17_aarch64.whl", hash = "sha256:fb3096c30df99fd01c7bf8e544f392103d0795b9f98ba71a8054bcbf56b255f1", size = 6267882, upload-time = "2025-10-15T18:23:42.434Z" },
+ { url = "https://files.pythonhosted.org/packages/9f/7a/4f7ff87f00d3ad33ba21af78bfcd2f032107710baf8280e3722ceec28cda/pillow-12.0.0-cp314-cp314t-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:7438839e9e053ef79f7112c881cef684013855016f928b168b81ed5835f3e75e", size = 8071001, upload-time = "2025-10-15T18:23:44.29Z" },
+ { url = "https://files.pythonhosted.org/packages/75/87/fcea108944a52dad8cca0715ae6247e271eb80459364a98518f1e4f480c1/pillow-12.0.0-cp314-cp314t-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:5d5c411a8eaa2299322b647cd932586b1427367fd3184ffbb8f7a219ea2041ca", size = 6380146, upload-time = "2025-10-15T18:23:46.065Z" },
+ { url = "https://files.pythonhosted.org/packages/91/52/0d31b5e571ef5fd111d2978b84603fce26aba1b6092f28e941cb46570745/pillow-12.0.0-cp314-cp314t-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:d7e091d464ac59d2c7ad8e7e08105eaf9dafbc3883fd7265ffccc2baad6ac925", size = 7067344, upload-time = "2025-10-15T18:23:47.898Z" },
+ { url = "https://files.pythonhosted.org/packages/7b/f4/2dd3d721f875f928d48e83bb30a434dee75a2531bca839bb996bb0aa5a91/pillow-12.0.0-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:792a2c0be4dcc18af9d4a2dfd8a11a17d5e25274a1062b0ec1c2d79c76f3e7f8", size = 6491864, upload-time = "2025-10-15T18:23:49.607Z" },
+ { url = "https://files.pythonhosted.org/packages/30/4b/667dfcf3d61fc309ba5a15b141845cece5915e39b99c1ceab0f34bf1d124/pillow-12.0.0-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:afbefa430092f71a9593a99ab6a4e7538bc9eabbf7bf94f91510d3503943edc4", size = 7158911, upload-time = "2025-10-15T18:23:51.351Z" },
+ { url = "https://files.pythonhosted.org/packages/a2/2f/16cabcc6426c32218ace36bf0d55955e813f2958afddbf1d391849fee9d1/pillow-12.0.0-cp314-cp314t-win32.whl", hash = "sha256:3830c769decf88f1289680a59d4f4c46c72573446352e2befec9a8512104fa52", size = 6408045, upload-time = "2025-10-15T18:23:53.177Z" },
+ { url = "https://files.pythonhosted.org/packages/35/73/e29aa0c9c666cf787628d3f0dcf379f4791fba79f4936d02f8b37165bdf8/pillow-12.0.0-cp314-cp314t-win_amd64.whl", hash = "sha256:905b0365b210c73afb0ebe9101a32572152dfd1c144c7e28968a331b9217b94a", size = 7148282, upload-time = "2025-10-15T18:23:55.316Z" },
+ { url = "https://files.pythonhosted.org/packages/c1/70/6b41bdcddf541b437bbb9f47f94d2db5d9ddef6c37ccab8c9107743748a4/pillow-12.0.0-cp314-cp314t-win_arm64.whl", hash = "sha256:99353a06902c2e43b43e8ff74ee65a7d90307d82370604746738a1e0661ccca7", size = 2525630, upload-time = "2025-10-15T18:23:57.149Z" },
+]
+
+[[package]]
+name = "platformdirs"
+version = "4.5.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/cf/86/0248f086a84f01b37aaec0fa567b397df1a119f73c16f6c7a9aac73ea309/platformdirs-4.5.1.tar.gz", hash = "sha256:61d5cdcc6065745cdd94f0f878977f8de9437be93de97c1c12f853c9c0cdcbda", size = 21715, upload-time = "2025-12-05T13:52:58.638Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/cb/28/3bfe2fa5a7b9c46fe7e13c97bda14c895fb10fa2ebf1d0abb90e0cea7ee1/platformdirs-4.5.1-py3-none-any.whl", hash = "sha256:d03afa3963c806a9bed9d5125c8f4cb2fdaf74a55ab60e5d59b3fde758104d31", size = 18731, upload-time = "2025-12-05T13:52:56.823Z" },
+]
+
+[[package]]
+name = "prometheus-client"
+version = "0.23.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/23/53/3edb5d68ecf6b38fcbcc1ad28391117d2a322d9a1a3eff04bfdb184d8c3b/prometheus_client-0.23.1.tar.gz", hash = "sha256:6ae8f9081eaaaf153a2e959d2e6c4f4fb57b12ef76c8c7980202f1e57b48b2ce", size = 80481, upload-time = "2025-09-18T20:47:25.043Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/b8/db/14bafcb4af2139e046d03fd00dea7873e48eafe18b7d2797e73d6681f210/prometheus_client-0.23.1-py3-none-any.whl", hash = "sha256:dd1913e6e76b59cfe44e7a4b83e01afc9873c1bdfd2ed8739f1e76aeca115f99", size = 61145, upload-time = "2025-09-18T20:47:23.875Z" },
+]
+
+[[package]]
+name = "prompt-toolkit"
+version = "3.0.52"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "wcwidth" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/a1/96/06e01a7b38dce6fe1db213e061a4602dd6032a8a97ef6c1a862537732421/prompt_toolkit-3.0.52.tar.gz", hash = "sha256:28cde192929c8e7321de85de1ddbe736f1375148b02f2e17edd840042b1be855", size = 434198, upload-time = "2025-08-27T15:24:02.057Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/84/03/0d3ce49e2505ae70cf43bc5bb3033955d2fc9f932163e84dc0779cc47f48/prompt_toolkit-3.0.52-py3-none-any.whl", hash = "sha256:9aac639a3bbd33284347de5ad8d68ecc044b91a762dc39b7c21095fcd6a19955", size = 391431, upload-time = "2025-08-27T15:23:59.498Z" },
+]
+
+[[package]]
+name = "propcache"
+version = "0.4.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/9e/da/e9fc233cf63743258bff22b3dfa7ea5baef7b5bc324af47a0ad89b8ffc6f/propcache-0.4.1.tar.gz", hash = "sha256:f48107a8c637e80362555f37ecf49abe20370e557cc4ab374f04ec4423c97c3d", size = 46442, upload-time = "2025-10-08T19:49:02.291Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/a2/0f/f17b1b2b221d5ca28b4b876e8bb046ac40466513960646bda8e1853cdfa2/propcache-0.4.1-cp312-cp312-macosx_10_13_universal2.whl", hash = "sha256:e153e9cd40cc8945138822807139367f256f89c6810c2634a4f6902b52d3b4e2", size = 80061, upload-time = "2025-10-08T19:46:46.075Z" },
+ { url = "https://files.pythonhosted.org/packages/76/47/8ccf75935f51448ba9a16a71b783eb7ef6b9ee60f5d14c7f8a8a79fbeed7/propcache-0.4.1-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:cd547953428f7abb73c5ad82cbb32109566204260d98e41e5dfdc682eb7f8403", size = 46037, upload-time = "2025-10-08T19:46:47.23Z" },
+ { url = "https://files.pythonhosted.org/packages/0a/b6/5c9a0e42df4d00bfb4a3cbbe5cf9f54260300c88a0e9af1f47ca5ce17ac0/propcache-0.4.1-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:f048da1b4f243fc44f205dfd320933a951b8d89e0afd4c7cacc762a8b9165207", size = 47324, upload-time = "2025-10-08T19:46:48.384Z" },
+ { url = "https://files.pythonhosted.org/packages/9e/d3/6c7ee328b39a81ee877c962469f1e795f9db87f925251efeb0545e0020d0/propcache-0.4.1-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:ec17c65562a827bba85e3872ead335f95405ea1674860d96483a02f5c698fa72", size = 225505, upload-time = "2025-10-08T19:46:50.055Z" },
+ { url = "https://files.pythonhosted.org/packages/01/5d/1c53f4563490b1d06a684742cc6076ef944bc6457df6051b7d1a877c057b/propcache-0.4.1-cp312-cp312-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:405aac25c6394ef275dee4c709be43745d36674b223ba4eb7144bf4d691b7367", size = 230242, upload-time = "2025-10-08T19:46:51.815Z" },
+ { url = "https://files.pythonhosted.org/packages/20/e1/ce4620633b0e2422207c3cb774a0ee61cac13abc6217763a7b9e2e3f4a12/propcache-0.4.1-cp312-cp312-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:0013cb6f8dde4b2a2f66903b8ba740bdfe378c943c4377a200551ceb27f379e4", size = 238474, upload-time = "2025-10-08T19:46:53.208Z" },
+ { url = "https://files.pythonhosted.org/packages/46/4b/3aae6835b8e5f44ea6a68348ad90f78134047b503765087be2f9912140ea/propcache-0.4.1-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:15932ab57837c3368b024473a525e25d316d8353016e7cc0e5ba9eb343fbb1cf", size = 221575, upload-time = "2025-10-08T19:46:54.511Z" },
+ { url = "https://files.pythonhosted.org/packages/6e/a5/8a5e8678bcc9d3a1a15b9a29165640d64762d424a16af543f00629c87338/propcache-0.4.1-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:031dce78b9dc099f4c29785d9cf5577a3faf9ebf74ecbd3c856a7b92768c3df3", size = 216736, upload-time = "2025-10-08T19:46:56.212Z" },
+ { url = "https://files.pythonhosted.org/packages/f1/63/b7b215eddeac83ca1c6b934f89d09a625aa9ee4ba158338854c87210cc36/propcache-0.4.1-cp312-cp312-musllinux_1_2_armv7l.whl", hash = "sha256:ab08df6c9a035bee56e31af99be621526bd237bea9f32def431c656b29e41778", size = 213019, upload-time = "2025-10-08T19:46:57.595Z" },
+ { url = "https://files.pythonhosted.org/packages/57/74/f580099a58c8af587cac7ba19ee7cb418506342fbbe2d4a4401661cca886/propcache-0.4.1-cp312-cp312-musllinux_1_2_ppc64le.whl", hash = "sha256:4d7af63f9f93fe593afbf104c21b3b15868efb2c21d07d8732c0c4287e66b6a6", size = 220376, upload-time = "2025-10-08T19:46:59.067Z" },
+ { url = "https://files.pythonhosted.org/packages/c4/ee/542f1313aff7eaf19c2bb758c5d0560d2683dac001a1c96d0774af799843/propcache-0.4.1-cp312-cp312-musllinux_1_2_s390x.whl", hash = "sha256:cfc27c945f422e8b5071b6e93169679e4eb5bf73bbcbf1ba3ae3a83d2f78ebd9", size = 226988, upload-time = "2025-10-08T19:47:00.544Z" },
+ { url = "https://files.pythonhosted.org/packages/8f/18/9c6b015dd9c6930f6ce2229e1f02fb35298b847f2087ea2b436a5bfa7287/propcache-0.4.1-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:35c3277624a080cc6ec6f847cbbbb5b49affa3598c4535a0a4682a697aaa5c75", size = 215615, upload-time = "2025-10-08T19:47:01.968Z" },
+ { url = "https://files.pythonhosted.org/packages/80/9e/e7b85720b98c45a45e1fca6a177024934dc9bc5f4d5dd04207f216fc33ed/propcache-0.4.1-cp312-cp312-win32.whl", hash = "sha256:671538c2262dadb5ba6395e26c1731e1d52534bfe9ae56d0b5573ce539266aa8", size = 38066, upload-time = "2025-10-08T19:47:03.503Z" },
+ { url = "https://files.pythonhosted.org/packages/54/09/d19cff2a5aaac632ec8fc03737b223597b1e347416934c1b3a7df079784c/propcache-0.4.1-cp312-cp312-win_amd64.whl", hash = "sha256:cb2d222e72399fcf5890d1d5cc1060857b9b236adff2792ff48ca2dfd46c81db", size = 41655, upload-time = "2025-10-08T19:47:04.973Z" },
+ { url = "https://files.pythonhosted.org/packages/68/ab/6b5c191bb5de08036a8c697b265d4ca76148efb10fa162f14af14fb5f076/propcache-0.4.1-cp312-cp312-win_arm64.whl", hash = "sha256:204483131fb222bdaaeeea9f9e6c6ed0cac32731f75dfc1d4a567fc1926477c1", size = 37789, upload-time = "2025-10-08T19:47:06.077Z" },
+ { url = "https://files.pythonhosted.org/packages/bf/df/6d9c1b6ac12b003837dde8a10231a7344512186e87b36e855bef32241942/propcache-0.4.1-cp313-cp313-macosx_10_13_universal2.whl", hash = "sha256:43eedf29202c08550aac1d14e0ee619b0430aaef78f85864c1a892294fbc28cf", size = 77750, upload-time = "2025-10-08T19:47:07.648Z" },
+ { url = "https://files.pythonhosted.org/packages/8b/e8/677a0025e8a2acf07d3418a2e7ba529c9c33caf09d3c1f25513023c1db56/propcache-0.4.1-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:d62cdfcfd89ccb8de04e0eda998535c406bf5e060ffd56be6c586cbcc05b3311", size = 44780, upload-time = "2025-10-08T19:47:08.851Z" },
+ { url = "https://files.pythonhosted.org/packages/89/a4/92380f7ca60f99ebae761936bc48a72a639e8a47b29050615eef757cb2a7/propcache-0.4.1-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:cae65ad55793da34db5f54e4029b89d3b9b9490d8abe1b4c7ab5d4b8ec7ebf74", size = 46308, upload-time = "2025-10-08T19:47:09.982Z" },
+ { url = "https://files.pythonhosted.org/packages/2d/48/c5ac64dee5262044348d1d78a5f85dd1a57464a60d30daee946699963eb3/propcache-0.4.1-cp313-cp313-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:333ddb9031d2704a301ee3e506dc46b1fe5f294ec198ed6435ad5b6a085facfe", size = 208182, upload-time = "2025-10-08T19:47:11.319Z" },
+ { url = "https://files.pythonhosted.org/packages/c6/0c/cd762dd011a9287389a6a3eb43aa30207bde253610cca06824aeabfe9653/propcache-0.4.1-cp313-cp313-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:fd0858c20f078a32cf55f7e81473d96dcf3b93fd2ccdb3d40fdf54b8573df3af", size = 211215, upload-time = "2025-10-08T19:47:13.146Z" },
+ { url = "https://files.pythonhosted.org/packages/30/3e/49861e90233ba36890ae0ca4c660e95df565b2cd15d4a68556ab5865974e/propcache-0.4.1-cp313-cp313-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:678ae89ebc632c5c204c794f8dab2837c5f159aeb59e6ed0539500400577298c", size = 218112, upload-time = "2025-10-08T19:47:14.913Z" },
+ { url = "https://files.pythonhosted.org/packages/f1/8b/544bc867e24e1bd48f3118cecd3b05c694e160a168478fa28770f22fd094/propcache-0.4.1-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:d472aeb4fbf9865e0c6d622d7f4d54a4e101a89715d8904282bb5f9a2f476c3f", size = 204442, upload-time = "2025-10-08T19:47:16.277Z" },
+ { url = "https://files.pythonhosted.org/packages/50/a6/4282772fd016a76d3e5c0df58380a5ea64900afd836cec2c2f662d1b9bb3/propcache-0.4.1-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:4d3df5fa7e36b3225954fba85589da77a0fe6a53e3976de39caf04a0db4c36f1", size = 199398, upload-time = "2025-10-08T19:47:17.962Z" },
+ { url = "https://files.pythonhosted.org/packages/3e/ec/d8a7cd406ee1ddb705db2139f8a10a8a427100347bd698e7014351c7af09/propcache-0.4.1-cp313-cp313-musllinux_1_2_armv7l.whl", hash = "sha256:ee17f18d2498f2673e432faaa71698032b0127ebf23ae5974eeaf806c279df24", size = 196920, upload-time = "2025-10-08T19:47:19.355Z" },
+ { url = "https://files.pythonhosted.org/packages/f6/6c/f38ab64af3764f431e359f8baf9e0a21013e24329e8b85d2da32e8ed07ca/propcache-0.4.1-cp313-cp313-musllinux_1_2_ppc64le.whl", hash = "sha256:580e97762b950f993ae618e167e7be9256b8353c2dcd8b99ec100eb50f5286aa", size = 203748, upload-time = "2025-10-08T19:47:21.338Z" },
+ { url = "https://files.pythonhosted.org/packages/d6/e3/fa846bd70f6534d647886621388f0a265254d30e3ce47e5c8e6e27dbf153/propcache-0.4.1-cp313-cp313-musllinux_1_2_s390x.whl", hash = "sha256:501d20b891688eb8e7aa903021f0b72d5a55db40ffaab27edefd1027caaafa61", size = 205877, upload-time = "2025-10-08T19:47:23.059Z" },
+ { url = "https://files.pythonhosted.org/packages/e2/39/8163fc6f3133fea7b5f2827e8eba2029a0277ab2c5beee6c1db7b10fc23d/propcache-0.4.1-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:9a0bd56e5b100aef69bd8562b74b46254e7c8812918d3baa700c8a8009b0af66", size = 199437, upload-time = "2025-10-08T19:47:24.445Z" },
+ { url = "https://files.pythonhosted.org/packages/93/89/caa9089970ca49c7c01662bd0eeedfe85494e863e8043565aeb6472ce8fe/propcache-0.4.1-cp313-cp313-win32.whl", hash = "sha256:bcc9aaa5d80322bc2fb24bb7accb4a30f81e90ab8d6ba187aec0744bc302ad81", size = 37586, upload-time = "2025-10-08T19:47:25.736Z" },
+ { url = "https://files.pythonhosted.org/packages/f5/ab/f76ec3c3627c883215b5c8080debb4394ef5a7a29be811f786415fc1e6fd/propcache-0.4.1-cp313-cp313-win_amd64.whl", hash = "sha256:381914df18634f5494334d201e98245c0596067504b9372d8cf93f4bb23e025e", size = 40790, upload-time = "2025-10-08T19:47:26.847Z" },
+ { url = "https://files.pythonhosted.org/packages/59/1b/e71ae98235f8e2ba5004d8cb19765a74877abf189bc53fc0c80d799e56c3/propcache-0.4.1-cp313-cp313-win_arm64.whl", hash = "sha256:8873eb4460fd55333ea49b7d189749ecf6e55bf85080f11b1c4530ed3034cba1", size = 37158, upload-time = "2025-10-08T19:47:27.961Z" },
+ { url = "https://files.pythonhosted.org/packages/83/ce/a31bbdfc24ee0dcbba458c8175ed26089cf109a55bbe7b7640ed2470cfe9/propcache-0.4.1-cp313-cp313t-macosx_10_13_universal2.whl", hash = "sha256:92d1935ee1f8d7442da9c0c4fa7ac20d07e94064184811b685f5c4fada64553b", size = 81451, upload-time = "2025-10-08T19:47:29.445Z" },
+ { url = "https://files.pythonhosted.org/packages/25/9c/442a45a470a68456e710d96cacd3573ef26a1d0a60067e6a7d5e655621ed/propcache-0.4.1-cp313-cp313t-macosx_10_13_x86_64.whl", hash = "sha256:473c61b39e1460d386479b9b2f337da492042447c9b685f28be4f74d3529e566", size = 46374, upload-time = "2025-10-08T19:47:30.579Z" },
+ { url = "https://files.pythonhosted.org/packages/f4/bf/b1d5e21dbc3b2e889ea4327044fb16312a736d97640fb8b6aa3f9c7b3b65/propcache-0.4.1-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:c0ef0aaafc66fbd87842a3fe3902fd889825646bc21149eafe47be6072725835", size = 48396, upload-time = "2025-10-08T19:47:31.79Z" },
+ { url = "https://files.pythonhosted.org/packages/f4/04/5b4c54a103d480e978d3c8a76073502b18db0c4bc17ab91b3cb5092ad949/propcache-0.4.1-cp313-cp313t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:f95393b4d66bfae908c3ca8d169d5f79cd65636ae15b5e7a4f6e67af675adb0e", size = 275950, upload-time = "2025-10-08T19:47:33.481Z" },
+ { url = "https://files.pythonhosted.org/packages/b4/c1/86f846827fb969c4b78b0af79bba1d1ea2156492e1b83dea8b8a6ae27395/propcache-0.4.1-cp313-cp313t-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:c07fda85708bc48578467e85099645167a955ba093be0a2dcba962195676e859", size = 273856, upload-time = "2025-10-08T19:47:34.906Z" },
+ { url = "https://files.pythonhosted.org/packages/36/1d/fc272a63c8d3bbad6878c336c7a7dea15e8f2d23a544bda43205dfa83ada/propcache-0.4.1-cp313-cp313t-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:af223b406d6d000830c6f65f1e6431783fc3f713ba3e6cc8c024d5ee96170a4b", size = 280420, upload-time = "2025-10-08T19:47:36.338Z" },
+ { url = "https://files.pythonhosted.org/packages/07/0c/01f2219d39f7e53d52e5173bcb09c976609ba30209912a0680adfb8c593a/propcache-0.4.1-cp313-cp313t-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:a78372c932c90ee474559c5ddfffd718238e8673c340dc21fe45c5b8b54559a0", size = 263254, upload-time = "2025-10-08T19:47:37.692Z" },
+ { url = "https://files.pythonhosted.org/packages/2d/18/cd28081658ce597898f0c4d174d4d0f3c5b6d4dc27ffafeef835c95eb359/propcache-0.4.1-cp313-cp313t-musllinux_1_2_aarch64.whl", hash = "sha256:564d9f0d4d9509e1a870c920a89b2fec951b44bf5ba7d537a9e7c1ccec2c18af", size = 261205, upload-time = "2025-10-08T19:47:39.659Z" },
+ { url = "https://files.pythonhosted.org/packages/7a/71/1f9e22eb8b8316701c2a19fa1f388c8a3185082607da8e406a803c9b954e/propcache-0.4.1-cp313-cp313t-musllinux_1_2_armv7l.whl", hash = "sha256:17612831fda0138059cc5546f4d12a2aacfb9e47068c06af35c400ba58ba7393", size = 247873, upload-time = "2025-10-08T19:47:41.084Z" },
+ { url = "https://files.pythonhosted.org/packages/4a/65/3d4b61f36af2b4eddba9def857959f1016a51066b4f1ce348e0cf7881f58/propcache-0.4.1-cp313-cp313t-musllinux_1_2_ppc64le.whl", hash = "sha256:41a89040cb10bd345b3c1a873b2bf36413d48da1def52f268a055f7398514874", size = 262739, upload-time = "2025-10-08T19:47:42.51Z" },
+ { url = "https://files.pythonhosted.org/packages/2a/42/26746ab087faa77c1c68079b228810436ccd9a5ce9ac85e2b7307195fd06/propcache-0.4.1-cp313-cp313t-musllinux_1_2_s390x.whl", hash = "sha256:e35b88984e7fa64aacecea39236cee32dd9bd8c55f57ba8a75cf2399553f9bd7", size = 263514, upload-time = "2025-10-08T19:47:43.927Z" },
+ { url = "https://files.pythonhosted.org/packages/94/13/630690fe201f5502d2403dd3cfd451ed8858fe3c738ee88d095ad2ff407b/propcache-0.4.1-cp313-cp313t-musllinux_1_2_x86_64.whl", hash = "sha256:6f8b465489f927b0df505cbe26ffbeed4d6d8a2bbc61ce90eb074ff129ef0ab1", size = 257781, upload-time = "2025-10-08T19:47:45.448Z" },
+ { url = "https://files.pythonhosted.org/packages/92/f7/1d4ec5841505f423469efbfc381d64b7b467438cd5a4bbcbb063f3b73d27/propcache-0.4.1-cp313-cp313t-win32.whl", hash = "sha256:2ad890caa1d928c7c2965b48f3a3815c853180831d0e5503d35cf00c472f4717", size = 41396, upload-time = "2025-10-08T19:47:47.202Z" },
+ { url = "https://files.pythonhosted.org/packages/48/f0/615c30622316496d2cbbc29f5985f7777d3ada70f23370608c1d3e081c1f/propcache-0.4.1-cp313-cp313t-win_amd64.whl", hash = "sha256:f7ee0e597f495cf415bcbd3da3caa3bd7e816b74d0d52b8145954c5e6fd3ff37", size = 44897, upload-time = "2025-10-08T19:47:48.336Z" },
+ { url = "https://files.pythonhosted.org/packages/fd/ca/6002e46eccbe0e33dcd4069ef32f7f1c9e243736e07adca37ae8c4830ec3/propcache-0.4.1-cp313-cp313t-win_arm64.whl", hash = "sha256:929d7cbe1f01bb7baffb33dc14eb5691c95831450a26354cd210a8155170c93a", size = 39789, upload-time = "2025-10-08T19:47:49.876Z" },
+ { url = "https://files.pythonhosted.org/packages/8e/5c/bca52d654a896f831b8256683457ceddd490ec18d9ec50e97dfd8fc726a8/propcache-0.4.1-cp314-cp314-macosx_10_13_universal2.whl", hash = "sha256:3f7124c9d820ba5548d431afb4632301acf965db49e666aa21c305cbe8c6de12", size = 78152, upload-time = "2025-10-08T19:47:51.051Z" },
+ { url = "https://files.pythonhosted.org/packages/65/9b/03b04e7d82a5f54fb16113d839f5ea1ede58a61e90edf515f6577c66fa8f/propcache-0.4.1-cp314-cp314-macosx_10_13_x86_64.whl", hash = "sha256:c0d4b719b7da33599dfe3b22d3db1ef789210a0597bc650b7cee9c77c2be8c5c", size = 44869, upload-time = "2025-10-08T19:47:52.594Z" },
+ { url = "https://files.pythonhosted.org/packages/b2/fa/89a8ef0468d5833a23fff277b143d0573897cf75bd56670a6d28126c7d68/propcache-0.4.1-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:9f302f4783709a78240ebc311b793f123328716a60911d667e0c036bc5dcbded", size = 46596, upload-time = "2025-10-08T19:47:54.073Z" },
+ { url = "https://files.pythonhosted.org/packages/86/bd/47816020d337f4a746edc42fe8d53669965138f39ee117414c7d7a340cfe/propcache-0.4.1-cp314-cp314-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:c80ee5802e3fb9ea37938e7eecc307fb984837091d5fd262bb37238b1ae97641", size = 206981, upload-time = "2025-10-08T19:47:55.715Z" },
+ { url = "https://files.pythonhosted.org/packages/df/f6/c5fa1357cc9748510ee55f37173eb31bfde6d94e98ccd9e6f033f2fc06e1/propcache-0.4.1-cp314-cp314-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:ed5a841e8bb29a55fb8159ed526b26adc5bdd7e8bd7bf793ce647cb08656cdf4", size = 211490, upload-time = "2025-10-08T19:47:57.499Z" },
+ { url = "https://files.pythonhosted.org/packages/80/1e/e5889652a7c4a3846683401a48f0f2e5083ce0ec1a8a5221d8058fbd1adf/propcache-0.4.1-cp314-cp314-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:55c72fd6ea2da4c318e74ffdf93c4fe4e926051133657459131a95c846d16d44", size = 215371, upload-time = "2025-10-08T19:47:59.317Z" },
+ { url = "https://files.pythonhosted.org/packages/b2/f2/889ad4b2408f72fe1a4f6a19491177b30ea7bf1a0fd5f17050ca08cfc882/propcache-0.4.1-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:8326e144341460402713f91df60ade3c999d601e7eb5ff8f6f7862d54de0610d", size = 201424, upload-time = "2025-10-08T19:48:00.67Z" },
+ { url = "https://files.pythonhosted.org/packages/27/73/033d63069b57b0812c8bd19f311faebeceb6ba31b8f32b73432d12a0b826/propcache-0.4.1-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:060b16ae65bc098da7f6d25bf359f1f31f688384858204fe5d652979e0015e5b", size = 197566, upload-time = "2025-10-08T19:48:02.604Z" },
+ { url = "https://files.pythonhosted.org/packages/dc/89/ce24f3dc182630b4e07aa6d15f0ff4b14ed4b9955fae95a0b54c58d66c05/propcache-0.4.1-cp314-cp314-musllinux_1_2_armv7l.whl", hash = "sha256:89eb3fa9524f7bec9de6e83cf3faed9d79bffa560672c118a96a171a6f55831e", size = 193130, upload-time = "2025-10-08T19:48:04.499Z" },
+ { url = "https://files.pythonhosted.org/packages/a9/24/ef0d5fd1a811fb5c609278d0209c9f10c35f20581fcc16f818da959fc5b4/propcache-0.4.1-cp314-cp314-musllinux_1_2_ppc64le.whl", hash = "sha256:dee69d7015dc235f526fe80a9c90d65eb0039103fe565776250881731f06349f", size = 202625, upload-time = "2025-10-08T19:48:06.213Z" },
+ { url = "https://files.pythonhosted.org/packages/f5/02/98ec20ff5546f68d673df2f7a69e8c0d076b5abd05ca882dc7ee3a83653d/propcache-0.4.1-cp314-cp314-musllinux_1_2_s390x.whl", hash = "sha256:5558992a00dfd54ccbc64a32726a3357ec93825a418a401f5cc67df0ac5d9e49", size = 204209, upload-time = "2025-10-08T19:48:08.432Z" },
+ { url = "https://files.pythonhosted.org/packages/a0/87/492694f76759b15f0467a2a93ab68d32859672b646aa8a04ce4864e7932d/propcache-0.4.1-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:c9b822a577f560fbd9554812526831712c1436d2c046cedee4c3796d3543b144", size = 197797, upload-time = "2025-10-08T19:48:09.968Z" },
+ { url = "https://files.pythonhosted.org/packages/ee/36/66367de3575db1d2d3f3d177432bd14ee577a39d3f5d1b3d5df8afe3b6e2/propcache-0.4.1-cp314-cp314-win32.whl", hash = "sha256:ab4c29b49d560fe48b696cdcb127dd36e0bc2472548f3bf56cc5cb3da2b2984f", size = 38140, upload-time = "2025-10-08T19:48:11.232Z" },
+ { url = "https://files.pythonhosted.org/packages/0c/2a/a758b47de253636e1b8aef181c0b4f4f204bf0dd964914fb2af90a95b49b/propcache-0.4.1-cp314-cp314-win_amd64.whl", hash = "sha256:5a103c3eb905fcea0ab98be99c3a9a5ab2de60228aa5aceedc614c0281cf6153", size = 41257, upload-time = "2025-10-08T19:48:12.707Z" },
+ { url = "https://files.pythonhosted.org/packages/34/5e/63bd5896c3fec12edcbd6f12508d4890d23c265df28c74b175e1ef9f4f3b/propcache-0.4.1-cp314-cp314-win_arm64.whl", hash = "sha256:74c1fb26515153e482e00177a1ad654721bf9207da8a494a0c05e797ad27b992", size = 38097, upload-time = "2025-10-08T19:48:13.923Z" },
+ { url = "https://files.pythonhosted.org/packages/99/85/9ff785d787ccf9bbb3f3106f79884a130951436f58392000231b4c737c80/propcache-0.4.1-cp314-cp314t-macosx_10_13_universal2.whl", hash = "sha256:824e908bce90fb2743bd6b59db36eb4f45cd350a39637c9f73b1c1ea66f5b75f", size = 81455, upload-time = "2025-10-08T19:48:15.16Z" },
+ { url = "https://files.pythonhosted.org/packages/90/85/2431c10c8e7ddb1445c1f7c4b54d886e8ad20e3c6307e7218f05922cad67/propcache-0.4.1-cp314-cp314t-macosx_10_13_x86_64.whl", hash = "sha256:c2b5e7db5328427c57c8e8831abda175421b709672f6cfc3d630c3b7e2146393", size = 46372, upload-time = "2025-10-08T19:48:16.424Z" },
+ { url = "https://files.pythonhosted.org/packages/01/20/b0972d902472da9bcb683fa595099911f4d2e86e5683bcc45de60dd05dc3/propcache-0.4.1-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:6f6ff873ed40292cd4969ef5310179afd5db59fdf055897e282485043fc80ad0", size = 48411, upload-time = "2025-10-08T19:48:17.577Z" },
+ { url = "https://files.pythonhosted.org/packages/e2/e3/7dc89f4f21e8f99bad3d5ddb3a3389afcf9da4ac69e3deb2dcdc96e74169/propcache-0.4.1-cp314-cp314t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:49a2dc67c154db2c1463013594c458881a069fcf98940e61a0569016a583020a", size = 275712, upload-time = "2025-10-08T19:48:18.901Z" },
+ { url = "https://files.pythonhosted.org/packages/20/67/89800c8352489b21a8047c773067644e3897f02ecbbd610f4d46b7f08612/propcache-0.4.1-cp314-cp314t-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:005f08e6a0529984491e37d8dbc3dd86f84bd78a8ceb5fa9a021f4c48d4984be", size = 273557, upload-time = "2025-10-08T19:48:20.762Z" },
+ { url = "https://files.pythonhosted.org/packages/e2/a1/b52b055c766a54ce6d9c16d9aca0cad8059acd9637cdf8aa0222f4a026ef/propcache-0.4.1-cp314-cp314t-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:5c3310452e0d31390da9035c348633b43d7e7feb2e37be252be6da45abd1abcc", size = 280015, upload-time = "2025-10-08T19:48:22.592Z" },
+ { url = "https://files.pythonhosted.org/packages/48/c8/33cee30bd890672c63743049f3c9e4be087e6780906bfc3ec58528be59c1/propcache-0.4.1-cp314-cp314t-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:4c3c70630930447f9ef1caac7728c8ad1c56bc5015338b20fed0d08ea2480b3a", size = 262880, upload-time = "2025-10-08T19:48:23.947Z" },
+ { url = "https://files.pythonhosted.org/packages/0c/b1/8f08a143b204b418285c88b83d00edbd61afbc2c6415ffafc8905da7038b/propcache-0.4.1-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:8e57061305815dfc910a3634dcf584f08168a8836e6999983569f51a8544cd89", size = 260938, upload-time = "2025-10-08T19:48:25.656Z" },
+ { url = "https://files.pythonhosted.org/packages/cf/12/96e4664c82ca2f31e1c8dff86afb867348979eb78d3cb8546a680287a1e9/propcache-0.4.1-cp314-cp314t-musllinux_1_2_armv7l.whl", hash = "sha256:521a463429ef54143092c11a77e04056dd00636f72e8c45b70aaa3140d639726", size = 247641, upload-time = "2025-10-08T19:48:27.207Z" },
+ { url = "https://files.pythonhosted.org/packages/18/ed/e7a9cfca28133386ba52278136d42209d3125db08d0a6395f0cba0c0285c/propcache-0.4.1-cp314-cp314t-musllinux_1_2_ppc64le.whl", hash = "sha256:120c964da3fdc75e3731aa392527136d4ad35868cc556fd09bb6d09172d9a367", size = 262510, upload-time = "2025-10-08T19:48:28.65Z" },
+ { url = "https://files.pythonhosted.org/packages/f5/76/16d8bf65e8845dd62b4e2b57444ab81f07f40caa5652b8969b87ddcf2ef6/propcache-0.4.1-cp314-cp314t-musllinux_1_2_s390x.whl", hash = "sha256:d8f353eb14ee3441ee844ade4277d560cdd68288838673273b978e3d6d2c8f36", size = 263161, upload-time = "2025-10-08T19:48:30.133Z" },
+ { url = "https://files.pythonhosted.org/packages/e7/70/c99e9edb5d91d5ad8a49fa3c1e8285ba64f1476782fed10ab251ff413ba1/propcache-0.4.1-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:ab2943be7c652f09638800905ee1bab2c544e537edb57d527997a24c13dc1455", size = 257393, upload-time = "2025-10-08T19:48:31.567Z" },
+ { url = "https://files.pythonhosted.org/packages/08/02/87b25304249a35c0915d236575bc3574a323f60b47939a2262b77632a3ee/propcache-0.4.1-cp314-cp314t-win32.whl", hash = "sha256:05674a162469f31358c30bcaa8883cb7829fa3110bf9c0991fe27d7896c42d85", size = 42546, upload-time = "2025-10-08T19:48:32.872Z" },
+ { url = "https://files.pythonhosted.org/packages/cb/ef/3c6ecf8b317aa982f309835e8f96987466123c6e596646d4e6a1dfcd080f/propcache-0.4.1-cp314-cp314t-win_amd64.whl", hash = "sha256:990f6b3e2a27d683cb7602ed6c86f15ee6b43b1194736f9baaeb93d0016633b1", size = 46259, upload-time = "2025-10-08T19:48:34.226Z" },
+ { url = "https://files.pythonhosted.org/packages/c4/2d/346e946d4951f37eca1e4f55be0f0174c52cd70720f84029b02f296f4a38/propcache-0.4.1-cp314-cp314t-win_arm64.whl", hash = "sha256:ecef2343af4cc68e05131e45024ba34f6095821988a9d0a02aa7c73fcc448aa9", size = 40428, upload-time = "2025-10-08T19:48:35.441Z" },
+ { url = "https://files.pythonhosted.org/packages/5b/5a/bc7b4a4ef808fa59a816c17b20c4bef6884daebbdf627ff2a161da67da19/propcache-0.4.1-py3-none-any.whl", hash = "sha256:af2a6052aeb6cf17d3e46ee169099044fd8224cbaf75c76a2ef596e8163e2237", size = 13305, upload-time = "2025-10-08T19:49:00.792Z" },
+]
+
+[[package]]
+name = "protobuf"
+version = "6.33.2"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/34/44/e49ecff446afeec9d1a66d6bbf9adc21e3c7cea7803a920ca3773379d4f6/protobuf-6.33.2.tar.gz", hash = "sha256:56dc370c91fbb8ac85bc13582c9e373569668a290aa2e66a590c2a0d35ddb9e4", size = 444296, upload-time = "2025-12-06T00:17:53.311Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/bc/91/1e3a34881a88697a7354ffd177e8746e97a722e5e8db101544b47e84afb1/protobuf-6.33.2-cp310-abi3-win32.whl", hash = "sha256:87eb388bd2d0f78febd8f4c8779c79247b26a5befad525008e49a6955787ff3d", size = 425603, upload-time = "2025-12-06T00:17:41.114Z" },
+ { url = "https://files.pythonhosted.org/packages/64/20/4d50191997e917ae13ad0a235c8b42d8c1ab9c3e6fd455ca16d416944355/protobuf-6.33.2-cp310-abi3-win_amd64.whl", hash = "sha256:fc2a0e8b05b180e5fc0dd1559fe8ebdae21a27e81ac77728fb6c42b12c7419b4", size = 436930, upload-time = "2025-12-06T00:17:43.278Z" },
+ { url = "https://files.pythonhosted.org/packages/b2/ca/7e485da88ba45c920fb3f50ae78de29ab925d9e54ef0de678306abfbb497/protobuf-6.33.2-cp39-abi3-macosx_10_9_universal2.whl", hash = "sha256:d9b19771ca75935b3a4422957bc518b0cecb978b31d1dd12037b088f6bcc0e43", size = 427621, upload-time = "2025-12-06T00:17:44.445Z" },
+ { url = "https://files.pythonhosted.org/packages/7d/4f/f743761e41d3b2b2566748eb76bbff2b43e14d5fcab694f494a16458b05f/protobuf-6.33.2-cp39-abi3-manylinux2014_aarch64.whl", hash = "sha256:b5d3b5625192214066d99b2b605f5783483575656784de223f00a8d00754fc0e", size = 324460, upload-time = "2025-12-06T00:17:45.678Z" },
+ { url = "https://files.pythonhosted.org/packages/b1/fa/26468d00a92824020f6f2090d827078c09c9c587e34cbfd2d0c7911221f8/protobuf-6.33.2-cp39-abi3-manylinux2014_s390x.whl", hash = "sha256:8cd7640aee0b7828b6d03ae518b5b4806fdfc1afe8de82f79c3454f8aef29872", size = 339168, upload-time = "2025-12-06T00:17:46.813Z" },
+ { url = "https://files.pythonhosted.org/packages/56/13/333b8f421738f149d4fe5e49553bc2a2ab75235486259f689b4b91f96cec/protobuf-6.33.2-cp39-abi3-manylinux2014_x86_64.whl", hash = "sha256:1f8017c48c07ec5859106533b682260ba3d7c5567b1ca1f24297ce03384d1b4f", size = 323270, upload-time = "2025-12-06T00:17:48.253Z" },
+ { url = "https://files.pythonhosted.org/packages/0e/15/4f02896cc3df04fc465010a4c6a0cd89810f54617a32a70ef531ed75d61c/protobuf-6.33.2-py3-none-any.whl", hash = "sha256:7636aad9bb01768870266de5dc009de2d1b936771b38a793f73cbbf279c91c5c", size = 170501, upload-time = "2025-12-06T00:17:52.211Z" },
+]
+
+[[package]]
+name = "psutil"
+version = "7.1.3"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/e1/88/bdd0a41e5857d5d703287598cbf08dad90aed56774ea52ae071bae9071b6/psutil-7.1.3.tar.gz", hash = "sha256:6c86281738d77335af7aec228328e944b30930899ea760ecf33a4dba66be5e74", size = 489059, upload-time = "2025-11-02T12:25:54.619Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/bd/93/0c49e776b8734fef56ec9c5c57f923922f2cf0497d62e0f419465f28f3d0/psutil-7.1.3-cp313-cp313t-macosx_10_13_x86_64.whl", hash = "sha256:0005da714eee687b4b8decd3d6cc7c6db36215c9e74e5ad2264b90c3df7d92dc", size = 239751, upload-time = "2025-11-02T12:25:58.161Z" },
+ { url = "https://files.pythonhosted.org/packages/6f/8d/b31e39c769e70780f007969815195a55c81a63efebdd4dbe9e7a113adb2f/psutil-7.1.3-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:19644c85dcb987e35eeeaefdc3915d059dac7bd1167cdcdbf27e0ce2df0c08c0", size = 240368, upload-time = "2025-11-02T12:26:00.491Z" },
+ { url = "https://files.pythonhosted.org/packages/62/61/23fd4acc3c9eebbf6b6c78bcd89e5d020cfde4acf0a9233e9d4e3fa698b4/psutil-7.1.3-cp313-cp313t-manylinux2010_x86_64.manylinux_2_12_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:95ef04cf2e5ba0ab9eaafc4a11eaae91b44f4ef5541acd2ee91d9108d00d59a7", size = 287134, upload-time = "2025-11-02T12:26:02.613Z" },
+ { url = "https://files.pythonhosted.org/packages/30/1c/f921a009ea9ceb51aa355cb0cc118f68d354db36eae18174bab63affb3e6/psutil-7.1.3-cp313-cp313t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:1068c303be3a72f8e18e412c5b2a8f6d31750fb152f9cb106b54090296c9d251", size = 289904, upload-time = "2025-11-02T12:26:05.207Z" },
+ { url = "https://files.pythonhosted.org/packages/a6/82/62d68066e13e46a5116df187d319d1724b3f437ddd0f958756fc052677f4/psutil-7.1.3-cp313-cp313t-win_amd64.whl", hash = "sha256:18349c5c24b06ac5612c0428ec2a0331c26443d259e2a0144a9b24b4395b58fa", size = 249642, upload-time = "2025-11-02T12:26:07.447Z" },
+ { url = "https://files.pythonhosted.org/packages/df/ad/c1cd5fe965c14a0392112f68362cfceb5230819dbb5b1888950d18a11d9f/psutil-7.1.3-cp313-cp313t-win_arm64.whl", hash = "sha256:c525ffa774fe4496282fb0b1187725793de3e7c6b29e41562733cae9ada151ee", size = 245518, upload-time = "2025-11-02T12:26:09.719Z" },
+ { url = "https://files.pythonhosted.org/packages/2e/bb/6670bded3e3236eb4287c7bcdc167e9fae6e1e9286e437f7111caed2f909/psutil-7.1.3-cp314-cp314t-macosx_10_15_x86_64.whl", hash = "sha256:b403da1df4d6d43973dc004d19cee3b848e998ae3154cc8097d139b77156c353", size = 239843, upload-time = "2025-11-02T12:26:11.968Z" },
+ { url = "https://files.pythonhosted.org/packages/b8/66/853d50e75a38c9a7370ddbeefabdd3d3116b9c31ef94dc92c6729bc36bec/psutil-7.1.3-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:ad81425efc5e75da3f39b3e636293360ad8d0b49bed7df824c79764fb4ba9b8b", size = 240369, upload-time = "2025-11-02T12:26:14.358Z" },
+ { url = "https://files.pythonhosted.org/packages/41/bd/313aba97cb5bfb26916dc29cf0646cbe4dd6a89ca69e8c6edce654876d39/psutil-7.1.3-cp314-cp314t-manylinux2010_x86_64.manylinux_2_12_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:8f33a3702e167783a9213db10ad29650ebf383946e91bc77f28a5eb083496bc9", size = 288210, upload-time = "2025-11-02T12:26:16.699Z" },
+ { url = "https://files.pythonhosted.org/packages/c2/fa/76e3c06e760927a0cfb5705eb38164254de34e9bd86db656d4dbaa228b04/psutil-7.1.3-cp314-cp314t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:fac9cd332c67f4422504297889da5ab7e05fd11e3c4392140f7370f4208ded1f", size = 291182, upload-time = "2025-11-02T12:26:18.848Z" },
+ { url = "https://files.pythonhosted.org/packages/0f/1d/5774a91607035ee5078b8fd747686ebec28a962f178712de100d00b78a32/psutil-7.1.3-cp314-cp314t-win_amd64.whl", hash = "sha256:3792983e23b69843aea49c8f5b8f115572c5ab64c153bada5270086a2123c7e7", size = 250466, upload-time = "2025-11-02T12:26:21.183Z" },
+ { url = "https://files.pythonhosted.org/packages/00/ca/e426584bacb43a5cb1ac91fae1937f478cd8fbe5e4ff96574e698a2c77cd/psutil-7.1.3-cp314-cp314t-win_arm64.whl", hash = "sha256:31d77fcedb7529f27bb3a0472bea9334349f9a04160e8e6e5020f22c59893264", size = 245756, upload-time = "2025-11-02T12:26:23.148Z" },
+ { url = "https://files.pythonhosted.org/packages/ef/94/46b9154a800253e7ecff5aaacdf8ebf43db99de4a2dfa18575b02548654e/psutil-7.1.3-cp36-abi3-macosx_10_9_x86_64.whl", hash = "sha256:2bdbcd0e58ca14996a42adf3621a6244f1bb2e2e528886959c72cf1e326677ab", size = 238359, upload-time = "2025-11-02T12:26:25.284Z" },
+ { url = "https://files.pythonhosted.org/packages/68/3a/9f93cff5c025029a36d9a92fef47220ab4692ee7f2be0fba9f92813d0cb8/psutil-7.1.3-cp36-abi3-macosx_11_0_arm64.whl", hash = "sha256:bc31fa00f1fbc3c3802141eede66f3a2d51d89716a194bf2cd6fc68310a19880", size = 239171, upload-time = "2025-11-02T12:26:27.23Z" },
+ { url = "https://files.pythonhosted.org/packages/ce/b1/5f49af514f76431ba4eea935b8ad3725cdeb397e9245ab919dbc1d1dc20f/psutil-7.1.3-cp36-abi3-manylinux2010_x86_64.manylinux_2_12_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:3bb428f9f05c1225a558f53e30ccbad9930b11c3fc206836242de1091d3e7dd3", size = 263261, upload-time = "2025-11-02T12:26:29.48Z" },
+ { url = "https://files.pythonhosted.org/packages/e0/95/992c8816a74016eb095e73585d747e0a8ea21a061ed3689474fabb29a395/psutil-7.1.3-cp36-abi3-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:56d974e02ca2c8eb4812c3f76c30e28836fffc311d55d979f1465c1feeb2b68b", size = 264635, upload-time = "2025-11-02T12:26:31.74Z" },
+ { url = "https://files.pythonhosted.org/packages/55/4c/c3ed1a622b6ae2fd3c945a366e64eb35247a31e4db16cf5095e269e8eb3c/psutil-7.1.3-cp37-abi3-win_amd64.whl", hash = "sha256:f39c2c19fe824b47484b96f9692932248a54c43799a84282cfe58d05a6449efd", size = 247633, upload-time = "2025-11-02T12:26:33.887Z" },
+ { url = "https://files.pythonhosted.org/packages/c9/ad/33b2ccec09bf96c2b2ef3f9a6f66baac8253d7565d8839e024a6b905d45d/psutil-7.1.3-cp37-abi3-win_arm64.whl", hash = "sha256:bd0d69cee829226a761e92f28140bec9a5ee9d5b4fb4b0cc589068dbfff559b1", size = 244608, upload-time = "2025-11-02T12:26:36.136Z" },
+]
+
+[[package]]
+name = "ptyprocess"
+version = "0.7.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/20/e5/16ff212c1e452235a90aeb09066144d0c5a6a8c0834397e03f5224495c4e/ptyprocess-0.7.0.tar.gz", hash = "sha256:5c5d0a3b48ceee0b48485e0c26037c0acd7d29765ca3fbb5cb3831d347423220", size = 70762, upload-time = "2020-12-28T15:15:30.155Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/22/a6/858897256d0deac81a172289110f31629fc4cee19b6f01283303e18c8db3/ptyprocess-0.7.0-py2.py3-none-any.whl", hash = "sha256:4b41f3967fce3af57cc7e94b888626c18bf37a083e3651ca8feeb66d492fef35", size = 13993, upload-time = "2020-12-28T15:15:28.35Z" },
+]
+
+[[package]]
+name = "pure-eval"
+version = "0.2.3"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/cd/05/0a34433a064256a578f1783a10da6df098ceaa4a57bbeaa96a6c0352786b/pure_eval-0.2.3.tar.gz", hash = "sha256:5f4e983f40564c576c7c8635ae88db5956bb2229d7e9237d03b3c0b0190eaf42", size = 19752, upload-time = "2024-07-21T12:58:21.801Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/8e/37/efad0257dc6e593a18957422533ff0f87ede7c9c6ea010a2177d738fb82f/pure_eval-0.2.3-py3-none-any.whl", hash = "sha256:1db8e35b67b3d218d818ae653e27f06c3aa420901fa7b081ca98cbedc874e0d0", size = 11842, upload-time = "2024-07-21T12:58:20.04Z" },
+]
+
+[[package]]
+name = "pyarrow"
+version = "22.0.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/30/53/04a7fdc63e6056116c9ddc8b43bc28c12cdd181b85cbeadb79278475f3ae/pyarrow-22.0.0.tar.gz", hash = "sha256:3d600dc583260d845c7d8a6db540339dd883081925da2bd1c5cb808f720b3cd9", size = 1151151, upload-time = "2025-10-24T12:30:00.762Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/af/63/ba23862d69652f85b615ca14ad14f3bcfc5bf1b99ef3f0cd04ff93fdad5a/pyarrow-22.0.0-cp312-cp312-macosx_12_0_arm64.whl", hash = "sha256:bea79263d55c24a32b0d79c00a1c58bb2ee5f0757ed95656b01c0fb310c5af3d", size = 34211578, upload-time = "2025-10-24T10:05:21.583Z" },
+ { url = "https://files.pythonhosted.org/packages/b1/d0/f9ad86fe809efd2bcc8be32032fa72e8b0d112b01ae56a053006376c5930/pyarrow-22.0.0-cp312-cp312-macosx_12_0_x86_64.whl", hash = "sha256:12fe549c9b10ac98c91cf791d2945e878875d95508e1a5d14091a7aaa66d9cf8", size = 35989906, upload-time = "2025-10-24T10:05:29.485Z" },
+ { url = "https://files.pythonhosted.org/packages/b4/a8/f910afcb14630e64d673f15904ec27dd31f1e009b77033c365c84e8c1e1d/pyarrow-22.0.0-cp312-cp312-manylinux_2_28_aarch64.whl", hash = "sha256:334f900ff08ce0423407af97e6c26ad5d4e3b0763645559ece6fbf3747d6a8f5", size = 45021677, upload-time = "2025-10-24T10:05:38.274Z" },
+ { url = "https://files.pythonhosted.org/packages/13/95/aec81f781c75cd10554dc17a25849c720d54feafb6f7847690478dcf5ef8/pyarrow-22.0.0-cp312-cp312-manylinux_2_28_x86_64.whl", hash = "sha256:c6c791b09c57ed76a18b03f2631753a4960eefbbca80f846da8baefc6491fcfe", size = 47726315, upload-time = "2025-10-24T10:05:47.314Z" },
+ { url = "https://files.pythonhosted.org/packages/bb/d4/74ac9f7a54cfde12ee42734ea25d5a3c9a45db78f9def949307a92720d37/pyarrow-22.0.0-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:c3200cb41cdbc65156e5f8c908d739b0dfed57e890329413da2748d1a2cd1a4e", size = 47990906, upload-time = "2025-10-24T10:05:58.254Z" },
+ { url = "https://files.pythonhosted.org/packages/2e/71/fedf2499bf7a95062eafc989ace56572f3343432570e1c54e6599d5b88da/pyarrow-22.0.0-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:ac93252226cf288753d8b46280f4edf3433bf9508b6977f8dd8526b521a1bbb9", size = 50306783, upload-time = "2025-10-24T10:06:08.08Z" },
+ { url = "https://files.pythonhosted.org/packages/68/ed/b202abd5a5b78f519722f3d29063dda03c114711093c1995a33b8e2e0f4b/pyarrow-22.0.0-cp312-cp312-win_amd64.whl", hash = "sha256:44729980b6c50a5f2bfcc2668d36c569ce17f8b17bccaf470c4313dcbbf13c9d", size = 27972883, upload-time = "2025-10-24T10:06:14.204Z" },
+ { url = "https://files.pythonhosted.org/packages/a6/d6/d0fac16a2963002fc22c8fa75180a838737203d558f0ed3b564c4a54eef5/pyarrow-22.0.0-cp313-cp313-macosx_12_0_arm64.whl", hash = "sha256:e6e95176209257803a8b3d0394f21604e796dadb643d2f7ca21b66c9c0b30c9a", size = 34204629, upload-time = "2025-10-24T10:06:20.274Z" },
+ { url = "https://files.pythonhosted.org/packages/c6/9c/1d6357347fbae062ad3f17082f9ebc29cc733321e892c0d2085f42a2212b/pyarrow-22.0.0-cp313-cp313-macosx_12_0_x86_64.whl", hash = "sha256:001ea83a58024818826a9e3f89bf9310a114f7e26dfe404a4c32686f97bd7901", size = 35985783, upload-time = "2025-10-24T10:06:27.301Z" },
+ { url = "https://files.pythonhosted.org/packages/ff/c0/782344c2ce58afbea010150df07e3a2f5fdad299cd631697ae7bd3bac6e3/pyarrow-22.0.0-cp313-cp313-manylinux_2_28_aarch64.whl", hash = "sha256:ce20fe000754f477c8a9125543f1936ea5b8867c5406757c224d745ed033e691", size = 45020999, upload-time = "2025-10-24T10:06:35.387Z" },
+ { url = "https://files.pythonhosted.org/packages/1b/8b/5362443737a5307a7b67c1017c42cd104213189b4970bf607e05faf9c525/pyarrow-22.0.0-cp313-cp313-manylinux_2_28_x86_64.whl", hash = "sha256:e0a15757fccb38c410947df156f9749ae4a3c89b2393741a50521f39a8cf202a", size = 47724601, upload-time = "2025-10-24T10:06:43.551Z" },
+ { url = "https://files.pythonhosted.org/packages/69/4d/76e567a4fc2e190ee6072967cb4672b7d9249ac59ae65af2d7e3047afa3b/pyarrow-22.0.0-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:cedb9dd9358e4ea1d9bce3665ce0797f6adf97ff142c8e25b46ba9cdd508e9b6", size = 48001050, upload-time = "2025-10-24T10:06:52.284Z" },
+ { url = "https://files.pythonhosted.org/packages/01/5e/5653f0535d2a1aef8223cee9d92944cb6bccfee5cf1cd3f462d7cb022790/pyarrow-22.0.0-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:252be4a05f9d9185bb8c18e83764ebcfea7185076c07a7a662253af3a8c07941", size = 50307877, upload-time = "2025-10-24T10:07:02.405Z" },
+ { url = "https://files.pythonhosted.org/packages/2d/f8/1d0bd75bf9328a3b826e24a16e5517cd7f9fbf8d34a3184a4566ef5a7f29/pyarrow-22.0.0-cp313-cp313-win_amd64.whl", hash = "sha256:a4893d31e5ef780b6edcaf63122df0f8d321088bb0dee4c8c06eccb1ca28d145", size = 27977099, upload-time = "2025-10-24T10:08:07.259Z" },
+ { url = "https://files.pythonhosted.org/packages/90/81/db56870c997805bf2b0f6eeeb2d68458bf4654652dccdcf1bf7a42d80903/pyarrow-22.0.0-cp313-cp313t-macosx_12_0_arm64.whl", hash = "sha256:f7fe3dbe871294ba70d789be16b6e7e52b418311e166e0e3cba9522f0f437fb1", size = 34336685, upload-time = "2025-10-24T10:07:11.47Z" },
+ { url = "https://files.pythonhosted.org/packages/1c/98/0727947f199aba8a120f47dfc229eeb05df15bcd7a6f1b669e9f882afc58/pyarrow-22.0.0-cp313-cp313t-macosx_12_0_x86_64.whl", hash = "sha256:ba95112d15fd4f1105fb2402c4eab9068f0554435e9b7085924bcfaac2cc306f", size = 36032158, upload-time = "2025-10-24T10:07:18.626Z" },
+ { url = "https://files.pythonhosted.org/packages/96/b4/9babdef9c01720a0785945c7cf550e4acd0ebcd7bdd2e6f0aa7981fa85e2/pyarrow-22.0.0-cp313-cp313t-manylinux_2_28_aarch64.whl", hash = "sha256:c064e28361c05d72eed8e744c9605cbd6d2bb7481a511c74071fd9b24bc65d7d", size = 44892060, upload-time = "2025-10-24T10:07:26.002Z" },
+ { url = "https://files.pythonhosted.org/packages/f8/ca/2f8804edd6279f78a37062d813de3f16f29183874447ef6d1aadbb4efa0f/pyarrow-22.0.0-cp313-cp313t-manylinux_2_28_x86_64.whl", hash = "sha256:6f9762274496c244d951c819348afbcf212714902742225f649cf02823a6a10f", size = 47504395, upload-time = "2025-10-24T10:07:34.09Z" },
+ { url = "https://files.pythonhosted.org/packages/b9/f0/77aa5198fd3943682b2e4faaf179a674f0edea0d55d326d83cb2277d9363/pyarrow-22.0.0-cp313-cp313t-musllinux_1_2_aarch64.whl", hash = "sha256:a9d9ffdc2ab696f6b15b4d1f7cec6658e1d788124418cb30030afbae31c64746", size = 48066216, upload-time = "2025-10-24T10:07:43.528Z" },
+ { url = "https://files.pythonhosted.org/packages/79/87/a1937b6e78b2aff18b706d738c9e46ade5bfcf11b294e39c87706a0089ac/pyarrow-22.0.0-cp313-cp313t-musllinux_1_2_x86_64.whl", hash = "sha256:ec1a15968a9d80da01e1d30349b2b0d7cc91e96588ee324ce1b5228175043e95", size = 50288552, upload-time = "2025-10-24T10:07:53.519Z" },
+ { url = "https://files.pythonhosted.org/packages/60/ae/b5a5811e11f25788ccfdaa8f26b6791c9807119dffcf80514505527c384c/pyarrow-22.0.0-cp313-cp313t-win_amd64.whl", hash = "sha256:bba208d9c7decf9961998edf5c65e3ea4355d5818dd6cd0f6809bec1afb951cc", size = 28262504, upload-time = "2025-10-24T10:08:00.932Z" },
+ { url = "https://files.pythonhosted.org/packages/bd/b0/0fa4d28a8edb42b0a7144edd20befd04173ac79819547216f8a9f36f9e50/pyarrow-22.0.0-cp314-cp314-macosx_12_0_arm64.whl", hash = "sha256:9bddc2cade6561f6820d4cd73f99a0243532ad506bc510a75a5a65a522b2d74d", size = 34224062, upload-time = "2025-10-24T10:08:14.101Z" },
+ { url = "https://files.pythonhosted.org/packages/0f/a8/7a719076b3c1be0acef56a07220c586f25cd24de0e3f3102b438d18ae5df/pyarrow-22.0.0-cp314-cp314-macosx_12_0_x86_64.whl", hash = "sha256:e70ff90c64419709d38c8932ea9fe1cc98415c4f87ea8da81719e43f02534bc9", size = 35990057, upload-time = "2025-10-24T10:08:21.842Z" },
+ { url = "https://files.pythonhosted.org/packages/89/3c/359ed54c93b47fb6fe30ed16cdf50e3f0e8b9ccfb11b86218c3619ae50a8/pyarrow-22.0.0-cp314-cp314-manylinux_2_28_aarch64.whl", hash = "sha256:92843c305330aa94a36e706c16209cd4df274693e777ca47112617db7d0ef3d7", size = 45068002, upload-time = "2025-10-24T10:08:29.034Z" },
+ { url = "https://files.pythonhosted.org/packages/55/fc/4945896cc8638536ee787a3bd6ce7cec8ec9acf452d78ec39ab328efa0a1/pyarrow-22.0.0-cp314-cp314-manylinux_2_28_x86_64.whl", hash = "sha256:6dda1ddac033d27421c20d7a7943eec60be44e0db4e079f33cc5af3b8280ccde", size = 47737765, upload-time = "2025-10-24T10:08:38.559Z" },
+ { url = "https://files.pythonhosted.org/packages/cd/5e/7cb7edeb2abfaa1f79b5d5eb89432356155c8426f75d3753cbcb9592c0fd/pyarrow-22.0.0-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:84378110dd9a6c06323b41b56e129c504d157d1a983ce8f5443761eb5256bafc", size = 48048139, upload-time = "2025-10-24T10:08:46.784Z" },
+ { url = "https://files.pythonhosted.org/packages/88/c6/546baa7c48185f5e9d6e59277c4b19f30f48c94d9dd938c2a80d4d6b067c/pyarrow-22.0.0-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:854794239111d2b88b40b6ef92aa478024d1e5074f364033e73e21e3f76b25e0", size = 50314244, upload-time = "2025-10-24T10:08:55.771Z" },
+ { url = "https://files.pythonhosted.org/packages/3c/79/755ff2d145aafec8d347bf18f95e4e81c00127f06d080135dfc86aea417c/pyarrow-22.0.0-cp314-cp314-win_amd64.whl", hash = "sha256:b883fe6fd85adad7932b3271c38ac289c65b7337c2c132e9569f9d3940620730", size = 28757501, upload-time = "2025-10-24T10:09:59.891Z" },
+ { url = "https://files.pythonhosted.org/packages/0e/d2/237d75ac28ced3147912954e3c1a174df43a95f4f88e467809118a8165e0/pyarrow-22.0.0-cp314-cp314t-macosx_12_0_arm64.whl", hash = "sha256:7a820d8ae11facf32585507c11f04e3f38343c1e784c9b5a8b1da5c930547fe2", size = 34355506, upload-time = "2025-10-24T10:09:02.953Z" },
+ { url = "https://files.pythonhosted.org/packages/1e/2c/733dfffe6d3069740f98e57ff81007809067d68626c5faef293434d11bd6/pyarrow-22.0.0-cp314-cp314t-macosx_12_0_x86_64.whl", hash = "sha256:c6ec3675d98915bf1ec8b3c7986422682f7232ea76cad276f4c8abd5b7319b70", size = 36047312, upload-time = "2025-10-24T10:09:10.334Z" },
+ { url = "https://files.pythonhosted.org/packages/7c/2b/29d6e3782dc1f299727462c1543af357a0f2c1d3c160ce199950d9ca51eb/pyarrow-22.0.0-cp314-cp314t-manylinux_2_28_aarch64.whl", hash = "sha256:3e739edd001b04f654b166204fc7a9de896cf6007eaff33409ee9e50ceaff754", size = 45081609, upload-time = "2025-10-24T10:09:18.61Z" },
+ { url = "https://files.pythonhosted.org/packages/8d/42/aa9355ecc05997915af1b7b947a7f66c02dcaa927f3203b87871c114ba10/pyarrow-22.0.0-cp314-cp314t-manylinux_2_28_x86_64.whl", hash = "sha256:7388ac685cab5b279a41dfe0a6ccd99e4dbf322edfb63e02fc0443bf24134e91", size = 47703663, upload-time = "2025-10-24T10:09:27.369Z" },
+ { url = "https://files.pythonhosted.org/packages/ee/62/45abedde480168e83a1de005b7b7043fd553321c1e8c5a9a114425f64842/pyarrow-22.0.0-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:f633074f36dbc33d5c05b5dc75371e5660f1dbf9c8b1d95669def05e5425989c", size = 48066543, upload-time = "2025-10-24T10:09:34.908Z" },
+ { url = "https://files.pythonhosted.org/packages/84/e9/7878940a5b072e4f3bf998770acafeae13b267f9893af5f6d4ab3904b67e/pyarrow-22.0.0-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:4c19236ae2402a8663a2c8f21f1870a03cc57f0bef7e4b6eb3238cc82944de80", size = 50288838, upload-time = "2025-10-24T10:09:44.394Z" },
+ { url = "https://files.pythonhosted.org/packages/7b/03/f335d6c52b4a4761bcc83499789a1e2e16d9d201a58c327a9b5cc9a41bd9/pyarrow-22.0.0-cp314-cp314t-win_amd64.whl", hash = "sha256:0c34fe18094686194f204a3b1787a27456897d8a2d62caf84b61e8dfbc0252ae", size = 29185594, upload-time = "2025-10-24T10:09:53.111Z" },
+]
+
+[[package]]
+name = "pycparser"
+version = "2.23"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/fe/cf/d2d3b9f5699fb1e4615c8e32ff220203e43b248e1dfcc6736ad9057731ca/pycparser-2.23.tar.gz", hash = "sha256:78816d4f24add8f10a06d6f05b4d424ad9e96cfebf68a4ddc99c65c0720d00c2", size = 173734, upload-time = "2025-09-09T13:23:47.91Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/a0/e3/59cd50310fc9b59512193629e1984c1f95e5c8ae6e5d8c69532ccc65a7fe/pycparser-2.23-py3-none-any.whl", hash = "sha256:e5c6e8d3fbad53479cab09ac03729e0a9faf2bee3db8208a550daf5af81a5934", size = 118140, upload-time = "2025-09-09T13:23:46.651Z" },
+]
+
+[[package]]
+name = "pydantic"
+version = "2.12.5"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "annotated-types" },
+ { name = "pydantic-core" },
+ { name = "typing-extensions" },
+ { name = "typing-inspection" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/69/44/36f1a6e523abc58ae5f928898e4aca2e0ea509b5aa6f6f392a5d882be928/pydantic-2.12.5.tar.gz", hash = "sha256:4d351024c75c0f085a9febbb665ce8c0c6ec5d30e903bdb6394b7ede26aebb49", size = 821591, upload-time = "2025-11-26T15:11:46.471Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/5a/87/b70ad306ebb6f9b585f114d0ac2137d792b48be34d732d60e597c2f8465a/pydantic-2.12.5-py3-none-any.whl", hash = "sha256:e561593fccf61e8a20fc46dfc2dfe075b8be7d0188df33f221ad1f0139180f9d", size = 463580, upload-time = "2025-11-26T15:11:44.605Z" },
+]
+
+[[package]]
+name = "pydantic-core"
+version = "2.41.5"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "typing-extensions" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/71/70/23b021c950c2addd24ec408e9ab05d59b035b39d97cdc1130e1bce647bb6/pydantic_core-2.41.5.tar.gz", hash = "sha256:08daa51ea16ad373ffd5e7606252cc32f07bc72b28284b6bc9c6df804816476e", size = 460952, upload-time = "2025-11-04T13:43:49.098Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/5f/5d/5f6c63eebb5afee93bcaae4ce9a898f3373ca23df3ccaef086d0233a35a7/pydantic_core-2.41.5-cp312-cp312-macosx_10_12_x86_64.whl", hash = "sha256:f41a7489d32336dbf2199c8c0a215390a751c5b014c2c1c5366e817202e9cdf7", size = 2110990, upload-time = "2025-11-04T13:39:58.079Z" },
+ { url = "https://files.pythonhosted.org/packages/aa/32/9c2e8ccb57c01111e0fd091f236c7b371c1bccea0fa85247ac55b1e2b6b6/pydantic_core-2.41.5-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:070259a8818988b9a84a449a2a7337c7f430a22acc0859c6b110aa7212a6d9c0", size = 1896003, upload-time = "2025-11-04T13:39:59.956Z" },
+ { url = "https://files.pythonhosted.org/packages/68/b8/a01b53cb0e59139fbc9e4fda3e9724ede8de279097179be4ff31f1abb65a/pydantic_core-2.41.5-cp312-cp312-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:e96cea19e34778f8d59fe40775a7a574d95816eb150850a85a7a4c8f4b94ac69", size = 1919200, upload-time = "2025-11-04T13:40:02.241Z" },
+ { url = "https://files.pythonhosted.org/packages/38/de/8c36b5198a29bdaade07b5985e80a233a5ac27137846f3bc2d3b40a47360/pydantic_core-2.41.5-cp312-cp312-manylinux_2_17_armv7l.manylinux2014_armv7l.whl", hash = "sha256:ed2e99c456e3fadd05c991f8f437ef902e00eedf34320ba2b0842bd1c3ca3a75", size = 2052578, upload-time = "2025-11-04T13:40:04.401Z" },
+ { url = "https://files.pythonhosted.org/packages/00/b5/0e8e4b5b081eac6cb3dbb7e60a65907549a1ce035a724368c330112adfdd/pydantic_core-2.41.5-cp312-cp312-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:65840751b72fbfd82c3c640cff9284545342a4f1eb1586ad0636955b261b0b05", size = 2208504, upload-time = "2025-11-04T13:40:06.072Z" },
+ { url = "https://files.pythonhosted.org/packages/77/56/87a61aad59c7c5b9dc8caad5a41a5545cba3810c3e828708b3d7404f6cef/pydantic_core-2.41.5-cp312-cp312-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:e536c98a7626a98feb2d3eaf75944ef6f3dbee447e1f841eae16f2f0a72d8ddc", size = 2335816, upload-time = "2025-11-04T13:40:07.835Z" },
+ { url = "https://files.pythonhosted.org/packages/0d/76/941cc9f73529988688a665a5c0ecff1112b3d95ab48f81db5f7606f522d3/pydantic_core-2.41.5-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:eceb81a8d74f9267ef4081e246ffd6d129da5d87e37a77c9bde550cb04870c1c", size = 2075366, upload-time = "2025-11-04T13:40:09.804Z" },
+ { url = "https://files.pythonhosted.org/packages/d3/43/ebef01f69baa07a482844faaa0a591bad1ef129253ffd0cdaa9d8a7f72d3/pydantic_core-2.41.5-cp312-cp312-manylinux_2_5_i686.manylinux1_i686.whl", hash = "sha256:d38548150c39b74aeeb0ce8ee1d8e82696f4a4e16ddc6de7b1d8823f7de4b9b5", size = 2171698, upload-time = "2025-11-04T13:40:12.004Z" },
+ { url = "https://files.pythonhosted.org/packages/b1/87/41f3202e4193e3bacfc2c065fab7706ebe81af46a83d3e27605029c1f5a6/pydantic_core-2.41.5-cp312-cp312-musllinux_1_1_aarch64.whl", hash = "sha256:c23e27686783f60290e36827f9c626e63154b82b116d7fe9adba1fda36da706c", size = 2132603, upload-time = "2025-11-04T13:40:13.868Z" },
+ { url = "https://files.pythonhosted.org/packages/49/7d/4c00df99cb12070b6bccdef4a195255e6020a550d572768d92cc54dba91a/pydantic_core-2.41.5-cp312-cp312-musllinux_1_1_armv7l.whl", hash = "sha256:482c982f814460eabe1d3bb0adfdc583387bd4691ef00b90575ca0d2b6fe2294", size = 2329591, upload-time = "2025-11-04T13:40:15.672Z" },
+ { url = "https://files.pythonhosted.org/packages/cc/6a/ebf4b1d65d458f3cda6a7335d141305dfa19bdc61140a884d165a8a1bbc7/pydantic_core-2.41.5-cp312-cp312-musllinux_1_1_x86_64.whl", hash = "sha256:bfea2a5f0b4d8d43adf9d7b8bf019fb46fdd10a2e5cde477fbcb9d1fa08c68e1", size = 2319068, upload-time = "2025-11-04T13:40:17.532Z" },
+ { url = "https://files.pythonhosted.org/packages/49/3b/774f2b5cd4192d5ab75870ce4381fd89cf218af999515baf07e7206753f0/pydantic_core-2.41.5-cp312-cp312-win32.whl", hash = "sha256:b74557b16e390ec12dca509bce9264c3bbd128f8a2c376eaa68003d7f327276d", size = 1985908, upload-time = "2025-11-04T13:40:19.309Z" },
+ { url = "https://files.pythonhosted.org/packages/86/45/00173a033c801cacf67c190fef088789394feaf88a98a7035b0e40d53dc9/pydantic_core-2.41.5-cp312-cp312-win_amd64.whl", hash = "sha256:1962293292865bca8e54702b08a4f26da73adc83dd1fcf26fbc875b35d81c815", size = 2020145, upload-time = "2025-11-04T13:40:21.548Z" },
+ { url = "https://files.pythonhosted.org/packages/f9/22/91fbc821fa6d261b376a3f73809f907cec5ca6025642c463d3488aad22fb/pydantic_core-2.41.5-cp312-cp312-win_arm64.whl", hash = "sha256:1746d4a3d9a794cacae06a5eaaccb4b8643a131d45fbc9af23e353dc0a5ba5c3", size = 1976179, upload-time = "2025-11-04T13:40:23.393Z" },
+ { url = "https://files.pythonhosted.org/packages/87/06/8806241ff1f70d9939f9af039c6c35f2360cf16e93c2ca76f184e76b1564/pydantic_core-2.41.5-cp313-cp313-macosx_10_12_x86_64.whl", hash = "sha256:941103c9be18ac8daf7b7adca8228f8ed6bb7a1849020f643b3a14d15b1924d9", size = 2120403, upload-time = "2025-11-04T13:40:25.248Z" },
+ { url = "https://files.pythonhosted.org/packages/94/02/abfa0e0bda67faa65fef1c84971c7e45928e108fe24333c81f3bfe35d5f5/pydantic_core-2.41.5-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:112e305c3314f40c93998e567879e887a3160bb8689ef3d2c04b6cc62c33ac34", size = 1896206, upload-time = "2025-11-04T13:40:27.099Z" },
+ { url = "https://files.pythonhosted.org/packages/15/df/a4c740c0943e93e6500f9eb23f4ca7ec9bf71b19e608ae5b579678c8d02f/pydantic_core-2.41.5-cp313-cp313-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:0cbaad15cb0c90aa221d43c00e77bb33c93e8d36e0bf74760cd00e732d10a6a0", size = 1919307, upload-time = "2025-11-04T13:40:29.806Z" },
+ { url = "https://files.pythonhosted.org/packages/9a/e3/6324802931ae1d123528988e0e86587c2072ac2e5394b4bc2bc34b61ff6e/pydantic_core-2.41.5-cp313-cp313-manylinux_2_17_armv7l.manylinux2014_armv7l.whl", hash = "sha256:03ca43e12fab6023fc79d28ca6b39b05f794ad08ec2feccc59a339b02f2b3d33", size = 2063258, upload-time = "2025-11-04T13:40:33.544Z" },
+ { url = "https://files.pythonhosted.org/packages/c9/d4/2230d7151d4957dd79c3044ea26346c148c98fbf0ee6ebd41056f2d62ab5/pydantic_core-2.41.5-cp313-cp313-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:dc799088c08fa04e43144b164feb0c13f9a0bc40503f8df3e9fde58a3c0c101e", size = 2214917, upload-time = "2025-11-04T13:40:35.479Z" },
+ { url = "https://files.pythonhosted.org/packages/e6/9f/eaac5df17a3672fef0081b6c1bb0b82b33ee89aa5cec0d7b05f52fd4a1fa/pydantic_core-2.41.5-cp313-cp313-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:97aeba56665b4c3235a0e52b2c2f5ae9cd071b8a8310ad27bddb3f7fb30e9aa2", size = 2332186, upload-time = "2025-11-04T13:40:37.436Z" },
+ { url = "https://files.pythonhosted.org/packages/cf/4e/35a80cae583a37cf15604b44240e45c05e04e86f9cfd766623149297e971/pydantic_core-2.41.5-cp313-cp313-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:406bf18d345822d6c21366031003612b9c77b3e29ffdb0f612367352aab7d586", size = 2073164, upload-time = "2025-11-04T13:40:40.289Z" },
+ { url = "https://files.pythonhosted.org/packages/bf/e3/f6e262673c6140dd3305d144d032f7bd5f7497d3871c1428521f19f9efa2/pydantic_core-2.41.5-cp313-cp313-manylinux_2_5_i686.manylinux1_i686.whl", hash = "sha256:b93590ae81f7010dbe380cdeab6f515902ebcbefe0b9327cc4804d74e93ae69d", size = 2179146, upload-time = "2025-11-04T13:40:42.809Z" },
+ { url = "https://files.pythonhosted.org/packages/75/c7/20bd7fc05f0c6ea2056a4565c6f36f8968c0924f19b7d97bbfea55780e73/pydantic_core-2.41.5-cp313-cp313-musllinux_1_1_aarch64.whl", hash = "sha256:01a3d0ab748ee531f4ea6c3e48ad9dac84ddba4b0d82291f87248f2f9de8d740", size = 2137788, upload-time = "2025-11-04T13:40:44.752Z" },
+ { url = "https://files.pythonhosted.org/packages/3a/8d/34318ef985c45196e004bc46c6eab2eda437e744c124ef0dbe1ff2c9d06b/pydantic_core-2.41.5-cp313-cp313-musllinux_1_1_armv7l.whl", hash = "sha256:6561e94ba9dacc9c61bce40e2d6bdc3bfaa0259d3ff36ace3b1e6901936d2e3e", size = 2340133, upload-time = "2025-11-04T13:40:46.66Z" },
+ { url = "https://files.pythonhosted.org/packages/9c/59/013626bf8c78a5a5d9350d12e7697d3d4de951a75565496abd40ccd46bee/pydantic_core-2.41.5-cp313-cp313-musllinux_1_1_x86_64.whl", hash = "sha256:915c3d10f81bec3a74fbd4faebe8391013ba61e5a1a8d48c4455b923bdda7858", size = 2324852, upload-time = "2025-11-04T13:40:48.575Z" },
+ { url = "https://files.pythonhosted.org/packages/1a/d9/c248c103856f807ef70c18a4f986693a46a8ffe1602e5d361485da502d20/pydantic_core-2.41.5-cp313-cp313-win32.whl", hash = "sha256:650ae77860b45cfa6e2cdafc42618ceafab3a2d9a3811fcfbd3bbf8ac3c40d36", size = 1994679, upload-time = "2025-11-04T13:40:50.619Z" },
+ { url = "https://files.pythonhosted.org/packages/9e/8b/341991b158ddab181cff136acd2552c9f35bd30380422a639c0671e99a91/pydantic_core-2.41.5-cp313-cp313-win_amd64.whl", hash = "sha256:79ec52ec461e99e13791ec6508c722742ad745571f234ea6255bed38c6480f11", size = 2019766, upload-time = "2025-11-04T13:40:52.631Z" },
+ { url = "https://files.pythonhosted.org/packages/73/7d/f2f9db34af103bea3e09735bb40b021788a5e834c81eedb541991badf8f5/pydantic_core-2.41.5-cp313-cp313-win_arm64.whl", hash = "sha256:3f84d5c1b4ab906093bdc1ff10484838aca54ef08de4afa9de0f5f14d69639cd", size = 1981005, upload-time = "2025-11-04T13:40:54.734Z" },
+ { url = "https://files.pythonhosted.org/packages/ea/28/46b7c5c9635ae96ea0fbb779e271a38129df2550f763937659ee6c5dbc65/pydantic_core-2.41.5-cp314-cp314-macosx_10_12_x86_64.whl", hash = "sha256:3f37a19d7ebcdd20b96485056ba9e8b304e27d9904d233d7b1015db320e51f0a", size = 2119622, upload-time = "2025-11-04T13:40:56.68Z" },
+ { url = "https://files.pythonhosted.org/packages/74/1a/145646e5687e8d9a1e8d09acb278c8535ebe9e972e1f162ed338a622f193/pydantic_core-2.41.5-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:1d1d9764366c73f996edd17abb6d9d7649a7eb690006ab6adbda117717099b14", size = 1891725, upload-time = "2025-11-04T13:40:58.807Z" },
+ { url = "https://files.pythonhosted.org/packages/23/04/e89c29e267b8060b40dca97bfc64a19b2a3cf99018167ea1677d96368273/pydantic_core-2.41.5-cp314-cp314-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:25e1c2af0fce638d5f1988b686f3b3ea8cd7de5f244ca147c777769e798a9cd1", size = 1915040, upload-time = "2025-11-04T13:41:00.853Z" },
+ { url = "https://files.pythonhosted.org/packages/84/a3/15a82ac7bd97992a82257f777b3583d3e84bdb06ba6858f745daa2ec8a85/pydantic_core-2.41.5-cp314-cp314-manylinux_2_17_armv7l.manylinux2014_armv7l.whl", hash = "sha256:506d766a8727beef16b7adaeb8ee6217c64fc813646b424d0804d67c16eddb66", size = 2063691, upload-time = "2025-11-04T13:41:03.504Z" },
+ { url = "https://files.pythonhosted.org/packages/74/9b/0046701313c6ef08c0c1cf0e028c67c770a4e1275ca73131563c5f2a310a/pydantic_core-2.41.5-cp314-cp314-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:4819fa52133c9aa3c387b3328f25c1facc356491e6135b459f1de698ff64d869", size = 2213897, upload-time = "2025-11-04T13:41:05.804Z" },
+ { url = "https://files.pythonhosted.org/packages/8a/cd/6bac76ecd1b27e75a95ca3a9a559c643b3afcd2dd62086d4b7a32a18b169/pydantic_core-2.41.5-cp314-cp314-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:2b761d210c9ea91feda40d25b4efe82a1707da2ef62901466a42492c028553a2", size = 2333302, upload-time = "2025-11-04T13:41:07.809Z" },
+ { url = "https://files.pythonhosted.org/packages/4c/d2/ef2074dc020dd6e109611a8be4449b98cd25e1b9b8a303c2f0fca2f2bcf7/pydantic_core-2.41.5-cp314-cp314-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:22f0fb8c1c583a3b6f24df2470833b40207e907b90c928cc8d3594b76f874375", size = 2064877, upload-time = "2025-11-04T13:41:09.827Z" },
+ { url = "https://files.pythonhosted.org/packages/18/66/e9db17a9a763d72f03de903883c057b2592c09509ccfe468187f2a2eef29/pydantic_core-2.41.5-cp314-cp314-manylinux_2_5_i686.manylinux1_i686.whl", hash = "sha256:2782c870e99878c634505236d81e5443092fba820f0373997ff75f90f68cd553", size = 2180680, upload-time = "2025-11-04T13:41:12.379Z" },
+ { url = "https://files.pythonhosted.org/packages/d3/9e/3ce66cebb929f3ced22be85d4c2399b8e85b622db77dad36b73c5387f8f8/pydantic_core-2.41.5-cp314-cp314-musllinux_1_1_aarch64.whl", hash = "sha256:0177272f88ab8312479336e1d777f6b124537d47f2123f89cb37e0accea97f90", size = 2138960, upload-time = "2025-11-04T13:41:14.627Z" },
+ { url = "https://files.pythonhosted.org/packages/a6/62/205a998f4327d2079326b01abee48e502ea739d174f0a89295c481a2272e/pydantic_core-2.41.5-cp314-cp314-musllinux_1_1_armv7l.whl", hash = "sha256:63510af5e38f8955b8ee5687740d6ebf7c2a0886d15a6d65c32814613681bc07", size = 2339102, upload-time = "2025-11-04T13:41:16.868Z" },
+ { url = "https://files.pythonhosted.org/packages/3c/0d/f05e79471e889d74d3d88f5bd20d0ed189ad94c2423d81ff8d0000aab4ff/pydantic_core-2.41.5-cp314-cp314-musllinux_1_1_x86_64.whl", hash = "sha256:e56ba91f47764cc14f1daacd723e3e82d1a89d783f0f5afe9c364b8bb491ccdb", size = 2326039, upload-time = "2025-11-04T13:41:18.934Z" },
+ { url = "https://files.pythonhosted.org/packages/ec/e1/e08a6208bb100da7e0c4b288eed624a703f4d129bde2da475721a80cab32/pydantic_core-2.41.5-cp314-cp314-win32.whl", hash = "sha256:aec5cf2fd867b4ff45b9959f8b20ea3993fc93e63c7363fe6851424c8a7e7c23", size = 1995126, upload-time = "2025-11-04T13:41:21.418Z" },
+ { url = "https://files.pythonhosted.org/packages/48/5d/56ba7b24e9557f99c9237e29f5c09913c81eeb2f3217e40e922353668092/pydantic_core-2.41.5-cp314-cp314-win_amd64.whl", hash = "sha256:8e7c86f27c585ef37c35e56a96363ab8de4e549a95512445b85c96d3e2f7c1bf", size = 2015489, upload-time = "2025-11-04T13:41:24.076Z" },
+ { url = "https://files.pythonhosted.org/packages/4e/bb/f7a190991ec9e3e0ba22e4993d8755bbc4a32925c0b5b42775c03e8148f9/pydantic_core-2.41.5-cp314-cp314-win_arm64.whl", hash = "sha256:e672ba74fbc2dc8eea59fb6d4aed6845e6905fc2a8afe93175d94a83ba2a01a0", size = 1977288, upload-time = "2025-11-04T13:41:26.33Z" },
+ { url = "https://files.pythonhosted.org/packages/92/ed/77542d0c51538e32e15afe7899d79efce4b81eee631d99850edc2f5e9349/pydantic_core-2.41.5-cp314-cp314t-macosx_10_12_x86_64.whl", hash = "sha256:8566def80554c3faa0e65ac30ab0932b9e3a5cd7f8323764303d468e5c37595a", size = 2120255, upload-time = "2025-11-04T13:41:28.569Z" },
+ { url = "https://files.pythonhosted.org/packages/bb/3d/6913dde84d5be21e284439676168b28d8bbba5600d838b9dca99de0fad71/pydantic_core-2.41.5-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:b80aa5095cd3109962a298ce14110ae16b8c1aece8b72f9dafe81cf597ad80b3", size = 1863760, upload-time = "2025-11-04T13:41:31.055Z" },
+ { url = "https://files.pythonhosted.org/packages/5a/f0/e5e6b99d4191da102f2b0eb9687aaa7f5bea5d9964071a84effc3e40f997/pydantic_core-2.41.5-cp314-cp314t-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:3006c3dd9ba34b0c094c544c6006cc79e87d8612999f1a5d43b769b89181f23c", size = 1878092, upload-time = "2025-11-04T13:41:33.21Z" },
+ { url = "https://files.pythonhosted.org/packages/71/48/36fb760642d568925953bcc8116455513d6e34c4beaa37544118c36aba6d/pydantic_core-2.41.5-cp314-cp314t-manylinux_2_17_armv7l.manylinux2014_armv7l.whl", hash = "sha256:72f6c8b11857a856bcfa48c86f5368439f74453563f951e473514579d44aa612", size = 2053385, upload-time = "2025-11-04T13:41:35.508Z" },
+ { url = "https://files.pythonhosted.org/packages/20/25/92dc684dd8eb75a234bc1c764b4210cf2646479d54b47bf46061657292a8/pydantic_core-2.41.5-cp314-cp314t-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:5cb1b2f9742240e4bb26b652a5aeb840aa4b417c7748b6f8387927bc6e45e40d", size = 2218832, upload-time = "2025-11-04T13:41:37.732Z" },
+ { url = "https://files.pythonhosted.org/packages/e2/09/f53e0b05023d3e30357d82eb35835d0f6340ca344720a4599cd663dca599/pydantic_core-2.41.5-cp314-cp314t-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:bd3d54f38609ff308209bd43acea66061494157703364ae40c951f83ba99a1a9", size = 2327585, upload-time = "2025-11-04T13:41:40Z" },
+ { url = "https://files.pythonhosted.org/packages/aa/4e/2ae1aa85d6af35a39b236b1b1641de73f5a6ac4d5a7509f77b814885760c/pydantic_core-2.41.5-cp314-cp314t-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:2ff4321e56e879ee8d2a879501c8e469414d948f4aba74a2d4593184eb326660", size = 2041078, upload-time = "2025-11-04T13:41:42.323Z" },
+ { url = "https://files.pythonhosted.org/packages/cd/13/2e215f17f0ef326fc72afe94776edb77525142c693767fc347ed6288728d/pydantic_core-2.41.5-cp314-cp314t-manylinux_2_5_i686.manylinux1_i686.whl", hash = "sha256:d0d2568a8c11bf8225044aa94409e21da0cb09dcdafe9ecd10250b2baad531a9", size = 2173914, upload-time = "2025-11-04T13:41:45.221Z" },
+ { url = "https://files.pythonhosted.org/packages/02/7a/f999a6dcbcd0e5660bc348a3991c8915ce6599f4f2c6ac22f01d7a10816c/pydantic_core-2.41.5-cp314-cp314t-musllinux_1_1_aarch64.whl", hash = "sha256:a39455728aabd58ceabb03c90e12f71fd30fa69615760a075b9fec596456ccc3", size = 2129560, upload-time = "2025-11-04T13:41:47.474Z" },
+ { url = "https://files.pythonhosted.org/packages/3a/b1/6c990ac65e3b4c079a4fb9f5b05f5b013afa0f4ed6780a3dd236d2cbdc64/pydantic_core-2.41.5-cp314-cp314t-musllinux_1_1_armv7l.whl", hash = "sha256:239edca560d05757817c13dc17c50766136d21f7cd0fac50295499ae24f90fdf", size = 2329244, upload-time = "2025-11-04T13:41:49.992Z" },
+ { url = "https://files.pythonhosted.org/packages/d9/02/3c562f3a51afd4d88fff8dffb1771b30cfdfd79befd9883ee094f5b6c0d8/pydantic_core-2.41.5-cp314-cp314t-musllinux_1_1_x86_64.whl", hash = "sha256:2a5e06546e19f24c6a96a129142a75cee553cc018ffee48a460059b1185f4470", size = 2331955, upload-time = "2025-11-04T13:41:54.079Z" },
+ { url = "https://files.pythonhosted.org/packages/5c/96/5fb7d8c3c17bc8c62fdb031c47d77a1af698f1d7a406b0f79aaa1338f9ad/pydantic_core-2.41.5-cp314-cp314t-win32.whl", hash = "sha256:b4ececa40ac28afa90871c2cc2b9ffd2ff0bf749380fbdf57d165fd23da353aa", size = 1988906, upload-time = "2025-11-04T13:41:56.606Z" },
+ { url = "https://files.pythonhosted.org/packages/22/ed/182129d83032702912c2e2d8bbe33c036f342cc735737064668585dac28f/pydantic_core-2.41.5-cp314-cp314t-win_amd64.whl", hash = "sha256:80aa89cad80b32a912a65332f64a4450ed00966111b6615ca6816153d3585a8c", size = 1981607, upload-time = "2025-11-04T13:41:58.889Z" },
+ { url = "https://files.pythonhosted.org/packages/9f/ed/068e41660b832bb0b1aa5b58011dea2a3fe0ba7861ff38c4d4904c1c1a99/pydantic_core-2.41.5-cp314-cp314t-win_arm64.whl", hash = "sha256:35b44f37a3199f771c3eaa53051bc8a70cd7b54f333531c59e29fd4db5d15008", size = 1974769, upload-time = "2025-11-04T13:42:01.186Z" },
+ { url = "https://files.pythonhosted.org/packages/09/32/59b0c7e63e277fa7911c2fc70ccfb45ce4b98991e7ef37110663437005af/pydantic_core-2.41.5-graalpy312-graalpy250_312_native-macosx_10_12_x86_64.whl", hash = "sha256:7da7087d756b19037bc2c06edc6c170eeef3c3bafcb8f532ff17d64dc427adfd", size = 2110495, upload-time = "2025-11-04T13:42:49.689Z" },
+ { url = "https://files.pythonhosted.org/packages/aa/81/05e400037eaf55ad400bcd318c05bb345b57e708887f07ddb2d20e3f0e98/pydantic_core-2.41.5-graalpy312-graalpy250_312_native-macosx_11_0_arm64.whl", hash = "sha256:aabf5777b5c8ca26f7824cb4a120a740c9588ed58df9b2d196ce92fba42ff8dc", size = 1915388, upload-time = "2025-11-04T13:42:52.215Z" },
+ { url = "https://files.pythonhosted.org/packages/6e/0d/e3549b2399f71d56476b77dbf3cf8937cec5cd70536bdc0e374a421d0599/pydantic_core-2.41.5-graalpy312-graalpy250_312_native-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:c007fe8a43d43b3969e8469004e9845944f1a80e6acd47c150856bb87f230c56", size = 1942879, upload-time = "2025-11-04T13:42:56.483Z" },
+ { url = "https://files.pythonhosted.org/packages/f7/07/34573da085946b6a313d7c42f82f16e8920bfd730665de2d11c0c37a74b5/pydantic_core-2.41.5-graalpy312-graalpy250_312_native-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:76d0819de158cd855d1cbb8fcafdf6f5cf1eb8e470abe056d5d161106e38062b", size = 2139017, upload-time = "2025-11-04T13:42:59.471Z" },
+]
+
+[[package]]
+name = "pygments"
+version = "2.19.2"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/b0/77/a5b8c569bf593b0140bde72ea885a803b82086995367bf2037de0159d924/pygments-2.19.2.tar.gz", hash = "sha256:636cb2477cec7f8952536970bc533bc43743542f70392ae026374600add5b887", size = 4968631, upload-time = "2025-06-21T13:39:12.283Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/c7/21/705964c7812476f378728bdf590ca4b771ec72385c533964653c68e86bdc/pygments-2.19.2-py3-none-any.whl", hash = "sha256:86540386c03d588bb81d44bc3928634ff26449851e99741617ecb9037ee5ec0b", size = 1225217, upload-time = "2025-06-21T13:39:07.939Z" },
+]
+
+[[package]]
+name = "pyparsing"
+version = "3.2.5"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/f2/a5/181488fc2b9d093e3972d2a472855aae8a03f000592dbfce716a512b3359/pyparsing-3.2.5.tar.gz", hash = "sha256:2df8d5b7b2802ef88e8d016a2eb9c7aeaa923529cd251ed0fe4608275d4105b6", size = 1099274, upload-time = "2025-09-21T04:11:06.277Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/10/5e/1aa9a93198c6b64513c9d7752de7422c06402de6600a8767da1524f9570b/pyparsing-3.2.5-py3-none-any.whl", hash = "sha256:e38a4f02064cf41fe6593d328d0512495ad1f3d8a91c4f73fc401b3079a59a5e", size = 113890, upload-time = "2025-09-21T04:11:04.117Z" },
+]
+
+[[package]]
+name = "python-dateutil"
+version = "2.9.0.post0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "six" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/66/c0/0c8b6ad9f17a802ee498c46e004a0eb49bc148f2fd230864601a86dcf6db/python-dateutil-2.9.0.post0.tar.gz", hash = "sha256:37dd54208da7e1cd875388217d5e00ebd4179249f90fb72437e91a35459a0ad3", size = 342432, upload-time = "2024-03-01T18:36:20.211Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/ec/57/56b9bcc3c9c6a792fcbaf139543cee77261f3651ca9da0c93f5c1221264b/python_dateutil-2.9.0.post0-py2.py3-none-any.whl", hash = "sha256:a8b2bc7bffae282281c8140a97d3aa9c14da0b136dfe83f850eea9a5f7470427", size = 229892, upload-time = "2024-03-01T18:36:18.57Z" },
+]
+
+[[package]]
+name = "python-debian"
+version = "1.0.1"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "charset-normalizer" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/bf/4b/3c4cf635311b6203f17c2d693dc15e898969983dd3f729bee3c428aa60d4/python-debian-1.0.1.tar.gz", hash = "sha256:3ada9b83a3d671b58081782c0969cffa0102f6ce433fbbc7cf21275b8b5cc771", size = 127249, upload-time = "2025-03-11T12:27:27.245Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/ba/15/e8096189b18dda72e4923622abc10b021ecff723b397e22eff29fb86637b/python_debian-1.0.1-py3-none-any.whl", hash = "sha256:8f137c230c1d9279c2ac892b35915068b2aca090c9fd3da5671ff87af32af12c", size = 137453, upload-time = "2025-03-11T12:27:25.014Z" },
+]
+
+[[package]]
+name = "python-json-logger"
+version = "4.0.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/29/bf/eca6a3d43db1dae7070f70e160ab20b807627ba953663ba07928cdd3dc58/python_json_logger-4.0.0.tar.gz", hash = "sha256:f58e68eb46e1faed27e0f574a55a0455eecd7b8a5b88b85a784519ba3cff047f", size = 17683, upload-time = "2025-10-06T04:15:18.984Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/51/e5/fecf13f06e5e5f67e8837d777d1bc43fac0ed2b77a676804df5c34744727/python_json_logger-4.0.0-py3-none-any.whl", hash = "sha256:af09c9daf6a813aa4cc7180395f50f2a9e5fa056034c9953aec92e381c5ba1e2", size = 15548, upload-time = "2025-10-06T04:15:17.553Z" },
+]
+
+[[package]]
+name = "python-magic"
+version = "0.4.27"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/da/db/0b3e28ac047452d079d375ec6798bf76a036a08182dbb39ed38116a49130/python-magic-0.4.27.tar.gz", hash = "sha256:c1ba14b08e4a5f5c31a302b7721239695b2f0f058d125bd5ce1ee36b9d9d3c3b", size = 14677, upload-time = "2022-06-07T20:16:59.508Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/6c/73/9f872cb81fc5c3bb48f7227872c28975f998f3e7c2b1c16e95e6432bbb90/python_magic-0.4.27-py2.py3-none-any.whl", hash = "sha256:c212960ad306f700aa0d01e5d7a325d20548ff97eb9920dcd29513174f0294d3", size = 13840, upload-time = "2022-06-07T20:16:57.763Z" },
+]
+
+[[package]]
+name = "pytz"
+version = "2025.2"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/f8/bf/abbd3cdfb8fbc7fb3d4d38d320f2441b1e7cbe29be4f23797b4a2b5d8aac/pytz-2025.2.tar.gz", hash = "sha256:360b9e3dbb49a209c21ad61809c7fb453643e048b38924c765813546746e81c3", size = 320884, upload-time = "2025-03-25T02:25:00.538Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/81/c4/34e93fe5f5429d7570ec1fa436f1986fb1f00c3e0f43a589fe2bbcd22c3f/pytz-2025.2-py2.py3-none-any.whl", hash = "sha256:5ddf76296dd8c44c26eb8f4b6f35488f3ccbf6fbbd7adee0b7262d43f0ec2f00", size = 509225, upload-time = "2025-03-25T02:24:58.468Z" },
+]
+
+[[package]]
+name = "pywinpty"
+version = "3.0.2"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/f3/bb/a7cc2967c5c4eceb6cc49cfe39447d4bfc56e6c865e7c2249b6eb978935f/pywinpty-3.0.2.tar.gz", hash = "sha256:1505cc4cb248af42cb6285a65c9c2086ee9e7e574078ee60933d5d7fa86fb004", size = 30669, upload-time = "2025-10-03T21:16:29.205Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/02/4e/1098484e042c9485f56f16eb2b69b43b874bd526044ee401512234cf9e04/pywinpty-3.0.2-cp312-cp312-win_amd64.whl", hash = "sha256:99fdd9b455f0ad6419aba6731a7a0d2f88ced83c3c94a80ff9533d95fa8d8a9e", size = 2050391, upload-time = "2025-10-03T21:19:01.642Z" },
+ { url = "https://files.pythonhosted.org/packages/fc/19/b757fe28008236a4a713e813283721b8a40aa60cd7d3f83549f2e25a3155/pywinpty-3.0.2-cp313-cp313-win_amd64.whl", hash = "sha256:18f78b81e4cfee6aabe7ea8688441d30247b73e52cd9657138015c5f4ee13a51", size = 2050057, upload-time = "2025-10-03T21:19:26.732Z" },
+ { url = "https://files.pythonhosted.org/packages/cb/44/cbae12ecf6f4fa4129c36871fd09c6bef4f98d5f625ecefb5e2449765508/pywinpty-3.0.2-cp313-cp313t-win_amd64.whl", hash = "sha256:663383ecfab7fc382cc97ea5c4f7f0bb32c2f889259855df6ea34e5df42d305b", size = 2049874, upload-time = "2025-10-03T21:18:53.923Z" },
+ { url = "https://files.pythonhosted.org/packages/ca/15/f12c6055e2d7a617d4d5820e8ac4ceaff849da4cb124640ef5116a230771/pywinpty-3.0.2-cp314-cp314-win_amd64.whl", hash = "sha256:28297cecc37bee9f24d8889e47231972d6e9e84f7b668909de54f36ca785029a", size = 2050386, upload-time = "2025-10-03T21:18:50.477Z" },
+ { url = "https://files.pythonhosted.org/packages/de/24/c6907c5bb06043df98ad6a0a0ff5db2e0affcecbc3b15c42404393a3f72a/pywinpty-3.0.2-cp314-cp314t-win_amd64.whl", hash = "sha256:34b55ae9a1b671fe3eae071d86618110538e8eaad18fcb1531c0830b91a82767", size = 2049834, upload-time = "2025-10-03T21:19:25.688Z" },
+]
+
+[[package]]
+name = "pyyaml"
+version = "6.0.3"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/05/8e/961c0007c59b8dd7729d542c61a4d537767a59645b82a0b521206e1e25c2/pyyaml-6.0.3.tar.gz", hash = "sha256:d76623373421df22fb4cf8817020cbb7ef15c725b9d5e45f17e189bfc384190f", size = 130960, upload-time = "2025-09-25T21:33:16.546Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/d1/33/422b98d2195232ca1826284a76852ad5a86fe23e31b009c9886b2d0fb8b2/pyyaml-6.0.3-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:7f047e29dcae44602496db43be01ad42fc6f1cc0d8cd6c83d342306c32270196", size = 182063, upload-time = "2025-09-25T21:32:11.445Z" },
+ { url = "https://files.pythonhosted.org/packages/89/a0/6cf41a19a1f2f3feab0e9c0b74134aa2ce6849093d5517a0c550fe37a648/pyyaml-6.0.3-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:fc09d0aa354569bc501d4e787133afc08552722d3ab34836a80547331bb5d4a0", size = 173973, upload-time = "2025-09-25T21:32:12.492Z" },
+ { url = "https://files.pythonhosted.org/packages/ed/23/7a778b6bd0b9a8039df8b1b1d80e2e2ad78aa04171592c8a5c43a56a6af4/pyyaml-6.0.3-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:9149cad251584d5fb4981be1ecde53a1ca46c891a79788c0df828d2f166bda28", size = 775116, upload-time = "2025-09-25T21:32:13.652Z" },
+ { url = "https://files.pythonhosted.org/packages/65/30/d7353c338e12baef4ecc1b09e877c1970bd3382789c159b4f89d6a70dc09/pyyaml-6.0.3-cp312-cp312-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:5fdec68f91a0c6739b380c83b951e2c72ac0197ace422360e6d5a959d8d97b2c", size = 844011, upload-time = "2025-09-25T21:32:15.21Z" },
+ { url = "https://files.pythonhosted.org/packages/8b/9d/b3589d3877982d4f2329302ef98a8026e7f4443c765c46cfecc8858c6b4b/pyyaml-6.0.3-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:ba1cc08a7ccde2d2ec775841541641e4548226580ab850948cbfda66a1befcdc", size = 807870, upload-time = "2025-09-25T21:32:16.431Z" },
+ { url = "https://files.pythonhosted.org/packages/05/c0/b3be26a015601b822b97d9149ff8cb5ead58c66f981e04fedf4e762f4bd4/pyyaml-6.0.3-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:8dc52c23056b9ddd46818a57b78404882310fb473d63f17b07d5c40421e47f8e", size = 761089, upload-time = "2025-09-25T21:32:17.56Z" },
+ { url = "https://files.pythonhosted.org/packages/be/8e/98435a21d1d4b46590d5459a22d88128103f8da4c2d4cb8f14f2a96504e1/pyyaml-6.0.3-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:41715c910c881bc081f1e8872880d3c650acf13dfa8214bad49ed4cede7c34ea", size = 790181, upload-time = "2025-09-25T21:32:18.834Z" },
+ { url = "https://files.pythonhosted.org/packages/74/93/7baea19427dcfbe1e5a372d81473250b379f04b1bd3c4c5ff825e2327202/pyyaml-6.0.3-cp312-cp312-win32.whl", hash = "sha256:96b533f0e99f6579b3d4d4995707cf36df9100d67e0c8303a0c55b27b5f99bc5", size = 137658, upload-time = "2025-09-25T21:32:20.209Z" },
+ { url = "https://files.pythonhosted.org/packages/86/bf/899e81e4cce32febab4fb42bb97dcdf66bc135272882d1987881a4b519e9/pyyaml-6.0.3-cp312-cp312-win_amd64.whl", hash = "sha256:5fcd34e47f6e0b794d17de1b4ff496c00986e1c83f7ab2fb8fcfe9616ff7477b", size = 154003, upload-time = "2025-09-25T21:32:21.167Z" },
+ { url = "https://files.pythonhosted.org/packages/1a/08/67bd04656199bbb51dbed1439b7f27601dfb576fb864099c7ef0c3e55531/pyyaml-6.0.3-cp312-cp312-win_arm64.whl", hash = "sha256:64386e5e707d03a7e172c0701abfb7e10f0fb753ee1d773128192742712a98fd", size = 140344, upload-time = "2025-09-25T21:32:22.617Z" },
+ { url = "https://files.pythonhosted.org/packages/d1/11/0fd08f8192109f7169db964b5707a2f1e8b745d4e239b784a5a1dd80d1db/pyyaml-6.0.3-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:8da9669d359f02c0b91ccc01cac4a67f16afec0dac22c2ad09f46bee0697eba8", size = 181669, upload-time = "2025-09-25T21:32:23.673Z" },
+ { url = "https://files.pythonhosted.org/packages/b1/16/95309993f1d3748cd644e02e38b75d50cbc0d9561d21f390a76242ce073f/pyyaml-6.0.3-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:2283a07e2c21a2aa78d9c4442724ec1eb15f5e42a723b99cb3d822d48f5f7ad1", size = 173252, upload-time = "2025-09-25T21:32:25.149Z" },
+ { url = "https://files.pythonhosted.org/packages/50/31/b20f376d3f810b9b2371e72ef5adb33879b25edb7a6d072cb7ca0c486398/pyyaml-6.0.3-cp313-cp313-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:ee2922902c45ae8ccada2c5b501ab86c36525b883eff4255313a253a3160861c", size = 767081, upload-time = "2025-09-25T21:32:26.575Z" },
+ { url = "https://files.pythonhosted.org/packages/49/1e/a55ca81e949270d5d4432fbbd19dfea5321eda7c41a849d443dc92fd1ff7/pyyaml-6.0.3-cp313-cp313-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:a33284e20b78bd4a18c8c2282d549d10bc8408a2a7ff57653c0cf0b9be0afce5", size = 841159, upload-time = "2025-09-25T21:32:27.727Z" },
+ { url = "https://files.pythonhosted.org/packages/74/27/e5b8f34d02d9995b80abcef563ea1f8b56d20134d8f4e5e81733b1feceb2/pyyaml-6.0.3-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:0f29edc409a6392443abf94b9cf89ce99889a1dd5376d94316ae5145dfedd5d6", size = 801626, upload-time = "2025-09-25T21:32:28.878Z" },
+ { url = "https://files.pythonhosted.org/packages/f9/11/ba845c23988798f40e52ba45f34849aa8a1f2d4af4b798588010792ebad6/pyyaml-6.0.3-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:f7057c9a337546edc7973c0d3ba84ddcdf0daa14533c2065749c9075001090e6", size = 753613, upload-time = "2025-09-25T21:32:30.178Z" },
+ { url = "https://files.pythonhosted.org/packages/3d/e0/7966e1a7bfc0a45bf0a7fb6b98ea03fc9b8d84fa7f2229e9659680b69ee3/pyyaml-6.0.3-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:eda16858a3cab07b80edaf74336ece1f986ba330fdb8ee0d6c0d68fe82bc96be", size = 794115, upload-time = "2025-09-25T21:32:31.353Z" },
+ { url = "https://files.pythonhosted.org/packages/de/94/980b50a6531b3019e45ddeada0626d45fa85cbe22300844a7983285bed3b/pyyaml-6.0.3-cp313-cp313-win32.whl", hash = "sha256:d0eae10f8159e8fdad514efdc92d74fd8d682c933a6dd088030f3834bc8e6b26", size = 137427, upload-time = "2025-09-25T21:32:32.58Z" },
+ { url = "https://files.pythonhosted.org/packages/97/c9/39d5b874e8b28845e4ec2202b5da735d0199dbe5b8fb85f91398814a9a46/pyyaml-6.0.3-cp313-cp313-win_amd64.whl", hash = "sha256:79005a0d97d5ddabfeeea4cf676af11e647e41d81c9a7722a193022accdb6b7c", size = 154090, upload-time = "2025-09-25T21:32:33.659Z" },
+ { url = "https://files.pythonhosted.org/packages/73/e8/2bdf3ca2090f68bb3d75b44da7bbc71843b19c9f2b9cb9b0f4ab7a5a4329/pyyaml-6.0.3-cp313-cp313-win_arm64.whl", hash = "sha256:5498cd1645aa724a7c71c8f378eb29ebe23da2fc0d7a08071d89469bf1d2defb", size = 140246, upload-time = "2025-09-25T21:32:34.663Z" },
+ { url = "https://files.pythonhosted.org/packages/9d/8c/f4bd7f6465179953d3ac9bc44ac1a8a3e6122cf8ada906b4f96c60172d43/pyyaml-6.0.3-cp314-cp314-macosx_10_13_x86_64.whl", hash = "sha256:8d1fab6bb153a416f9aeb4b8763bc0f22a5586065f86f7664fc23339fc1c1fac", size = 181814, upload-time = "2025-09-25T21:32:35.712Z" },
+ { url = "https://files.pythonhosted.org/packages/bd/9c/4d95bb87eb2063d20db7b60faa3840c1b18025517ae857371c4dd55a6b3a/pyyaml-6.0.3-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:34d5fcd24b8445fadc33f9cf348c1047101756fd760b4dacb5c3e99755703310", size = 173809, upload-time = "2025-09-25T21:32:36.789Z" },
+ { url = "https://files.pythonhosted.org/packages/92/b5/47e807c2623074914e29dabd16cbbdd4bf5e9b2db9f8090fa64411fc5382/pyyaml-6.0.3-cp314-cp314-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:501a031947e3a9025ed4405a168e6ef5ae3126c59f90ce0cd6f2bfc477be31b7", size = 766454, upload-time = "2025-09-25T21:32:37.966Z" },
+ { url = "https://files.pythonhosted.org/packages/02/9e/e5e9b168be58564121efb3de6859c452fccde0ab093d8438905899a3a483/pyyaml-6.0.3-cp314-cp314-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:b3bc83488de33889877a0f2543ade9f70c67d66d9ebb4ac959502e12de895788", size = 836355, upload-time = "2025-09-25T21:32:39.178Z" },
+ { url = "https://files.pythonhosted.org/packages/88/f9/16491d7ed2a919954993e48aa941b200f38040928474c9e85ea9e64222c3/pyyaml-6.0.3-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:c458b6d084f9b935061bc36216e8a69a7e293a2f1e68bf956dcd9e6cbcd143f5", size = 794175, upload-time = "2025-09-25T21:32:40.865Z" },
+ { url = "https://files.pythonhosted.org/packages/dd/3f/5989debef34dc6397317802b527dbbafb2b4760878a53d4166579111411e/pyyaml-6.0.3-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:7c6610def4f163542a622a73fb39f534f8c101d690126992300bf3207eab9764", size = 755228, upload-time = "2025-09-25T21:32:42.084Z" },
+ { url = "https://files.pythonhosted.org/packages/d7/ce/af88a49043cd2e265be63d083fc75b27b6ed062f5f9fd6cdc223ad62f03e/pyyaml-6.0.3-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:5190d403f121660ce8d1d2c1bb2ef1bd05b5f68533fc5c2ea899bd15f4399b35", size = 789194, upload-time = "2025-09-25T21:32:43.362Z" },
+ { url = "https://files.pythonhosted.org/packages/23/20/bb6982b26a40bb43951265ba29d4c246ef0ff59c9fdcdf0ed04e0687de4d/pyyaml-6.0.3-cp314-cp314-win_amd64.whl", hash = "sha256:4a2e8cebe2ff6ab7d1050ecd59c25d4c8bd7e6f400f5f82b96557ac0abafd0ac", size = 156429, upload-time = "2025-09-25T21:32:57.844Z" },
+ { url = "https://files.pythonhosted.org/packages/f4/f4/a4541072bb9422c8a883ab55255f918fa378ecf083f5b85e87fc2b4eda1b/pyyaml-6.0.3-cp314-cp314-win_arm64.whl", hash = "sha256:93dda82c9c22deb0a405ea4dc5f2d0cda384168e466364dec6255b293923b2f3", size = 143912, upload-time = "2025-09-25T21:32:59.247Z" },
+ { url = "https://files.pythonhosted.org/packages/7c/f9/07dd09ae774e4616edf6cda684ee78f97777bdd15847253637a6f052a62f/pyyaml-6.0.3-cp314-cp314t-macosx_10_13_x86_64.whl", hash = "sha256:02893d100e99e03eda1c8fd5c441d8c60103fd175728e23e431db1b589cf5ab3", size = 189108, upload-time = "2025-09-25T21:32:44.377Z" },
+ { url = "https://files.pythonhosted.org/packages/4e/78/8d08c9fb7ce09ad8c38ad533c1191cf27f7ae1effe5bb9400a46d9437fcf/pyyaml-6.0.3-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:c1ff362665ae507275af2853520967820d9124984e0f7466736aea23d8611fba", size = 183641, upload-time = "2025-09-25T21:32:45.407Z" },
+ { url = "https://files.pythonhosted.org/packages/7b/5b/3babb19104a46945cf816d047db2788bcaf8c94527a805610b0289a01c6b/pyyaml-6.0.3-cp314-cp314t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:6adc77889b628398debc7b65c073bcb99c4a0237b248cacaf3fe8a557563ef6c", size = 831901, upload-time = "2025-09-25T21:32:48.83Z" },
+ { url = "https://files.pythonhosted.org/packages/8b/cc/dff0684d8dc44da4d22a13f35f073d558c268780ce3c6ba1b87055bb0b87/pyyaml-6.0.3-cp314-cp314t-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:a80cb027f6b349846a3bf6d73b5e95e782175e52f22108cfa17876aaeff93702", size = 861132, upload-time = "2025-09-25T21:32:50.149Z" },
+ { url = "https://files.pythonhosted.org/packages/b1/5e/f77dc6b9036943e285ba76b49e118d9ea929885becb0a29ba8a7c75e29fe/pyyaml-6.0.3-cp314-cp314t-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:00c4bdeba853cc34e7dd471f16b4114f4162dc03e6b7afcc2128711f0eca823c", size = 839261, upload-time = "2025-09-25T21:32:51.808Z" },
+ { url = "https://files.pythonhosted.org/packages/ce/88/a9db1376aa2a228197c58b37302f284b5617f56a5d959fd1763fb1675ce6/pyyaml-6.0.3-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:66e1674c3ef6f541c35191caae2d429b967b99e02040f5ba928632d9a7f0f065", size = 805272, upload-time = "2025-09-25T21:32:52.941Z" },
+ { url = "https://files.pythonhosted.org/packages/da/92/1446574745d74df0c92e6aa4a7b0b3130706a4142b2d1a5869f2eaa423c6/pyyaml-6.0.3-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:16249ee61e95f858e83976573de0f5b2893b3677ba71c9dd36b9cf8be9ac6d65", size = 829923, upload-time = "2025-09-25T21:32:54.537Z" },
+ { url = "https://files.pythonhosted.org/packages/f0/7a/1c7270340330e575b92f397352af856a8c06f230aa3e76f86b39d01b416a/pyyaml-6.0.3-cp314-cp314t-win_amd64.whl", hash = "sha256:4ad1906908f2f5ae4e5a8ddfce73c320c2a1429ec52eafd27138b7f1cbe341c9", size = 174062, upload-time = "2025-09-25T21:32:55.767Z" },
+ { url = "https://files.pythonhosted.org/packages/f1/12/de94a39c2ef588c7e6455cfbe7343d3b2dc9d6b6b2f40c4c6565744c873d/pyyaml-6.0.3-cp314-cp314t-win_arm64.whl", hash = "sha256:ebc55a14a21cb14062aa4162f906cd962b28e2e9ea38f9b4391244cd8de4ae0b", size = 149341, upload-time = "2025-09-25T21:32:56.828Z" },
+]
+
+[[package]]
+name = "pyzmq"
+version = "27.1.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "cffi", marker = "implementation_name == 'pypy'" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/04/0b/3c9baedbdf613ecaa7aa07027780b8867f57b6293b6ee50de316c9f3222b/pyzmq-27.1.0.tar.gz", hash = "sha256:ac0765e3d44455adb6ddbf4417dcce460fc40a05978c08efdf2948072f6db540", size = 281750, upload-time = "2025-09-08T23:10:18.157Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/92/e7/038aab64a946d535901103da16b953c8c9cc9c961dadcbf3609ed6428d23/pyzmq-27.1.0-cp312-abi3-macosx_10_15_universal2.whl", hash = "sha256:452631b640340c928fa343801b0d07eb0c3789a5ffa843f6e1a9cee0ba4eb4fc", size = 1306279, upload-time = "2025-09-08T23:08:03.807Z" },
+ { url = "https://files.pythonhosted.org/packages/e8/5e/c3c49fdd0f535ef45eefcc16934648e9e59dace4a37ee88fc53f6cd8e641/pyzmq-27.1.0-cp312-abi3-manylinux2014_i686.manylinux_2_17_i686.whl", hash = "sha256:1c179799b118e554b66da67d88ed66cd37a169f1f23b5d9f0a231b4e8d44a113", size = 895645, upload-time = "2025-09-08T23:08:05.301Z" },
+ { url = "https://files.pythonhosted.org/packages/f8/e5/b0b2504cb4e903a74dcf1ebae157f9e20ebb6ea76095f6cfffea28c42ecd/pyzmq-27.1.0-cp312-abi3-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:3837439b7f99e60312f0c926a6ad437b067356dc2bc2ec96eb395fd0fe804233", size = 652574, upload-time = "2025-09-08T23:08:06.828Z" },
+ { url = "https://files.pythonhosted.org/packages/f8/9b/c108cdb55560eaf253f0cbdb61b29971e9fb34d9c3499b0e96e4e60ed8a5/pyzmq-27.1.0-cp312-abi3-manylinux_2_26_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:43ad9a73e3da1fab5b0e7e13402f0b2fb934ae1c876c51d0afff0e7c052eca31", size = 840995, upload-time = "2025-09-08T23:08:08.396Z" },
+ { url = "https://files.pythonhosted.org/packages/c2/bb/b79798ca177b9eb0825b4c9998c6af8cd2a7f15a6a1a4272c1d1a21d382f/pyzmq-27.1.0-cp312-abi3-musllinux_1_2_aarch64.whl", hash = "sha256:0de3028d69d4cdc475bfe47a6128eb38d8bc0e8f4d69646adfbcd840facbac28", size = 1642070, upload-time = "2025-09-08T23:08:09.989Z" },
+ { url = "https://files.pythonhosted.org/packages/9c/80/2df2e7977c4ede24c79ae39dcef3899bfc5f34d1ca7a5b24f182c9b7a9ca/pyzmq-27.1.0-cp312-abi3-musllinux_1_2_i686.whl", hash = "sha256:cf44a7763aea9298c0aa7dbf859f87ed7012de8bda0f3977b6fb1d96745df856", size = 2021121, upload-time = "2025-09-08T23:08:11.907Z" },
+ { url = "https://files.pythonhosted.org/packages/46/bd/2d45ad24f5f5ae7e8d01525eb76786fa7557136555cac7d929880519e33a/pyzmq-27.1.0-cp312-abi3-musllinux_1_2_x86_64.whl", hash = "sha256:f30f395a9e6fbca195400ce833c731e7b64c3919aa481af4d88c3759e0cb7496", size = 1878550, upload-time = "2025-09-08T23:08:13.513Z" },
+ { url = "https://files.pythonhosted.org/packages/e6/2f/104c0a3c778d7c2ab8190e9db4f62f0b6957b53c9d87db77c284b69f33ea/pyzmq-27.1.0-cp312-abi3-win32.whl", hash = "sha256:250e5436a4ba13885494412b3da5d518cd0d3a278a1ae640e113c073a5f88edd", size = 559184, upload-time = "2025-09-08T23:08:15.163Z" },
+ { url = "https://files.pythonhosted.org/packages/fc/7f/a21b20d577e4100c6a41795842028235998a643b1ad406a6d4163ea8f53e/pyzmq-27.1.0-cp312-abi3-win_amd64.whl", hash = "sha256:9ce490cf1d2ca2ad84733aa1d69ce6855372cb5ce9223802450c9b2a7cba0ccf", size = 619480, upload-time = "2025-09-08T23:08:17.192Z" },
+ { url = "https://files.pythonhosted.org/packages/78/c2/c012beae5f76b72f007a9e91ee9401cb88c51d0f83c6257a03e785c81cc2/pyzmq-27.1.0-cp312-abi3-win_arm64.whl", hash = "sha256:75a2f36223f0d535a0c919e23615fc85a1e23b71f40c7eb43d7b1dedb4d8f15f", size = 552993, upload-time = "2025-09-08T23:08:18.926Z" },
+ { url = "https://files.pythonhosted.org/packages/60/cb/84a13459c51da6cec1b7b1dc1a47e6db6da50b77ad7fd9c145842750a011/pyzmq-27.1.0-cp313-cp313-android_24_arm64_v8a.whl", hash = "sha256:93ad4b0855a664229559e45c8d23797ceac03183c7b6f5b4428152a6b06684a5", size = 1122436, upload-time = "2025-09-08T23:08:20.801Z" },
+ { url = "https://files.pythonhosted.org/packages/dc/b6/94414759a69a26c3dd674570a81813c46a078767d931a6c70ad29fc585cb/pyzmq-27.1.0-cp313-cp313-android_24_x86_64.whl", hash = "sha256:fbb4f2400bfda24f12f009cba62ad5734148569ff4949b1b6ec3b519444342e6", size = 1156301, upload-time = "2025-09-08T23:08:22.47Z" },
+ { url = "https://files.pythonhosted.org/packages/a5/ad/15906493fd40c316377fd8a8f6b1f93104f97a752667763c9b9c1b71d42d/pyzmq-27.1.0-cp313-cp313t-macosx_10_15_universal2.whl", hash = "sha256:e343d067f7b151cfe4eb3bb796a7752c9d369eed007b91231e817071d2c2fec7", size = 1341197, upload-time = "2025-09-08T23:08:24.286Z" },
+ { url = "https://files.pythonhosted.org/packages/14/1d/d343f3ce13db53a54cb8946594e567410b2125394dafcc0268d8dda027e0/pyzmq-27.1.0-cp313-cp313t-manylinux2014_i686.manylinux_2_17_i686.whl", hash = "sha256:08363b2011dec81c354d694bdecaef4770e0ae96b9afea70b3f47b973655cc05", size = 897275, upload-time = "2025-09-08T23:08:26.063Z" },
+ { url = "https://files.pythonhosted.org/packages/69/2d/d83dd6d7ca929a2fc67d2c3005415cdf322af7751d773524809f9e585129/pyzmq-27.1.0-cp313-cp313t-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:d54530c8c8b5b8ddb3318f481297441af102517602b569146185fa10b63f4fa9", size = 660469, upload-time = "2025-09-08T23:08:27.623Z" },
+ { url = "https://files.pythonhosted.org/packages/3e/cd/9822a7af117f4bc0f1952dbe9ef8358eb50a24928efd5edf54210b850259/pyzmq-27.1.0-cp313-cp313t-manylinux_2_26_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:6f3afa12c392f0a44a2414056d730eebc33ec0926aae92b5ad5cf26ebb6cc128", size = 847961, upload-time = "2025-09-08T23:08:29.672Z" },
+ { url = "https://files.pythonhosted.org/packages/9a/12/f003e824a19ed73be15542f172fd0ec4ad0b60cf37436652c93b9df7c585/pyzmq-27.1.0-cp313-cp313t-musllinux_1_2_aarch64.whl", hash = "sha256:c65047adafe573ff023b3187bb93faa583151627bc9c51fc4fb2c561ed689d39", size = 1650282, upload-time = "2025-09-08T23:08:31.349Z" },
+ { url = "https://files.pythonhosted.org/packages/d5/4a/e82d788ed58e9a23995cee70dbc20c9aded3d13a92d30d57ec2291f1e8a3/pyzmq-27.1.0-cp313-cp313t-musllinux_1_2_i686.whl", hash = "sha256:90e6e9441c946a8b0a667356f7078d96411391a3b8f80980315455574177ec97", size = 2024468, upload-time = "2025-09-08T23:08:33.543Z" },
+ { url = "https://files.pythonhosted.org/packages/d9/94/2da0a60841f757481e402b34bf4c8bf57fa54a5466b965de791b1e6f747d/pyzmq-27.1.0-cp313-cp313t-musllinux_1_2_x86_64.whl", hash = "sha256:add071b2d25f84e8189aaf0882d39a285b42fa3853016ebab234a5e78c7a43db", size = 1885394, upload-time = "2025-09-08T23:08:35.51Z" },
+ { url = "https://files.pythonhosted.org/packages/4f/6f/55c10e2e49ad52d080dc24e37adb215e5b0d64990b57598abc2e3f01725b/pyzmq-27.1.0-cp313-cp313t-win32.whl", hash = "sha256:7ccc0700cfdf7bd487bea8d850ec38f204478681ea02a582a8da8171b7f90a1c", size = 574964, upload-time = "2025-09-08T23:08:37.178Z" },
+ { url = "https://files.pythonhosted.org/packages/87/4d/2534970ba63dd7c522d8ca80fb92777f362c0f321900667c615e2067cb29/pyzmq-27.1.0-cp313-cp313t-win_amd64.whl", hash = "sha256:8085a9fba668216b9b4323be338ee5437a235fe275b9d1610e422ccc279733e2", size = 641029, upload-time = "2025-09-08T23:08:40.595Z" },
+ { url = "https://files.pythonhosted.org/packages/f6/fa/f8aea7a28b0641f31d40dea42d7ef003fded31e184ef47db696bc74cd610/pyzmq-27.1.0-cp313-cp313t-win_arm64.whl", hash = "sha256:6bb54ca21bcfe361e445256c15eedf083f153811c37be87e0514934d6913061e", size = 561541, upload-time = "2025-09-08T23:08:42.668Z" },
+ { url = "https://files.pythonhosted.org/packages/87/45/19efbb3000956e82d0331bafca5d9ac19ea2857722fa2caacefb6042f39d/pyzmq-27.1.0-cp314-cp314t-macosx_10_15_universal2.whl", hash = "sha256:ce980af330231615756acd5154f29813d553ea555485ae712c491cd483df6b7a", size = 1341197, upload-time = "2025-09-08T23:08:44.973Z" },
+ { url = "https://files.pythonhosted.org/packages/48/43/d72ccdbf0d73d1343936296665826350cb1e825f92f2db9db3e61c2162a2/pyzmq-27.1.0-cp314-cp314t-manylinux2014_i686.manylinux_2_17_i686.whl", hash = "sha256:1779be8c549e54a1c38f805e56d2a2e5c009d26de10921d7d51cfd1c8d4632ea", size = 897175, upload-time = "2025-09-08T23:08:46.601Z" },
+ { url = "https://files.pythonhosted.org/packages/2f/2e/a483f73a10b65a9ef0161e817321d39a770b2acf8bcf3004a28d90d14a94/pyzmq-27.1.0-cp314-cp314t-manylinux_2_26_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:7200bb0f03345515df50d99d3db206a0a6bee1955fbb8c453c76f5bf0e08fb96", size = 660427, upload-time = "2025-09-08T23:08:48.187Z" },
+ { url = "https://files.pythonhosted.org/packages/f5/d2/5f36552c2d3e5685abe60dfa56f91169f7a2d99bbaf67c5271022ab40863/pyzmq-27.1.0-cp314-cp314t-manylinux_2_26_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:01c0e07d558b06a60773744ea6251f769cd79a41a97d11b8bf4ab8f034b0424d", size = 847929, upload-time = "2025-09-08T23:08:49.76Z" },
+ { url = "https://files.pythonhosted.org/packages/c4/2a/404b331f2b7bf3198e9945f75c4c521f0c6a3a23b51f7a4a401b94a13833/pyzmq-27.1.0-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:80d834abee71f65253c91540445d37c4c561e293ba6e741b992f20a105d69146", size = 1650193, upload-time = "2025-09-08T23:08:51.7Z" },
+ { url = "https://files.pythonhosted.org/packages/1c/0b/f4107e33f62a5acf60e3ded67ed33d79b4ce18de432625ce2fc5093d6388/pyzmq-27.1.0-cp314-cp314t-musllinux_1_2_i686.whl", hash = "sha256:544b4e3b7198dde4a62b8ff6685e9802a9a1ebf47e77478a5eb88eca2a82f2fd", size = 2024388, upload-time = "2025-09-08T23:08:53.393Z" },
+ { url = "https://files.pythonhosted.org/packages/0d/01/add31fe76512642fd6e40e3a3bd21f4b47e242c8ba33efb6809e37076d9b/pyzmq-27.1.0-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:cedc4c68178e59a4046f97eca31b148ddcf51e88677de1ef4e78cf06c5376c9a", size = 1885316, upload-time = "2025-09-08T23:08:55.702Z" },
+ { url = "https://files.pythonhosted.org/packages/c4/59/a5f38970f9bf07cee96128de79590bb354917914a9be11272cfc7ff26af0/pyzmq-27.1.0-cp314-cp314t-win32.whl", hash = "sha256:1f0b2a577fd770aa6f053211a55d1c47901f4d537389a034c690291485e5fe92", size = 587472, upload-time = "2025-09-08T23:08:58.18Z" },
+ { url = "https://files.pythonhosted.org/packages/70/d8/78b1bad170f93fcf5e3536e70e8fadac55030002275c9a29e8f5719185de/pyzmq-27.1.0-cp314-cp314t-win_amd64.whl", hash = "sha256:19c9468ae0437f8074af379e986c5d3d7d7bfe033506af442e8c879732bedbe0", size = 661401, upload-time = "2025-09-08T23:08:59.802Z" },
+ { url = "https://files.pythonhosted.org/packages/81/d6/4bfbb40c9a0b42fc53c7cf442f6385db70b40f74a783130c5d0a5aa62228/pyzmq-27.1.0-cp314-cp314t-win_arm64.whl", hash = "sha256:dc5dbf68a7857b59473f7df42650c621d7e8923fb03fa74a526890f4d33cc4d7", size = 575170, upload-time = "2025-09-08T23:09:01.418Z" },
+]
+
+[[package]]
+name = "referencing"
+version = "0.37.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "attrs" },
+ { name = "rpds-py" },
+ { name = "typing-extensions", marker = "python_full_version < '3.13'" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/22/f5/df4e9027acead3ecc63e50fe1e36aca1523e1719559c499951bb4b53188f/referencing-0.37.0.tar.gz", hash = "sha256:44aefc3142c5b842538163acb373e24cce6632bd54bdb01b21ad5863489f50d8", size = 78036, upload-time = "2025-10-13T15:30:48.871Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/2c/58/ca301544e1fa93ed4f80d724bf5b194f6e4b945841c5bfd555878eea9fcb/referencing-0.37.0-py3-none-any.whl", hash = "sha256:381329a9f99628c9069361716891d34ad94af76e461dcb0335825aecc7692231", size = 26766, upload-time = "2025-10-13T15:30:47.625Z" },
+]
+
+[[package]]
+name = "regex"
+version = "2025.11.3"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/cc/a9/546676f25e573a4cf00fe8e119b78a37b6a8fe2dc95cda877b30889c9c45/regex-2025.11.3.tar.gz", hash = "sha256:1fedc720f9bb2494ce31a58a1631f9c82df6a09b49c19517ea5cc280b4541e01", size = 414669, upload-time = "2025-11-03T21:34:22.089Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/e8/74/18f04cb53e58e3fb107439699bd8375cf5a835eec81084e0bddbd122e4c2/regex-2025.11.3-cp312-cp312-macosx_10_13_universal2.whl", hash = "sha256:bc8ab71e2e31b16e40868a40a69007bc305e1109bd4658eb6cad007e0bf67c41", size = 489312, upload-time = "2025-11-03T21:31:34.343Z" },
+ { url = "https://files.pythonhosted.org/packages/78/3f/37fcdd0d2b1e78909108a876580485ea37c91e1acf66d3bb8e736348f441/regex-2025.11.3-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:22b29dda7e1f7062a52359fca6e58e548e28c6686f205e780b02ad8ef710de36", size = 291256, upload-time = "2025-11-03T21:31:35.675Z" },
+ { url = "https://files.pythonhosted.org/packages/bf/26/0a575f58eb23b7ebd67a45fccbc02ac030b737b896b7e7a909ffe43ffd6a/regex-2025.11.3-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:3a91e4a29938bc1a082cc28fdea44be420bf2bebe2665343029723892eb073e1", size = 288921, upload-time = "2025-11-03T21:31:37.07Z" },
+ { url = "https://files.pythonhosted.org/packages/ea/98/6a8dff667d1af907150432cf5abc05a17ccd32c72a3615410d5365ac167a/regex-2025.11.3-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:08b884f4226602ad40c5d55f52bf91a9df30f513864e0054bad40c0e9cf1afb7", size = 798568, upload-time = "2025-11-03T21:31:38.784Z" },
+ { url = "https://files.pythonhosted.org/packages/64/15/92c1db4fa4e12733dd5a526c2dd2b6edcbfe13257e135fc0f6c57f34c173/regex-2025.11.3-cp312-cp312-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:3e0b11b2b2433d1c39c7c7a30e3f3d0aeeea44c2a8d0bae28f6b95f639927a69", size = 864165, upload-time = "2025-11-03T21:31:40.559Z" },
+ { url = "https://files.pythonhosted.org/packages/f9/e7/3ad7da8cdee1ce66c7cd37ab5ab05c463a86ffeb52b1a25fe7bd9293b36c/regex-2025.11.3-cp312-cp312-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:87eb52a81ef58c7ba4d45c3ca74e12aa4b4e77816f72ca25258a85b3ea96cb48", size = 912182, upload-time = "2025-11-03T21:31:42.002Z" },
+ { url = "https://files.pythonhosted.org/packages/84/bd/9ce9f629fcb714ffc2c3faf62b6766ecb7a585e1e885eb699bcf130a5209/regex-2025.11.3-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:a12ab1f5c29b4e93db518f5e3872116b7e9b1646c9f9f426f777b50d44a09e8c", size = 803501, upload-time = "2025-11-03T21:31:43.815Z" },
+ { url = "https://files.pythonhosted.org/packages/7c/0f/8dc2e4349d8e877283e6edd6c12bdcebc20f03744e86f197ab6e4492bf08/regex-2025.11.3-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:7521684c8c7c4f6e88e35ec89680ee1aa8358d3f09d27dfbdf62c446f5d4c695", size = 787842, upload-time = "2025-11-03T21:31:45.353Z" },
+ { url = "https://files.pythonhosted.org/packages/f9/73/cff02702960bc185164d5619c0c62a2f598a6abff6695d391b096237d4ab/regex-2025.11.3-cp312-cp312-musllinux_1_2_ppc64le.whl", hash = "sha256:7fe6e5440584e94cc4b3f5f4d98a25e29ca12dccf8873679a635638349831b98", size = 858519, upload-time = "2025-11-03T21:31:46.814Z" },
+ { url = "https://files.pythonhosted.org/packages/61/83/0e8d1ae71e15bc1dc36231c90b46ee35f9d52fab2e226b0e039e7ea9c10a/regex-2025.11.3-cp312-cp312-musllinux_1_2_s390x.whl", hash = "sha256:8e026094aa12b43f4fd74576714e987803a315c76edb6b098b9809db5de58f74", size = 850611, upload-time = "2025-11-03T21:31:48.289Z" },
+ { url = "https://files.pythonhosted.org/packages/c8/f5/70a5cdd781dcfaa12556f2955bf170cd603cb1c96a1827479f8faea2df97/regex-2025.11.3-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:435bbad13e57eb5606a68443af62bed3556de2f46deb9f7d4237bc2f1c9fb3a0", size = 789759, upload-time = "2025-11-03T21:31:49.759Z" },
+ { url = "https://files.pythonhosted.org/packages/59/9b/7c29be7903c318488983e7d97abcf8ebd3830e4c956c4c540005fcfb0462/regex-2025.11.3-cp312-cp312-win32.whl", hash = "sha256:3839967cf4dc4b985e1570fd8d91078f0c519f30491c60f9ac42a8db039be204", size = 266194, upload-time = "2025-11-03T21:31:51.53Z" },
+ { url = "https://files.pythonhosted.org/packages/1a/67/3b92df89f179d7c367be654ab5626ae311cb28f7d5c237b6bb976cd5fbbb/regex-2025.11.3-cp312-cp312-win_amd64.whl", hash = "sha256:e721d1b46e25c481dc5ded6f4b3f66c897c58d2e8cfdf77bbced84339108b0b9", size = 277069, upload-time = "2025-11-03T21:31:53.151Z" },
+ { url = "https://files.pythonhosted.org/packages/d7/55/85ba4c066fe5094d35b249c3ce8df0ba623cfd35afb22d6764f23a52a1c5/regex-2025.11.3-cp312-cp312-win_arm64.whl", hash = "sha256:64350685ff08b1d3a6fff33f45a9ca183dc1d58bbfe4981604e70ec9801bbc26", size = 270330, upload-time = "2025-11-03T21:31:54.514Z" },
+ { url = "https://files.pythonhosted.org/packages/e1/a7/dda24ebd49da46a197436ad96378f17df30ceb40e52e859fc42cac45b850/regex-2025.11.3-cp313-cp313-macosx_10_13_universal2.whl", hash = "sha256:c1e448051717a334891f2b9a620fe36776ebf3dd8ec46a0b877c8ae69575feb4", size = 489081, upload-time = "2025-11-03T21:31:55.9Z" },
+ { url = "https://files.pythonhosted.org/packages/19/22/af2dc751aacf88089836aa088a1a11c4f21a04707eb1b0478e8e8fb32847/regex-2025.11.3-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:9b5aca4d5dfd7fbfbfbdaf44850fcc7709a01146a797536a8f84952e940cca76", size = 291123, upload-time = "2025-11-03T21:31:57.758Z" },
+ { url = "https://files.pythonhosted.org/packages/a3/88/1a3ea5672f4b0a84802ee9891b86743438e7c04eb0b8f8c4e16a42375327/regex-2025.11.3-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:04d2765516395cf7dda331a244a3282c0f5ae96075f728629287dfa6f76ba70a", size = 288814, upload-time = "2025-11-03T21:32:01.12Z" },
+ { url = "https://files.pythonhosted.org/packages/fb/8c/f5987895bf42b8ddeea1b315c9fedcfe07cadee28b9c98cf50d00adcb14d/regex-2025.11.3-cp313-cp313-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:5d9903ca42bfeec4cebedba8022a7c97ad2aab22e09573ce9976ba01b65e4361", size = 798592, upload-time = "2025-11-03T21:32:03.006Z" },
+ { url = "https://files.pythonhosted.org/packages/99/2a/6591ebeede78203fa77ee46a1c36649e02df9eaa77a033d1ccdf2fcd5d4e/regex-2025.11.3-cp313-cp313-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:639431bdc89d6429f6721625e8129413980ccd62e9d3f496be618a41d205f160", size = 864122, upload-time = "2025-11-03T21:32:04.553Z" },
+ { url = "https://files.pythonhosted.org/packages/94/d6/be32a87cf28cf8ed064ff281cfbd49aefd90242a83e4b08b5a86b38e8eb4/regex-2025.11.3-cp313-cp313-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:f117efad42068f9715677c8523ed2be1518116d1c49b1dd17987716695181efe", size = 912272, upload-time = "2025-11-03T21:32:06.148Z" },
+ { url = "https://files.pythonhosted.org/packages/62/11/9bcef2d1445665b180ac7f230406ad80671f0fc2a6ffb93493b5dd8cd64c/regex-2025.11.3-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:4aecb6f461316adf9f1f0f6a4a1a3d79e045f9b71ec76055a791affa3b285850", size = 803497, upload-time = "2025-11-03T21:32:08.162Z" },
+ { url = "https://files.pythonhosted.org/packages/e5/a7/da0dc273d57f560399aa16d8a68ae7f9b57679476fc7ace46501d455fe84/regex-2025.11.3-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:3b3a5f320136873cc5561098dfab677eea139521cb9a9e8db98b7e64aef44cbc", size = 787892, upload-time = "2025-11-03T21:32:09.769Z" },
+ { url = "https://files.pythonhosted.org/packages/da/4b/732a0c5a9736a0b8d6d720d4945a2f1e6f38f87f48f3173559f53e8d5d82/regex-2025.11.3-cp313-cp313-musllinux_1_2_ppc64le.whl", hash = "sha256:75fa6f0056e7efb1f42a1c34e58be24072cb9e61a601340cc1196ae92326a4f9", size = 858462, upload-time = "2025-11-03T21:32:11.769Z" },
+ { url = "https://files.pythonhosted.org/packages/0c/f5/a2a03df27dc4c2d0c769220f5110ba8c4084b0bfa9ab0f9b4fcfa3d2b0fc/regex-2025.11.3-cp313-cp313-musllinux_1_2_s390x.whl", hash = "sha256:dbe6095001465294f13f1adcd3311e50dd84e5a71525f20a10bd16689c61ce0b", size = 850528, upload-time = "2025-11-03T21:32:13.906Z" },
+ { url = "https://files.pythonhosted.org/packages/d6/09/e1cd5bee3841c7f6eb37d95ca91cdee7100b8f88b81e41c2ef426910891a/regex-2025.11.3-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:454d9b4ae7881afbc25015b8627c16d88a597479b9dea82b8c6e7e2e07240dc7", size = 789866, upload-time = "2025-11-03T21:32:15.748Z" },
+ { url = "https://files.pythonhosted.org/packages/eb/51/702f5ea74e2a9c13d855a6a85b7f80c30f9e72a95493260193c07f3f8d74/regex-2025.11.3-cp313-cp313-win32.whl", hash = "sha256:28ba4d69171fc6e9896337d4fc63a43660002b7da53fc15ac992abcf3410917c", size = 266189, upload-time = "2025-11-03T21:32:17.493Z" },
+ { url = "https://files.pythonhosted.org/packages/8b/00/6e29bb314e271a743170e53649db0fdb8e8ff0b64b4f425f5602f4eb9014/regex-2025.11.3-cp313-cp313-win_amd64.whl", hash = "sha256:bac4200befe50c670c405dc33af26dad5a3b6b255dd6c000d92fe4629f9ed6a5", size = 277054, upload-time = "2025-11-03T21:32:19.042Z" },
+ { url = "https://files.pythonhosted.org/packages/25/f1/b156ff9f2ec9ac441710764dda95e4edaf5f36aca48246d1eea3f1fd96ec/regex-2025.11.3-cp313-cp313-win_arm64.whl", hash = "sha256:2292cd5a90dab247f9abe892ac584cb24f0f54680c73fcb4a7493c66c2bf2467", size = 270325, upload-time = "2025-11-03T21:32:21.338Z" },
+ { url = "https://files.pythonhosted.org/packages/20/28/fd0c63357caefe5680b8ea052131acbd7f456893b69cc2a90cc3e0dc90d4/regex-2025.11.3-cp313-cp313t-macosx_10_13_universal2.whl", hash = "sha256:1eb1ebf6822b756c723e09f5186473d93236c06c579d2cc0671a722d2ab14281", size = 491984, upload-time = "2025-11-03T21:32:23.466Z" },
+ { url = "https://files.pythonhosted.org/packages/df/ec/7014c15626ab46b902b3bcc4b28a7bae46d8f281fc7ea9c95e22fcaaa917/regex-2025.11.3-cp313-cp313t-macosx_10_13_x86_64.whl", hash = "sha256:1e00ec2970aab10dc5db34af535f21fcf32b4a31d99e34963419636e2f85ae39", size = 292673, upload-time = "2025-11-03T21:32:25.034Z" },
+ { url = "https://files.pythonhosted.org/packages/23/ab/3b952ff7239f20d05f1f99e9e20188513905f218c81d52fb5e78d2bf7634/regex-2025.11.3-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:a4cb042b615245d5ff9b3794f56be4138b5adc35a4166014d31d1814744148c7", size = 291029, upload-time = "2025-11-03T21:32:26.528Z" },
+ { url = "https://files.pythonhosted.org/packages/21/7e/3dc2749fc684f455f162dcafb8a187b559e2614f3826877d3844a131f37b/regex-2025.11.3-cp313-cp313t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:44f264d4bf02f3176467d90b294d59bf1db9fe53c141ff772f27a8b456b2a9ed", size = 807437, upload-time = "2025-11-03T21:32:28.363Z" },
+ { url = "https://files.pythonhosted.org/packages/1b/0b/d529a85ab349c6a25d1ca783235b6e3eedf187247eab536797021f7126c6/regex-2025.11.3-cp313-cp313t-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:7be0277469bf3bd7a34a9c57c1b6a724532a0d235cd0dc4e7f4316f982c28b19", size = 873368, upload-time = "2025-11-03T21:32:30.4Z" },
+ { url = "https://files.pythonhosted.org/packages/7d/18/2d868155f8c9e3e9d8f9e10c64e9a9f496bb8f7e037a88a8bed26b435af6/regex-2025.11.3-cp313-cp313t-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:0d31e08426ff4b5b650f68839f5af51a92a5b51abd8554a60c2fbc7c71f25d0b", size = 914921, upload-time = "2025-11-03T21:32:32.123Z" },
+ { url = "https://files.pythonhosted.org/packages/2d/71/9d72ff0f354fa783fe2ba913c8734c3b433b86406117a8db4ea2bf1c7a2f/regex-2025.11.3-cp313-cp313t-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:e43586ce5bd28f9f285a6e729466841368c4a0353f6fd08d4ce4630843d3648a", size = 812708, upload-time = "2025-11-03T21:32:34.305Z" },
+ { url = "https://files.pythonhosted.org/packages/e7/19/ce4bf7f5575c97f82b6e804ffb5c4e940c62609ab2a0d9538d47a7fdf7d4/regex-2025.11.3-cp313-cp313t-musllinux_1_2_aarch64.whl", hash = "sha256:0f9397d561a4c16829d4e6ff75202c1c08b68a3bdbfe29dbfcdb31c9830907c6", size = 795472, upload-time = "2025-11-03T21:32:36.364Z" },
+ { url = "https://files.pythonhosted.org/packages/03/86/fd1063a176ffb7b2315f9a1b08d17b18118b28d9df163132615b835a26ee/regex-2025.11.3-cp313-cp313t-musllinux_1_2_ppc64le.whl", hash = "sha256:dd16e78eb18ffdb25ee33a0682d17912e8cc8a770e885aeee95020046128f1ce", size = 868341, upload-time = "2025-11-03T21:32:38.042Z" },
+ { url = "https://files.pythonhosted.org/packages/12/43/103fb2e9811205e7386366501bc866a164a0430c79dd59eac886a2822950/regex-2025.11.3-cp313-cp313t-musllinux_1_2_s390x.whl", hash = "sha256:ffcca5b9efe948ba0661e9df0fa50d2bc4b097c70b9810212d6b62f05d83b2dd", size = 854666, upload-time = "2025-11-03T21:32:40.079Z" },
+ { url = "https://files.pythonhosted.org/packages/7d/22/e392e53f3869b75804762c7c848bd2dd2abf2b70fb0e526f58724638bd35/regex-2025.11.3-cp313-cp313t-musllinux_1_2_x86_64.whl", hash = "sha256:c56b4d162ca2b43318ac671c65bd4d563e841a694ac70e1a976ac38fcf4ca1d2", size = 799473, upload-time = "2025-11-03T21:32:42.148Z" },
+ { url = "https://files.pythonhosted.org/packages/4f/f9/8bd6b656592f925b6845fcbb4d57603a3ac2fb2373344ffa1ed70aa6820a/regex-2025.11.3-cp313-cp313t-win32.whl", hash = "sha256:9ddc42e68114e161e51e272f667d640f97e84a2b9ef14b7477c53aac20c2d59a", size = 268792, upload-time = "2025-11-03T21:32:44.13Z" },
+ { url = "https://files.pythonhosted.org/packages/e5/87/0e7d603467775ff65cd2aeabf1b5b50cc1c3708556a8b849a2fa4dd1542b/regex-2025.11.3-cp313-cp313t-win_amd64.whl", hash = "sha256:7a7c7fdf755032ffdd72c77e3d8096bdcb0eb92e89e17571a196f03d88b11b3c", size = 280214, upload-time = "2025-11-03T21:32:45.853Z" },
+ { url = "https://files.pythonhosted.org/packages/8d/d0/2afc6f8e94e2b64bfb738a7c2b6387ac1699f09f032d363ed9447fd2bb57/regex-2025.11.3-cp313-cp313t-win_arm64.whl", hash = "sha256:df9eb838c44f570283712e7cff14c16329a9f0fb19ca492d21d4b7528ee6821e", size = 271469, upload-time = "2025-11-03T21:32:48.026Z" },
+ { url = "https://files.pythonhosted.org/packages/31/e9/f6e13de7e0983837f7b6d238ad9458800a874bf37c264f7923e63409944c/regex-2025.11.3-cp314-cp314-macosx_10_13_universal2.whl", hash = "sha256:9697a52e57576c83139d7c6f213d64485d3df5bf84807c35fa409e6c970801c6", size = 489089, upload-time = "2025-11-03T21:32:50.027Z" },
+ { url = "https://files.pythonhosted.org/packages/a3/5c/261f4a262f1fa65141c1b74b255988bd2fa020cc599e53b080667d591cfc/regex-2025.11.3-cp314-cp314-macosx_10_13_x86_64.whl", hash = "sha256:e18bc3f73bd41243c9b38a6d9f2366cd0e0137a9aebe2d8ff76c5b67d4c0a3f4", size = 291059, upload-time = "2025-11-03T21:32:51.682Z" },
+ { url = "https://files.pythonhosted.org/packages/8e/57/f14eeb7f072b0e9a5a090d1712741fd8f214ec193dba773cf5410108bb7d/regex-2025.11.3-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:61a08bcb0ec14ff4e0ed2044aad948d0659604f824cbd50b55e30b0ec6f09c73", size = 288900, upload-time = "2025-11-03T21:32:53.569Z" },
+ { url = "https://files.pythonhosted.org/packages/3c/6b/1d650c45e99a9b327586739d926a1cd4e94666b1bd4af90428b36af66dc7/regex-2025.11.3-cp314-cp314-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:c9c30003b9347c24bcc210958c5d167b9e4f9be786cb380a7d32f14f9b84674f", size = 799010, upload-time = "2025-11-03T21:32:55.222Z" },
+ { url = "https://files.pythonhosted.org/packages/99/ee/d66dcbc6b628ce4e3f7f0cbbb84603aa2fc0ffc878babc857726b8aab2e9/regex-2025.11.3-cp314-cp314-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:4e1e592789704459900728d88d41a46fe3969b82ab62945560a31732ffc19a6d", size = 864893, upload-time = "2025-11-03T21:32:57.239Z" },
+ { url = "https://files.pythonhosted.org/packages/bf/2d/f238229f1caba7ac87a6c4153d79947fb0261415827ae0f77c304260c7d3/regex-2025.11.3-cp314-cp314-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:6538241f45eb5a25aa575dbba1069ad786f68a4f2773a29a2bd3dd1f9de787be", size = 911522, upload-time = "2025-11-03T21:32:59.274Z" },
+ { url = "https://files.pythonhosted.org/packages/bd/3d/22a4eaba214a917c80e04f6025d26143690f0419511e0116508e24b11c9b/regex-2025.11.3-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:bce22519c989bb72a7e6b36a199384c53db7722fe669ba891da75907fe3587db", size = 803272, upload-time = "2025-11-03T21:33:01.393Z" },
+ { url = "https://files.pythonhosted.org/packages/84/b1/03188f634a409353a84b5ef49754b97dbcc0c0f6fd6c8ede505a8960a0a4/regex-2025.11.3-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:66d559b21d3640203ab9075797a55165d79017520685fb407b9234d72ab63c62", size = 787958, upload-time = "2025-11-03T21:33:03.379Z" },
+ { url = "https://files.pythonhosted.org/packages/99/6a/27d072f7fbf6fadd59c64d210305e1ff865cc3b78b526fd147db768c553b/regex-2025.11.3-cp314-cp314-musllinux_1_2_ppc64le.whl", hash = "sha256:669dcfb2e38f9e8c69507bace46f4889e3abbfd9b0c29719202883c0a603598f", size = 859289, upload-time = "2025-11-03T21:33:05.374Z" },
+ { url = "https://files.pythonhosted.org/packages/9a/70/1b3878f648e0b6abe023172dacb02157e685564853cc363d9961bcccde4e/regex-2025.11.3-cp314-cp314-musllinux_1_2_s390x.whl", hash = "sha256:32f74f35ff0f25a5021373ac61442edcb150731fbaa28286bbc8bb1582c89d02", size = 850026, upload-time = "2025-11-03T21:33:07.131Z" },
+ { url = "https://files.pythonhosted.org/packages/dd/d5/68e25559b526b8baab8e66839304ede68ff6727237a47727d240006bd0ff/regex-2025.11.3-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:e6c7a21dffba883234baefe91bc3388e629779582038f75d2a5be918e250f0ed", size = 789499, upload-time = "2025-11-03T21:33:09.141Z" },
+ { url = "https://files.pythonhosted.org/packages/fc/df/43971264857140a350910d4e33df725e8c94dd9dee8d2e4729fa0d63d49e/regex-2025.11.3-cp314-cp314-win32.whl", hash = "sha256:795ea137b1d809eb6836b43748b12634291c0ed55ad50a7d72d21edf1cd565c4", size = 271604, upload-time = "2025-11-03T21:33:10.9Z" },
+ { url = "https://files.pythonhosted.org/packages/01/6f/9711b57dc6894a55faf80a4c1b5aa4f8649805cb9c7aef46f7d27e2b9206/regex-2025.11.3-cp314-cp314-win_amd64.whl", hash = "sha256:9f95fbaa0ee1610ec0fc6b26668e9917a582ba80c52cc6d9ada15e30aa9ab9ad", size = 280320, upload-time = "2025-11-03T21:33:12.572Z" },
+ { url = "https://files.pythonhosted.org/packages/f1/7e/f6eaa207d4377481f5e1775cdeb5a443b5a59b392d0065f3417d31d80f87/regex-2025.11.3-cp314-cp314-win_arm64.whl", hash = "sha256:dfec44d532be4c07088c3de2876130ff0fbeeacaa89a137decbbb5f665855a0f", size = 273372, upload-time = "2025-11-03T21:33:14.219Z" },
+ { url = "https://files.pythonhosted.org/packages/c3/06/49b198550ee0f5e4184271cee87ba4dfd9692c91ec55289e6282f0f86ccf/regex-2025.11.3-cp314-cp314t-macosx_10_13_universal2.whl", hash = "sha256:ba0d8a5d7f04f73ee7d01d974d47c5834f8a1b0224390e4fe7c12a3a92a78ecc", size = 491985, upload-time = "2025-11-03T21:33:16.555Z" },
+ { url = "https://files.pythonhosted.org/packages/ce/bf/abdafade008f0b1c9da10d934034cb670432d6cf6cbe38bbb53a1cfd6cf8/regex-2025.11.3-cp314-cp314t-macosx_10_13_x86_64.whl", hash = "sha256:442d86cf1cfe4faabf97db7d901ef58347efd004934da045c745e7b5bd57ac49", size = 292669, upload-time = "2025-11-03T21:33:18.32Z" },
+ { url = "https://files.pythonhosted.org/packages/f9/ef/0c357bb8edbd2ad8e273fcb9e1761bc37b8acbc6e1be050bebd6475f19c1/regex-2025.11.3-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:fd0a5e563c756de210bb964789b5abe4f114dacae9104a47e1a649b910361536", size = 291030, upload-time = "2025-11-03T21:33:20.048Z" },
+ { url = "https://files.pythonhosted.org/packages/79/06/edbb67257596649b8fb088d6aeacbcb248ac195714b18a65e018bf4c0b50/regex-2025.11.3-cp314-cp314t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:bf3490bcbb985a1ae97b2ce9ad1c0f06a852d5b19dde9b07bdf25bf224248c95", size = 807674, upload-time = "2025-11-03T21:33:21.797Z" },
+ { url = "https://files.pythonhosted.org/packages/f4/d9/ad4deccfce0ea336296bd087f1a191543bb99ee1c53093dcd4c64d951d00/regex-2025.11.3-cp314-cp314t-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:3809988f0a8b8c9dcc0f92478d6501fac7200b9ec56aecf0ec21f4a2ec4b6009", size = 873451, upload-time = "2025-11-03T21:33:23.741Z" },
+ { url = "https://files.pythonhosted.org/packages/13/75/a55a4724c56ef13e3e04acaab29df26582f6978c000ac9cd6810ad1f341f/regex-2025.11.3-cp314-cp314t-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:f4ff94e58e84aedb9c9fce66d4ef9f27a190285b451420f297c9a09f2b9abee9", size = 914980, upload-time = "2025-11-03T21:33:25.999Z" },
+ { url = "https://files.pythonhosted.org/packages/67/1e/a1657ee15bd9116f70d4a530c736983eed997b361e20ecd8f5ca3759d5c5/regex-2025.11.3-cp314-cp314t-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:7eb542fd347ce61e1321b0a6b945d5701528dca0cd9759c2e3bb8bd57e47964d", size = 812852, upload-time = "2025-11-03T21:33:27.852Z" },
+ { url = "https://files.pythonhosted.org/packages/b8/6f/f7516dde5506a588a561d296b2d0044839de06035bb486b326065b4c101e/regex-2025.11.3-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:d6c2d5919075a1f2e413c00b056ea0c2f065b3f5fe83c3d07d325ab92dce51d6", size = 795566, upload-time = "2025-11-03T21:33:32.364Z" },
+ { url = "https://files.pythonhosted.org/packages/d9/dd/3d10b9e170cc16fb34cb2cef91513cf3df65f440b3366030631b2984a264/regex-2025.11.3-cp314-cp314t-musllinux_1_2_ppc64le.whl", hash = "sha256:3f8bf11a4827cc7ce5a53d4ef6cddd5ad25595d3c1435ef08f76825851343154", size = 868463, upload-time = "2025-11-03T21:33:34.459Z" },
+ { url = "https://files.pythonhosted.org/packages/f5/8e/935e6beff1695aa9085ff83195daccd72acc82c81793df480f34569330de/regex-2025.11.3-cp314-cp314t-musllinux_1_2_s390x.whl", hash = "sha256:22c12d837298651e5550ac1d964e4ff57c3f56965fc1812c90c9fb2028eaf267", size = 854694, upload-time = "2025-11-03T21:33:36.793Z" },
+ { url = "https://files.pythonhosted.org/packages/92/12/10650181a040978b2f5720a6a74d44f841371a3d984c2083fc1752e4acf6/regex-2025.11.3-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:62ba394a3dda9ad41c7c780f60f6e4a70988741415ae96f6d1bf6c239cf01379", size = 799691, upload-time = "2025-11-03T21:33:39.079Z" },
+ { url = "https://files.pythonhosted.org/packages/67/90/8f37138181c9a7690e7e4cb388debbd389342db3c7381d636d2875940752/regex-2025.11.3-cp314-cp314t-win32.whl", hash = "sha256:4bf146dca15cdd53224a1bf46d628bd7590e4a07fbb69e720d561aea43a32b38", size = 274583, upload-time = "2025-11-03T21:33:41.302Z" },
+ { url = "https://files.pythonhosted.org/packages/8f/cd/867f5ec442d56beb56f5f854f40abcfc75e11d10b11fdb1869dd39c63aaf/regex-2025.11.3-cp314-cp314t-win_amd64.whl", hash = "sha256:adad1a1bcf1c9e76346e091d22d23ac54ef28e1365117d99521631078dfec9de", size = 284286, upload-time = "2025-11-03T21:33:43.324Z" },
+ { url = "https://files.pythonhosted.org/packages/20/31/32c0c4610cbc070362bf1d2e4ea86d1ea29014d400a6d6c2486fcfd57766/regex-2025.11.3-cp314-cp314t-win_arm64.whl", hash = "sha256:c54f768482cef41e219720013cd05933b6f971d9562544d691c68699bf2b6801", size = 274741, upload-time = "2025-11-03T21:33:45.557Z" },
+]
+
+[[package]]
+name = "requests"
+version = "2.32.5"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "certifi" },
+ { name = "charset-normalizer" },
+ { name = "idna" },
+ { name = "urllib3" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/c9/74/b3ff8e6c8446842c3f5c837e9c3dfcfe2018ea6ecef224c710c85ef728f4/requests-2.32.5.tar.gz", hash = "sha256:dbba0bac56e100853db0ea71b82b4dfd5fe2bf6d3754a8893c3af500cec7d7cf", size = 134517, upload-time = "2025-08-18T20:46:02.573Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/1e/db/4254e3eabe8020b458f1a747140d32277ec7a271daf1d235b70dc0b4e6e3/requests-2.32.5-py3-none-any.whl", hash = "sha256:2462f94637a34fd532264295e186976db0f5d453d1cdd31473c85a6a161affb6", size = 64738, upload-time = "2025-08-18T20:46:00.542Z" },
+]
+
+[[package]]
+name = "reuse"
+version = "6.2.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "attrs" },
+ { name = "click" },
+ { name = "jinja2" },
+ { name = "license-expression" },
+ { name = "python-debian" },
+ { name = "python-magic" },
+ { name = "tomlkit" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/05/35/298d9410b3635107ce586725cdfbca4c219c08d77a3511551f5e479a78db/reuse-6.2.0.tar.gz", hash = "sha256:4feae057a2334c9a513e6933cdb9be819d8b822f3b5b435a36138bd218897d23", size = 1615611, upload-time = "2025-10-27T15:25:46.336Z" }
+
+[[package]]
+name = "rfc3339-validator"
+version = "0.1.4"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "six" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/28/ea/a9387748e2d111c3c2b275ba970b735e04e15cdb1eb30693b6b5708c4dbd/rfc3339_validator-0.1.4.tar.gz", hash = "sha256:138a2abdf93304ad60530167e51d2dfb9549521a836871b88d7f4695d0022f6b", size = 5513, upload-time = "2021-05-12T16:37:54.178Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/7b/44/4e421b96b67b2daff264473f7465db72fbdf36a07e05494f50300cc7b0c6/rfc3339_validator-0.1.4-py2.py3-none-any.whl", hash = "sha256:24f6ec1eda14ef823da9e36ec7113124b39c04d50a4d3d3a3c2859577e7791fa", size = 3490, upload-time = "2021-05-12T16:37:52.536Z" },
+]
+
+[[package]]
+name = "rfc3986-validator"
+version = "0.1.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/da/88/f270de456dd7d11dcc808abfa291ecdd3f45ff44e3b549ffa01b126464d0/rfc3986_validator-0.1.1.tar.gz", hash = "sha256:3d44bde7921b3b9ec3ae4e3adca370438eccebc676456449b145d533b240d055", size = 6760, upload-time = "2019-10-28T16:00:19.144Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/9e/51/17023c0f8f1869d8806b979a2bffa3f861f26a3f1a66b094288323fba52f/rfc3986_validator-0.1.1-py2.py3-none-any.whl", hash = "sha256:2f235c432ef459970b4306369336b9d5dbdda31b510ca1e327636e01f528bfa9", size = 4242, upload-time = "2019-10-28T16:00:13.976Z" },
+]
+
+[[package]]
+name = "rfc3987-syntax"
+version = "1.1.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "lark" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/2c/06/37c1a5557acf449e8e406a830a05bf885ac47d33270aec454ef78675008d/rfc3987_syntax-1.1.0.tar.gz", hash = "sha256:717a62cbf33cffdd16dfa3a497d81ce48a660ea691b1ddd7be710c22f00b4a0d", size = 14239, upload-time = "2025-07-18T01:05:05.015Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/7e/71/44ce230e1b7fadd372515a97e32a83011f906ddded8d03e3c6aafbdedbb7/rfc3987_syntax-1.1.0-py3-none-any.whl", hash = "sha256:6c3d97604e4c5ce9f714898e05401a0445a641cfa276432b0a648c80856f6a3f", size = 8046, upload-time = "2025-07-18T01:05:03.843Z" },
+]
+
+[[package]]
+name = "rpds-py"
+version = "0.30.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/20/af/3f2f423103f1113b36230496629986e0ef7e199d2aa8392452b484b38ced/rpds_py-0.30.0.tar.gz", hash = "sha256:dd8ff7cf90014af0c0f787eea34794ebf6415242ee1d6fa91eaba725cc441e84", size = 69469, upload-time = "2025-11-30T20:24:38.837Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/03/e7/98a2f4ac921d82f33e03f3835f5bf3a4a40aa1bfdc57975e74a97b2b4bdd/rpds_py-0.30.0-cp312-cp312-macosx_10_12_x86_64.whl", hash = "sha256:a161f20d9a43006833cd7068375a94d035714d73a172b681d8881820600abfad", size = 375086, upload-time = "2025-11-30T20:22:17.93Z" },
+ { url = "https://files.pythonhosted.org/packages/4d/a1/bca7fd3d452b272e13335db8d6b0b3ecde0f90ad6f16f3328c6fb150c889/rpds_py-0.30.0-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:6abc8880d9d036ecaafe709079969f56e876fcf107f7a8e9920ba6d5a3878d05", size = 359053, upload-time = "2025-11-30T20:22:19.297Z" },
+ { url = "https://files.pythonhosted.org/packages/65/1c/ae157e83a6357eceff62ba7e52113e3ec4834a84cfe07fa4b0757a7d105f/rpds_py-0.30.0-cp312-cp312-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:ca28829ae5f5d569bb62a79512c842a03a12576375d5ece7d2cadf8abe96ec28", size = 390763, upload-time = "2025-11-30T20:22:21.661Z" },
+ { url = "https://files.pythonhosted.org/packages/d4/36/eb2eb8515e2ad24c0bd43c3ee9cd74c33f7ca6430755ccdb240fd3144c44/rpds_py-0.30.0-cp312-cp312-manylinux_2_17_armv7l.manylinux2014_armv7l.whl", hash = "sha256:a1010ed9524c73b94d15919ca4d41d8780980e1765babf85f9a2f90d247153dd", size = 408951, upload-time = "2025-11-30T20:22:23.408Z" },
+ { url = "https://files.pythonhosted.org/packages/d6/65/ad8dc1784a331fabbd740ef6f71ce2198c7ed0890dab595adb9ea2d775a1/rpds_py-0.30.0-cp312-cp312-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:f8d1736cfb49381ba528cd5baa46f82fdc65c06e843dab24dd70b63d09121b3f", size = 514622, upload-time = "2025-11-30T20:22:25.16Z" },
+ { url = "https://files.pythonhosted.org/packages/63/8e/0cfa7ae158e15e143fe03993b5bcd743a59f541f5952e1546b1ac1b5fd45/rpds_py-0.30.0-cp312-cp312-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:d948b135c4693daff7bc2dcfc4ec57237a29bd37e60c2fabf5aff2bbacf3e2f1", size = 414492, upload-time = "2025-11-30T20:22:26.505Z" },
+ { url = "https://files.pythonhosted.org/packages/60/1b/6f8f29f3f995c7ffdde46a626ddccd7c63aefc0efae881dc13b6e5d5bb16/rpds_py-0.30.0-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:47f236970bccb2233267d89173d3ad2703cd36a0e2a6e92d0560d333871a3d23", size = 394080, upload-time = "2025-11-30T20:22:27.934Z" },
+ { url = "https://files.pythonhosted.org/packages/6d/d5/a266341051a7a3ca2f4b750a3aa4abc986378431fc2da508c5034d081b70/rpds_py-0.30.0-cp312-cp312-manylinux_2_31_riscv64.whl", hash = "sha256:2e6ecb5a5bcacf59c3f912155044479af1d0b6681280048b338b28e364aca1f6", size = 408680, upload-time = "2025-11-30T20:22:29.341Z" },
+ { url = "https://files.pythonhosted.org/packages/10/3b/71b725851df9ab7a7a4e33cf36d241933da66040d195a84781f49c50490c/rpds_py-0.30.0-cp312-cp312-manylinux_2_5_i686.manylinux1_i686.whl", hash = "sha256:a8fa71a2e078c527c3e9dc9fc5a98c9db40bcc8a92b4e8858e36d329f8684b51", size = 423589, upload-time = "2025-11-30T20:22:31.469Z" },
+ { url = "https://files.pythonhosted.org/packages/00/2b/e59e58c544dc9bd8bd8384ecdb8ea91f6727f0e37a7131baeff8d6f51661/rpds_py-0.30.0-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:73c67f2db7bc334e518d097c6d1e6fed021bbc9b7d678d6cc433478365d1d5f5", size = 573289, upload-time = "2025-11-30T20:22:32.997Z" },
+ { url = "https://files.pythonhosted.org/packages/da/3e/a18e6f5b460893172a7d6a680e86d3b6bc87a54c1f0b03446a3c8c7b588f/rpds_py-0.30.0-cp312-cp312-musllinux_1_2_i686.whl", hash = "sha256:5ba103fb455be00f3b1c2076c9d4264bfcb037c976167a6047ed82f23153f02e", size = 599737, upload-time = "2025-11-30T20:22:34.419Z" },
+ { url = "https://files.pythonhosted.org/packages/5c/e2/714694e4b87b85a18e2c243614974413c60aa107fd815b8cbc42b873d1d7/rpds_py-0.30.0-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:7cee9c752c0364588353e627da8a7e808a66873672bcb5f52890c33fd965b394", size = 563120, upload-time = "2025-11-30T20:22:35.903Z" },
+ { url = "https://files.pythonhosted.org/packages/6f/ab/d5d5e3bcedb0a77f4f613706b750e50a5a3ba1c15ccd3665ecc636c968fd/rpds_py-0.30.0-cp312-cp312-win32.whl", hash = "sha256:1ab5b83dbcf55acc8b08fc62b796ef672c457b17dbd7820a11d6c52c06839bdf", size = 223782, upload-time = "2025-11-30T20:22:37.271Z" },
+ { url = "https://files.pythonhosted.org/packages/39/3b/f786af9957306fdc38a74cef405b7b93180f481fb48453a114bb6465744a/rpds_py-0.30.0-cp312-cp312-win_amd64.whl", hash = "sha256:a090322ca841abd453d43456ac34db46e8b05fd9b3b4ac0c78bcde8b089f959b", size = 240463, upload-time = "2025-11-30T20:22:39.021Z" },
+ { url = "https://files.pythonhosted.org/packages/f3/d2/b91dc748126c1559042cfe41990deb92c4ee3e2b415f6b5234969ffaf0cc/rpds_py-0.30.0-cp312-cp312-win_arm64.whl", hash = "sha256:669b1805bd639dd2989b281be2cfd951c6121b65e729d9b843e9639ef1fd555e", size = 230868, upload-time = "2025-11-30T20:22:40.493Z" },
+ { url = "https://files.pythonhosted.org/packages/ed/dc/d61221eb88ff410de3c49143407f6f3147acf2538c86f2ab7ce65ae7d5f9/rpds_py-0.30.0-cp313-cp313-macosx_10_12_x86_64.whl", hash = "sha256:f83424d738204d9770830d35290ff3273fbb02b41f919870479fab14b9d303b2", size = 374887, upload-time = "2025-11-30T20:22:41.812Z" },
+ { url = "https://files.pythonhosted.org/packages/fd/32/55fb50ae104061dbc564ef15cc43c013dc4a9f4527a1f4d99baddf56fe5f/rpds_py-0.30.0-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:e7536cd91353c5273434b4e003cbda89034d67e7710eab8761fd918ec6c69cf8", size = 358904, upload-time = "2025-11-30T20:22:43.479Z" },
+ { url = "https://files.pythonhosted.org/packages/58/70/faed8186300e3b9bdd138d0273109784eea2396c68458ed580f885dfe7ad/rpds_py-0.30.0-cp313-cp313-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:2771c6c15973347f50fece41fc447c054b7ac2ae0502388ce3b6738cd366e3d4", size = 389945, upload-time = "2025-11-30T20:22:44.819Z" },
+ { url = "https://files.pythonhosted.org/packages/bd/a8/073cac3ed2c6387df38f71296d002ab43496a96b92c823e76f46b8af0543/rpds_py-0.30.0-cp313-cp313-manylinux_2_17_armv7l.manylinux2014_armv7l.whl", hash = "sha256:0a59119fc6e3f460315fe9d08149f8102aa322299deaa5cab5b40092345c2136", size = 407783, upload-time = "2025-11-30T20:22:46.103Z" },
+ { url = "https://files.pythonhosted.org/packages/77/57/5999eb8c58671f1c11eba084115e77a8899d6e694d2a18f69f0ba471ec8b/rpds_py-0.30.0-cp313-cp313-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:76fec018282b4ead0364022e3c54b60bf368b9d926877957a8624b58419169b7", size = 515021, upload-time = "2025-11-30T20:22:47.458Z" },
+ { url = "https://files.pythonhosted.org/packages/e0/af/5ab4833eadc36c0a8ed2bc5c0de0493c04f6c06de223170bd0798ff98ced/rpds_py-0.30.0-cp313-cp313-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:692bef75a5525db97318e8cd061542b5a79812d711ea03dbc1f6f8dbb0c5f0d2", size = 414589, upload-time = "2025-11-30T20:22:48.872Z" },
+ { url = "https://files.pythonhosted.org/packages/b7/de/f7192e12b21b9e9a68a6d0f249b4af3fdcdff8418be0767a627564afa1f1/rpds_py-0.30.0-cp313-cp313-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:9027da1ce107104c50c81383cae773ef5c24d296dd11c99e2629dbd7967a20c6", size = 394025, upload-time = "2025-11-30T20:22:50.196Z" },
+ { url = "https://files.pythonhosted.org/packages/91/c4/fc70cd0249496493500e7cc2de87504f5aa6509de1e88623431fec76d4b6/rpds_py-0.30.0-cp313-cp313-manylinux_2_31_riscv64.whl", hash = "sha256:9cf69cdda1f5968a30a359aba2f7f9aa648a9ce4b580d6826437f2b291cfc86e", size = 408895, upload-time = "2025-11-30T20:22:51.87Z" },
+ { url = "https://files.pythonhosted.org/packages/58/95/d9275b05ab96556fefff73a385813eb66032e4c99f411d0795372d9abcea/rpds_py-0.30.0-cp313-cp313-manylinux_2_5_i686.manylinux1_i686.whl", hash = "sha256:a4796a717bf12b9da9d3ad002519a86063dcac8988b030e405704ef7d74d2d9d", size = 422799, upload-time = "2025-11-30T20:22:53.341Z" },
+ { url = "https://files.pythonhosted.org/packages/06/c1/3088fc04b6624eb12a57eb814f0d4997a44b0d208d6cace713033ff1a6ba/rpds_py-0.30.0-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:5d4c2aa7c50ad4728a094ebd5eb46c452e9cb7edbfdb18f9e1221f597a73e1e7", size = 572731, upload-time = "2025-11-30T20:22:54.778Z" },
+ { url = "https://files.pythonhosted.org/packages/d8/42/c612a833183b39774e8ac8fecae81263a68b9583ee343db33ab571a7ce55/rpds_py-0.30.0-cp313-cp313-musllinux_1_2_i686.whl", hash = "sha256:ba81a9203d07805435eb06f536d95a266c21e5b2dfbf6517748ca40c98d19e31", size = 599027, upload-time = "2025-11-30T20:22:56.212Z" },
+ { url = "https://files.pythonhosted.org/packages/5f/60/525a50f45b01d70005403ae0e25f43c0384369ad24ffe46e8d9068b50086/rpds_py-0.30.0-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:945dccface01af02675628334f7cf49c2af4c1c904748efc5cf7bbdf0b579f95", size = 563020, upload-time = "2025-11-30T20:22:58.2Z" },
+ { url = "https://files.pythonhosted.org/packages/0b/5d/47c4655e9bcd5ca907148535c10e7d489044243cc9941c16ed7cd53be91d/rpds_py-0.30.0-cp313-cp313-win32.whl", hash = "sha256:b40fb160a2db369a194cb27943582b38f79fc4887291417685f3ad693c5a1d5d", size = 223139, upload-time = "2025-11-30T20:23:00.209Z" },
+ { url = "https://files.pythonhosted.org/packages/f2/e1/485132437d20aa4d3e1d8b3fb5a5e65aa8139f1e097080c2a8443201742c/rpds_py-0.30.0-cp313-cp313-win_amd64.whl", hash = "sha256:806f36b1b605e2d6a72716f321f20036b9489d29c51c91f4dd29a3e3afb73b15", size = 240224, upload-time = "2025-11-30T20:23:02.008Z" },
+ { url = "https://files.pythonhosted.org/packages/24/95/ffd128ed1146a153d928617b0ef673960130be0009c77d8fbf0abe306713/rpds_py-0.30.0-cp313-cp313-win_arm64.whl", hash = "sha256:d96c2086587c7c30d44f31f42eae4eac89b60dabbac18c7669be3700f13c3ce1", size = 230645, upload-time = "2025-11-30T20:23:03.43Z" },
+ { url = "https://files.pythonhosted.org/packages/ff/1b/b10de890a0def2a319a2626334a7f0ae388215eb60914dbac8a3bae54435/rpds_py-0.30.0-cp313-cp313t-macosx_10_12_x86_64.whl", hash = "sha256:eb0b93f2e5c2189ee831ee43f156ed34e2a89a78a66b98cadad955972548be5a", size = 364443, upload-time = "2025-11-30T20:23:04.878Z" },
+ { url = "https://files.pythonhosted.org/packages/0d/bf/27e39f5971dc4f305a4fb9c672ca06f290f7c4e261c568f3dea16a410d47/rpds_py-0.30.0-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:922e10f31f303c7c920da8981051ff6d8c1a56207dbdf330d9047f6d30b70e5e", size = 353375, upload-time = "2025-11-30T20:23:06.342Z" },
+ { url = "https://files.pythonhosted.org/packages/40/58/442ada3bba6e8e6615fc00483135c14a7538d2ffac30e2d933ccf6852232/rpds_py-0.30.0-cp313-cp313t-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:cdc62c8286ba9bf7f47befdcea13ea0e26bf294bda99758fd90535cbaf408000", size = 383850, upload-time = "2025-11-30T20:23:07.825Z" },
+ { url = "https://files.pythonhosted.org/packages/14/14/f59b0127409a33c6ef6f5c1ebd5ad8e32d7861c9c7adfa9a624fc3889f6c/rpds_py-0.30.0-cp313-cp313t-manylinux_2_17_armv7l.manylinux2014_armv7l.whl", hash = "sha256:47f9a91efc418b54fb8190a6b4aa7813a23fb79c51f4bb84e418f5476c38b8db", size = 392812, upload-time = "2025-11-30T20:23:09.228Z" },
+ { url = "https://files.pythonhosted.org/packages/b3/66/e0be3e162ac299b3a22527e8913767d869e6cc75c46bd844aa43fb81ab62/rpds_py-0.30.0-cp313-cp313t-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:1f3587eb9b17f3789ad50824084fa6f81921bbf9a795826570bda82cb3ed91f2", size = 517841, upload-time = "2025-11-30T20:23:11.186Z" },
+ { url = "https://files.pythonhosted.org/packages/3d/55/fa3b9cf31d0c963ecf1ba777f7cf4b2a2c976795ac430d24a1f43d25a6ba/rpds_py-0.30.0-cp313-cp313t-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:39c02563fc592411c2c61d26b6c5fe1e51eaa44a75aa2c8735ca88b0d9599daa", size = 408149, upload-time = "2025-11-30T20:23:12.864Z" },
+ { url = "https://files.pythonhosted.org/packages/60/ca/780cf3b1a32b18c0f05c441958d3758f02544f1d613abf9488cd78876378/rpds_py-0.30.0-cp313-cp313t-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:51a1234d8febafdfd33a42d97da7a43f5dcb120c1060e352a3fbc0c6d36e2083", size = 383843, upload-time = "2025-11-30T20:23:14.638Z" },
+ { url = "https://files.pythonhosted.org/packages/82/86/d5f2e04f2aa6247c613da0c1dd87fcd08fa17107e858193566048a1e2f0a/rpds_py-0.30.0-cp313-cp313t-manylinux_2_31_riscv64.whl", hash = "sha256:eb2c4071ab598733724c08221091e8d80e89064cd472819285a9ab0f24bcedb9", size = 396507, upload-time = "2025-11-30T20:23:16.105Z" },
+ { url = "https://files.pythonhosted.org/packages/4b/9a/453255d2f769fe44e07ea9785c8347edaf867f7026872e76c1ad9f7bed92/rpds_py-0.30.0-cp313-cp313t-manylinux_2_5_i686.manylinux1_i686.whl", hash = "sha256:6bdfdb946967d816e6adf9a3d8201bfad269c67efe6cefd7093ef959683c8de0", size = 414949, upload-time = "2025-11-30T20:23:17.539Z" },
+ { url = "https://files.pythonhosted.org/packages/a3/31/622a86cdc0c45d6df0e9ccb6becdba5074735e7033c20e401a6d9d0e2ca0/rpds_py-0.30.0-cp313-cp313t-musllinux_1_2_aarch64.whl", hash = "sha256:c77afbd5f5250bf27bf516c7c4a016813eb2d3e116139aed0096940c5982da94", size = 565790, upload-time = "2025-11-30T20:23:19.029Z" },
+ { url = "https://files.pythonhosted.org/packages/1c/5d/15bbf0fb4a3f58a3b1c67855ec1efcc4ceaef4e86644665fff03e1b66d8d/rpds_py-0.30.0-cp313-cp313t-musllinux_1_2_i686.whl", hash = "sha256:61046904275472a76c8c90c9ccee9013d70a6d0f73eecefd38c1ae7c39045a08", size = 590217, upload-time = "2025-11-30T20:23:20.885Z" },
+ { url = "https://files.pythonhosted.org/packages/6d/61/21b8c41f68e60c8cc3b2e25644f0e3681926020f11d06ab0b78e3c6bbff1/rpds_py-0.30.0-cp313-cp313t-musllinux_1_2_x86_64.whl", hash = "sha256:4c5f36a861bc4b7da6516dbdf302c55313afa09b81931e8280361a4f6c9a2d27", size = 555806, upload-time = "2025-11-30T20:23:22.488Z" },
+ { url = "https://files.pythonhosted.org/packages/f9/39/7e067bb06c31de48de3eb200f9fc7c58982a4d3db44b07e73963e10d3be9/rpds_py-0.30.0-cp313-cp313t-win32.whl", hash = "sha256:3d4a69de7a3e50ffc214ae16d79d8fbb0922972da0356dcf4d0fdca2878559c6", size = 211341, upload-time = "2025-11-30T20:23:24.449Z" },
+ { url = "https://files.pythonhosted.org/packages/0a/4d/222ef0b46443cf4cf46764d9c630f3fe4abaa7245be9417e56e9f52b8f65/rpds_py-0.30.0-cp313-cp313t-win_amd64.whl", hash = "sha256:f14fc5df50a716f7ece6a80b6c78bb35ea2ca47c499e422aa4463455dd96d56d", size = 225768, upload-time = "2025-11-30T20:23:25.908Z" },
+ { url = "https://files.pythonhosted.org/packages/86/81/dad16382ebbd3d0e0328776d8fd7ca94220e4fa0798d1dc5e7da48cb3201/rpds_py-0.30.0-cp314-cp314-macosx_10_12_x86_64.whl", hash = "sha256:68f19c879420aa08f61203801423f6cd5ac5f0ac4ac82a2368a9fcd6a9a075e0", size = 362099, upload-time = "2025-11-30T20:23:27.316Z" },
+ { url = "https://files.pythonhosted.org/packages/2b/60/19f7884db5d5603edf3c6bce35408f45ad3e97e10007df0e17dd57af18f8/rpds_py-0.30.0-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:ec7c4490c672c1a0389d319b3a9cfcd098dcdc4783991553c332a15acf7249be", size = 353192, upload-time = "2025-11-30T20:23:29.151Z" },
+ { url = "https://files.pythonhosted.org/packages/bf/c4/76eb0e1e72d1a9c4703c69607cec123c29028bff28ce41588792417098ac/rpds_py-0.30.0-cp314-cp314-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:f251c812357a3fed308d684a5079ddfb9d933860fc6de89f2b7ab00da481e65f", size = 384080, upload-time = "2025-11-30T20:23:30.785Z" },
+ { url = "https://files.pythonhosted.org/packages/72/87/87ea665e92f3298d1b26d78814721dc39ed8d2c74b86e83348d6b48a6f31/rpds_py-0.30.0-cp314-cp314-manylinux_2_17_armv7l.manylinux2014_armv7l.whl", hash = "sha256:ac98b175585ecf4c0348fd7b29c3864bda53b805c773cbf7bfdaffc8070c976f", size = 394841, upload-time = "2025-11-30T20:23:32.209Z" },
+ { url = "https://files.pythonhosted.org/packages/77/ad/7783a89ca0587c15dcbf139b4a8364a872a25f861bdb88ed99f9b0dec985/rpds_py-0.30.0-cp314-cp314-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:3e62880792319dbeb7eb866547f2e35973289e7d5696c6e295476448f5b63c87", size = 516670, upload-time = "2025-11-30T20:23:33.742Z" },
+ { url = "https://files.pythonhosted.org/packages/5b/3c/2882bdac942bd2172f3da574eab16f309ae10a3925644e969536553cb4ee/rpds_py-0.30.0-cp314-cp314-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:4e7fc54e0900ab35d041b0601431b0a0eb495f0851a0639b6ef90f7741b39a18", size = 408005, upload-time = "2025-11-30T20:23:35.253Z" },
+ { url = "https://files.pythonhosted.org/packages/ce/81/9a91c0111ce1758c92516a3e44776920b579d9a7c09b2b06b642d4de3f0f/rpds_py-0.30.0-cp314-cp314-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:47e77dc9822d3ad616c3d5759ea5631a75e5809d5a28707744ef79d7a1bcfcad", size = 382112, upload-time = "2025-11-30T20:23:36.842Z" },
+ { url = "https://files.pythonhosted.org/packages/cf/8e/1da49d4a107027e5fbc64daeab96a0706361a2918da10cb41769244b805d/rpds_py-0.30.0-cp314-cp314-manylinux_2_31_riscv64.whl", hash = "sha256:b4dc1a6ff022ff85ecafef7979a2c6eb423430e05f1165d6688234e62ba99a07", size = 399049, upload-time = "2025-11-30T20:23:38.343Z" },
+ { url = "https://files.pythonhosted.org/packages/df/5a/7ee239b1aa48a127570ec03becbb29c9d5a9eb092febbd1699d567cae859/rpds_py-0.30.0-cp314-cp314-manylinux_2_5_i686.manylinux1_i686.whl", hash = "sha256:4559c972db3a360808309e06a74628b95eaccbf961c335c8fe0d590cf587456f", size = 415661, upload-time = "2025-11-30T20:23:40.263Z" },
+ { url = "https://files.pythonhosted.org/packages/70/ea/caa143cf6b772f823bc7929a45da1fa83569ee49b11d18d0ada7f5ee6fd6/rpds_py-0.30.0-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:0ed177ed9bded28f8deb6ab40c183cd1192aa0de40c12f38be4d59cd33cb5c65", size = 565606, upload-time = "2025-11-30T20:23:42.186Z" },
+ { url = "https://files.pythonhosted.org/packages/64/91/ac20ba2d69303f961ad8cf55bf7dbdb4763f627291ba3d0d7d67333cced9/rpds_py-0.30.0-cp314-cp314-musllinux_1_2_i686.whl", hash = "sha256:ad1fa8db769b76ea911cb4e10f049d80bf518c104f15b3edb2371cc65375c46f", size = 591126, upload-time = "2025-11-30T20:23:44.086Z" },
+ { url = "https://files.pythonhosted.org/packages/21/20/7ff5f3c8b00c8a95f75985128c26ba44503fb35b8e0259d812766ea966c7/rpds_py-0.30.0-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:46e83c697b1f1c72b50e5ee5adb4353eef7406fb3f2043d64c33f20ad1c2fc53", size = 553371, upload-time = "2025-11-30T20:23:46.004Z" },
+ { url = "https://files.pythonhosted.org/packages/72/c7/81dadd7b27c8ee391c132a6b192111ca58d866577ce2d9b0ca157552cce0/rpds_py-0.30.0-cp314-cp314-win32.whl", hash = "sha256:ee454b2a007d57363c2dfd5b6ca4a5d7e2c518938f8ed3b706e37e5d470801ed", size = 215298, upload-time = "2025-11-30T20:23:47.696Z" },
+ { url = "https://files.pythonhosted.org/packages/3e/d2/1aaac33287e8cfb07aab2e6b8ac1deca62f6f65411344f1433c55e6f3eb8/rpds_py-0.30.0-cp314-cp314-win_amd64.whl", hash = "sha256:95f0802447ac2d10bcc69f6dc28fe95fdf17940367b21d34e34c737870758950", size = 228604, upload-time = "2025-11-30T20:23:49.501Z" },
+ { url = "https://files.pythonhosted.org/packages/e8/95/ab005315818cc519ad074cb7784dae60d939163108bd2b394e60dc7b5461/rpds_py-0.30.0-cp314-cp314-win_arm64.whl", hash = "sha256:613aa4771c99f03346e54c3f038e4cc574ac09a3ddfb0e8878487335e96dead6", size = 222391, upload-time = "2025-11-30T20:23:50.96Z" },
+ { url = "https://files.pythonhosted.org/packages/9e/68/154fe0194d83b973cdedcdcc88947a2752411165930182ae41d983dcefa6/rpds_py-0.30.0-cp314-cp314t-macosx_10_12_x86_64.whl", hash = "sha256:7e6ecfcb62edfd632e56983964e6884851786443739dbfe3582947e87274f7cb", size = 364868, upload-time = "2025-11-30T20:23:52.494Z" },
+ { url = "https://files.pythonhosted.org/packages/83/69/8bbc8b07ec854d92a8b75668c24d2abcb1719ebf890f5604c61c9369a16f/rpds_py-0.30.0-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:a1d0bc22a7cdc173fedebb73ef81e07faef93692b8c1ad3733b67e31e1b6e1b8", size = 353747, upload-time = "2025-11-30T20:23:54.036Z" },
+ { url = "https://files.pythonhosted.org/packages/ab/00/ba2e50183dbd9abcce9497fa5149c62b4ff3e22d338a30d690f9af970561/rpds_py-0.30.0-cp314-cp314t-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:0d08f00679177226c4cb8c5265012eea897c8ca3b93f429e546600c971bcbae7", size = 383795, upload-time = "2025-11-30T20:23:55.556Z" },
+ { url = "https://files.pythonhosted.org/packages/05/6f/86f0272b84926bcb0e4c972262f54223e8ecc556b3224d281e6598fc9268/rpds_py-0.30.0-cp314-cp314t-manylinux_2_17_armv7l.manylinux2014_armv7l.whl", hash = "sha256:5965af57d5848192c13534f90f9dd16464f3c37aaf166cc1da1cae1fd5a34898", size = 393330, upload-time = "2025-11-30T20:23:57.033Z" },
+ { url = "https://files.pythonhosted.org/packages/cb/e9/0e02bb2e6dc63d212641da45df2b0bf29699d01715913e0d0f017ee29438/rpds_py-0.30.0-cp314-cp314t-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:9a4e86e34e9ab6b667c27f3211ca48f73dba7cd3d90f8d5b11be56e5dbc3fb4e", size = 518194, upload-time = "2025-11-30T20:23:58.637Z" },
+ { url = "https://files.pythonhosted.org/packages/ee/ca/be7bca14cf21513bdf9c0606aba17d1f389ea2b6987035eb4f62bd923f25/rpds_py-0.30.0-cp314-cp314t-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:e5d3e6b26f2c785d65cc25ef1e5267ccbe1b069c5c21b8cc724efee290554419", size = 408340, upload-time = "2025-11-30T20:24:00.2Z" },
+ { url = "https://files.pythonhosted.org/packages/c2/c7/736e00ebf39ed81d75544c0da6ef7b0998f8201b369acf842f9a90dc8fce/rpds_py-0.30.0-cp314-cp314t-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:626a7433c34566535b6e56a1b39a7b17ba961e97ce3b80ec62e6f1312c025551", size = 383765, upload-time = "2025-11-30T20:24:01.759Z" },
+ { url = "https://files.pythonhosted.org/packages/4a/3f/da50dfde9956aaf365c4adc9533b100008ed31aea635f2b8d7b627e25b49/rpds_py-0.30.0-cp314-cp314t-manylinux_2_31_riscv64.whl", hash = "sha256:acd7eb3f4471577b9b5a41baf02a978e8bdeb08b4b355273994f8b87032000a8", size = 396834, upload-time = "2025-11-30T20:24:03.687Z" },
+ { url = "https://files.pythonhosted.org/packages/4e/00/34bcc2565b6020eab2623349efbdec810676ad571995911f1abdae62a3a0/rpds_py-0.30.0-cp314-cp314t-manylinux_2_5_i686.manylinux1_i686.whl", hash = "sha256:fe5fa731a1fa8a0a56b0977413f8cacac1768dad38d16b3a296712709476fbd5", size = 415470, upload-time = "2025-11-30T20:24:05.232Z" },
+ { url = "https://files.pythonhosted.org/packages/8c/28/882e72b5b3e6f718d5453bd4d0d9cf8df36fddeb4ddbbab17869d5868616/rpds_py-0.30.0-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:74a3243a411126362712ee1524dfc90c650a503502f135d54d1b352bd01f2404", size = 565630, upload-time = "2025-11-30T20:24:06.878Z" },
+ { url = "https://files.pythonhosted.org/packages/3b/97/04a65539c17692de5b85c6e293520fd01317fd878ea1995f0367d4532fb1/rpds_py-0.30.0-cp314-cp314t-musllinux_1_2_i686.whl", hash = "sha256:3e8eeb0544f2eb0d2581774be4c3410356eba189529a6b3e36bbbf9696175856", size = 591148, upload-time = "2025-11-30T20:24:08.445Z" },
+ { url = "https://files.pythonhosted.org/packages/85/70/92482ccffb96f5441aab93e26c4d66489eb599efdcf96fad90c14bbfb976/rpds_py-0.30.0-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:dbd936cde57abfee19ab3213cf9c26be06d60750e60a8e4dd85d1ab12c8b1f40", size = 556030, upload-time = "2025-11-30T20:24:10.956Z" },
+ { url = "https://files.pythonhosted.org/packages/20/53/7c7e784abfa500a2b6b583b147ee4bb5a2b3747a9166bab52fec4b5b5e7d/rpds_py-0.30.0-cp314-cp314t-win32.whl", hash = "sha256:dc824125c72246d924f7f796b4f63c1e9dc810c7d9e2355864b3c3a73d59ade0", size = 211570, upload-time = "2025-11-30T20:24:12.735Z" },
+ { url = "https://files.pythonhosted.org/packages/d0/02/fa464cdfbe6b26e0600b62c528b72d8608f5cc49f96b8d6e38c95d60c676/rpds_py-0.30.0-cp314-cp314t-win_amd64.whl", hash = "sha256:27f4b0e92de5bfbc6f86e43959e6edd1425c33b5e69aab0984a72047f2bcf1e3", size = 226532, upload-time = "2025-11-30T20:24:14.634Z" },
+]
+
+[[package]]
+name = "ruff"
+version = "0.14.8"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/ed/d9/f7a0c4b3a2bf2556cd5d99b05372c29980249ef71e8e32669ba77428c82c/ruff-0.14.8.tar.gz", hash = "sha256:774ed0dd87d6ce925e3b8496feb3a00ac564bea52b9feb551ecd17e0a23d1eed", size = 5765385, upload-time = "2025-12-04T15:06:17.669Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/48/b8/9537b52010134b1d2b72870cc3f92d5fb759394094741b09ceccae183fbe/ruff-0.14.8-py3-none-linux_armv6l.whl", hash = "sha256:ec071e9c82eca417f6111fd39f7043acb53cd3fde9b1f95bbed745962e345afb", size = 13441540, upload-time = "2025-12-04T15:06:14.896Z" },
+ { url = "https://files.pythonhosted.org/packages/24/00/99031684efb025829713682012b6dd37279b1f695ed1b01725f85fd94b38/ruff-0.14.8-py3-none-macosx_10_12_x86_64.whl", hash = "sha256:8cdb162a7159f4ca36ce980a18c43d8f036966e7f73f866ac8f493b75e0c27e9", size = 13669384, upload-time = "2025-12-04T15:06:51.809Z" },
+ { url = "https://files.pythonhosted.org/packages/72/64/3eb5949169fc19c50c04f28ece2c189d3b6edd57e5b533649dae6ca484fe/ruff-0.14.8-py3-none-macosx_11_0_arm64.whl", hash = "sha256:2e2fcbefe91f9fad0916850edf0854530c15bd1926b6b779de47e9ab619ea38f", size = 12806917, upload-time = "2025-12-04T15:06:08.925Z" },
+ { url = "https://files.pythonhosted.org/packages/c4/08/5250babb0b1b11910f470370ec0cbc67470231f7cdc033cee57d4976f941/ruff-0.14.8-py3-none-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:a9d70721066a296f45786ec31916dc287b44040f553da21564de0ab4d45a869b", size = 13256112, upload-time = "2025-12-04T15:06:23.498Z" },
+ { url = "https://files.pythonhosted.org/packages/78/4c/6c588e97a8e8c2d4b522c31a579e1df2b4d003eddfbe23d1f262b1a431ff/ruff-0.14.8-py3-none-manylinux_2_17_armv7l.manylinux2014_armv7l.whl", hash = "sha256:2c87e09b3cd9d126fc67a9ecd3b5b1d3ded2b9c7fce3f16e315346b9d05cfb52", size = 13227559, upload-time = "2025-12-04T15:06:33.432Z" },
+ { url = "https://files.pythonhosted.org/packages/23/ce/5f78cea13eda8eceac71b5f6fa6e9223df9b87bb2c1891c166d1f0dce9f1/ruff-0.14.8-py3-none-manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:1d62cb310c4fbcb9ee4ac023fe17f984ae1e12b8a4a02e3d21489f9a2a5f730c", size = 13896379, upload-time = "2025-12-04T15:06:02.687Z" },
+ { url = "https://files.pythonhosted.org/packages/cf/79/13de4517c4dadce9218a20035b21212a4c180e009507731f0d3b3f5df85a/ruff-0.14.8-py3-none-manylinux_2_17_ppc64.manylinux2014_ppc64.whl", hash = "sha256:1af35c2d62633d4da0521178e8a2641c636d2a7153da0bac1b30cfd4ccd91344", size = 15372786, upload-time = "2025-12-04T15:06:29.828Z" },
+ { url = "https://files.pythonhosted.org/packages/00/06/33df72b3bb42be8a1c3815fd4fae83fa2945fc725a25d87ba3e42d1cc108/ruff-0.14.8-py3-none-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:25add4575ffecc53d60eed3f24b1e934493631b48ebbc6ebaf9d8517924aca4b", size = 14990029, upload-time = "2025-12-04T15:06:36.812Z" },
+ { url = "https://files.pythonhosted.org/packages/64/61/0f34927bd90925880394de0e081ce1afab66d7b3525336f5771dcf0cb46c/ruff-0.14.8-py3-none-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:4c943d847b7f02f7db4201a0600ea7d244d8a404fbb639b439e987edcf2baf9a", size = 14407037, upload-time = "2025-12-04T15:06:39.979Z" },
+ { url = "https://files.pythonhosted.org/packages/96/bc/058fe0aefc0fbf0d19614cb6d1a3e2c048f7dc77ca64957f33b12cfdc5ef/ruff-0.14.8-py3-none-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:cb6e8bf7b4f627548daa1b69283dac5a296bfe9ce856703b03130732e20ddfe2", size = 14102390, upload-time = "2025-12-04T15:06:46.372Z" },
+ { url = "https://files.pythonhosted.org/packages/af/a4/e4f77b02b804546f4c17e8b37a524c27012dd6ff05855d2243b49a7d3cb9/ruff-0.14.8-py3-none-manylinux_2_31_riscv64.whl", hash = "sha256:7aaf2974f378e6b01d1e257c6948207aec6a9b5ba53fab23d0182efb887a0e4a", size = 14230793, upload-time = "2025-12-04T15:06:20.497Z" },
+ { url = "https://files.pythonhosted.org/packages/3f/52/bb8c02373f79552e8d087cedaffad76b8892033d2876c2498a2582f09dcf/ruff-0.14.8-py3-none-musllinux_1_2_aarch64.whl", hash = "sha256:e5758ca513c43ad8a4ef13f0f081f80f08008f410790f3611a21a92421ab045b", size = 13160039, upload-time = "2025-12-04T15:06:49.06Z" },
+ { url = "https://files.pythonhosted.org/packages/1f/ad/b69d6962e477842e25c0b11622548df746290cc6d76f9e0f4ed7456c2c31/ruff-0.14.8-py3-none-musllinux_1_2_armv7l.whl", hash = "sha256:f74f7ba163b6e85a8d81a590363bf71618847e5078d90827749bfda1d88c9cdf", size = 13205158, upload-time = "2025-12-04T15:06:54.574Z" },
+ { url = "https://files.pythonhosted.org/packages/06/63/54f23da1315c0b3dfc1bc03fbc34e10378918a20c0b0f086418734e57e74/ruff-0.14.8-py3-none-musllinux_1_2_i686.whl", hash = "sha256:eed28f6fafcc9591994c42254f5a5c5ca40e69a30721d2ab18bb0bb3baac3ab6", size = 13469550, upload-time = "2025-12-04T15:05:59.209Z" },
+ { url = "https://files.pythonhosted.org/packages/70/7d/a4d7b1961e4903bc37fffb7ddcfaa7beb250f67d97cfd1ee1d5cddb1ec90/ruff-0.14.8-py3-none-musllinux_1_2_x86_64.whl", hash = "sha256:21d48fa744c9d1cb8d71eb0a740c4dd02751a5de9db9a730a8ef75ca34cf138e", size = 14211332, upload-time = "2025-12-04T15:06:06.027Z" },
+ { url = "https://files.pythonhosted.org/packages/5d/93/2a5063341fa17054e5c86582136e9895db773e3c2ffb770dde50a09f35f0/ruff-0.14.8-py3-none-win32.whl", hash = "sha256:15f04cb45c051159baebb0f0037f404f1dc2f15a927418f29730f411a79bc4e7", size = 13151890, upload-time = "2025-12-04T15:06:11.668Z" },
+ { url = "https://files.pythonhosted.org/packages/02/1c/65c61a0859c0add13a3e1cbb6024b42de587456a43006ca2d4fd3d1618fe/ruff-0.14.8-py3-none-win_amd64.whl", hash = "sha256:9eeb0b24242b5bbff3011409a739929f497f3fb5fe3b5698aba5e77e8c833097", size = 14537826, upload-time = "2025-12-04T15:06:26.409Z" },
+ { url = "https://files.pythonhosted.org/packages/6d/63/8b41cea3afd7f58eb64ac9251668ee0073789a3bc9ac6f816c8c6fef986d/ruff-0.14.8-py3-none-win_arm64.whl", hash = "sha256:965a582c93c63fe715fd3e3f8aa37c4b776777203d8e1d8aa3cc0c14424a4b99", size = 13634522, upload-time = "2025-12-04T15:06:43.212Z" },
+]
+
+[[package]]
+name = "safetensors"
+version = "0.7.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/29/9c/6e74567782559a63bd040a236edca26fd71bc7ba88de2ef35d75df3bca5e/safetensors-0.7.0.tar.gz", hash = "sha256:07663963b67e8bd9f0b8ad15bb9163606cd27cc5a1b96235a50d8369803b96b0", size = 200878, upload-time = "2025-11-19T15:18:43.199Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/fa/47/aef6c06649039accf914afef490268e1067ed82be62bcfa5b7e886ad15e8/safetensors-0.7.0-cp38-abi3-macosx_10_12_x86_64.whl", hash = "sha256:c82f4d474cf725255d9e6acf17252991c3c8aac038d6ef363a4bf8be2f6db517", size = 467781, upload-time = "2025-11-19T15:18:35.84Z" },
+ { url = "https://files.pythonhosted.org/packages/e8/00/374c0c068e30cd31f1e1b46b4b5738168ec79e7689ca82ee93ddfea05109/safetensors-0.7.0-cp38-abi3-macosx_11_0_arm64.whl", hash = "sha256:94fd4858284736bb67a897a41608b5b0c2496c9bdb3bf2af1fa3409127f20d57", size = 447058, upload-time = "2025-11-19T15:18:34.416Z" },
+ { url = "https://files.pythonhosted.org/packages/f1/06/578ffed52c2296f93d7fd2d844cabfa92be51a587c38c8afbb8ae449ca89/safetensors-0.7.0-cp38-abi3-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:e07d91d0c92a31200f25351f4acb2bc6aff7f48094e13ebb1d0fb995b54b6542", size = 491748, upload-time = "2025-11-19T15:18:09.79Z" },
+ { url = "https://files.pythonhosted.org/packages/ae/33/1debbbb70e4791dde185edb9413d1fe01619255abb64b300157d7f15dddd/safetensors-0.7.0-cp38-abi3-manylinux_2_17_armv7l.manylinux2014_armv7l.whl", hash = "sha256:8469155f4cb518bafb4acf4865e8bb9d6804110d2d9bdcaa78564b9fd841e104", size = 503881, upload-time = "2025-11-19T15:18:16.145Z" },
+ { url = "https://files.pythonhosted.org/packages/8e/1c/40c2ca924d60792c3be509833df711b553c60effbd91da6f5284a83f7122/safetensors-0.7.0-cp38-abi3-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:54bef08bf00a2bff599982f6b08e8770e09cc012d7bba00783fc7ea38f1fb37d", size = 623463, upload-time = "2025-11-19T15:18:21.11Z" },
+ { url = "https://files.pythonhosted.org/packages/9b/3a/13784a9364bd43b0d61eef4bea2845039bc2030458b16594a1bd787ae26e/safetensors-0.7.0-cp38-abi3-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:42cb091236206bb2016d245c377ed383aa7f78691748f3bb6ee1bfa51ae2ce6a", size = 532855, upload-time = "2025-11-19T15:18:25.719Z" },
+ { url = "https://files.pythonhosted.org/packages/a0/60/429e9b1cb3fc651937727befe258ea24122d9663e4d5709a48c9cbfceecb/safetensors-0.7.0-cp38-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:dac7252938f0696ddea46f5e855dd3138444e82236e3be475f54929f0c510d48", size = 507152, upload-time = "2025-11-19T15:18:33.023Z" },
+ { url = "https://files.pythonhosted.org/packages/3c/a8/4b45e4e059270d17af60359713ffd83f97900d45a6afa73aaa0d737d48b6/safetensors-0.7.0-cp38-abi3-manylinux_2_5_i686.manylinux1_i686.whl", hash = "sha256:1d060c70284127fa805085d8f10fbd0962792aed71879d00864acda69dbab981", size = 541856, upload-time = "2025-11-19T15:18:31.075Z" },
+ { url = "https://files.pythonhosted.org/packages/06/87/d26d8407c44175d8ae164a95b5a62707fcc445f3c0c56108e37d98070a3d/safetensors-0.7.0-cp38-abi3-musllinux_1_2_aarch64.whl", hash = "sha256:cdab83a366799fa730f90a4ebb563e494f28e9e92c4819e556152ad55e43591b", size = 674060, upload-time = "2025-11-19T15:18:37.211Z" },
+ { url = "https://files.pythonhosted.org/packages/11/f5/57644a2ff08dc6325816ba7217e5095f17269dada2554b658442c66aed51/safetensors-0.7.0-cp38-abi3-musllinux_1_2_armv7l.whl", hash = "sha256:672132907fcad9f2aedcb705b2d7b3b93354a2aec1b2f706c4db852abe338f85", size = 771715, upload-time = "2025-11-19T15:18:38.689Z" },
+ { url = "https://files.pythonhosted.org/packages/86/31/17883e13a814bd278ae6e266b13282a01049b0c81341da7fd0e3e71a80a3/safetensors-0.7.0-cp38-abi3-musllinux_1_2_i686.whl", hash = "sha256:5d72abdb8a4d56d4020713724ba81dac065fedb7f3667151c4a637f1d3fb26c0", size = 714377, upload-time = "2025-11-19T15:18:40.162Z" },
+ { url = "https://files.pythonhosted.org/packages/4a/d8/0c8a7dc9b41dcac53c4cbf9df2b9c83e0e0097203de8b37a712b345c0be5/safetensors-0.7.0-cp38-abi3-musllinux_1_2_x86_64.whl", hash = "sha256:b0f6d66c1c538d5a94a73aa9ddca8ccc4227e6c9ff555322ea40bdd142391dd4", size = 677368, upload-time = "2025-11-19T15:18:41.627Z" },
+ { url = "https://files.pythonhosted.org/packages/05/e5/cb4b713c8a93469e3c5be7c3f8d77d307e65fe89673e731f5c2bfd0a9237/safetensors-0.7.0-cp38-abi3-win32.whl", hash = "sha256:c74af94bf3ac15ac4d0f2a7c7b4663a15f8c2ab15ed0fc7531ca61d0835eccba", size = 326423, upload-time = "2025-11-19T15:18:45.74Z" },
+ { url = "https://files.pythonhosted.org/packages/5d/e6/ec8471c8072382cb91233ba7267fd931219753bb43814cbc71757bfd4dab/safetensors-0.7.0-cp38-abi3-win_amd64.whl", hash = "sha256:d1239932053f56f3456f32eb9625590cc7582e905021f94636202a864d470755", size = 341380, upload-time = "2025-11-19T15:18:44.427Z" },
+]
+
+[[package]]
+name = "scikit-learn"
+version = "1.7.2"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "joblib" },
+ { name = "numpy" },
+ { name = "scipy" },
+ { name = "threadpoolctl" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/98/c2/a7855e41c9d285dfe86dc50b250978105dce513d6e459ea66a6aeb0e1e0c/scikit_learn-1.7.2.tar.gz", hash = "sha256:20e9e49ecd130598f1ca38a1d85090e1a600147b9c02fa6f15d69cb53d968fda", size = 7193136, upload-time = "2025-09-09T08:21:29.075Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/a7/aa/3996e2196075689afb9fce0410ebdb4a09099d7964d061d7213700204409/scikit_learn-1.7.2-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:8d91a97fa2b706943822398ab943cde71858a50245e31bc71dba62aab1d60a96", size = 9259818, upload-time = "2025-09-09T08:20:43.19Z" },
+ { url = "https://files.pythonhosted.org/packages/43/5d/779320063e88af9c4a7c2cf463ff11c21ac9c8bd730c4a294b0000b666c9/scikit_learn-1.7.2-cp312-cp312-macosx_12_0_arm64.whl", hash = "sha256:acbc0f5fd2edd3432a22c69bed78e837c70cf896cd7993d71d51ba6708507476", size = 8636997, upload-time = "2025-09-09T08:20:45.468Z" },
+ { url = "https://files.pythonhosted.org/packages/5c/d0/0c577d9325b05594fdd33aa970bf53fb673f051a45496842caee13cfd7fe/scikit_learn-1.7.2-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:e5bf3d930aee75a65478df91ac1225ff89cd28e9ac7bd1196853a9229b6adb0b", size = 9478381, upload-time = "2025-09-09T08:20:47.982Z" },
+ { url = "https://files.pythonhosted.org/packages/82/70/8bf44b933837ba8494ca0fc9a9ab60f1c13b062ad0197f60a56e2fc4c43e/scikit_learn-1.7.2-cp312-cp312-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:b4d6e9deed1a47aca9fe2f267ab8e8fe82ee20b4526b2c0cd9e135cea10feb44", size = 9300296, upload-time = "2025-09-09T08:20:50.366Z" },
+ { url = "https://files.pythonhosted.org/packages/c6/99/ed35197a158f1fdc2fe7c3680e9c70d0128f662e1fee4ed495f4b5e13db0/scikit_learn-1.7.2-cp312-cp312-win_amd64.whl", hash = "sha256:6088aa475f0785e01bcf8529f55280a3d7d298679f50c0bb70a2364a82d0b290", size = 8731256, upload-time = "2025-09-09T08:20:52.627Z" },
+ { url = "https://files.pythonhosted.org/packages/ae/93/a3038cb0293037fd335f77f31fe053b89c72f17b1c8908c576c29d953e84/scikit_learn-1.7.2-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:0b7dacaa05e5d76759fb071558a8b5130f4845166d88654a0f9bdf3eb57851b7", size = 9212382, upload-time = "2025-09-09T08:20:54.731Z" },
+ { url = "https://files.pythonhosted.org/packages/40/dd/9a88879b0c1104259136146e4742026b52df8540c39fec21a6383f8292c7/scikit_learn-1.7.2-cp313-cp313-macosx_12_0_arm64.whl", hash = "sha256:abebbd61ad9e1deed54cca45caea8ad5f79e1b93173dece40bb8e0c658dbe6fe", size = 8592042, upload-time = "2025-09-09T08:20:57.313Z" },
+ { url = "https://files.pythonhosted.org/packages/46/af/c5e286471b7d10871b811b72ae794ac5fe2989c0a2df07f0ec723030f5f5/scikit_learn-1.7.2-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:502c18e39849c0ea1a5d681af1dbcf15f6cce601aebb657aabbfe84133c1907f", size = 9434180, upload-time = "2025-09-09T08:20:59.671Z" },
+ { url = "https://files.pythonhosted.org/packages/f1/fd/df59faa53312d585023b2da27e866524ffb8faf87a68516c23896c718320/scikit_learn-1.7.2-cp313-cp313-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:7a4c328a71785382fe3fe676a9ecf2c86189249beff90bf85e22bdb7efaf9ae0", size = 9283660, upload-time = "2025-09-09T08:21:01.71Z" },
+ { url = "https://files.pythonhosted.org/packages/a7/c7/03000262759d7b6f38c836ff9d512f438a70d8a8ddae68ee80de72dcfb63/scikit_learn-1.7.2-cp313-cp313-win_amd64.whl", hash = "sha256:63a9afd6f7b229aad94618c01c252ce9e6fa97918c5ca19c9a17a087d819440c", size = 8702057, upload-time = "2025-09-09T08:21:04.234Z" },
+ { url = "https://files.pythonhosted.org/packages/55/87/ef5eb1f267084532c8e4aef98a28b6ffe7425acbfd64b5e2f2e066bc29b3/scikit_learn-1.7.2-cp313-cp313t-macosx_10_13_x86_64.whl", hash = "sha256:9acb6c5e867447b4e1390930e3944a005e2cb115922e693c08a323421a6966e8", size = 9558731, upload-time = "2025-09-09T08:21:06.381Z" },
+ { url = "https://files.pythonhosted.org/packages/93/f8/6c1e3fc14b10118068d7938878a9f3f4e6d7b74a8ddb1e5bed65159ccda8/scikit_learn-1.7.2-cp313-cp313t-macosx_12_0_arm64.whl", hash = "sha256:2a41e2a0ef45063e654152ec9d8bcfc39f7afce35b08902bfe290c2498a67a6a", size = 9038852, upload-time = "2025-09-09T08:21:08.628Z" },
+ { url = "https://files.pythonhosted.org/packages/83/87/066cafc896ee540c34becf95d30375fe5cbe93c3b75a0ee9aa852cd60021/scikit_learn-1.7.2-cp313-cp313t-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:98335fb98509b73385b3ab2bd0639b1f610541d3988ee675c670371d6a87aa7c", size = 9527094, upload-time = "2025-09-09T08:21:11.486Z" },
+ { url = "https://files.pythonhosted.org/packages/9c/2b/4903e1ccafa1f6453b1ab78413938c8800633988c838aa0be386cbb33072/scikit_learn-1.7.2-cp313-cp313t-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:191e5550980d45449126e23ed1d5e9e24b2c68329ee1f691a3987476e115e09c", size = 9367436, upload-time = "2025-09-09T08:21:13.602Z" },
+ { url = "https://files.pythonhosted.org/packages/b5/aa/8444be3cfb10451617ff9d177b3c190288f4563e6c50ff02728be67ad094/scikit_learn-1.7.2-cp313-cp313t-win_amd64.whl", hash = "sha256:57dc4deb1d3762c75d685507fbd0bc17160144b2f2ba4ccea5dc285ab0d0e973", size = 9275749, upload-time = "2025-09-09T08:21:15.96Z" },
+ { url = "https://files.pythonhosted.org/packages/d9/82/dee5acf66837852e8e68df6d8d3a6cb22d3df997b733b032f513d95205b7/scikit_learn-1.7.2-cp314-cp314-macosx_10_13_x86_64.whl", hash = "sha256:fa8f63940e29c82d1e67a45d5297bdebbcb585f5a5a50c4914cc2e852ab77f33", size = 9208906, upload-time = "2025-09-09T08:21:18.557Z" },
+ { url = "https://files.pythonhosted.org/packages/3c/30/9029e54e17b87cb7d50d51a5926429c683d5b4c1732f0507a6c3bed9bf65/scikit_learn-1.7.2-cp314-cp314-macosx_12_0_arm64.whl", hash = "sha256:f95dc55b7902b91331fa4e5845dd5bde0580c9cd9612b1b2791b7e80c3d32615", size = 8627836, upload-time = "2025-09-09T08:21:20.695Z" },
+ { url = "https://files.pythonhosted.org/packages/60/18/4a52c635c71b536879f4b971c2cedf32c35ee78f48367885ed8025d1f7ee/scikit_learn-1.7.2-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:9656e4a53e54578ad10a434dc1f993330568cfee176dff07112b8785fb413106", size = 9426236, upload-time = "2025-09-09T08:21:22.645Z" },
+ { url = "https://files.pythonhosted.org/packages/99/7e/290362f6ab582128c53445458a5befd471ed1ea37953d5bcf80604619250/scikit_learn-1.7.2-cp314-cp314-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:96dc05a854add0e50d3f47a1ef21a10a595016da5b007c7d9cd9d0bffd1fcc61", size = 9312593, upload-time = "2025-09-09T08:21:24.65Z" },
+ { url = "https://files.pythonhosted.org/packages/8e/87/24f541b6d62b1794939ae6422f8023703bbf6900378b2b34e0b4384dfefd/scikit_learn-1.7.2-cp314-cp314-win_amd64.whl", hash = "sha256:bb24510ed3f9f61476181e4db51ce801e2ba37541def12dc9333b946fc7a9cf8", size = 8820007, upload-time = "2025-09-09T08:21:26.713Z" },
+]
+
+[[package]]
+name = "scipy"
+version = "1.16.3"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "numpy" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/0a/ca/d8ace4f98322d01abcd52d381134344bf7b431eba7ed8b42bdea5a3c2ac9/scipy-1.16.3.tar.gz", hash = "sha256:01e87659402762f43bd2fee13370553a17ada367d42e7487800bf2916535aecb", size = 30597883, upload-time = "2025-10-28T17:38:54.068Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/40/41/5bf55c3f386b1643812f3a5674edf74b26184378ef0f3e7c7a09a7e2ca7f/scipy-1.16.3-cp312-cp312-macosx_10_14_x86_64.whl", hash = "sha256:81fc5827606858cf71446a5e98715ba0e11f0dbc83d71c7409d05486592a45d6", size = 36659043, upload-time = "2025-10-28T17:32:40.285Z" },
+ { url = "https://files.pythonhosted.org/packages/1e/0f/65582071948cfc45d43e9870bf7ca5f0e0684e165d7c9ef4e50d783073eb/scipy-1.16.3-cp312-cp312-macosx_12_0_arm64.whl", hash = "sha256:c97176013d404c7346bf57874eaac5187d969293bf40497140b0a2b2b7482e07", size = 28898986, upload-time = "2025-10-28T17:32:45.325Z" },
+ { url = "https://files.pythonhosted.org/packages/96/5e/36bf3f0ac298187d1ceadde9051177d6a4fe4d507e8f59067dc9dd39e650/scipy-1.16.3-cp312-cp312-macosx_14_0_arm64.whl", hash = "sha256:2b71d93c8a9936046866acebc915e2af2e292b883ed6e2cbe5c34beb094b82d9", size = 20889814, upload-time = "2025-10-28T17:32:49.277Z" },
+ { url = "https://files.pythonhosted.org/packages/80/35/178d9d0c35394d5d5211bbff7ac4f2986c5488b59506fef9e1de13ea28d3/scipy-1.16.3-cp312-cp312-macosx_14_0_x86_64.whl", hash = "sha256:3d4a07a8e785d80289dfe66b7c27d8634a773020742ec7187b85ccc4b0e7b686", size = 23565795, upload-time = "2025-10-28T17:32:53.337Z" },
+ { url = "https://files.pythonhosted.org/packages/fa/46/d1146ff536d034d02f83c8afc3c4bab2eddb634624d6529a8512f3afc9da/scipy-1.16.3-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.whl", hash = "sha256:0553371015692a898e1aa858fed67a3576c34edefa6b7ebdb4e9dde49ce5c203", size = 33349476, upload-time = "2025-10-28T17:32:58.353Z" },
+ { url = "https://files.pythonhosted.org/packages/79/2e/415119c9ab3e62249e18c2b082c07aff907a273741b3f8160414b0e9193c/scipy-1.16.3-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:72d1717fd3b5e6ec747327ce9bda32d5463f472c9dce9f54499e81fbd50245a1", size = 35676692, upload-time = "2025-10-28T17:33:03.88Z" },
+ { url = "https://files.pythonhosted.org/packages/27/82/df26e44da78bf8d2aeaf7566082260cfa15955a5a6e96e6a29935b64132f/scipy-1.16.3-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:1fb2472e72e24d1530debe6ae078db70fb1605350c88a3d14bc401d6306dbffe", size = 36019345, upload-time = "2025-10-28T17:33:09.773Z" },
+ { url = "https://files.pythonhosted.org/packages/82/31/006cbb4b648ba379a95c87262c2855cd0d09453e500937f78b30f02fa1cd/scipy-1.16.3-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:c5192722cffe15f9329a3948c4b1db789fbb1f05c97899187dcf009b283aea70", size = 38678975, upload-time = "2025-10-28T17:33:15.809Z" },
+ { url = "https://files.pythonhosted.org/packages/c2/7f/acbd28c97e990b421af7d6d6cd416358c9c293fc958b8529e0bd5d2a2a19/scipy-1.16.3-cp312-cp312-win_amd64.whl", hash = "sha256:56edc65510d1331dae01ef9b658d428e33ed48b4f77b1d51caf479a0253f96dc", size = 38555926, upload-time = "2025-10-28T17:33:21.388Z" },
+ { url = "https://files.pythonhosted.org/packages/ce/69/c5c7807fd007dad4f48e0a5f2153038dc96e8725d3345b9ee31b2b7bed46/scipy-1.16.3-cp312-cp312-win_arm64.whl", hash = "sha256:a8a26c78ef223d3e30920ef759e25625a0ecdd0d60e5a8818b7513c3e5384cf2", size = 25463014, upload-time = "2025-10-28T17:33:25.975Z" },
+ { url = "https://files.pythonhosted.org/packages/72/f1/57e8327ab1508272029e27eeef34f2302ffc156b69e7e233e906c2a5c379/scipy-1.16.3-cp313-cp313-macosx_10_14_x86_64.whl", hash = "sha256:d2ec56337675e61b312179a1ad124f5f570c00f920cc75e1000025451b88241c", size = 36617856, upload-time = "2025-10-28T17:33:31.375Z" },
+ { url = "https://files.pythonhosted.org/packages/44/13/7e63cfba8a7452eb756306aa2fd9b37a29a323b672b964b4fdeded9a3f21/scipy-1.16.3-cp313-cp313-macosx_12_0_arm64.whl", hash = "sha256:16b8bc35a4cc24db80a0ec836a9286d0e31b2503cb2fd7ff7fb0e0374a97081d", size = 28874306, upload-time = "2025-10-28T17:33:36.516Z" },
+ { url = "https://files.pythonhosted.org/packages/15/65/3a9400efd0228a176e6ec3454b1fa998fbbb5a8defa1672c3f65706987db/scipy-1.16.3-cp313-cp313-macosx_14_0_arm64.whl", hash = "sha256:5803c5fadd29de0cf27fa08ccbfe7a9e5d741bf63e4ab1085437266f12460ff9", size = 20865371, upload-time = "2025-10-28T17:33:42.094Z" },
+ { url = "https://files.pythonhosted.org/packages/33/d7/eda09adf009a9fb81827194d4dd02d2e4bc752cef16737cc4ef065234031/scipy-1.16.3-cp313-cp313-macosx_14_0_x86_64.whl", hash = "sha256:b81c27fc41954319a943d43b20e07c40bdcd3ff7cf013f4fb86286faefe546c4", size = 23524877, upload-time = "2025-10-28T17:33:48.483Z" },
+ { url = "https://files.pythonhosted.org/packages/7d/6b/3f911e1ebc364cb81320223a3422aab7d26c9c7973109a9cd0f27c64c6c0/scipy-1.16.3-cp313-cp313-manylinux2014_aarch64.manylinux_2_17_aarch64.whl", hash = "sha256:0c3b4dd3d9b08dbce0f3440032c52e9e2ab9f96ade2d3943313dfe51a7056959", size = 33342103, upload-time = "2025-10-28T17:33:56.495Z" },
+ { url = "https://files.pythonhosted.org/packages/21/f6/4bfb5695d8941e5c570a04d9fcd0d36bce7511b7d78e6e75c8f9791f82d0/scipy-1.16.3-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:7dc1360c06535ea6116a2220f760ae572db9f661aba2d88074fe30ec2aa1ff88", size = 35697297, upload-time = "2025-10-28T17:34:04.722Z" },
+ { url = "https://files.pythonhosted.org/packages/04/e1/6496dadbc80d8d896ff72511ecfe2316b50313bfc3ebf07a3f580f08bd8c/scipy-1.16.3-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:663b8d66a8748051c3ee9c96465fb417509315b99c71550fda2591d7dd634234", size = 36021756, upload-time = "2025-10-28T17:34:13.482Z" },
+ { url = "https://files.pythonhosted.org/packages/fe/bd/a8c7799e0136b987bda3e1b23d155bcb31aec68a4a472554df5f0937eef7/scipy-1.16.3-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:eab43fae33a0c39006a88096cd7b4f4ef545ea0447d250d5ac18202d40b6611d", size = 38696566, upload-time = "2025-10-28T17:34:22.384Z" },
+ { url = "https://files.pythonhosted.org/packages/cd/01/1204382461fcbfeb05b6161b594f4007e78b6eba9b375382f79153172b4d/scipy-1.16.3-cp313-cp313-win_amd64.whl", hash = "sha256:062246acacbe9f8210de8e751b16fc37458213f124bef161a5a02c7a39284304", size = 38529877, upload-time = "2025-10-28T17:35:51.076Z" },
+ { url = "https://files.pythonhosted.org/packages/7f/14/9d9fbcaa1260a94f4bb5b64ba9213ceb5d03cd88841fe9fd1ffd47a45b73/scipy-1.16.3-cp313-cp313-win_arm64.whl", hash = "sha256:50a3dbf286dbc7d84f176f9a1574c705f277cb6565069f88f60db9eafdbe3ee2", size = 25455366, upload-time = "2025-10-28T17:35:59.014Z" },
+ { url = "https://files.pythonhosted.org/packages/e2/a3/9ec205bd49f42d45d77f1730dbad9ccf146244c1647605cf834b3a8c4f36/scipy-1.16.3-cp313-cp313t-macosx_10_14_x86_64.whl", hash = "sha256:fb4b29f4cf8cc5a8d628bc8d8e26d12d7278cd1f219f22698a378c3d67db5e4b", size = 37027931, upload-time = "2025-10-28T17:34:31.451Z" },
+ { url = "https://files.pythonhosted.org/packages/25/06/ca9fd1f3a4589cbd825b1447e5db3a8ebb969c1eaf22c8579bd286f51b6d/scipy-1.16.3-cp313-cp313t-macosx_12_0_arm64.whl", hash = "sha256:8d09d72dc92742988b0e7750bddb8060b0c7079606c0d24a8cc8e9c9c11f9079", size = 29400081, upload-time = "2025-10-28T17:34:39.087Z" },
+ { url = "https://files.pythonhosted.org/packages/6a/56/933e68210d92657d93fb0e381683bc0e53a965048d7358ff5fbf9e6a1b17/scipy-1.16.3-cp313-cp313t-macosx_14_0_arm64.whl", hash = "sha256:03192a35e661470197556de24e7cb1330d84b35b94ead65c46ad6f16f6b28f2a", size = 21391244, upload-time = "2025-10-28T17:34:45.234Z" },
+ { url = "https://files.pythonhosted.org/packages/a8/7e/779845db03dc1418e215726329674b40576879b91814568757ff0014ad65/scipy-1.16.3-cp313-cp313t-macosx_14_0_x86_64.whl", hash = "sha256:57d01cb6f85e34f0946b33caa66e892aae072b64b034183f3d87c4025802a119", size = 23929753, upload-time = "2025-10-28T17:34:51.793Z" },
+ { url = "https://files.pythonhosted.org/packages/4c/4b/f756cf8161d5365dcdef9e5f460ab226c068211030a175d2fc7f3f41ca64/scipy-1.16.3-cp313-cp313t-manylinux2014_aarch64.manylinux_2_17_aarch64.whl", hash = "sha256:96491a6a54e995f00a28a3c3badfff58fd093bf26cd5fb34a2188c8c756a3a2c", size = 33496912, upload-time = "2025-10-28T17:34:59.8Z" },
+ { url = "https://files.pythonhosted.org/packages/09/b5/222b1e49a58668f23839ca1542a6322bb095ab8d6590d4f71723869a6c2c/scipy-1.16.3-cp313-cp313t-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:cd13e354df9938598af2be05822c323e97132d5e6306b83a3b4ee6724c6e522e", size = 35802371, upload-time = "2025-10-28T17:35:08.173Z" },
+ { url = "https://files.pythonhosted.org/packages/c1/8d/5964ef68bb31829bde27611f8c9deeac13764589fe74a75390242b64ca44/scipy-1.16.3-cp313-cp313t-musllinux_1_2_aarch64.whl", hash = "sha256:63d3cdacb8a824a295191a723ee5e4ea7768ca5ca5f2838532d9f2e2b3ce2135", size = 36190477, upload-time = "2025-10-28T17:35:16.7Z" },
+ { url = "https://files.pythonhosted.org/packages/ab/f2/b31d75cb9b5fa4dd39a0a931ee9b33e7f6f36f23be5ef560bf72e0f92f32/scipy-1.16.3-cp313-cp313t-musllinux_1_2_x86_64.whl", hash = "sha256:e7efa2681ea410b10dde31a52b18b0154d66f2485328830e45fdf183af5aefc6", size = 38796678, upload-time = "2025-10-28T17:35:26.354Z" },
+ { url = "https://files.pythonhosted.org/packages/b4/1e/b3723d8ff64ab548c38d87055483714fefe6ee20e0189b62352b5e015bb1/scipy-1.16.3-cp313-cp313t-win_amd64.whl", hash = "sha256:2d1ae2cf0c350e7705168ff2429962a89ad90c2d49d1dd300686d8b2a5af22fc", size = 38640178, upload-time = "2025-10-28T17:35:35.304Z" },
+ { url = "https://files.pythonhosted.org/packages/8e/f3/d854ff38789aca9b0cc23008d607ced9de4f7ab14fa1ca4329f86b3758ca/scipy-1.16.3-cp313-cp313t-win_arm64.whl", hash = "sha256:0c623a54f7b79dd88ef56da19bc2873afec9673a48f3b85b18e4d402bdd29a5a", size = 25803246, upload-time = "2025-10-28T17:35:42.155Z" },
+ { url = "https://files.pythonhosted.org/packages/99/f6/99b10fd70f2d864c1e29a28bbcaa0c6340f9d8518396542d9ea3b4aaae15/scipy-1.16.3-cp314-cp314-macosx_10_14_x86_64.whl", hash = "sha256:875555ce62743e1d54f06cdf22c1e0bc47b91130ac40fe5d783b6dfa114beeb6", size = 36606469, upload-time = "2025-10-28T17:36:08.741Z" },
+ { url = "https://files.pythonhosted.org/packages/4d/74/043b54f2319f48ea940dd025779fa28ee360e6b95acb7cd188fad4391c6b/scipy-1.16.3-cp314-cp314-macosx_12_0_arm64.whl", hash = "sha256:bb61878c18a470021fb515a843dc7a76961a8daceaaaa8bad1332f1bf4b54657", size = 28872043, upload-time = "2025-10-28T17:36:16.599Z" },
+ { url = "https://files.pythonhosted.org/packages/4d/e1/24b7e50cc1c4ee6ffbcb1f27fe9f4c8b40e7911675f6d2d20955f41c6348/scipy-1.16.3-cp314-cp314-macosx_14_0_arm64.whl", hash = "sha256:f2622206f5559784fa5c4b53a950c3c7c1cf3e84ca1b9c4b6c03f062f289ca26", size = 20862952, upload-time = "2025-10-28T17:36:22.966Z" },
+ { url = "https://files.pythonhosted.org/packages/dd/3a/3e8c01a4d742b730df368e063787c6808597ccb38636ed821d10b39ca51b/scipy-1.16.3-cp314-cp314-macosx_14_0_x86_64.whl", hash = "sha256:7f68154688c515cdb541a31ef8eb66d8cd1050605be9dcd74199cbd22ac739bc", size = 23508512, upload-time = "2025-10-28T17:36:29.731Z" },
+ { url = "https://files.pythonhosted.org/packages/1f/60/c45a12b98ad591536bfe5330cb3cfe1850d7570259303563b1721564d458/scipy-1.16.3-cp314-cp314-manylinux2014_aarch64.manylinux_2_17_aarch64.whl", hash = "sha256:8b3c820ddb80029fe9f43d61b81d8b488d3ef8ca010d15122b152db77dc94c22", size = 33413639, upload-time = "2025-10-28T17:36:37.982Z" },
+ { url = "https://files.pythonhosted.org/packages/71/bc/35957d88645476307e4839712642896689df442f3e53b0fa016ecf8a3357/scipy-1.16.3-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:d3837938ae715fc0fe3c39c0202de3a8853aff22ca66781ddc2ade7554b7e2cc", size = 35704729, upload-time = "2025-10-28T17:36:46.547Z" },
+ { url = "https://files.pythonhosted.org/packages/3b/15/89105e659041b1ca11c386e9995aefacd513a78493656e57789f9d9eab61/scipy-1.16.3-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:aadd23f98f9cb069b3bd64ddc900c4d277778242e961751f77a8cb5c4b946fb0", size = 36086251, upload-time = "2025-10-28T17:36:55.161Z" },
+ { url = "https://files.pythonhosted.org/packages/1a/87/c0ea673ac9c6cc50b3da2196d860273bc7389aa69b64efa8493bdd25b093/scipy-1.16.3-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:b7c5f1bda1354d6a19bc6af73a649f8285ca63ac6b52e64e658a5a11d4d69800", size = 38716681, upload-time = "2025-10-28T17:37:04.1Z" },
+ { url = "https://files.pythonhosted.org/packages/91/06/837893227b043fb9b0d13e4bd7586982d8136cb249ffb3492930dab905b8/scipy-1.16.3-cp314-cp314-win_amd64.whl", hash = "sha256:e5d42a9472e7579e473879a1990327830493a7047506d58d73fc429b84c1d49d", size = 39358423, upload-time = "2025-10-28T17:38:20.005Z" },
+ { url = "https://files.pythonhosted.org/packages/95/03/28bce0355e4d34a7c034727505a02d19548549e190bedd13a721e35380b7/scipy-1.16.3-cp314-cp314-win_arm64.whl", hash = "sha256:6020470b9d00245926f2d5bb93b119ca0340f0d564eb6fbaad843eaebf9d690f", size = 26135027, upload-time = "2025-10-28T17:38:24.966Z" },
+ { url = "https://files.pythonhosted.org/packages/b2/6f/69f1e2b682efe9de8fe9f91040f0cd32f13cfccba690512ba4c582b0bc29/scipy-1.16.3-cp314-cp314t-macosx_10_14_x86_64.whl", hash = "sha256:e1d27cbcb4602680a49d787d90664fa4974063ac9d4134813332a8c53dbe667c", size = 37028379, upload-time = "2025-10-28T17:37:14.061Z" },
+ { url = "https://files.pythonhosted.org/packages/7c/2d/e826f31624a5ebbab1cd93d30fd74349914753076ed0593e1d56a98c4fb4/scipy-1.16.3-cp314-cp314t-macosx_12_0_arm64.whl", hash = "sha256:9b9c9c07b6d56a35777a1b4cc8966118fb16cfd8daf6743867d17d36cfad2d40", size = 29400052, upload-time = "2025-10-28T17:37:21.709Z" },
+ { url = "https://files.pythonhosted.org/packages/69/27/d24feb80155f41fd1f156bf144e7e049b4e2b9dd06261a242905e3bc7a03/scipy-1.16.3-cp314-cp314t-macosx_14_0_arm64.whl", hash = "sha256:3a4c460301fb2cffb7f88528f30b3127742cff583603aa7dc964a52c463b385d", size = 21391183, upload-time = "2025-10-28T17:37:29.559Z" },
+ { url = "https://files.pythonhosted.org/packages/f8/d3/1b229e433074c5738a24277eca520a2319aac7465eea7310ea6ae0e98ae2/scipy-1.16.3-cp314-cp314t-macosx_14_0_x86_64.whl", hash = "sha256:f667a4542cc8917af1db06366d3f78a5c8e83badd56409f94d1eac8d8d9133fa", size = 23930174, upload-time = "2025-10-28T17:37:36.306Z" },
+ { url = "https://files.pythonhosted.org/packages/16/9d/d9e148b0ec680c0f042581a2be79a28a7ab66c0c4946697f9e7553ead337/scipy-1.16.3-cp314-cp314t-manylinux2014_aarch64.manylinux_2_17_aarch64.whl", hash = "sha256:f379b54b77a597aa7ee5e697df0d66903e41b9c85a6dd7946159e356319158e8", size = 33497852, upload-time = "2025-10-28T17:37:42.228Z" },
+ { url = "https://files.pythonhosted.org/packages/2f/22/4e5f7561e4f98b7bea63cf3fd7934bff1e3182e9f1626b089a679914d5c8/scipy-1.16.3-cp314-cp314t-manylinux2014_x86_64.manylinux_2_17_x86_64.whl", hash = "sha256:4aff59800a3b7f786b70bfd6ab551001cb553244988d7d6b8299cb1ea653b353", size = 35798595, upload-time = "2025-10-28T17:37:48.102Z" },
+ { url = "https://files.pythonhosted.org/packages/83/42/6644d714c179429fc7196857866f219fef25238319b650bb32dde7bf7a48/scipy-1.16.3-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:da7763f55885045036fabcebd80144b757d3db06ab0861415d1c3b7c69042146", size = 36186269, upload-time = "2025-10-28T17:37:53.72Z" },
+ { url = "https://files.pythonhosted.org/packages/ac/70/64b4d7ca92f9cf2e6fc6aaa2eecf80bb9b6b985043a9583f32f8177ea122/scipy-1.16.3-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:ffa6eea95283b2b8079b821dc11f50a17d0571c92b43e2b5b12764dc5f9b285d", size = 38802779, upload-time = "2025-10-28T17:37:59.393Z" },
+ { url = "https://files.pythonhosted.org/packages/61/82/8d0e39f62764cce5ffd5284131e109f07cf8955aef9ab8ed4e3aa5e30539/scipy-1.16.3-cp314-cp314t-win_amd64.whl", hash = "sha256:d9f48cafc7ce94cf9b15c6bffdc443a81a27bf7075cf2dcd5c8b40f85d10c4e7", size = 39471128, upload-time = "2025-10-28T17:38:05.259Z" },
+ { url = "https://files.pythonhosted.org/packages/64/47/a494741db7280eae6dc033510c319e34d42dd41b7ac0c7ead39354d1a2b5/scipy-1.16.3-cp314-cp314t-win_arm64.whl", hash = "sha256:21d9d6b197227a12dcbf9633320a4e34c6b0e51c57268df255a0942983bac562", size = 26464127, upload-time = "2025-10-28T17:38:11.34Z" },
+]
+
+[[package]]
+name = "seaborn"
+version = "0.13.2"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "matplotlib" },
+ { name = "numpy" },
+ { name = "pandas" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/86/59/a451d7420a77ab0b98f7affa3a1d78a313d2f7281a57afb1a34bae8ab412/seaborn-0.13.2.tar.gz", hash = "sha256:93e60a40988f4d65e9f4885df477e2fdaff6b73a9ded434c1ab356dd57eefff7", size = 1457696, upload-time = "2024-01-25T13:21:52.551Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/83/11/00d3c3dfc25ad54e731d91449895a79e4bf2384dc3ac01809010ba88f6d5/seaborn-0.13.2-py3-none-any.whl", hash = "sha256:636f8336facf092165e27924f223d3c62ca560b1f2bb5dff7ab7fad265361987", size = 294914, upload-time = "2024-01-25T13:21:49.598Z" },
+]
+
+[[package]]
+name = "send2trash"
+version = "1.8.3"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/fd/3a/aec9b02217bb79b87bbc1a21bc6abc51e3d5dcf65c30487ac96c0908c722/Send2Trash-1.8.3.tar.gz", hash = "sha256:b18e7a3966d99871aefeb00cfbcfdced55ce4871194810fc71f4aa484b953abf", size = 17394, upload-time = "2024-04-07T00:01:09.267Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/40/b0/4562db6223154aa4e22f939003cb92514c79f3d4dccca3444253fd17f902/Send2Trash-1.8.3-py3-none-any.whl", hash = "sha256:0c31227e0bd08961c7665474a3d1ef7193929fedda4233843689baa056be46c9", size = 18072, upload-time = "2024-04-07T00:01:07.438Z" },
+]
+
+[[package]]
+name = "sentencepiece"
+version = "0.2.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/15/15/2e7a025fc62d764b151ae6d0f2a92f8081755ebe8d4a64099accc6f77ba6/sentencepiece-0.2.1.tar.gz", hash = "sha256:8138cec27c2f2282f4a34d9a016e3374cd40e5c6e9cb335063db66a0a3b71fad", size = 3228515, upload-time = "2025-08-12T07:00:51.718Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/4a/be/32ce495aa1d0e0c323dcb1ba87096037358edee539cac5baf8755a6bd396/sentencepiece-0.2.1-cp312-cp312-macosx_10_13_universal2.whl", hash = "sha256:57cae326c8727de58c85977b175af132a7138d84c764635d7e71bbee7e774133", size = 1943152, upload-time = "2025-08-12T06:59:40.048Z" },
+ { url = "https://files.pythonhosted.org/packages/88/7e/ff23008899a58678e98c6ff592bf4d368eee5a71af96d0df6b38a039dd4f/sentencepiece-0.2.1-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:56dd39a3c4d6493db3cdca7e8cc68c6b633f0d4195495cbadfcf5af8a22d05a6", size = 1325651, upload-time = "2025-08-12T06:59:41.536Z" },
+ { url = "https://files.pythonhosted.org/packages/19/84/42eb3ce4796777a1b5d3699dfd4dca85113e68b637f194a6c8d786f16a04/sentencepiece-0.2.1-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:d9381351182ff9888cc80e41c632e7e274b106f450de33d67a9e8f6043da6f76", size = 1253645, upload-time = "2025-08-12T06:59:42.903Z" },
+ { url = "https://files.pythonhosted.org/packages/89/fa/d3d5ebcba3cb9e6d3775a096251860c41a6bc53a1b9461151df83fe93255/sentencepiece-0.2.1-cp312-cp312-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:99f955df238021bf11f0fc37cdb54fd5e5b5f7fd30ecc3d93fb48b6815437167", size = 1316273, upload-time = "2025-08-12T06:59:44.476Z" },
+ { url = "https://files.pythonhosted.org/packages/04/88/14f2f4a2b922d8b39be45bf63d79e6cd3a9b2f248b2fcb98a69b12af12f5/sentencepiece-0.2.1-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:0cdfecef430d985f1c2bcbfff3defd1d95dae876fbd0173376012d2d7d24044b", size = 1387881, upload-time = "2025-08-12T06:59:46.09Z" },
+ { url = "https://files.pythonhosted.org/packages/fd/b8/903e5ccb77b4ef140605d5d71b4f9e0ad95d456d6184688073ed11712809/sentencepiece-0.2.1-cp312-cp312-win32.whl", hash = "sha256:a483fd29a34c3e34c39ac5556b0a90942bec253d260235729e50976f5dba1068", size = 999540, upload-time = "2025-08-12T06:59:48.023Z" },
+ { url = "https://files.pythonhosted.org/packages/2d/81/92df5673c067148c2545b1bfe49adfd775bcc3a169a047f5a0e6575ddaca/sentencepiece-0.2.1-cp312-cp312-win_amd64.whl", hash = "sha256:4cdc7c36234fda305e85c32949c5211faaf8dd886096c7cea289ddc12a2d02de", size = 1054671, upload-time = "2025-08-12T06:59:49.895Z" },
+ { url = "https://files.pythonhosted.org/packages/fe/02/c5e3bc518655d714622bec87d83db9cdba1cd0619a4a04e2109751c4f47f/sentencepiece-0.2.1-cp312-cp312-win_arm64.whl", hash = "sha256:daeb5e9e9fcad012324807856113708614d534f596d5008638eb9b40112cd9e4", size = 1033923, upload-time = "2025-08-12T06:59:51.952Z" },
+ { url = "https://files.pythonhosted.org/packages/ba/4a/85fbe1706d4d04a7e826b53f327c4b80f849cf1c7b7c5e31a20a97d8f28b/sentencepiece-0.2.1-cp313-cp313-macosx_10_13_universal2.whl", hash = "sha256:dcd8161eee7b41aae57ded06272905dbd680a0a04b91edd0f64790c796b2f706", size = 1943150, upload-time = "2025-08-12T06:59:53.588Z" },
+ { url = "https://files.pythonhosted.org/packages/c2/83/4cfb393e287509fc2155480b9d184706ef8d9fa8cbf5505d02a5792bf220/sentencepiece-0.2.1-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:c6c8f42949f419ff8c7e9960dbadcfbc982d7b5efc2f6748210d3dd53a7de062", size = 1325651, upload-time = "2025-08-12T06:59:55.073Z" },
+ { url = "https://files.pythonhosted.org/packages/8d/de/5a007fb53b1ab0aafc69d11a5a3dd72a289d5a3e78dcf2c3a3d9b14ffe93/sentencepiece-0.2.1-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:097f3394e99456e9e4efba1737c3749d7e23563dd1588ce71a3d007f25475fff", size = 1253641, upload-time = "2025-08-12T06:59:56.562Z" },
+ { url = "https://files.pythonhosted.org/packages/2c/d2/f552be5928105588f4f4d66ee37dd4c61460d8097e62d0e2e0eec41bc61d/sentencepiece-0.2.1-cp313-cp313-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:d7b670879c370d350557edabadbad1f6561a9e6968126e6debca4029e5547820", size = 1316271, upload-time = "2025-08-12T06:59:58.109Z" },
+ { url = "https://files.pythonhosted.org/packages/96/df/0cfe748ace5485be740fed9476dee7877f109da32ed0d280312c94ec259f/sentencepiece-0.2.1-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:c7f0fd2f2693309e6628aeeb2e2faf6edd221134dfccac3308ca0de01f8dab47", size = 1387882, upload-time = "2025-08-12T07:00:00.701Z" },
+ { url = "https://files.pythonhosted.org/packages/ac/dd/f7774d42a881ced8e1739f393ab1e82ece39fc9abd4779e28050c2e975b5/sentencepiece-0.2.1-cp313-cp313-win32.whl", hash = "sha256:92b3816aa2339355fda2c8c4e021a5de92180b00aaccaf5e2808972e77a4b22f", size = 999541, upload-time = "2025-08-12T07:00:02.709Z" },
+ { url = "https://files.pythonhosted.org/packages/dd/e9/932b9eae6fd7019548321eee1ab8d5e3b3d1294df9d9a0c9ac517c7b636d/sentencepiece-0.2.1-cp313-cp313-win_amd64.whl", hash = "sha256:10ed3dab2044c47f7a2e7b4969b0c430420cdd45735d78c8f853191fa0e3148b", size = 1054669, upload-time = "2025-08-12T07:00:04.915Z" },
+ { url = "https://files.pythonhosted.org/packages/c9/3a/76488a00ea7d6931689cda28726a1447d66bf1a4837943489314593d5596/sentencepiece-0.2.1-cp313-cp313-win_arm64.whl", hash = "sha256:ac650534e2251083c5f75dde4ff28896ce7c8904133dc8fef42780f4d5588fcd", size = 1033922, upload-time = "2025-08-12T07:00:06.496Z" },
+ { url = "https://files.pythonhosted.org/packages/4a/b6/08fe2ce819e02ccb0296f4843e3f195764ce9829cbda61b7513f29b95718/sentencepiece-0.2.1-cp313-cp313t-macosx_10_13_universal2.whl", hash = "sha256:8dd4b477a7b069648d19363aad0cab9bad2f4e83b2d179be668efa672500dc94", size = 1946052, upload-time = "2025-08-12T07:00:08.136Z" },
+ { url = "https://files.pythonhosted.org/packages/ab/d9/1ea0e740591ff4c6fc2b6eb1d7510d02f3fb885093f19b2f3abd1363b402/sentencepiece-0.2.1-cp313-cp313t-macosx_10_13_x86_64.whl", hash = "sha256:0c0f672da370cc490e4c59d89e12289778310a0e71d176c541e4834759e1ae07", size = 1327408, upload-time = "2025-08-12T07:00:09.572Z" },
+ { url = "https://files.pythonhosted.org/packages/99/7e/1fb26e8a21613f6200e1ab88824d5d203714162cf2883248b517deb500b7/sentencepiece-0.2.1-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:ad8493bea8432dae8d6830365352350f3b4144415a1d09c4c8cb8d30cf3b6c3c", size = 1254857, upload-time = "2025-08-12T07:00:11.021Z" },
+ { url = "https://files.pythonhosted.org/packages/bc/85/c72fd1f3c7a6010544d6ae07f8ddb38b5e2a7e33bd4318f87266c0bbafbf/sentencepiece-0.2.1-cp313-cp313t-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:b81a24733726e3678d2db63619acc5a8dccd074f7aa7a54ecd5ca33ca6d2d596", size = 1315722, upload-time = "2025-08-12T07:00:12.989Z" },
+ { url = "https://files.pythonhosted.org/packages/4a/e8/661e5bd82a8aa641fd6c1020bd0e890ef73230a2b7215ddf9c8cd8e941c2/sentencepiece-0.2.1-cp313-cp313t-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:0a81799d0a68d618e89063fb423c3001a034c893069135ffe51fee439ae474d6", size = 1387452, upload-time = "2025-08-12T07:00:15.088Z" },
+ { url = "https://files.pythonhosted.org/packages/99/5e/ae66c361023a470afcbc1fbb8da722c72ea678a2fcd9a18f1a12598c7501/sentencepiece-0.2.1-cp313-cp313t-win32.whl", hash = "sha256:89a3ea015517c42c0341d0d962f3e6aaf2cf10d71b1932d475c44ba48d00aa2b", size = 1002501, upload-time = "2025-08-12T07:00:16.966Z" },
+ { url = "https://files.pythonhosted.org/packages/c1/03/d332828c4ff764e16c1b56c2c8f9a33488bbe796b53fb6b9c4205ddbf167/sentencepiece-0.2.1-cp313-cp313t-win_amd64.whl", hash = "sha256:33f068c9382dc2e7c228eedfd8163b52baa86bb92f50d0488bf2b7da7032e484", size = 1057555, upload-time = "2025-08-12T07:00:18.573Z" },
+ { url = "https://files.pythonhosted.org/packages/88/14/5aee0bf0864df9bd82bd59e7711362908e4935e3f9cdc1f57246b5d5c9b9/sentencepiece-0.2.1-cp313-cp313t-win_arm64.whl", hash = "sha256:b3616ad246f360e52c85781e47682d31abfb6554c779e42b65333d4b5f44ecc0", size = 1036042, upload-time = "2025-08-12T07:00:20.209Z" },
+ { url = "https://files.pythonhosted.org/packages/24/9c/89eb8b2052f720a612478baf11c8227dcf1dc28cd4ea4c0c19506b5af2a2/sentencepiece-0.2.1-cp314-cp314-macosx_10_13_universal2.whl", hash = "sha256:5d0350b686c320068702116276cfb26c066dc7e65cfef173980b11bb4d606719", size = 1943147, upload-time = "2025-08-12T07:00:21.809Z" },
+ { url = "https://files.pythonhosted.org/packages/82/0b/a1432bc87f97c2ace36386ca23e8bd3b91fb40581b5e6148d24b24186419/sentencepiece-0.2.1-cp314-cp314-macosx_10_13_x86_64.whl", hash = "sha256:c7f54a31cde6fa5cb030370566f68152a742f433f8d2be458463d06c208aef33", size = 1325624, upload-time = "2025-08-12T07:00:23.289Z" },
+ { url = "https://files.pythonhosted.org/packages/ea/99/bbe054ebb5a5039457c590e0a4156ed073fb0fe9ce4f7523404dd5b37463/sentencepiece-0.2.1-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:c83b85ab2d6576607f31df77ff86f28182be4a8de6d175d2c33ca609925f5da1", size = 1253670, upload-time = "2025-08-12T07:00:24.69Z" },
+ { url = "https://files.pythonhosted.org/packages/19/ad/d5c7075f701bd97971d7c2ac2904f227566f51ef0838dfbdfdccb58cd212/sentencepiece-0.2.1-cp314-cp314-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:1855f57db07b51fb51ed6c9c452f570624d2b169b36f0f79ef71a6e6c618cd8b", size = 1316247, upload-time = "2025-08-12T07:00:26.435Z" },
+ { url = "https://files.pythonhosted.org/packages/fb/03/35fbe5f3d9a7435eebd0b473e09584bd3cc354ce118b960445b060d33781/sentencepiece-0.2.1-cp314-cp314-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:01e6912125cb45d3792f530a4d38f8e21bf884d6b4d4ade1b2de5cf7a8d2a52b", size = 1387894, upload-time = "2025-08-12T07:00:28.339Z" },
+ { url = "https://files.pythonhosted.org/packages/dc/aa/956ef729aafb6c8f9c443104c9636489093bb5c61d6b90fc27aa1a865574/sentencepiece-0.2.1-cp314-cp314-win32.whl", hash = "sha256:c415c9de1447e0a74ae3fdb2e52f967cb544113a3a5ce3a194df185cbc1f962f", size = 1096698, upload-time = "2025-08-12T07:00:29.764Z" },
+ { url = "https://files.pythonhosted.org/packages/b8/cb/fe400d8836952cc535c81a0ce47dc6875160e5fedb71d2d9ff0e9894c2a6/sentencepiece-0.2.1-cp314-cp314-win_amd64.whl", hash = "sha256:881b2e44b14fc19feade3cbed314be37de639fc415375cefaa5bc81a4be137fd", size = 1155115, upload-time = "2025-08-12T07:00:32.865Z" },
+ { url = "https://files.pythonhosted.org/packages/32/89/047921cf70f36c7b6b6390876b2399b3633ab73b8d0cb857e5a964238941/sentencepiece-0.2.1-cp314-cp314-win_arm64.whl", hash = "sha256:2005242a16d2dc3ac5fe18aa7667549134d37854823df4c4db244752453b78a8", size = 1133890, upload-time = "2025-08-12T07:00:34.763Z" },
+ { url = "https://files.pythonhosted.org/packages/a1/11/5b414b9fae6255b5fb1e22e2ed3dc3a72d3a694e5703910e640ac78346bb/sentencepiece-0.2.1-cp314-cp314t-macosx_10_13_universal2.whl", hash = "sha256:a19adcec27c524cb7069a1c741060add95f942d1cbf7ad0d104dffa0a7d28a2b", size = 1946081, upload-time = "2025-08-12T07:00:36.97Z" },
+ { url = "https://files.pythonhosted.org/packages/77/eb/7a5682bb25824db8545f8e5662e7f3e32d72a508fdce086029d89695106b/sentencepiece-0.2.1-cp314-cp314t-macosx_10_13_x86_64.whl", hash = "sha256:e37e4b4c4a11662b5db521def4e44d4d30ae69a1743241412a93ae40fdcab4bb", size = 1327406, upload-time = "2025-08-12T07:00:38.669Z" },
+ { url = "https://files.pythonhosted.org/packages/03/b0/811dae8fb9f2784e138785d481469788f2e0d0c109c5737372454415f55f/sentencepiece-0.2.1-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:477c81505db072b3ab627e7eab972ea1025331bd3a92bacbf798df2b75ea86ec", size = 1254846, upload-time = "2025-08-12T07:00:40.611Z" },
+ { url = "https://files.pythonhosted.org/packages/ef/23/195b2e7ec85ebb6a547969f60b723c7aca5a75800ece6cc3f41da872d14e/sentencepiece-0.2.1-cp314-cp314t-manylinux_2_27_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:010f025a544ef770bb395091d57cb94deb9652d8972e0d09f71d85d5a0816c8c", size = 1315721, upload-time = "2025-08-12T07:00:42.914Z" },
+ { url = "https://files.pythonhosted.org/packages/7e/aa/553dbe4178b5f23eb28e59393dddd64186178b56b81d9b8d5c3ff1c28395/sentencepiece-0.2.1-cp314-cp314t-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:733e59ff1794d26db706cd41fc2d7ca5f6c64a820709cb801dc0ea31780d64ab", size = 1387458, upload-time = "2025-08-12T07:00:44.56Z" },
+ { url = "https://files.pythonhosted.org/packages/66/7c/08ff0012507297a4dd74a5420fdc0eb9e3e80f4e88cab1538d7f28db303d/sentencepiece-0.2.1-cp314-cp314t-win32.whl", hash = "sha256:d3233770f78e637dc8b1fda2cd7c3b99ec77e7505041934188a4e7fe751de3b0", size = 1099765, upload-time = "2025-08-12T07:00:46.058Z" },
+ { url = "https://files.pythonhosted.org/packages/91/d5/2a69e1ce15881beb9ddfc7e3f998322f5cedcd5e4d244cb74dade9441663/sentencepiece-0.2.1-cp314-cp314t-win_amd64.whl", hash = "sha256:5e4366c97b68218fd30ea72d70c525e6e78a6c0a88650f57ac4c43c63b234a9d", size = 1157807, upload-time = "2025-08-12T07:00:47.673Z" },
+ { url = "https://files.pythonhosted.org/packages/f3/16/54f611fcfc2d1c46cbe3ec4169780b2cfa7cf63708ef2b71611136db7513/sentencepiece-0.2.1-cp314-cp314t-win_arm64.whl", hash = "sha256:105e36e75cbac1292642045458e8da677b2342dcd33df503e640f0b457cb6751", size = 1136264, upload-time = "2025-08-12T07:00:49.485Z" },
+]
+
+[[package]]
+name = "sentry-sdk"
+version = "2.47.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "certifi" },
+ { name = "urllib3" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/4a/2a/d225cbf87b6c8ecce5664db7bcecb82c317e448e3b24a2dcdaacb18ca9a7/sentry_sdk-2.47.0.tar.gz", hash = "sha256:8218891d5e41b4ea8d61d2aed62ed10c80e39d9f2959d6f939efbf056857e050", size = 381895, upload-time = "2025-12-03T14:06:36.846Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/bd/ac/d6286ea0d49e7b58847faf67b00e56bb4ba3d525281e2ac306e1f1f353da/sentry_sdk-2.47.0-py2.py3-none-any.whl", hash = "sha256:d72f8c61025b7d1d9e52510d03a6247b280094a327dd900d987717a4fce93412", size = 411088, upload-time = "2025-12-03T14:06:35.374Z" },
+]
+
+[[package]]
+name = "setuptools"
+version = "80.9.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/18/5d/3bf57dcd21979b887f014ea83c24ae194cfcd12b9e0fda66b957c69d1fca/setuptools-80.9.0.tar.gz", hash = "sha256:f36b47402ecde768dbfafc46e8e4207b4360c654f1f3bb84475f0a28628fb19c", size = 1319958, upload-time = "2025-05-27T00:56:51.443Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/a3/dc/17031897dae0efacfea57dfd3a82fdd2a2aeb58e0ff71b77b87e44edc772/setuptools-80.9.0-py3-none-any.whl", hash = "sha256:062d34222ad13e0cc312a4c02d73f059e86a4acbfbdea8f8f76b28c99f306922", size = 1201486, upload-time = "2025-05-27T00:56:49.664Z" },
+]
+
+[[package]]
+name = "six"
+version = "1.17.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/94/e7/b2c673351809dca68a0e064b6af791aa332cf192da575fd474ed7d6f16a2/six-1.17.0.tar.gz", hash = "sha256:ff70335d468e7eb6ec65b95b99d3a2836546063f63acc5171de367e834932a81", size = 34031, upload-time = "2024-12-04T17:35:28.174Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/b7/ce/149a00dd41f10bc29e5921b496af8b574d8413afcd5e30dfa0ed46c2cc5e/six-1.17.0-py2.py3-none-any.whl", hash = "sha256:4721f391ed90541fddacab5acf947aa0d3dc7d27b2e1e8eda2be8970586c3274", size = 11050, upload-time = "2024-12-04T17:35:26.475Z" },
+]
+
+[[package]]
+name = "smmap"
+version = "5.0.2"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/44/cd/a040c4b3119bbe532e5b0732286f805445375489fceaec1f48306068ee3b/smmap-5.0.2.tar.gz", hash = "sha256:26ea65a03958fa0c8a1c7e8c7a58fdc77221b8910f6be2131affade476898ad5", size = 22329, upload-time = "2025-01-02T07:14:40.909Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/04/be/d09147ad1ec7934636ad912901c5fd7667e1c858e19d355237db0d0cd5e4/smmap-5.0.2-py3-none-any.whl", hash = "sha256:b30115f0def7d7531d22a0fb6502488d879e75b260a9db4d0819cfb25403af5e", size = 24303, upload-time = "2025-01-02T07:14:38.724Z" },
+]
+
+[[package]]
+name = "sniffio"
+version = "1.3.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/a2/87/a6771e1546d97e7e041b6ae58d80074f81b7d5121207425c964ddf5cfdbd/sniffio-1.3.1.tar.gz", hash = "sha256:f4324edc670a0f49750a81b895f35c3adb843cca46f0530f79fc1babb23789dc", size = 20372, upload-time = "2024-02-25T23:20:04.057Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/e9/44/75a9c9421471a6c4805dbf2356f7c181a29c1879239abab1ea2cc8f38b40/sniffio-1.3.1-py3-none-any.whl", hash = "sha256:2f6da418d1f1e0fddd844478f41680e794e6051915791a034ff65e5f100525a2", size = 10235, upload-time = "2024-02-25T23:20:01.196Z" },
+]
+
+[[package]]
+name = "soundfile"
+version = "0.13.1"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "cffi" },
+ { name = "numpy" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/e1/41/9b873a8c055582859b239be17902a85339bec6a30ad162f98c9b0288a2cc/soundfile-0.13.1.tar.gz", hash = "sha256:b2c68dab1e30297317080a5b43df57e302584c49e2942defdde0acccc53f0e5b", size = 46156, upload-time = "2025-01-25T09:17:04.831Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/64/28/e2a36573ccbcf3d57c00626a21fe51989380636e821b341d36ccca0c1c3a/soundfile-0.13.1-py2.py3-none-any.whl", hash = "sha256:a23c717560da2cf4c7b5ae1142514e0fd82d6bbd9dfc93a50423447142f2c445", size = 25751, upload-time = "2025-01-25T09:16:44.235Z" },
+ { url = "https://files.pythonhosted.org/packages/ea/ab/73e97a5b3cc46bba7ff8650a1504348fa1863a6f9d57d7001c6b67c5f20e/soundfile-0.13.1-py2.py3-none-macosx_10_9_x86_64.whl", hash = "sha256:82dc664d19831933fe59adad199bf3945ad06d84bc111a5b4c0d3089a5b9ec33", size = 1142250, upload-time = "2025-01-25T09:16:47.583Z" },
+ { url = "https://files.pythonhosted.org/packages/a0/e5/58fd1a8d7b26fc113af244f966ee3aecf03cb9293cb935daaddc1e455e18/soundfile-0.13.1-py2.py3-none-macosx_11_0_arm64.whl", hash = "sha256:743f12c12c4054921e15736c6be09ac26b3b3d603aef6fd69f9dde68748f2593", size = 1101406, upload-time = "2025-01-25T09:16:49.662Z" },
+ { url = "https://files.pythonhosted.org/packages/58/ae/c0e4a53d77cf6e9a04179535766b3321b0b9ced5f70522e4caf9329f0046/soundfile-0.13.1-py2.py3-none-manylinux_2_28_aarch64.whl", hash = "sha256:9c9e855f5a4d06ce4213f31918653ab7de0c5a8d8107cd2427e44b42df547deb", size = 1235729, upload-time = "2025-01-25T09:16:53.018Z" },
+ { url = "https://files.pythonhosted.org/packages/57/5e/70bdd9579b35003a489fc850b5047beeda26328053ebadc1fb60f320f7db/soundfile-0.13.1-py2.py3-none-manylinux_2_28_x86_64.whl", hash = "sha256:03267c4e493315294834a0870f31dbb3b28a95561b80b134f0bd3cf2d5f0e618", size = 1313646, upload-time = "2025-01-25T09:16:54.872Z" },
+ { url = "https://files.pythonhosted.org/packages/fe/df/8c11dc4dfceda14e3003bb81a0d0edcaaf0796dd7b4f826ea3e532146bba/soundfile-0.13.1-py2.py3-none-win32.whl", hash = "sha256:c734564fab7c5ddf8e9be5bf70bab68042cd17e9c214c06e365e20d64f9a69d5", size = 899881, upload-time = "2025-01-25T09:16:56.663Z" },
+ { url = "https://files.pythonhosted.org/packages/14/e9/6b761de83277f2f02ded7e7ea6f07828ec78e4b229b80e4ca55dd205b9dc/soundfile-0.13.1-py2.py3-none-win_amd64.whl", hash = "sha256:1e70a05a0626524a69e9f0f4dd2ec174b4e9567f4d8b6c11d38b5c289be36ee9", size = 1019162, upload-time = "2025-01-25T09:16:59.573Z" },
+]
+
+[[package]]
+name = "soupsieve"
+version = "2.8"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/6d/e6/21ccce3262dd4889aa3332e5a119a3491a95e8f60939870a3a035aabac0d/soupsieve-2.8.tar.gz", hash = "sha256:e2dd4a40a628cb5f28f6d4b0db8800b8f581b65bb380b97de22ba5ca8d72572f", size = 103472, upload-time = "2025-08-27T15:39:51.78Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/14/a0/bb38d3b76b8cae341dad93a2dd83ab7462e6dbcdd84d43f54ee60a8dc167/soupsieve-2.8-py3-none-any.whl", hash = "sha256:0cc76456a30e20f5d7f2e14a98a4ae2ee4e5abdc7c5ea0aafe795f344bc7984c", size = 36679, upload-time = "2025-08-27T15:39:50.179Z" },
+]
+
+[[package]]
+name = "stack-data"
+version = "0.6.3"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "asttokens" },
+ { name = "executing" },
+ { name = "pure-eval" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/28/e3/55dcc2cfbc3ca9c29519eb6884dd1415ecb53b0e934862d3559ddcb7e20b/stack_data-0.6.3.tar.gz", hash = "sha256:836a778de4fec4dcd1dcd89ed8abff8a221f58308462e1c4aa2a3cf30148f0b9", size = 44707, upload-time = "2023-09-30T13:58:05.479Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/f1/7b/ce1eafaf1a76852e2ec9b22edecf1daa58175c090266e9f6c64afcd81d91/stack_data-0.6.3-py3-none-any.whl", hash = "sha256:d5558e0c25a4cb0853cddad3d77da9891a08cb85dd9f9f91b9f8cd66e511e695", size = 24521, upload-time = "2023-09-30T13:58:03.53Z" },
+]
+
+[[package]]
+name = "sympy"
+version = "1.14.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "mpmath" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/83/d3/803453b36afefb7c2bb238361cd4ae6125a569b4db67cd9e79846ba2d68c/sympy-1.14.0.tar.gz", hash = "sha256:d3d3fe8df1e5a0b42f0e7bdf50541697dbe7d23746e894990c030e2b05e72517", size = 7793921, upload-time = "2025-04-27T18:05:01.611Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/a2/09/77d55d46fd61b4a135c444fc97158ef34a095e5681d0a6c10b75bf356191/sympy-1.14.0-py3-none-any.whl", hash = "sha256:e091cc3e99d2141a0ba2847328f5479b05d94a6635cb96148ccb3f34671bd8f5", size = 6299353, upload-time = "2025-04-27T18:04:59.103Z" },
+]
+
+[[package]]
+name = "terminado"
+version = "0.18.1"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "ptyprocess", marker = "os_name != 'nt'" },
+ { name = "pywinpty", marker = "os_name == 'nt' and sys_platform != 'linux'" },
+ { name = "tornado" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/8a/11/965c6fd8e5cc254f1fe142d547387da17a8ebfd75a3455f637c663fb38a0/terminado-0.18.1.tar.gz", hash = "sha256:de09f2c4b85de4765f7714688fff57d3e75bad1f909b589fde880460c753fd2e", size = 32701, upload-time = "2024-03-12T14:34:39.026Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/6a/9e/2064975477fdc887e47ad42157e214526dcad8f317a948dee17e1659a62f/terminado-0.18.1-py3-none-any.whl", hash = "sha256:a4468e1b37bb318f8a86514f65814e1afc977cf29b3992a4500d9dd305dcceb0", size = 14154, upload-time = "2024-03-12T14:34:36.569Z" },
+]
+
+[[package]]
+name = "threadpoolctl"
+version = "3.6.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/b7/4d/08c89e34946fce2aec4fbb45c9016efd5f4d7f24af8e5d93296e935631d8/threadpoolctl-3.6.0.tar.gz", hash = "sha256:8ab8b4aa3491d812b623328249fab5302a68d2d71745c8a4c719a2fcaba9f44e", size = 21274, upload-time = "2025-03-13T13:49:23.031Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/32/d5/f9a850d79b0851d1d4ef6456097579a9005b31fea68726a4ae5f2d82ddd9/threadpoolctl-3.6.0-py3-none-any.whl", hash = "sha256:43a0b8fd5a2928500110039e43a5eed8480b918967083ea48dc3ab9f13c4a7fb", size = 18638, upload-time = "2025-03-13T13:49:21.846Z" },
+]
+
+[[package]]
+name = "timm"
+version = "1.0.22"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "huggingface-hub" },
+ { name = "pyyaml" },
+ { name = "safetensors" },
+ { name = "torch" },
+ { name = "torchvision" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/c5/9d/e4670765d1c033f97096c760b3b907eeb659cf80f3678640e5f060b04c6c/timm-1.0.22.tar.gz", hash = "sha256:14fd74bcc17db3856b1a47d26fb305576c98579ab9d02b36714a5e6b25cde422", size = 2382998, upload-time = "2025-11-05T04:06:09.377Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/d6/14/fc04d491527b774ec7479897f5861959209de1480e4c4cd32ed098ff8bea/timm-1.0.22-py3-none-any.whl", hash = "sha256:888981753e65cbaacfc07494370138b1700a27b1f0af587f4f9b47bc024161d0", size = 2530238, upload-time = "2025-11-05T04:06:06.823Z" },
+]
+
+[[package]]
+name = "tinycss2"
+version = "1.4.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "webencodings" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/7a/fd/7a5ee21fd08ff70d3d33a5781c255cbe779659bd03278feb98b19ee550f4/tinycss2-1.4.0.tar.gz", hash = "sha256:10c0972f6fc0fbee87c3edb76549357415e94548c1ae10ebccdea16fb404a9b7", size = 87085, upload-time = "2024-10-24T14:58:29.895Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/e6/34/ebdc18bae6aa14fbee1a08b63c015c72b64868ff7dae68808ab500c492e2/tinycss2-1.4.0-py3-none-any.whl", hash = "sha256:3a49cf47b7675da0b15d0c6e1df8df4ebd96e9394bb905a5775adb0d884c5289", size = 26610, upload-time = "2024-10-24T14:58:28.029Z" },
+]
+
+[[package]]
+name = "tokenizers"
+version = "0.22.1"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "huggingface-hub" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/1c/46/fb6854cec3278fbfa4a75b50232c77622bc517ac886156e6afbfa4d8fc6e/tokenizers-0.22.1.tar.gz", hash = "sha256:61de6522785310a309b3407bac22d99c4db5dba349935e99e4d15ea2226af2d9", size = 363123, upload-time = "2025-09-19T09:49:23.424Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/bf/33/f4b2d94ada7ab297328fc671fed209368ddb82f965ec2224eb1892674c3a/tokenizers-0.22.1-cp39-abi3-macosx_10_12_x86_64.whl", hash = "sha256:59fdb013df17455e5f950b4b834a7b3ee2e0271e6378ccb33aa74d178b513c73", size = 3069318, upload-time = "2025-09-19T09:49:11.848Z" },
+ { url = "https://files.pythonhosted.org/packages/1c/58/2aa8c874d02b974990e89ff95826a4852a8b2a273c7d1b4411cdd45a4565/tokenizers-0.22.1-cp39-abi3-macosx_11_0_arm64.whl", hash = "sha256:8d4e484f7b0827021ac5f9f71d4794aaef62b979ab7608593da22b1d2e3c4edc", size = 2926478, upload-time = "2025-09-19T09:49:09.759Z" },
+ { url = "https://files.pythonhosted.org/packages/1e/3b/55e64befa1e7bfea963cf4b787b2cea1011362c4193f5477047532ce127e/tokenizers-0.22.1-cp39-abi3-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:19d2962dd28bc67c1f205ab180578a78eef89ac60ca7ef7cbe9635a46a56422a", size = 3256994, upload-time = "2025-09-19T09:48:56.701Z" },
+ { url = "https://files.pythonhosted.org/packages/71/0b/fbfecf42f67d9b7b80fde4aabb2b3110a97fac6585c9470b5bff103a80cb/tokenizers-0.22.1-cp39-abi3-manylinux_2_17_armv7l.manylinux2014_armv7l.whl", hash = "sha256:38201f15cdb1f8a6843e6563e6e79f4abd053394992b9bbdf5213ea3469b4ae7", size = 3153141, upload-time = "2025-09-19T09:48:59.749Z" },
+ { url = "https://files.pythonhosted.org/packages/17/a9/b38f4e74e0817af8f8ef925507c63c6ae8171e3c4cb2d5d4624bf58fca69/tokenizers-0.22.1-cp39-abi3-manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:d1cbe5454c9a15df1b3443c726063d930c16f047a3cc724b9e6e1a91140e5a21", size = 3508049, upload-time = "2025-09-19T09:49:05.868Z" },
+ { url = "https://files.pythonhosted.org/packages/d2/48/dd2b3dac46bb9134a88e35d72e1aa4869579eacc1a27238f1577270773ff/tokenizers-0.22.1-cp39-abi3-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:e7d094ae6312d69cc2a872b54b91b309f4f6fbce871ef28eb27b52a98e4d0214", size = 3710730, upload-time = "2025-09-19T09:49:01.832Z" },
+ { url = "https://files.pythonhosted.org/packages/93/0e/ccabc8d16ae4ba84a55d41345207c1e2ea88784651a5a487547d80851398/tokenizers-0.22.1-cp39-abi3-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:afd7594a56656ace95cdd6df4cca2e4059d294c5cfb1679c57824b605556cb2f", size = 3412560, upload-time = "2025-09-19T09:49:03.867Z" },
+ { url = "https://files.pythonhosted.org/packages/d0/c6/dc3a0db5a6766416c32c034286d7c2d406da1f498e4de04ab1b8959edd00/tokenizers-0.22.1-cp39-abi3-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:e2ef6063d7a84994129732b47e7915e8710f27f99f3a3260b8a38fc7ccd083f4", size = 3250221, upload-time = "2025-09-19T09:49:07.664Z" },
+ { url = "https://files.pythonhosted.org/packages/d7/a6/2c8486eef79671601ff57b093889a345dd3d576713ef047776015dc66de7/tokenizers-0.22.1-cp39-abi3-musllinux_1_2_aarch64.whl", hash = "sha256:ba0a64f450b9ef412c98f6bcd2a50c6df6e2443b560024a09fa6a03189726879", size = 9345569, upload-time = "2025-09-19T09:49:14.214Z" },
+ { url = "https://files.pythonhosted.org/packages/6b/16/32ce667f14c35537f5f605fe9bea3e415ea1b0a646389d2295ec348d5657/tokenizers-0.22.1-cp39-abi3-musllinux_1_2_armv7l.whl", hash = "sha256:331d6d149fa9c7d632cde4490fb8bbb12337fa3a0232e77892be656464f4b446", size = 9271599, upload-time = "2025-09-19T09:49:16.639Z" },
+ { url = "https://files.pythonhosted.org/packages/51/7c/a5f7898a3f6baa3fc2685c705e04c98c1094c523051c805cdd9306b8f87e/tokenizers-0.22.1-cp39-abi3-musllinux_1_2_i686.whl", hash = "sha256:607989f2ea68a46cb1dfbaf3e3aabdf3f21d8748312dbeb6263d1b3b66c5010a", size = 9533862, upload-time = "2025-09-19T09:49:19.146Z" },
+ { url = "https://files.pythonhosted.org/packages/36/65/7e75caea90bc73c1dd8d40438adf1a7bc26af3b8d0a6705ea190462506e1/tokenizers-0.22.1-cp39-abi3-musllinux_1_2_x86_64.whl", hash = "sha256:a0f307d490295717726598ef6fa4f24af9d484809223bbc253b201c740a06390", size = 9681250, upload-time = "2025-09-19T09:49:21.501Z" },
+ { url = "https://files.pythonhosted.org/packages/30/2c/959dddef581b46e6209da82df3b78471e96260e2bc463f89d23b1bf0e52a/tokenizers-0.22.1-cp39-abi3-win32.whl", hash = "sha256:b5120eed1442765cd90b903bb6cfef781fd8fe64e34ccaecbae4c619b7b12a82", size = 2472003, upload-time = "2025-09-19T09:49:27.089Z" },
+ { url = "https://files.pythonhosted.org/packages/b3/46/e33a8c93907b631a99377ef4c5f817ab453d0b34f93529421f42ff559671/tokenizers-0.22.1-cp39-abi3-win_amd64.whl", hash = "sha256:65fd6e3fb11ca1e78a6a93602490f134d1fdeb13bcef99389d5102ea318ed138", size = 2674684, upload-time = "2025-09-19T09:49:24.953Z" },
+]
+
+[[package]]
+name = "tomlkit"
+version = "0.13.3"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/cc/18/0bbf3884e9eaa38819ebe46a7bd25dcd56b67434402b66a58c4b8e552575/tomlkit-0.13.3.tar.gz", hash = "sha256:430cf247ee57df2b94ee3fbe588e71d362a941ebb545dec29b53961d61add2a1", size = 185207, upload-time = "2025-06-05T07:13:44.947Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/bd/75/8539d011f6be8e29f339c42e633aae3cb73bffa95dd0f9adec09b9c58e85/tomlkit-0.13.3-py3-none-any.whl", hash = "sha256:c89c649d79ee40629a9fda55f8ace8c6a1b42deb912b2a8fd8d942ddadb606b0", size = 38901, upload-time = "2025-06-05T07:13:43.546Z" },
+]
+
+[[package]]
+name = "torch"
+version = "2.9.1"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "filelock" },
+ { name = "fsspec" },
+ { name = "jinja2" },
+ { name = "networkx" },
+ { name = "nvidia-cublas-cu12", marker = "platform_machine == 'x86_64' and sys_platform == 'linux'" },
+ { name = "nvidia-cuda-cupti-cu12", marker = "platform_machine == 'x86_64' and sys_platform == 'linux'" },
+ { name = "nvidia-cuda-nvrtc-cu12", marker = "platform_machine == 'x86_64' and sys_platform == 'linux'" },
+ { name = "nvidia-cuda-runtime-cu12", marker = "platform_machine == 'x86_64' and sys_platform == 'linux'" },
+ { name = "nvidia-cudnn-cu12", marker = "platform_machine == 'x86_64' and sys_platform == 'linux'" },
+ { name = "nvidia-cufft-cu12", marker = "platform_machine == 'x86_64' and sys_platform == 'linux'" },
+ { name = "nvidia-cufile-cu12", marker = "platform_machine == 'x86_64' and sys_platform == 'linux'" },
+ { name = "nvidia-curand-cu12", marker = "platform_machine == 'x86_64' and sys_platform == 'linux'" },
+ { name = "nvidia-cusolver-cu12", marker = "platform_machine == 'x86_64' and sys_platform == 'linux'" },
+ { name = "nvidia-cusparse-cu12", marker = "platform_machine == 'x86_64' and sys_platform == 'linux'" },
+ { name = "nvidia-cusparselt-cu12", marker = "platform_machine == 'x86_64' and sys_platform == 'linux'" },
+ { name = "nvidia-nccl-cu12", marker = "platform_machine == 'x86_64' and sys_platform == 'linux'" },
+ { name = "nvidia-nvjitlink-cu12", marker = "platform_machine == 'x86_64' and sys_platform == 'linux'" },
+ { name = "nvidia-nvshmem-cu12", marker = "platform_machine == 'x86_64' and sys_platform == 'linux'" },
+ { name = "nvidia-nvtx-cu12", marker = "platform_machine == 'x86_64' and sys_platform == 'linux'" },
+ { name = "setuptools" },
+ { name = "sympy" },
+ { name = "triton", marker = "platform_machine == 'x86_64' and sys_platform == 'linux'" },
+ { name = "typing-extensions" },
+]
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/0f/27/07c645c7673e73e53ded71705045d6cb5bae94c4b021b03aa8d03eee90ab/torch-2.9.1-cp312-cp312-manylinux_2_28_aarch64.whl", hash = "sha256:da5f6f4d7f4940a173e5572791af238cb0b9e21b1aab592bd8b26da4c99f1cd6", size = 104126592, upload-time = "2025-11-12T15:20:41.62Z" },
+ { url = "https://files.pythonhosted.org/packages/19/17/e377a460603132b00760511299fceba4102bd95db1a0ee788da21298ccff/torch-2.9.1-cp312-cp312-manylinux_2_28_x86_64.whl", hash = "sha256:27331cd902fb4322252657f3902adf1c4f6acad9dcad81d8df3ae14c7c4f07c4", size = 899742281, upload-time = "2025-11-12T15:22:17.602Z" },
+ { url = "https://files.pythonhosted.org/packages/b1/1a/64f5769025db846a82567fa5b7d21dba4558a7234ee631712ee4771c436c/torch-2.9.1-cp312-cp312-win_amd64.whl", hash = "sha256:81a285002d7b8cfd3fdf1b98aa8df138d41f1a8334fd9ea37511517cedf43083", size = 110940568, upload-time = "2025-11-12T15:21:18.689Z" },
+ { url = "https://files.pythonhosted.org/packages/6e/ab/07739fd776618e5882661d04c43f5b5586323e2f6a2d7d84aac20d8f20bd/torch-2.9.1-cp312-none-macosx_11_0_arm64.whl", hash = "sha256:c0d25d1d8e531b8343bea0ed811d5d528958f1dcbd37e7245bc686273177ad7e", size = 74479191, upload-time = "2025-11-12T15:21:25.816Z" },
+ { url = "https://files.pythonhosted.org/packages/20/60/8fc5e828d050bddfab469b3fe78e5ab9a7e53dda9c3bdc6a43d17ce99e63/torch-2.9.1-cp313-cp313-manylinux_2_28_aarch64.whl", hash = "sha256:c29455d2b910b98738131990394da3e50eea8291dfeb4b12de71ecf1fdeb21cb", size = 104135743, upload-time = "2025-11-12T15:21:34.936Z" },
+ { url = "https://files.pythonhosted.org/packages/f2/b7/6d3f80e6918213babddb2a37b46dbb14c15b14c5f473e347869a51f40e1f/torch-2.9.1-cp313-cp313-manylinux_2_28_x86_64.whl", hash = "sha256:524de44cd13931208ba2c4bde9ec7741fd4ae6bfd06409a604fc32f6520c2bc9", size = 899749493, upload-time = "2025-11-12T15:24:36.356Z" },
+ { url = "https://files.pythonhosted.org/packages/a6/47/c7843d69d6de8938c1cbb1eba426b1d48ddf375f101473d3e31a5fc52b74/torch-2.9.1-cp313-cp313-win_amd64.whl", hash = "sha256:545844cc16b3f91e08ce3b40e9c2d77012dd33a48d505aed34b7740ed627a1b2", size = 110944162, upload-time = "2025-11-12T15:21:53.151Z" },
+ { url = "https://files.pythonhosted.org/packages/28/0e/2a37247957e72c12151b33a01e4df651d9d155dd74d8cfcbfad15a79b44a/torch-2.9.1-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:5be4bf7496f1e3ffb1dd44b672adb1ac3f081f204c5ca81eba6442f5f634df8e", size = 74830751, upload-time = "2025-11-12T15:21:43.792Z" },
+ { url = "https://files.pythonhosted.org/packages/4b/f7/7a18745edcd7b9ca2381aa03353647bca8aace91683c4975f19ac233809d/torch-2.9.1-cp313-cp313t-manylinux_2_28_aarch64.whl", hash = "sha256:30a3e170a84894f3652434b56d59a64a2c11366b0ed5776fab33c2439396bf9a", size = 104142929, upload-time = "2025-11-12T15:21:48.319Z" },
+ { url = "https://files.pythonhosted.org/packages/f4/dd/f1c0d879f2863ef209e18823a988dc7a1bf40470750e3ebe927efdb9407f/torch-2.9.1-cp313-cp313t-manylinux_2_28_x86_64.whl", hash = "sha256:8301a7b431e51764629208d0edaa4f9e4c33e6df0f2f90b90e261d623df6a4e2", size = 899748978, upload-time = "2025-11-12T15:23:04.568Z" },
+ { url = "https://files.pythonhosted.org/packages/1f/9f/6986b83a53b4d043e36f3f898b798ab51f7f20fdf1a9b01a2720f445043d/torch-2.9.1-cp313-cp313t-win_amd64.whl", hash = "sha256:2e1c42c0ae92bf803a4b2409fdfed85e30f9027a66887f5e7dcdbc014c7531db", size = 111176995, upload-time = "2025-11-12T15:22:01.618Z" },
+ { url = "https://files.pythonhosted.org/packages/40/60/71c698b466dd01e65d0e9514b5405faae200c52a76901baf6906856f17e4/torch-2.9.1-cp313-none-macosx_11_0_arm64.whl", hash = "sha256:2c14b3da5df416cf9cb5efab83aa3056f5b8cd8620b8fde81b4987ecab730587", size = 74480347, upload-time = "2025-11-12T15:21:57.648Z" },
+ { url = "https://files.pythonhosted.org/packages/48/50/c4b5112546d0d13cc9eaa1c732b823d676a9f49ae8b6f97772f795874a03/torch-2.9.1-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:1edee27a7c9897f4e0b7c14cfc2f3008c571921134522d5b9b5ec4ebbc69041a", size = 74433245, upload-time = "2025-11-12T15:22:39.027Z" },
+ { url = "https://files.pythonhosted.org/packages/81/c9/2628f408f0518b3bae49c95f5af3728b6ab498c8624ab1e03a43dd53d650/torch-2.9.1-cp314-cp314-manylinux_2_28_aarch64.whl", hash = "sha256:19d144d6b3e29921f1fc70503e9f2fc572cde6a5115c0c0de2f7ca8b1483e8b6", size = 104134804, upload-time = "2025-11-12T15:22:35.222Z" },
+ { url = "https://files.pythonhosted.org/packages/28/fc/5bc91d6d831ae41bf6e9e6da6468f25330522e92347c9156eb3f1cb95956/torch-2.9.1-cp314-cp314-manylinux_2_28_x86_64.whl", hash = "sha256:c432d04376f6d9767a9852ea0def7b47a7bbc8e7af3b16ac9cf9ce02b12851c9", size = 899747132, upload-time = "2025-11-12T15:23:36.068Z" },
+ { url = "https://files.pythonhosted.org/packages/63/5d/e8d4e009e52b6b2cf1684bde2a6be157b96fb873732542fb2a9a99e85a83/torch-2.9.1-cp314-cp314-win_amd64.whl", hash = "sha256:d187566a2cdc726fc80138c3cdb260970fab1c27e99f85452721f7759bbd554d", size = 110934845, upload-time = "2025-11-12T15:22:48.367Z" },
+ { url = "https://files.pythonhosted.org/packages/bd/b2/2d15a52516b2ea3f414643b8de68fa4cb220d3877ac8b1028c83dc8ca1c4/torch-2.9.1-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:cb10896a1f7fedaddbccc2017ce6ca9ecaaf990f0973bdfcf405439750118d2c", size = 74823558, upload-time = "2025-11-12T15:22:43.392Z" },
+ { url = "https://files.pythonhosted.org/packages/86/5c/5b2e5d84f5b9850cd1e71af07524d8cbb74cba19379800f1f9f7c997fc70/torch-2.9.1-cp314-cp314t-manylinux_2_28_aarch64.whl", hash = "sha256:0a2bd769944991c74acf0c4ef23603b9c777fdf7637f115605a4b2d8023110c7", size = 104145788, upload-time = "2025-11-12T15:23:52.109Z" },
+ { url = "https://files.pythonhosted.org/packages/a9/8c/3da60787bcf70add986c4ad485993026ac0ca74f2fc21410bc4eb1bb7695/torch-2.9.1-cp314-cp314t-manylinux_2_28_x86_64.whl", hash = "sha256:07c8a9660bc9414c39cac530ac83b1fb1b679d7155824144a40a54f4a47bfa73", size = 899735500, upload-time = "2025-11-12T15:24:08.788Z" },
+ { url = "https://files.pythonhosted.org/packages/db/2b/f7818f6ec88758dfd21da46b6cd46af9d1b3433e53ddbb19ad1e0da17f9b/torch-2.9.1-cp314-cp314t-win_amd64.whl", hash = "sha256:c88d3299ddeb2b35dcc31753305612db485ab6f1823e37fb29451c8b2732b87e", size = 111163659, upload-time = "2025-11-12T15:23:20.009Z" },
+]
+
+[[package]]
+name = "torchvision"
+version = "0.24.1"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "numpy" },
+ { name = "pillow" },
+ { name = "torch" },
+]
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/f0/af/18e2c6b9538a045f60718a0c5a058908ccb24f88fde8e6f0fc12d5ff7bd3/torchvision-0.24.1-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:e48bf6a8ec95872eb45763f06499f87bd2fb246b9b96cb00aae260fda2f96193", size = 1891433, upload-time = "2025-11-12T15:25:03.232Z" },
+ { url = "https://files.pythonhosted.org/packages/9d/43/600e5cfb0643d10d633124f5982d7abc2170dfd7ce985584ff16edab3e76/torchvision-0.24.1-cp312-cp312-manylinux_2_28_aarch64.whl", hash = "sha256:7fb7590c737ebe3e1c077ad60c0e5e2e56bb26e7bccc3b9d04dbfc34fd09f050", size = 2386737, upload-time = "2025-11-12T15:25:08.288Z" },
+ { url = "https://files.pythonhosted.org/packages/93/b1/db2941526ecddd84884132e2742a55c9311296a6a38627f9e2627f5ac889/torchvision-0.24.1-cp312-cp312-manylinux_2_28_x86_64.whl", hash = "sha256:66a98471fc18cad9064123106d810a75f57f0838eee20edc56233fd8484b0cc7", size = 8049868, upload-time = "2025-11-12T15:25:13.058Z" },
+ { url = "https://files.pythonhosted.org/packages/69/98/16e583f59f86cd59949f59d52bfa8fc286f86341a229a9d15cbe7a694f0c/torchvision-0.24.1-cp312-cp312-win_amd64.whl", hash = "sha256:4aa6cb806eb8541e92c9b313e96192c6b826e9eb0042720e2fa250d021079952", size = 4302006, upload-time = "2025-11-12T15:25:16.184Z" },
+ { url = "https://files.pythonhosted.org/packages/e4/97/ab40550f482577f2788304c27220e8ba02c63313bd74cf2f8920526aac20/torchvision-0.24.1-cp313-cp313-macosx_12_0_arm64.whl", hash = "sha256:8a6696db7fb71eadb2c6a48602106e136c785642e598eb1533e0b27744f2cce6", size = 1891435, upload-time = "2025-11-12T15:25:28.642Z" },
+ { url = "https://files.pythonhosted.org/packages/30/65/ac0a3f9be6abdbe4e1d82c915d7e20de97e7fd0e9a277970508b015309f3/torchvision-0.24.1-cp313-cp313-manylinux_2_28_aarch64.whl", hash = "sha256:db2125c46f9cb25dc740be831ce3ce99303cfe60439249a41b04fd9f373be671", size = 2338718, upload-time = "2025-11-12T15:25:26.19Z" },
+ { url = "https://files.pythonhosted.org/packages/10/b5/5bba24ff9d325181508501ed7f0c3de8ed3dd2edca0784d48b144b6c5252/torchvision-0.24.1-cp313-cp313-manylinux_2_28_x86_64.whl", hash = "sha256:f035f0cacd1f44a8ff6cb7ca3627d84c54d685055961d73a1a9fb9827a5414c8", size = 8049661, upload-time = "2025-11-12T15:25:22.558Z" },
+ { url = "https://files.pythonhosted.org/packages/5c/ec/54a96ae9ab6a0dd66d4bba27771f892e36478a9c3489fa56e51c70abcc4d/torchvision-0.24.1-cp313-cp313-win_amd64.whl", hash = "sha256:16274823b93048e0a29d83415166a2e9e0bf4e1b432668357b657612a4802864", size = 4319808, upload-time = "2025-11-12T15:25:17.318Z" },
+ { url = "https://files.pythonhosted.org/packages/d5/f3/a90a389a7e547f3eb8821b13f96ea7c0563cdefbbbb60a10e08dda9720ff/torchvision-0.24.1-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:e3f96208b4bef54cd60e415545f5200346a65024e04f29a26cd0006dbf9e8e66", size = 2005342, upload-time = "2025-11-12T15:25:11.871Z" },
+ { url = "https://files.pythonhosted.org/packages/a9/fe/ff27d2ed1b524078164bea1062f23d2618a5fc3208e247d6153c18c91a76/torchvision-0.24.1-cp313-cp313t-manylinux_2_28_aarch64.whl", hash = "sha256:f231f6a4f2aa6522713326d0d2563538fa72d613741ae364f9913027fa52ea35", size = 2341708, upload-time = "2025-11-12T15:25:25.08Z" },
+ { url = "https://files.pythonhosted.org/packages/b1/b9/d6c903495cbdfd2533b3ef6f7b5643ff589ea062f8feb5c206ee79b9d9e5/torchvision-0.24.1-cp313-cp313t-manylinux_2_28_x86_64.whl", hash = "sha256:1540a9e7f8cf55fe17554482f5a125a7e426347b71de07327d5de6bfd8d17caa", size = 8177239, upload-time = "2025-11-12T15:25:18.554Z" },
+ { url = "https://files.pythonhosted.org/packages/4f/2b/ba02e4261369c3798310483028495cf507e6cb3f394f42e4796981ecf3a7/torchvision-0.24.1-cp313-cp313t-win_amd64.whl", hash = "sha256:d83e16d70ea85d2f196d678bfb702c36be7a655b003abed84e465988b6128938", size = 4251604, upload-time = "2025-11-12T15:25:34.069Z" },
+ { url = "https://files.pythonhosted.org/packages/42/84/577b2cef8f32094add5f52887867da4c2a3e6b4261538447e9b48eb25812/torchvision-0.24.1-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:cccf4b4fec7fdfcd3431b9ea75d1588c0a8596d0333245dafebee0462abe3388", size = 2005319, upload-time = "2025-11-12T15:25:23.827Z" },
+ { url = "https://files.pythonhosted.org/packages/5f/34/ecb786bffe0159a3b49941a61caaae089853132f3cd1e8f555e3621f7e6f/torchvision-0.24.1-cp314-cp314-manylinux_2_28_aarch64.whl", hash = "sha256:1b495edd3a8f9911292424117544f0b4ab780452e998649425d1f4b2bed6695f", size = 2338844, upload-time = "2025-11-12T15:25:32.625Z" },
+ { url = "https://files.pythonhosted.org/packages/51/99/a84623786a6969504c87f2dc3892200f586ee13503f519d282faab0bb4f0/torchvision-0.24.1-cp314-cp314-manylinux_2_28_x86_64.whl", hash = "sha256:ab211e1807dc3e53acf8f6638df9a7444c80c0ad050466e8d652b3e83776987b", size = 8175144, upload-time = "2025-11-12T15:25:31.355Z" },
+ { url = "https://files.pythonhosted.org/packages/6d/ba/8fae3525b233e109317ce6a9c1de922ab2881737b029a7e88021f81e068f/torchvision-0.24.1-cp314-cp314-win_amd64.whl", hash = "sha256:18f9cb60e64b37b551cd605a3d62c15730c086362b40682d23e24b616a697d41", size = 4234459, upload-time = "2025-11-12T15:25:19.859Z" },
+ { url = "https://files.pythonhosted.org/packages/50/33/481602c1c72d0485d4b3a6b48c9534b71c2957c9d83bf860eb837bf5a620/torchvision-0.24.1-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:ec9d7379c519428395e4ffda4dbb99ec56be64b0a75b95989e00f9ec7ae0b2d7", size = 2005336, upload-time = "2025-11-12T15:25:27.225Z" },
+ { url = "https://files.pythonhosted.org/packages/d0/7f/372de60bf3dd8f5593bd0d03f4aecf0d1fd58f5bc6943618d9d913f5e6d5/torchvision-0.24.1-cp314-cp314t-manylinux_2_28_aarch64.whl", hash = "sha256:af9201184c2712d808bd4eb656899011afdfce1e83721c7cb08000034df353fe", size = 2341704, upload-time = "2025-11-12T15:25:29.857Z" },
+ { url = "https://files.pythonhosted.org/packages/36/9b/0f3b9ff3d0225ee2324ec663de0e7fb3eb855615ca958ac1875f22f1f8e5/torchvision-0.24.1-cp314-cp314t-manylinux_2_28_x86_64.whl", hash = "sha256:9ef95d819fd6df81bc7cc97b8f21a15d2c0d3ac5dbfaab5cbc2d2ce57114b19e", size = 8177422, upload-time = "2025-11-12T15:25:37.357Z" },
+ { url = "https://files.pythonhosted.org/packages/d6/ab/e2bcc7c2f13d882a58f8b30ff86f794210b075736587ea50f8c545834f8a/torchvision-0.24.1-cp314-cp314t-win_amd64.whl", hash = "sha256:480b271d6edff83ac2e8d69bbb4cf2073f93366516a50d48f140ccfceedb002e", size = 4335190, upload-time = "2025-11-12T15:25:35.745Z" },
+]
+
+[[package]]
+name = "tornado"
+version = "6.5.2"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/09/ce/1eb500eae19f4648281bb2186927bb062d2438c2e5093d1360391afd2f90/tornado-6.5.2.tar.gz", hash = "sha256:ab53c8f9a0fa351e2c0741284e06c7a45da86afb544133201c5cc8578eb076a0", size = 510821, upload-time = "2025-08-08T18:27:00.78Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/f6/48/6a7529df2c9cc12efd2e8f5dd219516184d703b34c06786809670df5b3bd/tornado-6.5.2-cp39-abi3-macosx_10_9_universal2.whl", hash = "sha256:2436822940d37cde62771cff8774f4f00b3c8024fe482e16ca8387b8a2724db6", size = 442563, upload-time = "2025-08-08T18:26:42.945Z" },
+ { url = "https://files.pythonhosted.org/packages/f2/b5/9b575a0ed3e50b00c40b08cbce82eb618229091d09f6d14bce80fc01cb0b/tornado-6.5.2-cp39-abi3-macosx_10_9_x86_64.whl", hash = "sha256:583a52c7aa94ee046854ba81d9ebb6c81ec0fd30386d96f7640c96dad45a03ef", size = 440729, upload-time = "2025-08-08T18:26:44.473Z" },
+ { url = "https://files.pythonhosted.org/packages/1b/4e/619174f52b120efcf23633c817fd3fed867c30bff785e2cd5a53a70e483c/tornado-6.5.2-cp39-abi3-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:b0fe179f28d597deab2842b86ed4060deec7388f1fd9c1b4a41adf8af058907e", size = 444295, upload-time = "2025-08-08T18:26:46.021Z" },
+ { url = "https://files.pythonhosted.org/packages/95/fa/87b41709552bbd393c85dd18e4e3499dcd8983f66e7972926db8d96aa065/tornado-6.5.2-cp39-abi3-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:b186e85d1e3536d69583d2298423744740986018e393d0321df7340e71898882", size = 443644, upload-time = "2025-08-08T18:26:47.625Z" },
+ { url = "https://files.pythonhosted.org/packages/f9/41/fb15f06e33d7430ca89420283a8762a4e6b8025b800ea51796ab5e6d9559/tornado-6.5.2-cp39-abi3-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:e792706668c87709709c18b353da1f7662317b563ff69f00bab83595940c7108", size = 443878, upload-time = "2025-08-08T18:26:50.599Z" },
+ { url = "https://files.pythonhosted.org/packages/11/92/fe6d57da897776ad2e01e279170ea8ae726755b045fe5ac73b75357a5a3f/tornado-6.5.2-cp39-abi3-musllinux_1_2_aarch64.whl", hash = "sha256:06ceb1300fd70cb20e43b1ad8aaee0266e69e7ced38fa910ad2e03285009ce7c", size = 444549, upload-time = "2025-08-08T18:26:51.864Z" },
+ { url = "https://files.pythonhosted.org/packages/9b/02/c8f4f6c9204526daf3d760f4aa555a7a33ad0e60843eac025ccfd6ff4a93/tornado-6.5.2-cp39-abi3-musllinux_1_2_i686.whl", hash = "sha256:74db443e0f5251be86cbf37929f84d8c20c27a355dd452a5cfa2aada0d001ec4", size = 443973, upload-time = "2025-08-08T18:26:53.625Z" },
+ { url = "https://files.pythonhosted.org/packages/ae/2d/f5f5707b655ce2317190183868cd0f6822a1121b4baeae509ceb9590d0bd/tornado-6.5.2-cp39-abi3-musllinux_1_2_x86_64.whl", hash = "sha256:b5e735ab2889d7ed33b32a459cac490eda71a1ba6857b0118de476ab6c366c04", size = 443954, upload-time = "2025-08-08T18:26:55.072Z" },
+ { url = "https://files.pythonhosted.org/packages/e8/59/593bd0f40f7355806bf6573b47b8c22f8e1374c9b6fd03114bd6b7a3dcfd/tornado-6.5.2-cp39-abi3-win32.whl", hash = "sha256:c6f29e94d9b37a95013bb669616352ddb82e3bfe8326fccee50583caebc8a5f0", size = 445023, upload-time = "2025-08-08T18:26:56.677Z" },
+ { url = "https://files.pythonhosted.org/packages/c7/2a/f609b420c2f564a748a2d80ebfb2ee02a73ca80223af712fca591386cafb/tornado-6.5.2-cp39-abi3-win_amd64.whl", hash = "sha256:e56a5af51cc30dd2cae649429af65ca2f6571da29504a07995175df14c18f35f", size = 445427, upload-time = "2025-08-08T18:26:57.91Z" },
+ { url = "https://files.pythonhosted.org/packages/5e/4f/e1f65e8f8c76d73658b33d33b81eed4322fb5085350e4328d5c956f0c8f9/tornado-6.5.2-cp39-abi3-win_arm64.whl", hash = "sha256:d6c33dc3672e3a1f3618eb63b7ef4683a7688e7b9e6e8f0d9aa5726360a004af", size = 444456, upload-time = "2025-08-08T18:26:59.207Z" },
+]
+
+[[package]]
+name = "tqdm"
+version = "4.67.1"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "colorama", marker = "sys_platform == 'win32'" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/a8/4b/29b4ef32e036bb34e4ab51796dd745cdba7ed47ad142a9f4a1eb8e0c744d/tqdm-4.67.1.tar.gz", hash = "sha256:f8aef9c52c08c13a65f30ea34f4e5aac3fd1a34959879d7e59e63027286627f2", size = 169737, upload-time = "2024-11-24T20:12:22.481Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/d0/30/dc54f88dd4a2b5dc8a0279bdd7270e735851848b762aeb1c1184ed1f6b14/tqdm-4.67.1-py3-none-any.whl", hash = "sha256:26445eca388f82e72884e0d580d5464cd801a3ea01e63e5601bdff9ba6a48de2", size = 78540, upload-time = "2024-11-24T20:12:19.698Z" },
+]
+
+[[package]]
+name = "traitlets"
+version = "5.14.3"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/eb/79/72064e6a701c2183016abbbfedaba506d81e30e232a68c9f0d6f6fcd1574/traitlets-5.14.3.tar.gz", hash = "sha256:9ed0579d3502c94b4b3732ac120375cda96f923114522847de4b3bb98b96b6b7", size = 161621, upload-time = "2024-04-19T11:11:49.746Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/00/c0/8f5d070730d7836adc9c9b6408dec68c6ced86b304a9b26a14df072a6e8c/traitlets-5.14.3-py3-none-any.whl", hash = "sha256:b74e89e397b1ed28cc831db7aea759ba6640cb3de13090ca145426688ff1ac4f", size = 85359, upload-time = "2024-04-19T11:11:46.763Z" },
+]
+
+[[package]]
+name = "transformers"
+version = "4.57.3"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "filelock" },
+ { name = "huggingface-hub" },
+ { name = "numpy" },
+ { name = "packaging" },
+ { name = "pyyaml" },
+ { name = "regex" },
+ { name = "requests" },
+ { name = "safetensors" },
+ { name = "tokenizers" },
+ { name = "tqdm" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/dd/70/d42a739e8dfde3d92bb2fff5819cbf331fe9657323221e79415cd5eb65ee/transformers-4.57.3.tar.gz", hash = "sha256:df4945029aaddd7c09eec5cad851f30662f8bd1746721b34cc031d70c65afebc", size = 10139680, upload-time = "2025-11-25T15:51:30.139Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/6a/6b/2f416568b3c4c91c96e5a365d164f8a4a4a88030aa8ab4644181fdadce97/transformers-4.57.3-py3-none-any.whl", hash = "sha256:c77d353a4851b1880191603d36acb313411d3577f6e2897814f333841f7003f4", size = 11993463, upload-time = "2025-11-25T15:51:26.493Z" },
+]
+
+[[package]]
+name = "triton"
+version = "3.5.1"
+source = { registry = "https://pypi.org/simple" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/f2/50/9a8358d3ef58162c0a415d173cfb45b67de60176e1024f71fbc4d24c0b6d/triton-3.5.1-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:d2c6b915a03888ab931a9fd3e55ba36785e1fe70cbea0b40c6ef93b20fc85232", size = 170470207, upload-time = "2025-11-11T17:41:00.253Z" },
+ { url = "https://files.pythonhosted.org/packages/27/46/8c3bbb5b0a19313f50edcaa363b599e5a1a5ac9683ead82b9b80fe497c8d/triton-3.5.1-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:f3f4346b6ebbd4fad18773f5ba839114f4826037c9f2f34e0148894cd5dd3dba", size = 170470410, upload-time = "2025-11-11T17:41:06.319Z" },
+ { url = "https://files.pythonhosted.org/packages/37/92/e97fcc6b2c27cdb87ce5ee063d77f8f26f19f06916aa680464c8104ef0f6/triton-3.5.1-cp313-cp313t-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:0b4d2c70127fca6a23e247f9348b8adde979d2e7a20391bfbabaac6aebc7e6a8", size = 170579924, upload-time = "2025-11-11T17:41:12.455Z" },
+ { url = "https://files.pythonhosted.org/packages/a4/e6/c595c35e5c50c4bc56a7bac96493dad321e9e29b953b526bbbe20f9911d0/triton-3.5.1-cp314-cp314-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:d0637b1efb1db599a8e9dc960d53ab6e4637db7d4ab6630a0974705d77b14b60", size = 170480488, upload-time = "2025-11-11T17:41:18.222Z" },
+ { url = "https://files.pythonhosted.org/packages/16/b5/b0d3d8b901b6a04ca38df5e24c27e53afb15b93624d7fd7d658c7cd9352a/triton-3.5.1-cp314-cp314t-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:bac7f7d959ad0f48c0e97d6643a1cc0fd5786fe61cb1f83b537c6b2d54776478", size = 170582192, upload-time = "2025-11-11T17:41:23.963Z" },
+]
+
+[[package]]
+name = "typing-extensions"
+version = "4.15.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/72/94/1a15dd82efb362ac84269196e94cf00f187f7ed21c242792a923cdb1c61f/typing_extensions-4.15.0.tar.gz", hash = "sha256:0cea48d173cc12fa28ecabc3b837ea3cf6f38c6d1136f85cbaaf598984861466", size = 109391, upload-time = "2025-08-25T13:49:26.313Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/18/67/36e9267722cc04a6b9f15c7f3441c2363321a3ea07da7ae0c0707beb2a9c/typing_extensions-4.15.0-py3-none-any.whl", hash = "sha256:f0fa19c6845758ab08074a0cfa8b7aecb71c999ca73d62883bc25cc018c4e548", size = 44614, upload-time = "2025-08-25T13:49:24.86Z" },
+]
+
+[[package]]
+name = "typing-inspection"
+version = "0.4.2"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "typing-extensions" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/55/e3/70399cb7dd41c10ac53367ae42139cf4b1ca5f36bb3dc6c9d33acdb43655/typing_inspection-0.4.2.tar.gz", hash = "sha256:ba561c48a67c5958007083d386c3295464928b01faa735ab8547c5692e87f464", size = 75949, upload-time = "2025-10-01T02:14:41.687Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/dc/9b/47798a6c91d8bdb567fe2698fe81e0c6b7cb7ef4d13da4114b41d239f65d/typing_inspection-0.4.2-py3-none-any.whl", hash = "sha256:4ed1cacbdc298c220f1bd249ed5287caa16f34d44ef4e9c3d0cbad5b521545e7", size = 14611, upload-time = "2025-10-01T02:14:40.154Z" },
+]
+
+[[package]]
+name = "tzdata"
+version = "2025.2"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/95/32/1a225d6164441be760d75c2c42e2780dc0873fe382da3e98a2e1e48361e5/tzdata-2025.2.tar.gz", hash = "sha256:b60a638fcc0daffadf82fe0f57e53d06bdec2f36c4df66280ae79bce6bd6f2b9", size = 196380, upload-time = "2025-03-23T13:54:43.652Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/5c/23/c7abc0ca0a1526a0774eca151daeb8de62ec457e77262b66b359c3c7679e/tzdata-2025.2-py2.py3-none-any.whl", hash = "sha256:1a403fada01ff9221ca8044d701868fa132215d84beb92242d9acd2147f667a8", size = 347839, upload-time = "2025-03-23T13:54:41.845Z" },
+]
+
+[[package]]
+name = "uri-template"
+version = "1.3.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/31/c7/0336f2bd0bcbada6ccef7aaa25e443c118a704f828a0620c6fa0207c1b64/uri-template-1.3.0.tar.gz", hash = "sha256:0e00f8eb65e18c7de20d595a14336e9f337ead580c70934141624b6d1ffdacc7", size = 21678, upload-time = "2023-06-21T01:49:05.374Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/e7/00/3fca040d7cf8a32776d3d81a00c8ee7457e00f80c649f1e4a863c8321ae9/uri_template-1.3.0-py3-none-any.whl", hash = "sha256:a44a133ea12d44a0c0f06d7d42a52d71282e77e2f937d8abd5655b8d56fc1363", size = 11140, upload-time = "2023-06-21T01:49:03.467Z" },
+]
+
+[[package]]
+name = "urllib3"
+version = "2.6.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/5e/1d/0f3a93cca1ac5e8287842ed4eebbd0f7a991315089b1a0b01c7788aa7b63/urllib3-2.6.1.tar.gz", hash = "sha256:5379eb6e1aba4088bae84f8242960017ec8d8e3decf30480b3a1abdaa9671a3f", size = 432678, upload-time = "2025-12-08T15:25:26.773Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/bc/56/190ceb8cb10511b730b564fb1e0293fa468363dbad26145c34928a60cb0c/urllib3-2.6.1-py3-none-any.whl", hash = "sha256:e67d06fe947c36a7ca39f4994b08d73922d40e6cca949907be05efa6fd75110b", size = 131138, upload-time = "2025-12-08T15:25:25.51Z" },
+]
+
+[[package]]
+name = "wandb"
+version = "0.23.1"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "click" },
+ { name = "gitpython" },
+ { name = "packaging" },
+ { name = "platformdirs" },
+ { name = "protobuf" },
+ { name = "pydantic" },
+ { name = "pyyaml" },
+ { name = "requests" },
+ { name = "sentry-sdk" },
+ { name = "typing-extensions" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/0a/cc/770ae3aa7ae44f6792f7ecb81c14c0e38b672deb35235719bb1006519487/wandb-0.23.1.tar.gz", hash = "sha256:f6fb1e3717949b29675a69359de0eeb01e67d3360d581947d5b3f98c273567d6", size = 44298053, upload-time = "2025-12-03T02:25:10.79Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/12/0b/c3d7053dfd93fd259a63c7818d9c4ac2ba0642ff8dc8db98662ea0cf9cc0/wandb-0.23.1-py3-none-macosx_12_0_arm64.whl", hash = "sha256:358e15471d19b7d73fc464e37371c19d44d39e433252ac24df107aff993a286b", size = 21527293, upload-time = "2025-12-03T02:24:48.011Z" },
+ { url = "https://files.pythonhosted.org/packages/ee/9f/059420fa0cb6c511dc5c5a50184122b6aca7b178cb2aa210139e354020da/wandb-0.23.1-py3-none-macosx_12_0_x86_64.whl", hash = "sha256:110304407f4b38f163bdd50ed5c5225365e4df3092f13089c30171a75257b575", size = 22745926, upload-time = "2025-12-03T02:24:50.519Z" },
+ { url = "https://files.pythonhosted.org/packages/96/b6/fd465827c14c64d056d30b4c9fcf4dac889a6969dba64489a88fc4ffa333/wandb-0.23.1-py3-none-manylinux_2_28_aarch64.whl", hash = "sha256:6cc984cf85feb2f8ee0451d76bc9fb7f39da94956bb8183e30d26284cf203b65", size = 21212973, upload-time = "2025-12-03T02:24:52.828Z" },
+ { url = "https://files.pythonhosted.org/packages/5c/ee/9a8bb9a39cc1f09c3060456cc79565110226dc4099a719af5c63432da21d/wandb-0.23.1-py3-none-manylinux_2_28_x86_64.whl", hash = "sha256:67431cd3168d79fdb803e503bd669c577872ffd5dadfa86de733b3274b93088e", size = 22887885, upload-time = "2025-12-03T02:24:55.281Z" },
+ { url = "https://files.pythonhosted.org/packages/6d/4d/8d9e75add529142e037b05819cb3ab1005679272950128d69d218b7e5b2e/wandb-0.23.1-py3-none-musllinux_1_2_aarch64.whl", hash = "sha256:07be70c0baa97ea25fadc4a9d0097f7371eef6dcacc5ceb525c82491a31e9244", size = 21250967, upload-time = "2025-12-03T02:24:57.603Z" },
+ { url = "https://files.pythonhosted.org/packages/97/72/0b35cddc4e4168f03c759b96d9f671ad18aec8bdfdd84adfea7ecb3f5701/wandb-0.23.1-py3-none-musllinux_1_2_x86_64.whl", hash = "sha256:216c95b08e0a2ec6a6008373b056d597573d565e30b43a7a93c35a171485ee26", size = 22988382, upload-time = "2025-12-03T02:25:00.518Z" },
+ { url = "https://files.pythonhosted.org/packages/c0/6d/e78093d49d68afb26f5261a70fc7877c34c114af5c2ee0ab3b1af85f5e76/wandb-0.23.1-py3-none-win32.whl", hash = "sha256:fb5cf0f85692f758a5c36ab65fea96a1284126de64e836610f92ddbb26df5ded", size = 22150756, upload-time = "2025-12-03T02:25:02.734Z" },
+ { url = "https://files.pythonhosted.org/packages/05/27/4f13454b44c9eceaac3d6e4e4efa2230b6712d613ff9bf7df010eef4fd18/wandb-0.23.1-py3-none-win_amd64.whl", hash = "sha256:21c8c56e436eb707b7d54f705652e030d48e5cfcba24cf953823eb652e30e714", size = 22150760, upload-time = "2025-12-03T02:25:05.106Z" },
+ { url = "https://files.pythonhosted.org/packages/30/20/6c091d451e2a07689bfbfaeb7592d488011420e721de170884fedd68c644/wandb-0.23.1-py3-none-win_arm64.whl", hash = "sha256:8aee7f3bb573f2c0acf860f497ca9c684f9b35f2ca51011ba65af3d4592b77c1", size = 20137463, upload-time = "2025-12-03T02:25:08.317Z" },
+]
+
+[[package]]
+name = "wcwidth"
+version = "0.2.14"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/24/30/6b0809f4510673dc723187aeaf24c7f5459922d01e2f794277a3dfb90345/wcwidth-0.2.14.tar.gz", hash = "sha256:4d478375d31bc5395a3c55c40ccdf3354688364cd61c4f6adacaa9215d0b3605", size = 102293, upload-time = "2025-09-22T16:29:53.023Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/af/b5/123f13c975e9f27ab9c0770f514345bd406d0e8d3b7a0723af9d43f710af/wcwidth-0.2.14-py2.py3-none-any.whl", hash = "sha256:a7bb560c8aee30f9957e5f9895805edd20602f2d7f720186dfd906e82b4982e1", size = 37286, upload-time = "2025-09-22T16:29:51.641Z" },
+]
+
+[[package]]
+name = "webcolors"
+version = "25.10.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/1d/7a/eb316761ec35664ea5174709a68bbd3389de60d4a1ebab8808bfc264ed67/webcolors-25.10.0.tar.gz", hash = "sha256:62abae86504f66d0f6364c2a8520de4a0c47b80c03fc3a5f1815fedbef7c19bf", size = 53491, upload-time = "2025-10-31T07:51:03.977Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/e2/cc/e097523dd85c9cf5d354f78310927f1656c422bd7b2613b2db3e3f9a0f2c/webcolors-25.10.0-py3-none-any.whl", hash = "sha256:032c727334856fc0b968f63daa252a1ac93d33db2f5267756623c210e57a4f1d", size = 14905, upload-time = "2025-10-31T07:51:01.778Z" },
+]
+
+[[package]]
+name = "webdataset"
+version = "1.0.2"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "braceexpand" },
+ { name = "numpy" },
+ { name = "pyyaml" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/5a/3a/68800d92e065cf4750ebecf973b13979c0c929b439e1293012938862038d/webdataset-1.0.2.tar.gz", hash = "sha256:7f0498be827cfa46cc5430a58768a24e2c6a410676a61be1838f53d61afdaab4", size = 80090, upload-time = "2025-06-19T23:26:21.945Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/d9/00/aca6beb3658dab4ed3dbb41a78e6e7f31342e0b41d28088f205525751601/webdataset-1.0.2-py3-none-any.whl", hash = "sha256:3dbfced32b25c0d199c6b9787937b6f85742bc3c84f652c846893075c1c082d9", size = 74956, upload-time = "2025-06-19T23:26:20.354Z" },
+]
+
+[[package]]
+name = "webencodings"
+version = "0.5.1"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/0b/02/ae6ceac1baeda530866a85075641cec12989bd8d31af6d5ab4a3e8c92f47/webencodings-0.5.1.tar.gz", hash = "sha256:b36a1c245f2d304965eb4e0a82848379241dc04b865afcc4aab16748587e1923", size = 9721, upload-time = "2017-04-05T20:21:34.189Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/f4/24/2a3e3df732393fed8b3ebf2ec078f05546de641fe1b667ee316ec1dcf3b7/webencodings-0.5.1-py2.py3-none-any.whl", hash = "sha256:a0af1213f3c2226497a97e2b3aa01a7e4bee4f403f95be16fc9acd2947514a78", size = 11774, upload-time = "2017-04-05T20:21:32.581Z" },
+]
+
+[[package]]
+name = "websocket-client"
+version = "1.9.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/2c/41/aa4bf9664e4cda14c3b39865b12251e8e7d239f4cd0e3cc1b6c2ccde25c1/websocket_client-1.9.0.tar.gz", hash = "sha256:9e813624b6eb619999a97dc7958469217c3176312b3a16a4bd1bc7e08a46ec98", size = 70576, upload-time = "2025-10-07T21:16:36.495Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/34/db/b10e48aa8fff7407e67470363eac595018441cf32d5e1001567a7aeba5d2/websocket_client-1.9.0-py3-none-any.whl", hash = "sha256:af248a825037ef591efbf6ed20cc5faa03d3b47b9e5a2230a529eeee1c1fc3ef", size = 82616, upload-time = "2025-10-07T21:16:34.951Z" },
+]
+
+[[package]]
+name = "wfdb"
+version = "4.3.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "aiohttp" },
+ { name = "fsspec" },
+ { name = "matplotlib" },
+ { name = "numpy" },
+ { name = "pandas" },
+ { name = "requests" },
+ { name = "scipy" },
+ { name = "soundfile" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/6d/5a/7afbcf36752b9192f3e786f4062904f81f5afd65563797b7721fd10c88aa/wfdb-4.3.0.tar.gz", hash = "sha256:60df86bc5c9186a91930d1118218d9301d40a730ff730ec1c8571d1141d92bb9", size = 15717569, upload-time = "2025-04-02T16:28:03.707Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/9c/b8/79fe1483255e728a791477d5ad748a8873063db854c77749a30d0e6d896c/wfdb-4.3.0-py3-none-any.whl", hash = "sha256:bbd9d291bc2038b0586616fcd8072cfdc906ac70c1858b1513378c4129a0110f", size = 163846, upload-time = "2025-04-02T16:28:00.24Z" },
+]
+
+[[package]]
+name = "widgetsnbextension"
+version = "4.0.15"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/bd/f4/c67440c7fb409a71b7404b7aefcd7569a9c0d6bd071299bf4198ae7a5d95/widgetsnbextension-4.0.15.tar.gz", hash = "sha256:de8610639996f1567952d763a5a41af8af37f2575a41f9852a38f947eb82a3b9", size = 1097402, upload-time = "2025-11-01T21:15:55.178Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/3f/0e/fa3b193432cfc60c93b42f3be03365f5f909d2b3ea410295cf36df739e31/widgetsnbextension-4.0.15-py3-none-any.whl", hash = "sha256:8156704e4346a571d9ce73b84bee86a29906c9abfd7223b7228a28899ccf3366", size = 2196503, upload-time = "2025-11-01T21:15:53.565Z" },
+]
+
+[[package]]
+name = "xxhash"
+version = "3.6.0"
+source = { registry = "https://pypi.org/simple" }
+sdist = { url = "https://files.pythonhosted.org/packages/02/84/30869e01909fb37a6cc7e18688ee8bf1e42d57e7e0777636bd47524c43c7/xxhash-3.6.0.tar.gz", hash = "sha256:f0162a78b13a0d7617b2845b90c763339d1f1d82bb04a4b07f4ab535cc5e05d6", size = 85160, upload-time = "2025-10-02T14:37:08.097Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/9a/07/d9412f3d7d462347e4511181dea65e47e0d0e16e26fbee2ea86a2aefb657/xxhash-3.6.0-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:01362c4331775398e7bb34e3ab403bc9ee9f7c497bc7dee6272114055277dd3c", size = 32744, upload-time = "2025-10-02T14:34:34.622Z" },
+ { url = "https://files.pythonhosted.org/packages/79/35/0429ee11d035fc33abe32dca1b2b69e8c18d236547b9a9b72c1929189b9a/xxhash-3.6.0-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:b7b2df81a23f8cb99656378e72501b2cb41b1827c0f5a86f87d6b06b69f9f204", size = 30816, upload-time = "2025-10-02T14:34:36.043Z" },
+ { url = "https://files.pythonhosted.org/packages/b7/f2/57eb99aa0f7d98624c0932c5b9a170e1806406cdbcdb510546634a1359e0/xxhash-3.6.0-cp312-cp312-manylinux1_i686.manylinux_2_28_i686.manylinux_2_5_i686.whl", hash = "sha256:dc94790144e66b14f67b10ac8ed75b39ca47536bf8800eb7c24b50271ea0c490", size = 194035, upload-time = "2025-10-02T14:34:37.354Z" },
+ { url = "https://files.pythonhosted.org/packages/4c/ed/6224ba353690d73af7a3f1c7cdb1fc1b002e38f783cb991ae338e1eb3d79/xxhash-3.6.0-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:93f107c673bccf0d592cdba077dedaf52fe7f42dcd7676eba1f6d6f0c3efffd2", size = 212914, upload-time = "2025-10-02T14:34:38.6Z" },
+ { url = "https://files.pythonhosted.org/packages/38/86/fb6b6130d8dd6b8942cc17ab4d90e223653a89aa32ad2776f8af7064ed13/xxhash-3.6.0-cp312-cp312-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:2aa5ee3444c25b69813663c9f8067dcfaa2e126dc55e8dddf40f4d1c25d7effa", size = 212163, upload-time = "2025-10-02T14:34:39.872Z" },
+ { url = "https://files.pythonhosted.org/packages/ee/dc/e84875682b0593e884ad73b2d40767b5790d417bde603cceb6878901d647/xxhash-3.6.0-cp312-cp312-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:f7f99123f0e1194fa59cc69ad46dbae2e07becec5df50a0509a808f90a0f03f0", size = 445411, upload-time = "2025-10-02T14:34:41.569Z" },
+ { url = "https://files.pythonhosted.org/packages/11/4f/426f91b96701ec2f37bb2b8cec664eff4f658a11f3fa9d94f0a887ea6d2b/xxhash-3.6.0-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:49e03e6fe2cac4a1bc64952dd250cf0dbc5ef4ebb7b8d96bce82e2de163c82a2", size = 193883, upload-time = "2025-10-02T14:34:43.249Z" },
+ { url = "https://files.pythonhosted.org/packages/53/5a/ddbb83eee8e28b778eacfc5a85c969673e4023cdeedcfcef61f36731610b/xxhash-3.6.0-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:bd17fede52a17a4f9a7bc4472a5867cb0b160deeb431795c0e4abe158bc784e9", size = 210392, upload-time = "2025-10-02T14:34:45.042Z" },
+ { url = "https://files.pythonhosted.org/packages/1e/c2/ff69efd07c8c074ccdf0a4f36fcdd3d27363665bcdf4ba399abebe643465/xxhash-3.6.0-cp312-cp312-musllinux_1_2_i686.whl", hash = "sha256:6fb5f5476bef678f69db04f2bd1efbed3030d2aba305b0fc1773645f187d6a4e", size = 197898, upload-time = "2025-10-02T14:34:46.302Z" },
+ { url = "https://files.pythonhosted.org/packages/58/ca/faa05ac19b3b622c7c9317ac3e23954187516298a091eb02c976d0d3dd45/xxhash-3.6.0-cp312-cp312-musllinux_1_2_ppc64le.whl", hash = "sha256:843b52f6d88071f87eba1631b684fcb4b2068cd2180a0224122fe4ef011a9374", size = 210655, upload-time = "2025-10-02T14:34:47.571Z" },
+ { url = "https://files.pythonhosted.org/packages/d4/7a/06aa7482345480cc0cb597f5c875b11a82c3953f534394f620b0be2f700c/xxhash-3.6.0-cp312-cp312-musllinux_1_2_s390x.whl", hash = "sha256:7d14a6cfaf03b1b6f5f9790f76880601ccc7896aff7ab9cd8978a939c1eb7e0d", size = 414001, upload-time = "2025-10-02T14:34:49.273Z" },
+ { url = "https://files.pythonhosted.org/packages/23/07/63ffb386cd47029aa2916b3d2f454e6cc5b9f5c5ada3790377d5430084e7/xxhash-3.6.0-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:418daf3db71e1413cfe211c2f9a528456936645c17f46b5204705581a45390ae", size = 191431, upload-time = "2025-10-02T14:34:50.798Z" },
+ { url = "https://files.pythonhosted.org/packages/0f/93/14fde614cadb4ddf5e7cebf8918b7e8fac5ae7861c1875964f17e678205c/xxhash-3.6.0-cp312-cp312-win32.whl", hash = "sha256:50fc255f39428a27299c20e280d6193d8b63b8ef8028995323bf834a026b4fbb", size = 30617, upload-time = "2025-10-02T14:34:51.954Z" },
+ { url = "https://files.pythonhosted.org/packages/13/5d/0d125536cbe7565a83d06e43783389ecae0c0f2ed037b48ede185de477c0/xxhash-3.6.0-cp312-cp312-win_amd64.whl", hash = "sha256:c0f2ab8c715630565ab8991b536ecded9416d615538be8ecddce43ccf26cbc7c", size = 31534, upload-time = "2025-10-02T14:34:53.276Z" },
+ { url = "https://files.pythonhosted.org/packages/54/85/6ec269b0952ec7e36ba019125982cf11d91256a778c7c3f98a4c5043d283/xxhash-3.6.0-cp312-cp312-win_arm64.whl", hash = "sha256:eae5c13f3bc455a3bbb68bdc513912dc7356de7e2280363ea235f71f54064829", size = 27876, upload-time = "2025-10-02T14:34:54.371Z" },
+ { url = "https://files.pythonhosted.org/packages/33/76/35d05267ac82f53ae9b0e554da7c5e281ee61f3cad44c743f0fcd354f211/xxhash-3.6.0-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:599e64ba7f67472481ceb6ee80fa3bd828fd61ba59fb11475572cc5ee52b89ec", size = 32738, upload-time = "2025-10-02T14:34:55.839Z" },
+ { url = "https://files.pythonhosted.org/packages/31/a8/3fbce1cd96534a95e35d5120637bf29b0d7f5d8fa2f6374e31b4156dd419/xxhash-3.6.0-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:7d8b8aaa30fca4f16f0c84a5c8d7ddee0e25250ec2796c973775373257dde8f1", size = 30821, upload-time = "2025-10-02T14:34:57.219Z" },
+ { url = "https://files.pythonhosted.org/packages/0c/ea/d387530ca7ecfa183cb358027f1833297c6ac6098223fd14f9782cd0015c/xxhash-3.6.0-cp313-cp313-manylinux1_i686.manylinux_2_28_i686.manylinux_2_5_i686.whl", hash = "sha256:d597acf8506d6e7101a4a44a5e428977a51c0fadbbfd3c39650cca9253f6e5a6", size = 194127, upload-time = "2025-10-02T14:34:59.21Z" },
+ { url = "https://files.pythonhosted.org/packages/ba/0c/71435dcb99874b09a43b8d7c54071e600a7481e42b3e3ce1eb5226a5711a/xxhash-3.6.0-cp313-cp313-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:858dc935963a33bc33490128edc1c12b0c14d9c7ebaa4e387a7869ecc4f3e263", size = 212975, upload-time = "2025-10-02T14:35:00.816Z" },
+ { url = "https://files.pythonhosted.org/packages/84/7a/c2b3d071e4bb4a90b7057228a99b10d51744878f4a8a6dd643c8bd897620/xxhash-3.6.0-cp313-cp313-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:ba284920194615cb8edf73bf52236ce2e1664ccd4a38fdb543506413529cc546", size = 212241, upload-time = "2025-10-02T14:35:02.207Z" },
+ { url = "https://files.pythonhosted.org/packages/81/5f/640b6eac0128e215f177df99eadcd0f1b7c42c274ab6a394a05059694c5a/xxhash-3.6.0-cp313-cp313-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:4b54219177f6c6674d5378bd862c6aedf64725f70dd29c472eaae154df1a2e89", size = 445471, upload-time = "2025-10-02T14:35:03.61Z" },
+ { url = "https://files.pythonhosted.org/packages/5e/1e/3c3d3ef071b051cc3abbe3721ffb8365033a172613c04af2da89d5548a87/xxhash-3.6.0-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:42c36dd7dbad2f5238950c377fcbf6811b1cdb1c444fab447960030cea60504d", size = 193936, upload-time = "2025-10-02T14:35:05.013Z" },
+ { url = "https://files.pythonhosted.org/packages/2c/bd/4a5f68381939219abfe1c22a9e3a5854a4f6f6f3c4983a87d255f21f2e5d/xxhash-3.6.0-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:f22927652cba98c44639ffdc7aaf35828dccf679b10b31c4ad72a5b530a18eb7", size = 210440, upload-time = "2025-10-02T14:35:06.239Z" },
+ { url = "https://files.pythonhosted.org/packages/eb/37/b80fe3d5cfb9faff01a02121a0f4d565eb7237e9e5fc66e73017e74dcd36/xxhash-3.6.0-cp313-cp313-musllinux_1_2_i686.whl", hash = "sha256:b45fad44d9c5c119e9c6fbf2e1c656a46dc68e280275007bbfd3d572b21426db", size = 197990, upload-time = "2025-10-02T14:35:07.735Z" },
+ { url = "https://files.pythonhosted.org/packages/d7/fd/2c0a00c97b9e18f72e1f240ad4e8f8a90fd9d408289ba9c7c495ed7dc05c/xxhash-3.6.0-cp313-cp313-musllinux_1_2_ppc64le.whl", hash = "sha256:6f2580ffab1a8b68ef2b901cde7e55fa8da5e4be0977c68f78fc80f3c143de42", size = 210689, upload-time = "2025-10-02T14:35:09.438Z" },
+ { url = "https://files.pythonhosted.org/packages/93/86/5dd8076a926b9a95db3206aba20d89a7fc14dd5aac16e5c4de4b56033140/xxhash-3.6.0-cp313-cp313-musllinux_1_2_s390x.whl", hash = "sha256:40c391dd3cd041ebc3ffe6f2c862f402e306eb571422e0aa918d8070ba31da11", size = 414068, upload-time = "2025-10-02T14:35:11.162Z" },
+ { url = "https://files.pythonhosted.org/packages/af/3c/0bb129170ee8f3650f08e993baee550a09593462a5cddd8e44d0011102b1/xxhash-3.6.0-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:f205badabde7aafd1a31e8ca2a3e5a763107a71c397c4481d6a804eb5063d8bd", size = 191495, upload-time = "2025-10-02T14:35:12.971Z" },
+ { url = "https://files.pythonhosted.org/packages/e9/3a/6797e0114c21d1725e2577508e24006fd7ff1d8c0c502d3b52e45c1771d8/xxhash-3.6.0-cp313-cp313-win32.whl", hash = "sha256:2577b276e060b73b73a53042ea5bd5203d3e6347ce0d09f98500f418a9fcf799", size = 30620, upload-time = "2025-10-02T14:35:14.129Z" },
+ { url = "https://files.pythonhosted.org/packages/86/15/9bc32671e9a38b413a76d24722a2bf8784a132c043063a8f5152d390b0f9/xxhash-3.6.0-cp313-cp313-win_amd64.whl", hash = "sha256:757320d45d2fbcce8f30c42a6b2f47862967aea7bf458b9625b4bbe7ee390392", size = 31542, upload-time = "2025-10-02T14:35:15.21Z" },
+ { url = "https://files.pythonhosted.org/packages/39/c5/cc01e4f6188656e56112d6a8e0dfe298a16934b8c47a247236549a3f7695/xxhash-3.6.0-cp313-cp313-win_arm64.whl", hash = "sha256:457b8f85dec5825eed7b69c11ae86834a018b8e3df5e77783c999663da2f96d6", size = 27880, upload-time = "2025-10-02T14:35:16.315Z" },
+ { url = "https://files.pythonhosted.org/packages/f3/30/25e5321c8732759e930c555176d37e24ab84365482d257c3b16362235212/xxhash-3.6.0-cp313-cp313t-macosx_10_13_x86_64.whl", hash = "sha256:a42e633d75cdad6d625434e3468126c73f13f7584545a9cf34e883aa1710e702", size = 32956, upload-time = "2025-10-02T14:35:17.413Z" },
+ { url = "https://files.pythonhosted.org/packages/9f/3c/0573299560d7d9f8ab1838f1efc021a280b5ae5ae2e849034ef3dee18810/xxhash-3.6.0-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:568a6d743219e717b07b4e03b0a828ce593833e498c3b64752e0f5df6bfe84db", size = 31072, upload-time = "2025-10-02T14:35:18.844Z" },
+ { url = "https://files.pythonhosted.org/packages/7a/1c/52d83a06e417cd9d4137722693424885cc9878249beb3a7c829e74bf7ce9/xxhash-3.6.0-cp313-cp313t-manylinux1_i686.manylinux_2_28_i686.manylinux_2_5_i686.whl", hash = "sha256:bec91b562d8012dae276af8025a55811b875baace6af510412a5e58e3121bc54", size = 196409, upload-time = "2025-10-02T14:35:20.31Z" },
+ { url = "https://files.pythonhosted.org/packages/e3/8e/c6d158d12a79bbd0b878f8355432075fc82759e356ab5a111463422a239b/xxhash-3.6.0-cp313-cp313t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:78e7f2f4c521c30ad5e786fdd6bae89d47a32672a80195467b5de0480aa97b1f", size = 215736, upload-time = "2025-10-02T14:35:21.616Z" },
+ { url = "https://files.pythonhosted.org/packages/bc/68/c4c80614716345d55071a396cf03d06e34b5f4917a467faf43083c995155/xxhash-3.6.0-cp313-cp313t-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:3ed0df1b11a79856df5ffcab572cbd6b9627034c1c748c5566fa79df9048a7c5", size = 214833, upload-time = "2025-10-02T14:35:23.32Z" },
+ { url = "https://files.pythonhosted.org/packages/7e/e9/ae27c8ffec8b953efa84c7c4a6c6802c263d587b9fc0d6e7cea64e08c3af/xxhash-3.6.0-cp313-cp313t-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:0e4edbfc7d420925b0dd5e792478ed393d6e75ff8fc219a6546fb446b6a417b1", size = 448348, upload-time = "2025-10-02T14:35:25.111Z" },
+ { url = "https://files.pythonhosted.org/packages/d7/6b/33e21afb1b5b3f46b74b6bd1913639066af218d704cc0941404ca717fc57/xxhash-3.6.0-cp313-cp313t-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:fba27a198363a7ef87f8c0f6b171ec36b674fe9053742c58dd7e3201c1ab30ee", size = 196070, upload-time = "2025-10-02T14:35:26.586Z" },
+ { url = "https://files.pythonhosted.org/packages/96/b6/fcabd337bc5fa624e7203aa0fa7d0c49eed22f72e93229431752bddc83d9/xxhash-3.6.0-cp313-cp313t-musllinux_1_2_aarch64.whl", hash = "sha256:794fe9145fe60191c6532fa95063765529770edcdd67b3d537793e8004cabbfd", size = 212907, upload-time = "2025-10-02T14:35:28.087Z" },
+ { url = "https://files.pythonhosted.org/packages/4b/d3/9ee6160e644d660fcf176c5825e61411c7f62648728f69c79ba237250143/xxhash-3.6.0-cp313-cp313t-musllinux_1_2_i686.whl", hash = "sha256:6105ef7e62b5ac73a837778efc331a591d8442f8ef5c7e102376506cb4ae2729", size = 200839, upload-time = "2025-10-02T14:35:29.857Z" },
+ { url = "https://files.pythonhosted.org/packages/0d/98/e8de5baa5109394baf5118f5e72ab21a86387c4f89b0e77ef3e2f6b0327b/xxhash-3.6.0-cp313-cp313t-musllinux_1_2_ppc64le.whl", hash = "sha256:f01375c0e55395b814a679b3eea205db7919ac2af213f4a6682e01220e5fe292", size = 213304, upload-time = "2025-10-02T14:35:31.222Z" },
+ { url = "https://files.pythonhosted.org/packages/7b/1d/71056535dec5c3177eeb53e38e3d367dd1d16e024e63b1cee208d572a033/xxhash-3.6.0-cp313-cp313t-musllinux_1_2_s390x.whl", hash = "sha256:d706dca2d24d834a4661619dcacf51a75c16d65985718d6a7d73c1eeeb903ddf", size = 416930, upload-time = "2025-10-02T14:35:32.517Z" },
+ { url = "https://files.pythonhosted.org/packages/dc/6c/5cbde9de2cd967c322e651c65c543700b19e7ae3e0aae8ece3469bf9683d/xxhash-3.6.0-cp313-cp313t-musllinux_1_2_x86_64.whl", hash = "sha256:5f059d9faeacd49c0215d66f4056e1326c80503f51a1532ca336a385edadd033", size = 193787, upload-time = "2025-10-02T14:35:33.827Z" },
+ { url = "https://files.pythonhosted.org/packages/19/fa/0172e350361d61febcea941b0cc541d6e6c8d65d153e85f850a7b256ff8a/xxhash-3.6.0-cp313-cp313t-win32.whl", hash = "sha256:1244460adc3a9be84731d72b8e80625788e5815b68da3da8b83f78115a40a7ec", size = 30916, upload-time = "2025-10-02T14:35:35.107Z" },
+ { url = "https://files.pythonhosted.org/packages/ad/e6/e8cf858a2b19d6d45820f072eff1bea413910592ff17157cabc5f1227a16/xxhash-3.6.0-cp313-cp313t-win_amd64.whl", hash = "sha256:b1e420ef35c503869c4064f4a2f2b08ad6431ab7b229a05cce39d74268bca6b8", size = 31799, upload-time = "2025-10-02T14:35:36.165Z" },
+ { url = "https://files.pythonhosted.org/packages/56/15/064b197e855bfb7b343210e82490ae672f8bc7cdf3ddb02e92f64304ee8a/xxhash-3.6.0-cp313-cp313t-win_arm64.whl", hash = "sha256:ec44b73a4220623235f67a996c862049f375df3b1052d9899f40a6382c32d746", size = 28044, upload-time = "2025-10-02T14:35:37.195Z" },
+ { url = "https://files.pythonhosted.org/packages/7e/5e/0138bc4484ea9b897864d59fce9be9086030825bc778b76cb5a33a906d37/xxhash-3.6.0-cp314-cp314-macosx_10_13_x86_64.whl", hash = "sha256:a40a3d35b204b7cc7643cbcf8c9976d818cb47befcfac8bbefec8038ac363f3e", size = 32754, upload-time = "2025-10-02T14:35:38.245Z" },
+ { url = "https://files.pythonhosted.org/packages/18/d7/5dac2eb2ec75fd771957a13e5dda560efb2176d5203f39502a5fc571f899/xxhash-3.6.0-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:a54844be970d3fc22630b32d515e79a90d0a3ddb2644d8d7402e3c4c8da61405", size = 30846, upload-time = "2025-10-02T14:35:39.6Z" },
+ { url = "https://files.pythonhosted.org/packages/fe/71/8bc5be2bb00deb5682e92e8da955ebe5fa982da13a69da5a40a4c8db12fb/xxhash-3.6.0-cp314-cp314-manylinux1_i686.manylinux_2_28_i686.manylinux_2_5_i686.whl", hash = "sha256:016e9190af8f0a4e3741343777710e3d5717427f175adfdc3e72508f59e2a7f3", size = 194343, upload-time = "2025-10-02T14:35:40.69Z" },
+ { url = "https://files.pythonhosted.org/packages/e7/3b/52badfb2aecec2c377ddf1ae75f55db3ba2d321c5e164f14461c90837ef3/xxhash-3.6.0-cp314-cp314-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:4f6f72232f849eb9d0141e2ebe2677ece15adfd0fa599bc058aad83c714bb2c6", size = 213074, upload-time = "2025-10-02T14:35:42.29Z" },
+ { url = "https://files.pythonhosted.org/packages/a2/2b/ae46b4e9b92e537fa30d03dbc19cdae57ed407e9c26d163895e968e3de85/xxhash-3.6.0-cp314-cp314-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:63275a8aba7865e44b1813d2177e0f5ea7eadad3dd063a21f7cf9afdc7054063", size = 212388, upload-time = "2025-10-02T14:35:43.929Z" },
+ { url = "https://files.pythonhosted.org/packages/f5/80/49f88d3afc724b4ac7fbd664c8452d6db51b49915be48c6982659e0e7942/xxhash-3.6.0-cp314-cp314-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:3cd01fa2aa00d8b017c97eb46b9a794fbdca53fc14f845f5a328c71254b0abb7", size = 445614, upload-time = "2025-10-02T14:35:45.216Z" },
+ { url = "https://files.pythonhosted.org/packages/ed/ba/603ce3961e339413543d8cd44f21f2c80e2a7c5cfe692a7b1f2cccf58f3c/xxhash-3.6.0-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:0226aa89035b62b6a86d3c68df4d7c1f47a342b8683da2b60cedcddb46c4d95b", size = 194024, upload-time = "2025-10-02T14:35:46.959Z" },
+ { url = "https://files.pythonhosted.org/packages/78/d1/8e225ff7113bf81545cfdcd79eef124a7b7064a0bba53605ff39590b95c2/xxhash-3.6.0-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:c6e193e9f56e4ca4923c61238cdaced324f0feac782544eb4c6d55ad5cc99ddd", size = 210541, upload-time = "2025-10-02T14:35:48.301Z" },
+ { url = "https://files.pythonhosted.org/packages/6f/58/0f89d149f0bad89def1a8dd38feb50ccdeb643d9797ec84707091d4cb494/xxhash-3.6.0-cp314-cp314-musllinux_1_2_i686.whl", hash = "sha256:9176dcaddf4ca963d4deb93866d739a343c01c969231dbe21680e13a5d1a5bf0", size = 198305, upload-time = "2025-10-02T14:35:49.584Z" },
+ { url = "https://files.pythonhosted.org/packages/11/38/5eab81580703c4df93feb5f32ff8fa7fe1e2c51c1f183ee4e48d4bb9d3d7/xxhash-3.6.0-cp314-cp314-musllinux_1_2_ppc64le.whl", hash = "sha256:c1ce4009c97a752e682b897aa99aef84191077a9433eb237774689f14f8ec152", size = 210848, upload-time = "2025-10-02T14:35:50.877Z" },
+ { url = "https://files.pythonhosted.org/packages/5e/6b/953dc4b05c3ce678abca756416e4c130d2382f877a9c30a20d08ee6a77c0/xxhash-3.6.0-cp314-cp314-musllinux_1_2_s390x.whl", hash = "sha256:8cb2f4f679b01513b7adbb9b1b2f0f9cdc31b70007eaf9d59d0878809f385b11", size = 414142, upload-time = "2025-10-02T14:35:52.15Z" },
+ { url = "https://files.pythonhosted.org/packages/08/a9/238ec0d4e81a10eb5026d4a6972677cbc898ba6c8b9dbaec12ae001b1b35/xxhash-3.6.0-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:653a91d7c2ab54a92c19ccf43508b6a555440b9be1bc8be553376778be7f20b5", size = 191547, upload-time = "2025-10-02T14:35:53.547Z" },
+ { url = "https://files.pythonhosted.org/packages/f1/ee/3cf8589e06c2164ac77c3bf0aa127012801128f1feebf2a079272da5737c/xxhash-3.6.0-cp314-cp314-win32.whl", hash = "sha256:a756fe893389483ee8c394d06b5ab765d96e68fbbfe6fde7aa17e11f5720559f", size = 31214, upload-time = "2025-10-02T14:35:54.746Z" },
+ { url = "https://files.pythonhosted.org/packages/02/5d/a19552fbc6ad4cb54ff953c3908bbc095f4a921bc569433d791f755186f1/xxhash-3.6.0-cp314-cp314-win_amd64.whl", hash = "sha256:39be8e4e142550ef69629c9cd71b88c90e9a5db703fecbcf265546d9536ca4ad", size = 32290, upload-time = "2025-10-02T14:35:55.791Z" },
+ { url = "https://files.pythonhosted.org/packages/b1/11/dafa0643bc30442c887b55baf8e73353a344ee89c1901b5a5c54a6c17d39/xxhash-3.6.0-cp314-cp314-win_arm64.whl", hash = "sha256:25915e6000338999236f1eb68a02a32c3275ac338628a7eaa5a269c401995679", size = 28795, upload-time = "2025-10-02T14:35:57.162Z" },
+ { url = "https://files.pythonhosted.org/packages/2c/db/0e99732ed7f64182aef4a6fb145e1a295558deec2a746265dcdec12d191e/xxhash-3.6.0-cp314-cp314t-macosx_10_13_x86_64.whl", hash = "sha256:c5294f596a9017ca5a3e3f8884c00b91ab2ad2933cf288f4923c3fd4346cf3d4", size = 32955, upload-time = "2025-10-02T14:35:58.267Z" },
+ { url = "https://files.pythonhosted.org/packages/55/f4/2a7c3c68e564a099becfa44bb3d398810cc0ff6749b0d3cb8ccb93f23c14/xxhash-3.6.0-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:1cf9dcc4ab9cff01dfbba78544297a3a01dafd60f3bde4e2bfd016cf7e4ddc67", size = 31072, upload-time = "2025-10-02T14:35:59.382Z" },
+ { url = "https://files.pythonhosted.org/packages/c6/d9/72a29cddc7250e8a5819dad5d466facb5dc4c802ce120645630149127e73/xxhash-3.6.0-cp314-cp314t-manylinux1_i686.manylinux_2_28_i686.manylinux_2_5_i686.whl", hash = "sha256:01262da8798422d0685f7cef03b2bd3f4f46511b02830861df548d7def4402ad", size = 196579, upload-time = "2025-10-02T14:36:00.838Z" },
+ { url = "https://files.pythonhosted.org/packages/63/93/b21590e1e381040e2ca305a884d89e1c345b347404f7780f07f2cdd47ef4/xxhash-3.6.0-cp314-cp314t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:51a73fb7cb3a3ead9f7a8b583ffd9b8038e277cdb8cb87cf890e88b3456afa0b", size = 215854, upload-time = "2025-10-02T14:36:02.207Z" },
+ { url = "https://files.pythonhosted.org/packages/ce/b8/edab8a7d4fa14e924b29be877d54155dcbd8b80be85ea00d2be3413a9ed4/xxhash-3.6.0-cp314-cp314t-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:b9c6df83594f7df8f7f708ce5ebeacfc69f72c9fbaaababf6cf4758eaada0c9b", size = 214965, upload-time = "2025-10-02T14:36:03.507Z" },
+ { url = "https://files.pythonhosted.org/packages/27/67/dfa980ac7f0d509d54ea0d5a486d2bb4b80c3f1bb22b66e6a05d3efaf6c0/xxhash-3.6.0-cp314-cp314t-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:627f0af069b0ea56f312fd5189001c24578868643203bca1abbc2c52d3a6f3ca", size = 448484, upload-time = "2025-10-02T14:36:04.828Z" },
+ { url = "https://files.pythonhosted.org/packages/8c/63/8ffc2cc97e811c0ca5d00ab36604b3ea6f4254f20b7bc658ca825ce6c954/xxhash-3.6.0-cp314-cp314t-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:aa912c62f842dfd013c5f21a642c9c10cd9f4c4e943e0af83618b4a404d9091a", size = 196162, upload-time = "2025-10-02T14:36:06.182Z" },
+ { url = "https://files.pythonhosted.org/packages/4b/77/07f0e7a3edd11a6097e990f6e5b815b6592459cb16dae990d967693e6ea9/xxhash-3.6.0-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:b465afd7909db30168ab62afe40b2fcf79eedc0b89a6c0ab3123515dc0df8b99", size = 213007, upload-time = "2025-10-02T14:36:07.733Z" },
+ { url = "https://files.pythonhosted.org/packages/ae/d8/bc5fa0d152837117eb0bef6f83f956c509332ce133c91c63ce07ee7c4873/xxhash-3.6.0-cp314-cp314t-musllinux_1_2_i686.whl", hash = "sha256:a881851cf38b0a70e7c4d3ce81fc7afd86fbc2a024f4cfb2a97cf49ce04b75d3", size = 200956, upload-time = "2025-10-02T14:36:09.106Z" },
+ { url = "https://files.pythonhosted.org/packages/26/a5/d749334130de9411783873e9b98ecc46688dad5db64ca6e04b02acc8b473/xxhash-3.6.0-cp314-cp314t-musllinux_1_2_ppc64le.whl", hash = "sha256:9b3222c686a919a0f3253cfc12bb118b8b103506612253b5baeaac10d8027cf6", size = 213401, upload-time = "2025-10-02T14:36:10.585Z" },
+ { url = "https://files.pythonhosted.org/packages/89/72/abed959c956a4bfc72b58c0384bb7940663c678127538634d896b1195c10/xxhash-3.6.0-cp314-cp314t-musllinux_1_2_s390x.whl", hash = "sha256:c5aa639bc113e9286137cec8fadc20e9cd732b2cc385c0b7fa673b84fc1f2a93", size = 417083, upload-time = "2025-10-02T14:36:12.276Z" },
+ { url = "https://files.pythonhosted.org/packages/0c/b3/62fd2b586283b7d7d665fb98e266decadf31f058f1cf6c478741f68af0cb/xxhash-3.6.0-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:5c1343d49ac102799905e115aee590183c3921d475356cb24b4de29a4bc56518", size = 193913, upload-time = "2025-10-02T14:36:14.025Z" },
+ { url = "https://files.pythonhosted.org/packages/9a/9a/c19c42c5b3f5a4aad748a6d5b4f23df3bed7ee5445accc65a0fb3ff03953/xxhash-3.6.0-cp314-cp314t-win32.whl", hash = "sha256:5851f033c3030dd95c086b4a36a2683c2ff4a799b23af60977188b057e467119", size = 31586, upload-time = "2025-10-02T14:36:15.603Z" },
+ { url = "https://files.pythonhosted.org/packages/03/d6/4cc450345be9924fd5dc8c590ceda1db5b43a0a889587b0ae81a95511360/xxhash-3.6.0-cp314-cp314t-win_amd64.whl", hash = "sha256:0444e7967dac37569052d2409b00a8860c2135cff05502df4da80267d384849f", size = 32526, upload-time = "2025-10-02T14:36:16.708Z" },
+ { url = "https://files.pythonhosted.org/packages/0f/c9/7243eb3f9eaabd1a88a5a5acadf06df2d83b100c62684b7425c6a11bcaa8/xxhash-3.6.0-cp314-cp314t-win_arm64.whl", hash = "sha256:bb79b1e63f6fd84ec778a4b1916dfe0a7c3fdb986c06addd5db3a0d413819d95", size = 28898, upload-time = "2025-10-02T14:36:17.843Z" },
+]
+
+[[package]]
+name = "yarl"
+version = "1.22.0"
+source = { registry = "https://pypi.org/simple" }
+dependencies = [
+ { name = "idna" },
+ { name = "multidict" },
+ { name = "propcache" },
+]
+sdist = { url = "https://files.pythonhosted.org/packages/57/63/0c6ebca57330cd313f6102b16dd57ffaf3ec4c83403dcb45dbd15c6f3ea1/yarl-1.22.0.tar.gz", hash = "sha256:bebf8557577d4401ba8bd9ff33906f1376c877aa78d1fe216ad01b4d6745af71", size = 187169, upload-time = "2025-10-06T14:12:55.963Z" }
+wheels = [
+ { url = "https://files.pythonhosted.org/packages/75/ff/46736024fee3429b80a165a732e38e5d5a238721e634ab41b040d49f8738/yarl-1.22.0-cp312-cp312-macosx_10_13_universal2.whl", hash = "sha256:e340382d1afa5d32b892b3ff062436d592ec3d692aeea3bef3a5cfe11bbf8c6f", size = 142000, upload-time = "2025-10-06T14:09:44.631Z" },
+ { url = "https://files.pythonhosted.org/packages/5a/9a/b312ed670df903145598914770eb12de1bac44599549b3360acc96878df8/yarl-1.22.0-cp312-cp312-macosx_10_13_x86_64.whl", hash = "sha256:f1e09112a2c31ffe8d80be1b0988fa6a18c5d5cad92a9ffbb1c04c91bfe52ad2", size = 94338, upload-time = "2025-10-06T14:09:46.372Z" },
+ { url = "https://files.pythonhosted.org/packages/ba/f5/0601483296f09c3c65e303d60c070a5c19fcdbc72daa061e96170785bc7d/yarl-1.22.0-cp312-cp312-macosx_11_0_arm64.whl", hash = "sha256:939fe60db294c786f6b7c2d2e121576628468f65453d86b0fe36cb52f987bd74", size = 94909, upload-time = "2025-10-06T14:09:48.648Z" },
+ { url = "https://files.pythonhosted.org/packages/60/41/9a1fe0b73dbcefce72e46cf149b0e0a67612d60bfc90fb59c2b2efdfbd86/yarl-1.22.0-cp312-cp312-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:e1651bf8e0398574646744c1885a41198eba53dc8a9312b954073f845c90a8df", size = 372940, upload-time = "2025-10-06T14:09:50.089Z" },
+ { url = "https://files.pythonhosted.org/packages/17/7a/795cb6dfee561961c30b800f0ed616b923a2ec6258b5def2a00bf8231334/yarl-1.22.0-cp312-cp312-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:b8a0588521a26bf92a57a1705b77b8b59044cdceccac7151bd8d229e66b8dedb", size = 345825, upload-time = "2025-10-06T14:09:52.142Z" },
+ { url = "https://files.pythonhosted.org/packages/d7/93/a58f4d596d2be2ae7bab1a5846c4d270b894958845753b2c606d666744d3/yarl-1.22.0-cp312-cp312-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:42188e6a615c1a75bcaa6e150c3fe8f3e8680471a6b10150c5f7e83f47cc34d2", size = 386705, upload-time = "2025-10-06T14:09:54.128Z" },
+ { url = "https://files.pythonhosted.org/packages/61/92/682279d0e099d0e14d7fd2e176bd04f48de1484f56546a3e1313cd6c8e7c/yarl-1.22.0-cp312-cp312-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:f6d2cb59377d99718913ad9a151030d6f83ef420a2b8f521d94609ecc106ee82", size = 396518, upload-time = "2025-10-06T14:09:55.762Z" },
+ { url = "https://files.pythonhosted.org/packages/db/0f/0d52c98b8a885aeda831224b78f3be7ec2e1aa4a62091f9f9188c3c65b56/yarl-1.22.0-cp312-cp312-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:50678a3b71c751d58d7908edc96d332af328839eea883bb554a43f539101277a", size = 377267, upload-time = "2025-10-06T14:09:57.958Z" },
+ { url = "https://files.pythonhosted.org/packages/22/42/d2685e35908cbeaa6532c1fc73e89e7f2efb5d8a7df3959ea8e37177c5a3/yarl-1.22.0-cp312-cp312-musllinux_1_2_aarch64.whl", hash = "sha256:1e8fbaa7cec507aa24ea27a01456e8dd4b6fab829059b69844bd348f2d467124", size = 365797, upload-time = "2025-10-06T14:09:59.527Z" },
+ { url = "https://files.pythonhosted.org/packages/a2/83/cf8c7bcc6355631762f7d8bdab920ad09b82efa6b722999dfb05afa6cfac/yarl-1.22.0-cp312-cp312-musllinux_1_2_armv7l.whl", hash = "sha256:433885ab5431bc3d3d4f2f9bd15bfa1614c522b0f1405d62c4f926ccd69d04fa", size = 365535, upload-time = "2025-10-06T14:10:01.139Z" },
+ { url = "https://files.pythonhosted.org/packages/25/e1/5302ff9b28f0c59cac913b91fe3f16c59a033887e57ce9ca5d41a3a94737/yarl-1.22.0-cp312-cp312-musllinux_1_2_ppc64le.whl", hash = "sha256:b790b39c7e9a4192dc2e201a282109ed2985a1ddbd5ac08dc56d0e121400a8f7", size = 382324, upload-time = "2025-10-06T14:10:02.756Z" },
+ { url = "https://files.pythonhosted.org/packages/bf/cd/4617eb60f032f19ae3a688dc990d8f0d89ee0ea378b61cac81ede3e52fae/yarl-1.22.0-cp312-cp312-musllinux_1_2_s390x.whl", hash = "sha256:31f0b53913220599446872d757257be5898019c85e7971599065bc55065dc99d", size = 383803, upload-time = "2025-10-06T14:10:04.552Z" },
+ { url = "https://files.pythonhosted.org/packages/59/65/afc6e62bb506a319ea67b694551dab4a7e6fb7bf604e9bd9f3e11d575fec/yarl-1.22.0-cp312-cp312-musllinux_1_2_x86_64.whl", hash = "sha256:a49370e8f711daec68d09b821a34e1167792ee2d24d405cbc2387be4f158b520", size = 374220, upload-time = "2025-10-06T14:10:06.489Z" },
+ { url = "https://files.pythonhosted.org/packages/e7/3d/68bf18d50dc674b942daec86a9ba922d3113d8399b0e52b9897530442da2/yarl-1.22.0-cp312-cp312-win32.whl", hash = "sha256:70dfd4f241c04bd9239d53b17f11e6ab672b9f1420364af63e8531198e3f5fe8", size = 81589, upload-time = "2025-10-06T14:10:09.254Z" },
+ { url = "https://files.pythonhosted.org/packages/c8/9a/6ad1a9b37c2f72874f93e691b2e7ecb6137fb2b899983125db4204e47575/yarl-1.22.0-cp312-cp312-win_amd64.whl", hash = "sha256:8884d8b332a5e9b88e23f60bb166890009429391864c685e17bd73a9eda9105c", size = 87213, upload-time = "2025-10-06T14:10:11.369Z" },
+ { url = "https://files.pythonhosted.org/packages/44/c5/c21b562d1680a77634d748e30c653c3ca918beb35555cff24986fff54598/yarl-1.22.0-cp312-cp312-win_arm64.whl", hash = "sha256:ea70f61a47f3cc93bdf8b2f368ed359ef02a01ca6393916bc8ff877427181e74", size = 81330, upload-time = "2025-10-06T14:10:13.112Z" },
+ { url = "https://files.pythonhosted.org/packages/ea/f3/d67de7260456ee105dc1d162d43a019ecad6b91e2f51809d6cddaa56690e/yarl-1.22.0-cp313-cp313-macosx_10_13_universal2.whl", hash = "sha256:8dee9c25c74997f6a750cd317b8ca63545169c098faee42c84aa5e506c819b53", size = 139980, upload-time = "2025-10-06T14:10:14.601Z" },
+ { url = "https://files.pythonhosted.org/packages/01/88/04d98af0b47e0ef42597b9b28863b9060bb515524da0a65d5f4db160b2d5/yarl-1.22.0-cp313-cp313-macosx_10_13_x86_64.whl", hash = "sha256:01e73b85a5434f89fc4fe27dcda2aff08ddf35e4d47bbbea3bdcd25321af538a", size = 93424, upload-time = "2025-10-06T14:10:16.115Z" },
+ { url = "https://files.pythonhosted.org/packages/18/91/3274b215fd8442a03975ce6bee5fe6aa57a8326b29b9d3d56234a1dca244/yarl-1.22.0-cp313-cp313-macosx_11_0_arm64.whl", hash = "sha256:22965c2af250d20c873cdbee8ff958fb809940aeb2e74ba5f20aaf6b7ac8c70c", size = 93821, upload-time = "2025-10-06T14:10:17.993Z" },
+ { url = "https://files.pythonhosted.org/packages/61/3a/caf4e25036db0f2da4ca22a353dfeb3c9d3c95d2761ebe9b14df8fc16eb0/yarl-1.22.0-cp313-cp313-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:b4f15793aa49793ec8d1c708ab7f9eded1aa72edc5174cae703651555ed1b601", size = 373243, upload-time = "2025-10-06T14:10:19.44Z" },
+ { url = "https://files.pythonhosted.org/packages/6e/9e/51a77ac7516e8e7803b06e01f74e78649c24ee1021eca3d6a739cb6ea49c/yarl-1.22.0-cp313-cp313-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:e5542339dcf2747135c5c85f68680353d5cb9ffd741c0f2e8d832d054d41f35a", size = 342361, upload-time = "2025-10-06T14:10:21.124Z" },
+ { url = "https://files.pythonhosted.org/packages/d4/f8/33b92454789dde8407f156c00303e9a891f1f51a0330b0fad7c909f87692/yarl-1.22.0-cp313-cp313-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:5c401e05ad47a75869c3ab3e35137f8468b846770587e70d71e11de797d113df", size = 387036, upload-time = "2025-10-06T14:10:22.902Z" },
+ { url = "https://files.pythonhosted.org/packages/d9/9a/c5db84ea024f76838220280f732970aa4ee154015d7f5c1bfb60a267af6f/yarl-1.22.0-cp313-cp313-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:243dda95d901c733f5b59214d28b0120893d91777cb8aa043e6ef059d3cddfe2", size = 397671, upload-time = "2025-10-06T14:10:24.523Z" },
+ { url = "https://files.pythonhosted.org/packages/11/c9/cd8538dc2e7727095e0c1d867bad1e40c98f37763e6d995c1939f5fdc7b1/yarl-1.22.0-cp313-cp313-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:bec03d0d388060058f5d291a813f21c011041938a441c593374da6077fe21b1b", size = 377059, upload-time = "2025-10-06T14:10:26.406Z" },
+ { url = "https://files.pythonhosted.org/packages/a1/b9/ab437b261702ced75122ed78a876a6dec0a1b0f5e17a4ac7a9a2482d8abe/yarl-1.22.0-cp313-cp313-musllinux_1_2_aarch64.whl", hash = "sha256:b0748275abb8c1e1e09301ee3cf90c8a99678a4e92e4373705f2a2570d581273", size = 365356, upload-time = "2025-10-06T14:10:28.461Z" },
+ { url = "https://files.pythonhosted.org/packages/b2/9d/8e1ae6d1d008a9567877b08f0ce4077a29974c04c062dabdb923ed98e6fe/yarl-1.22.0-cp313-cp313-musllinux_1_2_armv7l.whl", hash = "sha256:47fdb18187e2a4e18fda2c25c05d8251a9e4a521edaed757fef033e7d8498d9a", size = 361331, upload-time = "2025-10-06T14:10:30.541Z" },
+ { url = "https://files.pythonhosted.org/packages/ca/5a/09b7be3905962f145b73beb468cdd53db8aa171cf18c80400a54c5b82846/yarl-1.22.0-cp313-cp313-musllinux_1_2_ppc64le.whl", hash = "sha256:c7044802eec4524fde550afc28edda0dd5784c4c45f0be151a2d3ba017daca7d", size = 382590, upload-time = "2025-10-06T14:10:33.352Z" },
+ { url = "https://files.pythonhosted.org/packages/aa/7f/59ec509abf90eda5048b0bc3e2d7b5099dffdb3e6b127019895ab9d5ef44/yarl-1.22.0-cp313-cp313-musllinux_1_2_s390x.whl", hash = "sha256:139718f35149ff544caba20fce6e8a2f71f1e39b92c700d8438a0b1d2a631a02", size = 385316, upload-time = "2025-10-06T14:10:35.034Z" },
+ { url = "https://files.pythonhosted.org/packages/e5/84/891158426bc8036bfdfd862fabd0e0fa25df4176ec793e447f4b85cf1be4/yarl-1.22.0-cp313-cp313-musllinux_1_2_x86_64.whl", hash = "sha256:e1b51bebd221006d3d2f95fbe124b22b247136647ae5dcc8c7acafba66e5ee67", size = 374431, upload-time = "2025-10-06T14:10:37.76Z" },
+ { url = "https://files.pythonhosted.org/packages/bb/49/03da1580665baa8bef5e8ed34c6df2c2aca0a2f28bf397ed238cc1bbc6f2/yarl-1.22.0-cp313-cp313-win32.whl", hash = "sha256:d3e32536234a95f513bd374e93d717cf6b2231a791758de6c509e3653f234c95", size = 81555, upload-time = "2025-10-06T14:10:39.649Z" },
+ { url = "https://files.pythonhosted.org/packages/9a/ee/450914ae11b419eadd067c6183ae08381cfdfcb9798b90b2b713bbebddda/yarl-1.22.0-cp313-cp313-win_amd64.whl", hash = "sha256:47743b82b76d89a1d20b83e60d5c20314cbd5ba2befc9cda8f28300c4a08ed4d", size = 86965, upload-time = "2025-10-06T14:10:41.313Z" },
+ { url = "https://files.pythonhosted.org/packages/98/4d/264a01eae03b6cf629ad69bae94e3b0e5344741e929073678e84bf7a3e3b/yarl-1.22.0-cp313-cp313-win_arm64.whl", hash = "sha256:5d0fcda9608875f7d052eff120c7a5da474a6796fe4d83e152e0e4d42f6d1a9b", size = 81205, upload-time = "2025-10-06T14:10:43.167Z" },
+ { url = "https://files.pythonhosted.org/packages/88/fc/6908f062a2f77b5f9f6d69cecb1747260831ff206adcbc5b510aff88df91/yarl-1.22.0-cp313-cp313t-macosx_10_13_universal2.whl", hash = "sha256:719ae08b6972befcba4310e49edb1161a88cdd331e3a694b84466bd938a6ab10", size = 146209, upload-time = "2025-10-06T14:10:44.643Z" },
+ { url = "https://files.pythonhosted.org/packages/65/47/76594ae8eab26210b4867be6f49129861ad33da1f1ebdf7051e98492bf62/yarl-1.22.0-cp313-cp313t-macosx_10_13_x86_64.whl", hash = "sha256:47d8a5c446df1c4db9d21b49619ffdba90e77c89ec6e283f453856c74b50b9e3", size = 95966, upload-time = "2025-10-06T14:10:46.554Z" },
+ { url = "https://files.pythonhosted.org/packages/ab/ce/05e9828a49271ba6b5b038b15b3934e996980dd78abdfeb52a04cfb9467e/yarl-1.22.0-cp313-cp313t-macosx_11_0_arm64.whl", hash = "sha256:cfebc0ac8333520d2d0423cbbe43ae43c8838862ddb898f5ca68565e395516e9", size = 97312, upload-time = "2025-10-06T14:10:48.007Z" },
+ { url = "https://files.pythonhosted.org/packages/d1/c5/7dffad5e4f2265b29c9d7ec869c369e4223166e4f9206fc2243ee9eea727/yarl-1.22.0-cp313-cp313t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:4398557cbf484207df000309235979c79c4356518fd5c99158c7d38203c4da4f", size = 361967, upload-time = "2025-10-06T14:10:49.997Z" },
+ { url = "https://files.pythonhosted.org/packages/50/b2/375b933c93a54bff7fc041e1a6ad2c0f6f733ffb0c6e642ce56ee3b39970/yarl-1.22.0-cp313-cp313t-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:2ca6fd72a8cd803be290d42f2dec5cdcd5299eeb93c2d929bf060ad9efaf5de0", size = 323949, upload-time = "2025-10-06T14:10:52.004Z" },
+ { url = "https://files.pythonhosted.org/packages/66/50/bfc2a29a1d78644c5a7220ce2f304f38248dc94124a326794e677634b6cf/yarl-1.22.0-cp313-cp313t-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:ca1f59c4e1ab6e72f0a23c13fca5430f889634166be85dbf1013683e49e3278e", size = 361818, upload-time = "2025-10-06T14:10:54.078Z" },
+ { url = "https://files.pythonhosted.org/packages/46/96/f3941a46af7d5d0f0498f86d71275696800ddcdd20426298e572b19b91ff/yarl-1.22.0-cp313-cp313t-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:6c5010a52015e7c70f86eb967db0f37f3c8bd503a695a49f8d45700144667708", size = 372626, upload-time = "2025-10-06T14:10:55.767Z" },
+ { url = "https://files.pythonhosted.org/packages/c1/42/8b27c83bb875cd89448e42cd627e0fb971fa1675c9ec546393d18826cb50/yarl-1.22.0-cp313-cp313t-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:9d7672ecf7557476642c88497c2f8d8542f8e36596e928e9bcba0e42e1e7d71f", size = 341129, upload-time = "2025-10-06T14:10:57.985Z" },
+ { url = "https://files.pythonhosted.org/packages/49/36/99ca3122201b382a3cf7cc937b95235b0ac944f7e9f2d5331d50821ed352/yarl-1.22.0-cp313-cp313t-musllinux_1_2_aarch64.whl", hash = "sha256:3b7c88eeef021579d600e50363e0b6ee4f7f6f728cd3486b9d0f3ee7b946398d", size = 346776, upload-time = "2025-10-06T14:10:59.633Z" },
+ { url = "https://files.pythonhosted.org/packages/85/b4/47328bf996acd01a4c16ef9dcd2f59c969f495073616586f78cd5f2efb99/yarl-1.22.0-cp313-cp313t-musllinux_1_2_armv7l.whl", hash = "sha256:f4afb5c34f2c6fecdcc182dfcfc6af6cccf1aa923eed4d6a12e9d96904e1a0d8", size = 334879, upload-time = "2025-10-06T14:11:01.454Z" },
+ { url = "https://files.pythonhosted.org/packages/c2/ad/b77d7b3f14a4283bffb8e92c6026496f6de49751c2f97d4352242bba3990/yarl-1.22.0-cp313-cp313t-musllinux_1_2_ppc64le.whl", hash = "sha256:59c189e3e99a59cf8d83cbb31d4db02d66cda5a1a4374e8a012b51255341abf5", size = 350996, upload-time = "2025-10-06T14:11:03.452Z" },
+ { url = "https://files.pythonhosted.org/packages/81/c8/06e1d69295792ba54d556f06686cbd6a7ce39c22307100e3fb4a2c0b0a1d/yarl-1.22.0-cp313-cp313t-musllinux_1_2_s390x.whl", hash = "sha256:5a3bf7f62a289fa90f1990422dc8dff5a458469ea71d1624585ec3a4c8d6960f", size = 356047, upload-time = "2025-10-06T14:11:05.115Z" },
+ { url = "https://files.pythonhosted.org/packages/4b/b8/4c0e9e9f597074b208d18cef227d83aac36184bfbc6eab204ea55783dbc5/yarl-1.22.0-cp313-cp313t-musllinux_1_2_x86_64.whl", hash = "sha256:de6b9a04c606978fdfe72666fa216ffcf2d1a9f6a381058d4378f8d7b1e5de62", size = 342947, upload-time = "2025-10-06T14:11:08.137Z" },
+ { url = "https://files.pythonhosted.org/packages/e0/e5/11f140a58bf4c6ad7aca69a892bff0ee638c31bea4206748fc0df4ebcb3a/yarl-1.22.0-cp313-cp313t-win32.whl", hash = "sha256:1834bb90991cc2999f10f97f5f01317f99b143284766d197e43cd5b45eb18d03", size = 86943, upload-time = "2025-10-06T14:11:10.284Z" },
+ { url = "https://files.pythonhosted.org/packages/31/74/8b74bae38ed7fe6793d0c15a0c8207bbb819cf287788459e5ed230996cdd/yarl-1.22.0-cp313-cp313t-win_amd64.whl", hash = "sha256:ff86011bd159a9d2dfc89c34cfd8aff12875980e3bd6a39ff097887520e60249", size = 93715, upload-time = "2025-10-06T14:11:11.739Z" },
+ { url = "https://files.pythonhosted.org/packages/69/66/991858aa4b5892d57aef7ee1ba6b4d01ec3b7eb3060795d34090a3ca3278/yarl-1.22.0-cp313-cp313t-win_arm64.whl", hash = "sha256:7861058d0582b847bc4e3a4a4c46828a410bca738673f35a29ba3ca5db0b473b", size = 83857, upload-time = "2025-10-06T14:11:13.586Z" },
+ { url = "https://files.pythonhosted.org/packages/46/b3/e20ef504049f1a1c54a814b4b9bed96d1ac0e0610c3b4da178f87209db05/yarl-1.22.0-cp314-cp314-macosx_10_13_universal2.whl", hash = "sha256:34b36c2c57124530884d89d50ed2c1478697ad7473efd59cfd479945c95650e4", size = 140520, upload-time = "2025-10-06T14:11:15.465Z" },
+ { url = "https://files.pythonhosted.org/packages/e4/04/3532d990fdbab02e5ede063676b5c4260e7f3abea2151099c2aa745acc4c/yarl-1.22.0-cp314-cp314-macosx_10_13_x86_64.whl", hash = "sha256:0dd9a702591ca2e543631c2a017e4a547e38a5c0f29eece37d9097e04a7ac683", size = 93504, upload-time = "2025-10-06T14:11:17.106Z" },
+ { url = "https://files.pythonhosted.org/packages/11/63/ff458113c5c2dac9a9719ac68ee7c947cb621432bcf28c9972b1c0e83938/yarl-1.22.0-cp314-cp314-macosx_11_0_arm64.whl", hash = "sha256:594fcab1032e2d2cc3321bb2e51271e7cd2b516c7d9aee780ece81b07ff8244b", size = 94282, upload-time = "2025-10-06T14:11:19.064Z" },
+ { url = "https://files.pythonhosted.org/packages/a7/bc/315a56aca762d44a6aaaf7ad253f04d996cb6b27bad34410f82d76ea8038/yarl-1.22.0-cp314-cp314-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:f3d7a87a78d46a2e3d5b72587ac14b4c16952dd0887dbb051451eceac774411e", size = 372080, upload-time = "2025-10-06T14:11:20.996Z" },
+ { url = "https://files.pythonhosted.org/packages/3f/3f/08e9b826ec2e099ea6e7c69a61272f4f6da62cb5b1b63590bb80ca2e4a40/yarl-1.22.0-cp314-cp314-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:852863707010316c973162e703bddabec35e8757e67fcb8ad58829de1ebc8590", size = 338696, upload-time = "2025-10-06T14:11:22.847Z" },
+ { url = "https://files.pythonhosted.org/packages/e3/9f/90360108e3b32bd76789088e99538febfea24a102380ae73827f62073543/yarl-1.22.0-cp314-cp314-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:131a085a53bfe839a477c0845acf21efc77457ba2bcf5899618136d64f3303a2", size = 387121, upload-time = "2025-10-06T14:11:24.889Z" },
+ { url = "https://files.pythonhosted.org/packages/98/92/ab8d4657bd5b46a38094cfaea498f18bb70ce6b63508fd7e909bd1f93066/yarl-1.22.0-cp314-cp314-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:078a8aefd263f4d4f923a9677b942b445a2be970ca24548a8102689a3a8ab8da", size = 394080, upload-time = "2025-10-06T14:11:27.307Z" },
+ { url = "https://files.pythonhosted.org/packages/f5/e7/d8c5a7752fef68205296201f8ec2bf718f5c805a7a7e9880576c67600658/yarl-1.22.0-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:bca03b91c323036913993ff5c738d0842fc9c60c4648e5c8d98331526df89784", size = 372661, upload-time = "2025-10-06T14:11:29.387Z" },
+ { url = "https://files.pythonhosted.org/packages/b6/2e/f4d26183c8db0bb82d491b072f3127fb8c381a6206a3a56332714b79b751/yarl-1.22.0-cp314-cp314-musllinux_1_2_aarch64.whl", hash = "sha256:68986a61557d37bb90d3051a45b91fa3d5c516d177dfc6dd6f2f436a07ff2b6b", size = 364645, upload-time = "2025-10-06T14:11:31.423Z" },
+ { url = "https://files.pythonhosted.org/packages/80/7c/428e5812e6b87cd00ee8e898328a62c95825bf37c7fa87f0b6bb2ad31304/yarl-1.22.0-cp314-cp314-musllinux_1_2_armv7l.whl", hash = "sha256:4792b262d585ff0dff6bcb787f8492e40698443ec982a3568c2096433660c694", size = 355361, upload-time = "2025-10-06T14:11:33.055Z" },
+ { url = "https://files.pythonhosted.org/packages/ec/2a/249405fd26776f8b13c067378ef4d7dd49c9098d1b6457cdd152a99e96a9/yarl-1.22.0-cp314-cp314-musllinux_1_2_ppc64le.whl", hash = "sha256:ebd4549b108d732dba1d4ace67614b9545b21ece30937a63a65dd34efa19732d", size = 381451, upload-time = "2025-10-06T14:11:35.136Z" },
+ { url = "https://files.pythonhosted.org/packages/67/a8/fb6b1adbe98cf1e2dd9fad71003d3a63a1bc22459c6e15f5714eb9323b93/yarl-1.22.0-cp314-cp314-musllinux_1_2_s390x.whl", hash = "sha256:f87ac53513d22240c7d59203f25cc3beac1e574c6cd681bbfd321987b69f95fd", size = 383814, upload-time = "2025-10-06T14:11:37.094Z" },
+ { url = "https://files.pythonhosted.org/packages/d9/f9/3aa2c0e480fb73e872ae2814c43bc1e734740bb0d54e8cb2a95925f98131/yarl-1.22.0-cp314-cp314-musllinux_1_2_x86_64.whl", hash = "sha256:22b029f2881599e2f1b06f8f1db2ee63bd309e2293ba2d566e008ba12778b8da", size = 370799, upload-time = "2025-10-06T14:11:38.83Z" },
+ { url = "https://files.pythonhosted.org/packages/50/3c/af9dba3b8b5eeb302f36f16f92791f3ea62e3f47763406abf6d5a4a3333b/yarl-1.22.0-cp314-cp314-win32.whl", hash = "sha256:6a635ea45ba4ea8238463b4f7d0e721bad669f80878b7bfd1f89266e2ae63da2", size = 82990, upload-time = "2025-10-06T14:11:40.624Z" },
+ { url = "https://files.pythonhosted.org/packages/ac/30/ac3a0c5bdc1d6efd1b41fa24d4897a4329b3b1e98de9449679dd327af4f0/yarl-1.22.0-cp314-cp314-win_amd64.whl", hash = "sha256:0d6e6885777af0f110b0e5d7e5dda8b704efed3894da26220b7f3d887b839a79", size = 88292, upload-time = "2025-10-06T14:11:42.578Z" },
+ { url = "https://files.pythonhosted.org/packages/df/0a/227ab4ff5b998a1b7410abc7b46c9b7a26b0ca9e86c34ba4b8d8bc7c63d5/yarl-1.22.0-cp314-cp314-win_arm64.whl", hash = "sha256:8218f4e98d3c10d683584cb40f0424f4b9fd6e95610232dd75e13743b070ee33", size = 82888, upload-time = "2025-10-06T14:11:44.863Z" },
+ { url = "https://files.pythonhosted.org/packages/06/5e/a15eb13db90abd87dfbefb9760c0f3f257ac42a5cac7e75dbc23bed97a9f/yarl-1.22.0-cp314-cp314t-macosx_10_13_universal2.whl", hash = "sha256:45c2842ff0e0d1b35a6bf1cd6c690939dacb617a70827f715232b2e0494d55d1", size = 146223, upload-time = "2025-10-06T14:11:46.796Z" },
+ { url = "https://files.pythonhosted.org/packages/18/82/9665c61910d4d84f41a5bf6837597c89e665fa88aa4941080704645932a9/yarl-1.22.0-cp314-cp314t-macosx_10_13_x86_64.whl", hash = "sha256:d947071e6ebcf2e2bee8fce76e10faca8f7a14808ca36a910263acaacef08eca", size = 95981, upload-time = "2025-10-06T14:11:48.845Z" },
+ { url = "https://files.pythonhosted.org/packages/5d/9a/2f65743589809af4d0a6d3aa749343c4b5f4c380cc24a8e94a3c6625a808/yarl-1.22.0-cp314-cp314t-macosx_11_0_arm64.whl", hash = "sha256:334b8721303e61b00019474cc103bdac3d7b1f65e91f0bfedeec2d56dfe74b53", size = 97303, upload-time = "2025-10-06T14:11:50.897Z" },
+ { url = "https://files.pythonhosted.org/packages/b0/ab/5b13d3e157505c43c3b43b5a776cbf7b24a02bc4cccc40314771197e3508/yarl-1.22.0-cp314-cp314t-manylinux2014_aarch64.manylinux_2_17_aarch64.manylinux_2_28_aarch64.whl", hash = "sha256:1e7ce67c34138a058fd092f67d07a72b8e31ff0c9236e751957465a24b28910c", size = 361820, upload-time = "2025-10-06T14:11:52.549Z" },
+ { url = "https://files.pythonhosted.org/packages/fb/76/242a5ef4677615cf95330cfc1b4610e78184400699bdda0acb897ef5e49a/yarl-1.22.0-cp314-cp314t-manylinux2014_armv7l.manylinux_2_17_armv7l.manylinux_2_31_armv7l.whl", hash = "sha256:d77e1b2c6d04711478cb1c4ab90db07f1609ccf06a287d5607fcd90dc9863acf", size = 323203, upload-time = "2025-10-06T14:11:54.225Z" },
+ { url = "https://files.pythonhosted.org/packages/8c/96/475509110d3f0153b43d06164cf4195c64d16999e0c7e2d8a099adcd6907/yarl-1.22.0-cp314-cp314t-manylinux2014_ppc64le.manylinux_2_17_ppc64le.manylinux_2_28_ppc64le.whl", hash = "sha256:c4647674b6150d2cae088fc07de2738a84b8bcedebef29802cf0b0a82ab6face", size = 363173, upload-time = "2025-10-06T14:11:56.069Z" },
+ { url = "https://files.pythonhosted.org/packages/c9/66/59db471aecfbd559a1fd48aedd954435558cd98c7d0da8b03cc6c140a32c/yarl-1.22.0-cp314-cp314t-manylinux2014_s390x.manylinux_2_17_s390x.manylinux_2_28_s390x.whl", hash = "sha256:efb07073be061c8f79d03d04139a80ba33cbd390ca8f0297aae9cce6411e4c6b", size = 373562, upload-time = "2025-10-06T14:11:58.783Z" },
+ { url = "https://files.pythonhosted.org/packages/03/1f/c5d94abc91557384719da10ff166b916107c1b45e4d0423a88457071dd88/yarl-1.22.0-cp314-cp314t-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl", hash = "sha256:e51ac5435758ba97ad69617e13233da53908beccc6cfcd6c34bbed8dcbede486", size = 339828, upload-time = "2025-10-06T14:12:00.686Z" },
+ { url = "https://files.pythonhosted.org/packages/5f/97/aa6a143d3afba17b6465733681c70cf175af89f76ec8d9286e08437a7454/yarl-1.22.0-cp314-cp314t-musllinux_1_2_aarch64.whl", hash = "sha256:33e32a0dd0c8205efa8e83d04fc9f19313772b78522d1bdc7d9aed706bfd6138", size = 347551, upload-time = "2025-10-06T14:12:02.628Z" },
+ { url = "https://files.pythonhosted.org/packages/43/3c/45a2b6d80195959239a7b2a8810506d4eea5487dce61c2a3393e7fc3c52e/yarl-1.22.0-cp314-cp314t-musllinux_1_2_armv7l.whl", hash = "sha256:bf4a21e58b9cde0e401e683ebd00f6ed30a06d14e93f7c8fd059f8b6e8f87b6a", size = 334512, upload-time = "2025-10-06T14:12:04.871Z" },
+ { url = "https://files.pythonhosted.org/packages/86/a0/c2ab48d74599c7c84cb104ebd799c5813de252bea0f360ffc29d270c2caa/yarl-1.22.0-cp314-cp314t-musllinux_1_2_ppc64le.whl", hash = "sha256:e4b582bab49ac33c8deb97e058cd67c2c50dac0dd134874106d9c774fd272529", size = 352400, upload-time = "2025-10-06T14:12:06.624Z" },
+ { url = "https://files.pythonhosted.org/packages/32/75/f8919b2eafc929567d3d8411f72bdb1a2109c01caaab4ebfa5f8ffadc15b/yarl-1.22.0-cp314-cp314t-musllinux_1_2_s390x.whl", hash = "sha256:0b5bcc1a9c4839e7e30b7b30dd47fe5e7e44fb7054ec29b5bb8d526aa1041093", size = 357140, upload-time = "2025-10-06T14:12:08.362Z" },
+ { url = "https://files.pythonhosted.org/packages/cf/72/6a85bba382f22cf78add705d8c3731748397d986e197e53ecc7835e76de7/yarl-1.22.0-cp314-cp314t-musllinux_1_2_x86_64.whl", hash = "sha256:c0232bce2170103ec23c454e54a57008a9a72b5d1c3105dc2496750da8cfa47c", size = 341473, upload-time = "2025-10-06T14:12:10.994Z" },
+ { url = "https://files.pythonhosted.org/packages/35/18/55e6011f7c044dc80b98893060773cefcfdbf60dfefb8cb2f58b9bacbd83/yarl-1.22.0-cp314-cp314t-win32.whl", hash = "sha256:8009b3173bcd637be650922ac455946197d858b3630b6d8787aa9e5c4564533e", size = 89056, upload-time = "2025-10-06T14:12:13.317Z" },
+ { url = "https://files.pythonhosted.org/packages/f9/86/0f0dccb6e59a9e7f122c5afd43568b1d31b8ab7dda5f1b01fb5c7025c9a9/yarl-1.22.0-cp314-cp314t-win_amd64.whl", hash = "sha256:9fb17ea16e972c63d25d4a97f016d235c78dd2344820eb35bc034bc32012ee27", size = 96292, upload-time = "2025-10-06T14:12:15.398Z" },
+ { url = "https://files.pythonhosted.org/packages/48/b7/503c98092fb3b344a179579f55814b613c1fbb1c23b3ec14a7b008a66a6e/yarl-1.22.0-cp314-cp314t-win_arm64.whl", hash = "sha256:9f6d73c1436b934e3f01df1e1b21ff765cd1d28c77dfb9ace207f746d4610ee1", size = 85171, upload-time = "2025-10-06T14:12:16.935Z" },
+ { url = "https://files.pythonhosted.org/packages/73/ae/b48f95715333080afb75a4504487cbe142cae1268afc482d06692d605ae6/yarl-1.22.0-py3-none-any.whl", hash = "sha256:1380560bdba02b6b6c90de54133c81c9f2a453dee9912fe58c1dcced1edb7cff", size = 46814, upload-time = "2025-10-06T14:12:53.872Z" },
+]
 +
+ 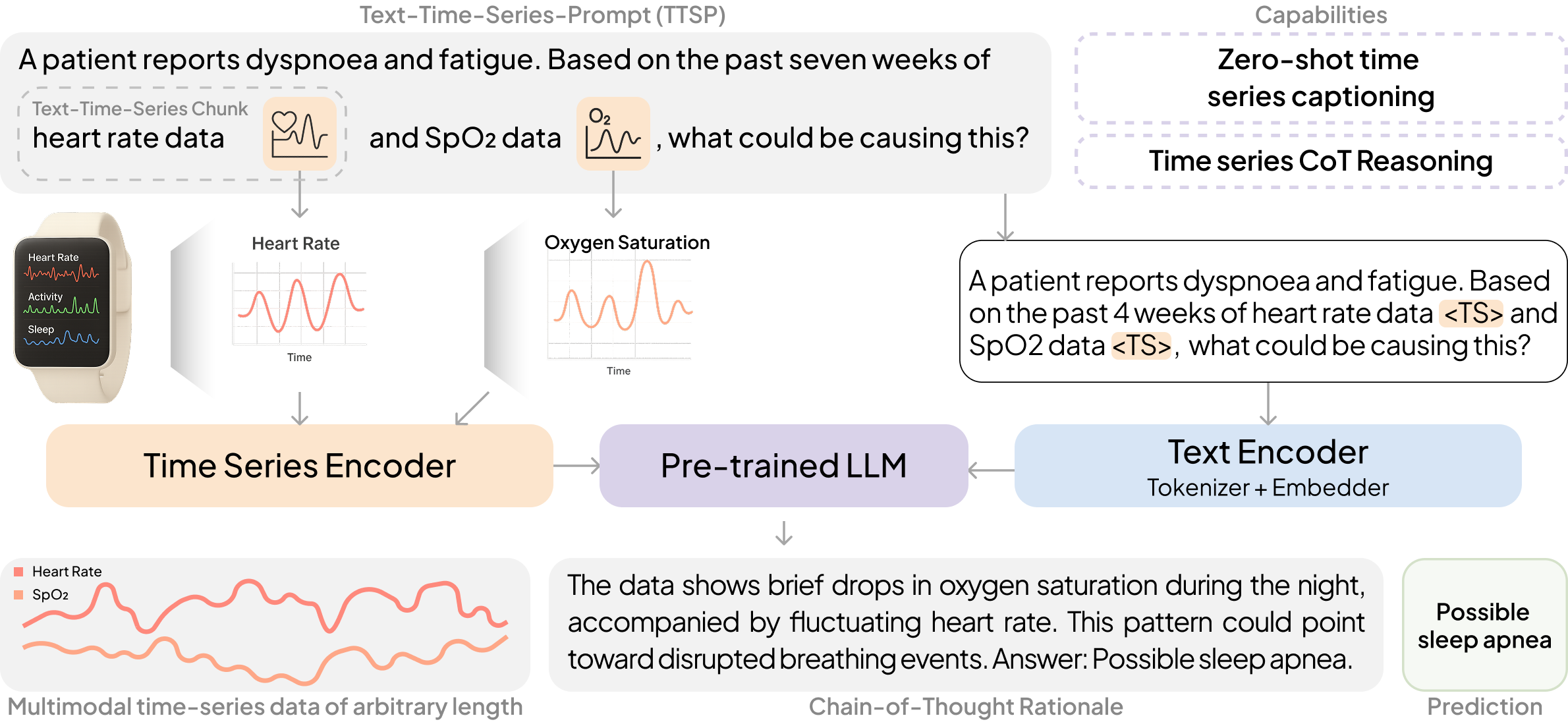
 -
-  -
-  +
+  +
+ 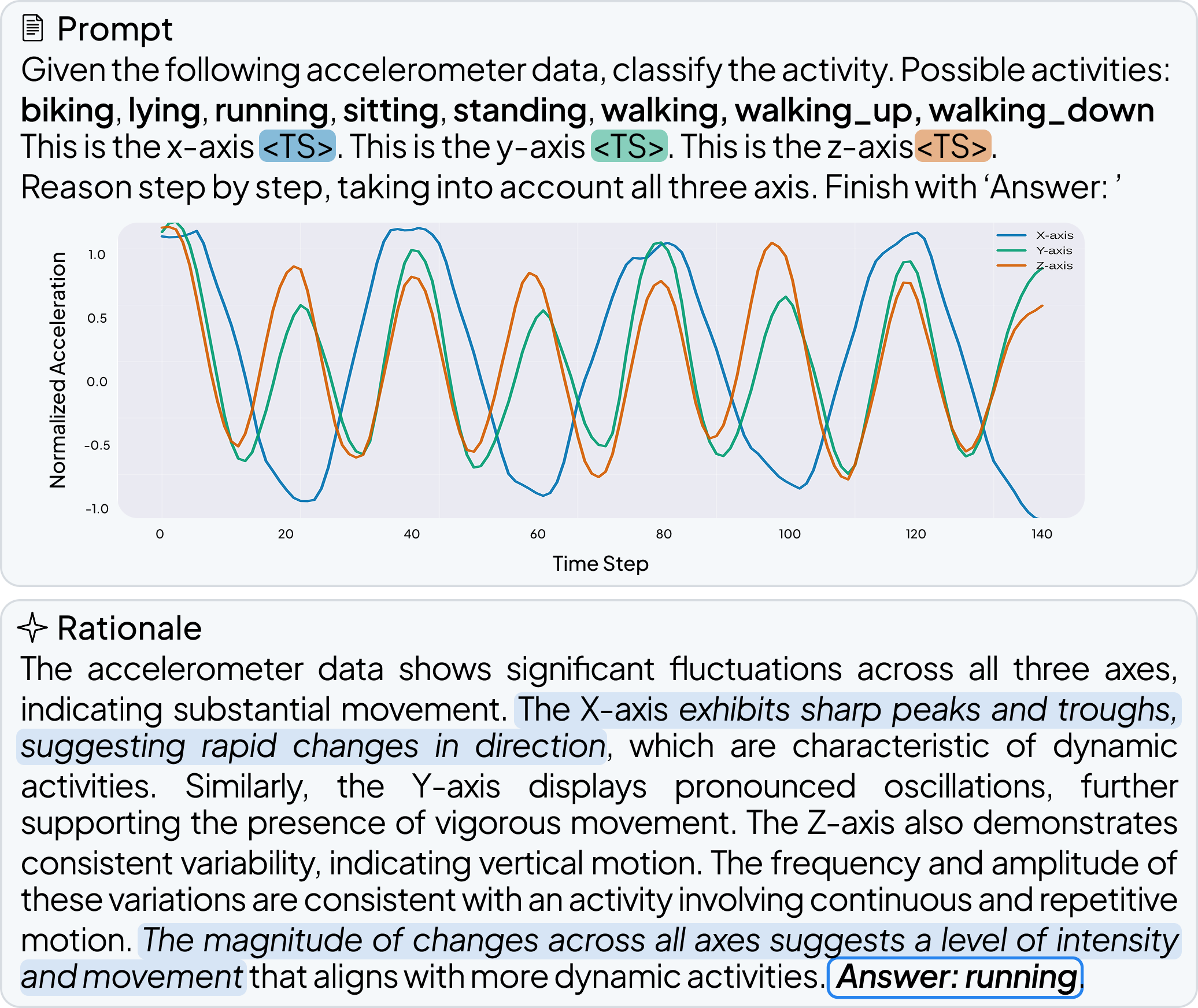 +
+ 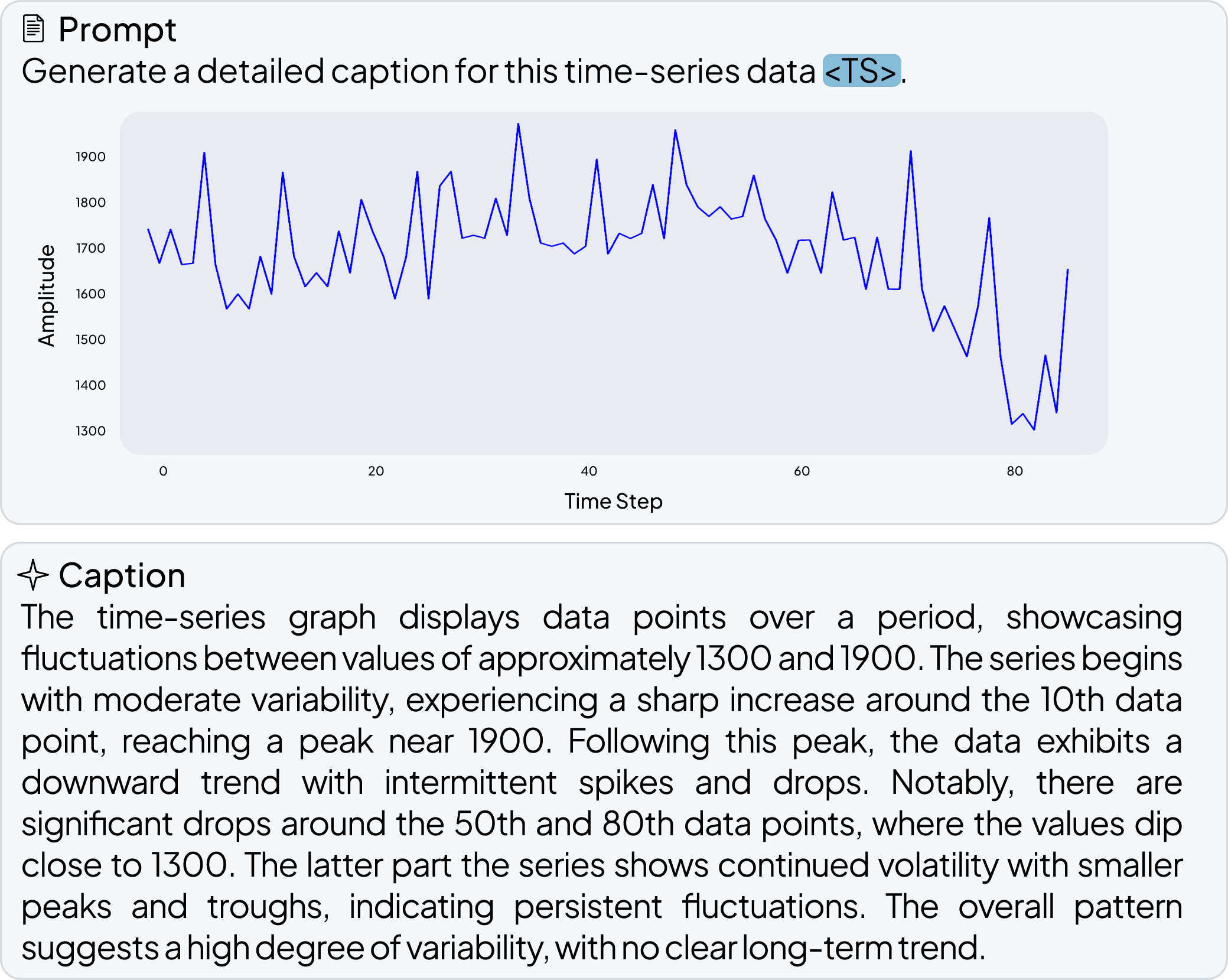
 -
-  +
+  +
+ 